计组第七章 指令系统
第七章 指令系统
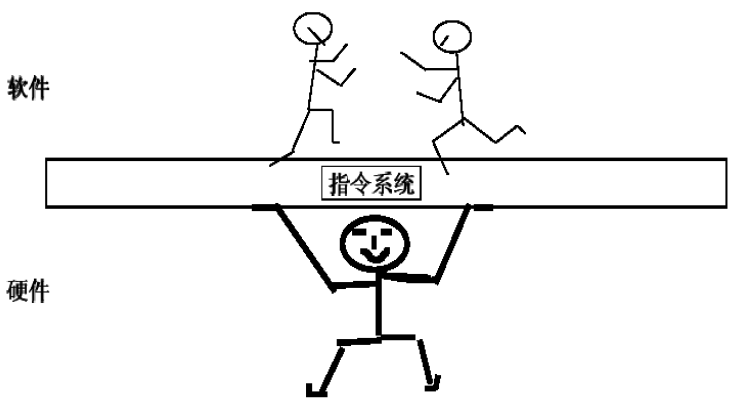
指令系统在计算机中的地位
-
机器指令:CPU能识别并且直接执行的操作命令
-
指令集:CPU能够执行的所有的指令的集合
指令集是软件和硬件的交界面
7.1 机器指令
机器指令如何设计,系统中应当有哪些类型的机器指令,每种类型的指令做什么操作,这些都是计算机体系结构要做的
而组成原理则是将体系结构设计师设计的指令用组合逻辑的方式实现
7.1.1. 指令的一般格式

- 操作码字段:反映机器做什么操作
- 地址码字段:对谁进行操作,就是要操作的数据的地址
(1) 操作码
事实上,操作码不仅仅反映机器做什么操作
- 有的还反映操作数的类型:比如说,IBM360有8种加法指令,分别进行定点数的加法,浮点数的加法,采用二进制的还是十进制的等
- 有的还指出了寻址方式
① 长度固定
- 用于指令字长较长的情况,比如早期的
精简指令计算机(RISC:Reduced Instruction Set Computer RISC)中,这样是为了译码方便 - 还有IBM370中就是用的8位操作码
② 长度可变
虽然上面的图显示的操作码是集中存储的,但是实际上是可以分散存储的
比如现在使用的×86处理器中就是采用 操作码分散在指令字的不同字段中
使用扩展操作码技术来扩展长度,实现长度可变
扩展操作码技术
好像有两种方式,一种是保留编码的码点作为编码方式,要么利用操作码的某一位作为扩展标志
这里介绍前者,即保留码点
我们以16位长度的操作码,每段4位为例
操作码的位数随地址数的减少而增加
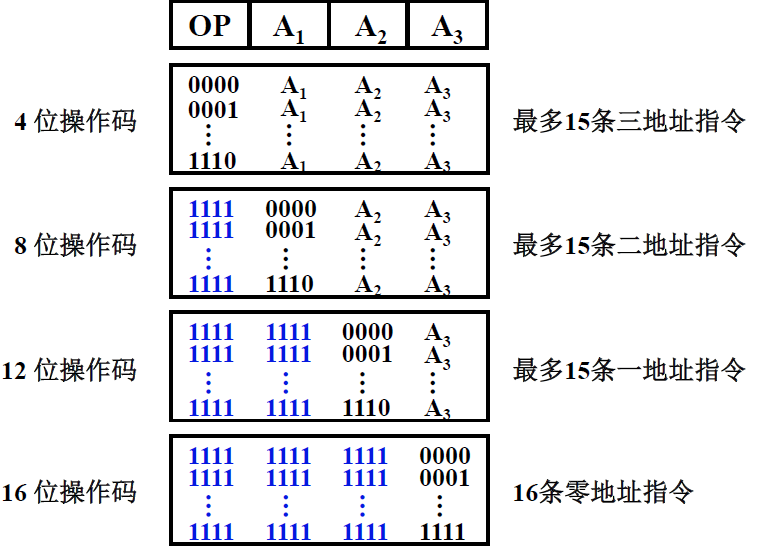
分析:
-
4位操作码—三地址指令:就是前四位是操作码,后面的12位是地址码
最多15条:1111不能作为操作码,而是作为码点
-
4位操作码—二地址指令:1111作为码点,也就是说如果前四位是1111的话,说明这个操作码有8位操作码,8位地址码,在译码的时候按照这个方式译码
也是最多15条
-
后面以此类推
-
注意,16位操作码有16条,因为后面不需要保留码点了
三地址指令操作码每减少一种最多可多构成24 种二地址指令
解释:
- 三地址指令操作码如果减少一种,我们假设减少1110,就是将1110也作为码点,那么,2地址指令就有1110和1111两种码点了,因此保留的指令吗也会增多(最多是16条,如果整个操作码就8位的话,少的话是15条)
- 以此类推,三地址指令操作码每减少一种,二地址指令操作码就会增多
- 二地址指令码的减少也一样
原则:短操作码不能作为长操作码的前缀
哪些指令的操作码用长操作码,哪些用短操作码?
- 常使用的是短操作码,不常使用的是长操作吗
假设8位操作码有31条,如何进行编码(以上面的长度为例)?
(2) 地址码
设指令字长为 32 位,操作码固定为 8 位,其余平均分给地址码
① 四地址
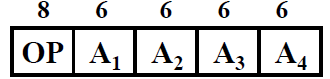
解释:
- A1:第一操作数地址
- A2:第二操作数地址
- A3:结果的地址
- A4:下一条指令地址
- (A1) OP (A2) ——> A3
分析:
- 4次访存:两次操作数,一次结果的地址,一次下一条指令
- 寻址范围为 26 = 64(6位地址码)
缺点:
- 可访问的地址空间很小,寄存器还可以,但是内存不可以用
② 三地址
现在我们使用的计算机中,采用的是PC代替A4
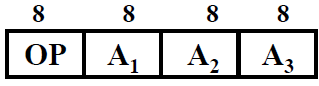
分析:
- (A1) OP (A2) ——> A3
- 四次访存
- 寻址范围 28 = 256(寻址范围增大)
还可以进一步 减少地址码的个数 扩大寻址范围
③ 二地址
结果直接保存在 A1 或者 A2中
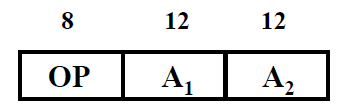
- (A1) OP (A2) ——> A1 或者 (A1) OP (A2) ——> A2,若结果存于 ACC
- 4 次访存:取操作数2次,存结果一次,取吓一条指令1次
- 寻址范围 212 = 4 K
如果操作结果保存在给定的寄存器中,存结果的时候就不需要再访存,直接存到给定的寄存器了
访存就是问着是不是存到寄存器中
可以使用ACC代替A1或者A2,就三次访存
④ 一地址
ACC的内容与 访存得到的操作数 操作 结果放在 ACC中
那就访存2次:一次取第一个操作数,一次取下一条指令
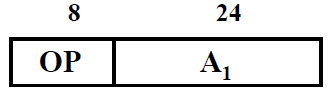
- (ACC) OP (A1) ——> ACC
- 2次访存:取A1操作数,取指令
- 寻址范围 224 = 16 M
⑤ 零地址
无地址码,比如说对ACC的数据进行操作,比如说清零,取反,或者将ACC中某一个数据进行某一个操作,或者判断01,采用操作码就可以了,不用地址码
或者说对栈的操作,一个操作码就直接取出栈顶的两个了
⑥ 总结
- 就是将结果存到指定的寄存器,比如ACC存操作数和结果,PC存下一条指令的地址
- 这样的方式来 扩大寻址范围, 减小访存次数
7.1.2. 指令字长
(1) 决定指令字长的因素
指令字长决定于
- 操作码的长度
- 操作数地址的长度
- 操作数地址的个数
(2) 确定指令字长
在确定指令字长的时候要考虑很多方式,可能固定,可能不固定
-
指令字长固定
指令字长 = 存储字长
-
指令字长 可变
按字节的倍数变化,比如说同一个指令集,有的占1个字节,有的占3 4个字节
一个字节8位
比如说0地址就能将指令字长减少为8位
小结
-
当用一些硬件资源代替指令字中的地址码字段后
- 可扩大指令的寻址范围
- 可缩短指令字长
- 可减少访存次数
-
当指令的地址字段为寄存器时
三地址 OP R1, R2, R3
二地址 OP R1, R2
一地址 OP R1
- 指令执行阶段不访存,执行指令的时候,操作数的来源和结果都在寄存器中
- 可缩短指令字长
7.2 操作数类型和操作种类
7.2.1. 操作数类型
| 类型 | 说明 |
|---|---|
| 地址(地址也是操作数) | 如果是绝对地址,无符号整数;相对地址的 相对,有符号整数 |
| 数字 | 定点数、浮点数、十进制数 |
| 字符 | ASCII |
| 逻辑数 | 逻辑操作的 操作数 是 逻辑数 |
7.2.2. 数据在存储器中的存放方式
我们假设模拟机的地址是按照地址来划分的,就是一个字节是一个地址
那么4个字节的操作数如何保存呢?
我们假设存储字长是32位,也就是4个字节
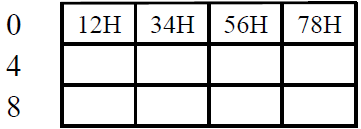
1 2 3 4 5 6 7 8 H 的存放方式
注意这个是16进制,一个数要用4位存储
大端/小端
| 字地址 为 高字节 地址(大端方式) | 字地址 为 低字节 地址(小端方式) |
|---|---|
 |
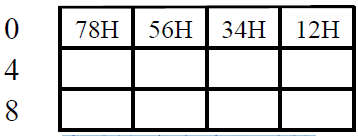 |
- 字地址就是0,表示这一行
- 第一种方式,高字节为12H,地址是0,低字节是78H,地址是3
- 第二种一样
上面的这个是一个机器字的存储方式
接下来看看实际在内存中的存储方式
字节编址,数据在存储器中的存放方式(存储字长64位,机器字长32位)
存储字长 机器字长是不一样的
CPU一次可以拿到双字长的数据
并且注意以下概念
- 字节,就是一个字节8位
- 半字,一个字是4个字节32位,半字就是2个字节16位
- 双子,8个字节32位,一个存储字的长度
- 单字,4个字节32位
(1) 从任意位置开始存储

可以看到,不同类型的数据都是挨着存储的
优点:
- 不浪费存储资源
缺点:
-
除了访问一个字节之外,访问其它任何类型的数据,都可能花费两个存储周期的时间。读写控制比较复杂。
访存一个周期访问的是一个存储字长,而且是根据存储字的地址来访问的,也就是说,一次访问的是上图中的一行
对于一个数据分在两个存储字中的情况,在储存的过程中
- 要用到两个存储周期
- 而且还得判断这个机器字是否在两个存储字中
我们前面学过,存储器是计算机性能的瓶颈,我们希望访存速度变快,因此不使用这种方法
(2) 从一个存储字的起始位置开始访问
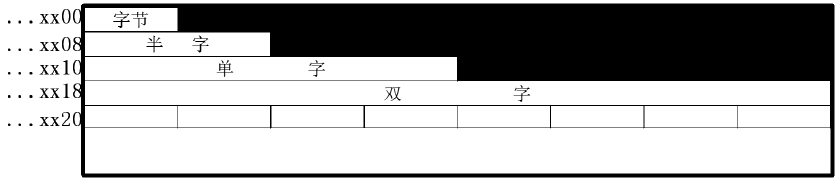
优点:
- 无论访问何种类型的数据,在一个周期内 均可完成,读写控制简单。
缺点:
- 浪费了宝贵的存储资源(图片中的黑色部分都是浪费的资源)
有没有一种方式保证任意一种类型都能在一个存储周期中访问且浪费空间较少?
(3) 边界对准方式——从地址的整数倍位置开始访问
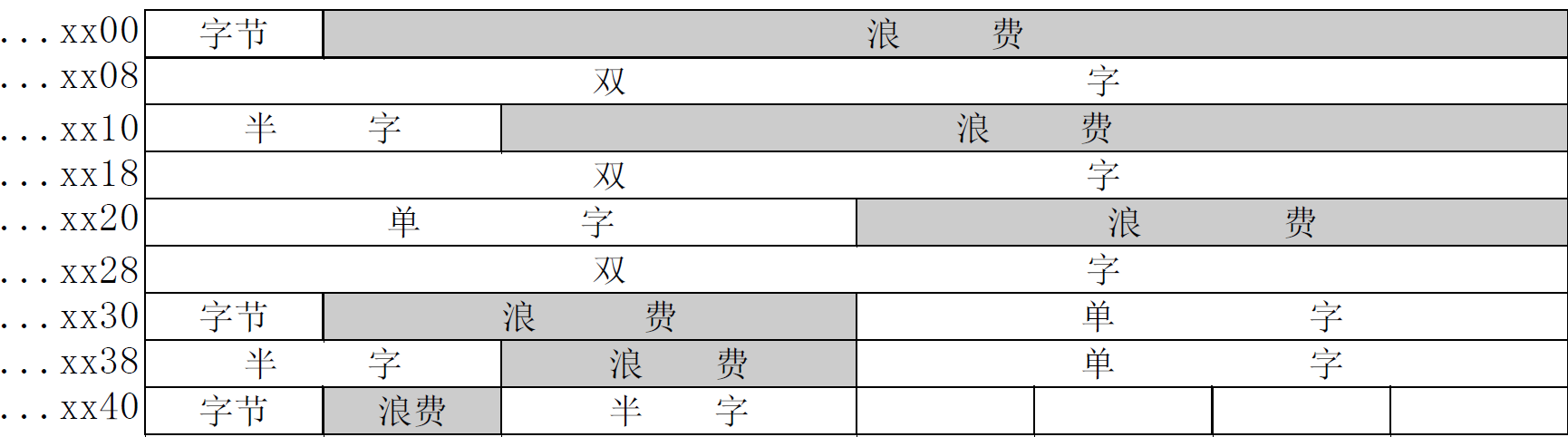
-
数据存放的起始地址是数据长度(按照编址单位进行计算)的整数倍
数据类型 字节数 起始地址 字节 1个字节 1的倍数 半字 2个字节 2的倍数 单字 4个字节 4的倍数 双字 8个字节 8的倍数 这样就可以保证每个数据类型可以完整的存到一个存储字中,一个存储周期就能访问完成
-
本方案是前两个方案的折衷,在一个周期内可以完成存储访问,空间浪费也不太严重。
7.2.3. 操作类型
老师假设已经学过汇编语言,在此基础上讲的
(1) 数据传送
| 源 | 目的 | 指令 |
|---|---|---|
| 寄存器 | 寄存器 | MOVE |
| 寄存器 | 存储器 | STORE,MOVE,PUSH(push压栈操作,栈就是存储器) |
| 存储器 | 寄存器 | LOAD,MOVE,POP(pop出栈就是从栈中取出来) |
| 存储器 | 存储器 | MOVE |
| 存储器/寄存器 | 无 | 置“1”,清“0” |
(2) 算术逻辑操作
加、减、乘、除、增 1、减 1、求补、浮点运算、十进制运算、与、或、非、异或、位操作、位测试、位清除、位求反
如8086:
ADD SUB MUL DIV INC DEC CMP NEG
AAA AAS AAM AAD
AND OR 7T XOR TEST
(3) 移位操作
- 算术移位
- 逻辑移位
- 循环移位(分带进位和不带进位的)
(4) 转移操作
① 无条件转移
JMP:就是直接进行跳转
② 条件转移
| 转移的情况 | 相关寄存器的值 | 指令 |
|---|---|---|
| 结果为0转 | Z = 1 | JZ |
| 结果溢出转 | O = 1 | JO |
| 结果有进位转 | C = 1(我们之前运算器中的进位都是C表示的) | JC |
| 跳过一条指令 | 这个看情况 |
SKP |
③ 调用和返回
就是指调用子程序,子程序结束后返回源程序
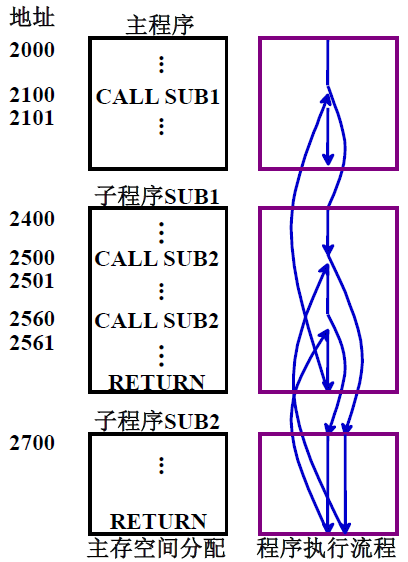
④ 陷阱(Trap)与陷阱指令
a. 陷阱
就是指在一条指令执行的过程中,指令本身出现的非法情况,比如:
- 操作数越界
- 操作数非法
- 除法除数为0
相当于java的异常,这个就是陷阱
b. 陷阱指令
意外事故的中断,就是处理陷阱的指令
-
一般不提供给用户直接使用,在出现事故时,由 CPU 自动产生并执行(隐指令,就是硬件自动执行的,不提供指令给用户)
-
也有一些系统中会提供一些指令给用户,
设置供用户使用的陷阱指令
如 8086 INT TYPE 软中断
提供给用户使用的陷阱指令,完成系统调用
(5) 输入输出
- 并不是每一个指令集中都有输入输出指令
- 如果IO端口的存储空间被作为内存空间的一部分,就不需要输入输出指令,直接访问IO端口的存储空间就可以实现输入输出
- 如果IO端口有单独的地址的话,就有单独的了
-
输入:端口中的内容 ——> CPU 的寄存器
如 IN AK, n;IN AK,DX
-
输出:CPU的寄存器 ——> 端口中的内容
如 OUT n, AK; OUT DX, AK
注意,输入输出都是先存到CPU的寄存器中了,不过之前也学过DMA了
7.3 寻址方式
学习的过程中思考,为什么要在指令中设计多种寻址方式呢?
- 寻址方式:确定 本条指令 的 操作数地址 或者 下一条 要执行 指令 的 指令地址
- 分为 指令的寻址 和 指令当中数据的寻址
7.3.1. 指令寻址
(1) 顺序寻址
( PC ) + 1 ——> PC,这个"1"是看情况的
如果内存中按字节编址
- 如果一个指令是4个字节,那么 +1 相当于 +4
- 如果是8个字节,那么+1相当于+8
- 可变指令中,更加复杂
(2) 跳跃寻址
由转移指令,比如JMP,指出
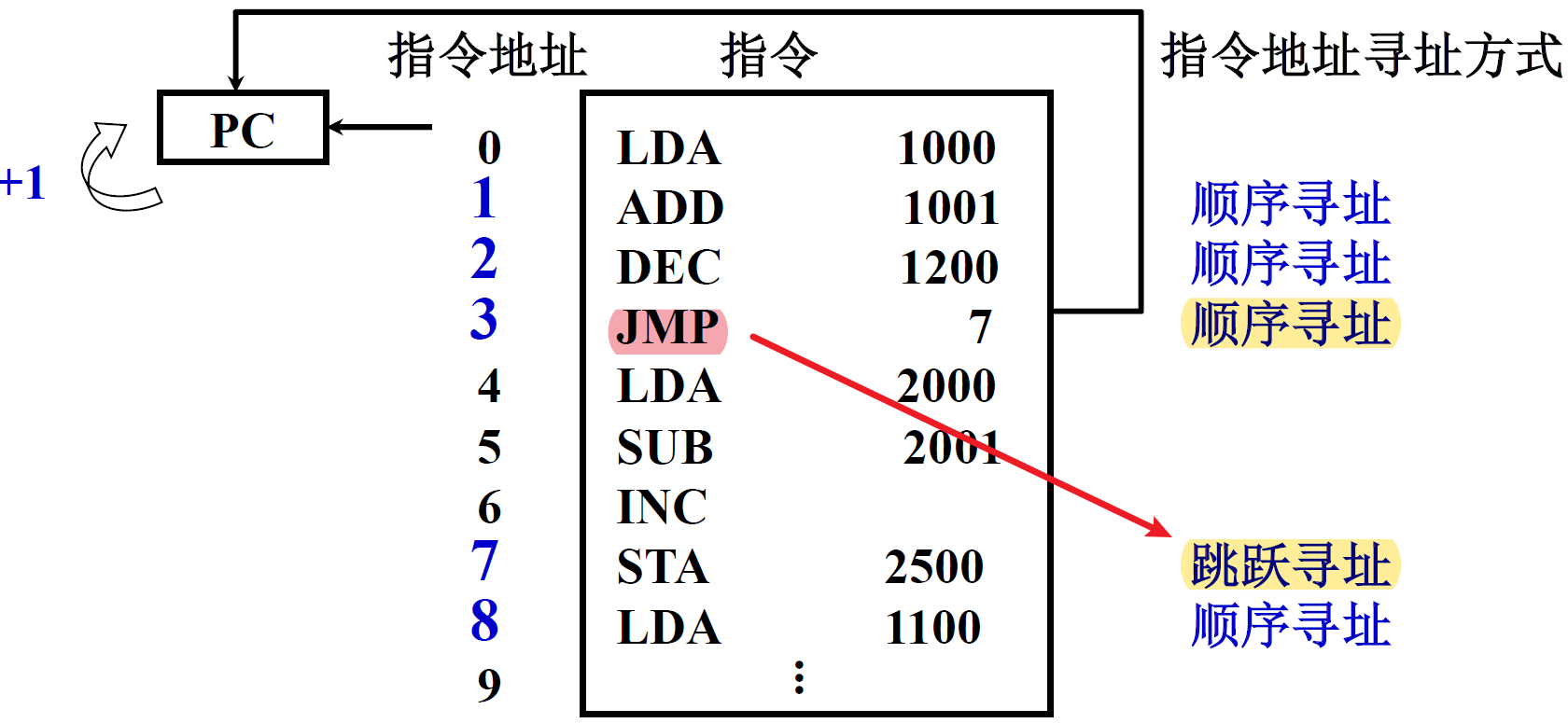
(3) 相对寻址
这个就是数据寻址中的相对寻址,可以看那个
7.3.2. 数据寻址
我们以单地址指令为例,并且咋地址前面给出一个 寻址特征 字段,标识采用什么寻址方式

- 形式地址:指令当中使用到的地址,并不是真实的地址
- 有效地址:寻址特征 + 形式地址进行运算 得到的 操作数的真实地址
我们这里做如下约定(实际上不一定是这样):指令字长 = 存储字长 = 机器字长
(1) 立即(数)寻址
形式地址 A 就是操作数,不是地址了
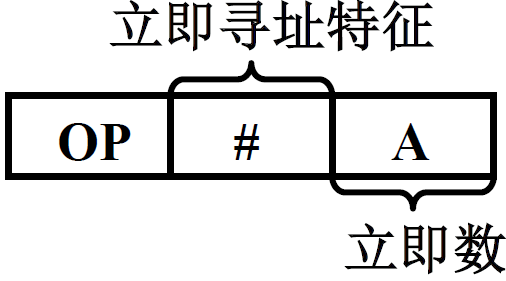
特点
-
指令执行阶段不访存
A就是操作数,操作数在取指的时候已经取出来了
-
A 的位数限制了立即数的范围
具体的长度是通过实验得到的,这是体系结构的知识
(2) 直接寻址
EA = A,有效地址由形式地址直接给出
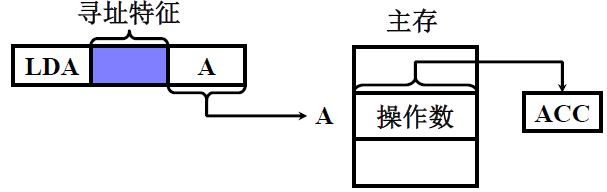
- 这里我们假设LDA的操作是LOAD,将数据从内存中取出到ACC中;
- 操作数只有1位
寻址特征就是蓝色的
特点:
-
执行阶段访问一次存储器
-
A 的位数决定了该指令操作数的寻址范围
-
操作数的地址不易修改(必须修改A)
假如我们要遍历操作一块的数,那么遍历过程中都得修改A
(3) 隐含寻址
操作数地址隐含在操作码中
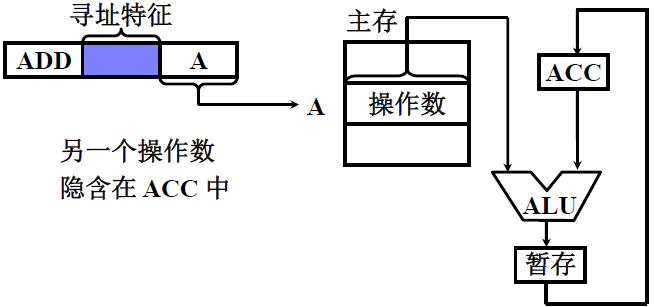
- 这里进行ADD操作
- 寻址特征也是和上面的一样,A = EA,就是直接寻址
- 但是ADD操作涉及到三个数据,两个操作数和一个结果
- 这里只给出了一个地址(整个小节都采用单地址举例)
- 将另一个操作数和结果的地址 都隐含在ACC中,也就是从ACC中取出数据运算后存到ACC中
如8086:
- MUL 指令:被乘数隐含在 AX(16位)或 AL(8位)中
- MOVS 指令:源操作数的地址隐含在 SI 中;目的操作数的地址隐含在 DI 中
特点:
- 指令字中少了一个地址字段,可缩短指令字长
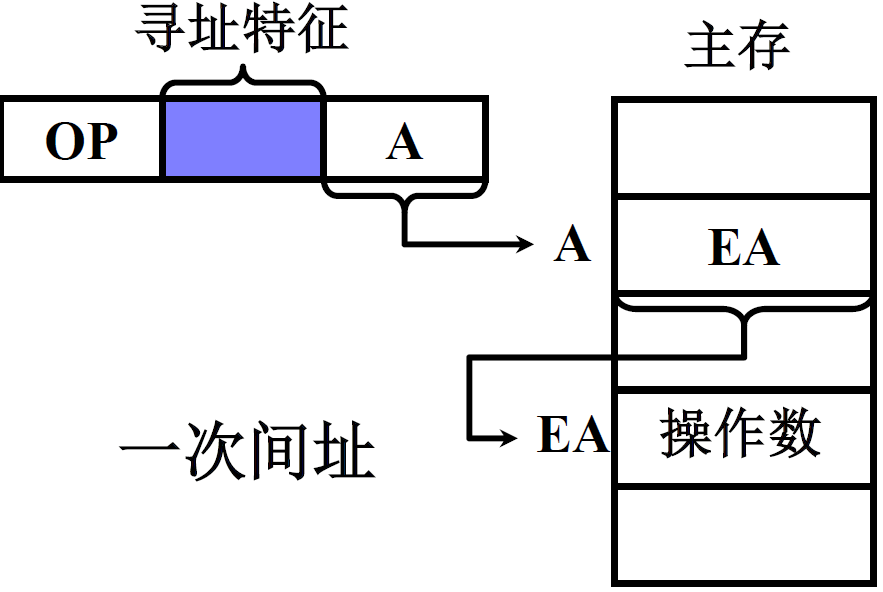
(4) 间接寻址
EA =(A),有效地址由形式地址间接提供,操作数的地址保存在内存单元中
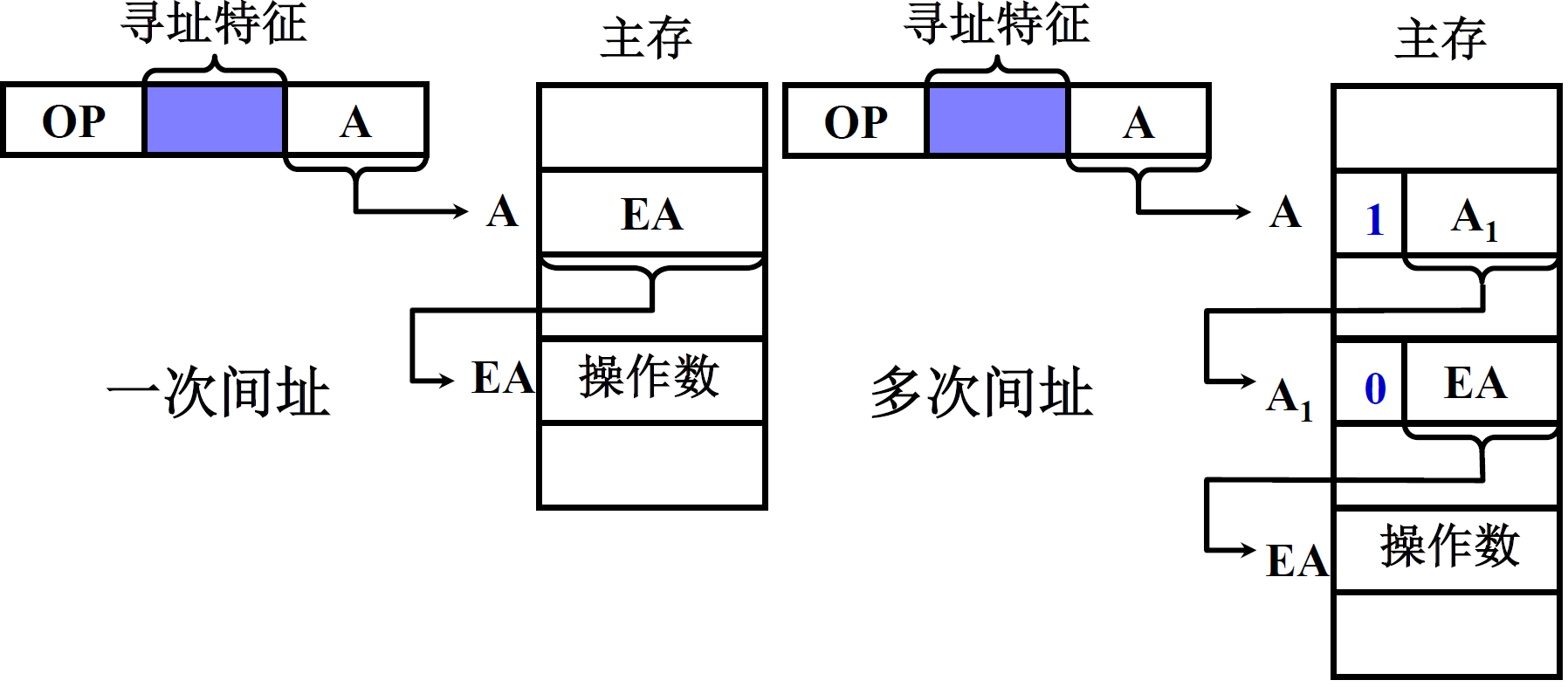
| 一次间址 | 多次间址 |
|---|---|
 |
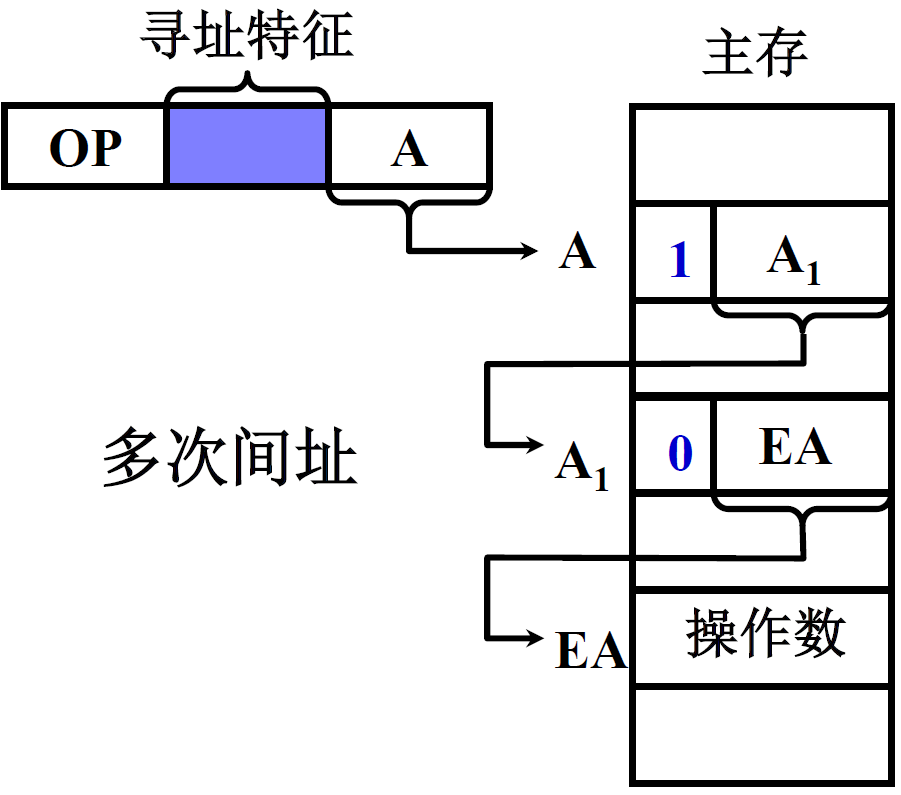 |
特点:
- 执行指令阶段 2 次访存(一次间址)
- 可扩大寻址范围,A虽然不好变,但是EA可以变长
- 便于编制程序
- 多次间址的地址前面都有一个标志位,标志位=0时,说明保存的就是操作数有效地址
- 更加能扩大寻址范围
我们拿一个程序举例子,其中@是间接寻址的特征
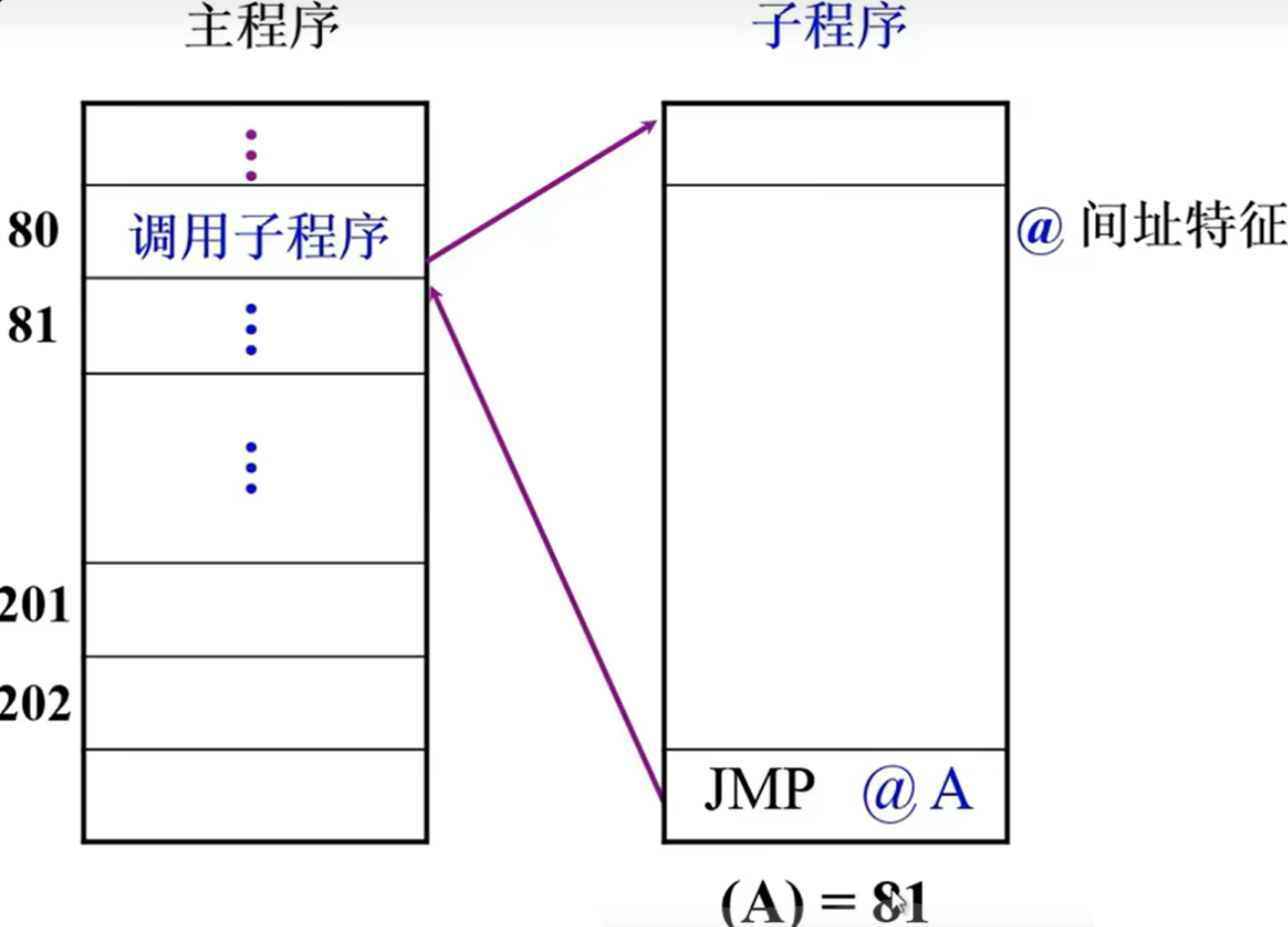
-
80进行跳转
-
81就是断点处
-
将81这个断点保存在(A)处,也就是A这个指向一个地址,这个地址保存着81这个断点
也就是(A)先跳到地址,再跳到81,间接寻址
-
子程序最后 JMP@A,就跳回到81了
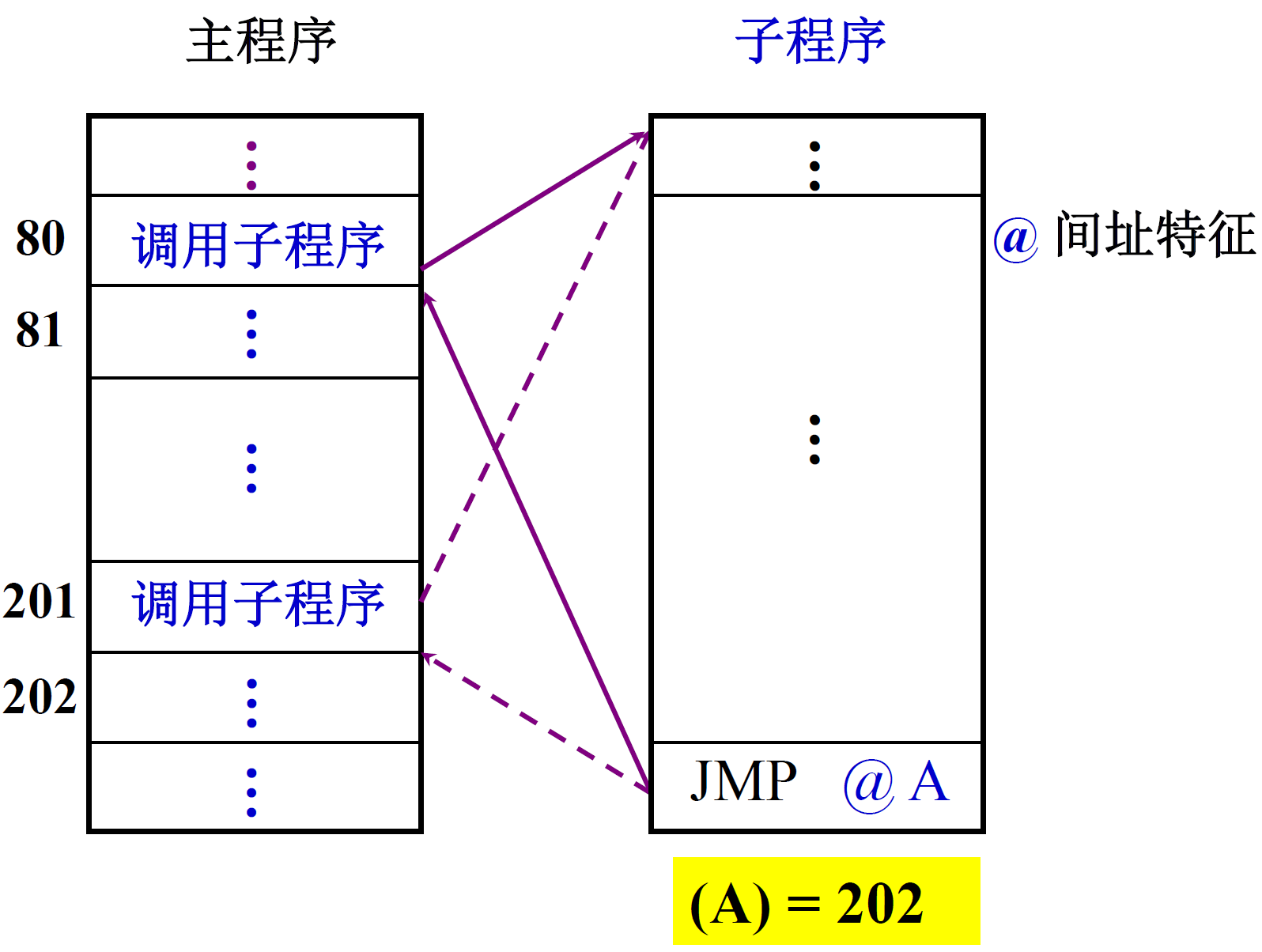
可以看到,间接寻址是可以保存断点的
(5) 寄存器寻址
EA = Ri,有效地址即为寄存器编号,操作数保存在寄存器中
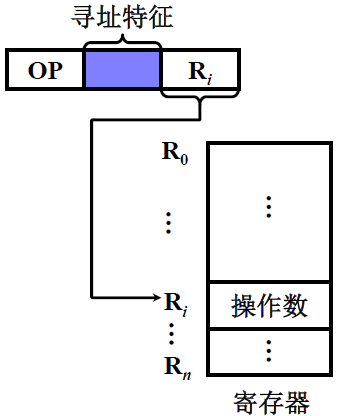
特点:
- 执行阶段不访存,只访问寄存器,执行速度快(因为寄存器的速度很快)
- 寄存器个数有限,可缩短指令字长
(6) 寄存器间接寻址
EA = ( Ri )
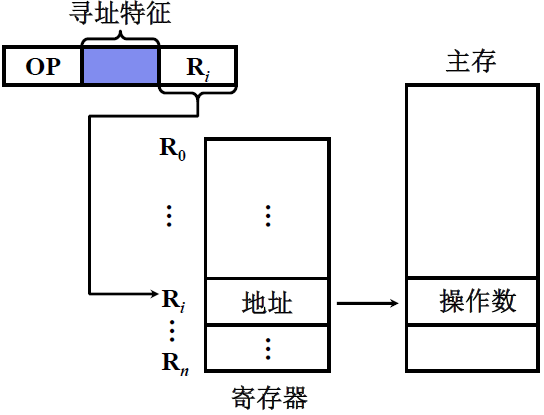
特点:
-
有效地址在寄存器中, 操作数在存储器中,执行阶段访存
-
便于编制循环程序
如果要修改操作数的地址,只需要修改寄存器的内容即可,不需要修改指令
(7) 基址寻址
① 采用专用寄存器作基址寄存器
就是在CPU中设置专用的寄存器作为基址寄存器
有效地址 = 基址寄存器中的内容 + 形式地址
EA = ( BR ) + A,BR 为基址寄存器
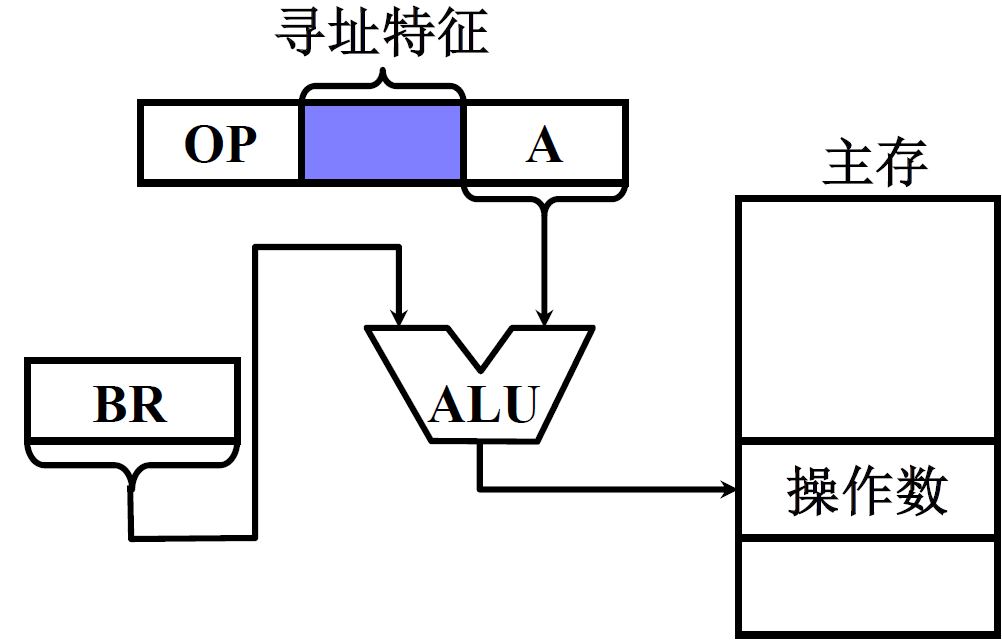
特点:
-
可扩大寻址范围
BR是基址,给出了寻址的起点,这个可以设置的很大;A是偏移量
-
有利于多道程序
多道程序,分时执行的时候,程序的起始地址可以放到BR当中;
在执行过程中,动态形成操作数的地址,就是通过改变BR来改变程序的选择;
在体系结构中,这种方式叫做动态定位
一般基址寻址也就是用于多道程序
-
BR 内容由操作系统或管理程序确定
用户不能修改
-
在程序的执行过程中 BR 内容不变,形式地址 A 可变
② 采用通用寄存器作基址寄存器
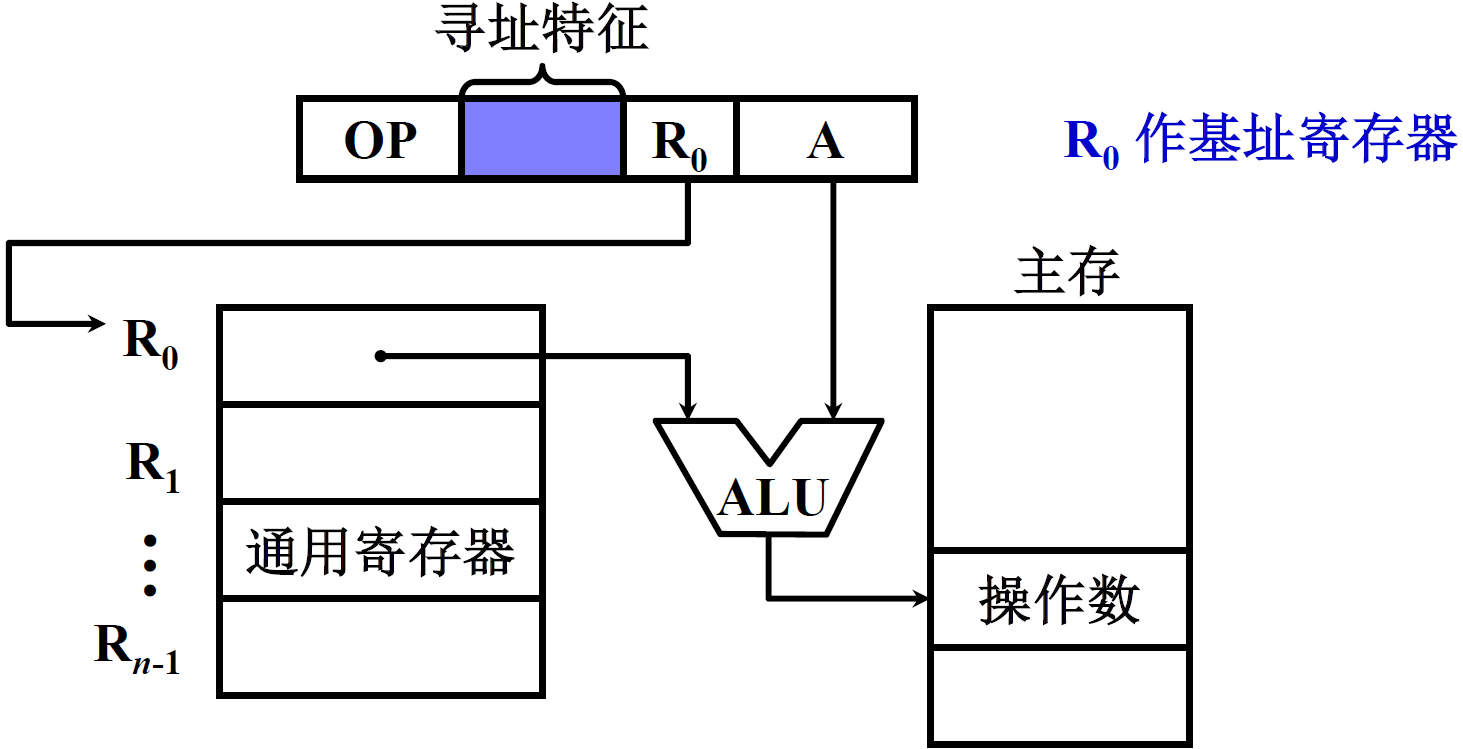
- 由用户指定哪个通用寄存器作为基址寄存器
- 基址寄存器的内容由操作系统确定
- 在程序的执行过程中 R0 内容不变,形式地址 A 可变
(8) 变址寻址
EA = ( IX ) +A
- IX 为变址寄存器(专用)
- 通用寄存器也可以作为变址寄存器
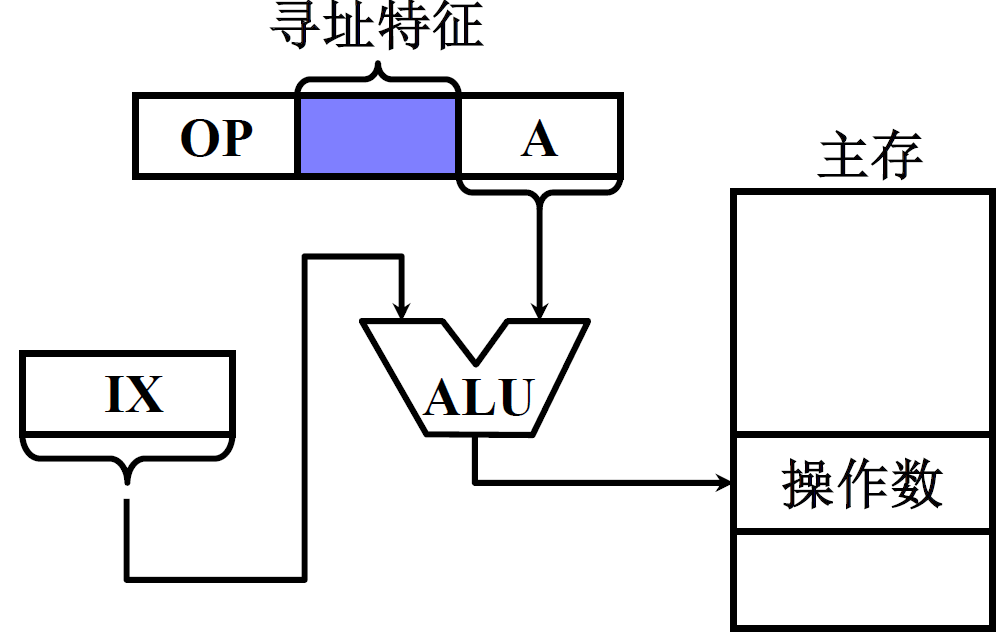
特点:
- 可扩大寻址范围;IX是可以修改的
- IX 的内容由用户给定
- 在程序的执行过程中 IX 内容可变,形式地址 A 不变
- 便于处理数组问题;A作为数组起始地址,IX作为数组下标
例题
使用变址寻址对数组进行操作
设数据块首地址为 D,求 N 个数的平均值
| 直接寻址 | 变址寻址 |
|---|---|
 |
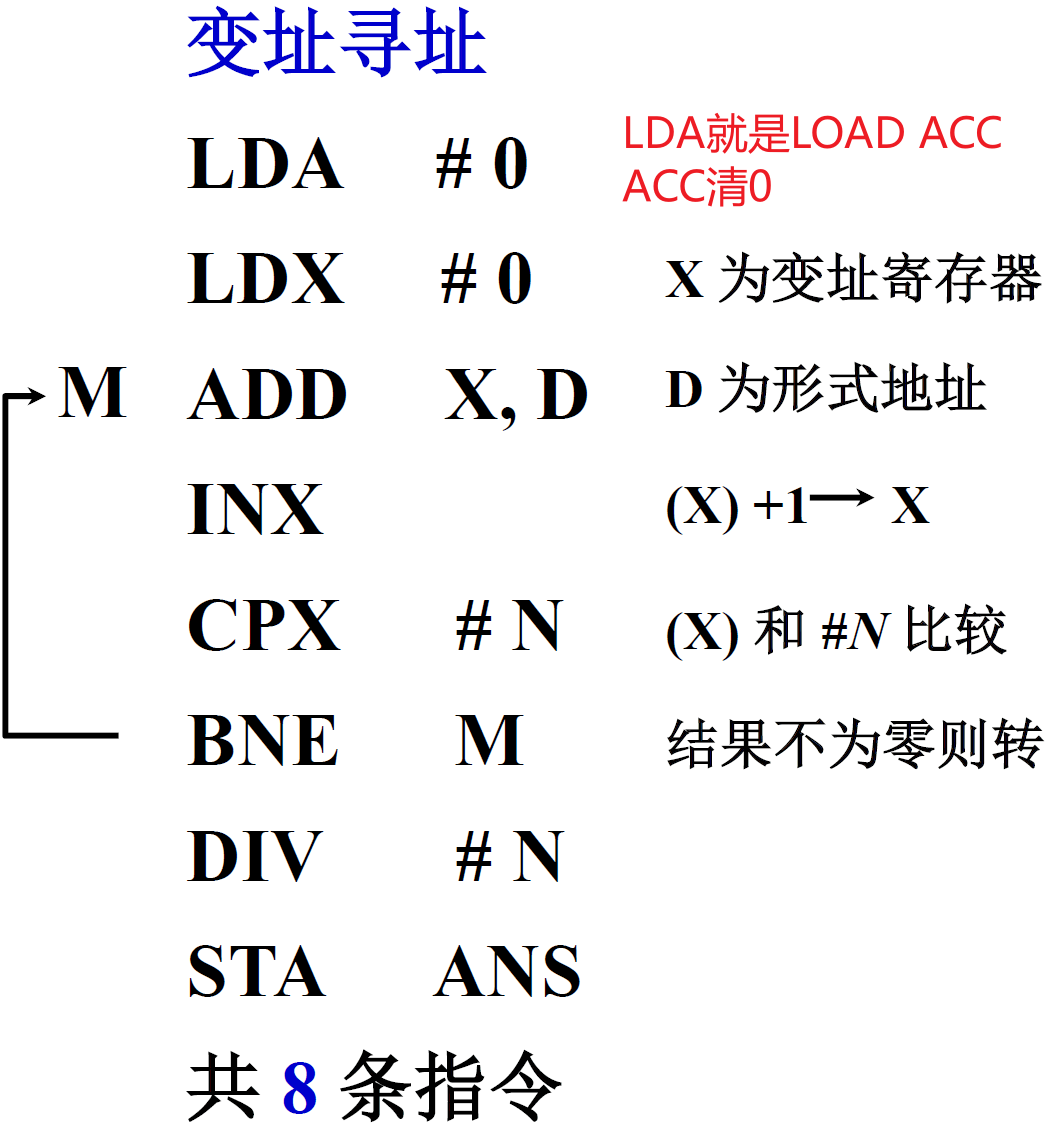 |
汇编语言知识:
LDA 就是 LOAD ACC
LDX 就是 LOAD IX
INX 就是 INCREASE IX
CPX 就是 COMPARE IX
等等,以此类推
变址寻址可以减少代码量,即减少程序在内存中的占有量
(9) 相对寻址
EA = ( PC ) + A,A 是相对于当前指令的位移量(可正可负,用补码表示)
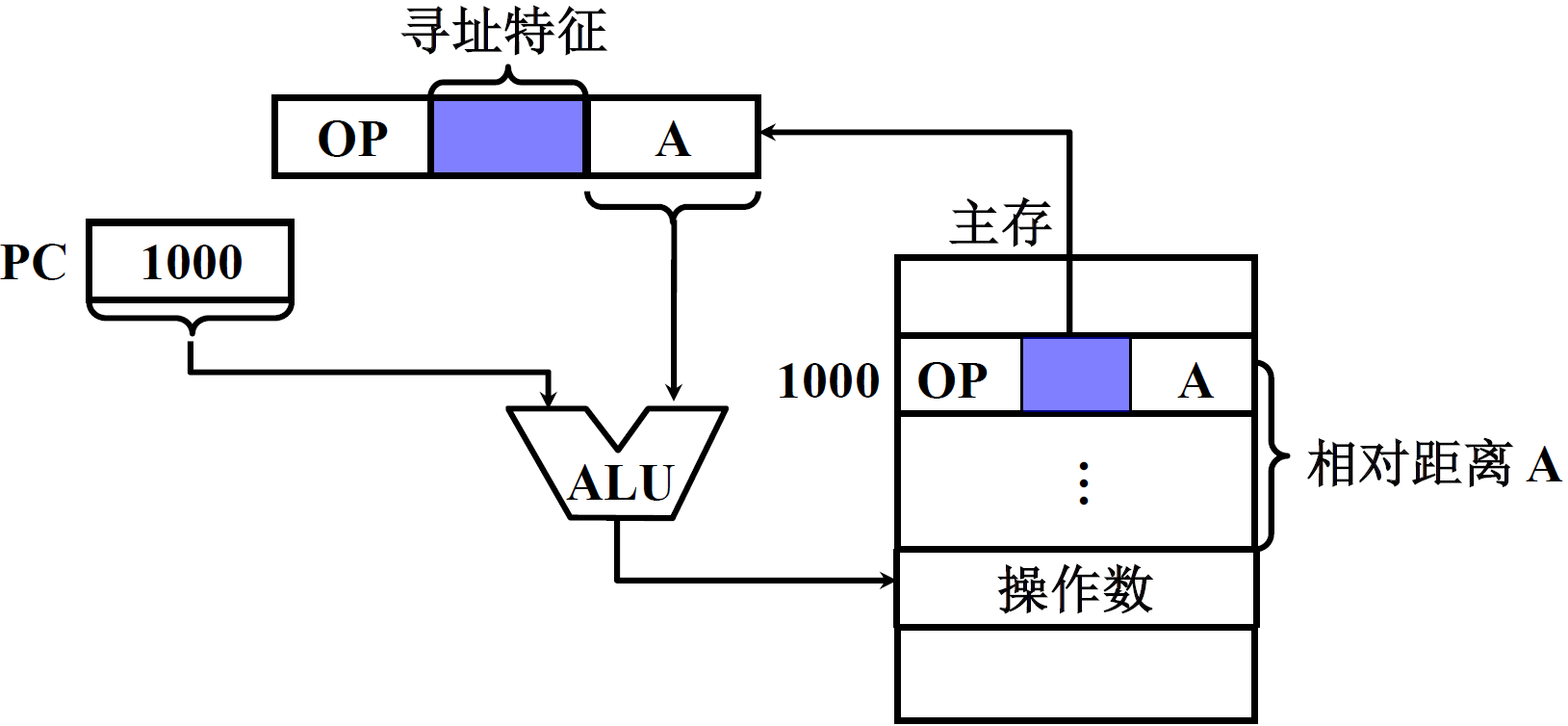
特点:
-
A 的位数决定操作数的寻址范围
-
有利于程序浮动;
程序浮动是指程序在内存中的地址发生变化,这样就保证程序指令与数据一起移动了
-
广泛用于转移指令
这种寻址方式应当归于指令寻址当中,这个寻找的也可以是指令
例题
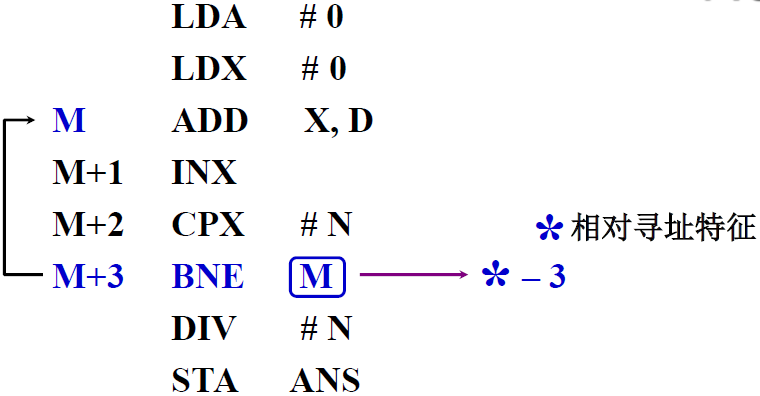
- M 随程序所在存储空间的位置不同而不同
- 而指令 BNE * -3 与 指令 ADD X, D 相对位移量不变(*是相对寻址的特征,*就表示形式地址,是-3)
- 指令 BNE *– 3 操作数的有效地址为 EA = ( M+3 ) – 3 = M
按字节寻址的相对寻址举例
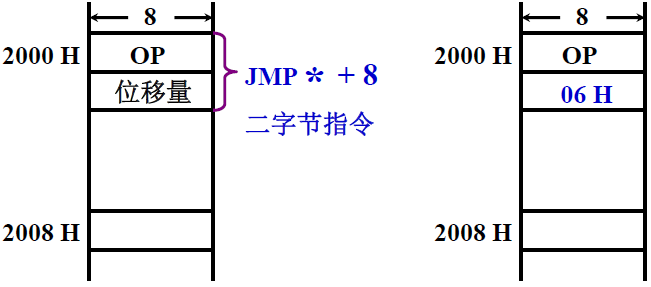
- 设 当前指令地址 PC = 2000H,一个指令是2个字节
- 转移后的目的地址为 2008H
- 因为 取出 JMP * + 8 后 PC = 2002H(取出指令还没有执行的时候,PC已经修改了,(PC) +1 实际上是 PC的值+2了)
- 故 JMP * + 8 指令 的第二字节为 2008H - 2002H = 06H
(10) 堆栈寻址
堆栈分为 硬堆栈 和 软堆栈,堆栈型计算机多采用硬堆栈
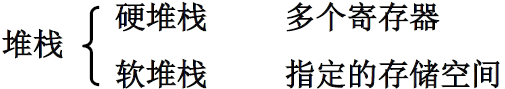
硬堆栈
- 就是有两个或者多个寄存器作为栈顶
- 两个操作数保存在寄存器中,结果也保存在寄存器中
先进后出(一个入出口)栈顶地址 由 SP(寄存器) 指出
-
通常情况下,栈顶是低地址,栈底是高地址,当存到0的时候就说明满了
往下是增加的方向
| 进栈 | 出栈 |
|---|---|
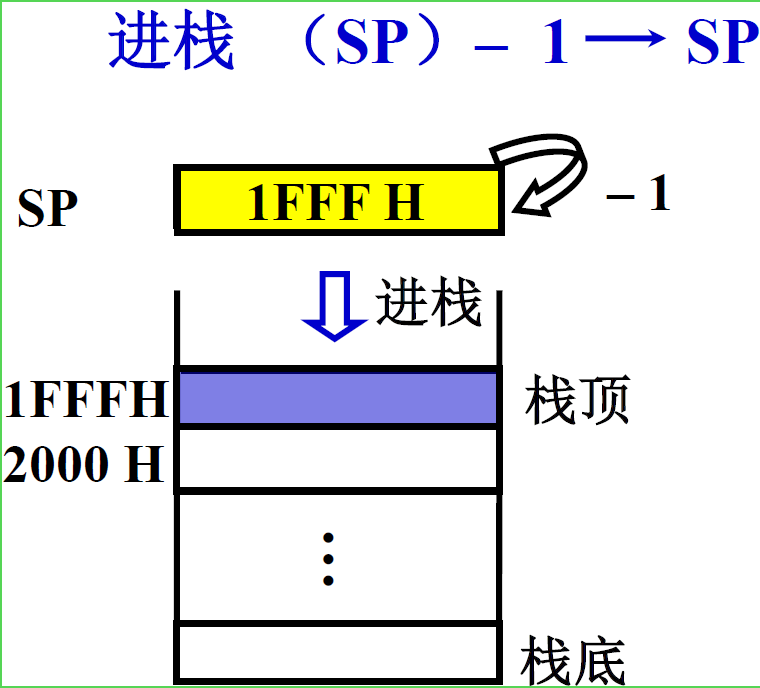 |
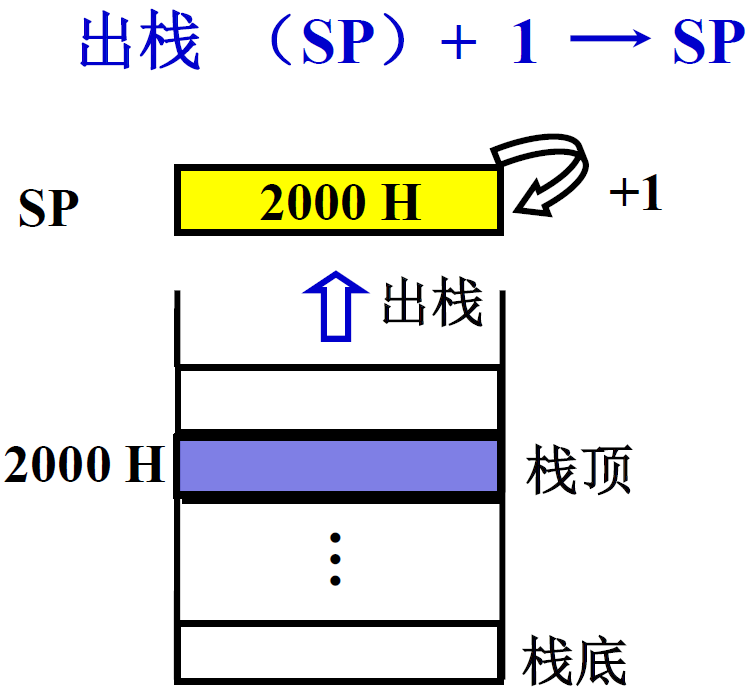 |
这里假设的是一个内容占据一个字节
举例
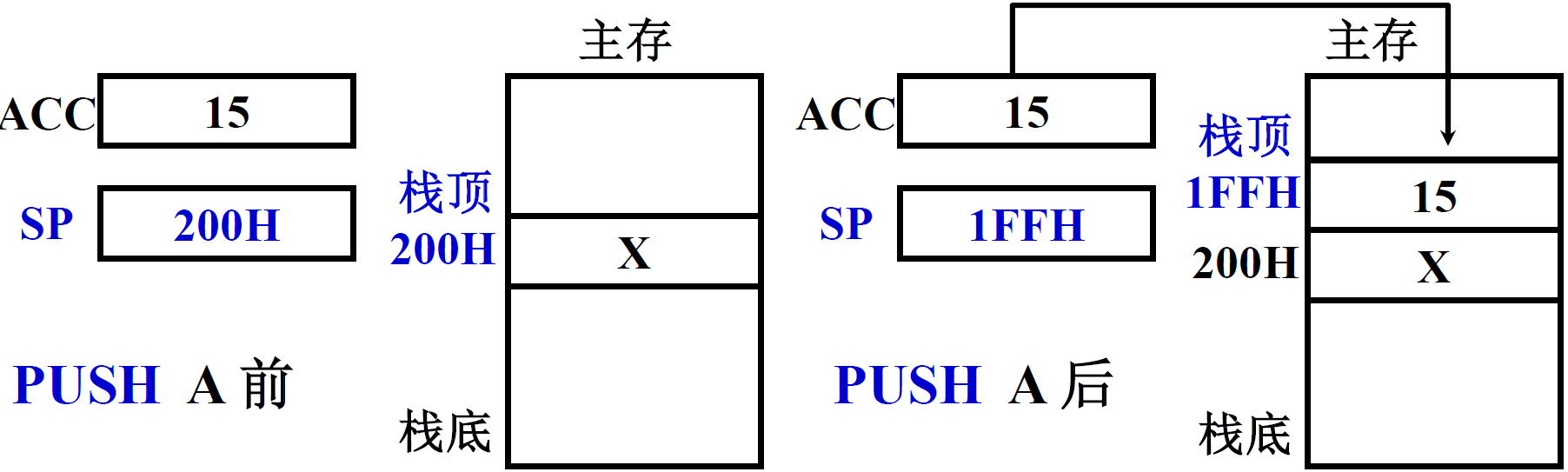
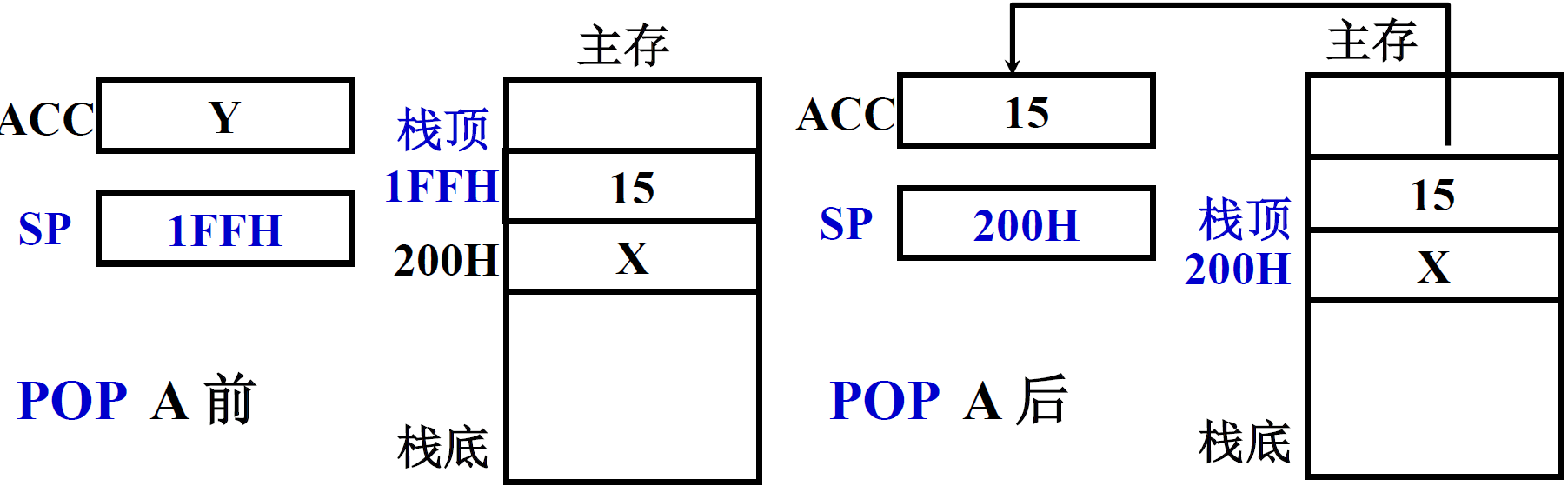
SP 的修改与主存编址方法有关
-
按 字 编址
进栈(SP)– 1 ——> SP
出栈(SP)+ 1 ——> SP -
按 字节 编址
-
存储字长 16 位
进栈(SP)– 2 ——> SP
出栈(SP)+ 2 ——> SP -
存储字长 32 位
进栈(SP)– 4 ——> SP
出栈(SP)+ 4 ——> SP
-
总结
自己思考一下
- 为什么要这么多的寻址方式
- 每种方式适用于哪些地方,操作数地址都在哪,特点是啥
7.4 指令格式举例
以 IBM360 和 Intel×86 为例子举例
7.4.1. 设计指令格式时应考虑的各种因素
这里只是简要说明了要考虑的因素,具体如何设计是体系结构的内容
-
指令系统的 兼容性
一开始的指令集比较少,然后用这些指令集设计了旧的程序
在设计新的指令集的时候,希望旧的程序可以在这个新的指令集的基础上运行
-
其他因素
因素 说明 操作类型 包括指令个数及操作的难易程度 数据类型 确定哪些数据类型可参与操作 指令格式 指令字长是否固定 操作码位数、是否采用扩展操作码技术 地址码位数、地址个数、寻址方式类型 寻址方式 指令寻址、操作数寻址 寄存器个数 寄存器的多少直接影响指令的执行时间
7.4.2. 举例
(1) IBM 360
IBM 360有5种格式的指令
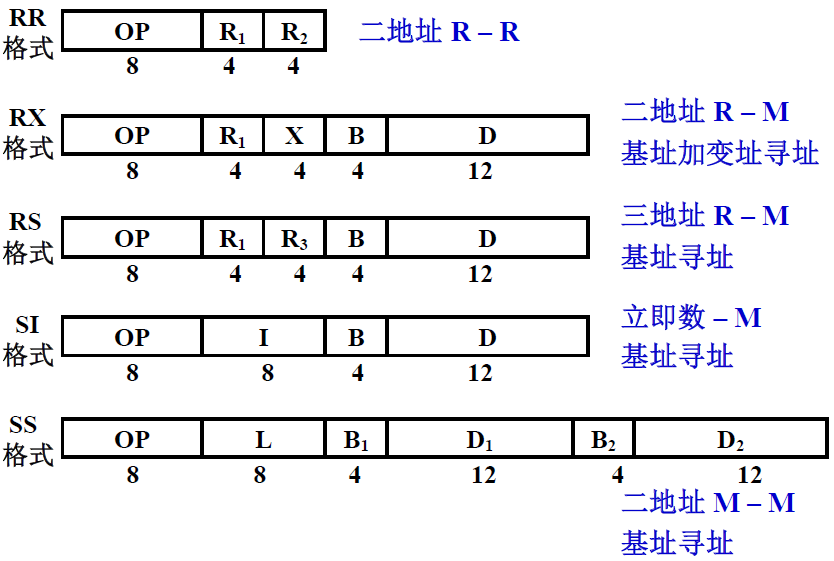
| 格式 | 图解 | 指令长度 | 寻址方式 | 说明 |
|---|---|---|---|---|
| RR格式 |  |
16 | 寄存器寻址 | R1和R2是两个寄存器,两个寄存器参加操作,结果保存在其中一个寄存器 |
| RX格式 |  |
32 | 基址加变址寻址 | X是变址寄存器IX,B是基址寄存器BR,D是偏移地址 Ri有4位—16个寄存器 |
| RS格式 |  |
32 | 基址寻址 | 应用于数据的成组传送 3地址,寄存器和存储器的操作,进行成组的数据传送 |
| SI格式 |  |
32 | ||
| SS格式 |  |
存储器和存储器中的数据进行操作,比如在内存中进行数据传输,比如从B1开始的内存块的内容传送到B2开始的内存块当中 |
(2) Intel 8086
-
指令字长
8086是典型的复杂指令集计算机 有 1~6个字节布丁
INC AX 1 字节
MOV WORD PTR[0204], 0138H 6 字节
-
地址格式
类型 指令 指令字节数 零地址 7P 1 字节 一地址 CALL 段间调用 5 字节 CALL 段内调用 3 字节 二地址 ADD AX,BX 2 字节 寄存器 – 寄存器 ADD AX,3048H 3 字节 寄存器 – 立即数 ADD AX,[3048H] 4 字节 寄存器 – 存储器
7.5 RISC技术
7.5.1. RISC 的产生和发展
- RISC(Reduced Instruction Set Computer)精简指令集计算机
- CISC(Complex Instruction Set Computer)复杂指令集计算机
最早的指令集肯定是精简的,在后来面向高级语言,面向操作系统,设计了复杂的指令集,这些指令集更加复杂,更加庞大,然后人们反思是否指令集越多越大越好
在总结的时候得到的80-20规律
80 — 20 规律
典型程序中 80% 的语句仅仅使用处理机中 20% 的指令
执行频度高的简单指令,因复杂指令的存在,执行速度无法提高
能否用 20% 的简单指令组合不常用的80% 的指令功能?
这就是RISC技术
因此指令集越简单越好
7.5.2. RISC的主要特征
| 特征 | 结果 |
|---|---|
| 选用使用频度较高的一些 简单指令,复杂指令的功能由简单指令来组合 | 控制器设计很简单很快 |
| 指令 长度固定、指令格式种类少、寻址方式少 | 译码简单;如果操作码和操作数的位置固定,在译码的过程中就可以取操作数 |
| 只有 LOAD / STORE 指令访存 | 其他指令进行的操作只能在寄存器和寄存器之间进行,结果只能保存在寄存器中 |
| CPU 中有多个 通用 寄存器(上一点也决定了这个) | |
| 采用 流水技术 一个时钟周期 内完成一条指令 | |
| 采用 组合逻辑 实现控制器 | 用硬件控制指令执行,速度快 |
7.5.3. CISC的主要特征
| 特征 | 结果 |
|---|---|
| 系统指令 复杂庞大,各种指令使用频度相差大 | |
| 指令 长度不固定、指令格式种类多、寻址方式多 | 译码过程复杂,硬件设计也复杂 |
| 访存 指令 不受限制 | |
| CPU 中设有 专用寄存器 | |
| 大多数指令需要 多个时钟周期 执行完毕 | |
| 采用 微程序 控制器 | 指令被分成了若干个微指令,微指令按顺序执行完成这个指令,微指令组成的微程序保存在控制存储器,执行指令的时候多次访问控制存储器,会很慢 |
7.5.4. RISC和CISC的比较
-
RISC更能 充分利用 VLSI 芯片的面积
剩余的芯片可以做存储,提高CPU速度
-
RISC 更能 提高计算机运算速度
指令数、指令格式、寻址方式少;通用 寄存器多,采用 组合逻辑;便于实现 指令流水
-
RISC 便于设计,可 降低成本,提高 可靠性
-
RISC 不易 实现 指令系统兼容
思考:
- 现代计算机使用RISC和CISC的都由,什么情况下使用哪一种?
- RISC和CISC相结合是现在的一个趋势,这是如何结合的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号