分布式系统第四讲 物理时钟和逻辑时钟
第四讲 物理时钟和逻辑时钟
分布式算法设计困难的原因之一是不同节点时钟不同步
主要内容
- 物理时钟
- Lamport 逻辑时钟(标量时钟)
- 向量时钟
- 逻辑时钟的应用
时钟介绍
(1) 时钟的用途
- 任务调度;
- 超时机制(检测节点错误、链路错误)
- 性能测量
- 日志中的时间戳(分布式日志的处理)
- 基于时间的数据有效性检验(如缓存数据的处理)
- 令牌 租约机制(互斥访问)
- 分布式系统中基于时间的事件排序
- 任务调度:linux里面有一个软件,可以每天定时启动一个程序
- 超时机制:问什么在算法中不能完全依赖超时时间,因为本地计算机的时钟可能不完全准确
- 日志中的时间戳:分布式系统中,不能通过时间戳来判断先后关系的,因为多个节点的时钟可能不同步
- 基于时间的数据有效性检验:比如每隔一段时间对缓存进行淘汰
- 令牌/租约机制是用来对公用变量的使用加锁的,但是也依赖于时钟
(2) 分布式系统中需要时钟的例子
多副本数据库是常用的:
- 提高安全性:在多处备份,防止一处出现问题导致数据丢失
- 提高效率:西安的用户访问西安的数据库,北京的用户访问北京的数据库
- 问题是如何保持多个副本的状态一致
- 同一个逻辑数据库在异地保存了两个副本
- 客户端可用向任意的副本数据库服务器发送读写请求
- 需要依赖时钟对不同客户端的写入操作进行排序

- 如图,一个写x = x +10, 一个写 x = x * 1.1
- 但是数据库的同步怎么进行
因为传输延迟的抖动
- 两个节点接受到的操作先后顺序不一样,导致结果不一样
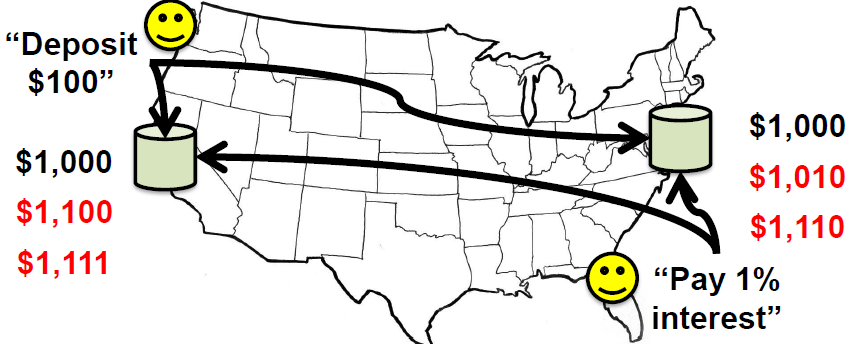
- 解决方法就是对操作打时间戳,当收到多个操作之后根据时间戳进行排序
- 问题是每个节点取本地的时间戳,但是不同节点的时钟可能不一样
分布式论坛
- 需要依赖时钟对不同用户的发帖和评论进行排序
- 就是P2P的论坛
4.1 物理时钟
4.1.1 说明
- 每个计算机都带有基于晶振的计时器(频率发生器),根据该计时器生成的时钟称为物理时钟。部分计算机还带有电池,使得在关机期间计时器仍然在工作。
- 更精确的物理时钟源:铯原子钟; GPS 时钟
- 物理时钟分类:
- 单调钟:
- 按照一定频率持续自增;
- 其绝对值无意义,相对值表示延时或时间差;
- Java System.nanoTime
- 墙钟 wall clock time
- 和日常生活中的日历、天文事件对应的时钟;
- 世界墙钟标准:协调世界时(Coordinated Universal Time
- 可能会发生倒流现象( NTP 时钟校正、闰秒)
- System.currentTimeMillis () 1970 1 1 午夜 0 点以来的秒数
- 单调钟:
单调钟
- 操作系统一直加的变量
- 计量软件的运行时间就可以这要能够与
4.1.2 物理时钟的同步问题
- 每个节点有自己独立的物理时钟
- 由于硬件问题,不同节点的物理时钟精度不一样
- 节点的物理时钟还容易受到温度、使用年限、震动、辐射等环境因素影响。
- 即便开始做了时钟同步,随着时间的推移,不同节点物理时钟之间的差异逐渐增大,最后超出了误差范围。(失同步)
- 与 NTP 服务进行时间同步时带来的误差(几十到一百毫秒)
- 参考数据:
- 每 30 秒与 NTP 服务器重新同步一次的时钟漂移为 6 毫秒
- 每天与 NTP 服务器重新同步一次的时钟漂移为 17 秒
但也不是物理时钟都不能用,比如进行大数据排序的时候,分给每个节点进行排序,排完序之后进行归并排序,对时钟精确度要求不高
4.1.3 实现物理时钟同步的方法
方法一 :每个节点都定期地与世界标准时间 (UTC:Coordinated Universal Time ) 同步
-
世界上建了 40 多个地面短波站,每一秒都向全世界广播一次 UTC 时间
-
GPS 接收器也可以接收到 UTC 时间
-
缺点:
-
成本高
-
大部分计算机都放在室内,接收不到 UTC
一般服务器都放在室内,防止打雷,静电或者黑客
-
方法二 :每个节点定期地通过网络与 时间服务器 同步
- 时间服务器配备了 GPS 接收器。
- 需要考虑传输延时
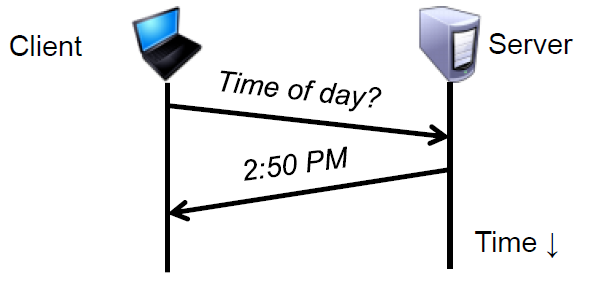
4.1.4 时间同步协议(NTP)
Cristian时间同步算法
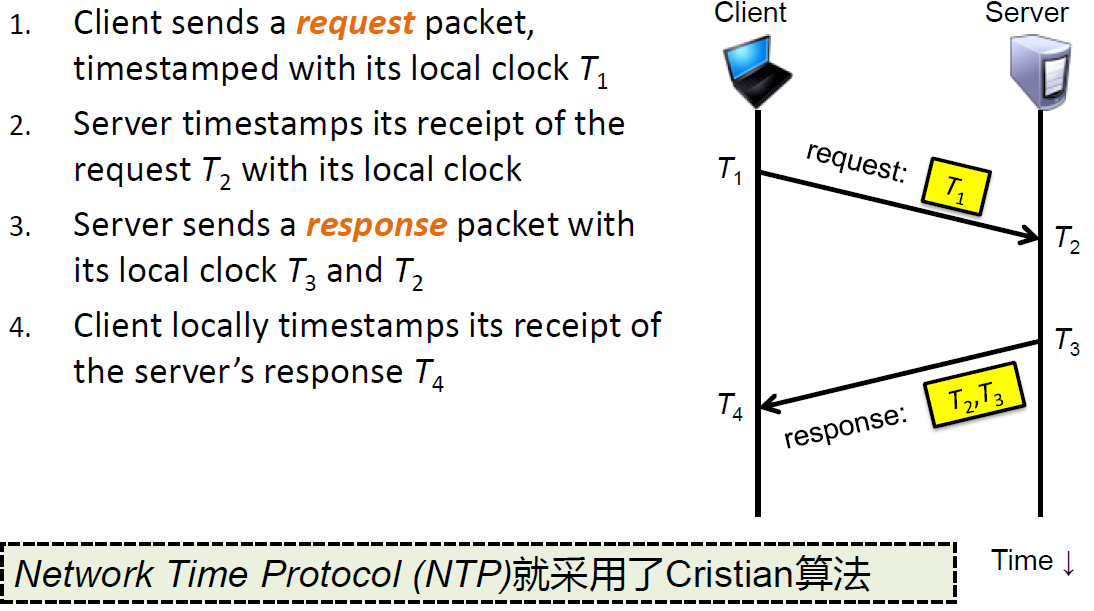
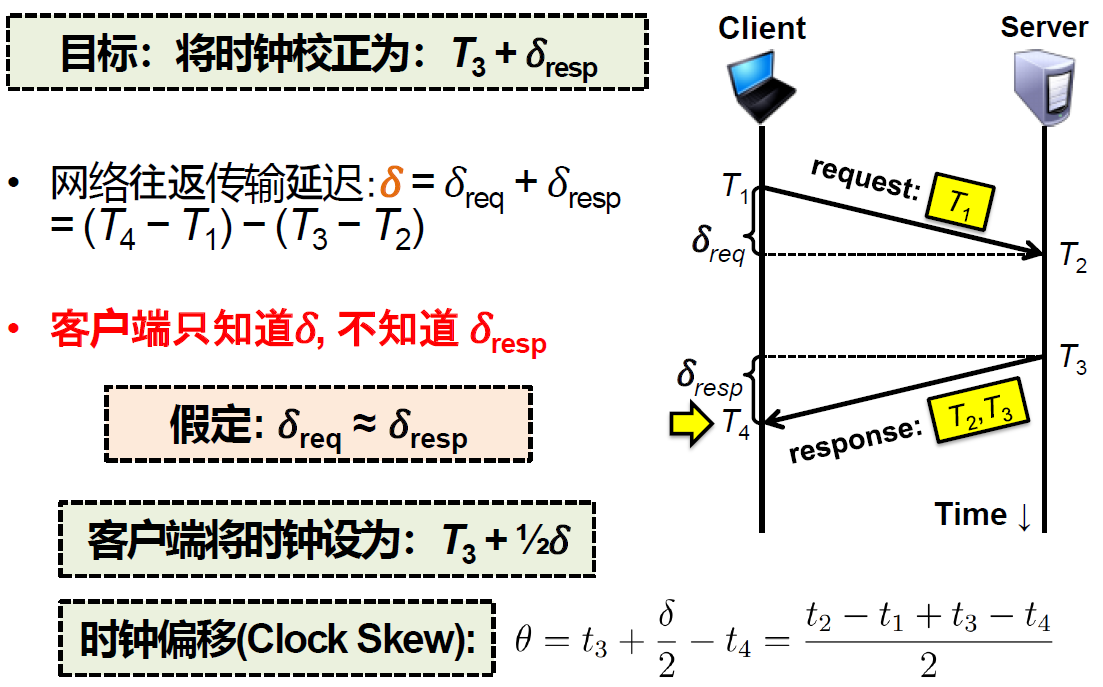
实际上,NTP协议计算的是时钟偏移sitar
4.1.5 测量延时的正确方法
首先展示错误的
使用墙钟是错误的,因为在两次获取时间的中期那可能进行时钟同步,发现原来的时钟快了
long startTime = System.currentTimeMillis();
// NTP client steps the clock during this
doSomething();
long endTime = System.currentTime();
long elapsedMillis = endTime - satrtTime;
// elapsedMillis may be negative!
计算延时一般使用单调钟
long startTime = System.nanoTime();
doSomething();
long endTime = System.nanoTime();
long elapsedMillis = endTime - satrtTime;
// elapsedMillis is always >= 0
4.1.6 如何处理时钟偏移
历史上的很多程序都是使用的currentTimeMillis()
为了避免这些程序出问题,有以下的处理方法

- 总的来说,就是如果偏移很小的话,不会直接设置,而是放慢或者加快频率,从而避免直接设置值造成的问题
4.1.8 常用的时钟同步协议
不一定所有系统都需要与世界时钟同步的,也就是不一定都需要使用NTP,只要保证系统内部的时间一致即可
- NTP Network Time Protocol ):广泛应用于 Internet精度在百毫秒级别;
- PTP Precision Time Protocol PTP 协议是一种精确时间协议,主要用于 局域网内 的时钟同步,提供了比 NTP 协议更高的时钟同步精度和更低的延迟,因此它被广泛应用于需要高精度时钟同步的工业自动化、电力系统和科学研究等领域;
- GPS Global Positioning System GPS 是一种全球定位系统,通过卫星向地面设备提供时间和位置信息。在许多应用场景中, GPS 被用作主时钟源,以确保节点之间的时间同步性。
- Google TrueTime Google 在其 Spanner 数据库中用到的时钟同步协议,误差范围在 1ms 到 7ms 之间
4.2 逻辑时钟
4.2.1 提出
- 由于物理时钟很难做到精确的同步,所以在分布式系统中无法用物理时钟对事件的发生进行排序。
- 分布式系统中很多问题的关键在于不同的节点对多个事件的发生顺序达成一致 就可以,并且达成一致的顺序 尽量不要破坏因果关系 。
- Leslie Lamport 在 1978 年的论文 《 Time , Clocks , and theOrdering of Events in a Distributed System 》 首次提出了逻辑时钟的思想。
4.2.2 先于关系的提出
定义先于 → 关系如下:
- 如果 a 和 b 是同一个节点(单进程 线程)中的两个事件,如果 a 在 b 之前发生,那么 a → b
- 如果 a 事件是 “节点 P1 发送消息 m 到 P2” b 事件是 P2 收到 P1 发送的消息 m ”,那么 a → b
- 如果 a → b 且 b → c ,那么 a → c ( 传递性)
- 如果 a → b 且 b → c ,那么 a 和 b 是 并发(concurrent) 事件,写作 a||b
- 关系符合离散数学中的 偏序 定义
- 关系隐含了 因果 关系
之所以定义先于关系,就是因为只要知道因果关系即可
先于关系包含因果关系,但是不等于,因为先于可能仅仅是因为时间上先于,并不存在逻辑上的因果关系
下面是一个示例
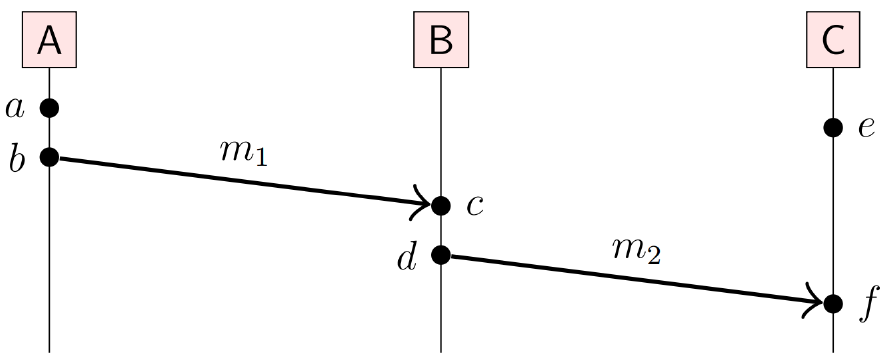
- a → b,c→d,and e→f due to node execution order
- b→c and d→f due to messages m1 and m2
- a → c,a → d a → f,b → d,b→f and c →f due to transitivity
- a||e, b||e, c||e, and d||e ,这些都是无法知道的
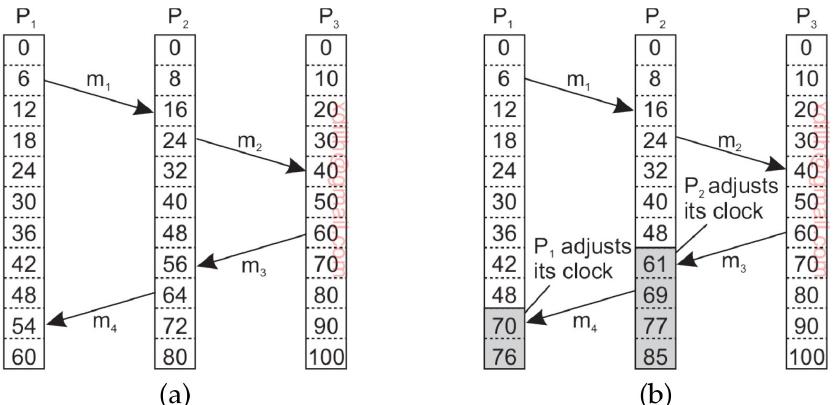
4.2.3 Lamport(标量)逻辑时钟的思想
- 每个节点维护一个不断增加的整数作为本地逻辑时钟
- 节点内 事件 的发生(消息产生、消息发送、消息接收都是事件)会触发逻辑时钟的增长
- 每发生一个新事件就让本地逻辑时钟 Ci 加 1
- 节点 i 发出的每个消息都绑定本地逻辑时钟 C i 作为时间戳
- 假定节点 j 接收到一个消息 m ,其时间戳为 C i , 则节点 j 将自己的逻辑时间调整为:
Cj ← 1 + max {Cj , Ci} - Lamport 逻辑 时钟也成为 标量逻辑时钟
事件的定义和整体的系统功能有关,不能说很小的一件事情发生就 i++,那太小了
可以是一个程序的完成
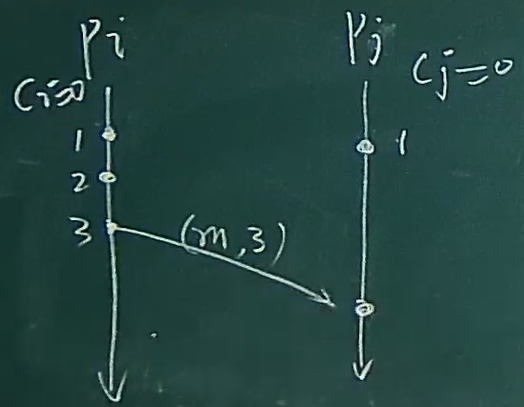
Cj ← 1 + max {Cj , Ci} 的示意图
在消息发布的时候是会发送本地的时间戳的
可以看到,此时Pj 的时钟为0,但是Pi的时钟为3
接受到消息之后,如下
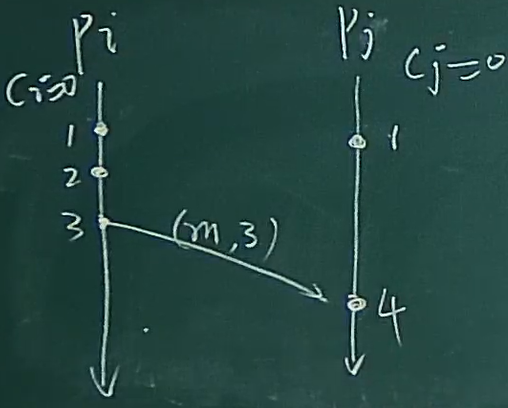
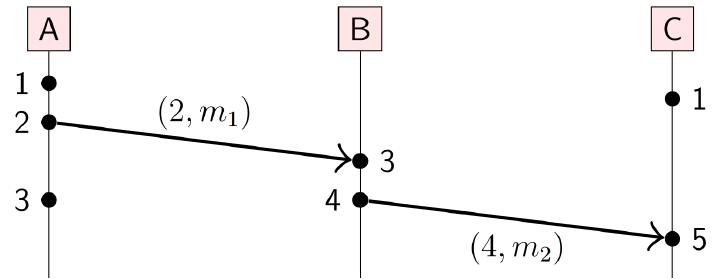
下面还有一个例子
P1,P2,P3的时钟频率是不一样的,但是通过这个方法仍能保证先后顺序的一致
只要满足Cj ← 1 + max {Cj , Ci}即可,不需要满足多个节点的时钟一致
(灰色部分是时钟调整的部分)
结论
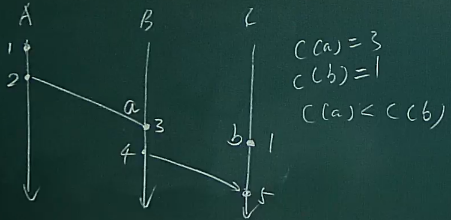
设 C(a) 表示事件 a 对应的逻辑时间戳(此处的a具体到哪个节点做了哪些事情,所以C可以是不同节点的逻辑时间戳),
- 如果 a → b ,那么 C(a)<C(b)
- 但是 C(a)<C(b) 时,不一定满足 a → b
- 有可能事件 a → b ,但是 C(a)=C(b)
如果 a → b ,那么 C(a)<C(b)
- 如果a b在单线程,那么必定如此
- 如果a是发送消息,b是接受消息,那么b的时钟一定最慢是 a的时间种 + 1得来的
C(a)<C(b) 时,不一定满足 a → b
可以看到,捕获不到a b的发生关系,不确定
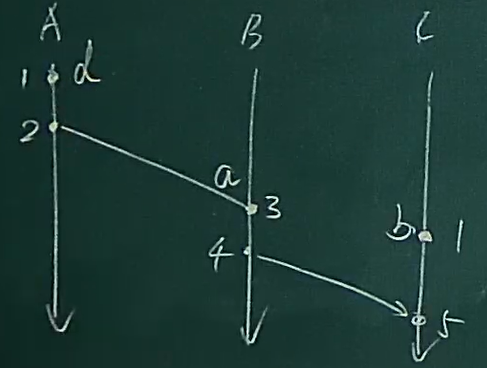
还有一种情况
C(b) = C(d) = 1
但是也是不知道先后顺序
4.2.4 可靠、全序广播协议
(1) 可靠广播协议
- 如果一个节点正确接收到了广播消息 m ,则其它所有节点都正确接收到了该消息 m ;(除非某些节点失效
- 如果消息 m 被正确投递( Delivered )给节点 A ,则消息 m 一定会被被正确投递其它所有节点;(和( 1 )是一个意思
- 如果一个节点正确接收到了广播消息 m ,则 m 一定是某个节点发送的。(即 m 不能无中生有)(一般也不会考虑这个的正确性)
(2) 全序广播协议
在可靠广播基础上,再满足如下性质:
- 多个广播消息以完全相同的顺序投递给所有节点;
(即所有节点以完全相同的顺序接收到了多个广播消息)
如图

- S1发布消息m1 m2给 ABCD
- S2发布消息m3 m4给ABCD
如果仅仅是逐个发送的话是会导致先后顺序的不一致的
应用:分布式多副本数据库
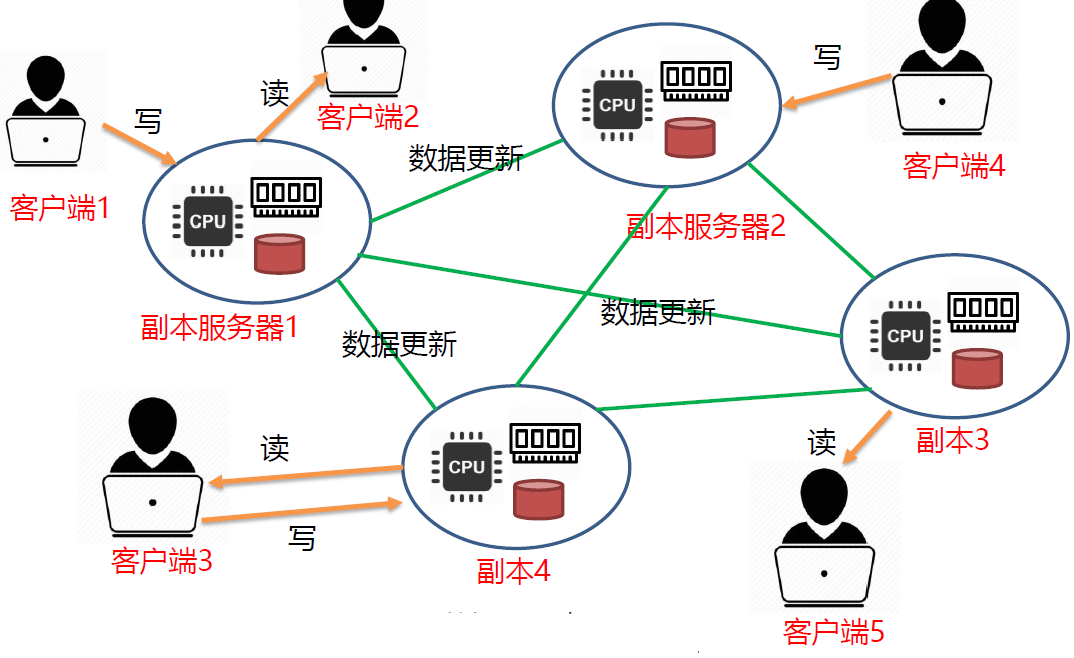
- 每个服务器中保存了完全相同的数据库副本。
- 客户端可以向任意的副本服务器发送数据读、写请求。
- 任意时刻都有多个客户端向不同服务器发出数据写入 更新 请求,要保证多副本之间的一致性
实现了多副本数据库可以提高一致性与效率
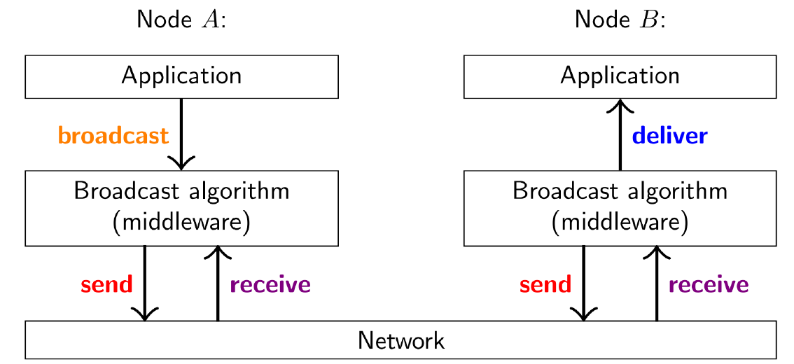
4.2.5 中间件的位置
(1) 逻辑时钟中间件的位置
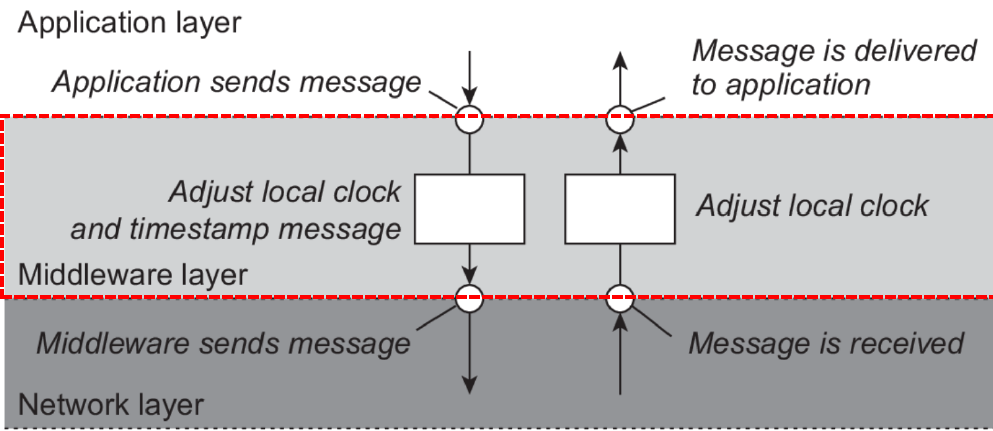
- 实现逻辑时钟功能的软件模块一般放在中间件中,该中间件位于 应用层和 OS 网络协议栈 层之间, 对上 为应用程序提供 API 接口, 对下 调用 网络
协议栈 层的服务接口( Socket 接口) - 实现逻辑时钟功能的软件 模块也可以与应用层集成到一起
逻辑时钟中间件就是进行排序的
(2) 消息广播中间件的位置
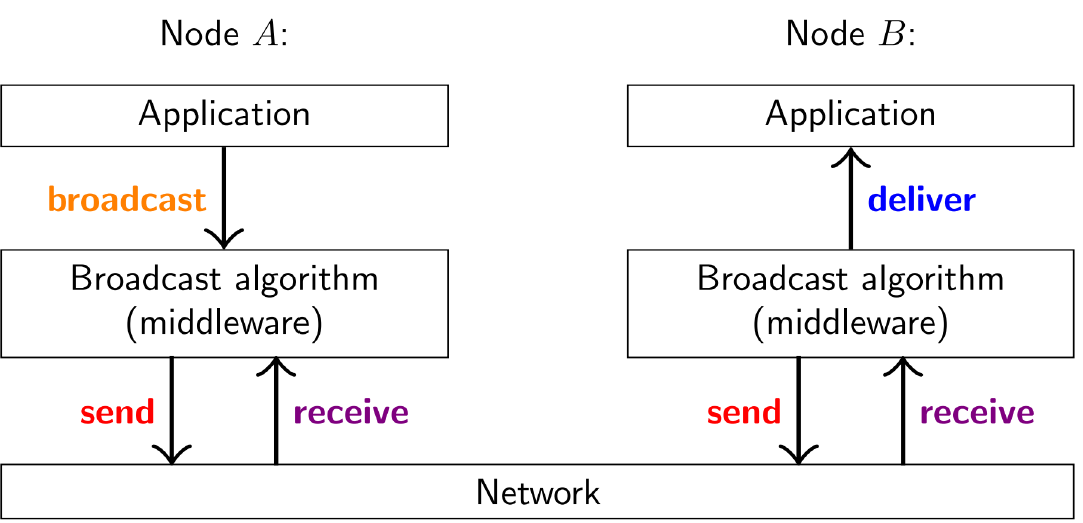
注意receive和deliver的区别
- receive仅仅是中间件将消息从网络中取出
- 取出之后不直接发给节点,而是先缓存起来,当缓存了一定数量的消息之后,对其进行排序
- 然后按照排序发给节点
如下

进行排序后,就有 m3 m2 m1 的顺序了
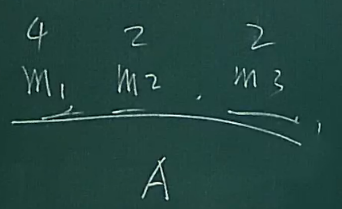
但是出现了问题,如果m2和m3的顺序一致呢?
4.2.6 满足全序关系的逻辑时钟算法
(1) 说明
原始的逻辑时钟算法存在如下
- 问题 :给定 两 个消息 <a, C( a)>,,<b, C( b)>,有
可能无法根据其逻辑时间戳 C(a) 、 C(b) 进行排序(因为 C(a )=C(b)。
下面给出一个 改进的 满足全序关系的逻辑时钟 算法
- 每个 节点维护一个不断增加的整数作为本地逻辑时钟
- 节点内事件的发生(消息产生、消息发送、消息接收都是事件)会触发逻辑时钟的增长
- 节点 i 发出的每个消息都绑定一个二元组:
<本地逻辑时钟 C i ,节点 ID 号 i> - 每发生一个新事件就让本地逻辑时钟 Ci 加 1
- 假定节点 j 接收到一个消息 m ,其时间戳为 <Ci , i >, 则节点 j 将自己的逻辑时间调整为:Cj ← 1 + max { Cj , Ci }
总之就是在后面添加了编号
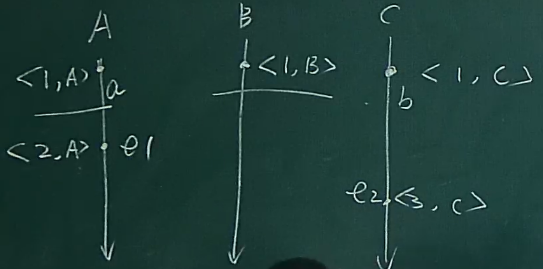
有 a < b
(2) 主要思想
- 系统内任意的两个消息(或者事件) a 、 b 都可以基于时间戳L(a)=<C(a), ID(a)>, L(b)= <C(b), ID(b)> 比较大小,规则为L(a)<L(b),当且仅当 C(a) < C(b) or C(a)=C(b) and ID(a)<ID(b)
- 有了消息 比较大小的 规则,分布式系统内 所有消息都可以进行统一排序 。
- 该排序的性质:
- 保持了潜在因果关系
a 先于 b ,则一定有 C(a)<C(b)(但反过来不成立
目的就是为了统一排序,节点的标号并无实际意义
4.2.7 全序广播协议
(1) 假设可靠FIFO链路
- 假设模型:
- 点对点拓扑;
- 可靠 FIFO 链路;
- 节点不会失效
- 每个节点执行如下协议(下面这个协议要记住):
- 需要广播一个消息时,将其利用点对点链路发送给所有节点 包括自己
- 当收到了一个消息时
- 将消息按 逻辑时间戳 先后顺序放入缓存队列中;
- 向所有节点发送关于该消息 的 ACK 消息 包括自己
- 当收到关于某消息 m 的 ACK 消息 时,
- 将队列中对应消息 m 的 ACK 计数 加 1
- 观察队列头部 的消息 ,如果关于该消息已经收到了所有节点的ACK 消息 ,则将其从队列中取出,并完成投递(给应用层)。
- 定理:如果缓存队列中处于头部的消息收到了所有节点 的 ACK 消息 ,则该消息也位于所有节点内部队列的头部。( 用反证法证明)
- 优化方法:节点 N2 收到节点 N1 的广播消息 m1 后,如果 N2 也有自己的消息 m2要广播,则可以直接广播 m2 ,不用广播关于 m1 的 ACK 消息。
说明
FIFO链路,就是 <6,C> 必定在<3,C>之前被接受到,如果已经接受了<6,C>,那么就不用考虑<3,C>的可能了
发送消息也会给自己发送
可以看到,A发送m1的时候,也给自己发送了
- 消息的发送要一视同仁,否则就要加入很多判断语句
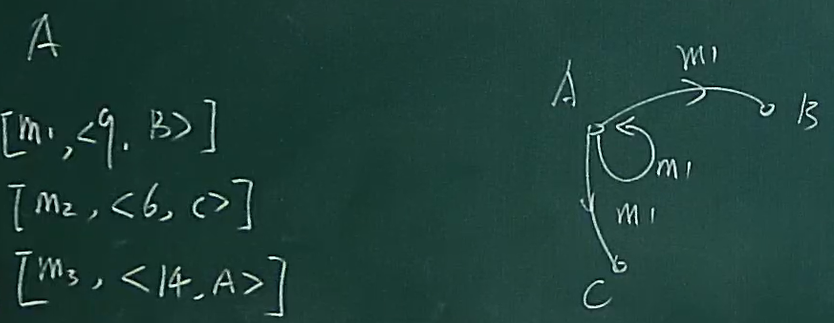
问题:什么时候deliver
由上可以看到,中间件receive到消息后先进行缓存,排好序后deliver给application
- 如果只有ABC三个节点
- 现在接受到了 m2 m1 m3三个消息,不用担心出现<3, C>这样的消息,因为假设可靠FIFO链路
- 所以现在三个节点的消息全部接受了,就可以直接发送了
但是如果有4个几点呢?担心<3,D>的到来
这就体现算法的精髓了
- 当收到了一个消息时
- 将消息按 逻辑时间戳 先后顺序放入缓存队列中;
- 向所有节点发送关于该消息 的 ACK 消息 包括自己
- 当收到关于某消息 m 的 ACK 消息 时,
- 将队列中对应消息 m 的 ACK 计数 加 1
- 观察队列头部 的消息 ,如果关于该消息已经收到了所有节点的ACK 消息 ,则将其从队列中取出,并完成投递(给应用层)。
就是当A已经收到了m2 m1 m3消息的时候,向所有节点发送对应的ACK消息,加入B C也都收到了m2 m1 m3,此时就会将这些消息的ACK计数+1,对于B节点,如果m2的ACK=4(总共有4个节点),那么就投递即可
精华就在于,B不用的担心<3,D>的出现了,因为B已经收到了D关于m2的ACK消息了,如果存在<3,D>,那么<3,D>必定在m2的ACK之前到达B


优化方法:节点 N2 收到节点 N1 的广播消息 m1 后,如果 N2 也有自己的消息 m2
要广播,则可以直接广播 m2 ,不用广播关于 m1 的 ACK 消息。
(2) 假设可靠链路
- 假设模型:
- 点对点拓扑;
- 可靠链路(不用FIFO链路);
- 节点不会失效
- 每个节点执行如下协议:
- 当需要广播一个消息时,将其利用点对点链路发送给所有节点 包括自己
- 当收到了一个消息时
- 将消息按 逻辑时间戳 先后顺序放入缓存队列中;
- 观察缓存队列头部的消息,如果关于该消息尚未广播 过 ACK 消息则向所有节点发送关于该消息的 ACK 消息 包括自己
- 当收到关于某消息 m 的 ACK 消息 时,
- 将队列中对应消息 m 的 ACK 计数 加 1
- 观察队列头部 的消息 ,如果关于该消息已经收到了所有节点的ACK 消息 ,则将其从队列中取出,并完成投递(给应用层)。
- 定理:如果缓存队列中处于头部的消息收到了所有节点 的 ACK 消息 ,则该消息也位于所有节点内部队列的头部。( 用反证法证明)
不要求FIFO链路了
- 当头部为<6,C>的时候,不用担心<3,C>的出现
- 比起第一种假设,现在的区别是
- 第一种假设发送的是接受到的m的ACK
- 第二种假设发送的是头部消息的ACK
- 因此确定头部消息都会被接受到
不实用
实际上这个协议是不实用的,因为只有当收到所有节点都收到这个消息的时候才会deliver给application,如果有一个节点比较慢,那么其他所有节点都会变慢
总的就是效率低
用全序广播实现分布式互斥锁
当然这也不是什么好协议
问题:如何 在分布式系统中 保证同一时刻只有一个节点可以访问某共享资源?
假设模型: 点对点拓扑; 可靠 FIFO 链路 节点不会失效
主要思想
-
想要访问共享资源的节点利用 可靠广播协议 广播一个 LOCK 消息;
-
任意节点收到 LOCK 消息后:
- 将 LOCK 消息 放 入一个本地队列, 将 队列中消息按逻辑时间戳排序;
- 利用 可靠广播协议 广播一 个针对该 LOCK 的 ACK 消息;
-
任意节点 收到 ACK 消息后:
- 在队列中找到该 ACK 针对的 LOCK 消息,将该 LOCK 的 ACK 计数加 1
-
想要获得互斥锁的节点收到 ACK 消息后,除了完成动作 3,还需要 检查
-
自己发出的 LOCK 消息是否位于本地队列的头部;
-
自己发出 的 LOCK 消息 是否 已经 收到了所有 节点的 ACK 消息;
如果上面两个条件都成立,则该节点成功获得了互斥锁 ,开始访问共享资源。
-
-
获得互斥锁的节点访问完共享资源之后 利用 可靠广播协议 广播一 个 RELEACE 消息
-
任意节点 收到 RELEACE 消息 后:
- 删除队列头部与该 RELEACE 对应的 LOCK 消息;
-
想要获得互斥锁的节点 收到 RELEACE 消息 后,除了完成动作 ( 还要完成动作 (
假如ABCD中AB要锁,发出消息
Locka 和 Lockb
根据全序广播协议,当A发现Locka在头部的时候,就自动访问即可
当a访问结束之后,释放锁,发出RELEASE信号
当节点接受到 RELEASEa之后,删除头部的LOCKa
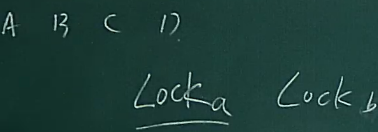
用全序广播实现leader全局
同理,想当leader的发出消息
但是问题是,leader失效或者leader不愿意放弃当leader,那就会当到死了
4.2.8 全序Lamport逻辑时钟的缺点
能够实现全序广播协议,前提是这个全序逻辑时钟
设L(a) 表示 事件(或消息) a 对应的逻辑时间戳
对于任意的事件a 、 b
如果L(a)<L( b),则无法区分如下两种情况
- a → b (a Happen Before b a 和 b 有因果关系)
- a || b (a 与 b 逻辑并发, a 和 b 没有因果关系)
在某些场景下,我们需要准确区分上述两种情况,以方
便进行区别处理。为此引入 向量时钟 。
全序逻辑时钟仅仅能够实现统一排序,但是不能确定
L(a) < L(b)
- 可能 a = ❤️, C>, b = <4, D>
- 也可能 a = ❤️, C>, b = ❤️, D>
不能判断两种情况的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号