SpringCloud-Ribbon:认识并配置负载均衡
什么是负载均衡?
LB,即负载均衡(Load Balance),在微服务或分布式集群中经常用的一种应用。简单来说,随着业务的发展,单台服务无法支撑访问的需要,于是搭建多个服务形成集群。那么随之要解决的是,每次请求,调用哪个服务,也就是需要进行负载均衡,从而达到系统的HA(高可用)。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间并避免任何单一资源的过载。
目前负载均衡常用的有两种模式:
-
客户端模式(集中式LB)
- 即在服务的消费方和提供方之间使用独立的LB设施,如Nginx,由改设施负责把访问请求通过某种策略转发至服务的提供方!
-
服务端模式(进程式LB)
- 将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选一个合适的服务器。
- Ribbon就属于这种模式,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务方提供的地址。
什么是Ribbon?
我们也上面也提到了Ribbon是属于C负载均衡的服务端模式,那么什么是Ribbon?
我们这里要介绍的Ribbon是SpringCloud Ribbon,是基于Netflix Ribbon的一套客户端负载均衡工具。简单来说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起。Ribbon的客户端组件提供一系列完整的配置项如:连接超时,重试等等。简单的说,就是在配置文件中列出LoadBalancer(负载均衡)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法!
配置Ribbon负载均衡
(这里我使用的测试项目为之前SpringCloud已经配置好Eureka)
配置Ribbon使用,我们第一步就是导入Ribbon的依赖,在我们的服务消费端的模块中导入(这里的版本我是以我的项目版本为参考),还有Eureka客户端的依赖(我们以注解方式开启客户端)。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
配置好Eureka之后我们就在服务消费模块的yml下配置我们的Eureka,将服务中心的地址都存下来。
server:
port: 80
#Eureka配置
eureka:
client:
register-with-eureka: false #不向Eureka注册自己
service-url:
defaultZone: http://eureka-7001:7001/eureka/,http://eureka-7002:7002/eureka/,http://eureka-7003:7003/eureka/
同时在我们的主启动类上面加上@EnableEurekaClient表示这个模式是Eureka的客户端。最后要开启我们的负载均衡是最简单的,只需要一个注解就搞定。在我们RestTemplate注册的bean上面加一个@LoadBlanced就行。
package com.lin.springcloud.config;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class ConfigBean {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
但是我们项目这个时候只有一个服务提供模块,8001端口
这样我们虽然配置好了负载均衡,但因为只有一个服务提供模块,不能够体现出来负载均衡。所以我们需要再新增两个模块,每个模块都有自己的数据库。很简单,就是复制模块,然后改一下application.yml文件里面的数据库的名字和端口就行,其他的我们都不用去动。(当然,数据库还是需要去创建的)
我们三个服务提供模块,数据库里面的数据都有一个db_source字段,用来显示自己的当前的数据库名字,这样我们在查询数据的时候可以很清楚的看到我们查到的数据在从哪个服务提供模块里面的数据库查到的。
我们顺序启动服务中心,然后启动服务提供模块,最后再启动服务消费模块。

三个服务中心模块,三个服务提供模块,一个服务消费模块
我们随便进到一个服务中心模块

这个时候我们去查询数据的话
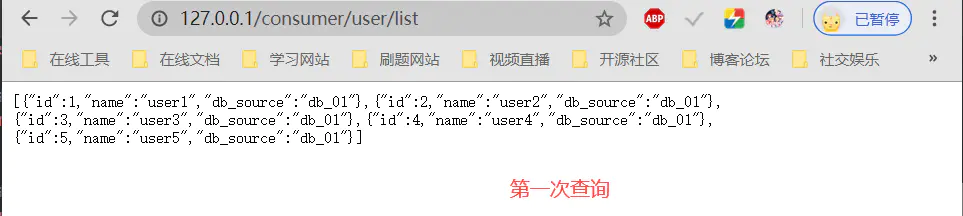
第一次查询:
第二次查询:

第三次查询:
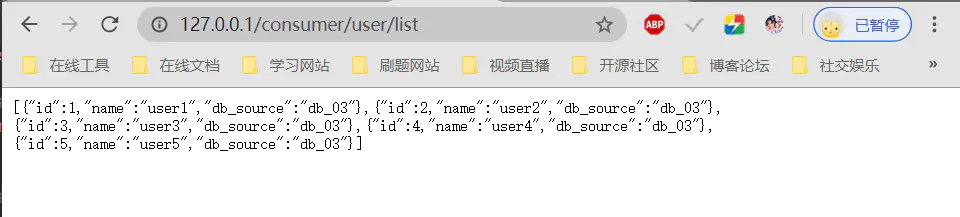
可以看到我们查询的结果先是db_01数据库(8001端口的服务提供者),然后是db_02数据库(8002端口的服务提供者),再然后是db_03数据库(8003端口的服务提供者),很好负载均衡到每一个服务提供模块上面,避免某一个模块的过载使用。同时我们可以发现它是按顺序去访问这三个模块,也就是轮询。这其实就是Ribbon默认的负载均衡的算法,轮询算法。
运用Ribbon和Eureka我们可以很好的实现负载均衡,那么我们的Ribbon是如何与Eureka整合的呢?
Ribbon与Eureka整合

-
服务提供者在Eureka注册中心集群注册服务
-
服务消费者查询可用的服务列表
-
Ribbon 会从 服务消费者 里获取到对应的服务列表。
-
Ribbon 使用负载均衡算法获得使用的服务。
-
Ribbon 调用对应的服务。
Ribbon负载均衡算法
其实Ribbon也给我们封装了很多负载均衡的策略
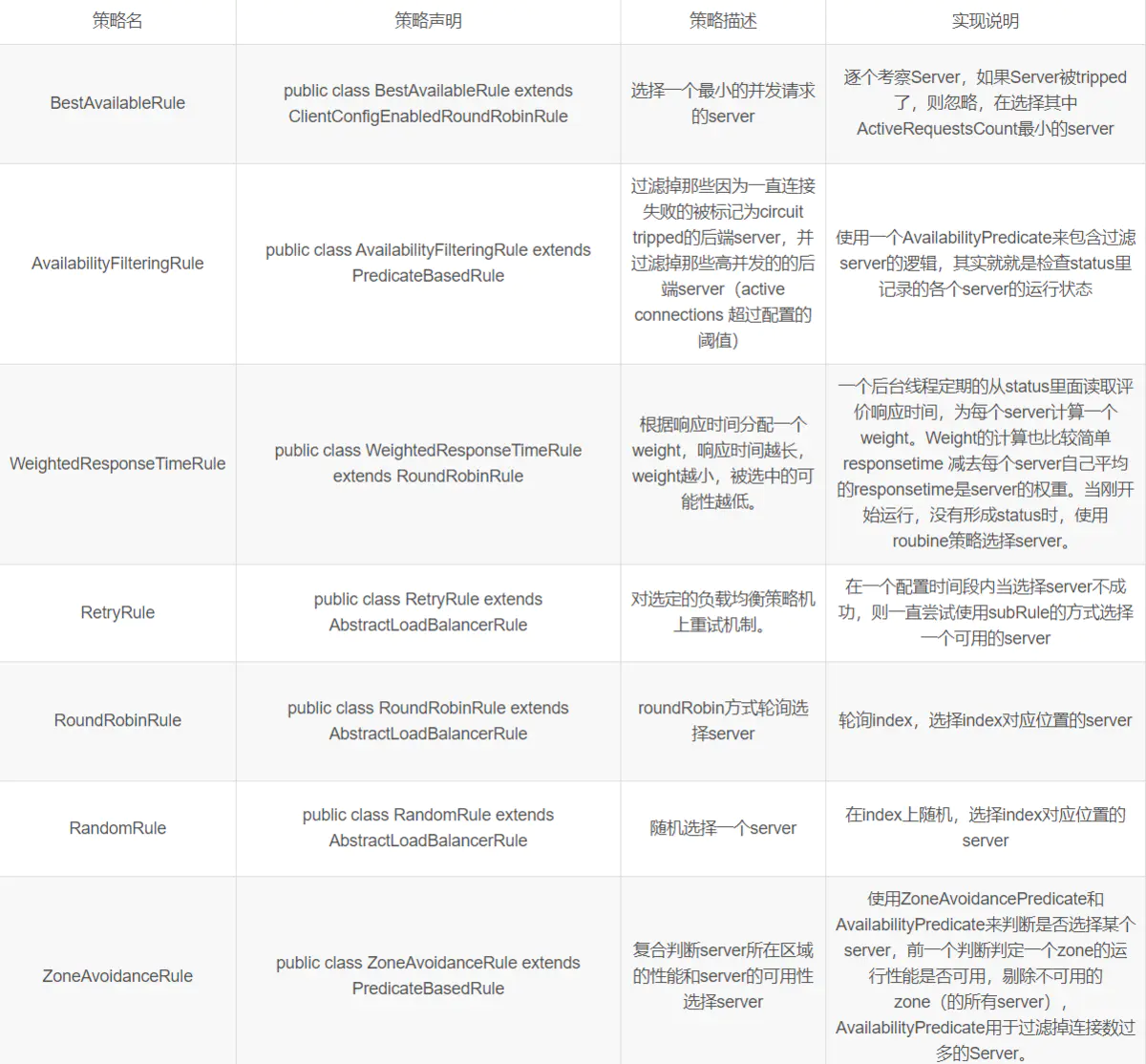
如果要使用这些算法的话,在我们使用@LoadBalanced注解下面注册一下
package com.lin.springcloud.config;
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class ConfigBean {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
//默认是轮询算法,这里我们改成随机算法
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
}
我们可以访问服务消费端的接口

可以看到我们的取出数据的数据库不再是按照轮询来的,而是使用我们选择的随机策略来的。
除了这些封装好的策略,我们也可以自定义策略算法,只需要继承AbstractLoadBalancerRule类,然后重写方法就行。最后在上面注册的位置返回我们自定义策略算法的类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号