分布式系统第二讲 模型问题
第二讲 模型问题
主要内容
- 设计产品级分布式系统的挑战
- 分布式系统模型
- 网络模型(网络拓扑、链路模型)
- 节点模型
- 时间模型
产品级分布式系统需要关注的特性
- 功能正确性
- 效率(时间、空间、通信)
- 可扩展性 可伸缩性( Scalability
- 垂直可扩展性( Vertical Scalability
- 水平可扩展性( Horizontal Scalability ))(节点热插拔
- 容错性( Fault Tolerance/Reliability
- 可用性( Availability
- 可恢复性( Recoverability
- 透明性( Transparency
- 开放性( Openness
- 安全性( Security
- 可维护性( Maintainability
ChatGPT的出现不是仅仅一个团队的成功,而是整个计算机领域的成功,即使是人工智能的系统,它的模型训练也是依靠分布式系统实现的
设计产品级分布式系统的挑战
- 不可靠的计算节点
- 部分节点失效是常态;
- 不可靠的通信网络
- 丢包
- 乱序
- 传输延迟剧烈变化
- 数据包内容被修改(被动、主动)
- 网络断裂
- 不可靠的时钟
- 不同节点的时钟不同步
- 没有全局观 ,只能通过与其它节点的交互信息对系统状态进行评估
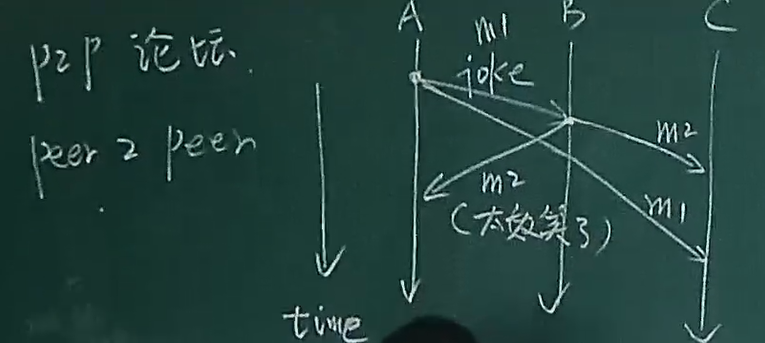
不可靠的时钟问题
以下是一个 P2P的论坛
- m1: 是A的消息
- m2: 是B的回复
可以看到C先得到m2,后得到m1,
一个解决的方法:
- (m1, timestamp)
- (m2, timestamp)
即在发送消息的时候发送时间戳
但是问题来了:
- 就是A B各自取自己的本地时钟,可能不匹配,就是不同节点的时间不同步,因此不能用时间戳排序
使用逻辑时钟来解决这个问题,这个问题已经研究了几十年了
分布式系统设计困难性示例
- 两将军问题( The two generals problem
- 分布式事务问题
- 拜占庭将军问题( The Byzantine generals problem
- 开放分布式系统中的恶意节点问题
- 可靠广播协议的设计
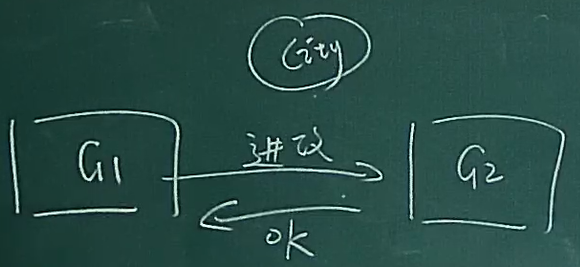
两将军问题
- G1发动进攻消息给G2,G2返回ok给G1
- G1需要等待G2的ok即可
- 但是G2要担心G1是否接收到了ok,最好是G1再次返回一个ok
但是这样就陷入循环了
这就是不可靠的网络造成的问题

分布式事务问题
两个事物,要么大家都做,要么大家都不做
比如两个事务,必须都做或者都不做

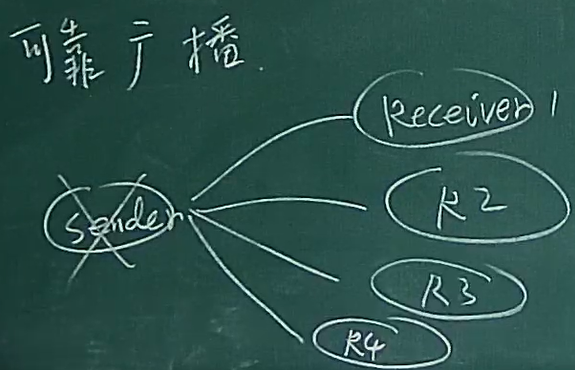
下面以可靠广播为例
Sender必须将消息发送给每个Receiver,并且要保证每个都收到
- 如果依次发送然后等待确认的话,就忽视了节点失效问题,Sender本身也会失效的
可靠广播协议的设计
Gossip协议
就是流言协议,每个receiver接受到消息之后,发送给其他“亲近”的节点,告诉他们不要告诉别人,但是会逐渐往外传
即便sender失效也没问题
Gossip有个参数比较重要,就是每次传播的节点的个数
节点过小过大都不合适
- 过小:传播的慢
- 过大:传播的快,但是浪费带宽
分布式系统模型
一开始就要对系统进行建模,建模的时候既要考虑容忍性问题,就是哪些问题可以容忍,哪些不可以容忍
设计分布式系统、分布式协议时使用的抽象模型,从以下三个方面进行定义:
在设计分布式系统的时候,下面这些东西都要定义的
1. 定义角度
-
网络行为模式
- 网络拓扑(点对点、多播、广播);
- 通信链路的行为模式
-
节点故障模式
-
失效停止模式( fail stop
(有一个节点失效就停止了)
-
失效停止重启模式( fail recovery
-
拜占庭 ( 模式( fail arbitrary
(一个节点失效后,不确定,可能不工作,可能产生一些副作用。就是失效之后瞎捣乱
比如黑客控制一个节点,说谎
分布式系统的学术研究,很多都是研究拜占庭的)
-
-
时间(同步)模式
- 同步模式( Synchronous
- 异步模式( Asynchronous
- 部分同步模式( Partially synchronous
2. 不同模式的链路
以下只考虑点对点通信拓扑:
-
任意链路
- 丢包、重复包、内容篡改、伪造、乱序、传输延迟抖动
- 有 主动攻击者 存在的情况
-
一般损失链路
-
只存在丢包、重复包、乱序和传输延迟抖动
在局域网内可能只有这些问题,因为不存在黑客进行内容篡改伪造,也不存在打雷造成传输延迟抖动
-
链路会发生断裂( Partition ),但断裂持续时间是有限的
-
-
可靠链路
-
发送者发出的每个消息都可以被正确接收
UDP + Retry + quchong
-
但是:( 1 )存在传输延迟抖动
-
但是:( 2 )接收到消息的顺序可能和发送顺序不一致
-
-
可靠 FIFO 链路
- 发出的每个消息都可以被正确接收并且不会乱序
TCP 底层直接采用TCP那么就是可靠链路,那么可能效率会下降
但是即使使用TCP协议,也会出问题,比如网线断了,那么TCP连接也会断
TCP + 重连retry,在TCP上面新建立一个retry的业务,就是定时进行测试,如果tcp断了,那么retry
而且TCP能避免了点对点乱序,但是避免不了多点乱序
也就是可靠链路要考虑乱序和延迟抖动问题
3. 时间(同步)模式
- 同步模式
- 消息传输延迟不超过已知的上限
- 节点以已知速度执行算法
- 异步模式
- 消息传输延迟没有上限
- 节点在运行期间可能会暂停任意长的时间
- 部分同步模式
- 系统大部分时间工作在同步模式;
- 但在有限时间段(该时间段长度不可预知)内工作在异步模式;
- 具体应用:设计分布式协议时可以在某些环节设定超时值,但协议的正确性、活性不完全依赖于该超时值。
同步模式:
- 假设最大延迟是1s,如果有个节点超过1s还未回馈,说明这个节点死了,就在算法中排除这个节点了
- 这样从算法层面上就排除了
- 但是系统在真正运行的过程中容错性比较低,实际中节点也有可能因为在做其他处理而来不及回馈
异步模式:
- 容错性比较高,允许一个节点很长时间不回馈
- 但是在异步模式下设计算法是比较困难的
部分同步:
- 实际的算法大都采用部分同步模式
- 当工作在同步模式下不再实用的时候,采用部分同步
- 大部分时间是同步,但是小段时间允许异步
Paxos协议
- 其他几个节点选举A是leader,A给其他节点发布号令
- 但是如果有段时间A不响应了,一些节点会认为A挂了,选举B节点为leader,但是一些节点并不知道A挂了
- 而且A可能处于内外存倒换状态,就是处于部分同步的超时状态
- 等一段时间之后A醒来了,但是并不知道自己不是leader了,继续给部分节点发布号令,此时B也发号令;而且一部分节点认为A是leader,一部分认为B是leader
- 这就是部分同步模式下出现的问题
- 而Paxos协议能够解决这些问题的
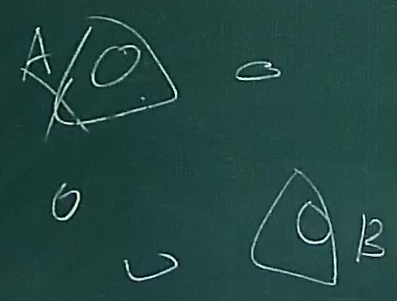
如何验证一个分布式算法的正确性
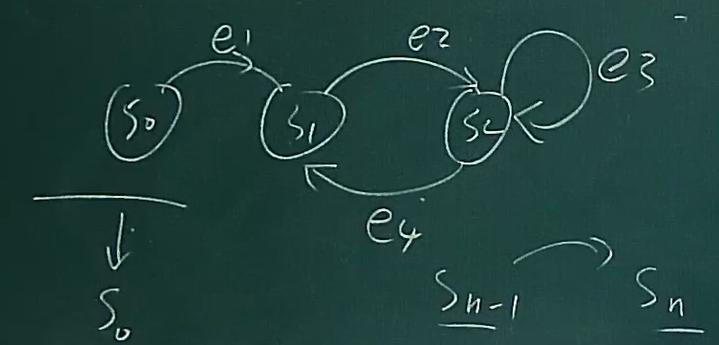
- 就是这个样子,一个算法可以转换成一个状态机
- 然后假定S0正确,证明对任意的Sn-1,Sn是正确的
证明算法的正确性一定要在严格意义的数学上证明是正确的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号