
分布式系统第一讲 基本概念
第一讲 基本概念
1.1 分布式相关概念
1.1.1 分布式系统
从普通用户角度看,分布式系统是计算节点内聚在一起的一个整体,用户在使用系统功能的时候,往往无法察觉分布式系统的内部构成和节点之间的协作关系。
1.1.2 分布式计算
多个通过网络互联的计算节点通过相互协作共同完成计算任务
1.1.3 注意点
- 多个计算节点:
计算节点一般指单个计算机,也可以是计算机中的一个进程、线程或虚拟机。计算节点抽象为有限状态机(图灵机)。
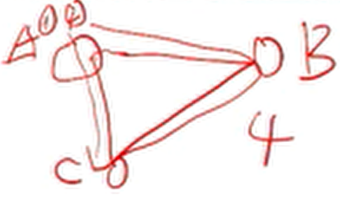
一个进程也算是一个节点,以下图中A有两个进程,总共看做是4个节点
-
网络互联:
节点之间可以通过有线、无线等任意网络通信方式互联。对物理拓扑结构不做明确限定。有线和无线连接都可以

-
独立自治:
每个节点都有自己独立的CPU、独立的时钟,发生错误的时机和模式也相互独立。并发:不同节点的动作是同时进行的。
异步:A节点在做事情,B节点也在做事情,但是两个节点做事情的频率是不一样的
分布式系统一定是异步的,同步的话节点之间有耦合性
分布式计算和多线程的区别:
- 多线程有同一个时钟去控制
- 不用考虑某一个线程崩掉,一个线程崩掉意味着CPU过热或者内存不够,这样的话所有线程实际上都会出问题,需要重新启动,
-
相互协作以完成共同目标
-
消息传递模型:
消息传递槟型,并非内存共享模型
1.1.4 消息传递模型&共享内存模型
消息传递模型
消息传递模型
- 节点之间没有公共状态(这个可以对比多线程系统,他们中间是有公共状态的),必须通过相互发送消息来进行协作(在设计算法的时候减少通信次数)。
- 内部运算速度比消息传递速度高几个数量级。通信复杂度是影响效率的重要因素(因此在设计算法的时候尽量减少消息传递的次数)。
- 系统设计时必须要应对局部失效、消息延迟/丢失等错误。
- 也被称为“Share Nothing”架构
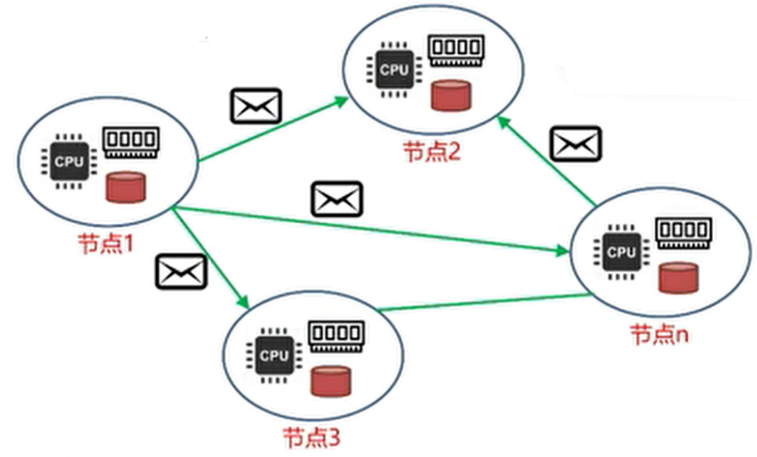
在设计分布式算法的时候不仅考虑时间复杂度,还考虑通信复杂度,就是考虑一个算法通信的次数。
尽量让CPU多算一些,而少在通信上花费时间
共享内存模型
老师:计算机大学培养的两种素养:
- 算法设计能力
- 系统设计能力(这也是架构师也必须使用的 )
算法有很多线程的算法可以使用,但是系统设计能力却不一定,这也是大学教育所欠缺的
比如排序1TB的数据,如果只用算法,那么可能最快也是10天,这是算法的上限
系统设计能力体现在,会想到使用多线程的方法,如何充分利用CPU:比如将所有的数据分成4个子数组,每个数组分给一个CPU排序,最终将得到的4个排好序的数组进行一次归并排序
多线程系统
在OS中,
- 进程是资源分配的单位,多个线程属于一个进程
- 给进程分配的最重要的资源:
虚拟内存VM管理有两个主要作用
扩大物理内存(就是当物理内存不够用的时候,用外存来模拟内存,因此外存可以接入与物理内存公用,当然这不是最重要的)
最终要的是给每一个进程分配一个独立的内存空间(这个是最重要的作用)
也就是进程获得的最重要的资源
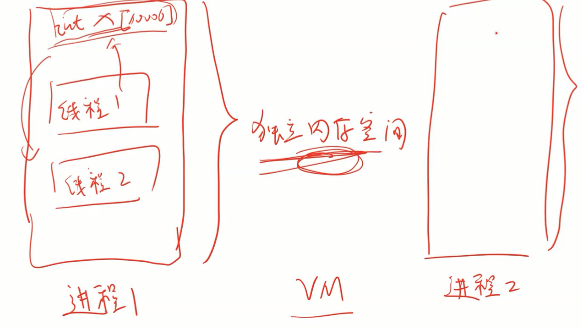
- 线程依附于进程,线程之间通信的方式就是进程之间的全局变量,因为他们都是共享这个独立内存空间的
多CPU系统
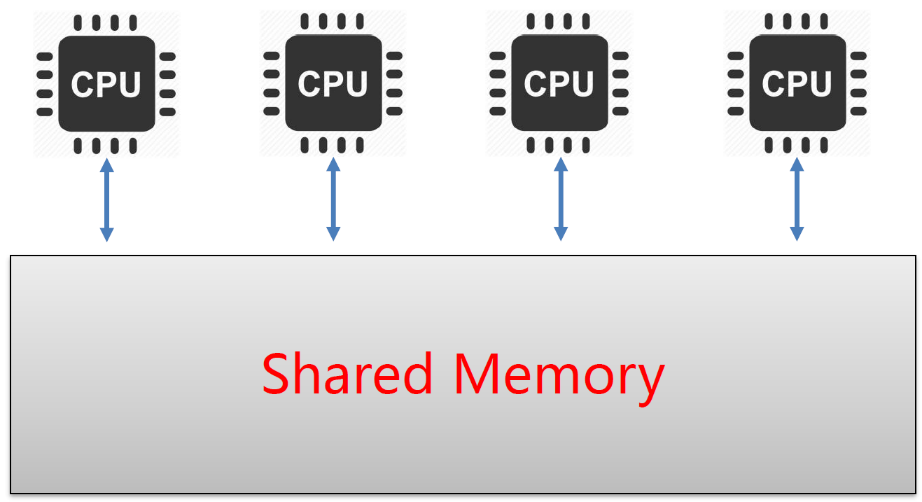
事实上,多CPU系统的每个CPU都可以看做是一个线程
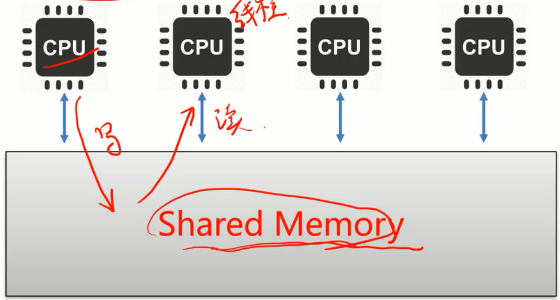
- 不同节点之间共享公共状态;
- 节点之间通过写 读共享存储器中的公共状态来隐式地进行通信 。
不用考虑信息丢失的问题,信息丢失说明内存出问题了,说明整个系统都坏了就好像设计算法的时候不考虑世界末日的问题一样
关注点的不同
- 共享内存模型的关注点在锁,就是对统一资源访问的加锁问题
- 消息传递模型的关注点在消息能否接收到
1.2 与并行计算的关系
分布式计算是一种特殊的并行计算
1.2.1 不同层次的并行计算
-
指令级并行:多指令并行;单指多数并行(向量指令)
比如向量计算 a[100], b[100], c = a + b,如果不并行的话那么要循环100次,但是有个指令可以直接并行计算100次
IADD a, b, c, 100或者
ADD R1,R2,ADD R3,R4可以合起来ADD R1, R2 | ADD R3, R4,直接计算两个加法 -
CPU 多核并行:多线程编程
-
多 CPU 并行(一致性内存访问):多线程编程
-
多 CPU 并行(非一致性内存访问):超级计算机
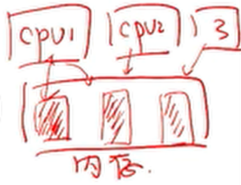
服务器的内存也是放在一起的,每个CPU都有一个特有的内存,访问特有内存时速度比较快,访问其他的内存时速度慢
-
基于 GPU 的并行:单指多数并行; CUDA 、 OpenCL
GPU处理并行计算很快,比如a[100][100], b[100][100], c = a + b矩阵运算,双重循环的话要循环1w次,但是GPU可以将运算摊到每个核中,这样很快就能算完
- GPU是显卡里面的处理器,里面有成干上万个核,每个核只能做很简单的浮点计算,并不能像CPU一样做if else的流程控制
- 矩阵运算的时候,如果每一个核处理一对数的计算,那么100*100的矩阵一个时钟周期就可以完成
- 每个核都有一个内存,所有核又有共享的内存
-
多机并行:基于消息传递的分布式计算( share nothing
1.2.2 分布式计算 & 并行计算
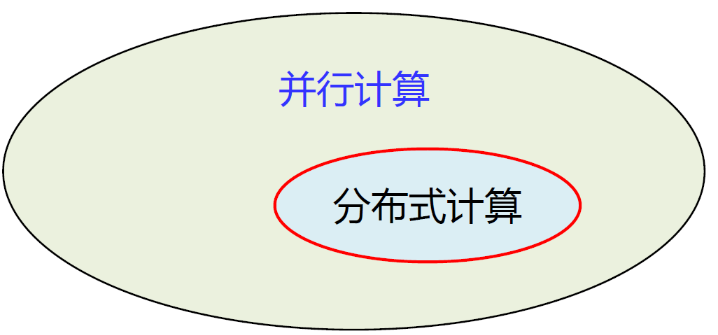
可以看到,分布式计算属于并行计算
1.3 云计算
1.3.1 概念
- 云计算是一种计算资源的应用模式/服务模式/交付模式(站在用户角度看),不是一种技术。
- 核心理念是使用户可以随时随地、便捷地、随需应变地从可配置计算资源共享池(云)中获取所需的资源(包括计算、网络、存储、软件应用等资源)。资源能够按需供应、按需释放、按需付费 。
- 共享资源池的管理主要由云服务提供商负责,用户可以专注于自己的业务逻辑(这里的用户多指技术用户)。
1.3.2 云计算的不同服务模型
-
IaaS :基础设施即服务 Infrastructure as a Service(相当于直接给一个2核 8G的服务器,里面什么都不装着,包括OS也不装,不过一般都会给装OS的)
-
PaaS :平台即服务 Platform as a Service(提供一个开发平台,比如Java开发,里面有JDK,Tomcat,Mysql,Spring等,都在平台上,程序员不需要考虑这些环境问题,直接告诉阿里云平台要这些东西,自动给你配好,只要将jar包放上去就行)
实际上,对于程序员,最关键的就是业务逻辑,这些环境都不是关键的
-
SaaS :软件即服务 Software as a Service(相当于提供一个软件,用户完全不用考虑,比如用户就要一个库存管理的网页)
-
CaaS :容器即服务 Container as a Service(CAAS:将程序和运行时环境打包后,不用OS,交给CAAS就能运行)
-
FaaS :函数即服务 Function as a Service Serverless Computing
-
BaaS (Backend )、 DaaS (Data )、 NaaS (Network
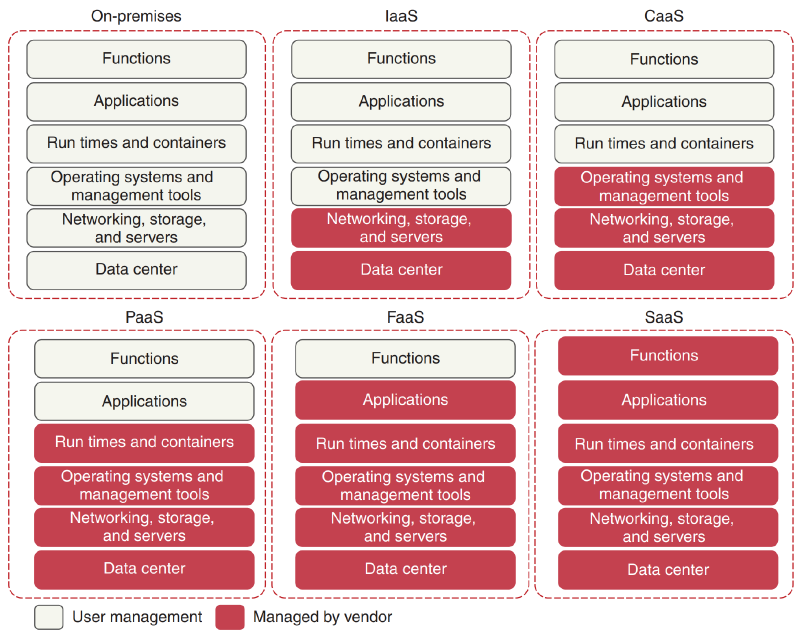
可以看到,提供的东西越来越多,能让技术人员更加专注于业务
依次为
On-premises < Iaas < Caas < Paas < Faas < Saas
1.3.3 云计算&分布式计算
分布式计算是实现云计算的核心技术之一云计算是目标,分布式计算是手段。
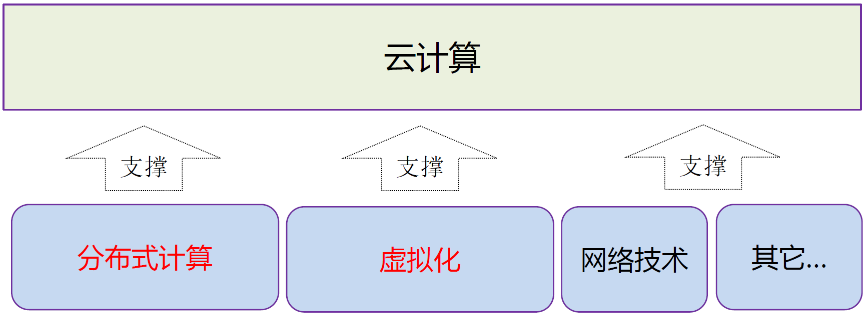
1.4 关于分布式计算
1.4.1 出现背景
- 大大小小的计算设备无处不在
- 网络通信技术高速发展、网络规模不断扩大
- 摩尔定律走到瓶颈,免费午餐已经结束
- 越来越多的计算任务需要由分布在不同区域的多个计算节点协作完成(比如天网,多个摄像头内部都有自己的CPU,缓存,在实现追踪的过程中,肯定不可能是摄像头全部将数据给中心,而是多个摄像头之间之间通信,相互合作)。
1.4.2 构建分布式系统的目的
- 提高计算能力
- 提高存储能力
- 提高网络吞吐能力(并发访问能力)
- 提高可靠性(解决局部失效问题)
- 提高安全性(解决被局部攻击问题)
- 提高可扩展性(解决瓶颈问题)
- 实现资源共享
- 实现跨越时空的协同服务(发挥不同节点的优势)
1.4.3 衡量分布式系统优劣的特性
-
可扩展性 可伸缩性( Scalability
-
垂直可扩展性( Vertical Scalability)
就是当所有机器指标提升时,整个分布式系统的性能提升的幅度
-
水平可扩展性( Horizontal Scalability ))
当机器数量增多时,整个分布式系统的性能提升的幅度(一般来说,是不会线性增长的)
-
-
容错性( Fault Tolerance/Reliability
- 可用性( Availability
- 可恢复性( Recoverability
-
并发 性( Concurrency)
-
透明性( Transparency)
-
开放性( Openness)
-
安全性( Security)
-
可维护性( Maintainability)
-
可观测性( Observability)
1.4.4 透明性分类
| 透明性 | 描述 |
|---|---|
| 访问透明性 | 数据的表示、存储和底层访问方式被隐藏 |
| 节点透明性 | 实际提供服务的物理计算机节点标识被隐藏 |
| 迁移透明性 | 用户感觉不到对象资源的迁移过程 |
| 复制透明性 | 用户感觉不到对象资源存在多个副本 |
| 并发透明性 | 多个用户能并发的使用共享资源而互不干扰 |
| 伸缩透明性 | 分布式系统内部节点的增减被隐藏错误 |
| 错误透明性 | 用户感觉不到分布式系统的局部错误 |
| 性能透明性 | 系统能够自动通过增减资源以适应变化负载变化 |
| 移动透明性 | 用户能够在系统内移动而不会影响到正在使用的功能 |
1.4.5 设计分布式系统的挑战
- 自治 :各节点有自己独立的时钟、独立的内部状态
- 局部视图 :节点只能看到整个系统的某个局部 视图
- 故障处理 :必须处理网络故障、局部节点 故障等
- 开放性 :节点数目在变动,网络情况在变动
- 可扩展性 :节点增加时性能须合理增长
- 异构性 :各个节点的软硬件差异性很大
- 安全性 :保密性、完整性、认证性、隐私、可用性
- 透明性 :应用层或用户无法察觉位置、并发、复制、故障、移动、伸缩、性能等 变化
- 观测问题 :运维者如何准确获取各个节点的运行状态和参数
- 维护问题 :针对具体节点如何快速上线 下线 升级 更改配置
- 服务质量保证
1.5 分布式计算的应用和展望
1.5.1 应用领域
现实生活中分布式系统已经得到了广泛应用近年来的热点技术背后都以分布式系统作为后盾
- 云计算(边缘计算、雾计算)
- 物联网
- 大数据(分布式采集、存储、处理)
- 人工智能(高性能分布式计算、GPU)
- 区块链
可能没听过的一些热点:
- SOA
- 微服务
- P2P
- 网格计算
- 无处不在计算(Ubiquitous Computing)
- 大型Web系统:HW/BAT的后台是什么?
计算机科学发展到今天,分布式计算应该成为和操作系统同等重要的专业基础课程。
分布式计算领域还大有可为
1.5.2 分布式系统的例子
- 实现资源共享的分布式系统(分布式存储)
- Web 系统、 DNS 系统
- 网络文件系统: NFS 、 HDFS
- P2P 资源共享系统: BitTorrent 、 μ Torrent 、 eMule
- 区块链、比特币
- 高性能计算系统: Map Reduce 、 Spark 、 TensorFlow
- 云计算
- 网格计算
- 集群计算
- 分布式信息系统: 跨企业应用系统、金融应用系统
- 泛在计算( Ubiquitous Computing
1.5.3 国内中间件
- Spring Cloud Alibaba 微服务 开发一站式解决 方案 阿里
- Dubbo :高性能 、 轻量级开 源 Java RPC 框架 阿里
- TFS :分布式文件系统 。高 可扩展、高可用、高性能、面向互联网服务的分布式文件系统 。 阿里
- TubeMQ :腾讯开源万亿级分布式消息中间 件 腾讯
- Tendis :高性能 的分布式存储系统,兼容 redis 协议 腾讯
- Angel :高性能分布式机器学习 平台 腾讯
- HarmonyOS :基于 微内核的全场景分布式 OS 华为
- KubeEdge :用于边缘计算的容器编排系统 华为
- PaddlePaddle 飞桨:开源深度学习 平台 百度
- OneFlow :分布式深度学习流式 系统 一流 袁进辉,院友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号