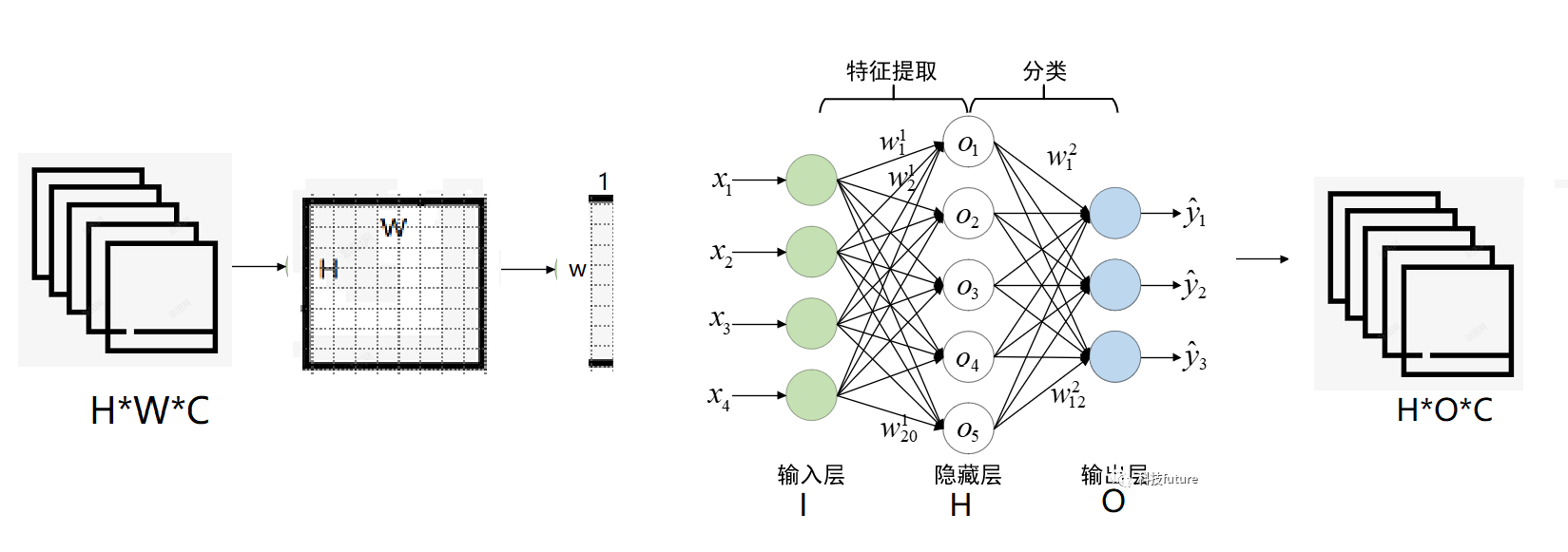
多层感知机
多层感知机的结构
import torch import torch.nn as nn import torchvision.transforms as transformers


# 多层感知机 class Mlp(nn.Module): ''' in_features: 输入特征层的神经元数量,每个神经元代表一个特征,也就是输入特征的维度 hidden_features: 隐藏层神经元的个数,即隐藏层特征的维度 out_features: 输出层的特征维度 act_layer=nn.GELU:激活函数层类型,使用GELU激活函数,也可以是sigmoid drop=0 : 概率随机关闭神经元,0%代表不关闭任何神经元此时是全连接 ''' def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): # 新式类继承父级初始化的写法 super().__init__() # 特征逻辑或计算 out_features = out_features or in_features hidden_features = hidden_features or in_features # 输入层到隐藏层之间的全连接 self.fc1 = nn.Linear(in_features, hidden_features) # 激活层 self.act = act_layer() # 隐藏层和输出层的全连接 self.fc2 = nn.Linear(hidden_features, out_features) # 随机概率丢弃层 self.drop = nn.Dropout(drop) # 前向传播 def forward(self, x): # 输入层到隐藏层之间的连接 x = self.fc1(x) # 激活函数 x = self.act(x) # 神经元根据随机丢弃率丢弃 x = self.drop(x) # 隐藏层到输出层之间的连接 x = self.fc2(x) # 神经元根据随机丢弃率丢弃 x = self.drop(x) # 返回最后输出张量x return x
为了验证上述图的真实性,我们对上面的多层感知机实例化,打开一张图片为32*32*4,然后进行图片调整以及转化为张量输入到输入层中,分别输出图像张量的形状,输出形状以及最后输出张量在第2维度也就是每行元素张量的最大值。
from PIL import Image # 多层感知机的实例化 mlp = Mlp(in_features=32, hidden_features=None, out_features=8, act_layer=nn.GELU, drop=0.) # 打开图片 img = Image.open("beauty.png") # 预转化为张量 transformer = transformers.Compose([ # 图像调整,只有参数宽度和高度 transformers.Resize((32,32)), #(高度,宽度) # 转换为张量 transformers.ToTensor() ]) # 转化图像 img_tensor = transformer(img) #torch.Size([4, 32, 32]) print("输入图像的形状:",img_tensor.shape) # 将图像张量输入到MLP pre = mlp(img_tensor) # 输出层输出的形状 print("输出形状:",pre.shape)# torch.Size([4, 32, 8]) # 获取输出层张量pre在第2维度上(行)的最大索引值 predict = torch.argmax(pre,dim=2) # 输出最大索引值 print("每行最大值:",predict) print("每行最大值输出形状:",predict.shape) # torch.Size([4, 32])
输出结果:
输入图像的形状: torch.Size([4, 32, 32]) 输出形状: torch.Size([4, 32, 8]) 每行最大值: tensor([[0, 0, 0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 0, 0, 7, 7, 7, 7, 0, 7, 7, 0, 7, 7, 7, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 7, 7, 7, 0, 7, 7, 7, 7, 7, 7, 7, 7, 0, 0, 0, 7, 7, 7, 7, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 0, 0, 0, 7, 7, 7, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 3, 3, 3, 7, 0, 0, 0, 0]]) 每行最大值输出形状: torch.Size([4, 32])
M54

 浙公网安备 33010602011771号
浙公网安备 33010602011771号