西电分布式计算实验报告
分布式计算实验报告
一、实验要求及目的
目的:学习基于MapReduce框架的分布式计算程序设计方法。
要求:
二 实验题目 题目1
输入文件为学生成绩信息,包含了必修课与选修课成绩,格式如下:
班级1, 姓名1, 科目1, 必修, 成绩1 <br> (注:<br> 为换行符)
班级2, 姓名2, 科目1, 必修, 成绩2 <br>
班级1, 姓名1, 科目2, 选修,成绩3 <br>
………., ………, ………, ……… <br>
编写两个Hadoop平台上的MapReduce程序,分别实现如下功能:
-
计算每个学生必修课的平均成绩。
-
按科目统计每个班的平均成绩。
题目2
输入文件的每一行为具有父子/父女/母子/母女/关系的一对人名,例如:
Tim, Andy <br>
Harry, Alice <br>
Mark, Louis <br>
Andy, Joseph <br>
……….., ………… <br>
假定不会出现重名现象。
编写Hadoop平台上的MapReduce程序,找出所有具有grandchild-grandparent关系的人名组。
二、实验介绍
1. hadoop
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决海量数据的存储和海量数据的分析计算问题。
2. MapReduce
- MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析应用”的核心框架。
- MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的分布式运算程序 ,并发运行在一个 Hadoop集群上。
三、环境搭建
1. 配置虚拟机ip

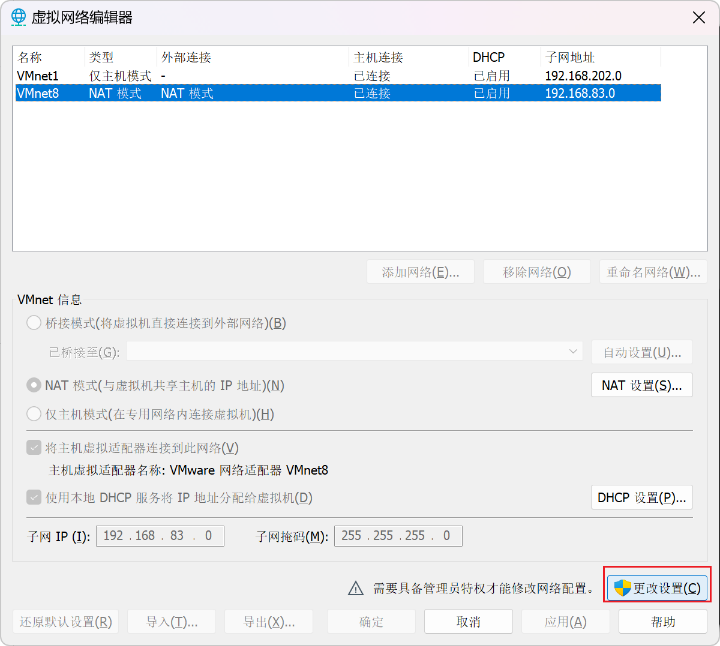
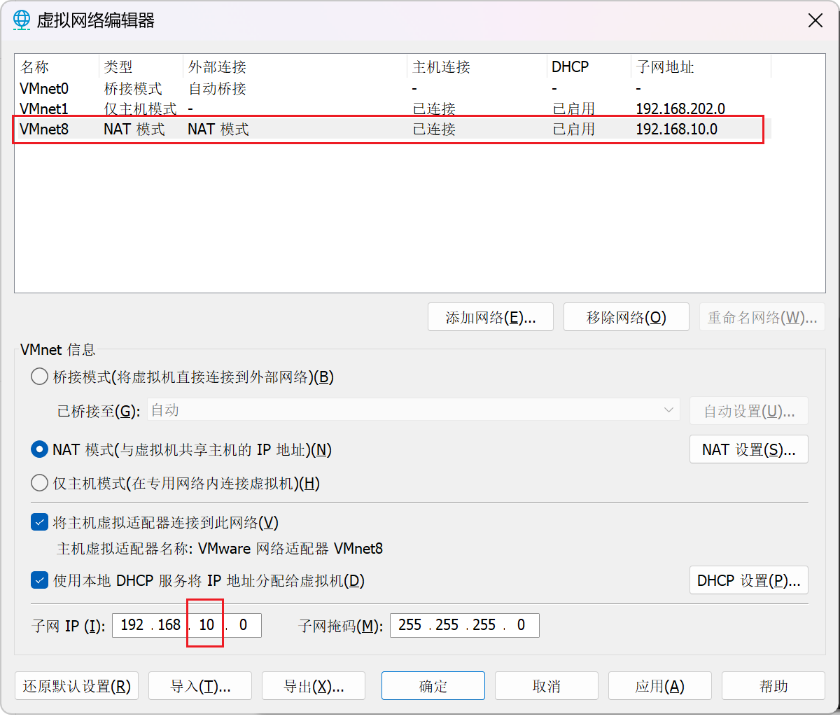
2. 配置linux虚拟机ip
此处仅仅配置一台服务器,之后进行虚拟机复制从而得到多个节点
(1) 设置静态ip
- 进入管理员模式
- 修改ip为静态
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
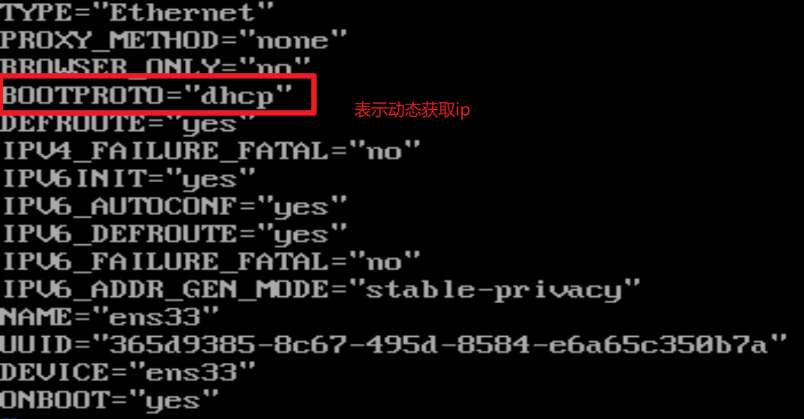
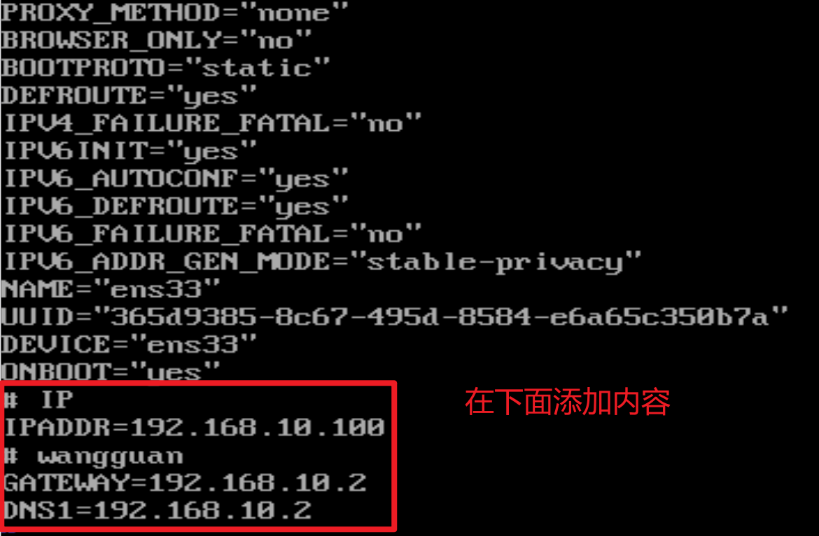
- 将dhcp改为static,如下
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.102
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
(2) 设置ip地址
(3) 修改主机名称
[root@hadoop100 vim /etc/hostnamehadoop102
将文件的内容改成主机名即可,例如改成
hadoop100
(4) 配置主机名称和ip映射
该过程是为了防止ip之后变化带来的改变的麻烦,因此将主机名和ip进行关联,之后使用主机名即可
[root@hadoop100 ~]# vim /etc/hosts
追加如下内容
192.168. 10 .100 hadoop100
192.168. 10 .101 hadoop101
192.168. 10 .102 hadoop102
192.168. 10 .103 hadoop103
192.168. 10 .104 hadoop104
192.168. 10 .105 hadoop105
192.168. 10 .106 hadoop106
192.168. 10 .107 hadoop107
192.168. 10 .108 hadoop108
(5) 重启
[root@hadoop100 ~]# reboot
检查
重启之后输入如下命令
- 查看ip
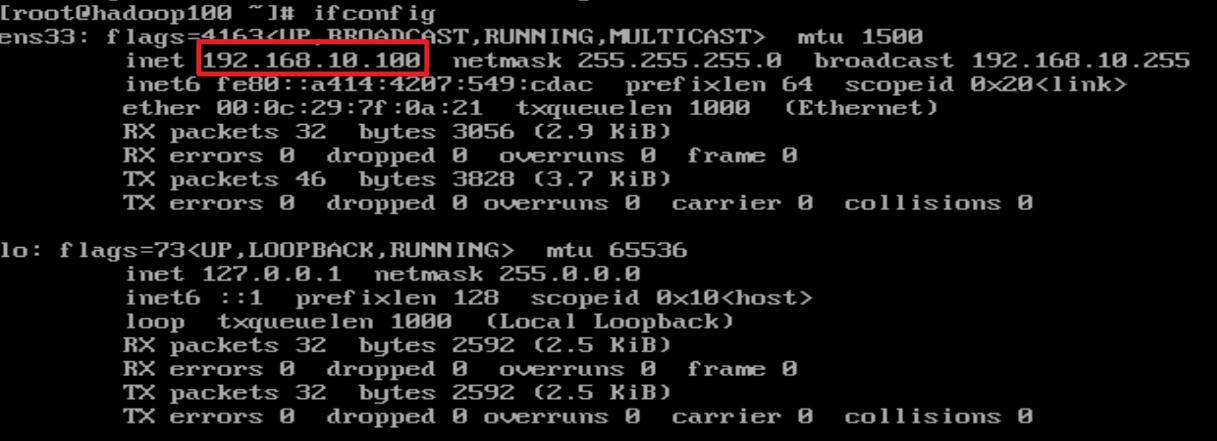
- ping外网,测试连接

- 查看hostname

3. 环境配置
(1) 安装epel-relase
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
[root@hadoop100 ~]# yum install -y epel-release
(2) 关闭防火墙
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service
(3) 创建用户
[root@hadoop100 ~]# useradd crispycandy
[root@hadoop100 ~]# passwd crispycandy
然后赋予用户权限
[root@hadoop100 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
crispycandy ALL=(ALL) NOPASSWD:ALL
注意:最后这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了atguigu具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以atguigu要放到%wheel这行下面。
(4) 创建文件夹
- 在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
- 修改module、software文件夹的所有者和所属组均为{username}用户
[root@hadoop100 ~]# chown crispycandy:crispycandy /opt/module
[root@hadoop100 ~]# chown crispycandy:crispycandy /opt/software
- 查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 crispycandy crispycandy 4096 5月 28 17:18 module
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 crispycandy crispycandy 4096 5月 28 17:18 software
4. 克隆虚拟机集群
- 前提:我们已经为hadoop100配置了ip和基本环境
- 现在通过复制来得到多个节点
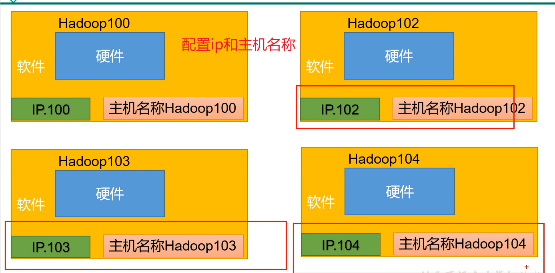
- 首先根据Hadoop克隆多个虚拟机

- 然后修改每个的ip地址和主机名(上面有步骤)
- 然后使用ifconfig和hostname查看是否修改成功
- ssh为每个都建立连接

5. 安装jdk并配置环境变量
- 将软件和压缩包放到指定的文件文件夹

- 从java官网里面下载linux的jdk
- 然后上传到software里面

- 然后解压到module中
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /opt/module/

- 本来应该在profile里面配置的,但是还有别的方法
- 先打开看看
sudo vim /etc/profile
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
- 可以看到,其会遍历所有的.sh文件,然后运行
- 因此只要创建一个.sh文件添加全局变量即可
[root@hadoop102 etc]# cd profile.d/
[root@hadoop102 profile.d]# vim my_env.sh # 没有文件就直接创建了
写如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_361
export PATH=$PATH:JAVA_HOME/bin
export是全局的意思
- 然后重新启动profile文件
source /etc/profile
6. 安装并配置hadoop
- 上传Hadoop的压缩包到software上面
[root@hadoop102 opt]# cd software/
[root@hadoop102 software]# ll
total 465668
-rw-r--r--. 1 root root 338075860 Jun 16 16:39 hadoop-3.1.3.tar.gz # 可以看到有文件
-rw-r--r--. 1 root root 138762230 Jun 16 16:24 jdk-8u361-linux-x64.tar.gz
- 然后解压
[root@hadoop102 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
即可
[root@hadoop102 software]# cd ../module/
[root@hadoop102 module]# ll
total 4
drwxr-xr-x. 9 root root 149 Sep 12 2019 hadoop-3.1.3
drwxr-xr-x. 8 root root 4096 Jun 16 16:25 jdk1.8.0_361
配置全局变量
sudo vim /etc/profile.d/my_env.sh
- 追加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
然后重新启动profile文件
source /etc/profile
- 测试
hadoop
输入指令,会打印相关内容
- Hadoop是hadoop/bin里面的命令
7. 同步环境及配置信息
上面已经为hadoop102配置了jdk和hadoop了,接下来使用下面的脚本来进行同步
该脚本能够同步hadoop102、hadoop103和hadoop104的所有目录
#!/bin/bash
#1. 判断参数个数,如果<1,则打印Not Enough Arguement!
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
# 先打印这个内容
echo ==================== $host ====================
#3. 遍历所有目录($@是全部参数的意思),挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录 cd -P $(dirname $file); pwd就是根据$file获取文件
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
# ssh $host是连接远程的服务器,也就是进入到远程的服务器了
# mkdir -p $pdir是创建一个相同的目录,-p是如果没有就创建,如果有就不创建了
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
然后运行
[crispycandy@hadoop102 ~]$ sudo xsync /etc/profile.d/my_env.sh
最终在hadoop103和hadoop104重新运行profile文件
[crispycandy@hadoop103 bin]$ source /etc/profile
[crispycandy@hadoop104 opt]$ source /etc/profile
最终配置结果
通过如上的操作,我们已经有了如下的节点
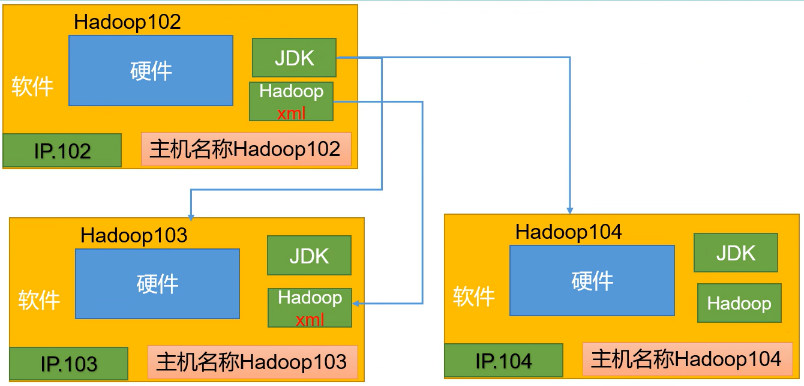
- hadoop102、hadoop104和hadoop103已经全部有了jdk和hadoop环境了
四、搭建hadoop完全分布式模式
1. 集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
2. 设置配置文件
先配置hadoop102的文件,然后同步到hadoop103和hadoop104
- 核心配置文件
配置core-site.xml
[crispycandy@hadoop102 hadoop]$ vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
</configuration>
如果要设置HDFS网页登录时使用的静态用户为crispycandy的话,还要添加一项
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>
- HDFS配置文件
配置hdfs-site.xml
[crispycandy@hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
- YARN配置文件
配置yarn-site.xml
[crispycandy@hadoop102 hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- MapReduce文件
配置mapred-site.xml文件
[crispycandy@hadoop102 hadoop]$ vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3. 集群分发文件
此时已经在hadoop102上面配置好了4个自定义文件,然后需要分发到hadoop103和hadoop104
[crispycandy@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
4. 配置工作节点
配置 /opt/module/hadoop-3.1.3/etc/hadoop/workers 文件
hadoop102
hadoop103
hadoop104
注意
- 每行后面不能有空格
- 不能再下面有空行
然后同步
[crispycandy@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
5. 启动集群
(1) 格式化NameNode
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[crispycandy@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
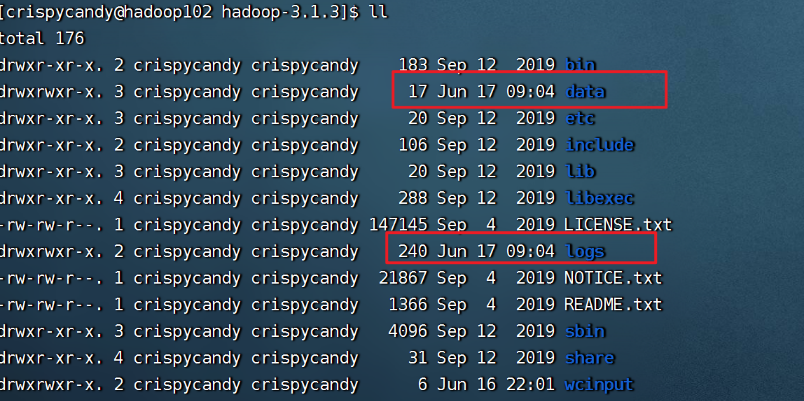
- 初始化之后有了data和logs目录
(2) 启动HDFS
- 启动的命令在sbin目录下的start-dfs.sh
[crispycandy@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[crispycandy@hadoop103 .ssh]$ jps
90675 Jps
86622 DataNode
可以看到hadoop103下面有一个DataNode启动
[crispycandy@hadoop104 .ssh]$ jps
86784 SecondaryNameNode
86514 DataNode
91414 Jps
好像hadoop2作为NameNode启动后很多环境变量就无法使用了,比如jps,java等
(3) 启动YARN
在配置了ResourceManager的节点(hadoop103)启动YARN
[crispycandy@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
[crispycandy@hadoop103 hadoop-3.1.3]$ jps
92945 ResourceManager
93673 Jps
93117 NodeManager
86622 DataNode
可以看到
2. 查看监控页面
(1) 查看HDFS的NameNode
- 浏览器中输入:http://hadoop102:9870
- 查看HDFS上存储的数据信息
五、代码编写
1. 实验一
(1) 题目要求
输入文件为学生成绩信息,包含了必修课与选修课成绩,格式如下:
班级1, 姓名1, 科目1, 必修, 成绩1 <br> (注:<br> 为换行符)
班级2, 姓名2, 科目1, 必修, 成绩2 <br>
班级1, 姓名1, 科目2, 选修,成绩3 <br>
………., ………, ………, ……… <br>
编写两个Hadoop平台上的MapReduce程序,分别实现如下功能:
- 计算每个学生必修课的平均成绩。
- 按科目统计每个班的平均成绩。
(2) 分析
- 统计每个必修课的平均成绩
| 阶段 | 任务 |
|---|---|
| Map阶段 | 解析每行的数据,如果类型为必修,则返回<姓名,成绩>格式的map |
| reduce阶段 | 对于每个map,其value是成绩的列表,统计其平均值即可,最终返回<姓名,平均成绩> |
- 按科目统计每个班的平均成绩
| 阶段 | 任务 |
|---|---|
| Map阶段 | 解析每行的数据,如果类型为必修,则返回<科目,班级-成绩>格式的map |
| reduce阶段 | 对于每个map,key是科目,value是班级-成绩,然后先按照班级将成绩聚集起来再统计平均值,最终范湖<科目,班级-平均成绩> |
(3) 代码
① 要求1
- 第一个要求
/**
* LongWritable:每行开头的序列号
* Text:每行的内容,包含班级,姓名,课程,选修还是必修,成绩
* Text:输出的key,学生的名字
* IntWritable:输出的value,成绩
* 如果是非必修,那么就不输出
*/
public class StuAvgGradeMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outKey = new Text();
private IntWritable outValue = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 获取每行的数据
String line = value.toString();
// 2. 分割
String[] words = line.split(",");
// 3. 先判断是必修还是选秀,选秀的话直接退出
if("选修".equals(words[3]))
return;
// 4. 如果是必修,则输出
outKey.set(words[1]);
outValue.set(Integer.parseInt(words[4]));
context.write(outKey, outValue);
}
}
/**
* Text: 学生的姓名
* IntWritable:学生的成绩
* Text:学生的姓名
* DoubleWritable:学生的平均分
*/
public class StuAvgGradeReduce extends Reducer<Text, IntWritable, Text, DoubleWritable> {
private DoubleWritable outValue = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1. 获取每个学生的成绩,遍历求和sum,再/科目
double sum = 0;
int num = 0;
for (IntWritable value : values) {
sum += value.get();
num++;
}
double avg = sum / num;
outValue.set(Util.formatDouble(avg, 2));
context.write(key, outValue);
}
}
public class StuAvgGradeDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. 获取job
Configuration configuration = new Configuration();
Job job = new Job(configuration);
//2. 设置jar包路径
// 传入类,通过映射来获取jar包
job.setJarByClass(StuAvgGradeDriver.class);
//3. 关联mapper和reducer
job.setMapperClass(StuAvgGradeMapper.class);
job.setReducerClass(StuAvgGradeReduce.class);
//4. 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5. 设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//6. 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
② 要求2
/**
* LongWritable:每行开头的序列号
* Text:每行的内容
* Text:科目
* Text: 班级 成绩
*/
public class SubjAvgGradeMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text outKey = new Text();
/*private Text classIdKey = new Text("classId");
private Text classIdText = new Text();
private Text gradeKey = new Text("grade");
private IntWritable gradeIntWritable = new IntWritable();*/
// private MapWritable outValue = new MapWritable();
private Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 获取每一行的数据
String line = value.toString();
// 2. 截取每一行的分割
String[] items = line.split(",");
// 3. 获取科目作为key,然后<班级,成绩作为value>
String subject = items[2];
String classId = items[0];
String grade = items[4];
outKey.set(subject);
outValue.set(classId + " " + grade);
context.write(outKey, outValue);
}
}
/**
* Text:科目
* Text:班级 成绩
* Text: 科目
* Text:班级 平均成绩
*/
public class SubjAvgGradeReducer extends Reducer<Text, Text, Text, Text> {
private Text outValue = new Text();
/**
* @param key 科目
* @param values 每个科目对应的所有的班级及成绩
*/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 2. 将每一个map都转换成ClassGradeDto, 得到一个List
List<ClassGradeDto> classGradeDtos = transMapToDto(values);
// 3. 然后list按照grade进行划分
Map<String, List<ClassGradeDto>> gradeGroupByClass = classGradeDtos.stream().collect(Collectors.groupingBy(ClassGradeDto::getClassId));
// 4. 然后统计平均值,并输出
for (Map.Entry<String, List<ClassGradeDto>> entry : gradeGroupByClass.entrySet()) {
String classId = entry.getKey();
double sum = 0;
for (ClassGradeDto dto : entry.getValue()) {
sum += dto.getGrade();
}
double avg = Util.formatDouble(sum / entry.getValue().size(), 2);
outValue.set(classId + " " + avg);
context.write(key, outValue);
}
}
private List<ClassGradeDto> transMapToDto(Iterable<Text> values) {
List<ClassGradeDto> res = new ArrayList<>();
for (Text value : values) {
String[] item = value.toString().split(" ");
String classId = item[0];
int grade = Integer.parseInt(item[1]);
res.add(new ClassGradeDto(classId, grade));
}
return res;
}
}
class ClassGradeDto {
private String classId;
private Integer grade;
}
public class SubjAvgGradeDriver{
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. 获取job
Configuration configuration = new Configuration();
Job job = new Job(configuration);
//2. 设置jar包路径
// 传入类,通过映射来获取jar包
job.setJarByClass(SubjAvgGradeDriver.class);
//3. 关联mapper和reducer
job.setMapperClass(SubjAvgGradeMapper.class);
job.setReducerClass(SubjAvgGradeReducer.class);
//4. 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//5. 设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6. 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
2. 实验二
(1) 题目要求
题目2
输入文件的每一行为具有父子/父女/母子/母女/关系的一对人名,例如:
Tim, Andy <br>
Harry, Alice <br>
Mark, Louis <br>
Andy, Joseph <br>
……….., ………… <br>
假定不会出现重名现象。
编写Hadoop平台上的MapReduce程序,找出所有具有grandchild-grandparent关系的人名组。
(2) 分析
| 阶段 | 任务 |
|---|---|
| Map阶段 | 解析每行的数据,如果类型为必修,则返回<名字0,名字1-标识符>格式的map 如果标志位是0,表示名字0是名字1的父母,如果标志位是1,表示0是1的子女 |
| reduce阶段 | 对于每个map,key是中间者的名称,然后根据01来进行判断子女关系 |
(3) 代码
/**
* LongWritable: 每行的序列号
* Text:每行的内容
* Text:名字0,为中间者的名字
* Text: 名字1-标志位 如果标志位是0,表示名字0是名字1的父母,如果标志位是1,表示0是1的子女
*/
public class GrandRelationMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 获取一行的数据
String line = value.toString();
// 2. 提取出两个名字
String[] names = line.split(",");
// 3. 分别正序和倒序写出去
outKey.set(names[0]);
// 0表示name[0]是name[1]的父母
outValue.set(names[1] + " 0");
context.write(outKey, outValue);
outKey.set(names[1]);
outValue.set(names[0] + " 1");
context.write(outKey, outValue);
}
}
/**
* Text:名字0,为中间者的名字
* Text: 名字1-标志位 如果标志位是0,表示名字0是名字1的父母,如果标志位是1,表示0是1的子女
* Text: grandchild
* Text: grandparent
*/
public class GrandRelationReducer extends Reducer<Text, Text, Text, Text> {
private Text grandChildText = new Text();
private Text grandParentText = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 1. 获取values,如果是0则是祖辈的名称,否则是父辈的名称
List<String> grandChildList = new ArrayList<>();
List<String> grandParentList = new ArrayList<>();
for (Text value : values) {
String[] item = value.toString().split(" ");
// item[1]为标志符,如果item[1]为0,那么item[0]是grandchild。否则是grandparent
if ("0".equals(item[1])) {
grandChildList.add(item[0]);
} else {
grandParentList.add(item[0]);
}
}
// 遍历两级输出
for (String grandChild : grandChildList) {
for (String grandParent : grandParentList) {
grandChildText.set(grandChild);
grandParentText.set(grandParent);
context.write(grandChildText, grandParentText);
}
}
}
}
public class GrandRelationDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. 获取job
Configuration configuration = new Configuration();
Job job = new Job(configuration);
//2. 设置jar包路径
// 传入类,通过映射来获取jar包
job.setJarByClass(GrandRelationDriver.class);
//3. 关联mapper和reducer
job.setMapperClass(GrandRelationMapper.class);
job.setReducerClass(GrandRelationReducer.class);
//4. 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//5. 设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6. 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
六、实验结果
1. 上传文件到HDFS
将已有的grand.txt和child-parent上传到hdfs目录中
- 先创建目录
[crispycandy@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input
[crispycandy@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input/grade
[crispycandy@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input/relation
[crispycandy@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /output
- 上传文件
[crispycandy@hadoop102 hadoop-3.1.3]hadoop fs -put child-parent.txt /input/relation
[crispycandy@hadoop102 hadoop-3.1.3]hadoop fs -put grades.txt /input/grade
2. 运行
[crispycandy@hadoop102 hadoop-3.1.3]hadoop jar avgGrade.jar com.hadoop.mapreduce.AvgGrade.StuAvgGradeDriver /input/grade /output/stuAvgGrade
[crispycandy@hadoop102 hadoop-3.1.3]hadoop jar avgGrade.jar com.hadoop.mapreduce.subjectAvgGrade.SubjAvgGradeDriver /input/grade /output/classAvgGrade
[crispycandy@hadoop102 hadoop-3.1.3]hadoop jar avgGrade.jar com.hadoop.mapreduce.grandRelation.GrandRelationDriver /input/relation /output/relation
3. 结果
丁一 75.57
丁一石 71.29
丁丰 77.43
丁丰欣 71.86
丁丽 80.86
丁丽焕 82.14
丁义 77.14
丁伟子 67.0
丁伦 75.57
...
线性代数 170315班 74.27
线性代数 170314班 74.46
线性代数 170313班 75.07
线性代数 170301班 74.19
线性代数 170312班 74.74
线性代数 170311班 74.8
计算机图形学 160313班 72.65
计算机图形学 160314班 74.27
计算机图形学 160315班 74.29
计算机图形学 160311班 73.84
...
Wendy Gino
Tasha Gino
Peggy Katrina
Randy Katrina
Olina Katrina
Jean Katrina
Charlotte Katrina
Christina Katrina
...
七、总结
通过本次实验,我很好的掌握了MapReduce的用法,也理解了其作为数据处理的优势

 浙公网安备 33010602011771号
浙公网安备 33010602011771号