MySQL主从复制与备份
MySQL的主从复制
MySQL的复制解决的基本问题就是让一台服务器的数据与其他服务器保持同步。如一台主库的数据可以同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。主库和备库之间可以有多种不同的组合方式。
复制的实现方式
MySQL支持两种复制方式:基于行的复制和基于语句的复制。这两种复制的复制原理都是通过在主库上记录二进制日志、在备库重放日志的方式来实现异步的数据复制。这也意味着在同一时间点备库上的数据可能和主库存在不一致,并且无法保证主备之间的延迟。
基于语句的复制
语句复制也称逻辑复制。主库会记录那些造成数据更改的查询,当备库读取并重放这些时间时,实际上只是把主库上执行过的SQL再执行一遍。
优点
- 实现相当简单。只需要简单地记录和执行这些语句就能让主备保持同步。
- 节约资源。因为是通过语句来执行复制,所以一条好几兆的更新数据在二进制日志里面可能就只占几十个字节。所以对于我们的二进制日志可以更加紧凑,节约空间。同时因为数据量的缩小,也不会使用太多带宽。
- 更容易定位问题。因为执行复制过程基本上就是执行SQL语句,在服务器上的变更都是以一种容易理解的方式运行。
缺点
- 可能存在一些无法被正确复制的SQL,或者查询语句里面包括了一些元数据信息,如当前的时间戳。
- 更新必须是串行的。这也意味需要更多的锁,我们的并发量就会大大减小。
基于行的复制
基于行的复制就是直接将每一行的数据记录在二进制日志中,可以正确地复制每一行以及一些语句可以更加有效地复制。
优点
- 可以处理很多基于语句复制无法处理的场景。比如对于SQL构造、触发器、存储过程等都可以正确执行。
- 可以减少锁的使用。基于行的复制不要求强制串行化是可重复的,所以可以提高并发量。
- 可以实时记录数据变更。因此在二进制日志中记录的都是实际上在主库上发生了变化的数据。
缺点
- 如果做全表更新,那么二进制的日志文件将会特别大。
- 因为是直接复制数据,所以在出现问题的时候,不像执行SQL那样可以快速定位问题的所在。
复制解决的问题
主从复制可以解决很多的问题, 所以用途也是比较广的。
(1)数据分布:将数据分布在不同服务器上,这样即使一些服务器出现故障也能很好的工作。
(2)负载均衡:可以通过复制然后将读操作分布到多个服务器上,实现对读密集型应用的优化。
(3)备份:用来保证数据的安全性,复制是备份的一项技术补充。
(4)高可用和故障切换:一个包含复制的设计良好的故障切换系统能够显著地缩短宕机时间。
(5)MySQL升级测试:这种做法比较普遍,使用一个更高版本的MySQL作为备库,保证在升级全部实例前,查询能够在备库按照预期执行。
主从复制的过程
复制的过程总的来说是有三个步骤,三个步骤主要涉及到了三个线程:binlog线程,I/O线程和SQL线程。
binlog线程:负责将主服务器上的数据更改写入二进制日志(Binary log)中。
I/O线程:负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
SQL线程:负责读取中继日志,解析出主服务器已经执行的数据更改并在才服务器中重放(Replay)。
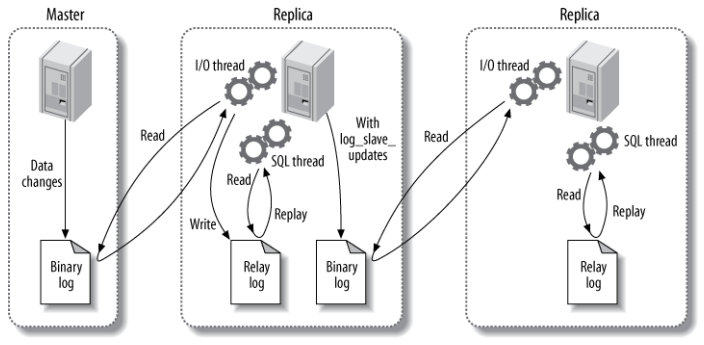
具体的详细过程如下:
第一步是在主库上记录二进制日志,每次准备提交事务完成数据更新前,主库将数据更新的事件记录到二进制日志中。MySQL 会按事务提交的顺序而非每条语句的执行顺序来记录二进制日志,在记录二进制日志后,主库会告诉存储引擎可以提交事务了。
下一步,备库将主库的二进制日志复制到其本地的中继日志中。备库首先会启动一个工作的 IO 线程,IO 线程跟主库建立一个普通的客户端连接,然后在主库上启动一个特殊的二进制转储线程,这个线程会读取主库上二进制日志中的事件。它不会对事件进行轮询。如果该线程追赶上了主库将进入睡眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒,备库 IO 线程会将接收到的事件记录到中继日志中。
备库的 SQL 线程执行最后一步,该线程从中继日志中读取事件并在备库执行,从而实现备库数据的更新。当 SQL 线程追赶上 IO 线程时,中继日志通常已经在系统缓存中,所以中继日志的开销很低。SQL 线程执行的时间也可以通过配置选项来决定是否写入其自己的二进制日志中。
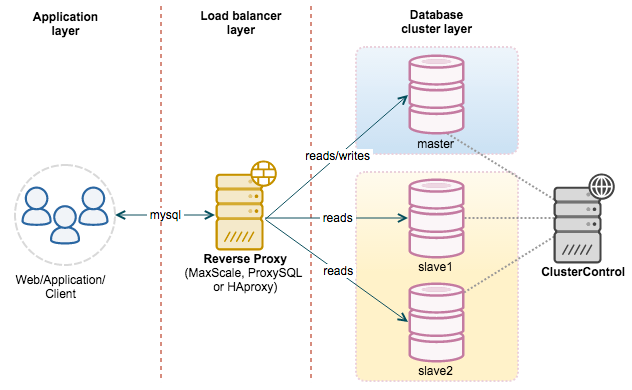
读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
- 增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
MySQL的数据备份
上面我们讲到了MySQL的数据复制,但是我们要知道,复制不等于备份。比如我们的生产库上执行了DROP DATABASE,复制就无法就恢复原来的数据。所以只有备份才能满足备份的要求。
备份理由
之所以需要备份也是为了应对类似以下情况的发生:
- 灾难恢复。用于硬件故障,一个不经意间的Bug,或者有人删库跑路等其他原因导致服务器及其数据由于某些原因不可获取或无法使用等。
- 审计。有时候需要知道数据或Shema在过去某个时间点是什么样的。(仅靠代码的版本控制是不够的。)
- 测试。一个最简单的基于实际数据来测试的方式是,定义用最新的生产环境数据更新测试服务器。如果使用备份的方案就非常简单:只要把备份文件还原到测试服务器上即可。
备份方式
逻辑备份
SQL级别的备份机制,其将数据表导成SQL脚本文件,然后相当于在另一台服务器上执行一遍备份的SQL语句。
-
操作语句: 使用
mysqldump语句来实现,具体语句为:mysqldump -h主机名 -P端口 -u用户名 -p密码 --database 数据库名 > 文件名.sql -
优点: 恢复简单、与存储引擎无关,消除了底层数据存储的不同,有助于避免数据损坏
-
缺点: 必须有数据库完成逻辑工作,需要更多地CPU周期,且逻辑备份还原慢
物理备份
是基于文件的物理备份,比较类似于拷贝数据库的文件,然后复制到另一台服务器加载。
- 优点: 容易跨平台、跨操作系统和MySQL版本,且恢复起来很快
- 缺点: 文件比较大,不总是可以跨平台、操作系统和MySQL版本
参考资料
《高性能MySQL》
《cyc2018》Github高星项目

 浙公网安备 33010602011771号
浙公网安备 33010602011771号