操作系统第四章 文件外存管理
操作系统第四章 文件(外存)管理
本章按照分层的结构来讲解文件管理
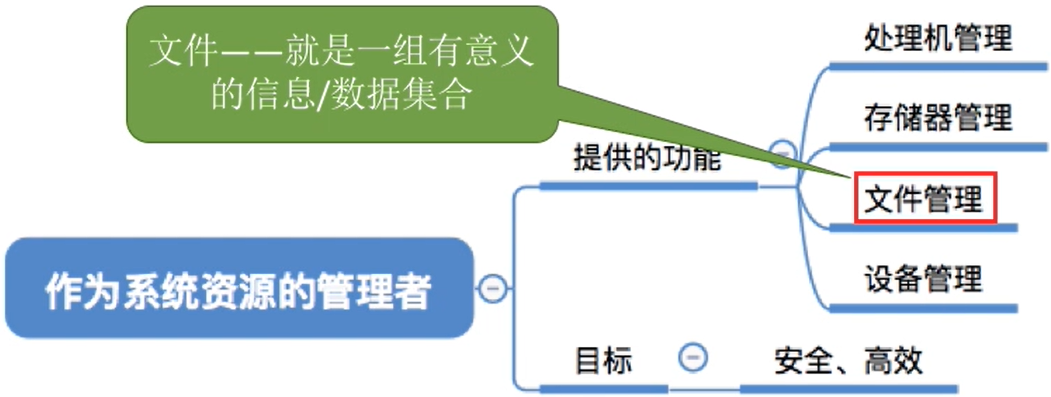
4.1 文件介绍
本节单纯讲述文件,之后开始将文件系统
4.1.1 文件的属性
一个文件有哪些属性?
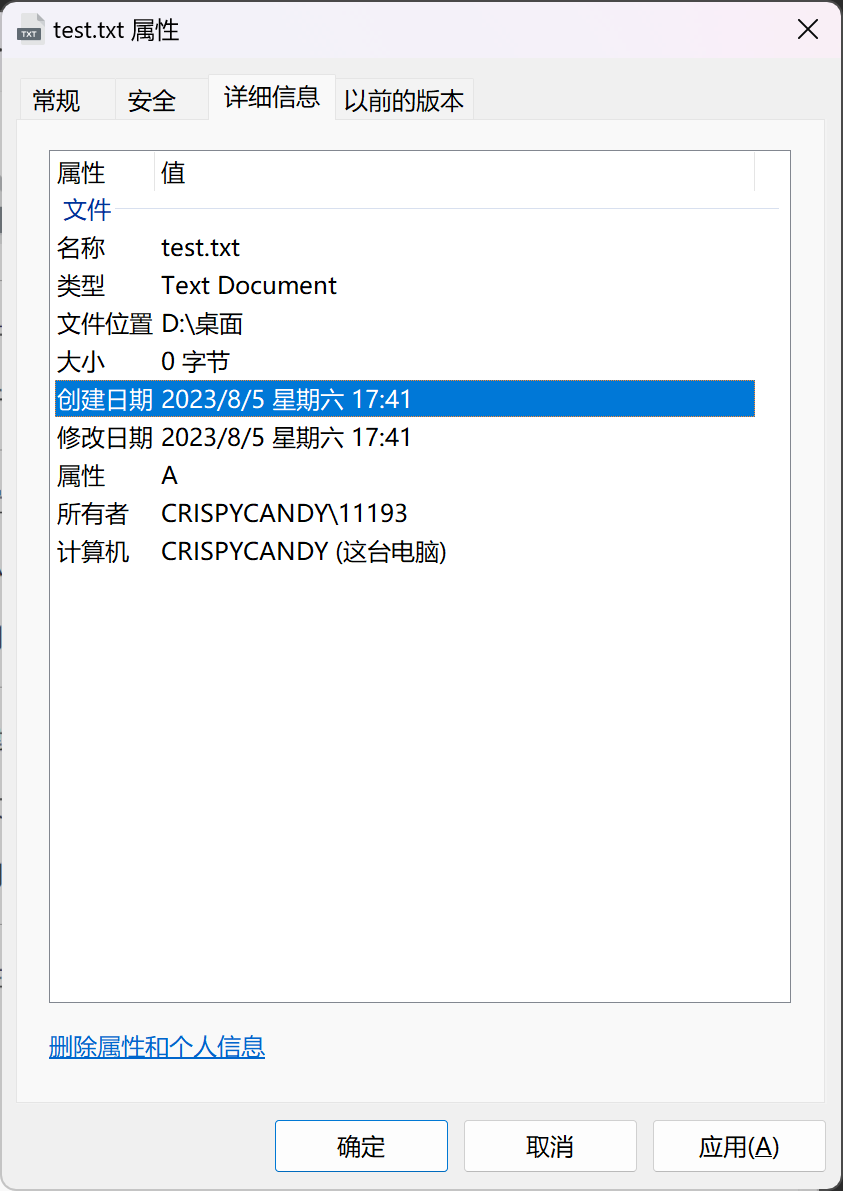
文件名:由创建文件的用户决定文件名,主要是为了方便用户找到文件,同一目录下不允许有重名文件。标识符:一个系统内的各文件标识符唯一,对用户来说毫无可读性,因此标识符只是操作系统用于区分各个文件的一种内部名称。类型:指明文件的类型位置:文件存放的路径(让用户使用)、在外存中的地址(操作系统使用,对用户不可见)大小:指明文件大小创建时间、上次修改时间文件所有者信息保护信息:对文件进行保护的访问控制信息
| 属性 | 安全 | 详细信息 |
|---|---|---|
 |
 |
 |
4.2 用户接口(文件的基本操作)
本节讲解文件系统给用户提供的接口
系统应该提供哪些接口
- 可以“创建文件”,(点击新建后,图形化交互进程在背后调用了“
create系统调用”) - 可以“读文件”,将文件数据读入内存,才能让CPU处理(双击后,“记事本”应用程序通过操作系统提供的“读文件”功能,即read系统调用,将文件数据从外存读入内存,并显示在屏幕上)
- 可以“写文件”,将更改过的文件数据写回外存(我们在“记事本”应用程序中编辑文件内容,点击“保存”后,“记事本”应用程序通过操作系统提供的“写文件”功能,即 write系统调用,将文件数据从内存写回外存)
- 可以“删除文件”(点了“删除”之后,图形化交互进程通过操作系统提供的“删除文件”功能,即delete系统调用,将文件数据从外存中删除)
- 其他操作都可以由这几个操作组合而成,考试中常考的还是这几个操作
- 用户调用的库函数,编译时就会转换成这几个接口
4.2.1 创建文件
可以“创建文件”,(点击新建后,图形化交互进程在背后调用了“create系统调用”)
进行Create系统调用时,需要提供的几个主要参数:
所需的外存空间大小(如:一个盘块,即1KB)文件存放路径(“D:/Demo”)文件名(这个地方默认为“新建文本文档.txt”)
操作系统在处理Create系统调用时,主要做了两件事:
- 在外存中找到文件所需的空间(根据
文件存储空间管理) - 根据文件存放路径的信息找到该目录对应的
目录文件(此处就是D:/Demo目录),在目录中创建该文件对应的目录项。 - 目录项中包含了文件名、文件在外存中的存放位置等信息。
4.2.2 删除文件
可以“删除文件”(点了“删除”之后,图形化交互进程通过操作系统提供的“删除文件”功能,即delete系统调用,将文件数据从外存中删除)
进行Delete系统调用时,需要提供的几个主要参数:
文件存放路径(“D:/Demo”)文件名(“test.txt”)
操作系统在处理Delete系统调用时,主要做了几件事:
- 根据文件存放路径找到相应的
目录文件,从目录中找到文件名对应的目录项。 - 根据该目录项记录的文件在外存的存放位置、文件大小等信息,
回收文件占用的磁盘块。(回收磁盘块时,根据空闲表法、空闲链表法、位图法等管理策略的不同,需要做不同的处理) - 从目录表中
删除文件对应的目录项。
4.2.3 打开文件

在很多操作系统中,在对文件进行操作之前,要求用户先使用open系统调用“打开文件”,需要提供的几个主要参数:
- 文件存放路径(“D:/Demo”)
- 文件名(“test.txt”)
- 要对文件的操作类型(如:r只读,rw读写等)
操作系统在处理open系统调用时,主要做了几件事:
- 根据文件存放路径找到相应的目录文件,从目录中
找到文件名对应的的目录项,并检查该用户是否有指定的操作权限。 - 将
目录项复制到内存中的“打开文件表”中。并将对应表目的编号返回给用户。之后用户使用打开文供表的编号来指明要操作的文件。
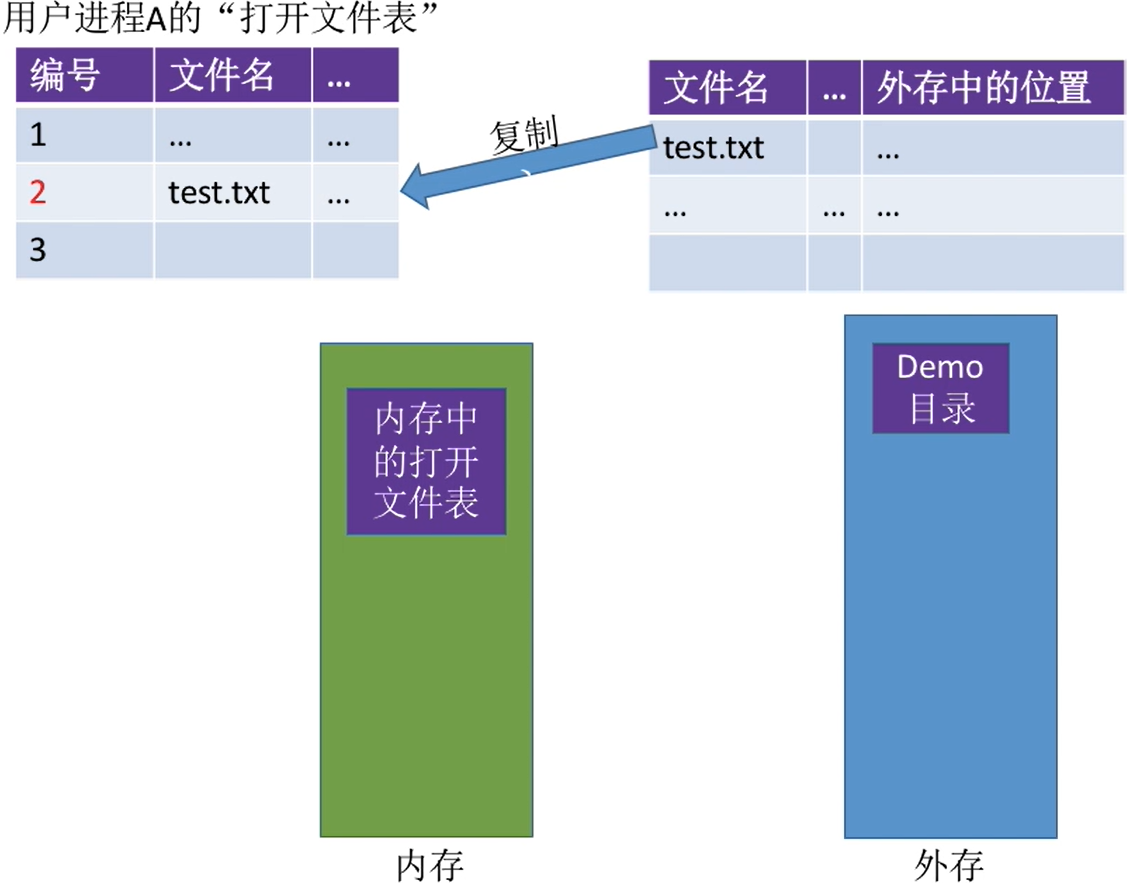
- 有了打开文件表,之后用户进程A再操作文件就不需要每次都重新查目录了,这样可以
加快文件的访问速度
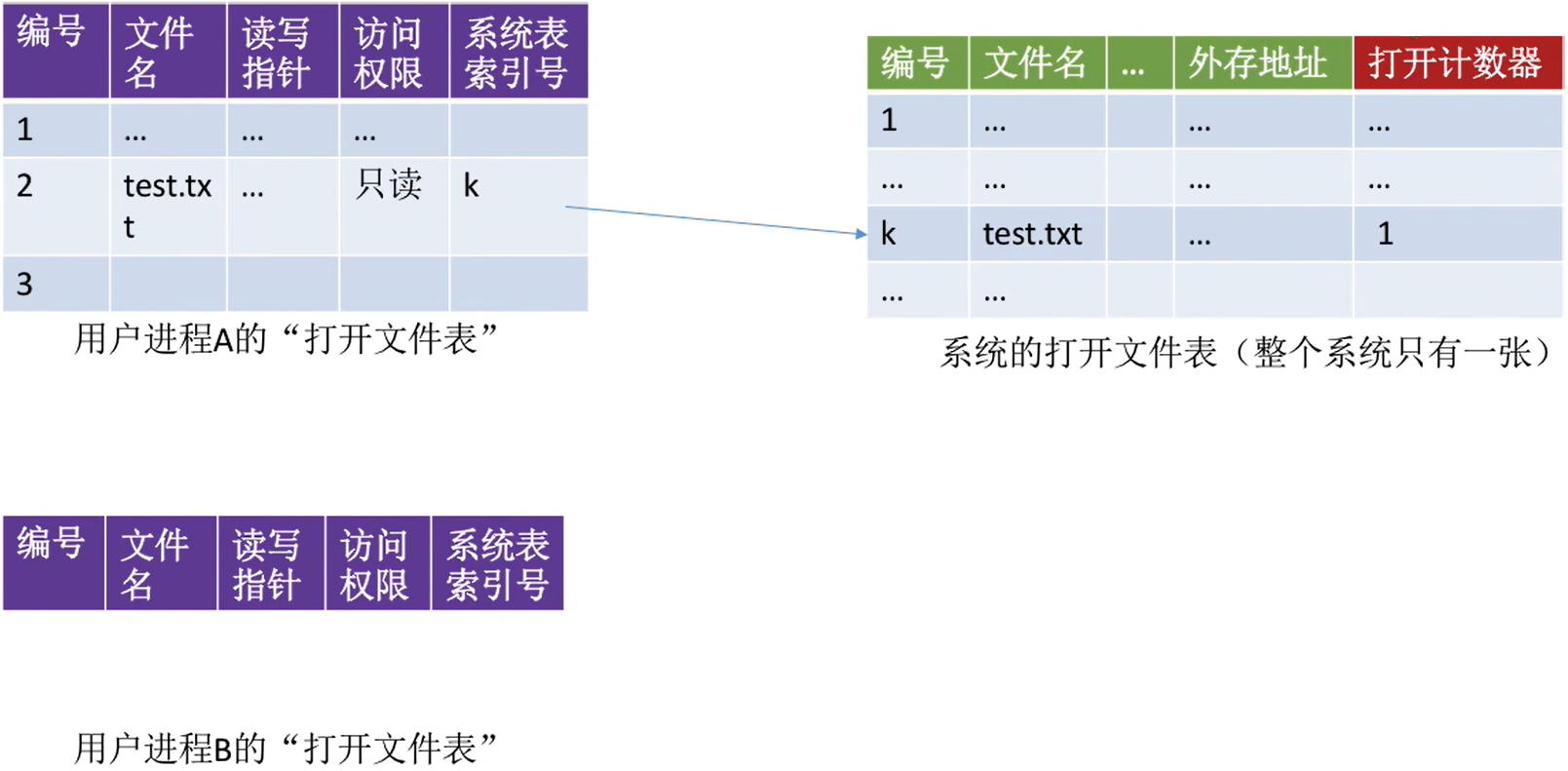
有两种打开文件表,一种是系统的打开文件表,一种是用户的打开文件表,关系如下

-
系统的打开文件表的 打开计数器记录此时有多少个进程打开此文件
-
系统的打开文件表可以方便实现某些文件管理的功能。
例如:在Windows系统中,我们
尝试删除某个txt文件,如果此时该文件已被某个“记事本”进程打开,则系统会提示我们“暂时无法删除该文件”。其实系统在背后做的事就是先检查了系统打开文件表,确认此时是否有进程正在使用该文件。
用户的打开文件表记录着各自用户对文件的相关信息
- 读写指针记录该进程的度/写操作进行到的位置
- 访问权限:如果打开文件时声明的是“只读”,则该进程不能对文件进行写操作
这些都是每个进程各自拥有的数据,因此分开存放
4.2.4 关闭文件
进程使用完文件后,要“关闭文件”
操作系统在处理Close系统调用时,主要做了几件事
- 将进程的打开文件表相应表项删除
- 回收分配给该文件的内存空间等资源
- 系统
打开文件表的打开计数器count减1,若count =0,则删除对应表项。
| 关闭前 | 关闭后 |
|---|---|
|
 |
4.2.5 读文件
可以“读文件”,将文件数据读入内存,才能让CPU处理
用记事本打开文件:“记事本”应用程序通过操作系统提供的“读文件”功能,即read系统调用,将文件数据从外存读入内存,并显示在屏幕上
从这里可以看出,打开文件仅仅是操作了打开文件表,但是文件此时并没有读入到内存中呢
记事本打开文件应该是 打开文件后 又 读了文件

进程使用read系统调用完成写操作。
参数:
- 需要指明是哪个文件(在支持“
打开文件”操作的系统中,只需要提供文件在打开文件表中的索引号即可) - 还需要
指明要读入多少数据(如:读入1KB) - 指明读入的数据要放在内存中的什么位置。
操作系统在处理read系统调用时
- 会从读指针指向的外存中,将用户指定大小的数据读入用户指定的内存区域中。
这些都是记事本在背后帮忙做的事情
4.2.6 写文件
进程使用write系统调用完成写操作
参数:
- 需要指明是哪个文件(在支持“打开文件”操作的系统中,只需要提供文件在打开文件表中的索引号即可)
- 还需要指明要写出多少数据(如:写出1KB)
- 写回外存的数据放在内存中的什么位置
操作系统在处理write系统调用时,会从用户指定的内存区域中,将指定大小的数据写回写指针指向的外存。
读文件和写文件选择题中常考
4.3 文件目录系统(文件的管理)
 |
 |
|---|
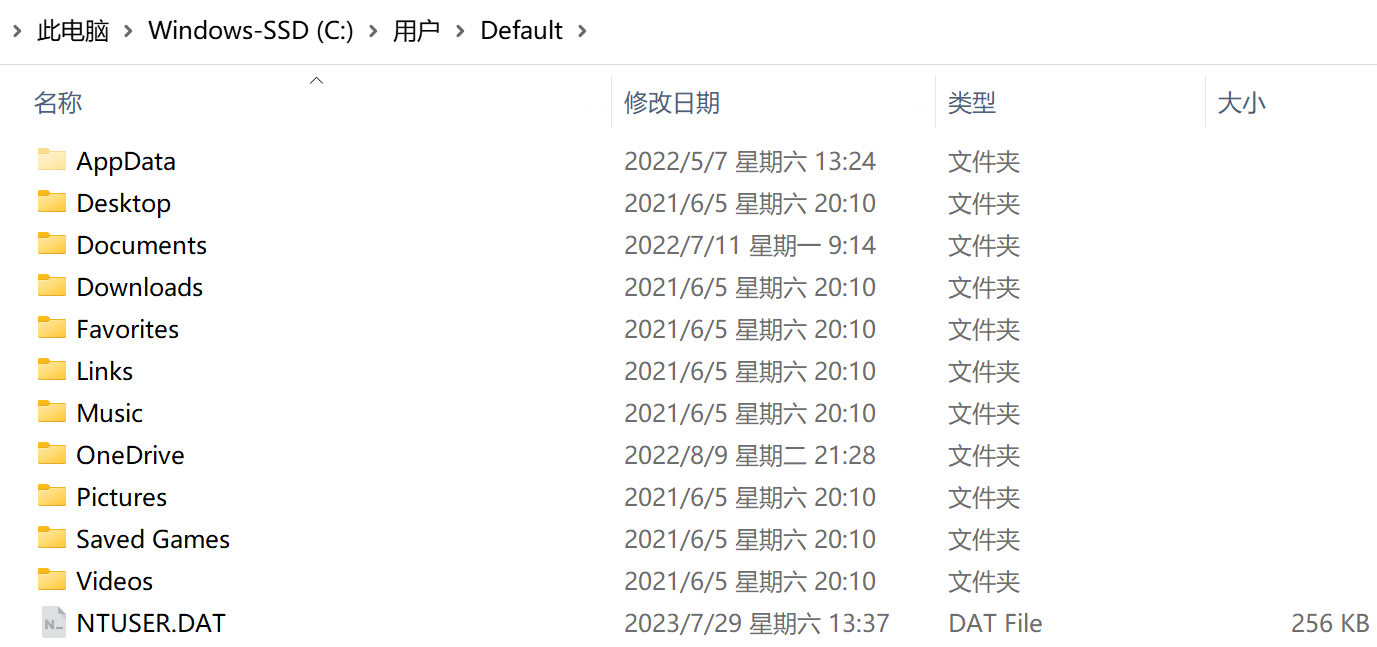
- 所谓的“目录”其实就是我们熟悉的“文件夹”
- 用户可以自己创建一层一层的目录,各层目录中存放相应的文件。系统中的各个文件就通过一层一层的目录合理有序的组织起来了
- 目录其实也是一种特殊的有结构文件(由记录组成),如何实现文件目录是本节会重点探讨的问题
这种目录结构对于用户来说有什么好处?
- 文件之间的
组织结构清晰,易于查找 编程时也可以很方便的用文件路径找到一个文件。用户可以轻松实现“按名存取”。如:
FILE *fp;
fp=fopen("F:\data\myfile.dat");
- 从操作系统的角度来看,这些
目录结构应该是如何实现的?
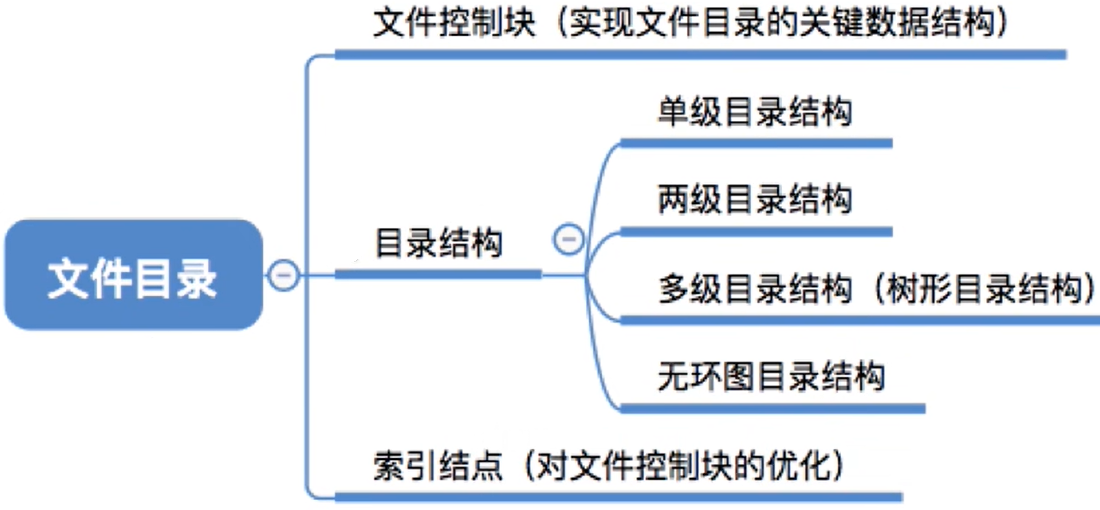
4.3.1 文件控制块
(1) 文件目录和FCB
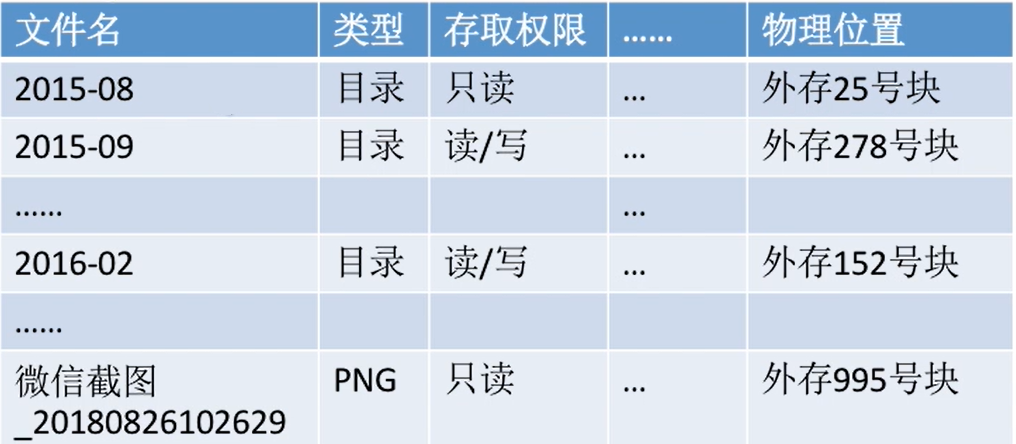
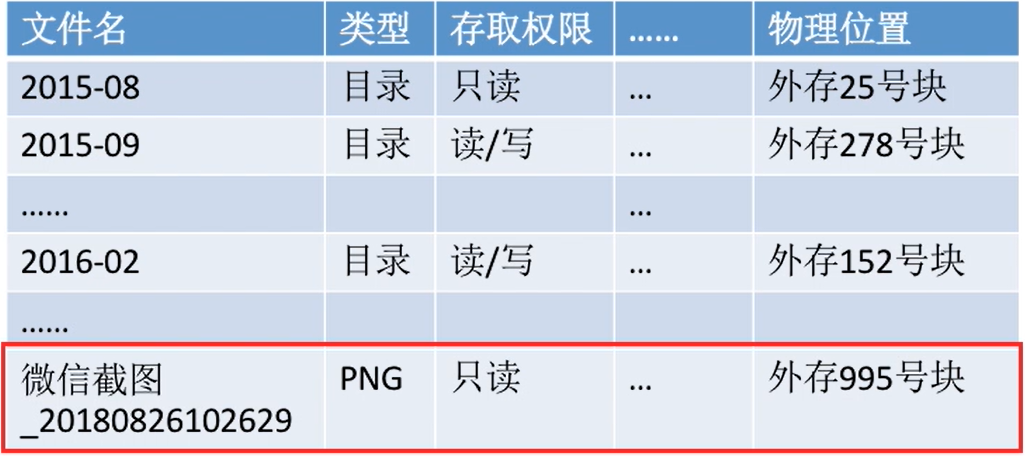
对于D盘直接的目录,有如下的文件目录
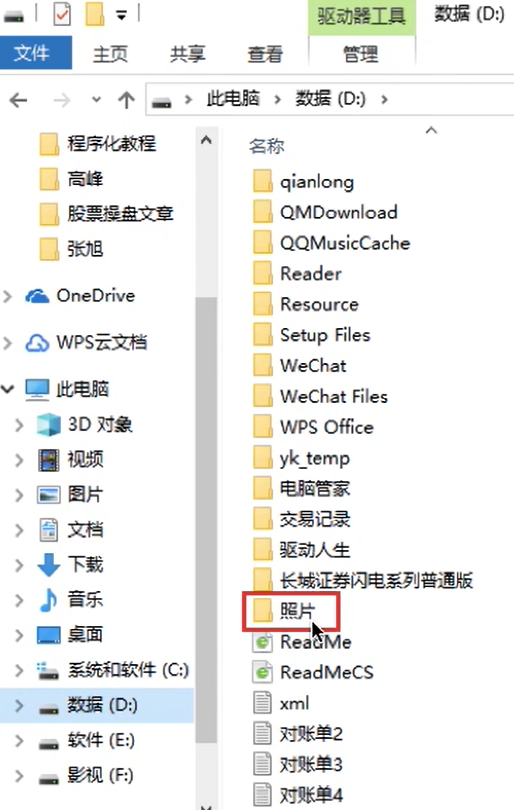
| 文件名 | 类型 | 存取权限 | ... | 物理位置 |
|---|---|---|---|---|
| qianlong | 目录 | 只读 | 外存7号块 | |
| QMDownLoad | 目录 | 读/写 | 外存18号块 | |
| ...... | ||||
| 照片 | 目录 | 读/写 | 外存643号块 | |
| ...... | ||||
| 对账单4.txt | txt | 只读 | 外存324号块 |
目录本身就是一种有结构文件,由一条条记录组成。每条记录对应一个在该放在该目录下的文件;所以父目录下的子目录也会作为文件在父目录的目录文件当中- 一个目录里面的文件管理就是通过这样的文件列表实现的
- 每个文件项都记录着类型,存取权限,还有
物理位置 - (这个物理位置不一定是这样的,可能会有其他的存储形式,而且也不一定是一列)
- 当我们双击目录“照片”后,操作系统会
在这个目录表中找到关键字“照片”对应的目录项(也就是记录),然后从外存中将“照片”目录的信息读入内存,于是,“照片”目录中的内容就可以显示出来了。
| 照片目录 | 对应的目录文件 |
|---|---|
 |
 |
- 目录文件中的一条记录就是一个“文件控制块FCB(上表中的每一项就是一个FCB)
- FCB的
有序集合称为“文件目录”,一个FCB就是一个文件目录项。 - FCB中包含了文件的
基本信息(文件名、物理地址、逻辑结构、物理结构等),存取控制信息(是否可读/可写、禁止访问的用户名单等),使用信息(如文件的建立时间、修改时间等)。 - 最重要,
最基本的还是文件名、文件存放的物理地址。
FCB 实现了
文件名和文件之间的映射。使用户(用户程序)可以实现“按名存取”(这应该是最主要的功能)
(2) 对目录的操作
需要对目录进行哪些操作?
搜索:当用户要使用一个文件时,系统要根据文件名搜索目录,找到该文件对应的目录项创建文件:创建一个新文件时,需要在其所属的目录中增加一个目录项删除文件:当删除一个文件时,需要在目录中删除相应的目录项显示目录:用户可以请求显示目录的内容,如显示该目录中的所有文件及相应属性修改目录:某些文件属性保存在目录中,因此这些属性变化时需要修改相应的目录项(如:文件重命名)
4.3.2 目录结构
(1) 单级目录结构
早期操作系统并不支持多级目录,整个系统中只建立一张目录表,每个文件占一个目录项。

- 单级目录实现了“按名存取”,但是
不允许文件重名。 - 在创建一个文件时,需要先
检查目录表中有没有重名文件,确定不重名后才能允许建立文件,并将新文件对应的目录项插入目录表中。 - 显然,
单级目录结构不适用于多用户操作系统。
(2) 两级目录结构
早期的多用户操作系统,采用两级目录结构。分为主文件目录(MFD,Master File Directory)和用户文件目录(UFD,User Flie Directory) 。
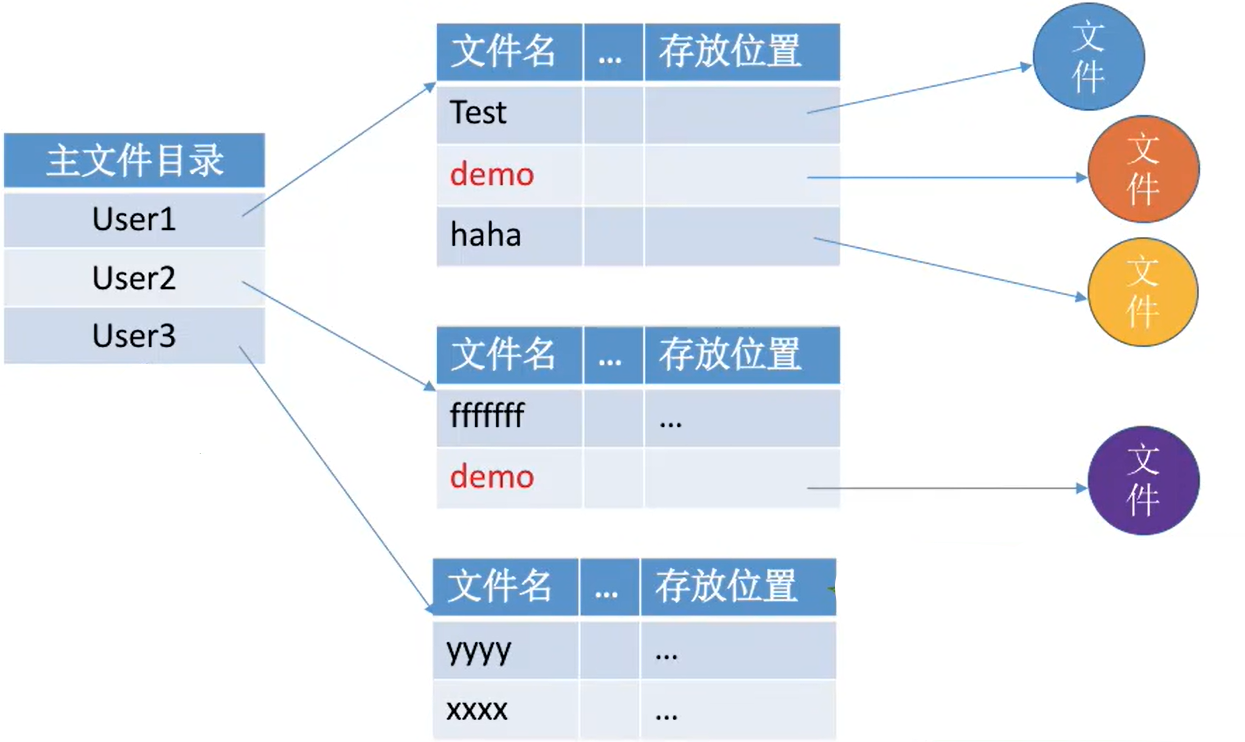
主文件目录记录用户名及相应用户文件目录的存放位置;用户文件目录由该用户的文件FCB组成- 允许
不同用户的文件重名。文件名虽然相同,但是对应的其实是不同的文件
这类似于linux的home目录,一个用户有一个目录
- 两级目录结构允许不同用户的文件重名,也可以在目录上实现实现访问限制(检查此时登录的用户名是否匹配)。
- 但是两级目录结构依然缺乏灵活性,用户
不能对自己的文件进行分类(也就是用户目录下不能再创建目录了)
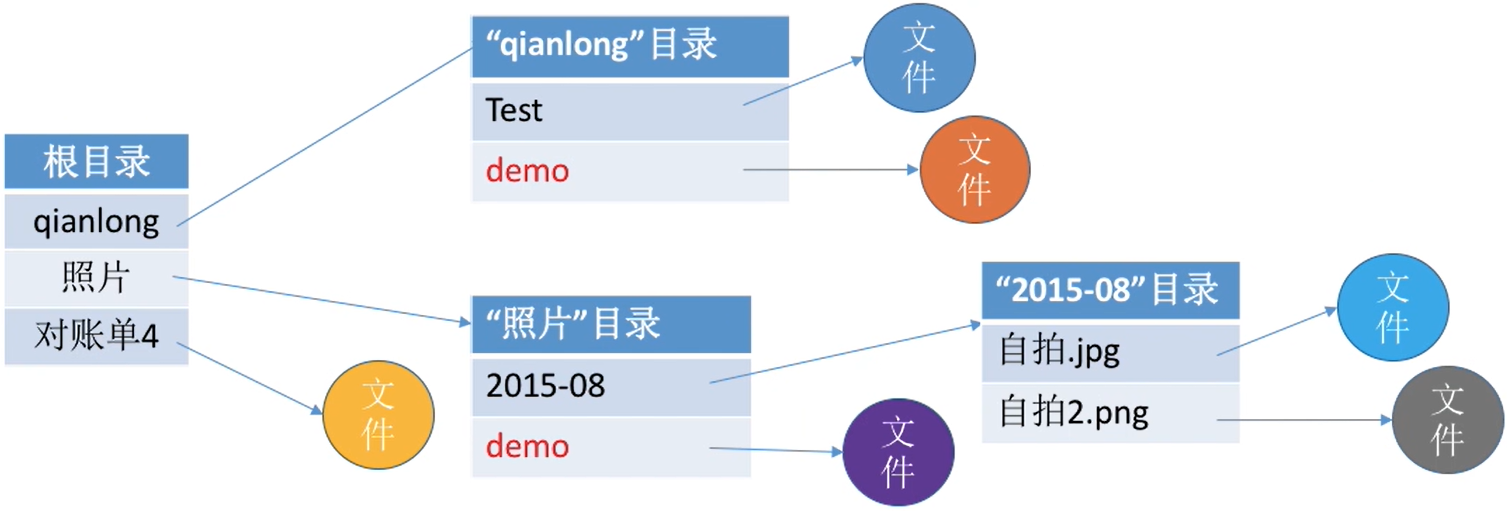
(3) 多级目录结构(树形目录结构)
- 如下:可以看到没有用户特有的目录了
- 主文件目录也成为了普通的根目录
-
用户(或用户进程)要访问某个文件时要用
文件路径名标识文件。 -
文件路径名是个字符串。各级目录之间用“/”隔开。从根目录出发的路径称为绝对路径。例如:自拍.jpg的绝对路径是“/照片/2015-08/自拍.jpg”
-
系统根据
绝对路径一层一层地找到下一级目录。 -
刚开始
从外存读入根目录的目录表;找到“照片”目录的存放位置后,从外存读入对应的目录表;再找到“2015-08”目录的存放位置,再从外存读入对应目录表;最后才找到文件“自拍.jpg”的存放位置。整个过程需要3次读磁盘I/O操作。
也就是说,绝对目录,每过一层,都需要进行一次IO操作读取磁盘中该目录的信息
-
很多时候,用户会
连续访问同一目录内的多个文件(比如:接连查看"2015-08"目录内的多个照片文件),显然,每次都从根目录开始查找,是很低效的。因此可以设置一个“当前目录”。例如,此时已经打开了“照片”的目录文件,也就是说,这张目录表已调入内存,那么可以把它设置为“当前目录”。当用户想要访问某个文件时,可以使用从当前目录出发的“相对路径”。
-
在Linux中,“
.”表杀当前目录,因此如果“照片”是当前目录,则"自拍.jpg"的相对路径为:“./2015-08/自拍.jpg”。 -
从当前路径出发,只需要查询内存中的“照片”目录表,即可知道"2015-08"目录表的存放位置,从外存调入该目录,即可知道“自拍.jpg”存放的位置了
-
可见,引入“
当前目录”和“相对路径”后,磁盘I/O的次数减少了。这就提升了访问文件的效率。
这是绝对路径和相对路径的区别啊
优缺点:
- 树形目录结构可以很方便地对文件进行分类,层次结构清晰,也能够更有效地进行文件的管理和保护。
- 但是,
树形结构不便于实现文件的共享。为此,提出了“无环图目录结构”。
(4) 无环图目录结构
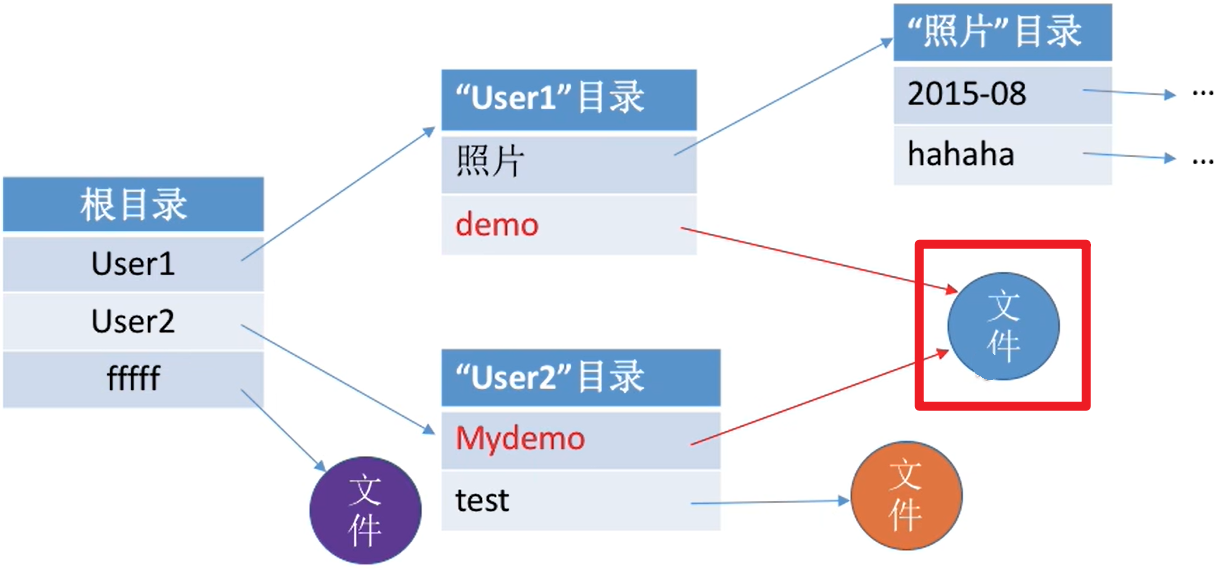
- 在树形目录结构的基础上,增加一些
指向同一节点的有向边,使整个目录成为一个有向无环图。 - 可以更方便地实现
多个用户间的文件共享。 - 可以用
不同的文件名指向同一个文件,甚至可以指向同一个目录(共享同一目录下的所有内容)。(目录也是一种特殊的文件)
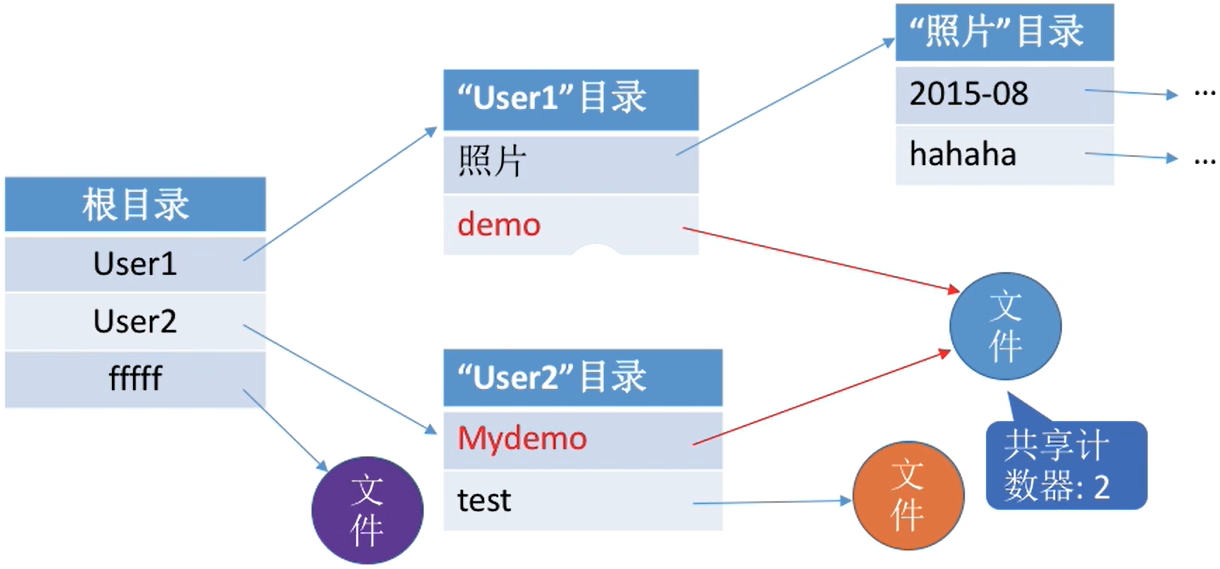
- 需要为每个共享结点设置一个共享计数器,用于记录此时有多少个地方在共享该结点。
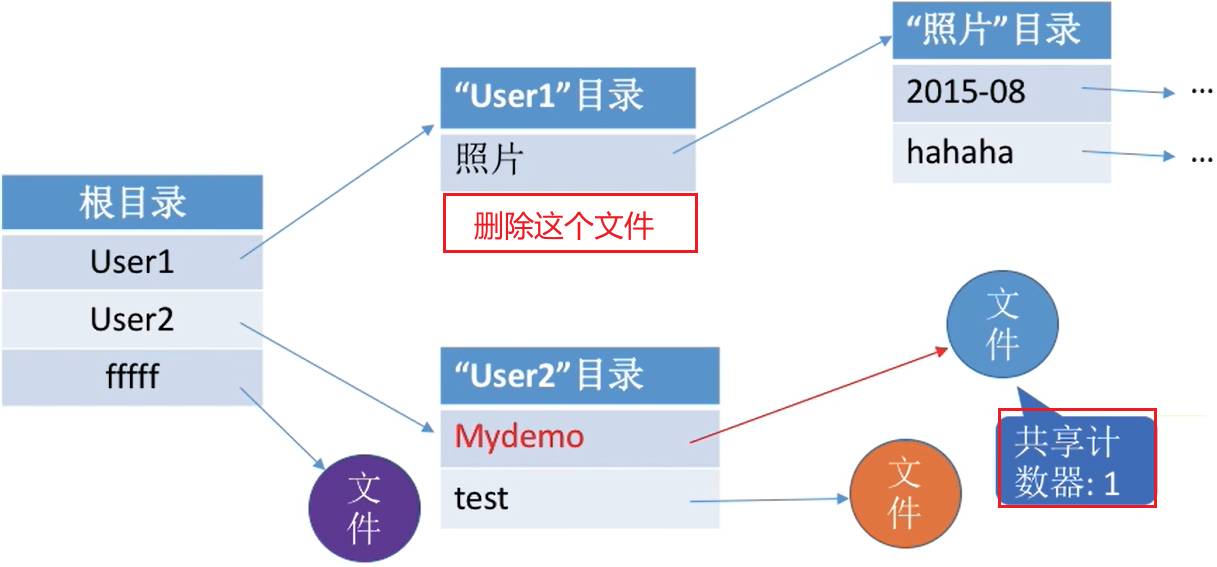
- 用户提出
删除结点的请求时,只是删除该用户的FCB、并使共享计数器减1,并不会直接删除共享结点。 - 只有
共享计数器减为0时,才删除结点。
| 初始情况 | 删除一个文件 |
|---|---|
 |
 |
注意:
共享文件不同于复制文件。在共享文件中,由于各用户指向的是同一个文件,因此只要其中一个用户修改了文件数据,那么所有用户都可以看到文件数据的变化。
4.3.3 索引节点(对FCB的瘦身)
- 如下是基础的文件目录
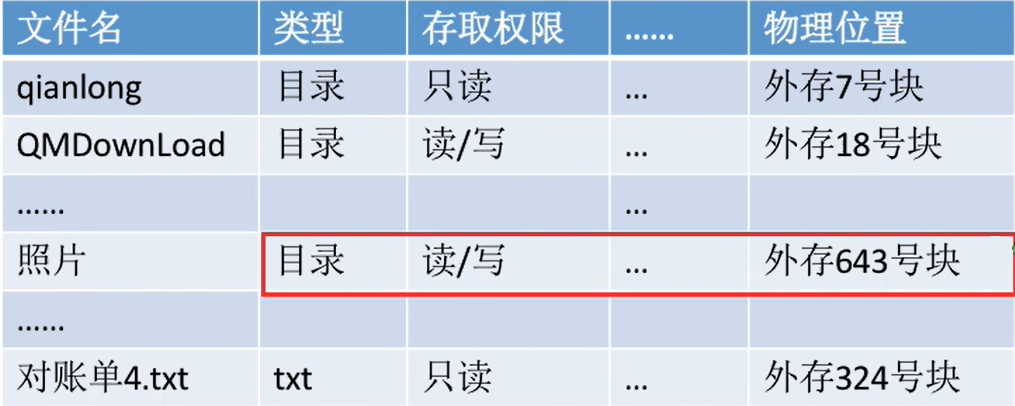
- 其实在查找各级目录的过程中
只需要用到“文件名”这个信息,只有文件名匹配时,才需要读出文件的其他信息。 - 因此可以考虑
让目录表“瘦身”来提升效率。
| 原先 | 改进后 |
|---|---|
|
 |
- 瘦身后:除了文件名之外的文件描述信息都放到
索引节点
好处:
- 假设一个FCB是64B,磁盘块的大小为1KB,则
每个盘块中只能存放16个FCB。 - 若
一个文件目录中共有640个目录项,则共需要占用640/16=40个盘块。因此按照某文件名检索该目录,平均需要查询320个目录项,平均需要启动磁盘20次(每次磁盘I/O读入一块)。 - 若使用
索引结点机制,文件名占14B,索引结点指针站2B,则每个盘块可存放64个目录项,那么按文件名检索目录平均只需要读入320/64=5个磁盘块。显然,这将大大提升文件检索速度。
如果单纯地将一个文件目录放到一块,那么修改目录项的长度并不会影响查询效率。但是实际上,文件目录不一定在一个块中,减小长度就可以减少块的数量,从而间接地减少读取磁盘的次数
- 当
找到文件名对应的目录项时,才需要将索引结点调入内存,索引结点中记录了文件的各种信息,包括文件在外存中的存放位置,根据“存放位置”即可找到文件。 - 存放
在外存中的索引结点称为“磁盘索引结点”,当索引结点放入内存后称为“内存索引结点”。 - 相比之下
内存索引结点中需要增加一些信息,比如:文件是否被修改、此时有几个进程正在访问该文件等。
- 索引节点并不是文件本身,而是一个一个FCB(当然应该没有文件名了)。
- 也不是一个索引节点站一个块,可能多个索引节点连续存放,也可能不连续存放。目录表记录着他们的物理地址
- 通过索引节点的物理地址找到索引节点后,将其调入到内存中,索引节点的内存中保存着对应文件的物理地址

这节的内容很重要,很容易在选择题中考察
4.3.4 文件共享

- 操作系统为用户提供文件共享功能,可以让多个用户共享地使用同一个文件
注意:共享和复制的区别
- 多个用户
共享同一个文件,意味着系统中只有“一份”文件数据。并且只要某个用户修改了该文件的数据,其他用户也可以看到文件数据的变化。 - 如果是多个用户都“
复制”了同一个文件,那么系统中会有“好几份”文件数据。其中一个用户修改了自己的那份文件数据,对其他用户的文件数据并没有影响。
(1) 基于索引节点的共享方式(硬链接)
知识回顾:索引结点,是一种文件目录瘦身策略。由于检索文件时只需用到文件名,因此可以将除了文件名之外的其他信息放到索引结点中。这样目录项就只需要包含文件名、索引结点指针。

- 索引结点中设置一个链接计数变量count,用于表示链接到本索引结点上的用户目录项数。
左边的表格就是一个文件目录,一个目录项只有文件名和索引节点指针,其他的所有信息都在索引节点当中
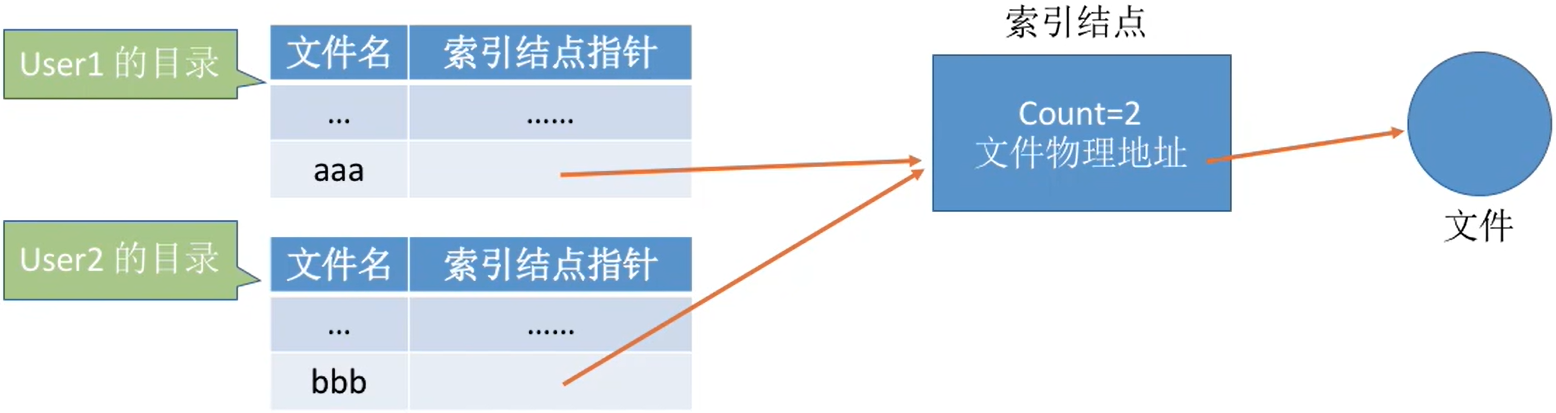
- 若count =2,说明此时有两个用户目录项链接到该索引结点上,或者说是有两个用户在共享此文件。
- 若某个用户决定“删除”该文件,则只是要把用户目录中与该文件对应的目录项删除,且索引结点的count值减1。
- 若count>0,说明还有别的用户要使用该文件,暂时不能把文件数据删除,否则会导致指针悬空。
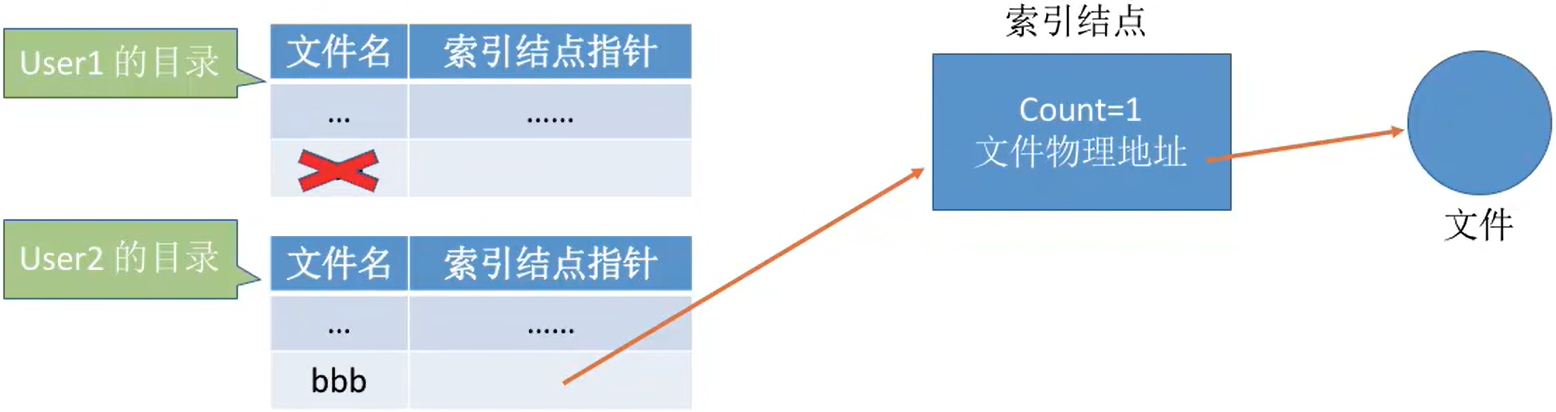
- 当count = 0,系统负责删除文件

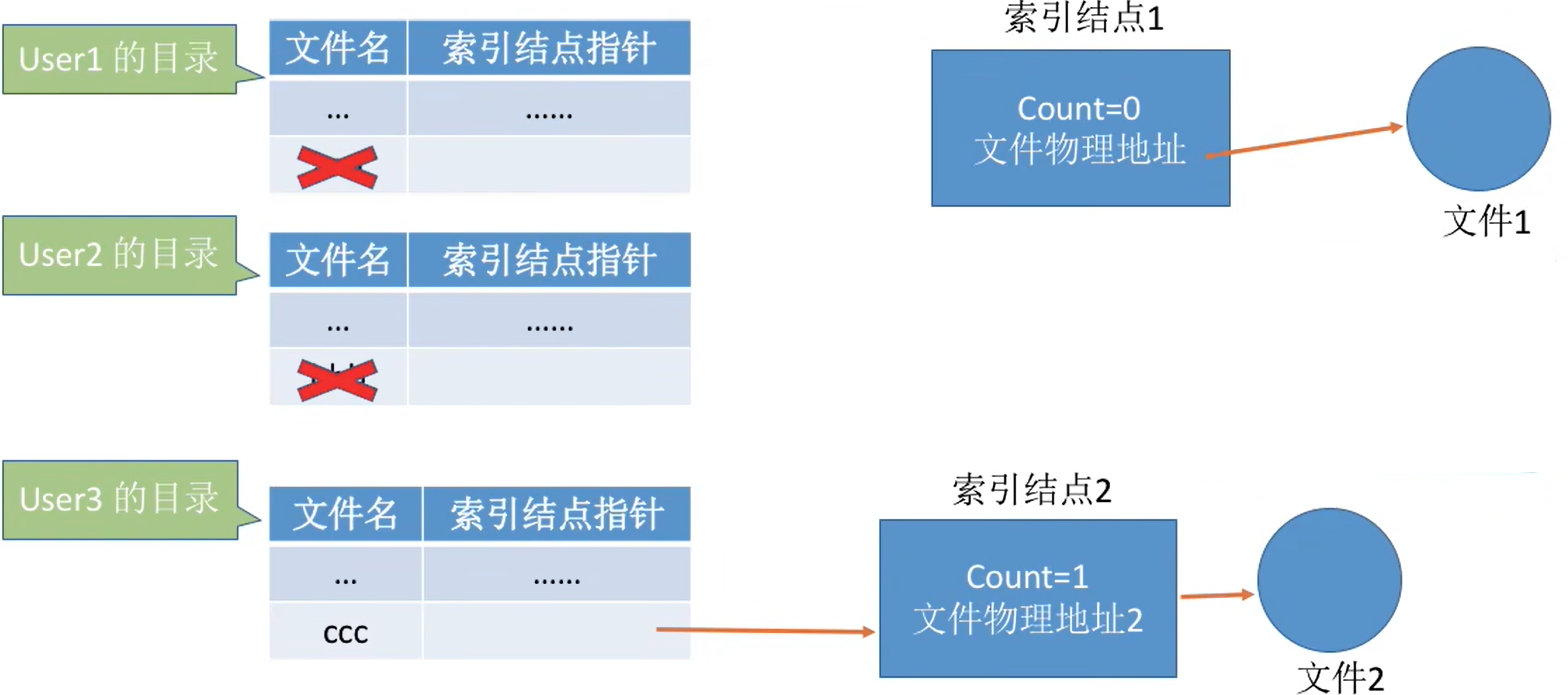
(2) 基于符号链的共享方式(软链接)
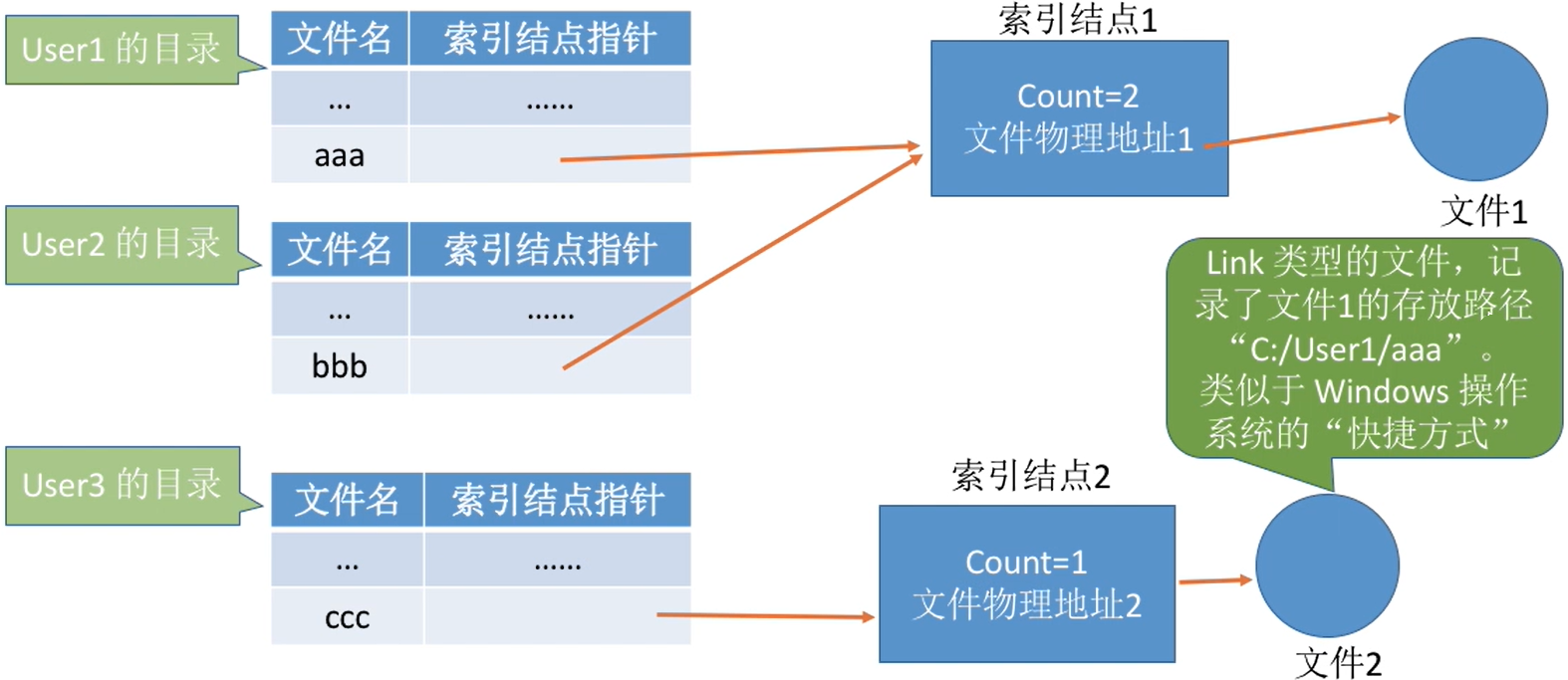
- 当User3访问“ccc”时,操作系统判断文件“ccc”属于Link类型文件,于是会根据其中记录的路径层层查找目录,最终找到User1的目录表中的“aaa”表项,于是就找到了文件1的索引结点。
文件2是一个真实的文件,类型是link类型
- Link类型的文件名可以不同
- 双击打开link类型的文件时,操作系统判断这个文件是Link类型的“快捷方式”文件,于是会根据其中记录的“路径信息"检索目录,最终找到被链接的程序
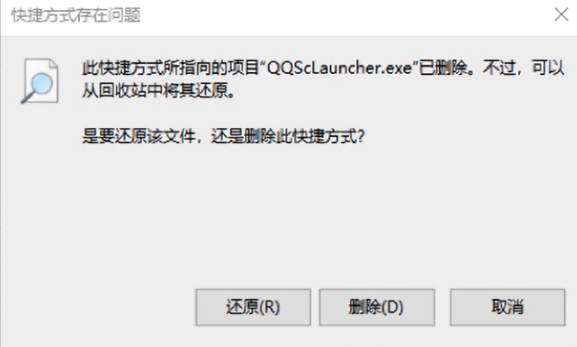
此时如果删除了源文件
- 文件1己删除,但是文件2依然存在,只是通过“c:/User1/aaa”这个路径已经找不到文件1了

4.4 存取控制模块(文件保护)
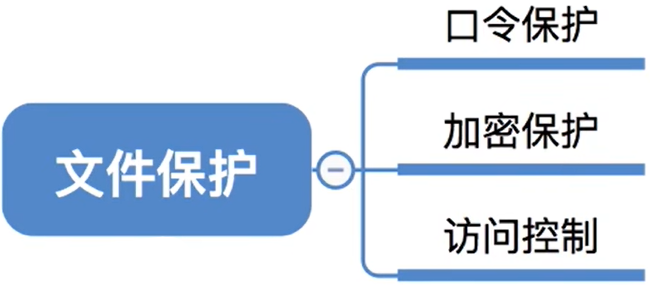
4.4.1 口令保护
-
为文件设置一个“口令”(如: abc112233),用户请求访问该文件时必须提供“口令”。
-
口令一般存放在文件对应的FCB或索引结点中。用户访问文件前需要先输入“口令”,操作系统会将用户提供的口令与FCB中存储的口令进行对比,如果正确,则允许该用户访问文件
-
优点:保存口令的空间开销不多,验证口令的时间开销也很小(这种方法仅仅是对文件的访问权加密)。
-
缺点:正确的“口令”存放在系统内部,不够安全。
4.4.2 加密保护
使用某个“密码”对文件进行加密,在访问文件时需要提供正确的“密码”才能对文件进行正确的解密。
这是直接对文件的内容加密了
Eg:一个最简单的加密算法――异或加密
假设用于加密/解密的“密码”为“01001”,每五个为一组加密


因为是异或,解密使用同样的密码即可

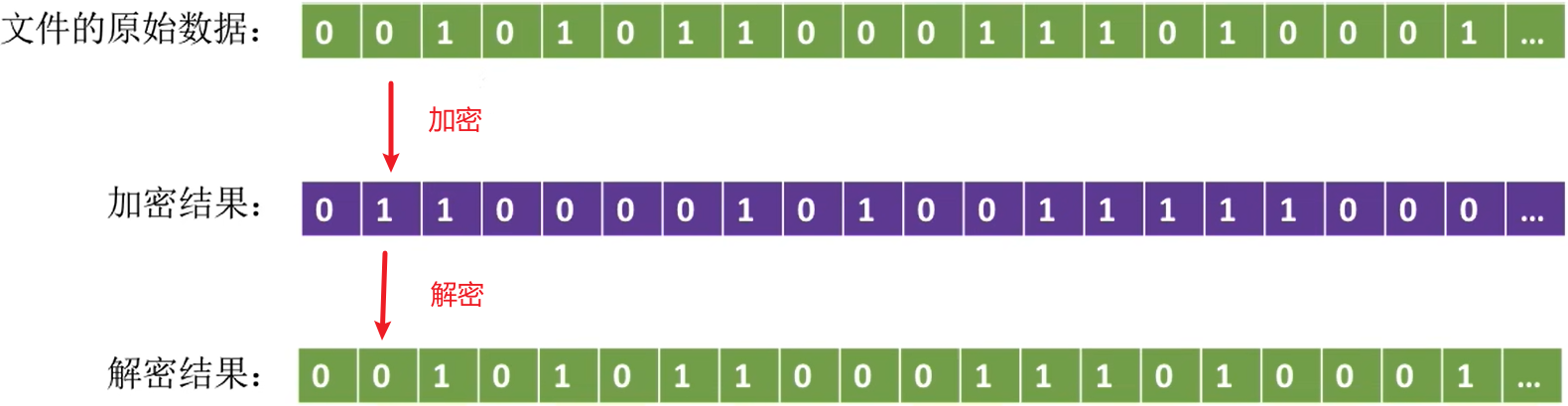
如果解密的密码错误,结果就会不一样
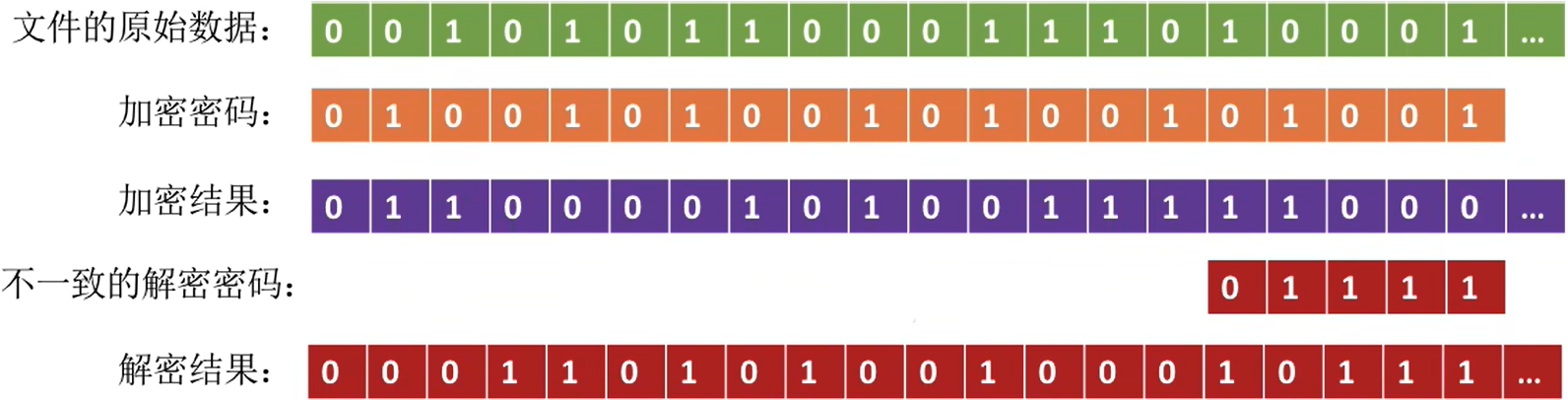
- 优点:保密性强,不需要在系统中存储“密码”
- 缺点:编码/译码,或者说加密/解密要花费一定时间。
4.4.3 访问控制
在每个文件的FCB(或索引结点)中增加一个访问控制列表(Access-Control List, ACL),该表中记录了各个用户可以对该文件执行哪些操作。
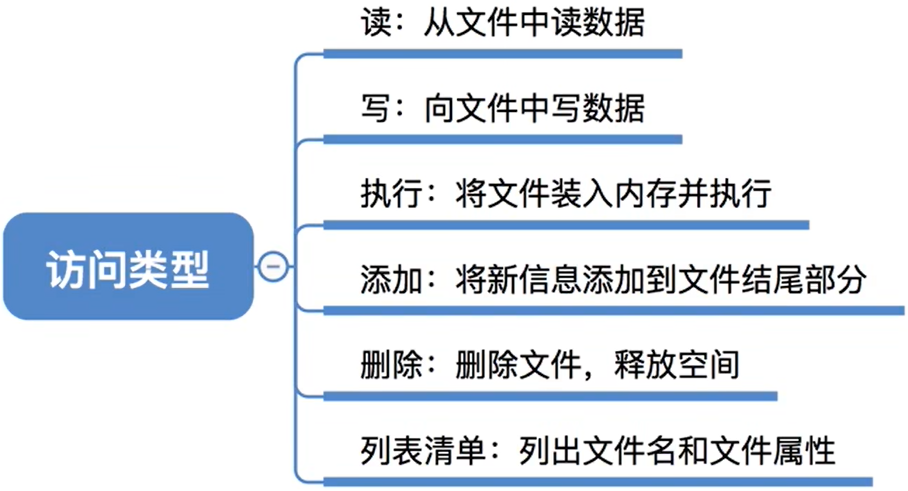
| 用户 | 读 | 写 | 执行 | 添加 | 删除 | 列表清单 |
|---|---|---|---|---|---|---|
| father | 1 | 1 | 1 | 1 | 1 | 1 |
| mother | 1 | 0 | 1 | 0 | 0 | 1 |
| son | 0 | 0 | 0 | 0 | 0 | 0 |
有的计算机可能会脊很多个用户,因此访问控制列表可能会很大,可以用
精简的访问列表解决这个问题
精简的访问列表:以“组”为单位,标记各“组”用户可以对文件执行哪些操作。
如:分为系统管理员、文件主、文件主的伙伴、其他用户几个分组。
| 完全控制 | 执行 | 修改 | 读取 | 写入 | |
|---|---|---|---|---|---|
| 系统管理员 | 1 | 1 | 1 | 1 | 1 |
| 文件主 | 0 | 1 | 1 | 1 | 1 |
| 文件主的伙伴 | 0 | 1 | 0 | 1 | 0 |
| 其他用户 | 0 | 0 | 0 | 0 | 0 |
- 当某用户想要访问文件时,系统会检查
该用户所属的分组是否有相应的访问权限。(系统需要管理分组的信息) - 若想要让某个用户能够读取文件,只需要把该用户放入‘文件主的伙伴”这个分组即可
(1) 操作系统实例
① linux
linux的就是文件访问权限的那一节内容
② Windows
- 首先是添加和选择用户
 |
 |
|---|---|
 |
 |
 |
 |
- 然后是设置权限
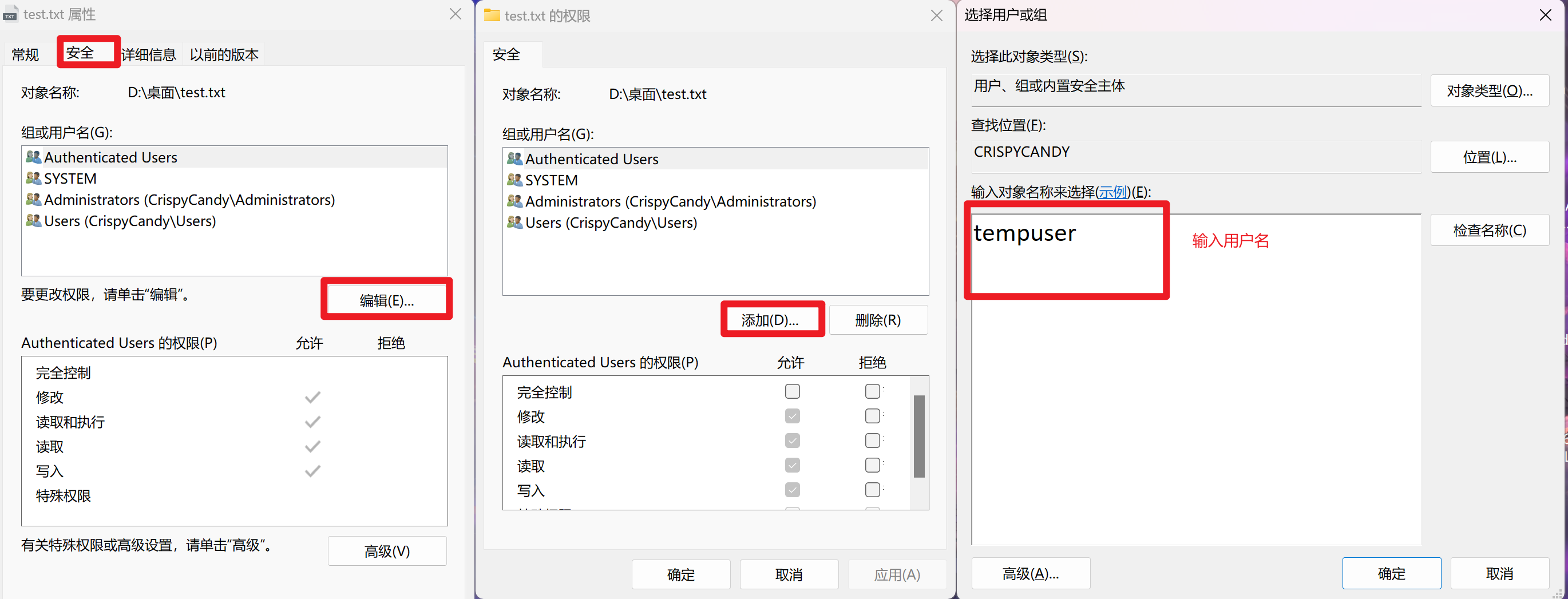
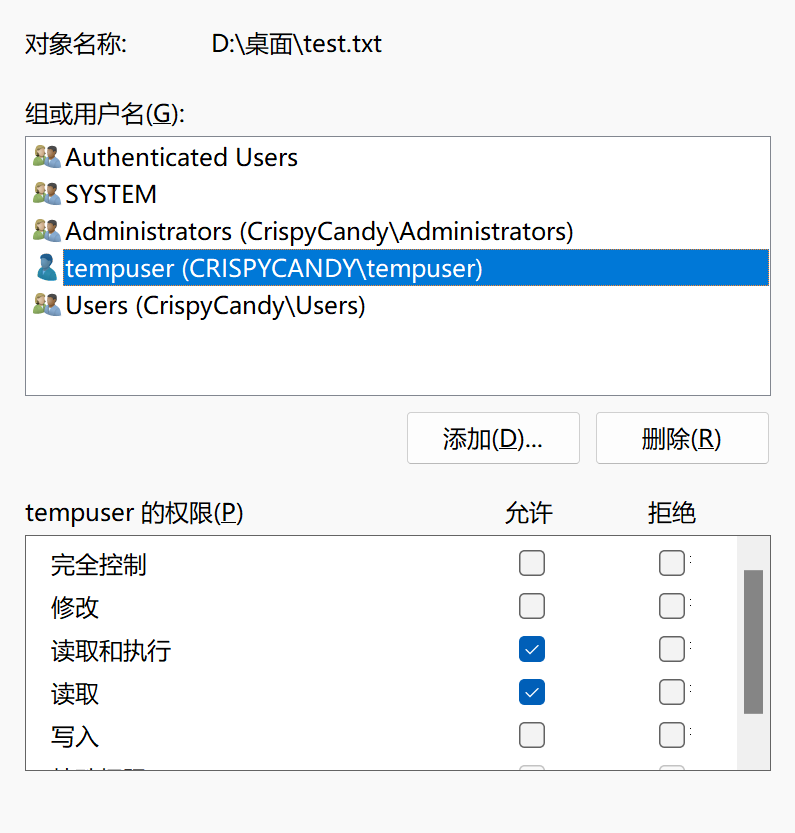
然后就可以修改权限了

用另一个用户 查看的时候
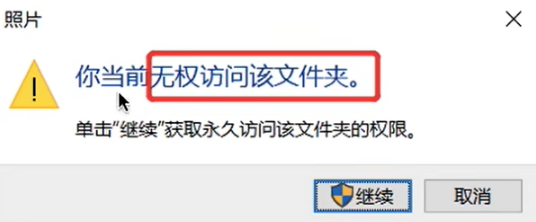

- 注意:如果对某个目录进行了访问权限的控制,那也要对目录下的所有文件进行相同的访问权限控制
允许访问文件之后,才会真正地能够访问文件
4.5 逻辑文件系统与文件信息缓冲区(文件的逻辑结构)
逻辑文件系统就是
管理文件的逻辑结构的,文件信息缓冲区就是建立逻辑的
在获取了访问权限之后
- 用户指明想要访问文件记录号,这一层需要将记录号
转换为对应的逻辑地址
- 文件记录号,其实也就是指有结构文件的某条记录的索引号吧,转换成逻辑地址就需要掌握文件的逻辑结构
- 文件的逻辑结构对于用户软件来说是透明的,是操作系统管理的
- 例如Excel的文件中,应该是自动进行了访问文件记录号,所以能立即显示出所有文件
4.5.1 文件的逻辑结构
这个是讲述内部如何组织的
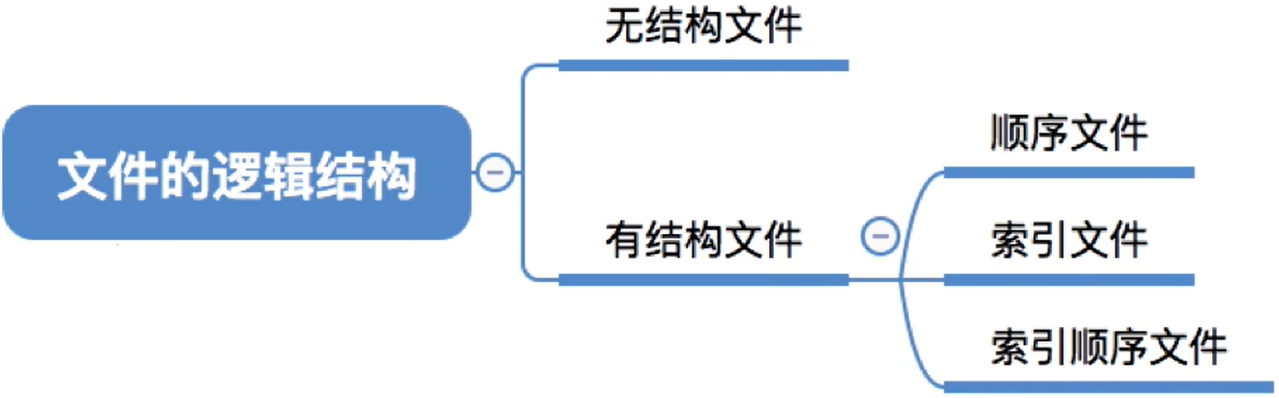
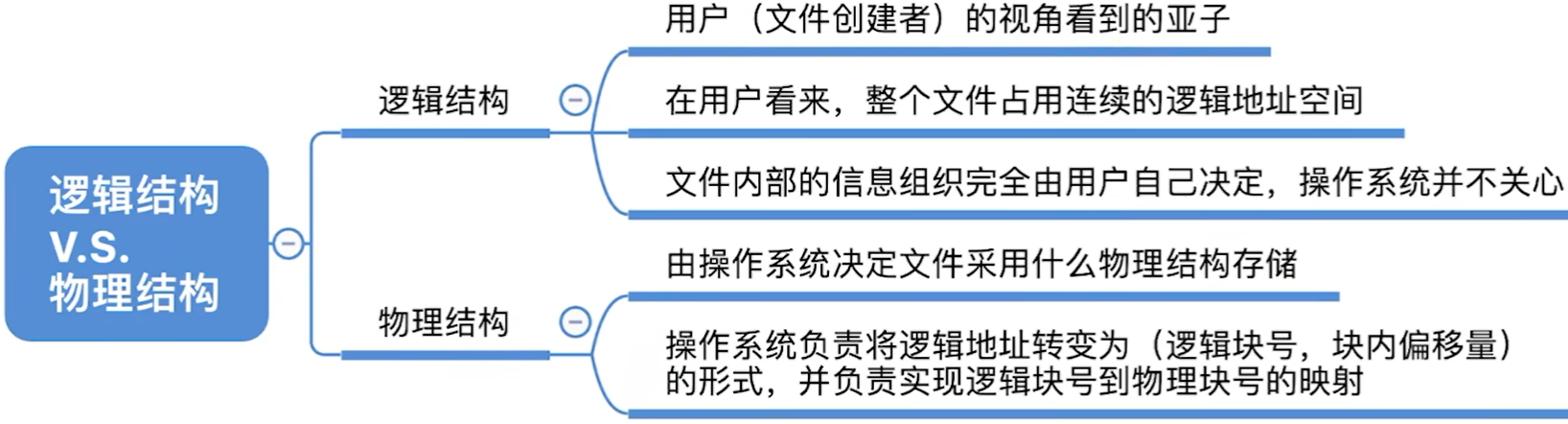
- 所谓的“逻辑结构”,就是指
在用户看来,文件内部的数据应该是如何组织起来的。 - 而“物理结构”指的是
在操作系统看来,文件的数据是如何存放在外存中的。
- 类似于数据结构的“逻辑结构”和“物理结构”。
- 如“
线性表”就是一种逻辑结构,在用户角度看来,线性表就是一组有先后关系的元素序列,如: a,b, c, d, e ..... - “线性表”这种
逻辑结构可以用不同的物理结构实现,如:顺序表/链表。 - 顺序表的各个元素在逻辑上相邻,在物理上也相邻;而
链表的各个元素在物理上可以是不相邻的。因此,顺序表可以买现“随机访问”,而“链表”无法实现随机访问。 - 可见,算法的具体实现与逻辑结构、物理结构都有关(文件也一样,文件操作的具体实现与文件的逻辑结构、物理结构都有关)
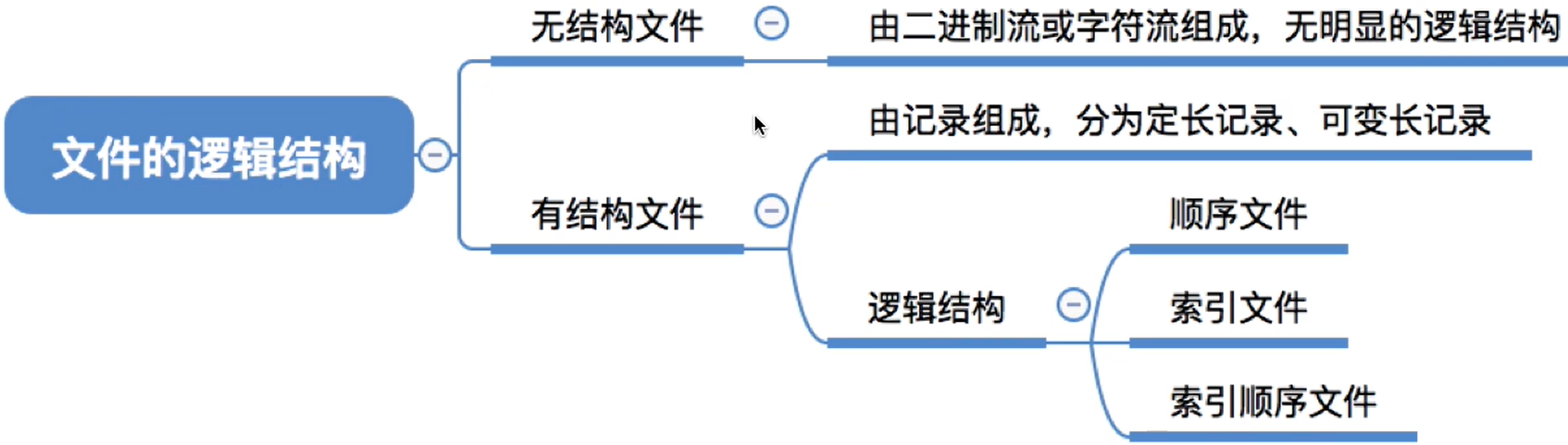
按文件是否有结构分类,可以分为无结构文件、有结构文件两种。
(1) 文件的分类
文件可以分为:
- 无结构文件:无结构文件(如文本文件)—— 由一些二进制或字符流组成,又称“流式文件”
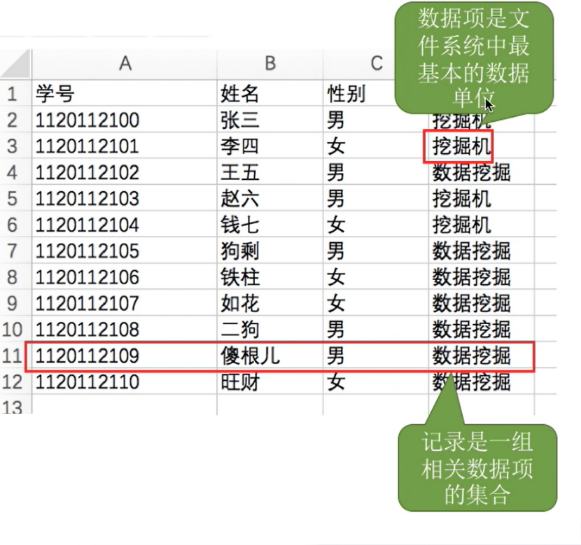
有结构文件(如数据库表、Excel文件)—―由一组相似的记录组成,又称“记录式文件”- 记录是一组相关数据项的集合
- 数据项是文件系统中最基本的数据单位
(2) 无结构文件逻辑结构
无结构文件:文件内部的数据就是一系列二进制流或字符流组成。又称“流式文件”。如:Windows操作系统中的.txt文件。- 文件内部的数据其实就是一系列字符流,
没有明显的结构特性。因此也不用探讨无结构文件的“逻辑结构”问题。
(3) 有结构文件逻辑结构
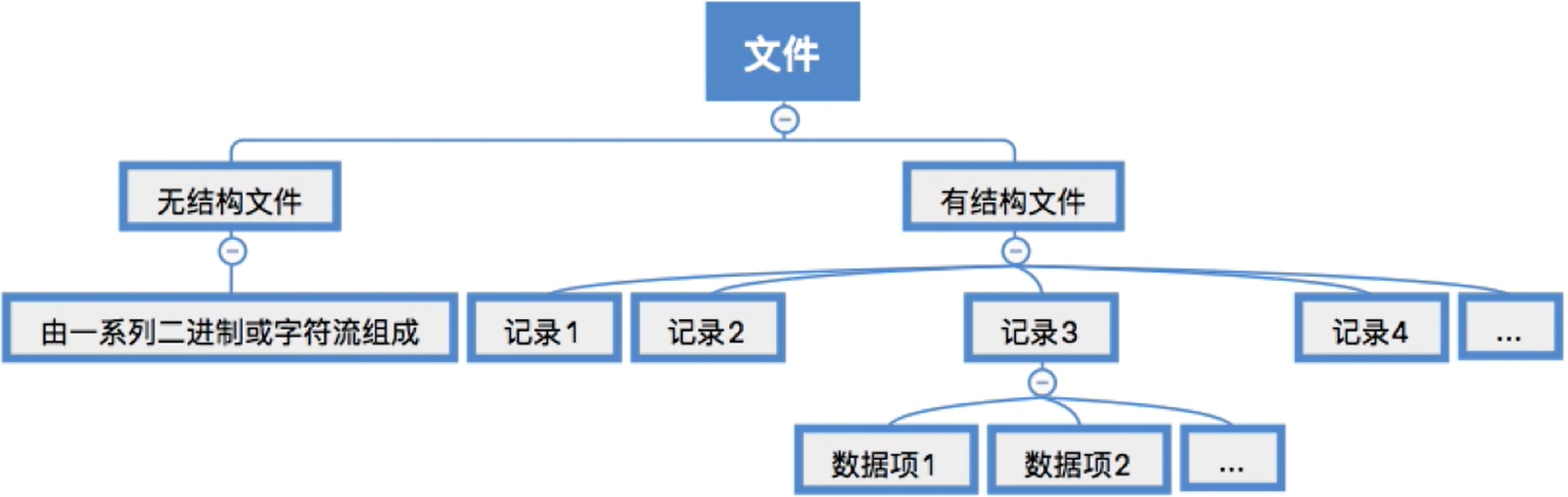
有结构文件中,各个记录间应该如何组织的问题——应该顺序存放?还是用索引表来表示记录间的顺序? ――这是“文件的逻辑结构”重点要探讨的问题
- 有结构文件:由一组相似的记录组成,又称“
记录式文件”。每条记录又若干个数据项组成。如:数据库表文件。 - 一般来说,每条记录有一个数据项可作为
关键字(作为识别不同记录的ID) - 根据各条记录的长度(占用的存储空间)是否相等,又可分为定长记录和可变长记录两种。
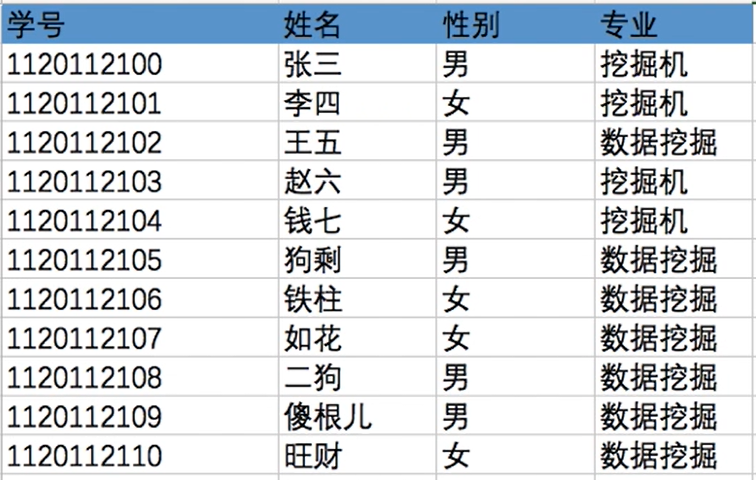
- 如图:这是一张数据库表,记录了各个学生的信息
- 每个学生对应一条记录,每条记录由若干个数据项组成
- 在本例中,
“学号”即可作为各个记录的关键字

- 这个有结构文件由
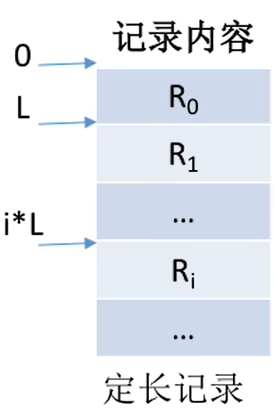
定长记录组成,每条记录的长度都相同(共128B)。各数据项都处在记录中相同的位置,具有相同的顺序和长度(前32B一定是学号,之后32B一定是姓名......
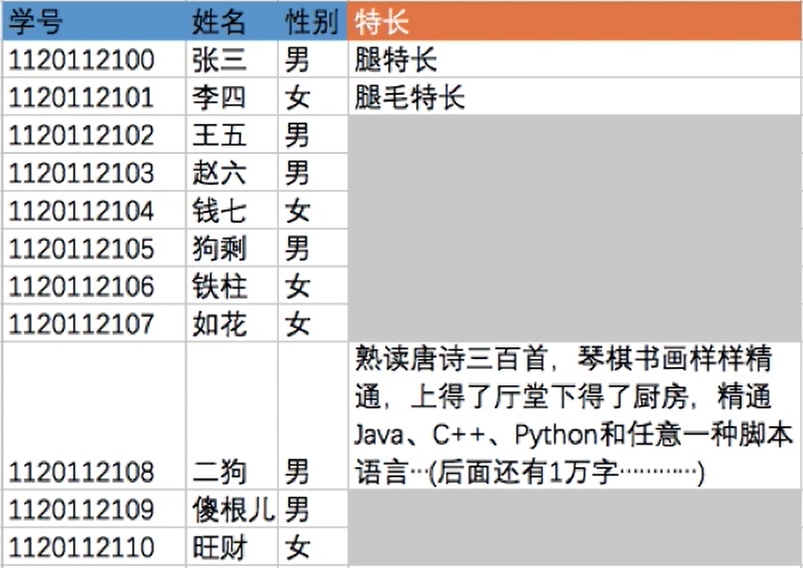

- 这个有结构文件由
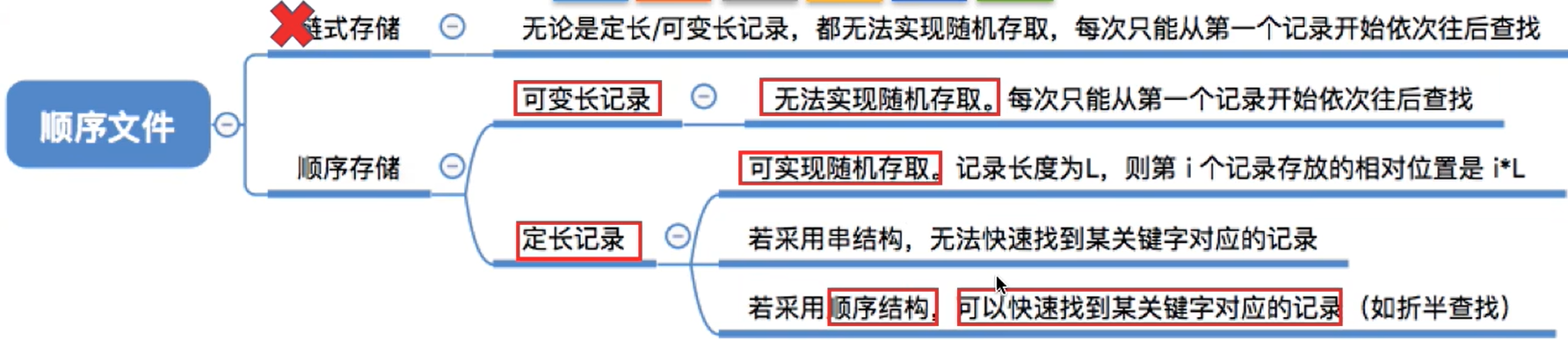
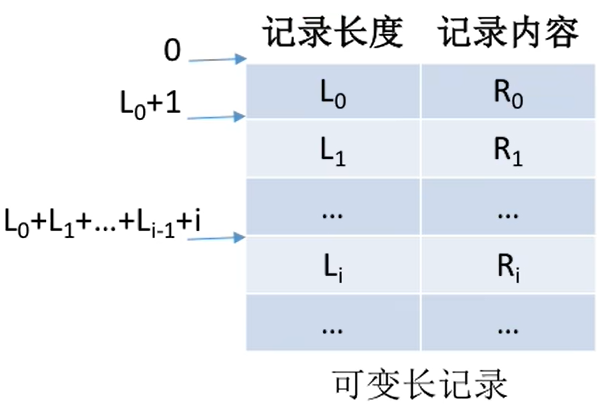
可变长记录组成,由于各个学生的特长存在很大区别,因此“特长”这个数据项的长度不确定,这就导致了各条记录的长度也不确定。当然,没有特长的学生甚至可以去掉“特长”数据项。
根据有结构文件中的各条记录在逻辑上如何组织,可以分为三类

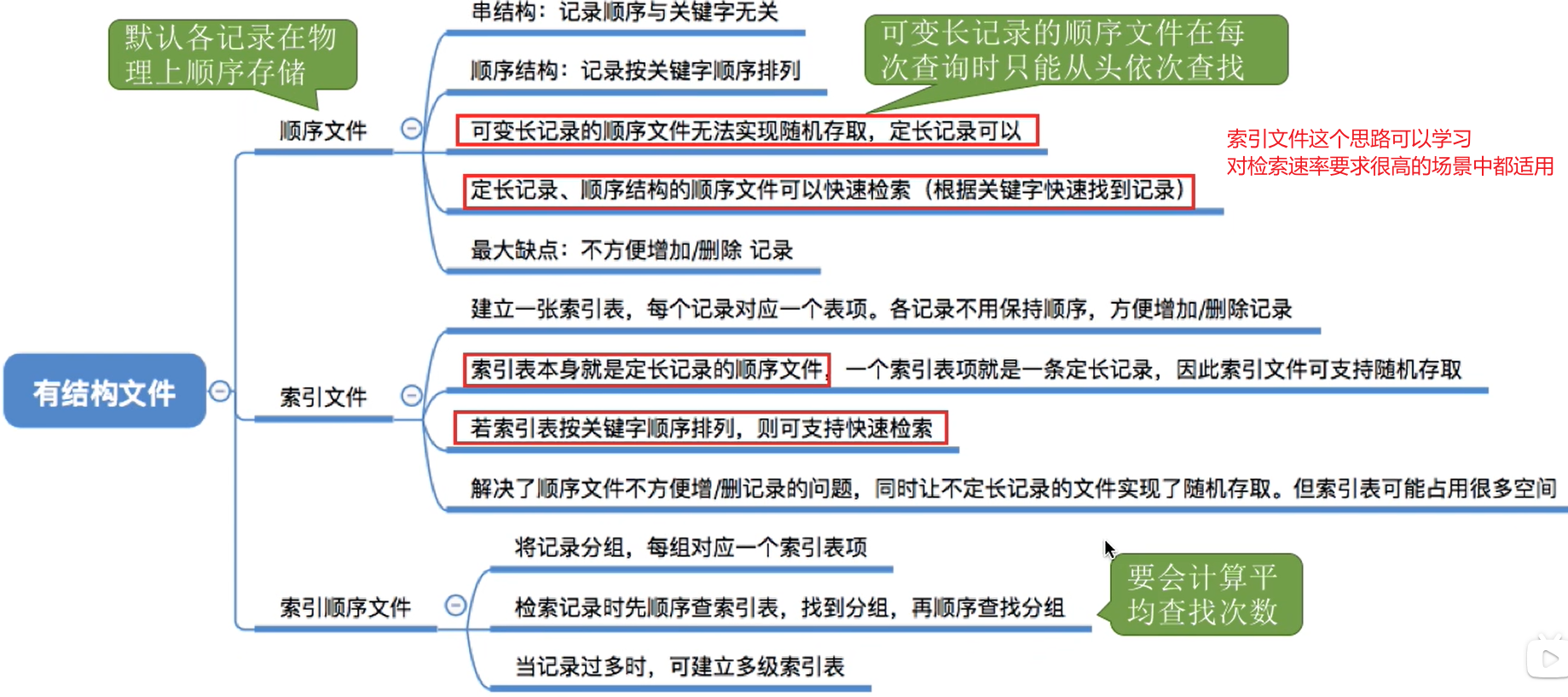
① 顺序文件
顺序文件:文件中的记录一个接一个地顺序排列(逻辑上),记录可以是定长的或可变长的。- 各个记录
在物理上可以顺序存储或链式存储。
| 物理上顺序存储 | 链式存储 |
|---|---|
 |
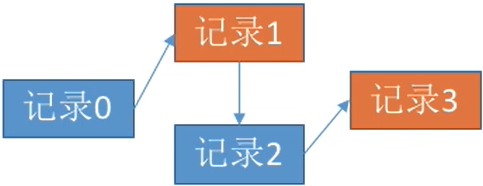 |
- 顺序存储:逻辑上相邻的记录物理上也相邻(类似于顺序表)
- 链式存储:逻辑上相邻的记录物理上不一定相邻(类似于链表)
这里不是很清楚,记录如果物理上不相邻的话,那么每块不能表示一个记录吧?哦对了,是不一定的,每块肯定有多条记录,但是物理上连续的记录不一定是相邻的,都是链表串起来的。而且逻辑地址一定不能影响物理内存,这是肯定的

穿结构通常按照记录存入的时间决定记录的顺序
假设:已经知道了文件的起始地址(也就是第一个记录存放的位置)
- 思考1:能否
快速找到第i个记录对应的地址?(即能否实现随机存取) - 思考2:能否
快速找到某个关键字对应的记录存放的位置?
链式存储肯定不能快速找到
| 可变长记录 | 定长记录 |
|---|---|
 |
 |
- 可变长记录:需要显式地给出记录长度,假设用
1字节表示记录长度
(也就是可变长的记录实际上需要记录每条记录的长度,当然在显示的时候看不到这个长度,可是文件中是必须有的),但是定长记录就不用
- 结论:定长记录的顺序文件,若
物理上采用顺序存储,则可实现随机存取;若能再保证记录的顺序结构,则可实现快速检索(即根据关键字快速找到对应记录)
注:一般来说,考试题目中所说的“顺序文件”指的是物理上顺序存储的顺序文件。之后的讲解中提到的顺序文件也默认如此。
- 顺序文件的
缺点:是增加/删除一个记录比较困难(如果是串结构则相对简单)
② 索引文件
可变长记录文件,要找到第i个记录,必须先顺序第查找前i-1个记录,但是很多应用场景中又必须使用可变长记录。如何解决这个问题?
这也是可变长记录,这个的话就是
这里有个问题啊,这个索引是文件装的吗。还是操作系统将文件写入到硬盘的时候创建的?
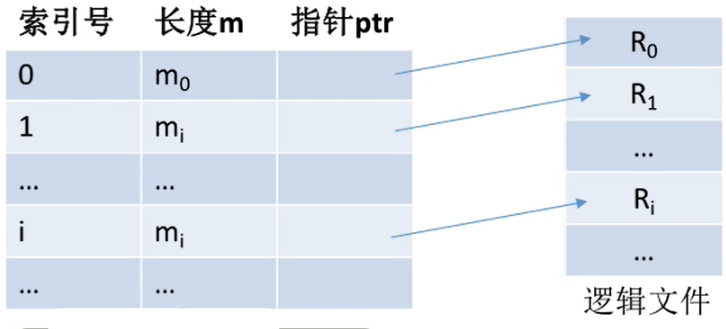
- 建立一张索引表以加快文件检索速度。每条记录对应一个索引项。
- 文件中的这些记录在物理上可以离散地存放。
- 索引表本身是定长记录的顺序文件。因此可以快速找到
第i个记录对应的索引项。 - 可将
关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字折半查找。 - 每当要增加/删除一个记录时,需要对索引表进行修改。由于索引文件有很快的检索速度,因此
主要用于对信息处理的及时性要求比较高的场合。 - 另外,可以用不同的数据项建立多个索引表。如:学生信息表中,可用关键字“学号”建立一张索引表。也可用“姓名”建立一张索引表。这样就可以根据“姓名”快速地检索文件了。
(Eg: SQL就支持根据某个数据项建立索引的功能)
当对信息处理的及时性比较高的场合,就可以用
索引表索引表有线性表的优势,但是添加或者删除的时候也有线性表的问题吧
索引表不是用户建立的吧,这个到底和物理结构是啥关系呀,因为物理结构中索引表一个指向一块,但是逻辑结构中,一个项肯定不是一块呀
③ 索引顺序文件
索引文件的缺点:每个记录对应一个索引表项,因此索引表可能会很大。
比如:文件的每个记录平均只占8B,而每个索引表项占32个字节,那么索引表都要比文件内容本身大4倍,这样对存储空间的利用率就太低了。
索引顺序文件是索引文件和顺序文件思想的结合。索引顺序文件中,同样会为文件建立一张索引表,但不同的是:并不是每个记录对应一个索引表项,而是一组记录对应一个索引表项。- 索引顺序文件的索引项也
不需要按关键字顺序排列,这样可以极大地方便新表项的插入 - 如下图,左边的是索引项,右边的是对应的逻辑文件的组
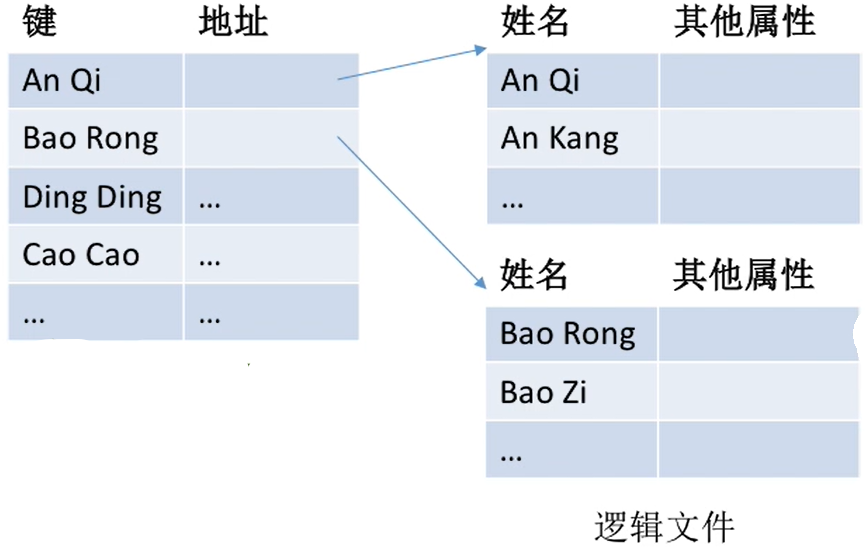
- 在本例中,学生记录按照学生姓名的开头字母进行分组。
每个分组就是一个顺序文件,分组内的记录不需要按关键字排序
每个分组是一个顺序文件,但是查找每一个组需要索引
- 用这种策略确实可以
让索引表“瘦身”,但是是否会出现不定长记录的顺序文件检索速度慢的问题呢?
索引顺序文件的检索效率分析
- 若一个
顺序文件有10000个记录,则根据关键字检索文件,只能从头开始顺序查找(这里指的并不是定长记录、顺序结构的顺序文件),平均须查找5000个记录。 - 若采用
索引顺序文件结构,可把10000个记录分为100组,每组100个记录。则需要先顺序查找索引表找到分组(共100个分组,因此索引表长度为100,平均需要查50次),找到分组后,再在分组中顺序查找记录(每个分组100个记录,因此平均需要查50次)。可见,采用索引顺序文件结构后,平均查找次数减少为50+50= 100次。 - 同理,若文件共有106个记录,则可分为1000个分组,每个分组1000个记录。根据关键字检索一个记录平均需要查找500+500 = 1000次。
这个查找次数依然很多,如何解决呢?
④ 多级索引顺序文件
为了进一步提高检索效率,可以为顺序文件建立多级索引表。
例如,对于一个含106个记录的文件
- 可先为该文件建立一张
低级索引表,每100个记录为一组,故低级索引表中共有10000个表项(即10000个定长记录) - 再把这10000个定长记录分组,每组100个,为其建立顶级索引表,故
顶级索引表中共有100个表项。
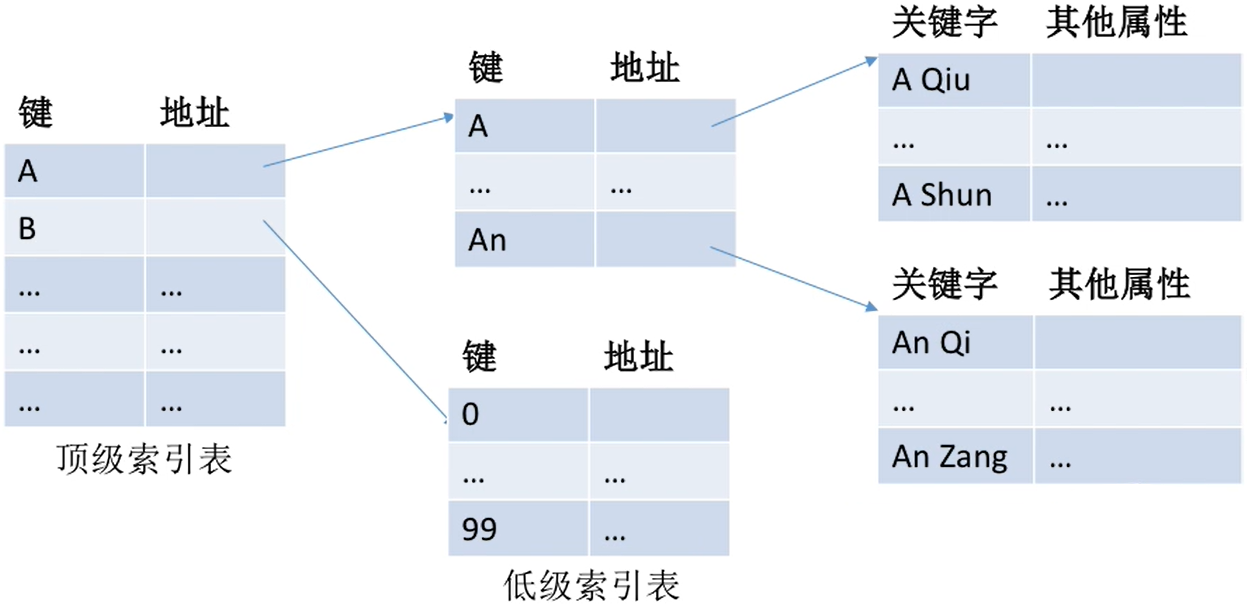
此时,检索一个记录平均需要查找50+50+50 =150次
4.5.2 文件信息缓冲区
文件信息的缓冲区:
- 文件的逻辑结构中,有一种索引文件,这种方式会为文件的记录建立一种索引表
- 在查询索引表之前,需要将其调入到内存的文件信息缓冲区中
可以理解为,文件信息缓冲区是存储管理文件逻辑结构的内存空间
4.6 物理文件系统(文件的物理结构/文件的分配方式)
- 这一层需要把
上一层(逻辑文件系统与文件信息缓冲区)提供的文件逻辑地址转换为实际的物理地址 - 下一层就对应着辅助分配模块和设备管理模块了,其中辅助分配模块
管理的是空闲的存储空间,设备管理模块是管理硬件的 - 要进行逻辑地址和物理地址的转化,就需要掌握文件的物理结构了
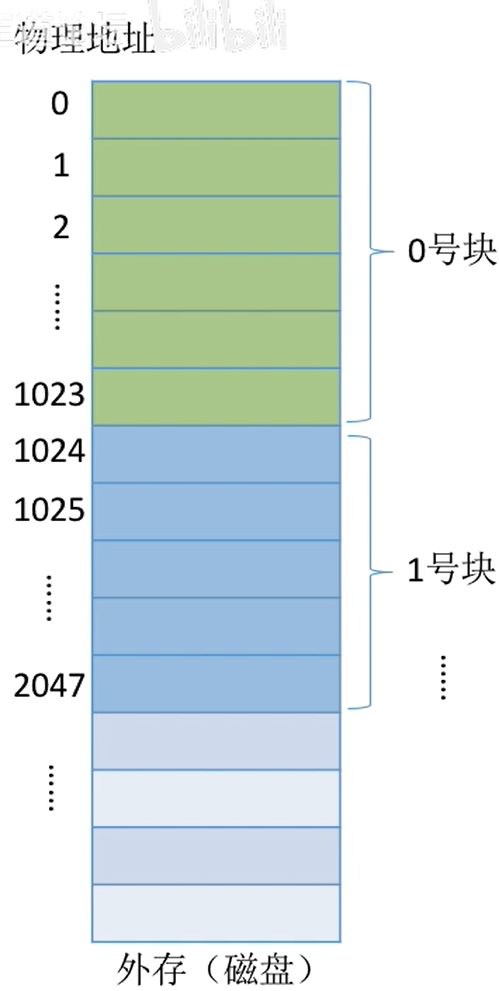
从上往下看,文件数据应该怎么存放在外存(磁盘)上?
- 与内存一样,外存也是由一个个存储单元组成的,
每个存储单元可以存储一定量的数据(如1B)。每个存储单元对应一个物理地址 - 类似于内存分为一个个“内存块”,外存会分为一个个“
块/磁盘块/物理块”。每个磁盘块的大小是相等的,每块一般包含2的整数幂个地址(如本例中,一块包含210个地址,即1KB)。 - 同样类似的是,
文件的逻辑地址也可以分为(逻辑块号,块内地址),操作系统同样需要将逻辑地址转换为外存的物理地址(物理块号,块内地址)的形式。块内地址的位数取决于磁盘块的大小 - 操作系统以“
块”为单位为文件分配存储空间,因此即使一个文件大小只有10B,但它依然需要占用1KB的磁盘块。外存中的数据读入内存时同样以块为单位
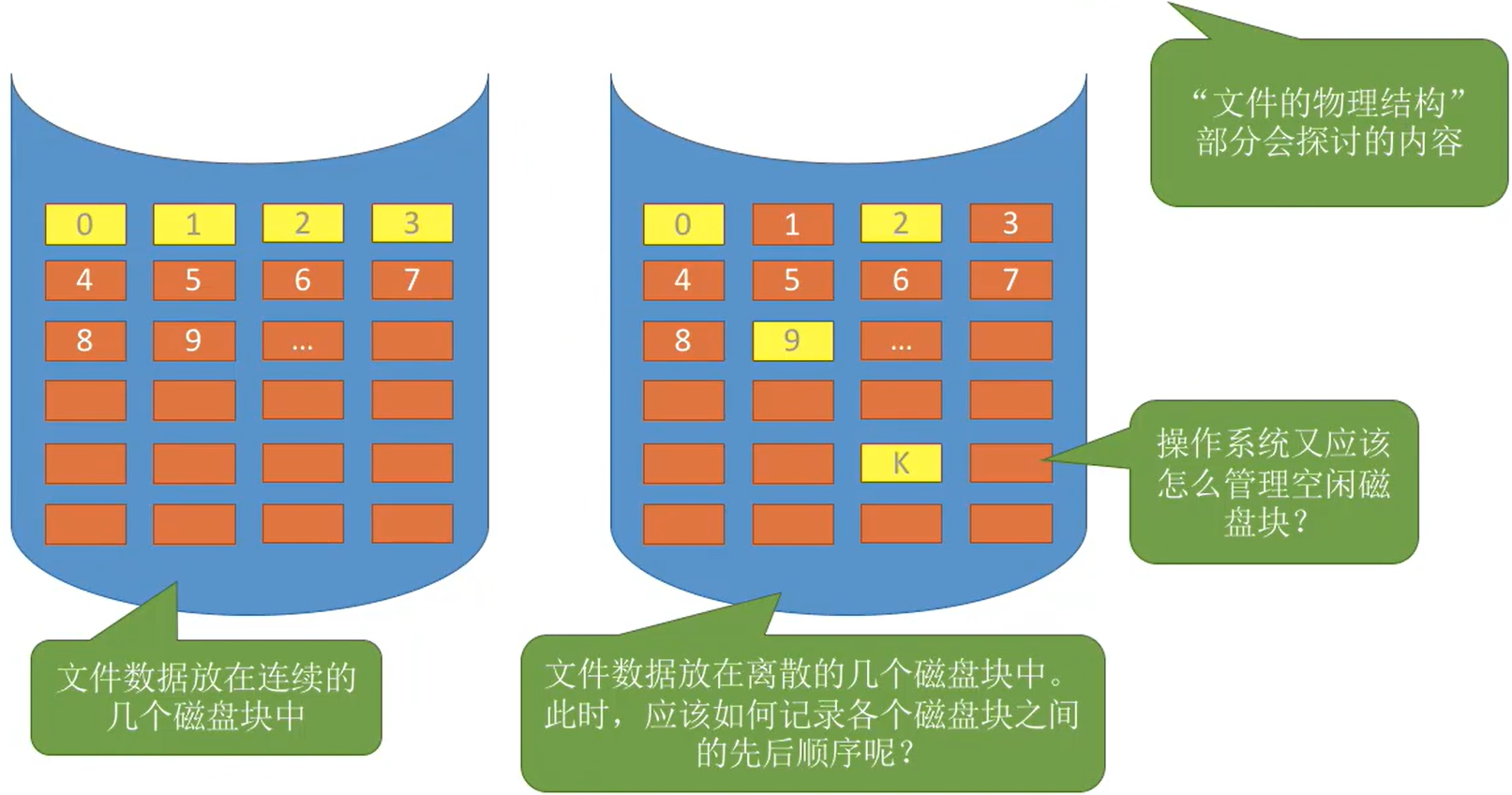
很重要,考试中经常出现2-3道选择题
- 物理结构是实际存放文件的结构
- 但是对于逻辑结构而言,物理结构是透明的,是连续存放的一个空间
- 因此逻辑结构可以在这个 逻辑上连续的空间 按照自己的逻辑来存放文件(这是我对逻辑结构和物理结构的理解)

使用过的磁盘和空闲的磁盘是分开管理的
其中:
- 对非空闲磁盘块的管理 是 “文件的物理结构/文件分配方式”要探讨的问题
- 对空闲磁盘块的管理师是 "文件存储空间管理" 要探讨的问题
即:文件数据应该怎样存放在外存中?
4.6.1 文件块 & 磁盘块
磁盘的分块机构如下
|
 |
|---|
- 类似于内存分页,
磁盘中的存储单元也会被分为一个个“块/磁盘块/物理块”。 - 很多操作系统中,
磁盘块的大小与内存块、页面的大小相同
内存与磁盘之间的数据交换(即读/写操作、磁盘I/O)都是以“块”为单位进行的。- 即
每次读入一块,或每次写出一块
- 在
内存管理中,进程的逻辑地址空间被分为一个一个页面 - 同样的,在
外存管理中,为了方便对文件数据的管理,文件的逻辑地址空间也被分为了一个一个的文件“块”。 - 于是
文件的逻辑地址也可以表示为(逻辑块号,块内地址)的形式。
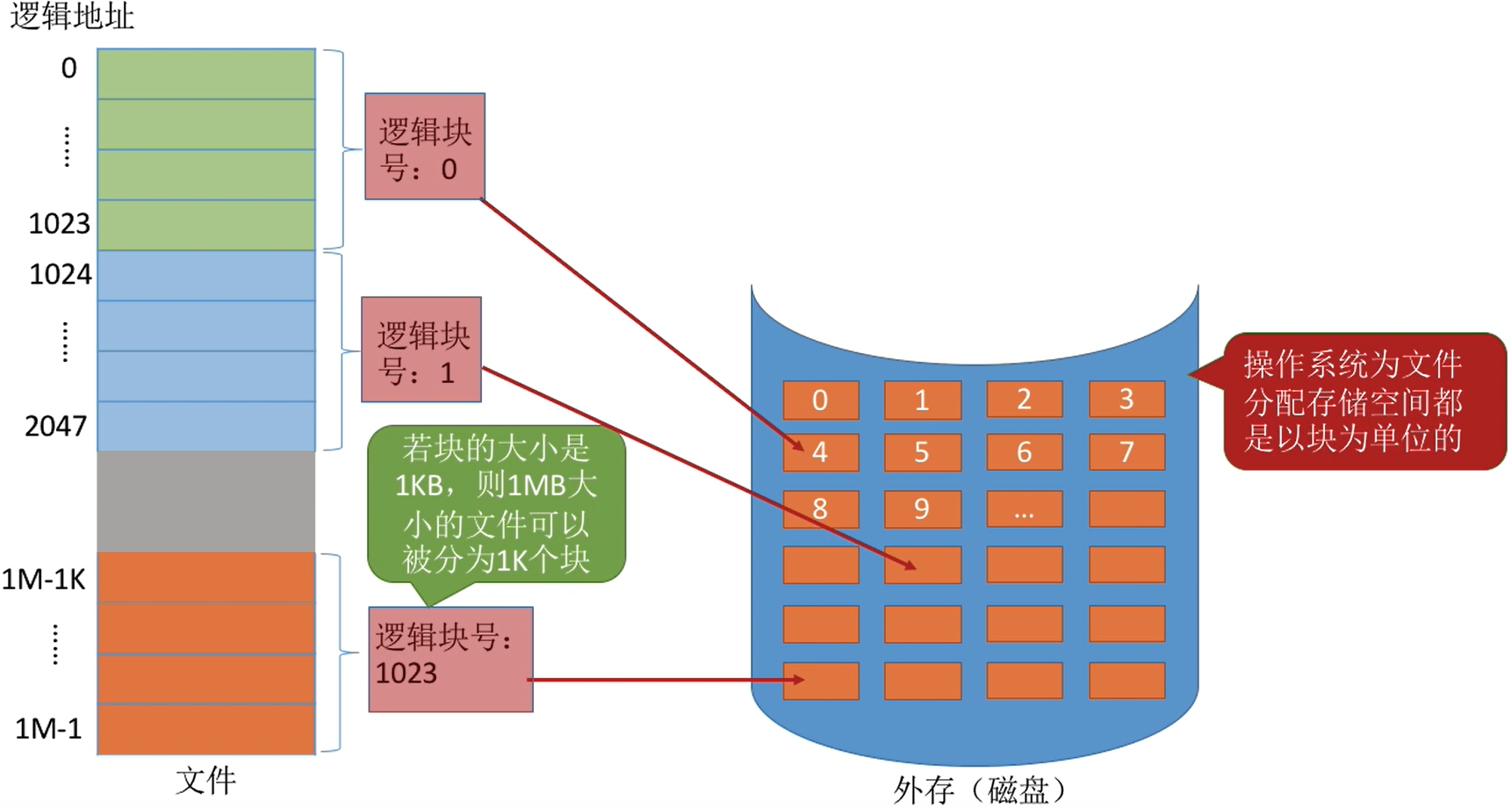
- 操作系统为文件分配存储空间都是以块为单位的
- 用户通过
逻辑地址来操作自己的文件,操作系统要负责实现从逻辑地址到物理地址的映射
(所以文件是有逻辑地址的,在文件的逻辑结构中使用的就是文件的逻辑地址,所以说有结构文件并不是连续存放的,有的逻辑地址可能为空)
- 但是逻辑地址和物理地址并不是一一对应的吧,而且是
- 而且
外存地址和文件的页面大小不一样吧。比如如果外存中有指针的话?那么内存是看不到这些指针,还是不能操作这些指针?- 对于内存的逻辑结构来说,地址肯定是连续的吧
- 不懂啊
4.6.2 文件分配方式
(1) 连续分配
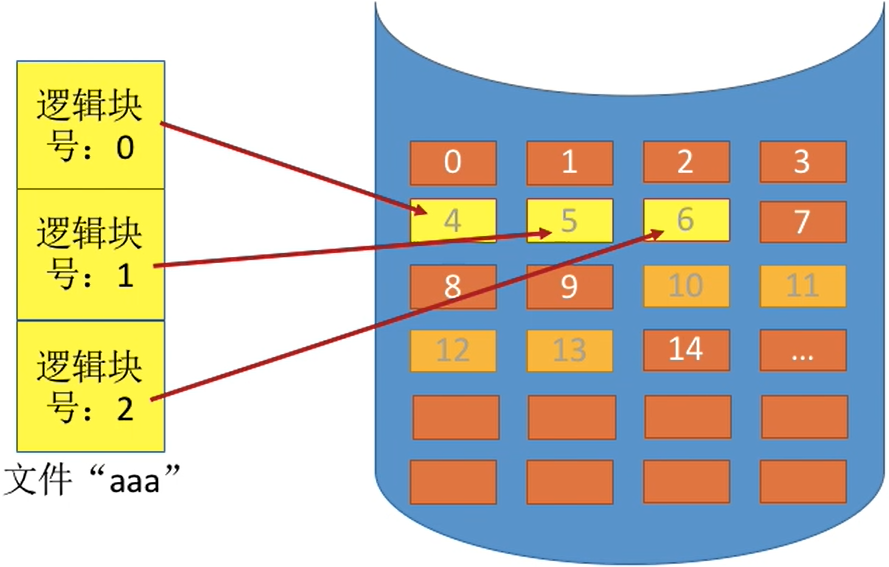
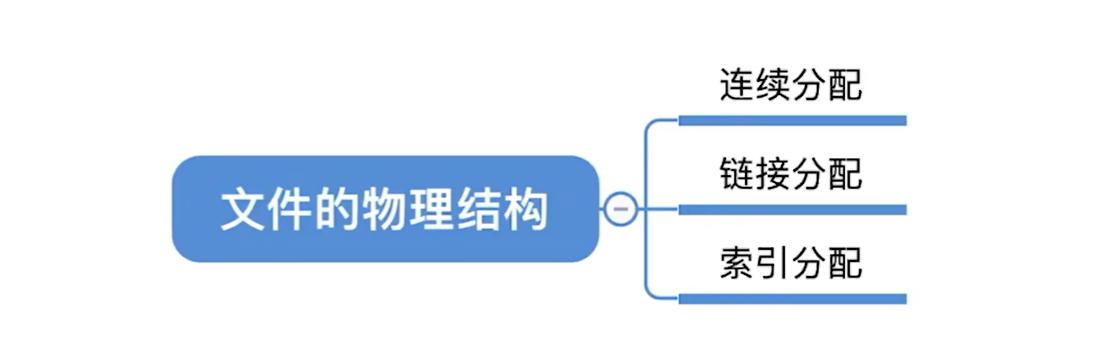
连续分配方式要求每个文件在磁盘上占有一组连续的块。
- 用户通过
逻辑地址来操作自己的文件,操作系统如何实现从逻辑地址到物理地址的映射? (逻辑块号,块内地址)→(物理块号,块内地址)。只需转换块号就行,块内地址保持不变
- 所以一个文件的逻辑地址还是用户管理的
- 当文件从硬盘移动到内存的过程中,需要进行文件
逻辑块号 → 物理块号的转换- 但是从内存写到硬盘的过程中,需要进行文件
物理块号 → 逻辑块号的转换
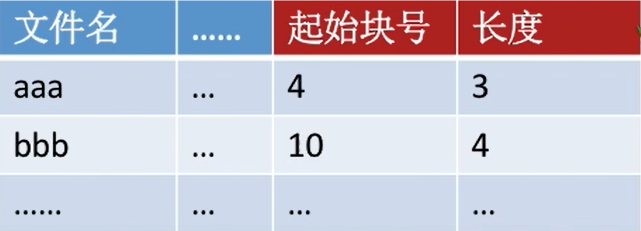
-
文件目录中记录存放的
起始块号和长度(总共占用几个块) -
用户给出要访问的逻辑块号,操作系统找到该文件对应的目录项(FCB),就是上图中的一项,主要是找到其起始块号 -
物理块号 = 起始块号+逻辑块号
-
当然,还需要检查用户提供的逻辑块号是否合法(逻辑块号≥长度就不合法)
优点:
- 这种方法 可以
直接算出逻辑块号对应的物理块号,因此连续分配支持顺序访问和直接访问(即随机访问) - 连续分配的文件在
顺序读/写时速度最快。
读取某个磁盘块时,需要移动磁头。访问的两个磁盘块相隔越远,移动磁头所需时间就越长。连续分配方式
要求每个文件在磁盘上占有一组连续的块,因此连续分配的文件在顺序读/写时速度最快。
缺点:
- 物理上采用连续分配的文件不方便拓展。
- 物理上采用连续分配,
存储空间利用率低,会产生难以利用的磁盘碎片
不方便拓展
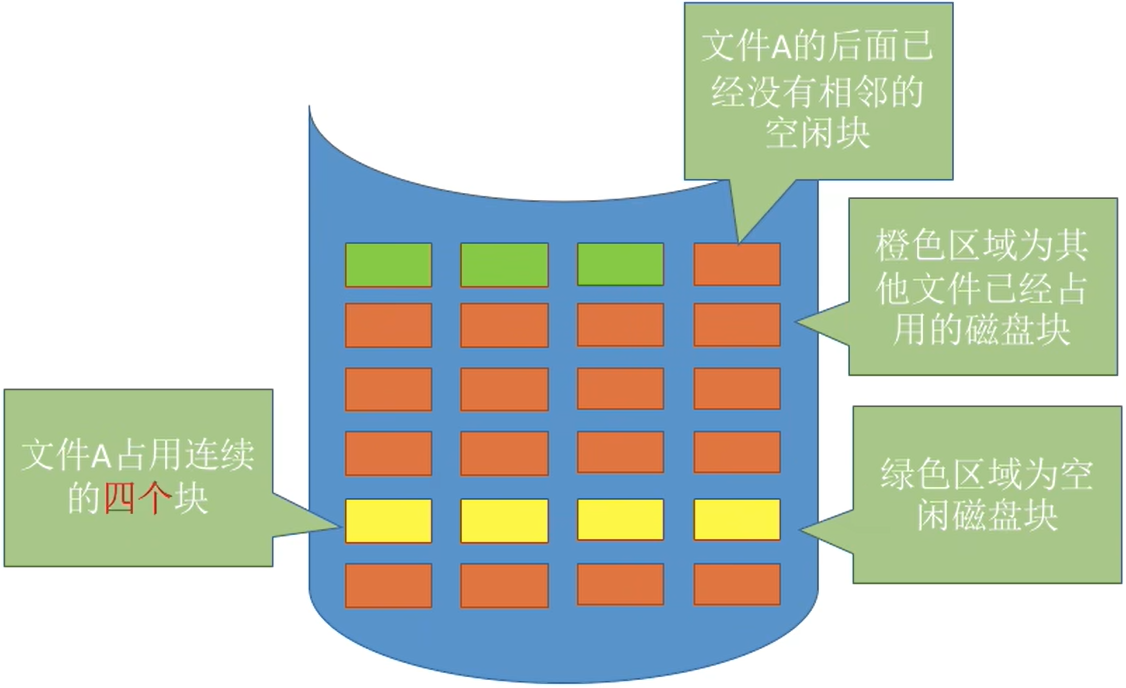
如图
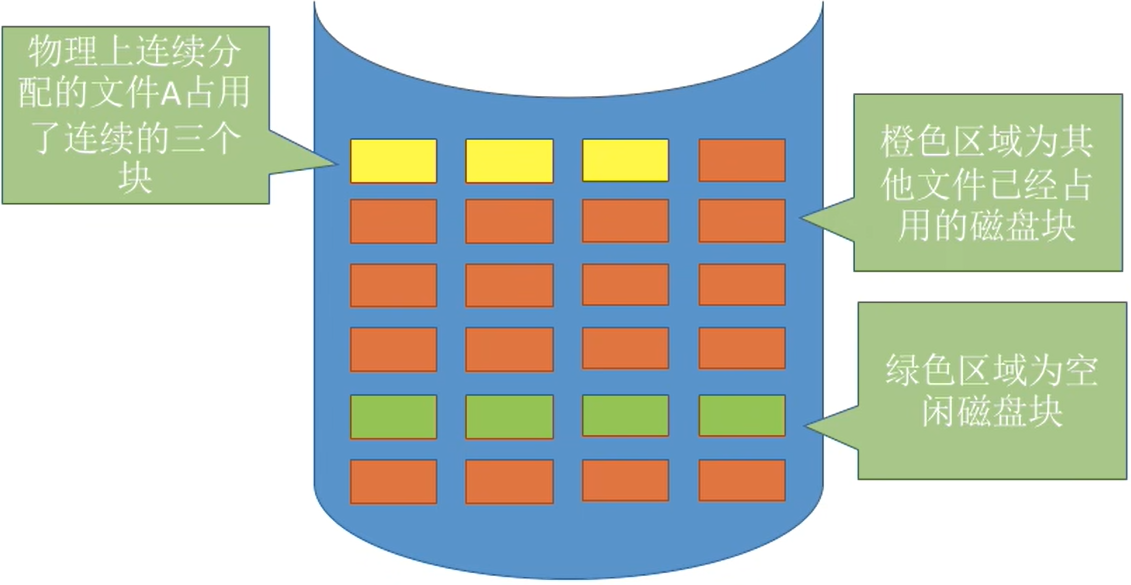
- 若此时文传A要拓展,需要再
增加一个磁盘块(总共需要连续的4个磁盘块)。 - 由于采用连续结构,因此文件A占用的磁盘块必须是连续的。
- 因此只能将文件A全部“迁移”到
绿色区域,如下图。
| 拓展前 | 拓展后 |
|---|---|
|
 |
产生磁盘碎片
如图
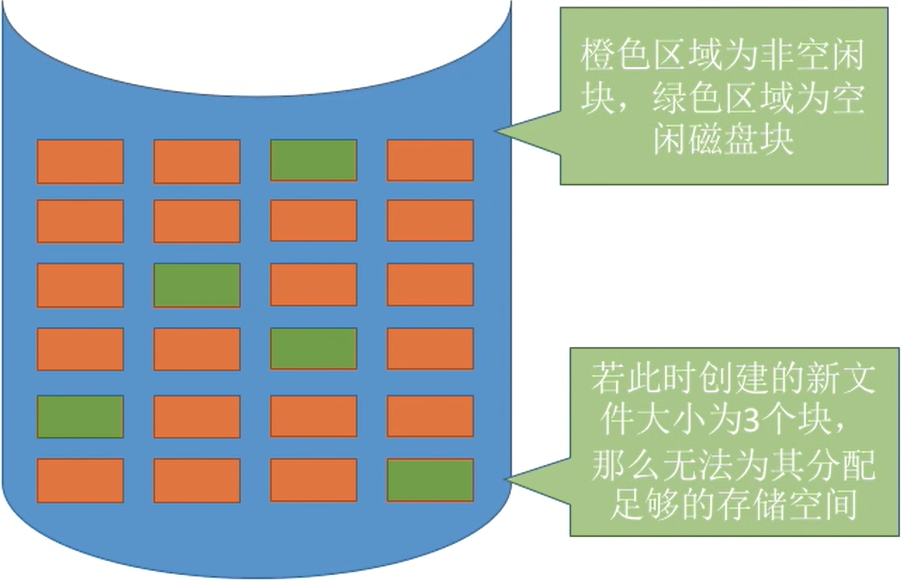
- 可以用紧凑来处理碎片,但是需要耗费很大的时间代价。
总结:连续分配方式要求每个文件在磁盘上占有一组连续的块。
优点:
- 支持顺序访问和直接访问(即随机访问)
- 连续分配的文件在顺序访问时速度最快
缺点
- 不方便文件拓展
- 存储空间利用率低,会产生磁盘碎片
(2) 链接分配
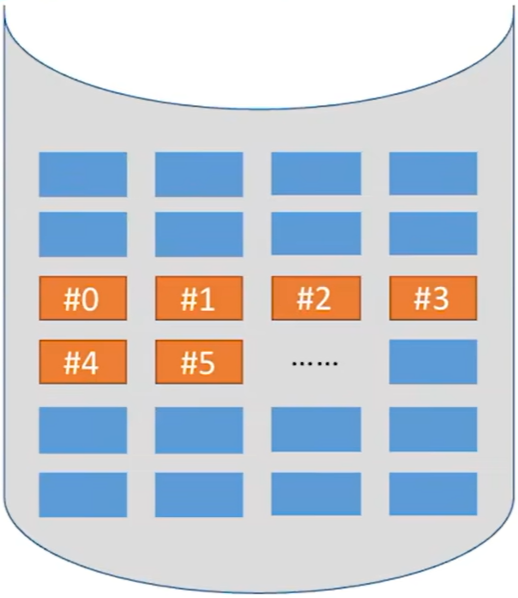
链接分配采取离散分配的方式,可以为文件分配离散的磁盘块。分为隐式链接和显式链接两种。
① 隐式链接
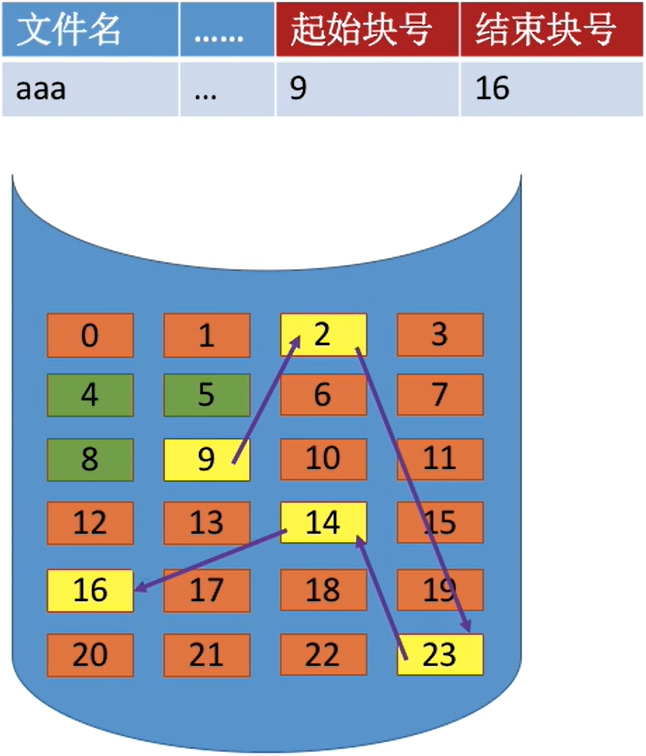
- 目录中记录了文件存放的
起始块号和结束块号。当然,也可以增加一个字段来表示文件的长度 - 除了
文件的最后一个磁盘块之外,每个磁盘块中都会保存指向下一个盘块的指针,这些指针对用户是透明的
如何实现文件的逻辑块号到物理块号的转变?
- 用户给出要访问的
逻辑块号i,操作系统找到该文件对应的目录项(FCB)
实际上给的是逻辑地址,不过能够很容易地从逻辑地址中分理出逻辑块号
- 从目录项FCB中找到起始块号(即0号块),将0号逻辑块读入内存,由此知道1号逻辑块存放的物理块号,于是读入1号逻辑块,再找到2号逻辑块的存放位置....以此类推。
- 因此,
读入i号逻辑块,总共需要i+1次磁盘I/O。
缺点:
- 采用链式分配(隐式链接)方式的文件,
只支持顺序访问,不支持随机访问,查找效率低。 - 另外,
指向下一个盘块的指针也需要耗费少量的存储空间。
是否方便拓展文件?
- 若此时要拓展文件,则可以
随便找一个空闲磁盘块,挂到文件的磁盘块链尾,并修改文件的FCB
优点:
- 采用隐式链接的链接分配方式,很
方便文件拓展。 - 另外,所有的空闲磁盘块都可以被利用,不会有碎片问题,
外存利用率高。
这和连续分配恰恰是相反的
总结:
隐式链接:除文件的最后一个盘块之外,每个盘块中都存有指向下一个盘块的指针。文件目录包括文件第一块的指针和最后一块的指针。
优点:
- 很方便文件拓展
- 不会有碎片问题,外存利用率高。
缺点:
- 只支持顺序访问,不支持随机访问,查找效率低
- 指向下一个盘块的指针也需要耗费少量的存储空间。
② 显示链接
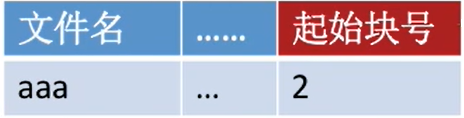
目录中只需记录文件的起始块号
- 把用于链接文件各物理块的指针显式地存放在一张表中。即
文件分配表(FAT,File Allocation Table) - 下一块为-1,表示这是文件结尾
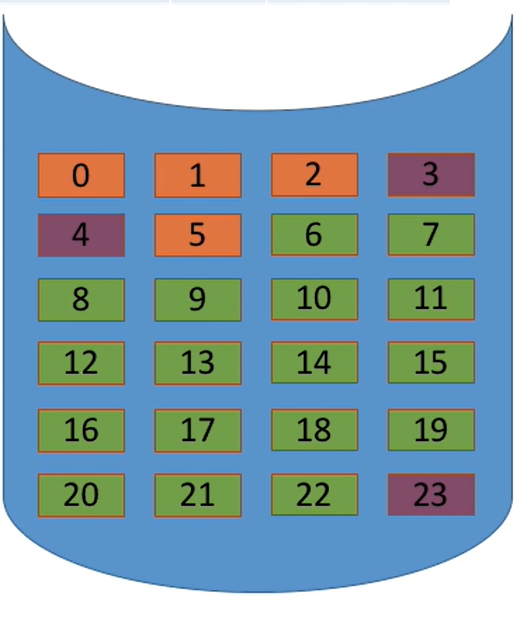
假设某个新创建的文件“aaa”依次存放在磁盘块2→5 →0→>1;假设某个新创建的文件“bbb”依次存放在磁盘块4→23 >3
| 硬盘分配情况 | FAT |
|---|---|
 |
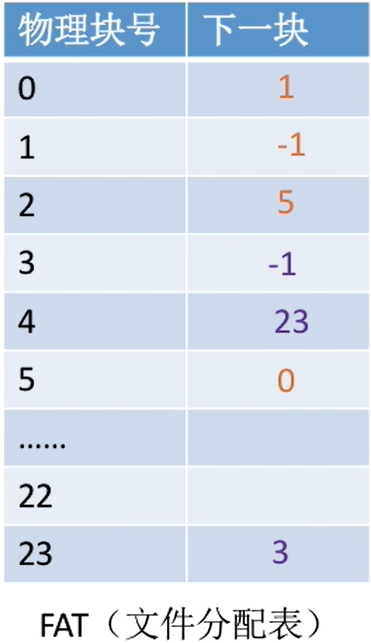 |
- 注意:
一个磁盘仅设置一张FAT。开机时,将FAT读入内存,并常驻内存。 - FAT的各个表项在物理上连续存储,且每一个表项长度相同,因此
“物理块号”字段可以是隐含的。
连续存储的数据,
并且长度是相同的,序号都是可以隐含的
如何实现文件的逻辑块号到物理块号的转变?
- 用户给出要访问的
逻辑块号i(实际上是给出逻辑地址,然后提取出逻辑块号),操作系统找到该文件对应的目录项(FCB) .... - 从目录项中找到起始块号,若i>0,则查询内存中的文件分配表FAT,往后找到i号逻辑块对应的物理块号。
- 逻辑块号转换成物理块号的过程不需要读磁盘操作(因为FAT就常驻在内存中)。
结论
优点:
- 采用链式分配(显式链接)方式的文件,
支持顺序访问,也支持随机访问(想访问i号逻辑块时,并不需要依次访问之前的0~ i-1号逻辑块) - 由于
块号转换的过程不需要访问磁盘,因此相比于隐式链接来说,访问速度快很多。 - 显然,显式链接也不会产生外部碎片,也可以很方便地对文件进行拓展。
- 这里支持随机访问,实际上也是要根据链表的顺序依次往后找到第i个块的物理块号
- 但是不同于隐式链接的是,隐式链接需要每个块都从磁盘读到内存中,但是显示链接由于FAB就在内存中,所以只要在内存中就能很快查到
- 因此可以随机访问磁盘
总结:
- 显式链接:把用于链接文件各物理块的指针显式地存放在一张表中,即文作分配表(FAT,File Allocation Table)。一个磁盘只会建立一张文件分配表。开机时文件分配表放入内存,并常驻内存。
优点
- 很方便文件拓展
- 不会有碎片问题,外存利用率高
- 并且支持随机访问。
- 相比于隐式链接来说,地址转换时不需要访问磁盘,因此文件的访问效率更高。
缺点
- 文件分配表的需要占用一定的存储空间。
考试题目中遇到未指明隐式/显式的“链接分配”,
默认指的是隐式链接的链接分配
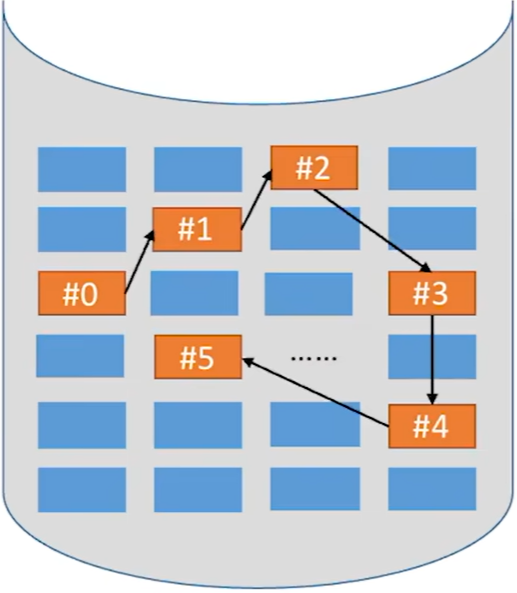
(3) 索引分配
① 索引分配原理
- 索引分配允许文件离散地分配在各个磁盘块中,系统会为每个文件建立一张索引表,索引表中记录了文件的
各个逻辑块对应的物理块 - (
索引表的功能类似于内存管理中的页表―—建立逻辑页面到物理页之间的映射关系)。 - 索引表存放的磁盘块称为
索引块。文件数据存放的磁盘块称为数据块。
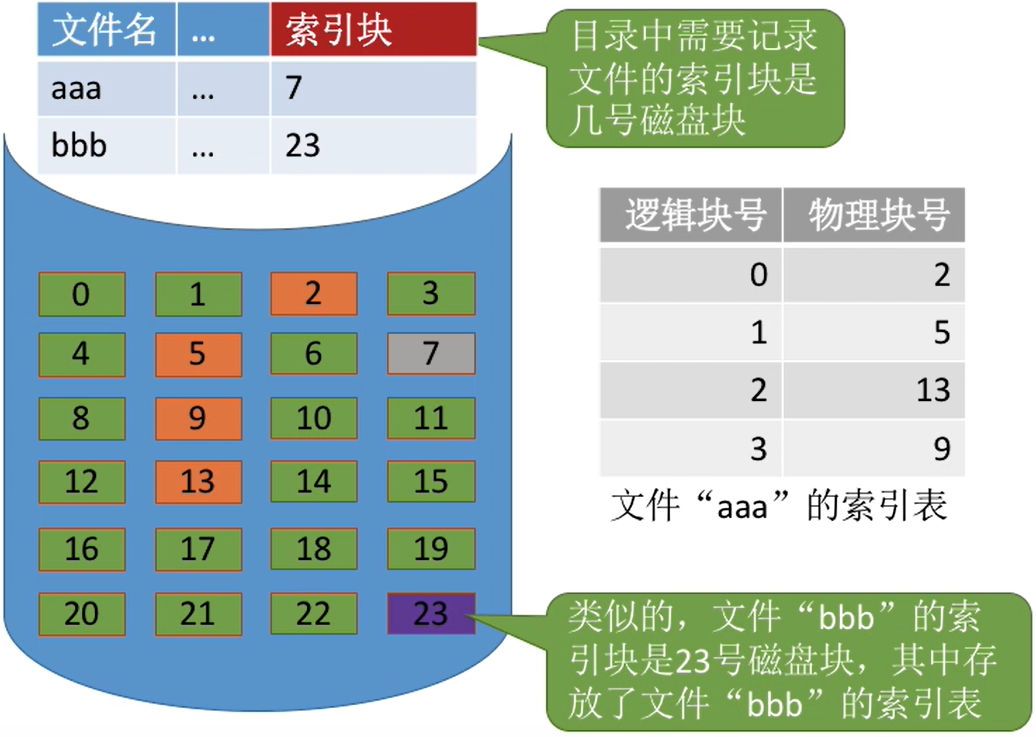
- 假设某个新创建的文件“aaa”的数据依次存放在磁盘块2→5→13→9
- 7号磁盘块作为“aaa”的索引块,索引块中保存了索引表的内容。
注:在
显式链接的链式分配方式中,文件分配表FAT是一个磁盘对应一张。而索引分配方式中,索引表是一个文件对应一张。
- 可以用固定的长度表示物理块号(如:假设磁盘总容量为1TB=240B,磁盘块大小为1KB,则共有230个磁盘块,则可用4B表示磁盘块号)
- 因此,索引表中的“逻辑块号”可以是隐含的。
如何实现文件的逻辑块号到物理块号的转换
- 用户给出要访问的逻辑块号i,操作系统找到该
文件对应的目录项(FCB), - 从目录项FCB中可知索引表存放位置,将索引表从外存读入内存,并查找索引表即可只i号逻辑块在外存中的存放位置。
- 可见,索引分配方式可以支持随机访问。
- 文件拓展也很容易实现(只需要
给文件分配一个空闲块,并增加一个索引表项即可) - 但是
索引表需要占用一定的存储空间
问题:
- 若每个磁盘块1KB,一个索引表项4B,则一个磁盘块只能存放256个索引项。
如果一个文件的大小超过了256块,那么一个磁盘块是装不下文件的整张索引表的,如何解决这个问题?
- 链接方案
- 多层索引
- 混合索引
索引表也是数据,也需要存放,这里是将索引表作为文件了
② 链接方案索引表
链接方案:如果索引表太大,一个索引块装不下,那么可以将多个索引块链接起来存放。
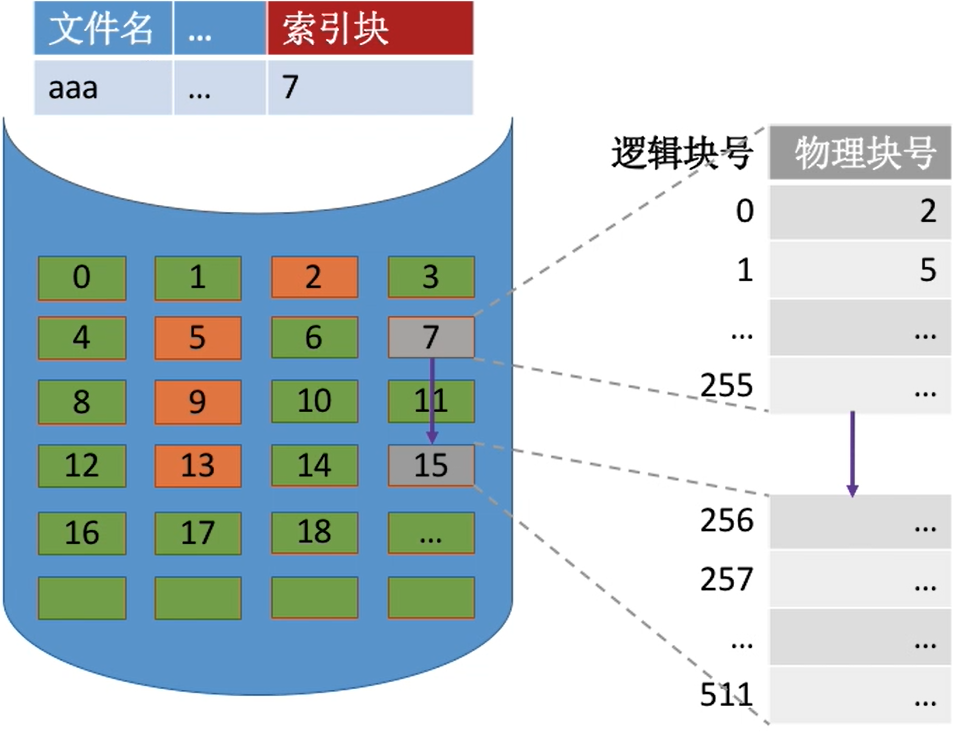
- 假设磁盘块大小为1KB,一个索引表项占4B,则一个磁盘块只能存放256个索引项。
- 若一个文件大小为256*256KB =65,536 KB = 64MB
- 该文件共有256*256个块,也就对应256*256个索引项,也就需要256个索引块来存储,这些索引块用链接方案连起来。
- 若想要
访问文件的最后一个逻辑块,就必须找到最后一个索引块(第256个索引块),而各个索引块之间是用指针链接起来的,因此必须先顺序地读入前255个索引块。 - 低效
但是实际上物理块存储指针也要空间的,上面说的只是理想情况吧
② 多层索引索引表
② 多层索引:建立多层索引(原理类似于多级页表)。
使第一层索引块指向第二层的索引块。还可根据文件大小的要求再建立第三层、第四层索引块。
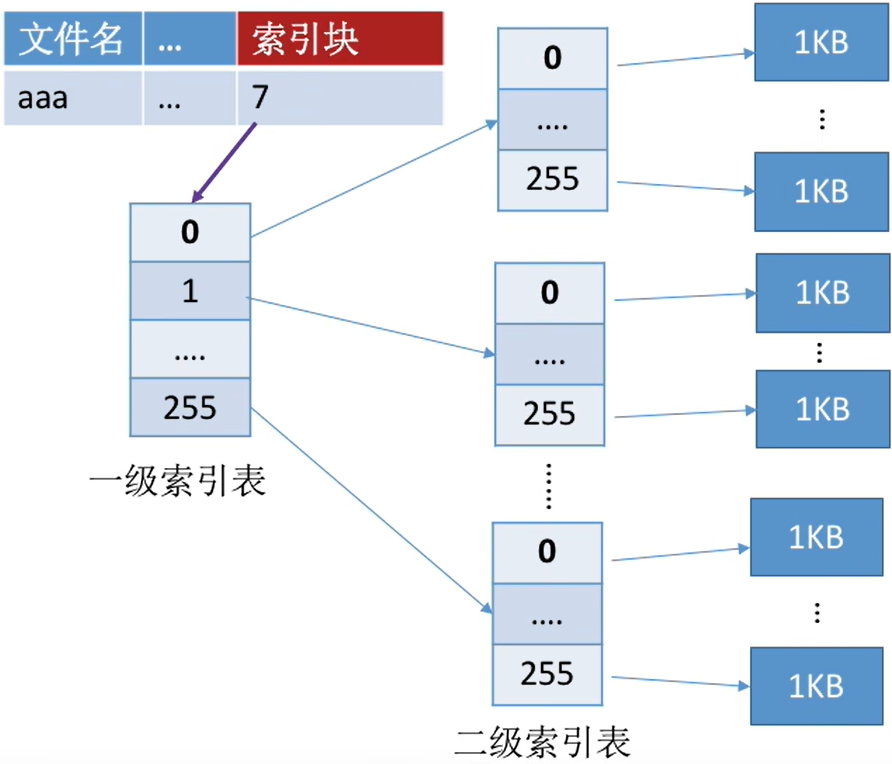
- 假设磁盘块大小为1KB,一个索引表项占4B,则
一个磁盘块只能存放256个索引项。 - 若某文件采用两层索引,则该文件的最大长度可以到256*256*1KB= 65,536 KB = 64MB
- 可根据逻辑块号算出应该查找索引表中的哪个表项。如:要访问1026号逻辑块,则
1026/256= 4,1026%256= 2 - 因此可以
先将一级索引表调入内存,查询4号表项,将其对应的二级索引表调入内存,再查询二级索引表的2号表项即可知道1026号逻辑块存放的磁盘块号了。 访问目标数据块,需要3次磁盘I/O。
多级索引表,每集索引的物理地址都是一样的
- 若采用三层索引,则文件的最大长度为256*256*256*1KB = 16GB
- 类似的,访问目标数据块,需要4次磁盘I/O
采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要K+1次读磁盘操作
缺点:假如一个文件很小,那么二级索引也需要进行三次读磁盘的操作
③ 混合索引索引表
③ 混合索引:多种索引分配方式的结合。
- 例如,一个文件的顶级索引表中,既包含直接地址索引(直接指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表)。
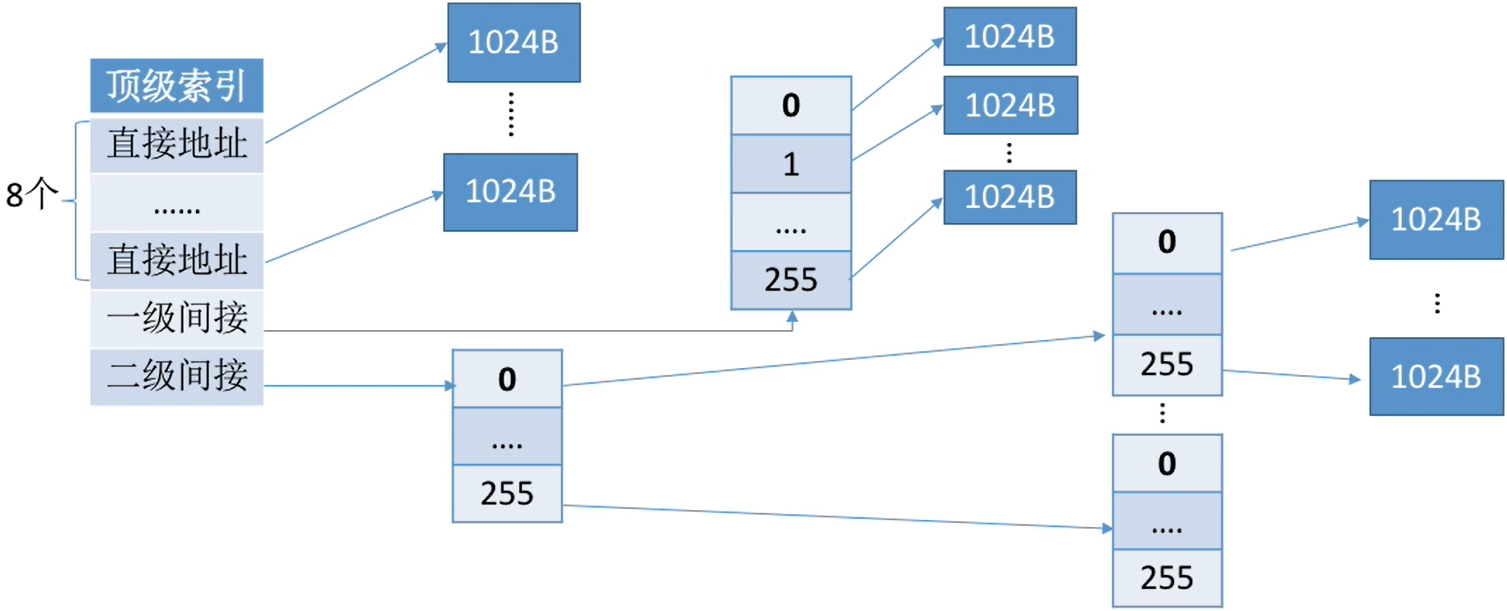
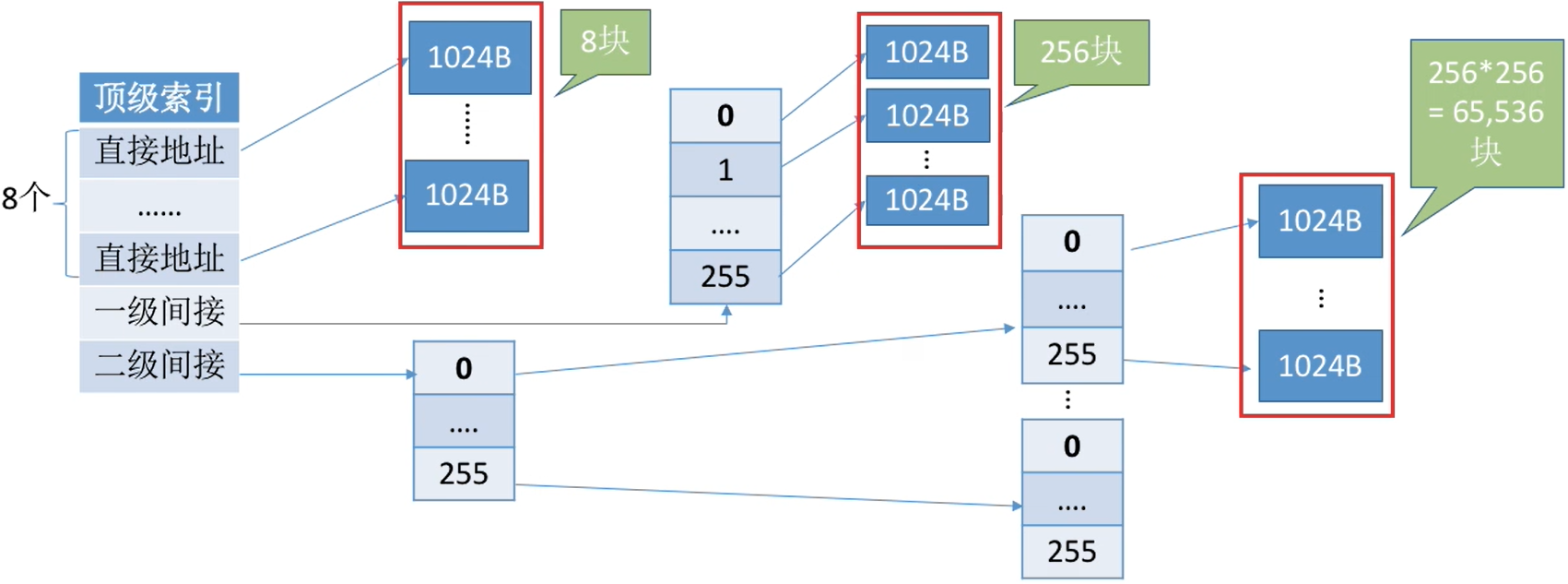
- 这种结构的索引支持的最大文件长度为65800KB
这是一种考题
- (虽然存储的少了,但是对于小文件来说,读取速率快了)
对于小文件,只需较少的读磁盘次数就可以访问目标数据块。(一般计算机中小文件更多)
若顶级索引表还没
- 读入内存访问0~7号逻辑块:两次读磁盘
- 访问8~263:三次读磁盘
- 访问264~65799:四次读磁盘
包括将顶级索引读入内存的访问
总结
索引分配允许文件离散地分配在各个磁盘块中,系统会为每个文件建立一张索引表,索引表中记录了文件的各个逻辑块对应的物理块(索引表的功能类似于内存管理中的页表――建立逻辑页面到物理页之间的映射关系)。- 索引表存放的磁盘块称为索引块。文件数据存放的磁盘块称为数据块。
- 若文件太大,索引表项太多,可以采取以下三种方法解决:
- 链接方案:如果索引表太大,一个索引块装不下,那么可以将多个索引块链接起来存放。缺点:若文件很大,索引表很长,就需要将很多个索引块链接起来。想要找到i号索引块,必须先依次读入0~i-1号索引块,这就导致磁盘I/O次数过多,查找效率低下。
- 多层索引:建立多层索引(原理类似于多级页表)。使第一层索引块指向第二层的索引块。还可根据文件大小的要求再建立第三层、第四层索引块。采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要K+1次读磁盘操作。缺点:即使是小文件,访问一个数据块依然需要K+1次读磁盘。
- 混合索引:多种索引分配方式的结合。例如,一个文件的顶级索引表中,既包含直接地址索引(直接指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表)。优点:对于小文件来说,访问一个数据块所需的读磁盘次数更少
超级超级超级重要考点:
- 要会根据多层索引、混合索引的结构计算出文件的最大长度(Key:各级索引表最大不能超过一个块)
- 要能自己分析访问某个数据块所需要的读磁盘次数(Key:FCB中会存有指向顶级索引块的指针,因此可以根据FCB读入顶级索引块。每次读入下一级的索引块都需要一次读磁盘操作。另外,要注意题目条件――
顶级索引块是否已调入内存)
(4) 比较
| 实现 | 目录项内容 | 优点 | 缺点 | |
|---|---|---|---|---|
| 顺序分配 | 为文件分配的必须是连续的磁盘块 | 起始块号、文件长度 | 顺序存取速度快,支持随机访问 | 会产生碎片,不利于文件拓展 |
| 链接分配(隐式链接) | 除文件的最后一个盘块之外,每个盘块中都存有指向下一个盘块的指针 | 起始块号、结束块号 | 可解决碎片问题,外存利用率高,文件拓展实现方便 | 只能顺序访问,不能随机访问。 |
| 连接分配(显示链接) | 建立一张文件分配表(FAT),显式记录盘块的先后关系(开机后FAT常驻内存) | 起始块号 | 除了拥有隐式链接的优点之外,还可通过查询内存中的FAT实现随机访问 | FAT需要占用一定的存储空间 |
| 索引分配 | 为文件数据块建立索引表。若文件太大,可采用链接方案、多层索引、混合索引 | 链接方案记录的是第一个索引块的块号,多层/混合索引记录的是顶级索引块的块号 | 支持随机访问,易于实现文件的拓展 | 索引表需占用一定的存储空间。访问数据块前需要先读入索引块。若采用链接方案,查找索引块时可能需要很多次读磁盘操作。 |
逻辑结构VS物理结构
| 逻辑结构 | 物理结构 |
|---|---|
 |
 |
容易理解的一点是,无结构文件肯定是按顺序依次存储的,这个好理解
下面是一个例子,用C语言创建无结构文件
FILE *fp = fopen("test.txt", "w"); // 打开文件
if (fp == NULL) {
printf("打开文件失败!");
exit(0);
}
// 写入一个HelloWorld
for (int i = 0; i < 10000; i++)
fputs("Hello World!", fp);
fclose(fp); // 关闭文件
4.5.1 逻辑结构(从用户视角看)

Eg:你要找到第16个字符(从编号0开始)
FILE *fp = fopen("test.txt", "r"); // 以"读"方式打开文件
if ( fp == NULL) {
puts("Fail to open file!");
exit(0);
}
fseek(fp, 16, SEEK_SET); // 读写指针移向16
char c = fgetc(fp); // 从读写指针所指位置读出1个字符
printf("字符:%c", c); // 打印从文件中读出的字符
fclose(fp); // 关闭文件

- 这里的16指的就是逻辑地址,用户用逻辑地址访问文件
4.5.2 物理结构(从操作系统视角看)

| 连续分配(逻辑上相邻的物理上也相邻) | 链接分配(逻辑上相邻的块在物理上用链接指针表示先后关系) | 索引分配 (操作系统为每个文件维护一张索引表,其中记录了逻辑块号→物理块号的映射关系) |
|---|---|---|
 |
 |
 |
用户:
- 使用C语言库函数fseek,将文件读写指针指向位置n(指明逻辑地址)
- 使用C语言库函数fgetc,从文件指针所指位置读出1B内容
fgetc底层使用了 Read系统调用,操作系统将
(逻辑块号,块内偏移量)转换为(物理块号,块内偏移量)
下面是案例,用C语言创建顺序文件
typedef struct {
int number; // 学号
char name[30]; // 姓名
char major[30]; // 专业
} Student_info;
// 以写方式打开文件
FILE *fp = fopen("students.info", "w");
if(fp == NULL) {
printf("打开文件失败!");
exit(0);
}
Student_info student[N]; // 用数组保存N个学生信息
for(int i = 0; i < N; i++) { // 生成N个学生信息
student[i].number = i;
student[i].name[0] = '?';
student[i].major[0] = '?';
}
// 将N个学生的信息写入文件
fwrite(student, sizeof(Student_info), N, fp);
fclose(fp);
- 写的时候指明了文件指针fp
- 将整个数组都按顺序写入了

// 以"读"的方式打开文件
FILE *fp = fopen("students.info", "r");
if (fp == NULL) {
printf("打开文件失败!");
exit(0);
}
//文件读写指针指向编号为5的学生记录 !
fseek(fp,5*sizeof(Student_info) , SEEK_SET);
Student_info stu;
//从文件读出1条记录,记录大小为sizeof(Student_info)
fread(&stu, sizeof(Student_info), 1, fp);
printf("学生编号:%d\n", stu.number);
fclose(fp);
- 用fseek移动指针
逻辑上看来,是存储到一块的,实际上的物理结构是不能一起的
| 逻辑结构 | 物理结构 |
|---|---|
|
 |
| 连续分配 | 链接分配 | 索引分配 |
|---|---|---|
|
|
|
区分点:顺序文件采用顺序存储 / 链式存储
顺序文件:各个记录可以顺序存储或链式存储。
| 顺序存储(支持随机访问:指可以直接确定第i条记录的逻辑地址) | 链式存储 |
|---|---|
 |
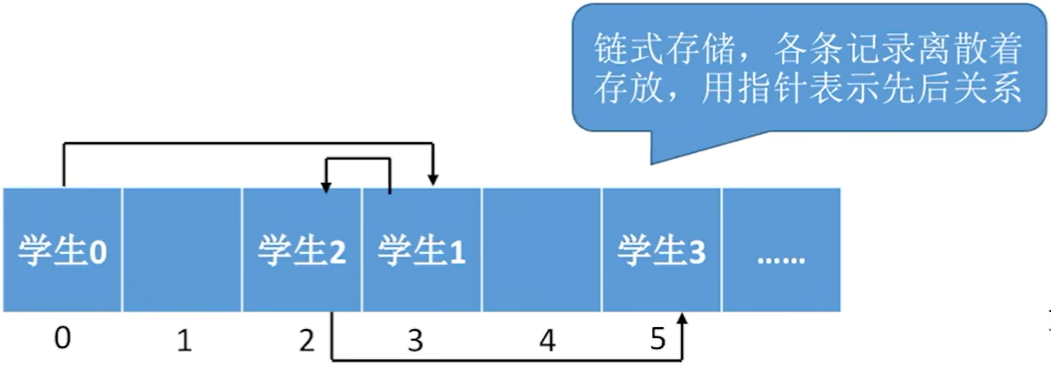 |
/*顺序存储*/
typedef struct {
int number; // 学号
char name[30]; // 姓名
char major[30]; // 专业
} Student_info;
/*链式存储*/
typedef struct {
int number; // 学号
char name[30]; // 姓名
char major[30]; // 专业
int next; // 下一个学生记录存放的位置
} Student_info;
| 逻辑结构 | 物理结构 |
|---|---|
|
|
| 连续分配 | 链接分配 | 索引分配 |
|---|---|---|
|
|
|
物理上分块之后不一定连续存放
逻辑结构为索引文件的呢?
typedef struct {
int number; // 学号
int addr; // 学生记录的逻辑地址
} IndexTable;
typedef struct {
char name[30]; // 姓名
char major[30]; // 专业
// 还可添加其他各种各样的学生信息
} Student_info;

- 索引文件的前面一部分是索引项,后面一部分是数据信息
| 逻辑结构 | 物理结构 |
|---|---|
|
|
| 连续分配 | 链接分配 | 索引分配 |
|---|---|---|
|
|
|
- 链接分配中的指针,索引分配中的索引表,这些都不属于文件内容(这些是组织文件的额外信息)
- 但是逻辑结构中的索引表属于文件当中的内容
- 索引文件的索引表:用户自己建立的,映射:关键字→记录存放的逻辑地址
- 索引分配的索引表:操作系统建立的,映射:逻辑块号→物理块号
也就是操作系统根本不管文件里面写着什么
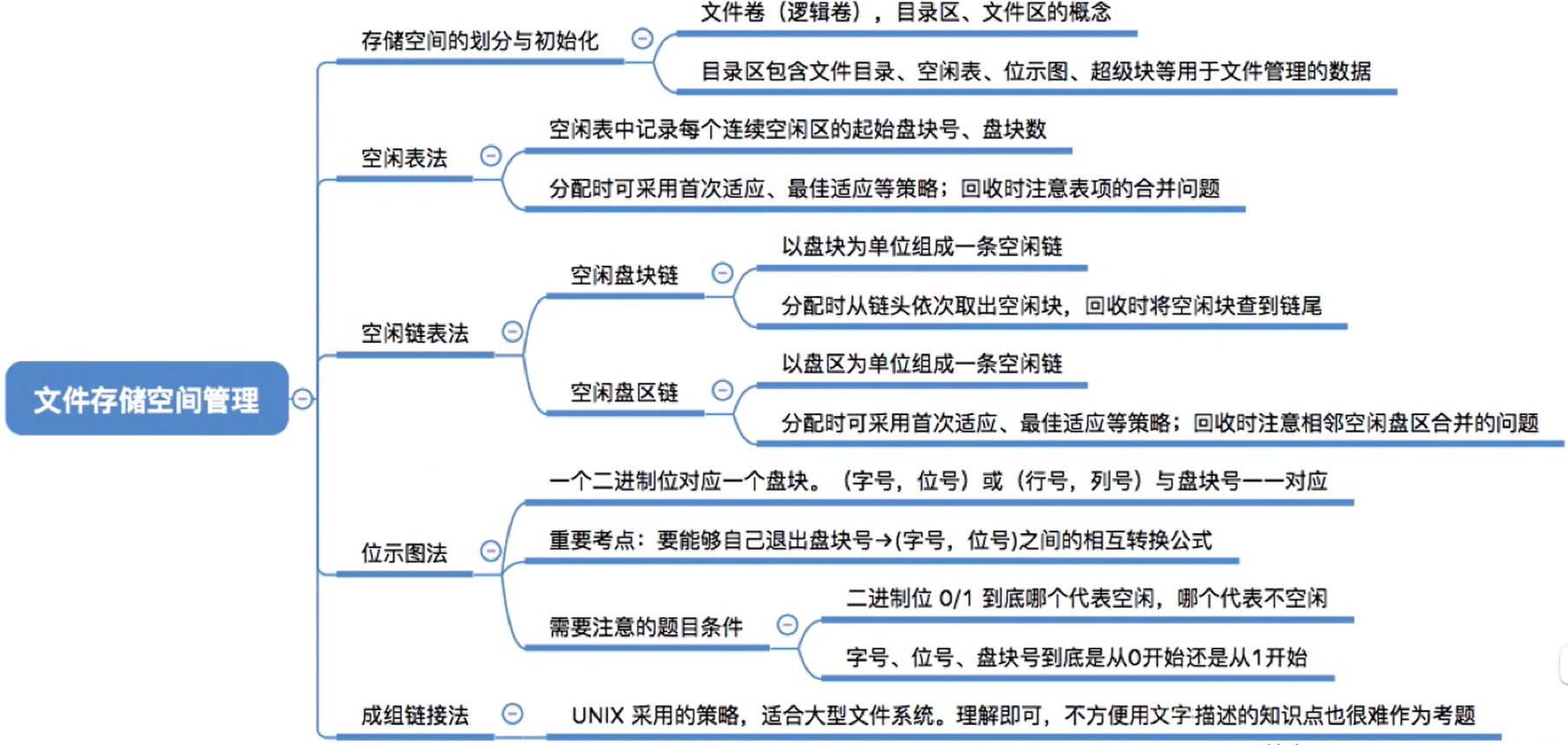
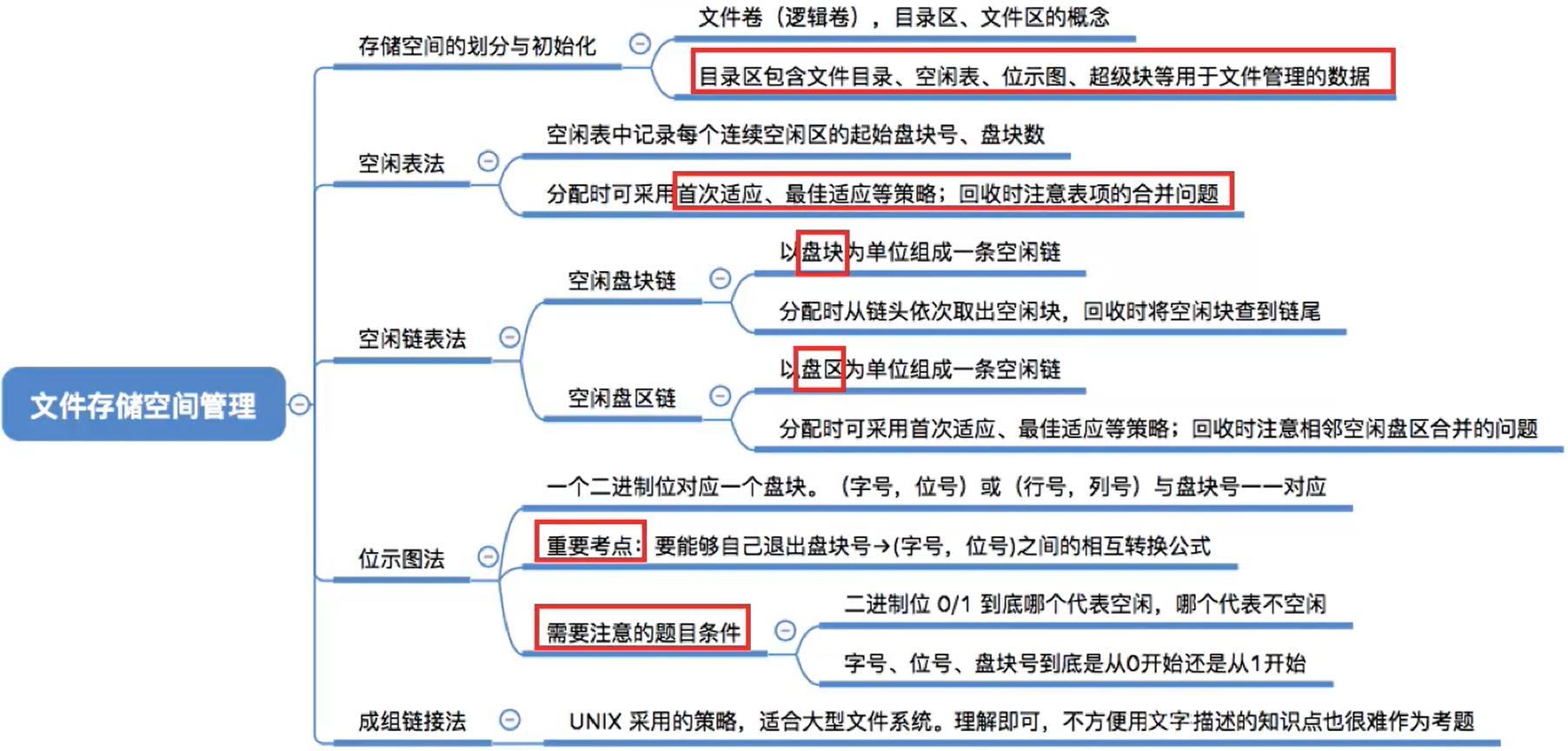
4.7 辅助分配模块(存储空间管理)
本节管理的是对非空闲磁盘块的管理
已经使用的空间不属于这个犯愁,因为已经使用的空间由FCB管理
对于管理方法:
学习时注意从三个方面进行理解:
- 用什么方式记录、组织空闲块?
- 如何分配磁盘块
- 如何回收磁盘块
4.7.1 存储空间的划分与初始化
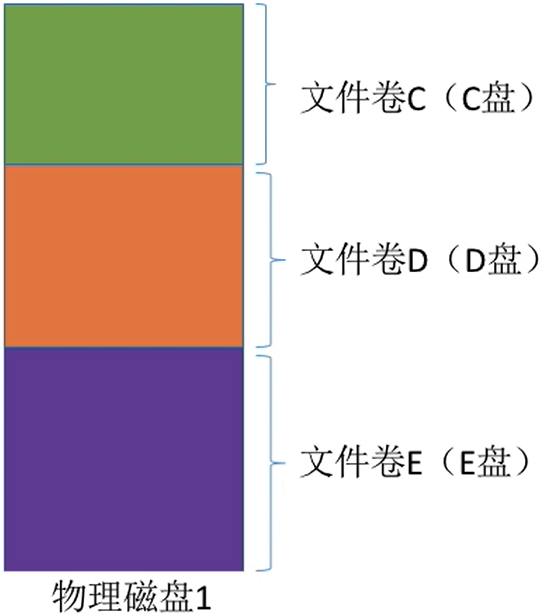
安装Windows操作系统的时候,一个必经步骤是――为磁盘分区(C:盘、D:盘、E:盘等)
- 存储空间的划分:将物理磁盘划分为一个个文件卷(逻辑卷、逻辑盘)
- 存储空间的初始化:将各个文件卷划分为目录区、文件区
| 存储空间的划分 | 存储空间的初始化 |
|---|---|
 |
 |
- 目录区:主要存放文件目录信息(FCB)于磁盘存储空间管理的信息(这里的FCB是只是根目录的吧,每个目录都有一个文件目录用来管理本文件)
- 文件区:用于存放文件数据
现在大部分的笔记本电脑,硬盘只有一个
- 第一种:只有一个机械硬盘,或者一个固态硬盘。
- 第二种:混合硬盘。 一个机械硬盘,一个固态硬盘。 ——百度
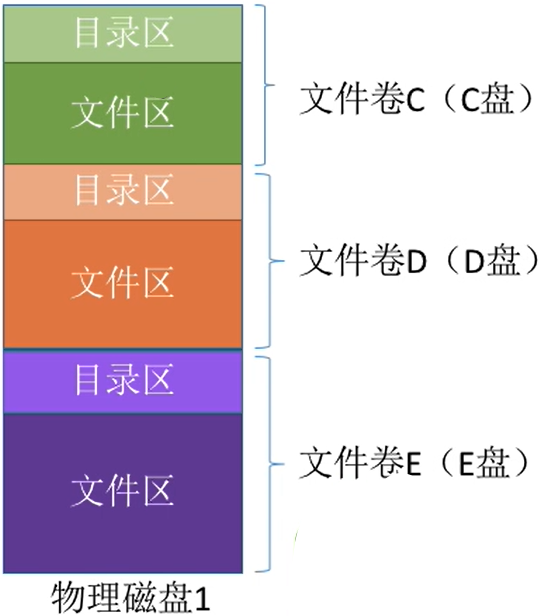
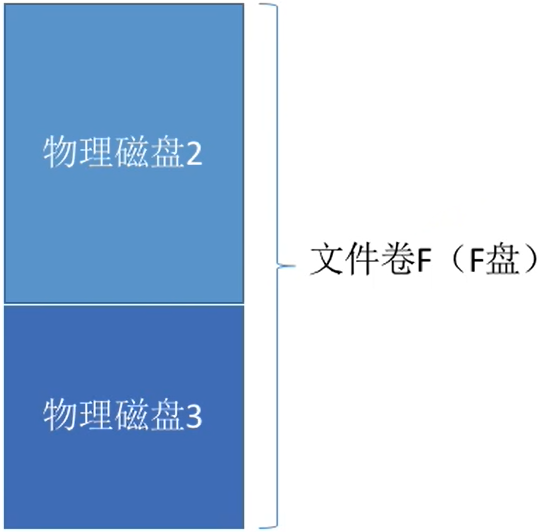
有的系统支持超大型文件,可支持由多个物理磁盘组成一个文件卷
4.7.2 存储空间管理
学习时注意从三个方面进行理解:
- 用什么方式记录、组织空闲块?
- 如何分配磁盘块
- 如何回收磁盘块
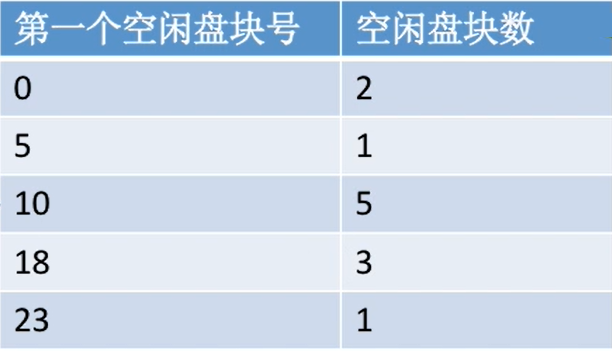
(1) 空闲表法
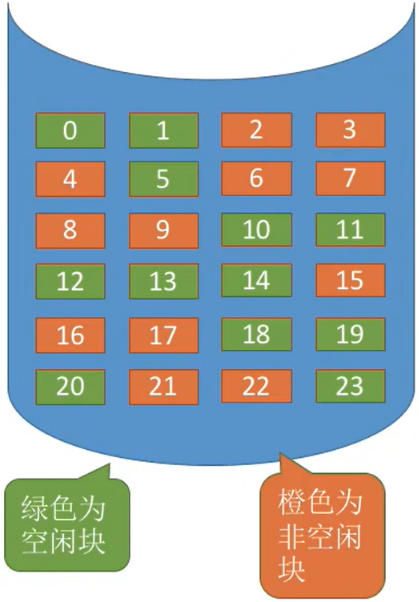
- 用什么方式记录、组织空闲块?
和内存管理的空闲内存表差不多
| 硬盘空间 | 空闲盘块表 |
|---|---|
 |
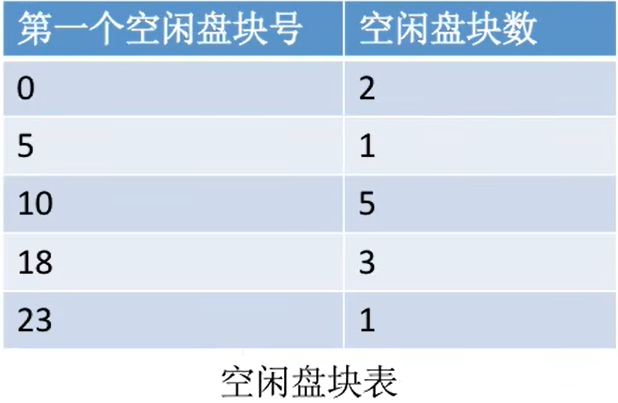 |
| 第一个空闲盘块号 | 空闲盘块数 |
|---|---|
| 0 | 2 |
| 5 | 1 |
| 10 | 5 |
| 18 | 3 |
| 23 | 1 |
- 如何分配磁盘块
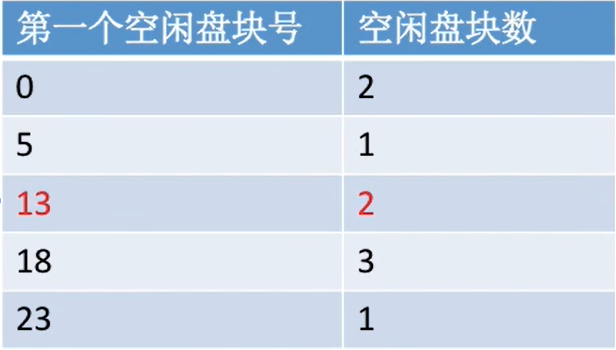
如何分配磁盘块:与内存管理中的动态分区分配很类似,为一个文件分配连续的存储空间。
同样可采用首次适应、最佳适应、最坏适应等算法来决定要为文件分配哪个区间。
例如首次适应
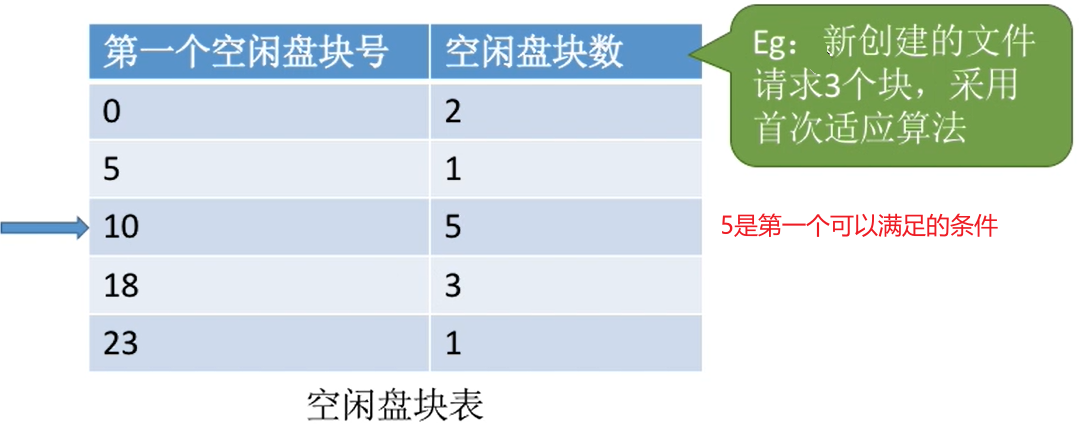
| 分配前 | 分配后 |
|---|---|
 |
 |
- 如何回收磁盘块
如何回收磁盘块:与内存管理中的动态分区分配很类似。当回收某个存储区时需要有四种情况
- 回收区的前后都没有相邻空闲区
- 回收区的前后都是空闲区
- 回收区前面是空闲区
- 回收区后面是空闲区。
总之,回收时需要注意表项的合并问题。
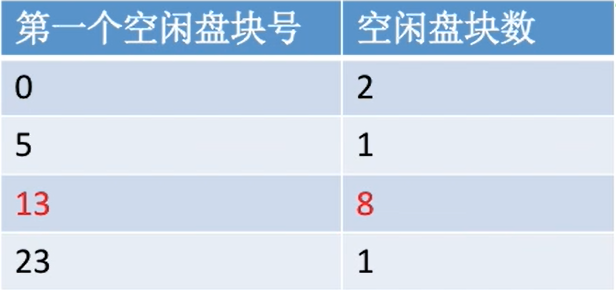
Eg:假设此时删除了某文件,系统回收了它占用的15 16 17号的块
| 删除前 | 删除后 |
|---|---|
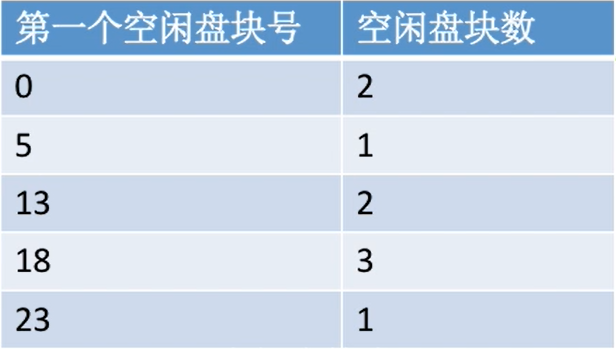 |
 |
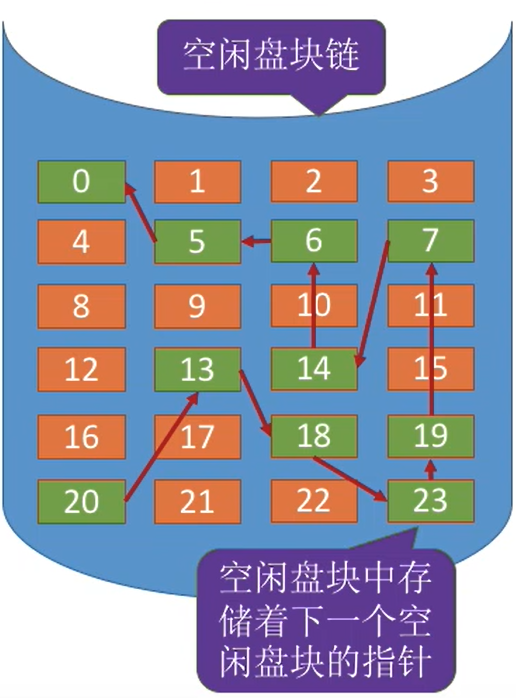
(2) 空闲链表法

| 空闲盘块链 | 空闲盘区链 |
|---|---|
 |
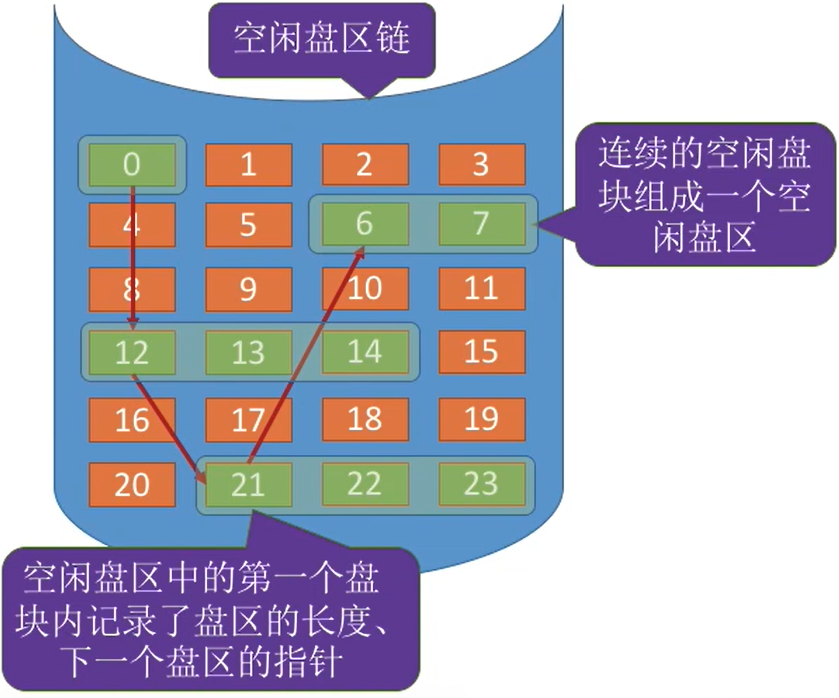 |
- 空闲盘区链中,该盘区所有的信息都记录在第一个盘块
① 空闲链表法
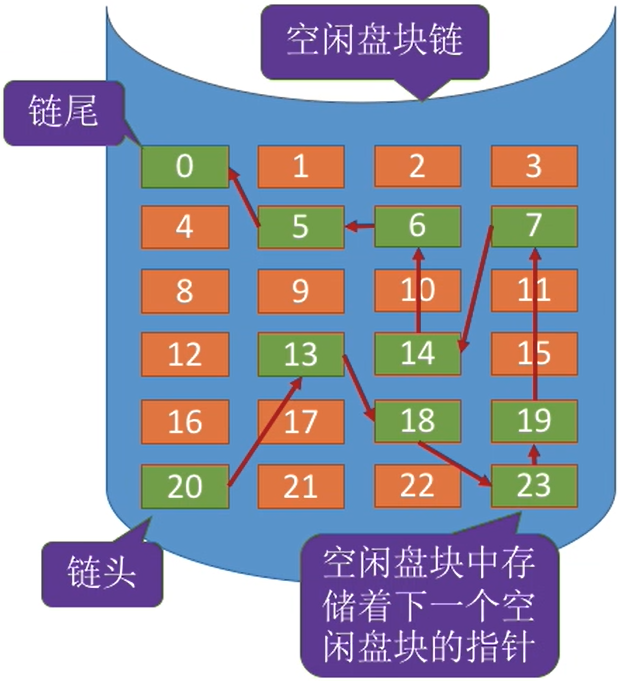
- 操作系统保存着链头、链尾指针。
- 如何分配:若某文件
申请K个盘块,则从链头开始依次摘下K个盘块分配,并修改空闲链的链头指针。 - 如何回收:回收的盘块
依次挂到链尾,并修改空闲链的链尾指针。
适用于离散分配的物理结构。为文件分配多个盘块时可能要重复多次操作
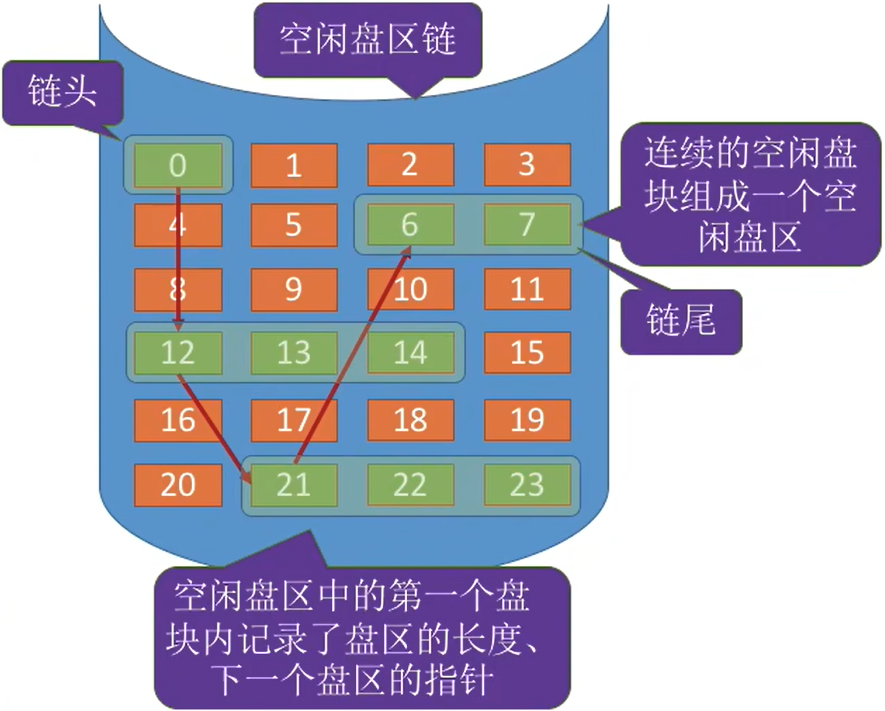
② 空闲盘块法
- 操作系统保存着链头、链尾指针。
如何分配:若某文件申请K个盘块,则可以采用首次适应、最佳适应等算法,从链头开始检索,按照算法规则找到一个大小符合要求的空闲盘区,分配给文件。若没有合适的连续空闲块,也可以将不同盘区的盘块同时分配给一个文件,注意分配后可能要修改相应的链指针、盘区大小等数据。如何回收:若回收区和某个空闲盘区相邻,则需要将回收区合并到空闲盘区中。若回收区没有和任何空闲区相邻,将回收区作为单独的一个空闲盘区挂到链尾。
离散分配、连续分配都适用。为一个文件分配多个盘块时效率更高
(3) 位示图法
| 硬盘空间 | 位示图 |
|---|---|
 |
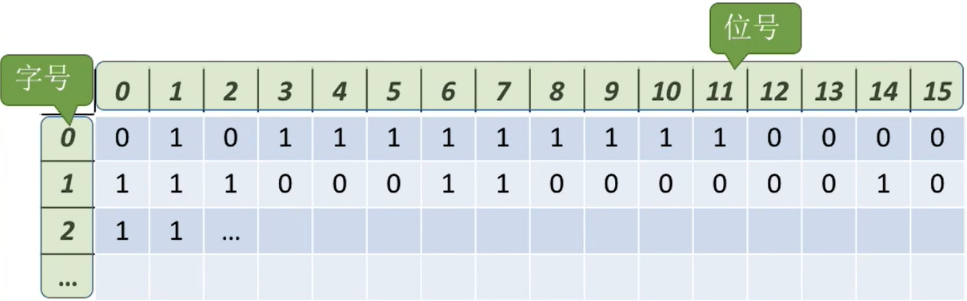 |
- 位示图:每个
二进制位对应一个盘块。在本例中,“0”代表盘块空闲,“1”代表盘块已分配。 - 位示图一般用连续的“
字”来表示,如本例中一个字的字长是16位,字中的每一位对应一个盘块。因此可以用(字号,位号)对应一个盘块号。 - 当然有的题目中也描述为(行号,列号)
重要重要重要:要能自己推出
盘块号与(字号,位号)相互转换的公式。
如本例中盘块号、字号、位号从0开始,若n表示字长,则
(字号,位号)=(i,j)的二进制位对应的盘块号b=ni+j- b号盘块对应的字号
i= b/n,位号j= b%n
例如
- (0,1) → b = 16 * 0 + 1 = 1
- (1, 10) → b = 16 * 1 + 10 = 26
- b = 13 → i = 13 / 16 = 0,j = 13 % 16 = 13
- b = 31 → i = 31 / 16 = 1,j = 31 % 16 = 15
注意题目条件:盘块号、字号、位号到底是从0开始还是从1开始
- 如何分配:若文件需要k个块:
- 顺序扫描位示图,找到K个相邻或不相邻的“0”
- 根据字号、位号算出对应的盘块号,将相应盘块分配给文件
- 将相应位设置为“1”。
- 如何回收
- 根据回收的盘块号计算出对应的字号、位号
- 将相应二进制位设为“0”
连续分配、离散分配都适用
(4) 成组链接法
- 空闲表法、空闲链表法不适用于大型文件系统,因为空闲表或空闲链表可能过大。UNIX系统中采用了
成组链接法对磁盘空闲块进行管理。 文件卷的目录区中专门用一个磁盘块作为“超级块”,当系统启动时需要将超级块读入内存。并且要保证内存与外存中的“超级块”数据一致。
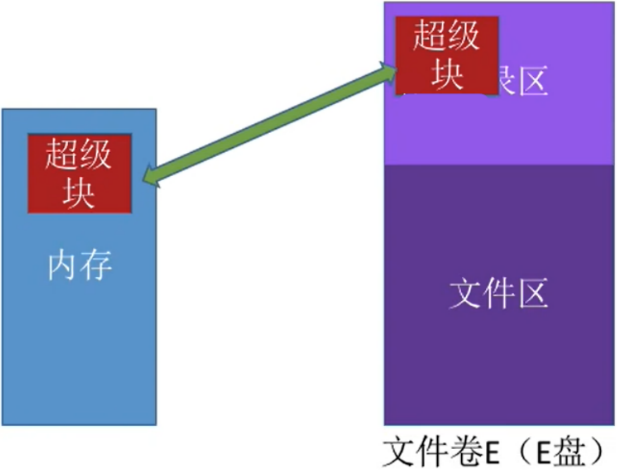
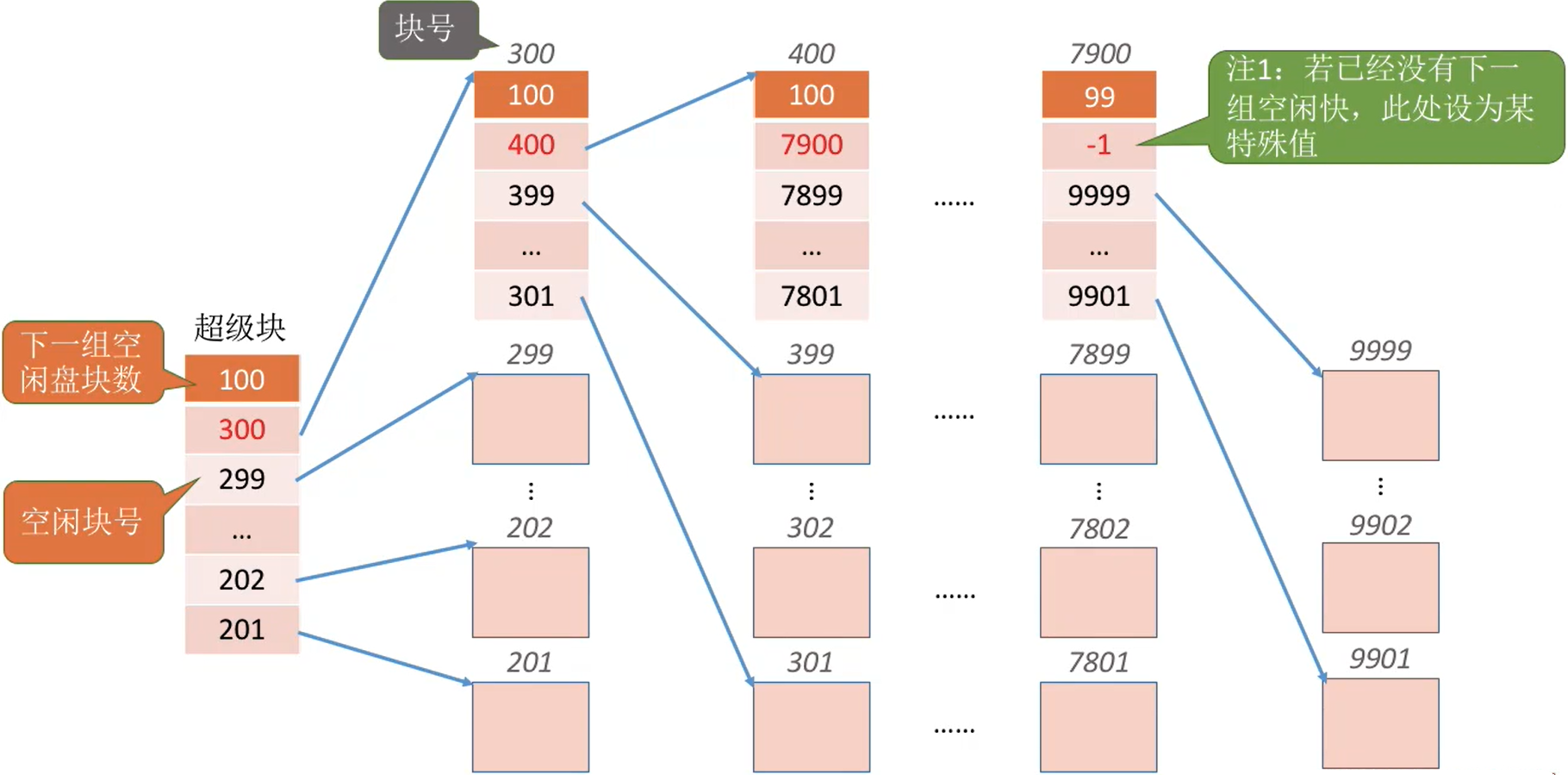
- 只有最顶部的块才叫超级块
- 每个块的第一个记录着下一组的空闲块块数
- 第二个记录着下一组块的块首的地址
- 剩下的记录的都是空闲盘块的地址
- 也就是说,
每组的第一块记录着下一组的信息;后面的块记录的全是空盘块
- 注意,第二列才是第一个分组,超级块不属于分组
- 还有就是,除了超级块 ,每组所有的块都是空闲块,包括每组的第一块也是空闲块,
尽管其存储了信息,但是该分配的时候还是得分配出去的
注1:若已经没有下一组空闲快,此处设为某特殊值
注2:一个分组中的块号不需要连续,此处只是为了让大家更方便看出各个分组的数量
注3:每个分组的盘块的数量有个上限,并且最后一组的盘块数量<=其他分块
如何分配?
Eg :需要1个空闲块
- 检查第一个分组的块数是否足够。1<100,因此是足够的。
由于此时超级块已经读入内存了,所以在这次检查的时候只需要找到超级块查询即可
- 分配第一个分组中的1个空闲块,并修改相应数据
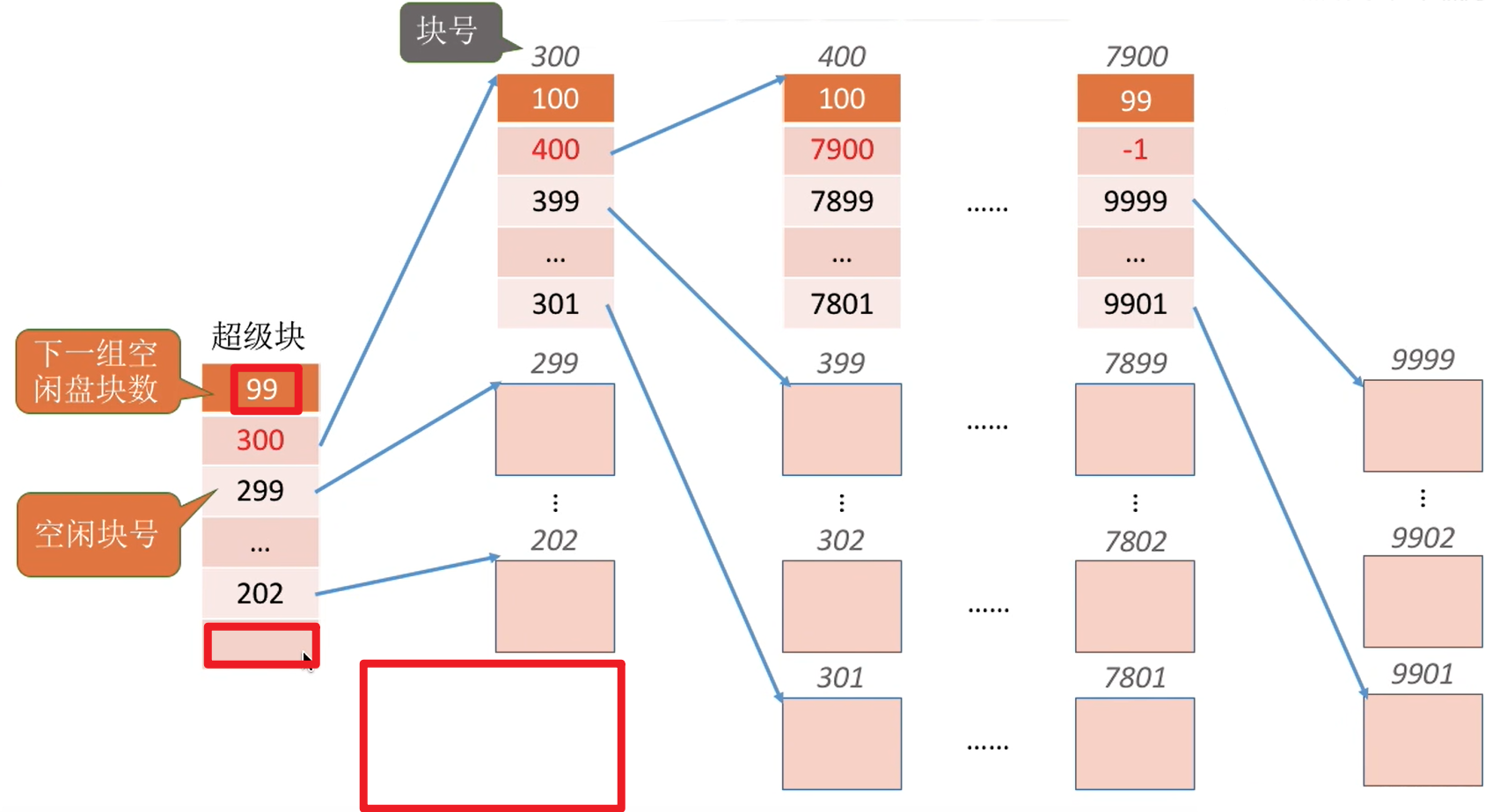
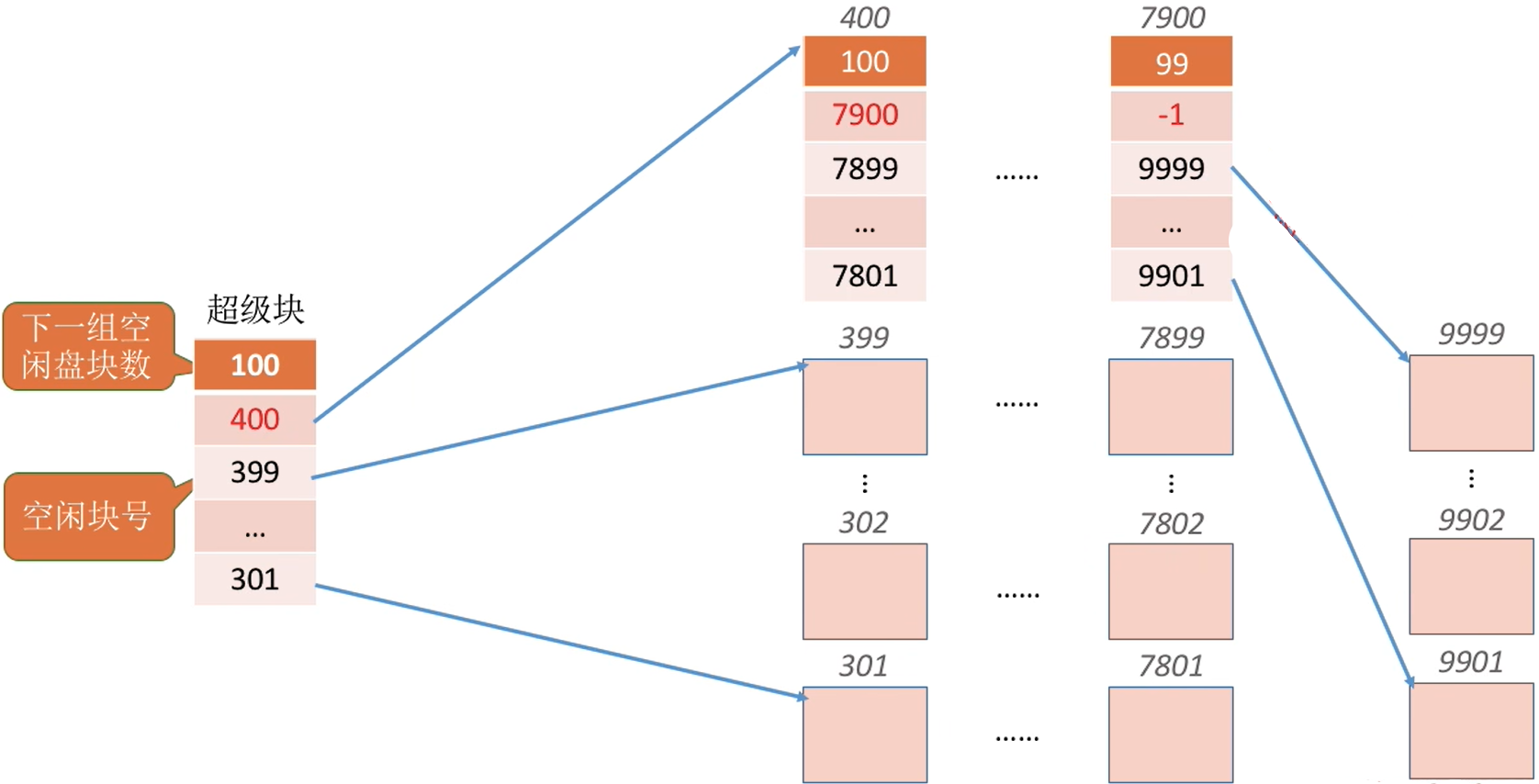
Eg:需要100个空闲块
- 检查第一个分组的块数是否足够。100=100,是足够的。
- 分配第一个分组中的100个空闲块。
- 但是由于300号块内存放了再下一组的信息,因此300号块的数据需要复制到超级块中。
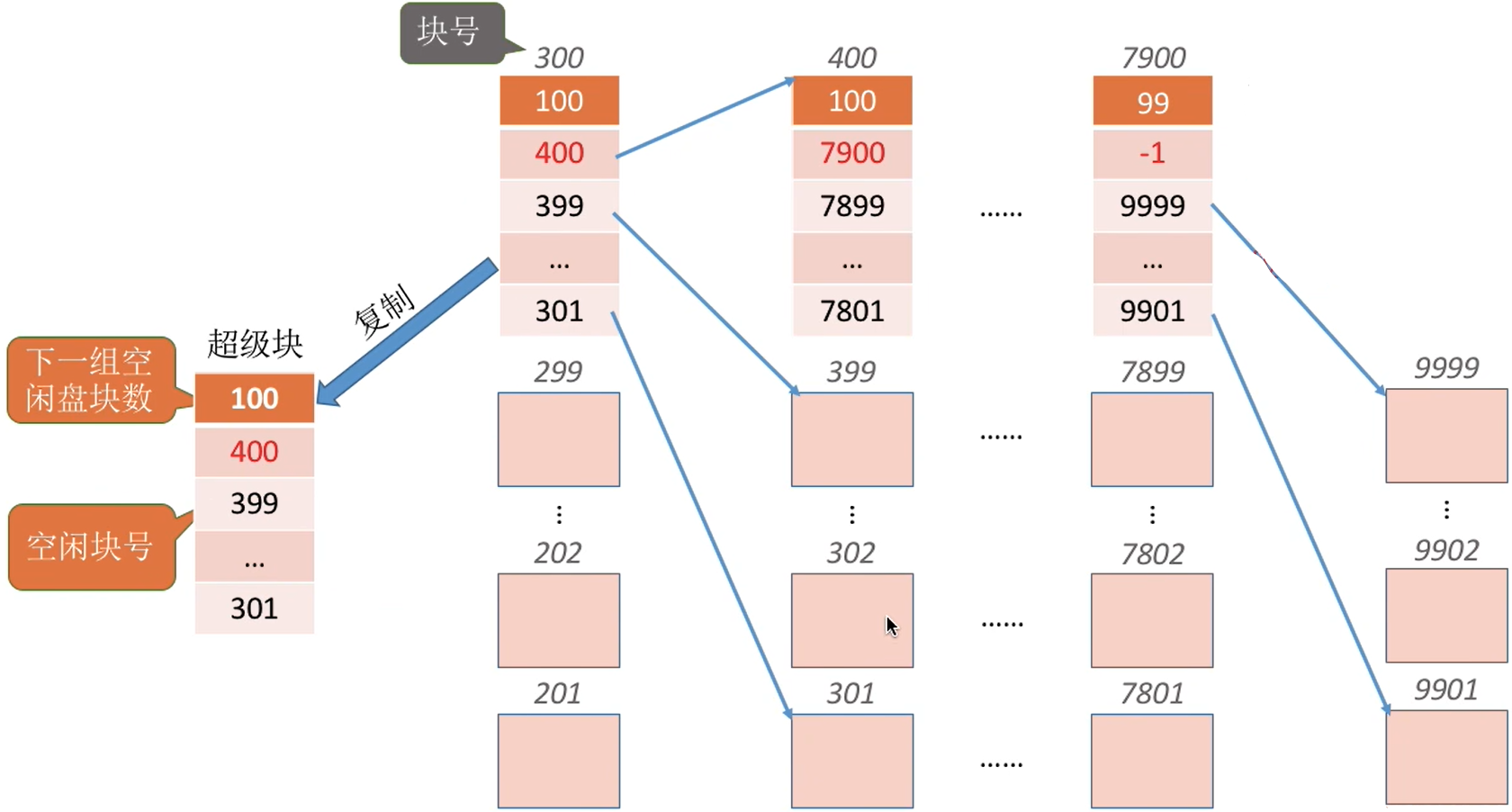 |
 |
|---|
如何回收?
Eg :假设每个分组最多为100个空闲块,此时第一个分组已有99个块,还要再回收一块
| 回收前 | 回收后 |
|---|---|
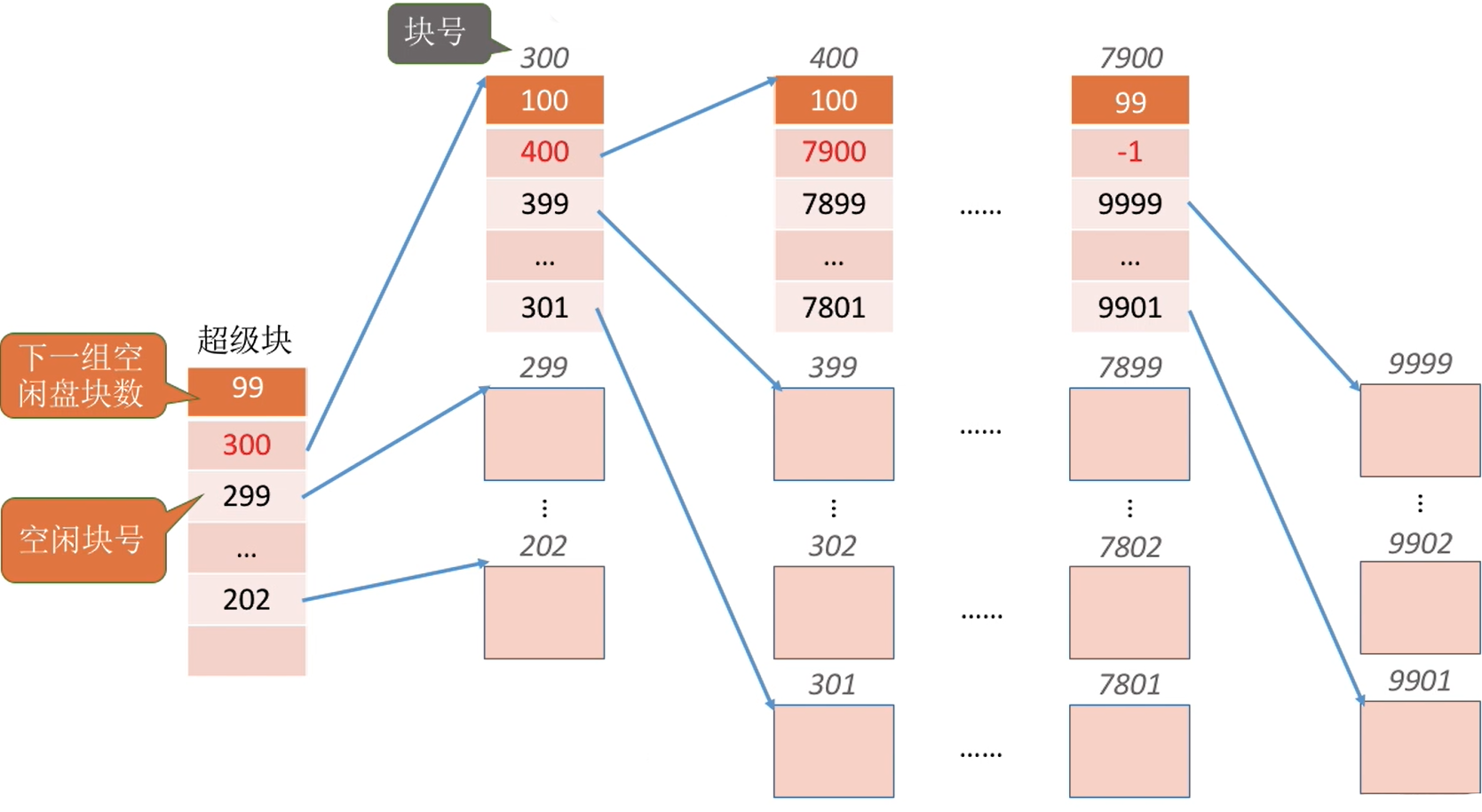 |
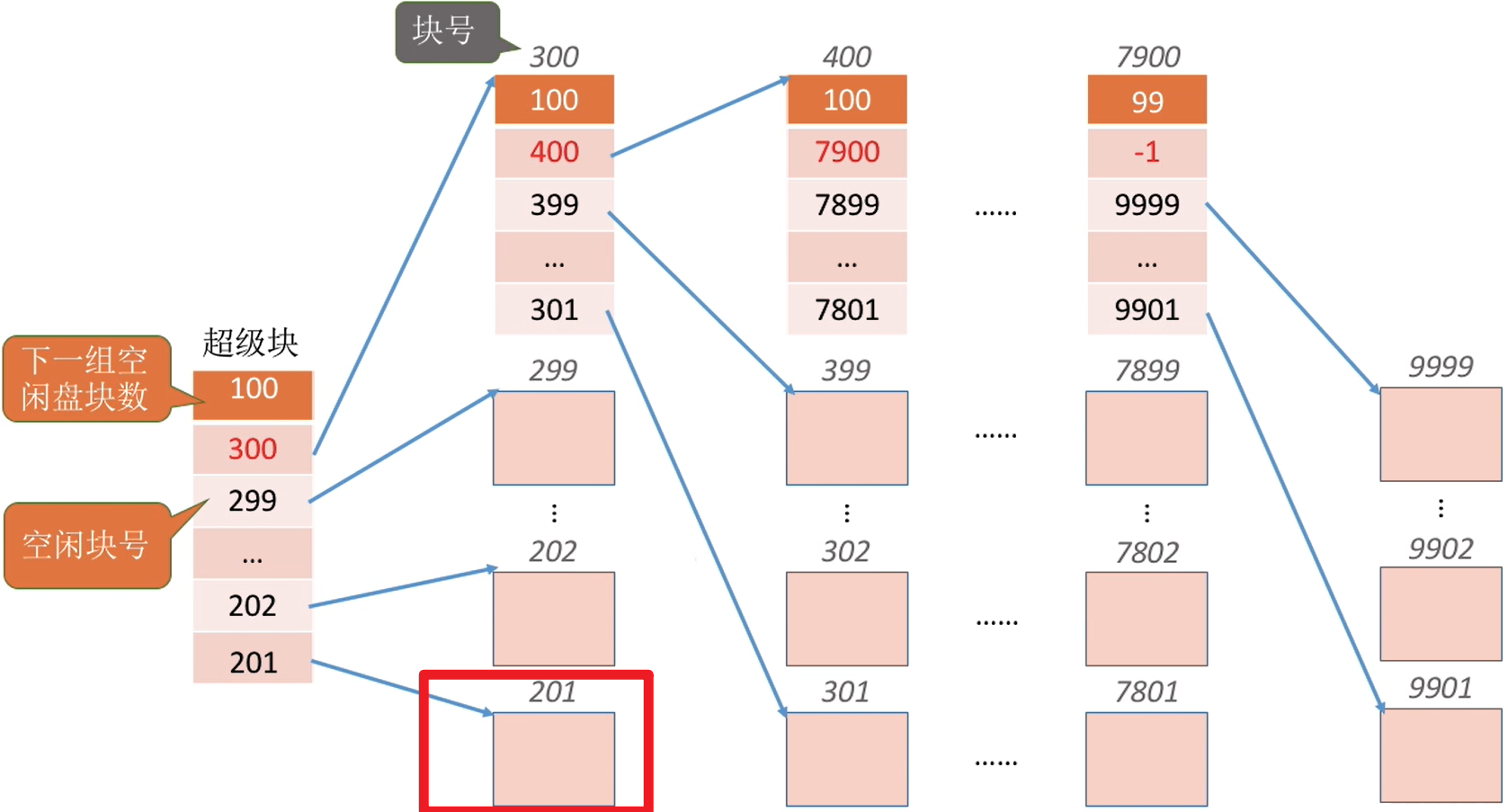 |
Eg :假设每个分组最多为100个空闲块,此时第一个分组已有100个块,还要再回收一块。
需要将超级块中的数据复制到新回收的块中,并修改超级块的内容,让新回收的块成为第一个分组。
| 回收前 | 回收后 |
|---|---|
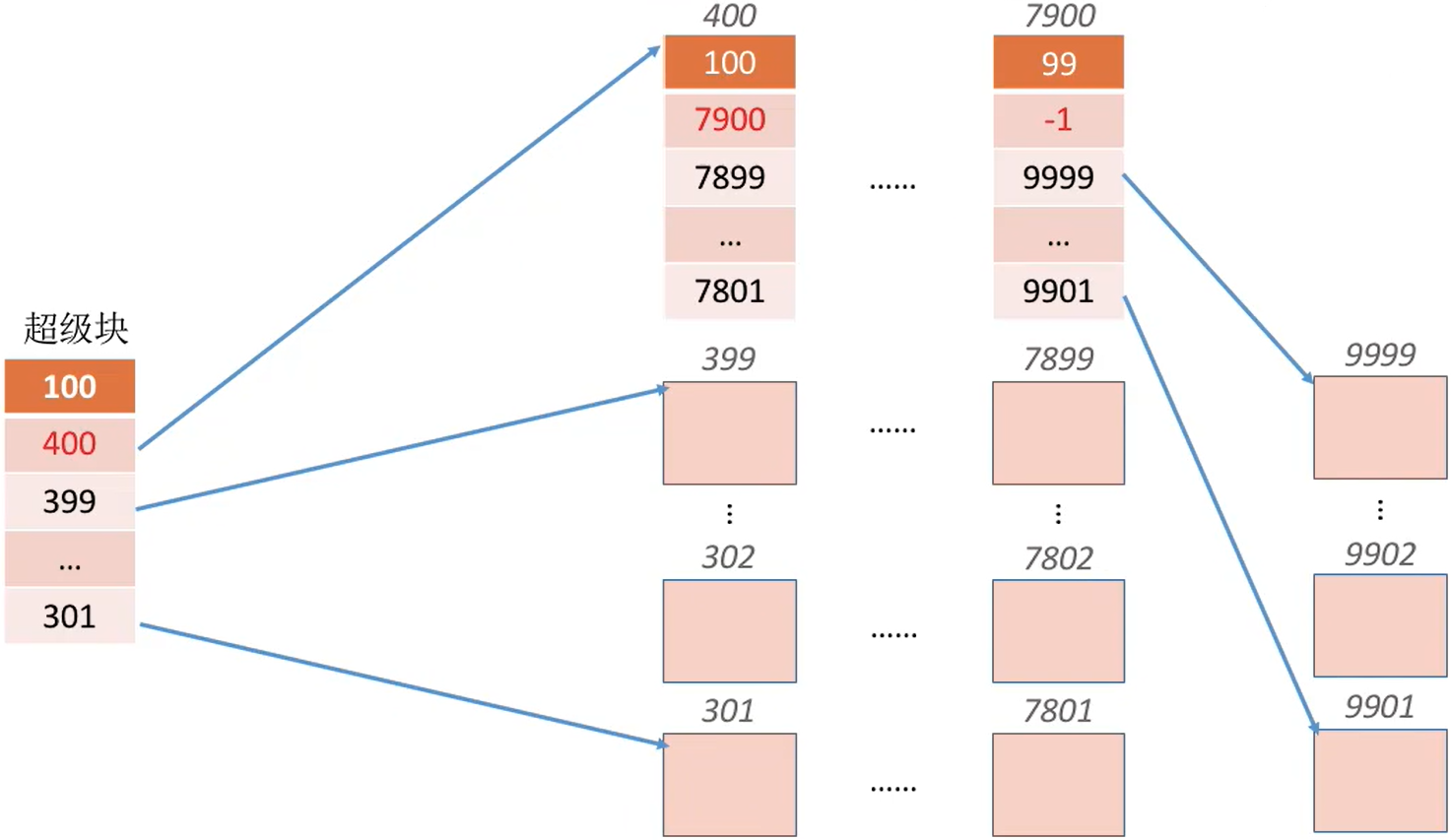 |
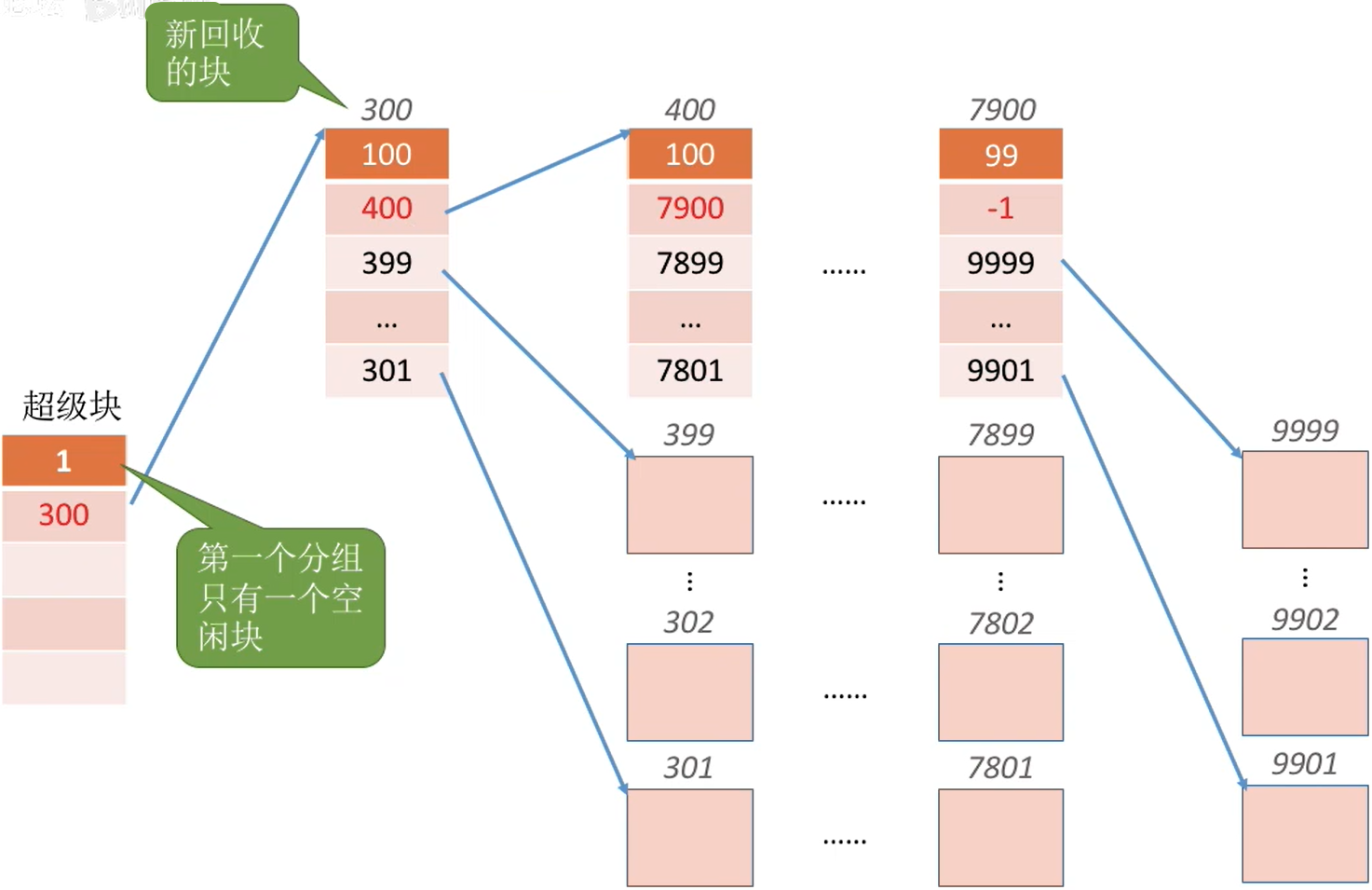 |
- 块号为300的是回收的块,也是空闲块,虽然存储着信息,但是要分配的时候还是要将其分配出去
最终只有超级块不是空闲块,其他的都可以成为空闲块
4.8 设备管理模块(磁盘管理)
“磁盘”属于一种l/O设备:但是和文件系统是相关联的,因此我放在第四章了
- 但是并不能认为
设备管理模块就是管理磁盘的,它的任务是直接与硬件交互,负责和硬件直接相关的一些管理工作。如:分配设备、分配设备缓冲区、磁盘调度、启动设备、释放设备等 - 只是将与文件管理相关的磁盘给拿出来了
4.8.1 磁盘的结构
(1) 磁盘、磁道和扇区
- 磁盘的表面由一些磁性物质组成,可以用这些磁性物质来记录二进制数据
机械硬盘内部如下
把硬盘拆开之后里面就是这个样子,所以说硬盘是磁盘里面的一个组件

- 读取的时候由磁头臂带动磁头沿着半径方向的移动,读取相应的数据
磁盘的初始化如下
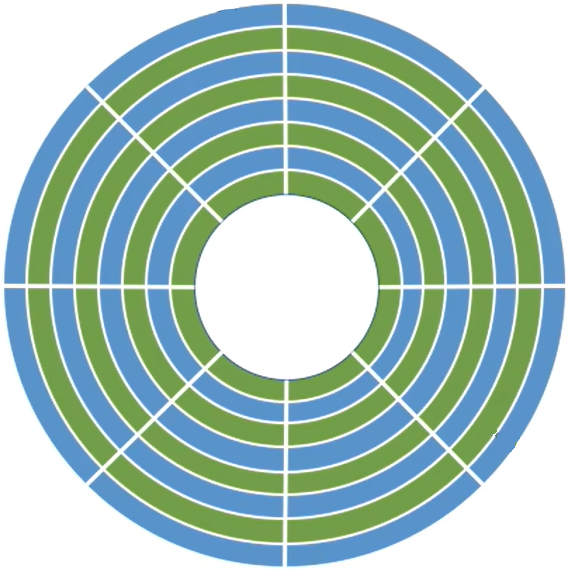
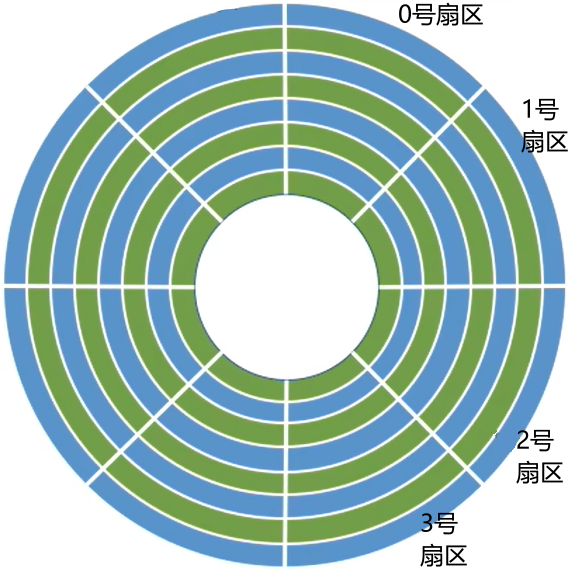
- 磁盘的盘面被划分成一个个
磁道。这样的一个“圈”就是一个磁道

- 一个磁道又被划分成一个个
扇区,每个扇区就是一个“磁盘块”。各个扇区存放的数据量相同(如1KB)
 |
 |
|---|
每个扇区存放的数据量相同,由于最内侧磁道上的扇区面积最小,因此数据密度最大
(2) 盘面、柱面
硬盘只有一个,但是磁盘有多个,并且磁头臂等带着各个磁头统一地往内外移动
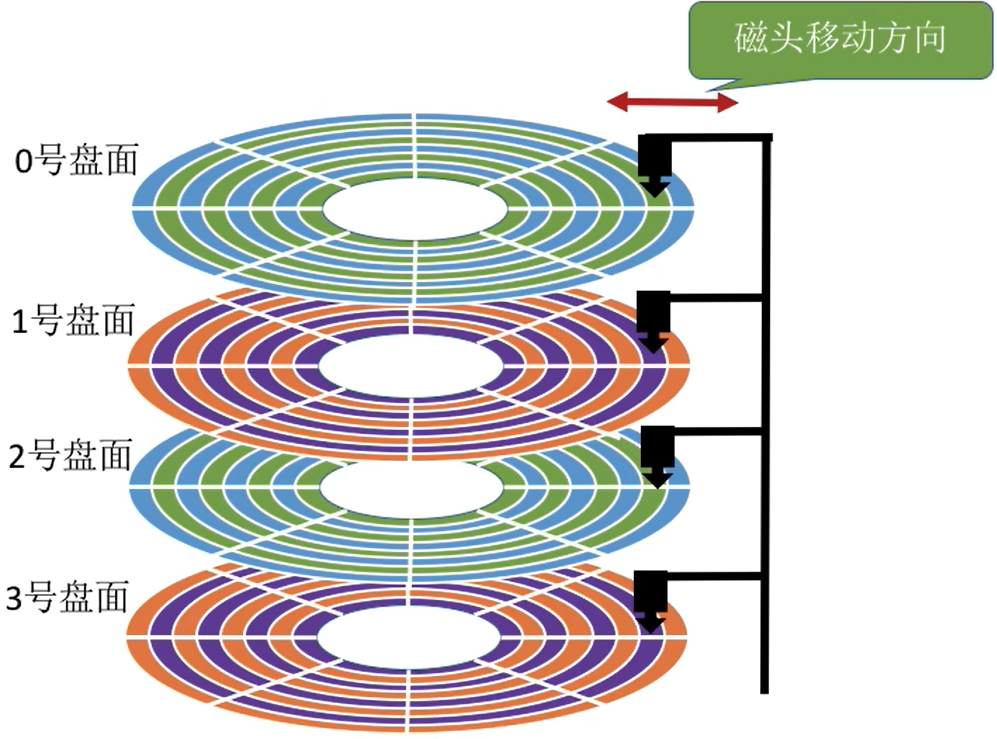
- 一个盘片可能会有两个盘面(上下都能存储数据)
- 每个盘面对应一个磁头
- 所有的磁头都是连在同一个磁臂上的,因此所有的磁头只能共进退
- 所有的
盘面中,相对位置相同的磁道组成柱面(很好理解,比如所有磁盘的最外圈就是一个柱面,次外圈也是一个柱面)
(3) 磁盘的地址编码
- 可用
(柱面号,盘面号,扇区号)来定位任意一个“磁盘块”。 - 在“文件的物理结构”小节中,我们经常提到文件数据存放在外存中的几号块,这个
块号就可以转换成(柱面号,盘面号,扇区号)的地址形式。 - 可根据该地址读取一个“块”
- 根据“柱面号”移动磁臂,让磁头
指向指定柱面; - 激活
指定盘面对应的磁头; - 磁盘旋转的过程中,
指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读/写。
- 根据“柱面号”移动磁臂,让磁头
磁盘是一次读取一个块的,也就是一次读取一个扇区
4.8.2 磁盘的操作
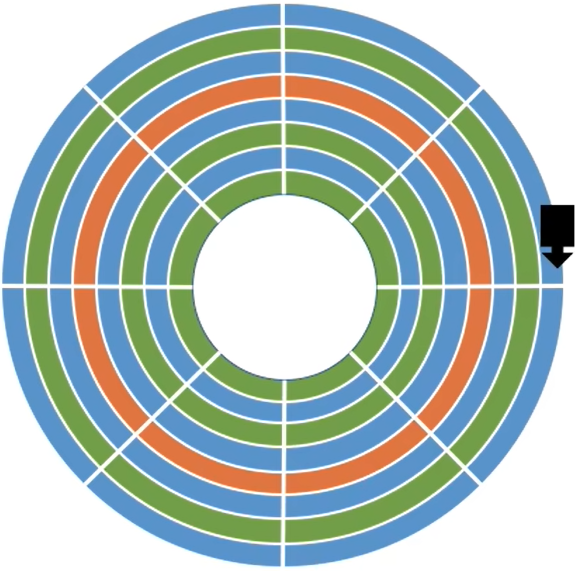
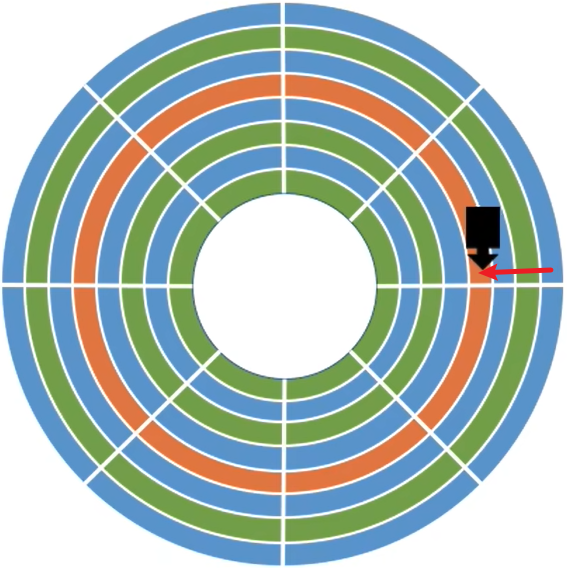
(1) 读写磁盘数据
- 需要
把“磁头”移动到想要读/写的扇区所在的磁道。 磁盘会转起来,让目标扇区从磁头下面划过,才能完成对扇区的读/写操作。
如下,读取橙色磁盘的内容
| 初始状态 | 磁头移动 | 磁盘旋转 |
|---|---|---|
 |
 |
 |
(2) 磁盘初始化
磁盘初始化:
首先是磁盘刚被制造出来时,仅仅被划分成一个个磁道

-
进行低级格式化(物理格式化),将
磁盘的各个磁道划分为扇区。一个扇区通常可分为头、数据区域(如512B大小)、尾三个部分组成。管理扇区所需要的各种数据结构一般存放在头、尾两个部分,包括扇区校验码(如奇偶校验、CRC循环冗余校验码等,校验码用于校验扇区中的数据是否发生错误)
所以之前困扰我的问题就解决了,之前一直认为,不论是内存还是磁盘,假设一块大小是1K的话,那么不可能全存放数据,用于管理块的指针之类的信息也要占位置的啊。但实际上,1K仅仅是指数据部分,进行数据交换的时候也是指数据部分,其他管理信息存放在头部和尾部
- 将磁盘分区,每个分区由若干柱面组成(即分为我们熟悉的c盘、D盘、E盘)
- 所以并不是说,一个分区(比如C盘,D盘)占有一个磁盘,说是按照柱面分还比较准确一些
- 是否可以这样理解,越常用的数据放在内侧越好?因为数据密度比较大嘛
- 进行逻辑格式化,创建文件系统。包括创建文件系统的根目录、初始化存储空间管理所用的数据结构(如位示图、空闲分区表)
| 初始状态 | 物理格式化 | 分区 |
|---|---|---|
|
|
|
(3) 引导块 & 开机流程
计算机开机时需要进行一系列初始化的工作,这些初始化工作是通过执行初始化程序(自举程序)完成的
-
初始化程序可以放在ROM(只读存储器)中,每次开机的时候读取ROM中的初始化程序。
ROM中的数据在出厂时就写入了,并且
以后不能再修改注:ROM一般是出厂时就集成在主板上的
初始化程序程序(自举程序)放在ROM中存在什么问题?
- 万一需要更新自举程序,将会很不方便,因为ROM中的数据无法更改。
如何解决呢?
- ROM中只存放很小的“
自举装入程序”,完整的自举程序放在磁盘的启动块(即引导块拥有启动分区的磁/启动分区)上,启动块位于磁盘的固定位置。 - 开机时计算机先运行“
自举装入程序”,通过执行该程序就可找到引导块,并将完整的“自举程序”读入内存,完成初始化
拥有启动分区的磁盘称为启动磁盘或系统磁盘(C:盘)
所以C盘还是比较特殊的,因为系统启动块在C盘
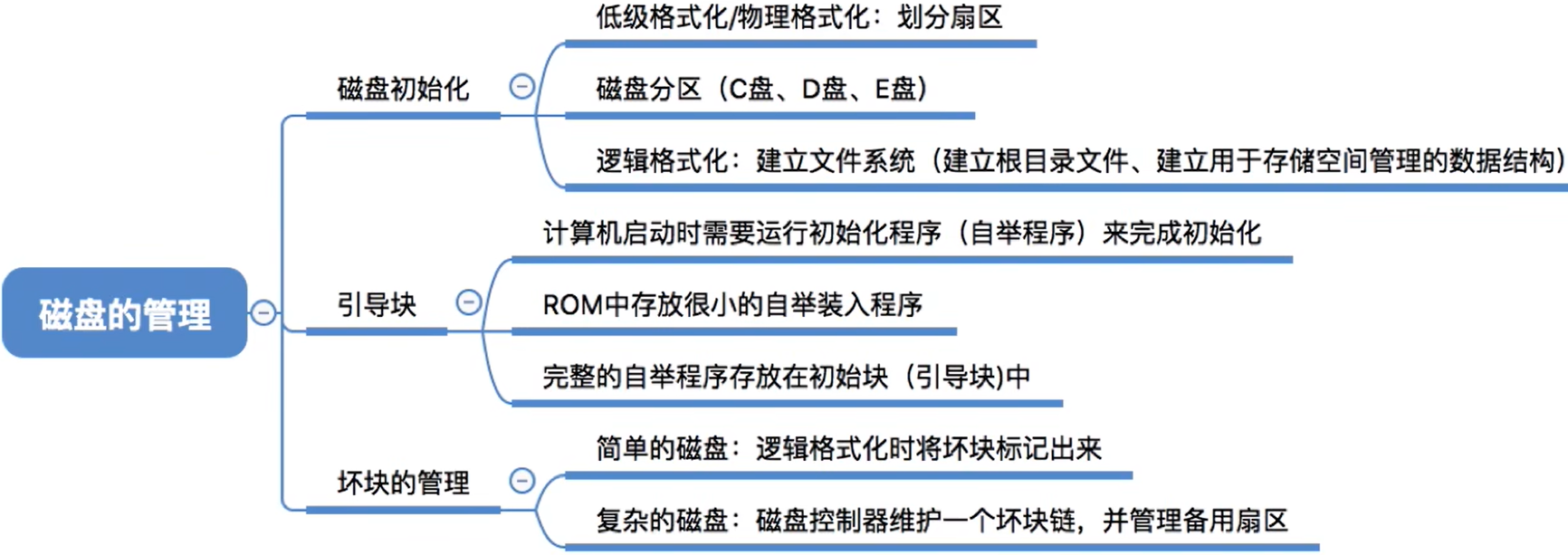
(4) 坏块的管理
坏了、无法正常使用的扇区就是“坏块”。这属于硬件故障,操作系统是无法修复的。应该将坏块标记出来,以免错误地使用到它
有两种管理方式:
-
对于简单的磁盘,可以在
逻辑格式化时(建立文件系统时)对整个磁盘进行坏块检查,标明哪些扇区是坏扇区比如:在 FAT表上标明。(在这种方式中,
坏块对操作系统不透明,因为操作系统要读取FAT的) -
对于复杂的磁盘,
磁盘控制器(磁盘设备内部的一个硬件部件)会维护一个坏块链表。在磁盘出厂前进行低级格式化(物理格式化)时就将坏块链进行初始化。会保留一些“备用扇区”,用于替换坏块。这种方案称为扇区备用。且这种处理方式中,
坏块对操作系统透明。
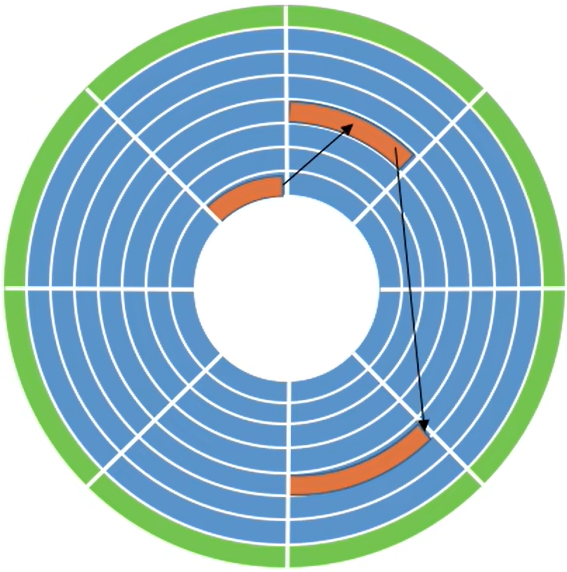
如图,橙色的部分为坏块,通过指针链起来
4.8.3 磁盘的分类
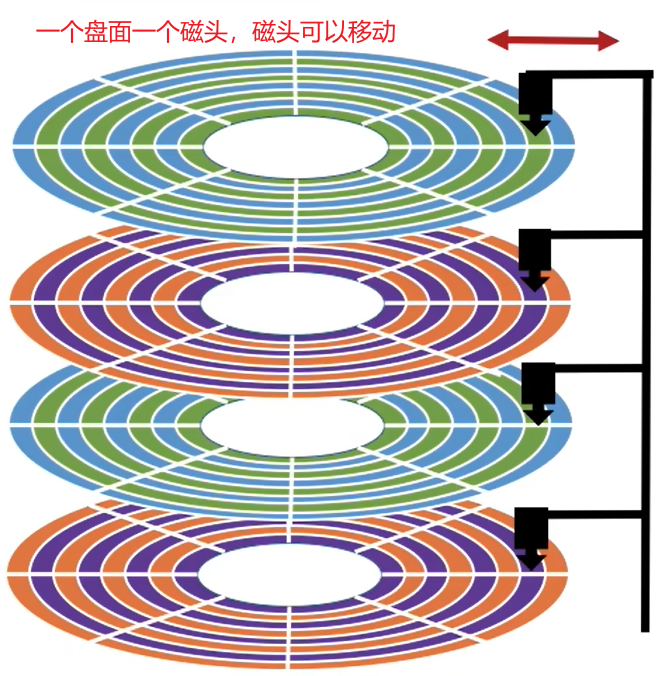
(1) 根据磁头可否移动
根据磁头可否移动分类
- 磁头可以移动的称为
活动头磁盘。磁臂可以来回伸缩来带动磁头定位磁道 - 磁头不可移动的称为
固定头磁盘。这种磁盘中每个磁道有一个磁头
| 活动头磁盘 | 固定头磁盘 |
|---|---|
 |
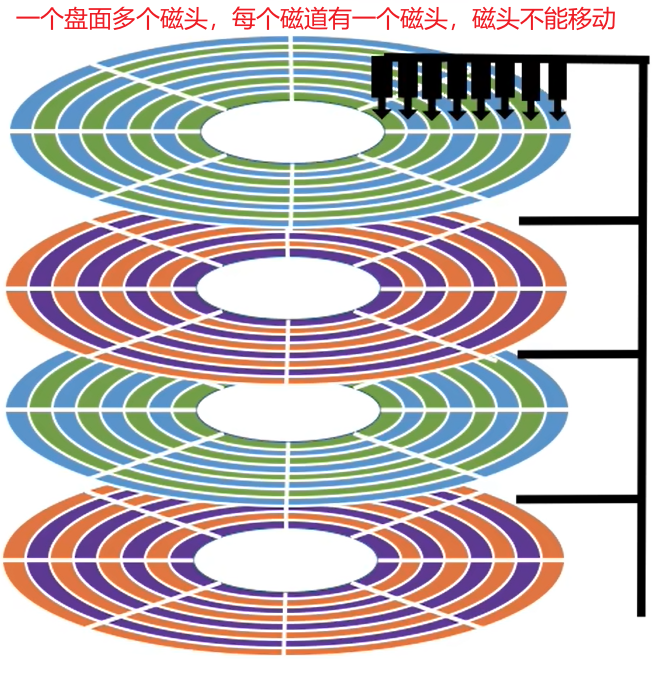 |
- 在上方固定头磁盘中,下面的磁盘也有多个磁头,只是画出来太丑陋了
(2) 根据盘片可否更换
根据盘片是否可更换分类
- 盘片可以更换的称为
可换盘磁盘 - 盘片不可更换的称为
固定盘磁盘

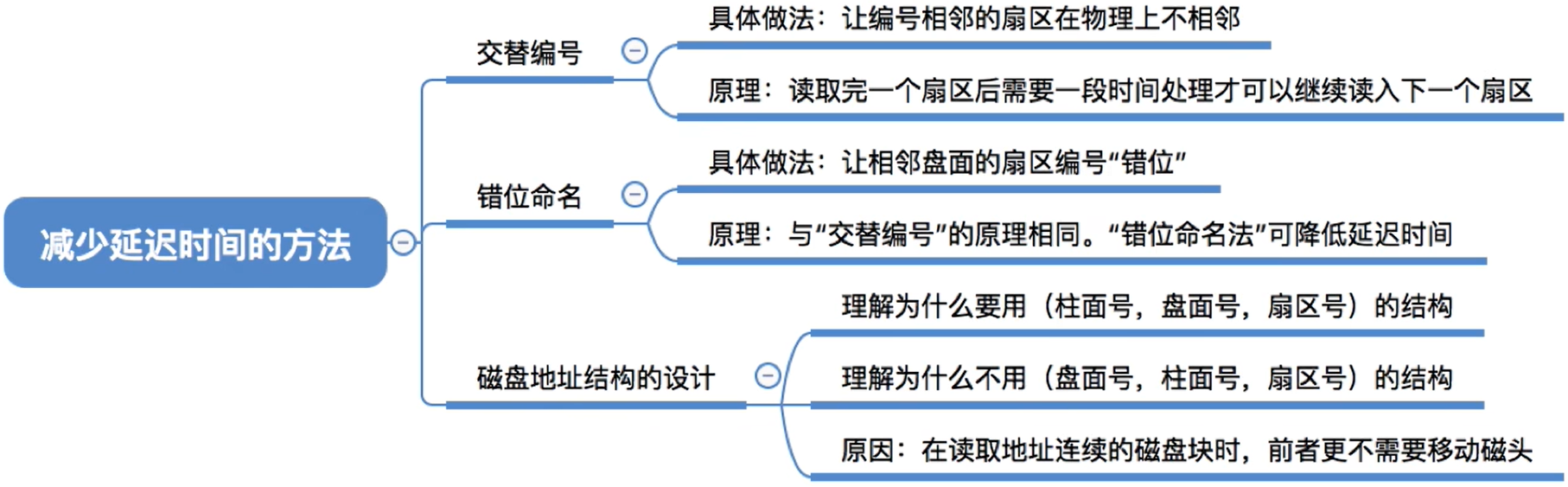
4.8.4 减少磁盘延迟
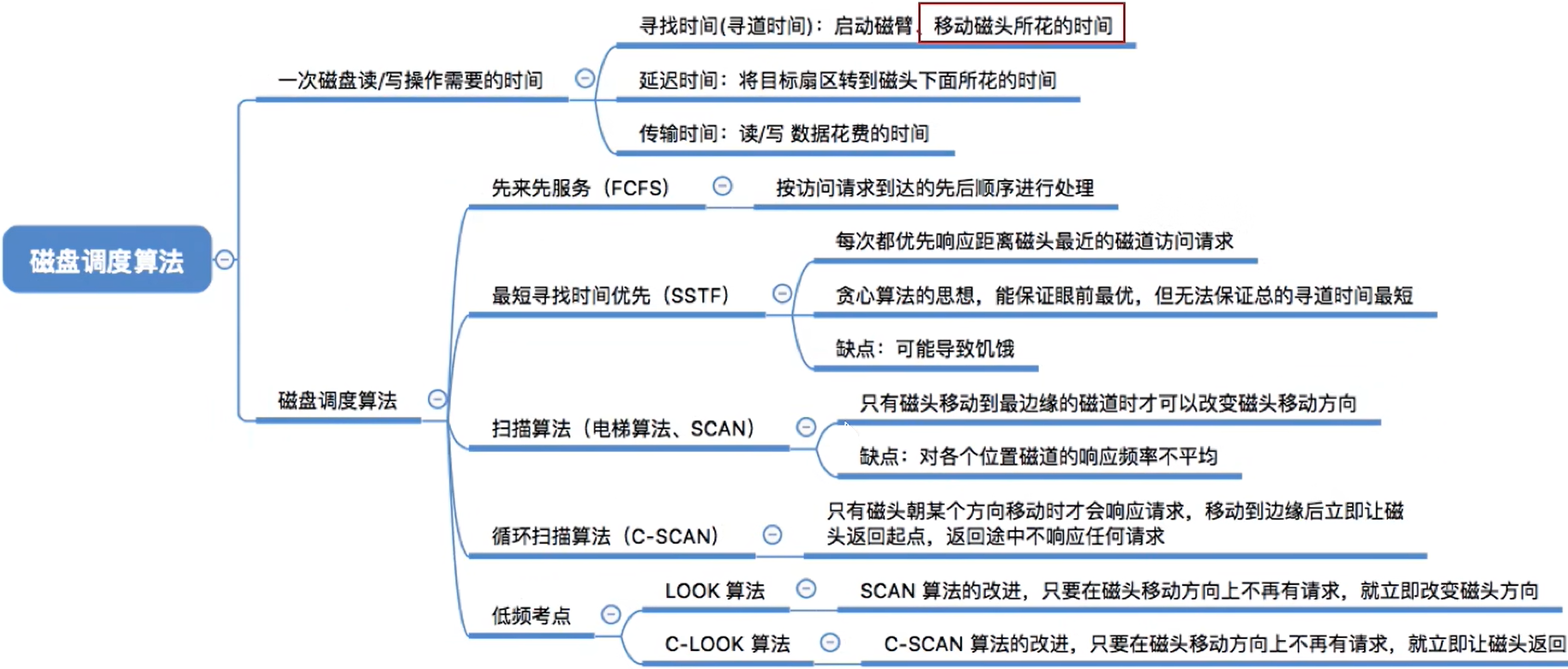
(1) 一次磁/盘读写操作需要的时间
寻找时间(寻道时间)Ts:在读/写数据前,将磁头移动到指定磁道所花的时间。
启动磁头臂是需要时间的。假设耗时为s;移动磁头也是需要时间的。
假设磁头匀速移动,每跨越一个磁道耗时为m,即共需要跨越n条磁道。则:
寻道时间Ts = s + m*n
延迟时间TR:通过旋转磁盘,使磁头定位到目标扇区所需要的时间。
设磁盘转速为r(单位:转/秒,或转/分),则
- 平均所需的延迟时间TR=(1/2)*(1/r)= 1/2r
1/r就是转一圈需要的时间。找到目标扇区平均需要转半圈,因此再乘以1/2
硬盘的典型转速为5400转/分,或7200转/分
由此就可以得出为什么磁盘转速越快,效率越高了
传输时间Tt:磁盘读出或向磁盘写入数据所经历的时间,假设磁盘转速为r,此次读/写的字节数为b,每个磁道上的字节数为N。则:
传输时间Tt=(1/r)* (b/N)= b/(rN)
每个磁道要可存N字节的数据,因此b字节的数据需要b/N个磁道才能存储。而读/写一个磁道所需的时间刚好又是转一圈所需要的时间1/r
总的平均存取时间Ta=Ts+ 1/2r + b/(rN)
如何提升效率呢?
延迟时间和传输时间都与磁盘转速相关,且为线性相关。而转速是硬件的固有属性,因此操作系统也无法优化延迟时间和传输时间- 但是操作系统的磁盘调度算法会
直接影响寻道时间
(2) 降低寻道时间—磁盘调度算法
这个是高频考点
① 先来先服务算法FCFS
根据进程请求访问磁盘的先后顺序进行调度。
假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道
按照FCFS的规则,按照请求到达的顺序,磁头需要依次移动到55、58、39、18、90、160、150、38、184号磁道
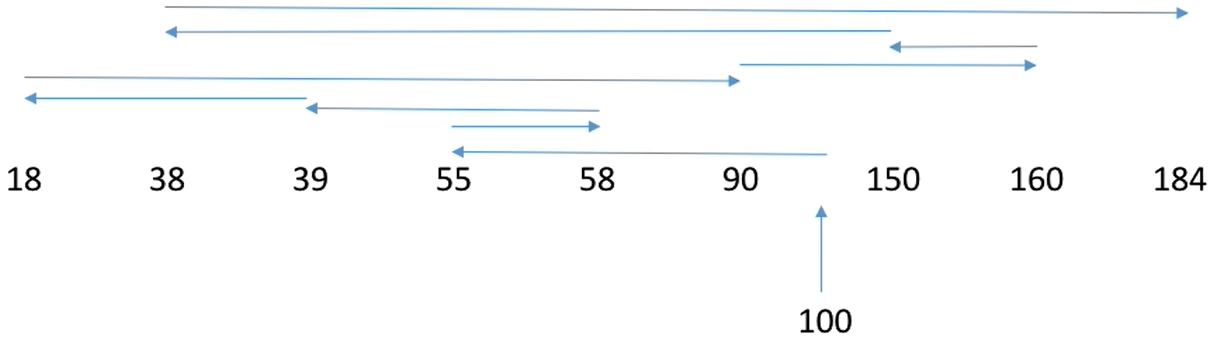
磁头总共移动了45+3+19+21+72+70+10+112+146 = 498个磁道;响应一个请求平均需要移动498/9= 55.3个磁道(平均寻找长度)
优点:公平;如果请求访问的磁道比较集中的话,算法性能还算过的去缺点:如果有大量进程竞争使用磁盘,请求访问的磁道很分散,则FCFS在性能上很差,寻道时间长。
性能上类似于随机调度算法,可能是因为请求访问的磁道可能是随机的
② 最短寻找时间优先SSTF
SSTF算法会优先处理的磁道是与当前磁头最近的磁道。
可以保证每次的寻道时间最短,但是并不能保证总的寻道时间最短。(其实就是贪心算法的思想,只是选择眼前最优,但是总体未必最优)
假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(100-18)+ (184-18)=248个磁道,响应一个请求平均需要移动248/9= 27.5个磁道(平均寻找长度)
- 优点:性能较好,平均寻道时间短
- 缺点:可能产生“饥饿”现象
Eg:本例中,如果在处理18号磁道的访问请求时又来了一个38号磁道的访问请求,处理38号磁道的访问请求时又来了一个18号磁道的访问请求。如果有源源不断的18号、38号磁道的访问请求到来的话,150、160、184号磁道的访问请求就永远得不到满足,从而产生“饥饿”现象。
产生饥饿的原因在于:
磁头在一个小区域内来回来去地移动
③ 扫描算法SCAN
- SSTF算法会产生饥饿的原因在于:磁头有可能在一个小区域内来回来去地移动。
- 为了防止这个问题,可以规定,
只有磁头移动到最外侧磁道的时候才能往内移动,移动到最内侧磁道的时候才能往外移动。这就是扫描算法(SCAN)的思想。 - 由于磁头移动的方式很像电梯,因此也叫
电梯算法。
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(200-100)+(200-18)= 282个磁道,响应一个请求平均需要移动282/9= 31.3个磁道(平均寻找长度)
- 优点:性能较好,平均寻道时间较短,不会产生饥饿现象
- 缺点:
- 只有
到达最边上的磁道时才能改变磁头移动方向,事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。 - SCAN算法
对于各个位置磁道的响应频率不平均(如:假设此时磁头正在往右移动,且刚处理过90号磁道,那么下次处理90号磁道的请求就需要等磁头移动很长一段距离;而响应了184号磁道的请求之后,很快又可以再次响应184号磁道的请求了)
- 只有
下面的就依次解决SCAN算法的两个问题
④ LOOK调度算法
解决是磁头移动方向的问题
- 扫描算法(SCAN)中,只有到达最边上的磁道时才能改变磁头移动方向,事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。
- LOOK调度算法就是为了解决这个问题,
如果在磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向。(边移动边观察,因此叫LOOK)
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(184-100)+(184-18)= 250个磁道,响应一个请求平均需要移动250/9= 27.5个磁道(平均寻找长度)
- 优点:比起SCAN算法来,不需要每次都移动到最外侧或最内侧才改变磁头方向,使寻道时间进一步缩短
⑤ 循环扫描算法C-SCAN
解决的是 SCAN算法
对于各个位置磁道的响应频率不平均的问题
- SCAN算法对于
各个位置磁道的响应频率不平均,而C-SCAN算法就是为了解决这个问题。 - 规定只有磁头朝某个特定方向移动时才处理磁道访问请求,而返回时直接快速移动至起始端而不处理任何请求。
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(200-100) + (200-0)+ (90-0)= 390个磁道,响应一个请求平均需要移动390/9 = 43.3个磁道(平均寻找长度)
- 优点:比起SCAN来,对于各个位置磁道的响应频率很平均。
- 缺点:只有到达最边上的磁道时才能改变磁头移动方向,事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了;并且,磁头返回时其实只需要返回到18号磁道即可,不需要返回到最边缘的磁道。另外,
比起SCAN算法来,平均寻道时间更长
⑥ C-LOOK调度算法
将上面两个算法整合
- C-SCAN算法的主要缺点是只有到达最边上的磁道时才能改变磁头移动方向,并且磁头返回时不一定
- 需要返回到最边缘的磁道上。C-LOOK算法就是为了解决这个回题。如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(184-100)+(184-18)+(90-18)= 322个磁道
响应一个请求平均需要移动322/9= 35.8个磁道(平均寻找长度)
- 优点:比起C-SCAN算法来,不需要每次都移动到最外侧或最内侧才改变磁头方向,使寻道时间讲一步缩短
若题目中无特别说明,则
SCAN就是LOOK,C-SCAN就是C-LOOK
(3) 降低延迟时间—扇区编号
延迟时间:将目标扇区转到磁头下面花费的时间
这个也不是操作系统的做的事情,是磁盘的设定
假设要连续读取橙色区域的2、3、4扇区:
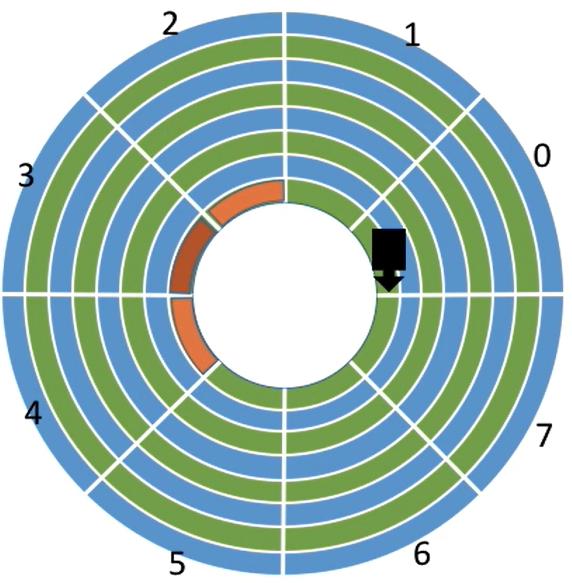
磁头读取一块的内容(也就是一个扇区的内容)后,需要一小段时间处理,而盘片又在不停地旋转
因此,如果2、3号扇区相邻着排列,则读完2号扇区后无法连续不断地读入3号扇区
必须等盘片继续旋转,3号扇区再次划过磁头,才能完成扇区读入
- 结论:磁头读入一个扇区数据后需要一小段时间处理,如果逻辑上相邻的扇区在物理上也相邻,则读入几个连续的逻辑扇区,可能需要很长的“延迟时间”
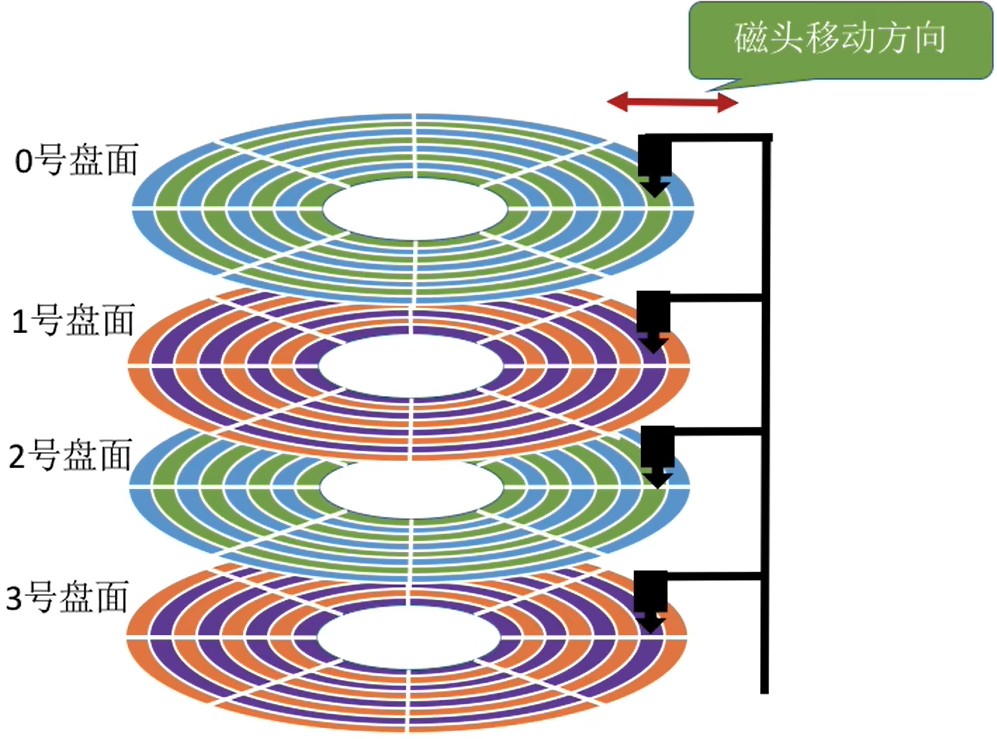
① 交替编号
若采用交替编号的策略,即让逻辑上相邻的扇区在物理上有一定的间隔,可以使读取连续的逻辑扇区所需要的延迟时间更小。

- 这样如果再次读取 2 3 4的haute,那么读完2号扇区之后进入6号扇区,此时可以处理收尾工作,然后读取3号扇区
- 这样转1圈即可读取连续的扇区了
这里思考一下:磁盘的物理地址是(柱面号,盘面号,扇区号)而不是(盘面号,柱面号,扇区号)
假设某磁盘有8个柱面/磁道(假设最内侧柱面/磁道号为0 ) ,4个盘面,8个扇区。则可用3个二进制位表示柱面,2个二进制位表示盘面,3个二进制位表示扇区,需要读取的连续地址是(00, 000,000) ~ (00,001,111)
-
若物理地址结构是
(盘面号,柱面号,扇区号),且需要连续读取物理地址(00, 000,000) ~ (00,001,111)的扇区:(00, 000, 000) ~ (00, 000,111)转两圈可读完(第一次旋转读取0123,第二次读取4567)
之后再读取物理地址相邻的区域,即(00,001, 000) ~ ( 00,001,111 ),
需要启动磁头臂,将磁头移动到下一个磁道(这就要耗费寻道时间) -
若物理地址结构是
(柱面号,盘面号,扇区号),且需要连续读取物理地址(000, 00,000) ~ (000,01,111)的扇区:(000, 00,000) ~( 000, 00,111)由盘面0的磁头读入数据,之后再读取物理地址相邻的区域,即(000,01,000) ~ ( 000,01,111 )
由于柱面号/磁道号相同,
只是盘面号不同,因此不需要移动磁头臂。只需要激活相邻盘面的磁头即可
这里说一下我的理解
- 在读连续的区域的时候,低位的变化频率可能比较高,比如 0000 - 1000,低三位会一直变化,因此用来代表扇区号,因为扇区是一直转动的,这个是不可避免的
- 然后再往高位幅度会依次减小,这里要考虑到
寻道时间,所以希望柱面变化要比较小,所以柱面放在最高位,这样就减小了柱面切换的可能,从而避免寻道时间- 盘面的切换只要考虑寻道时间中的 磁头启动的时间,这个的开销肯定小于整个寻道时间,所以盘面放在中间
答案:读取地址连续的磁盘块时,采用(柱面号,盘面号,扇区号)的地址结构可以减少磁头移动消耗的时间(原因就是柱面放在最高位,切换频率低了)
错位命名
一般情况:若相邻的盘面相对位置相同处扇区编号相同,如下
| 0号盘面 | 1号盘面 |
|---|---|
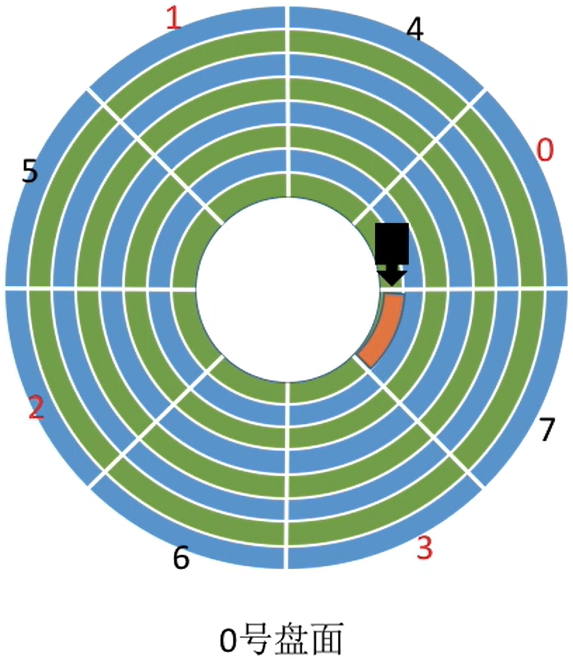 |
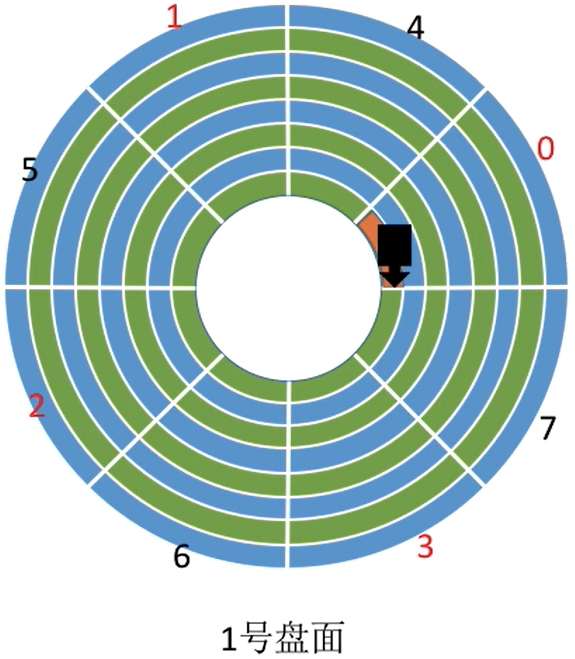 |
如果我们要依次读取连续地址 (000, 00, 111) 和 (000, 01, 000)
柱面一样,都是000,读完0号盘面的111,也就是7号扇区之后,立即读1号盘面的000,也就是0号扇区
- 注意:所有盘面都是一起连轴转的
读取完磁盘块(000,00,111)之后,需要短暂的时间处理,而盘面又在不停地转动,因此当(000,01, 000)第一次划过1号盘面的磁头下方时,并不能读取数据,只能再等该扇区再次划过磁头。
因此可以采用错位命名的方式
| 0号盘面 | 1号盘面 |
|---|---|
|
 |
- 这样错一位即可
4.8.5 固态硬盘
(1) 机械硬盘 VS 固态硬盘
- 机械硬盘是磁盘存储数据
- 固态硬盘是芯片存储数据
| 机械硬盘 | 固态硬盘 |
|---|---|
 |
 |
(2) 固态硬盘的结构
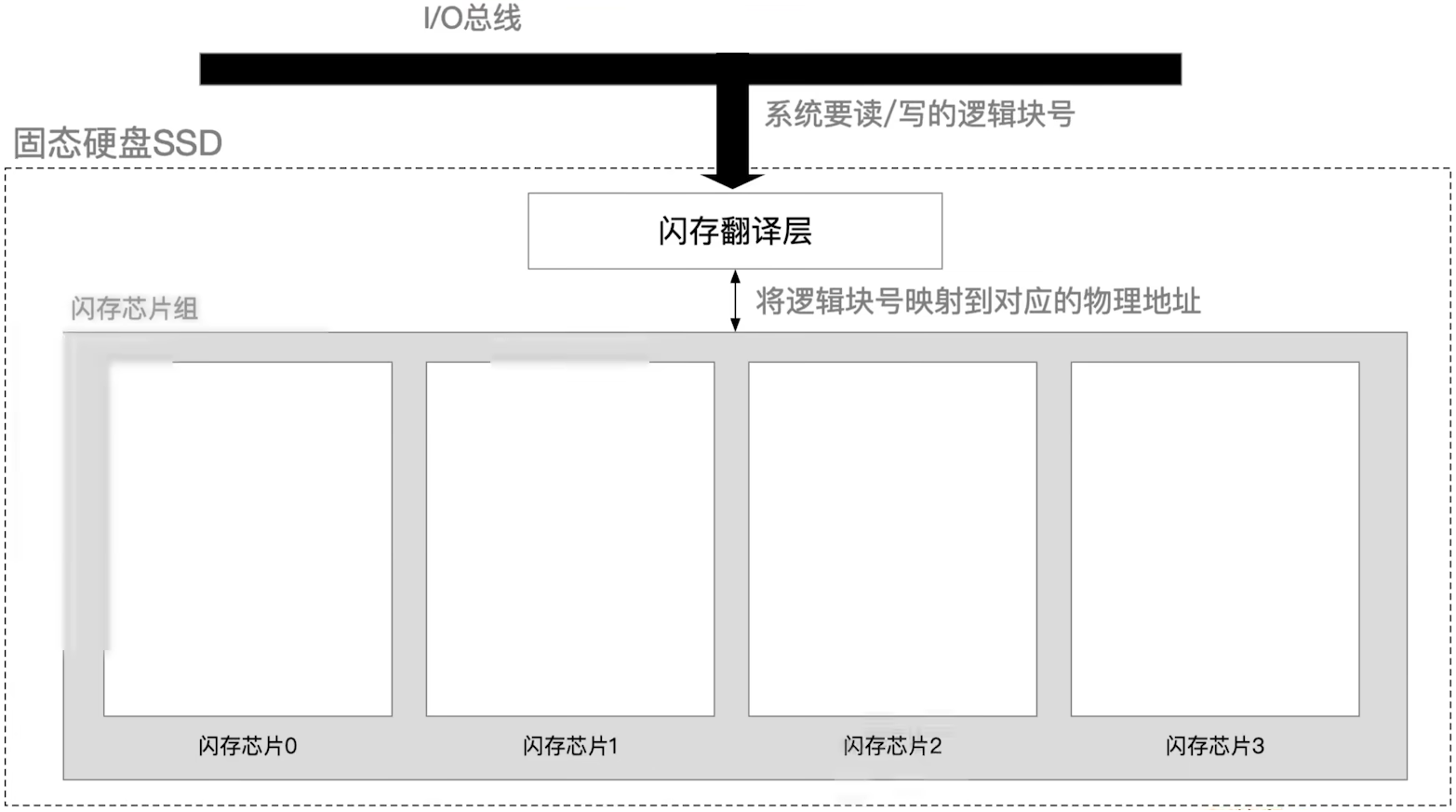
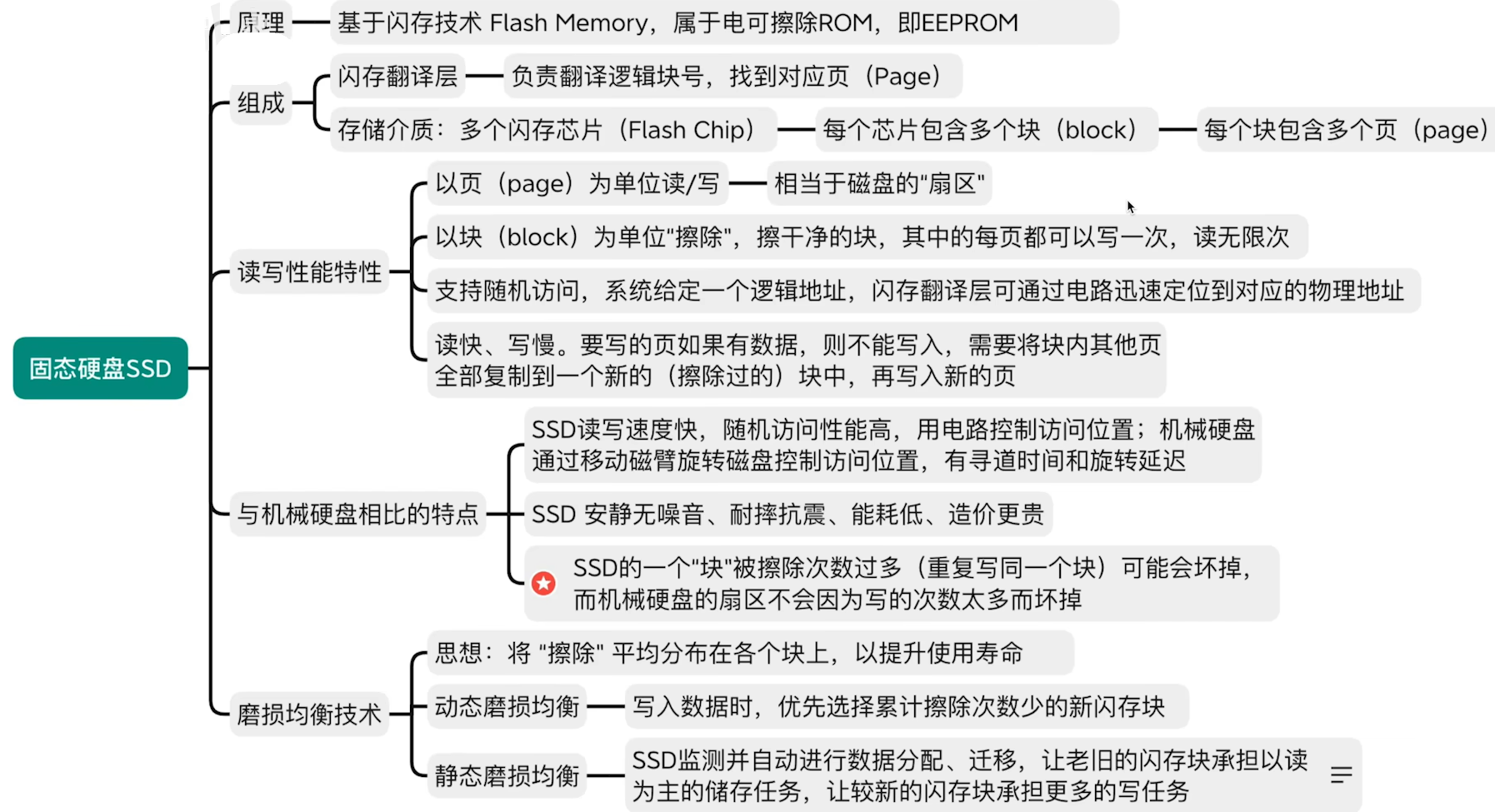
- SSD固态硬盘的每个芯片都是闪存芯片,使用的是闪存技术
每一个内存芯片里面有若干个数据块组成(块大小 16KB~512KB)
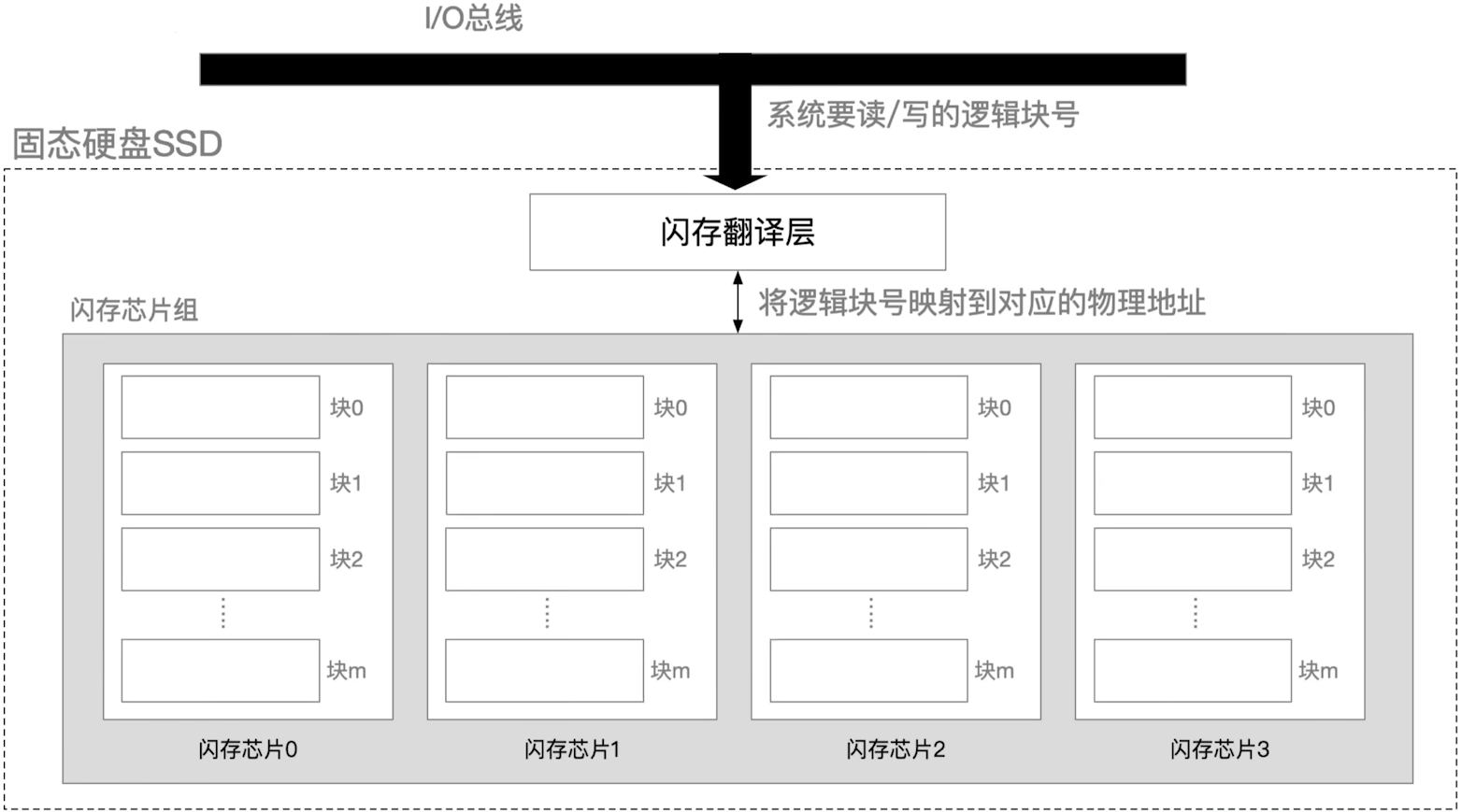
每个块又可以进一步拆分成页(页大小 512B ~ 4KB)
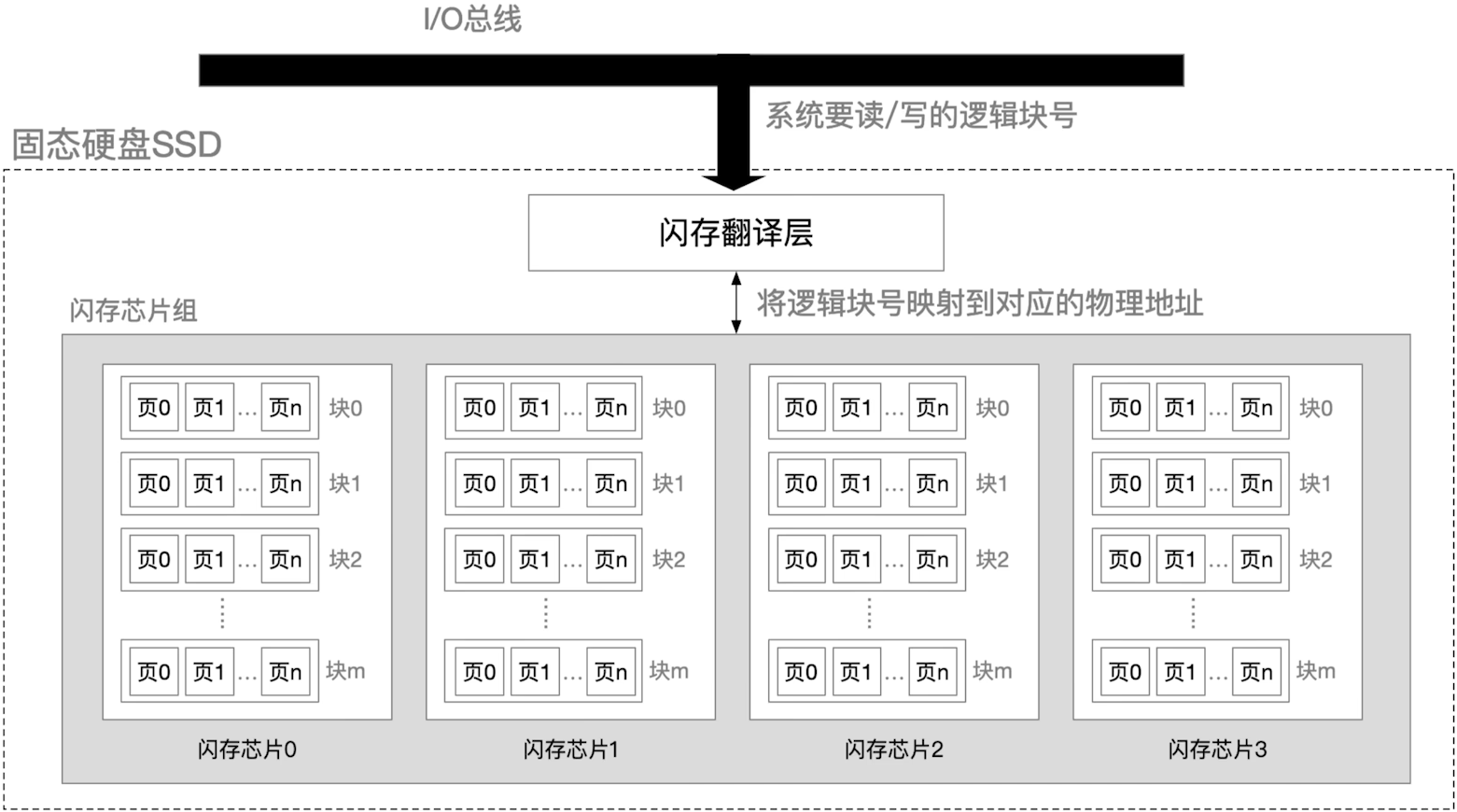
(3) 读写性能特性
- 以页(page)为单位读/写——相当于磁盘的"扇区"
- 以块(block)为单位"擦除",擦干净的块,其中的每页都可以写一次,读无限次
- 支持
随机访问,系统给定一个逻辑地址,闪存翻译层可通过电路迅速定位到对应的物理地址读快、写慢。要写的页如果有数据,则不能写入,需要将块内其他页 - 全部复制到一个新的(擦除过的)块中,再写入新的页
也就是说,常用的数据放到前面的分区这样的说法对于固态硬盘不适用了,在固态硬盘中,所有的位置都是品等的
读取规则如下:
-
系统对固态硬盘的读取是以页为单位的,也就是传来
逻辑块号之后,转换成的地址是页的地址(对于磁盘来说就是具体到扇区)也就是说,固态硬盘的页相当于磁盘的一个扇区
-
想要重写页,就必须将整个块进行擦除

- 如果只要重写第一页的数据其他页的数据不变,那么
需要将其他页复制到其他块,然后把原来的块擦除
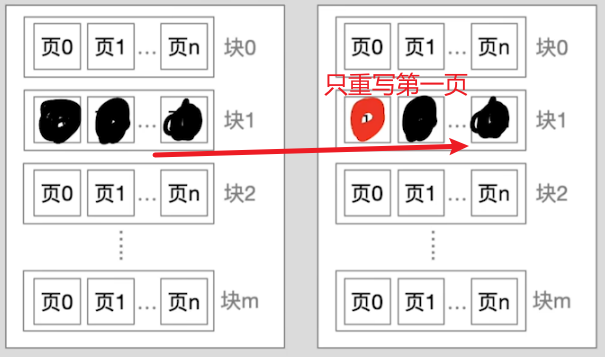
-
但此时出现问题了,那么系统发来逻辑块号之后,对应的物理块号就会变了。
这点由闪存翻译层管理。闪存翻译层会修改逻辑块号到物理块好的映射
(4) 与机械硬盘相比的特点
- SSD读写速度快,随机访问性能高,用电路控制访问位置;机械硬盘通过移动磁臂旋转磁盘控制访问位置,有寻道时间和旋转延迟
- SSD安静无噪音、耐摔抗震、能耗低、造价更贵
SSD的一个"块"被擦除次数过多(重复写同一个块)可能会坏掉,而机械硬盘的扇区不会因为写的次数太多而坏掉
(5) 磨损均衡技术
思想:将"擦除"平均分布在各个块上,以提升使用寿命
- 动态磨损均衡——写入数据时,优先选择累计擦除次数少的新闪存块
- 静态磨损均衡——SSD监测并自动进行数据分配、迁移,
让老旧的闪存块承担以读为主的储在任务,让较新的闪存块承担更多的写任务
比如视频这些不怎么修改,只读的文件,就放在老旧的存储块上
下面讨论一下固态硬盘的寿命
某固态硬盘采用磨损均衡技术,大小为240B=1TB,闪存块的擦写寿命只有210=1K次。某男子平均每天会对该固态硬盘写237B=128GB数据。
在最理想的情况下,这个固态硬盘可以用多久?
SSD采用磨损均衡技术,最理想情况下,SSD中每个块被擦除的次数都是完全均衡的。
- 1TB/128GB= 8
- 因此,平均每8天,每个闪存块需要擦除一次。
- 每个闪存块可以被擦除1K次,因此,经过8K天,约23年后,该固态硬盘被男子玩坏
4.9 总结:文件系统的层次结构
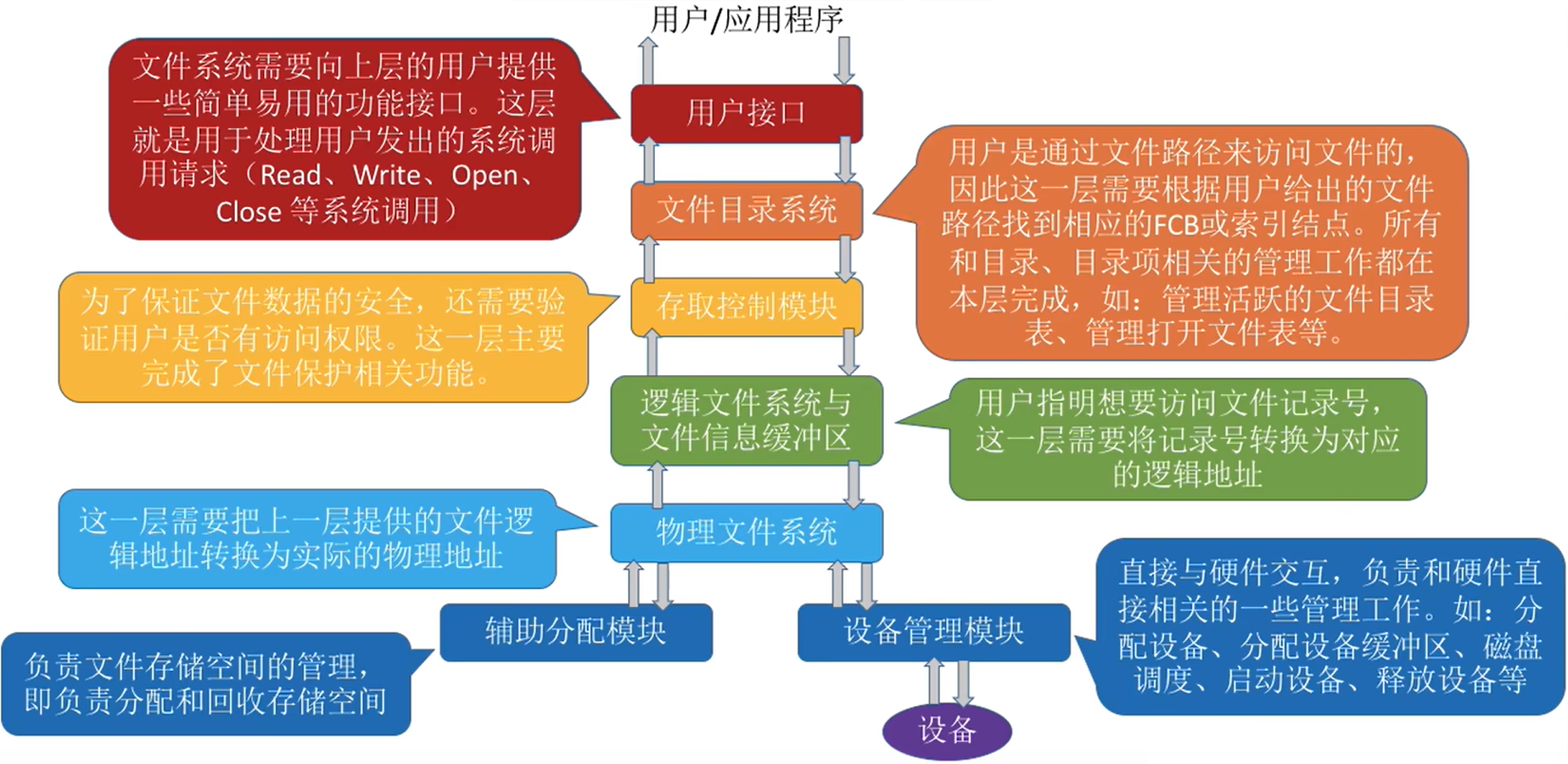
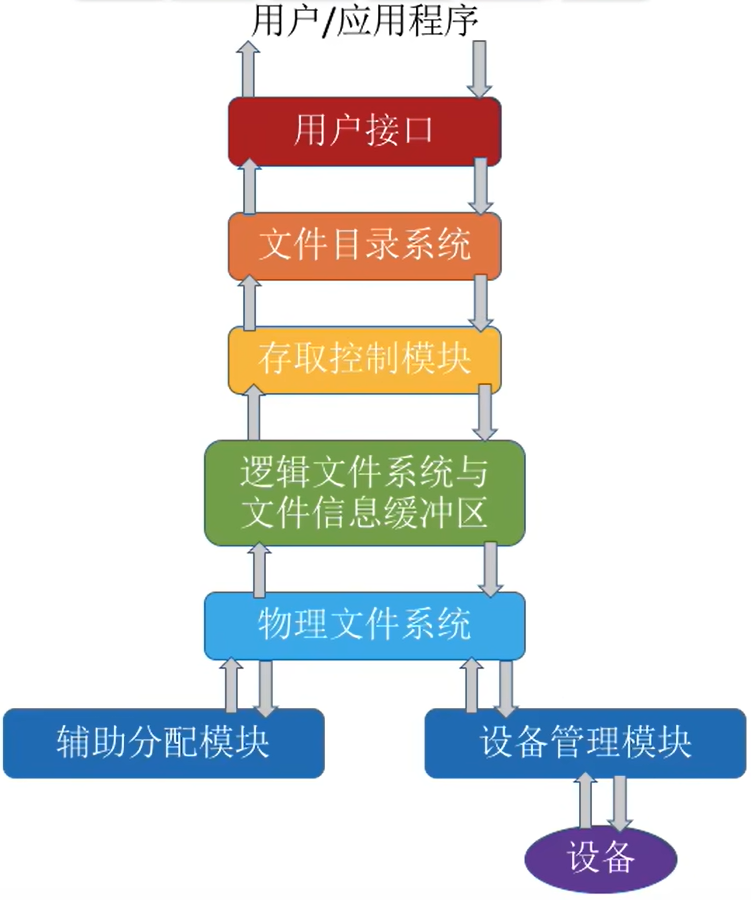
这是对上述多层的结构的总结
 |
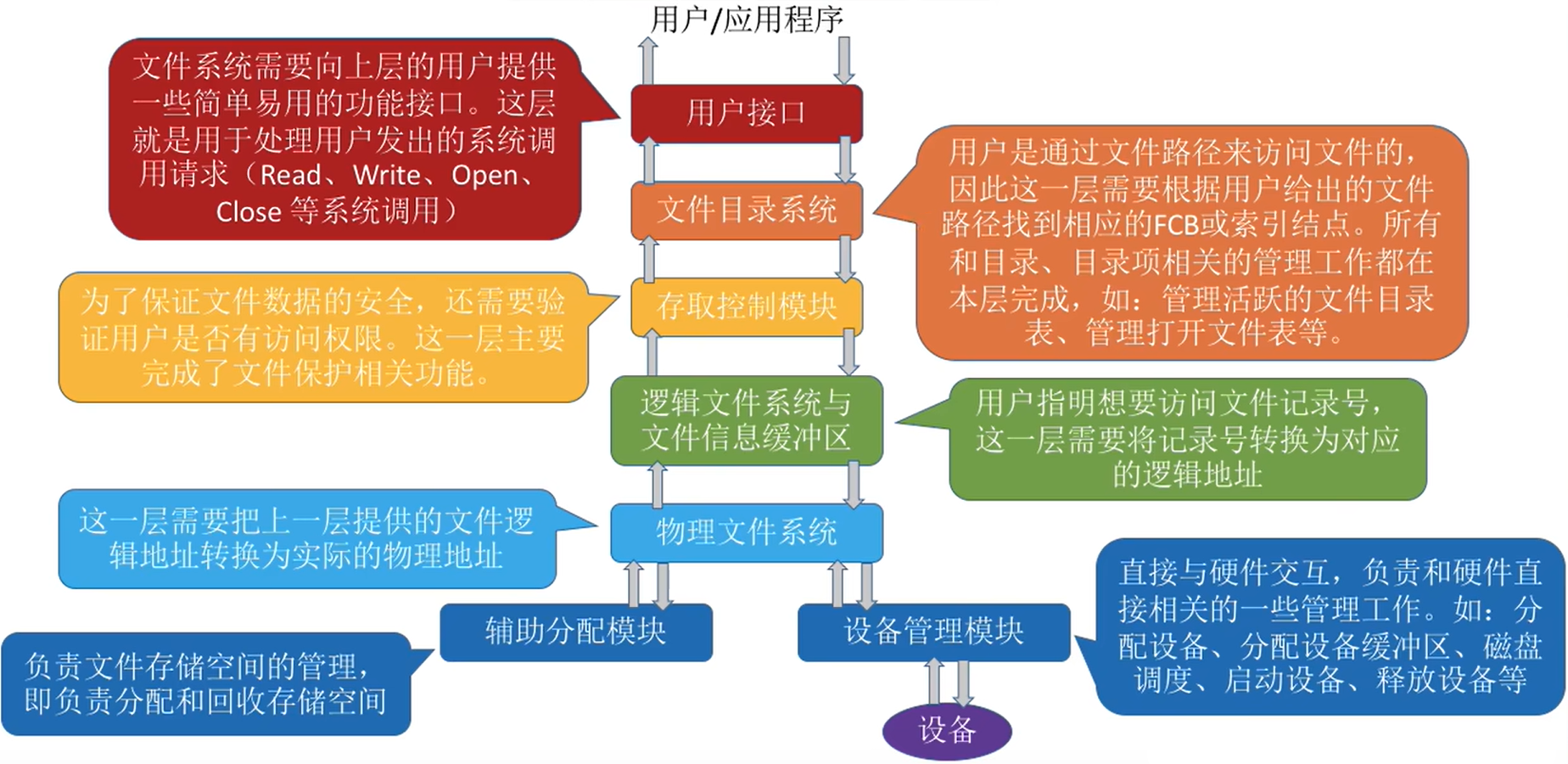 |
|---|
| 层次 | 功能 |
|---|---|
| 用户接口 | 文件系统需要向上层的用户提供一些简单易用的功能接口。这层就是用于处理用户发出的系统调用请求(Read、Write、Open、Close等系统调用) |
| 文件目录系统 | 用户是通过文件路径来访问文件的,因此这一层需要根据用户给出的文件路径找到相应的FCB或索引结点。所有和目录、目录项相关的管理工作都在本层完成如:管理活跃的文件目录表、管理打开文件表等。 |
| 存取控制模块 | 为了保证文件数据的安全,还需要验证用户是否有访问权限。这一层主要完成了文件保护相关功能。 |
| 逻辑文件系统与文件信息缓冲区 | 用户指明想要访问文件记录号,这一层需要将记录号转换为对应的逻辑地址 |
| 物理文件系统 | 这一层需要把上一层提供的文件逻辑地址转换为实际的物理地址 |
| 辅助分配模块 | 负责文件存储空间的管理,即负责分配和回收存储空间 |
| 设备管理模块 | 直接与硬件交互,负责和硬件直接相关的一些管理工作。如:分配设备、分配设备缓冲区、磁盘调度、启动设备、释放设备等 |
用一个例子来辅助记忆文件系统的层次结构:
假设某用户请求删除文件“D:/工作目录/学生信息.xlsx”的最后100条记录。
- 用户需要
通过操作系统提供的接口发出上述请求――用户接口 - 由于用户提供的是文件的存放路径,因此
需要操作系统一层一层地查找目录,找到对应的目录项――文件目录系统 - 不同的用户对文件有不同的操作权限,因此为了保证安全,需要
检查用户是否有访问权限——存取控制模块(存取控制验证层) - 验证了用户的访问权限之后,需要
把用户提供的“记录号”转变为对应的逻辑地址一一逻辑文件系统与文件信息缓冲区 - 知道了目标记录对应的逻辑地址后,还需要转换成实际的物理地址――
物理文件系统 - 要删除这条记录,必定要
对磁盘设备发出请求――设备管理程序模块 - 删除这些记录后,会有一些盘块空闲,因此要将这些空闲盘块回收――
辅助分配模块
下面整体讲述文件系统
4.10 文件系统的全局结构(布局)
从磁盘出厂,到物理格式化,再到逻辑格式化,了解文件系统在外存中是如何一步一步被建立的
4.10.1 磁盘的结构
一般一个笔记本有一个磁盘,总之对于操作系统来说,可以将磁盘看做一个,即使有多个磁盘也是透明的
- 磁盘出厂

- 物理格式化:即低级格式化——划分扇区,检测坏扇区,并用备用扇区替换坏扇区(扇区的替换对于操作系统是透明的)

-
逻辑格式化后,
磁盘分区(分卷volume),完成各分区的文件系统初始化注:逻辑格式化后,
灰色部分就有实际数据了,白色部分还没有数据
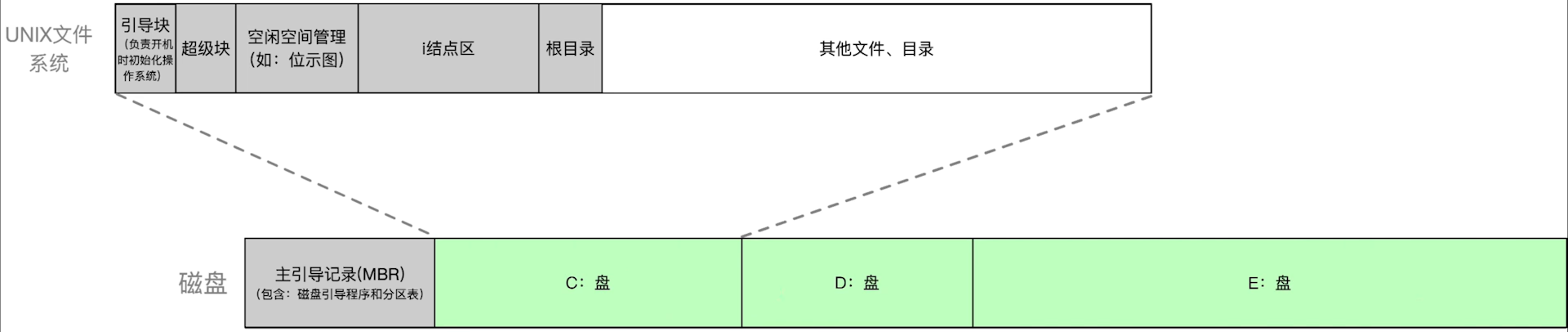
-
逻辑格式化分成了多个分区,
每个分区的大小是多少,起始终止地址在哪里,记录在MBR的分区表中 -
每个分区可以建立自己的
文件系统 -
超级块在磁盘空闲分区里面学过,有了
超级块就可以快速找到磁盘中的空闲磁盘块 -
空闲空间管理,位示图表示一个特定的磁盘块是否被使用
-
i节点区:每个文件都会有对应的
索引节点,Unix中所有的索引节点都是连续存放在i节点区的,以数组的形式索引节点是FCB指向的,因此不用担心顺序问题
4.10.2 文件系统在内存中的位置
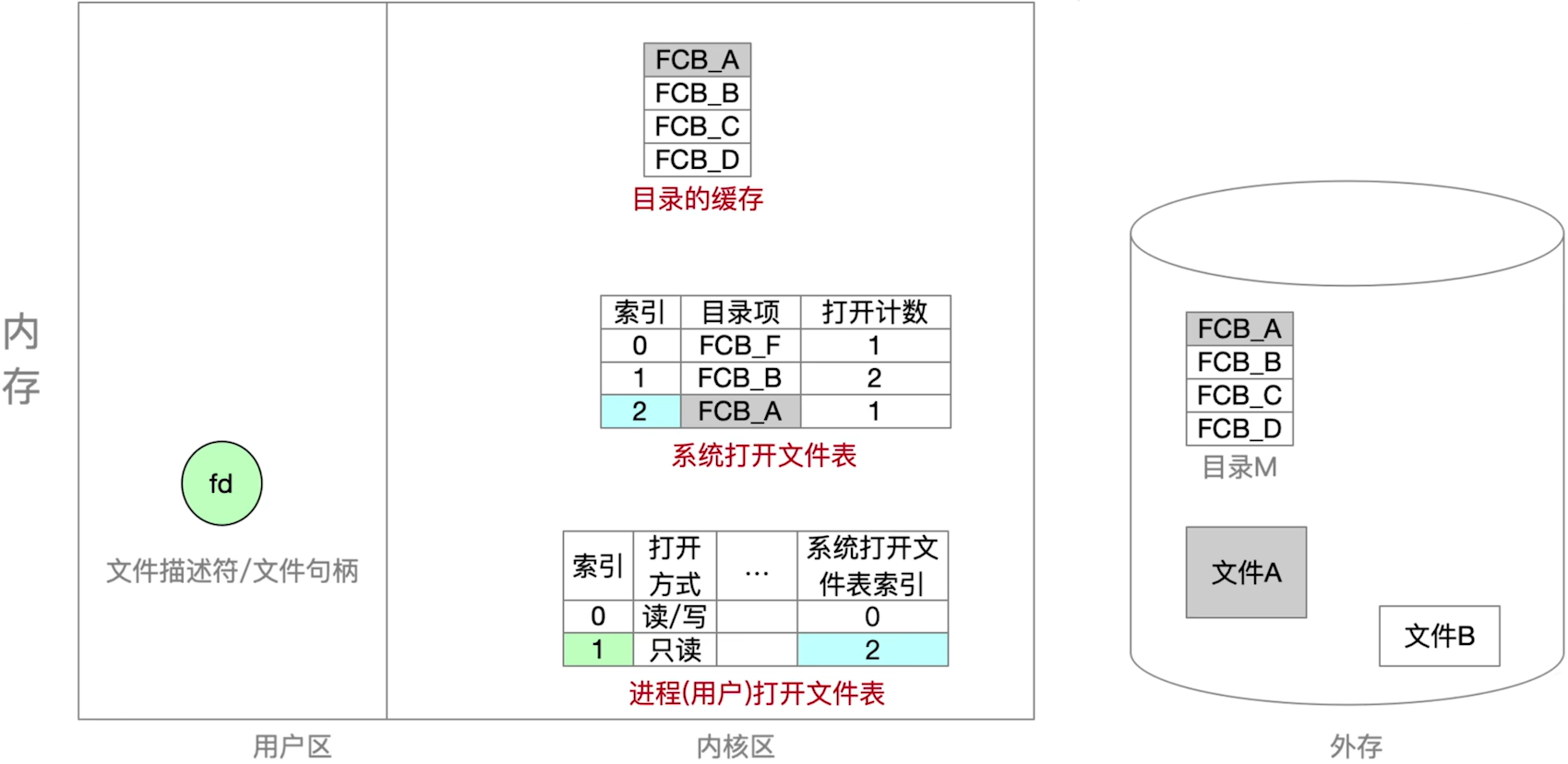
注:近期访问过的目录文件会缓存在内存中,不用每次都从磁盘读入,这样可以加快目录检索速度
会议目录文件是什么,是记录每个目录下文件列表的信息
- open系统调用打开文件的背后过程
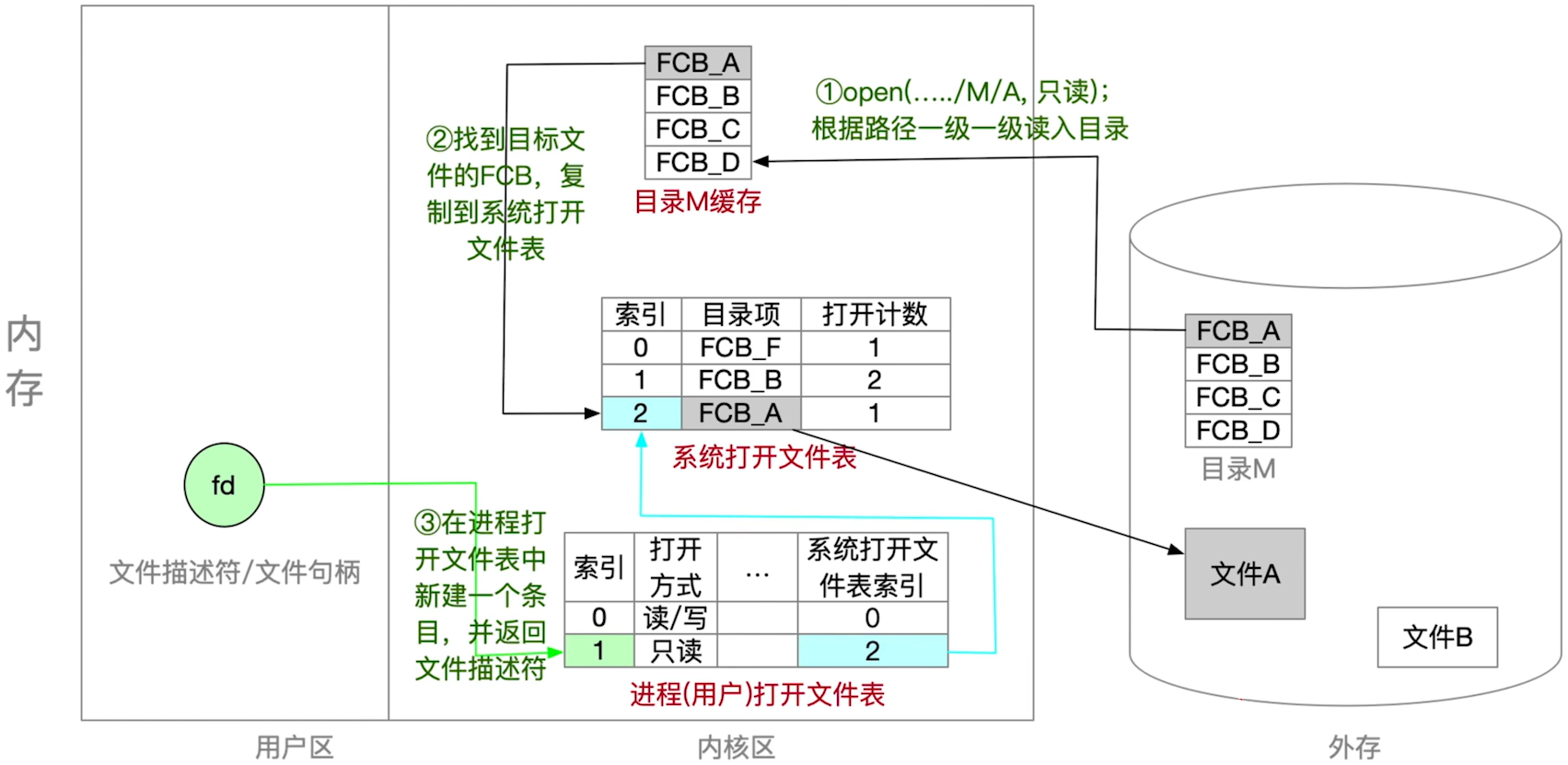
- 在C语言中,打开文件之后就会返回一个句柄fd,使用这个句柄就可以操作文件,因为读取文件的信息保存在内存中了,句柄为关键字
- 类似于socket
- 注意用户的打开文件表和系统的打开文件表之间的关系
4.11 虚拟文件系统
4.11.1 普通的文件系统
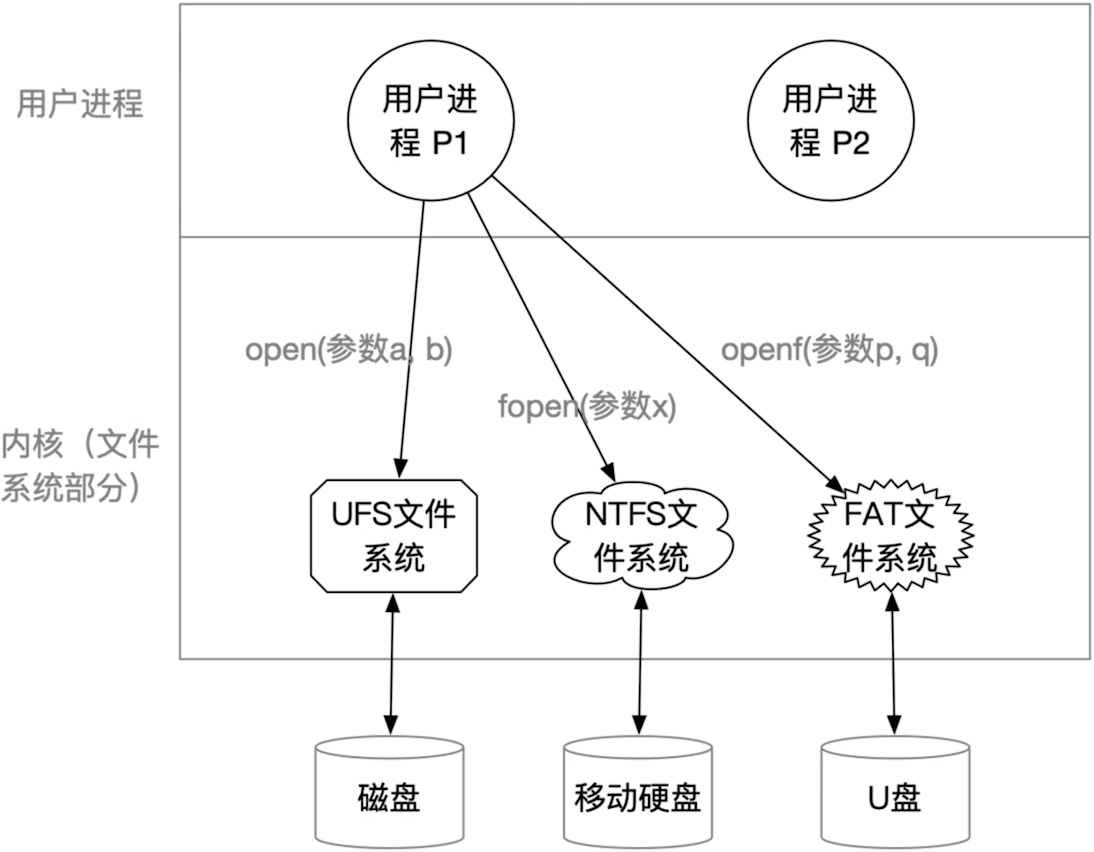
- 不同的硬件,对应的文件格式可能不同其文件接口也可能
- 这样给编程带来了麻烦
- 而且要改动文件的系统的内核
4.11.2 虚拟文件系统
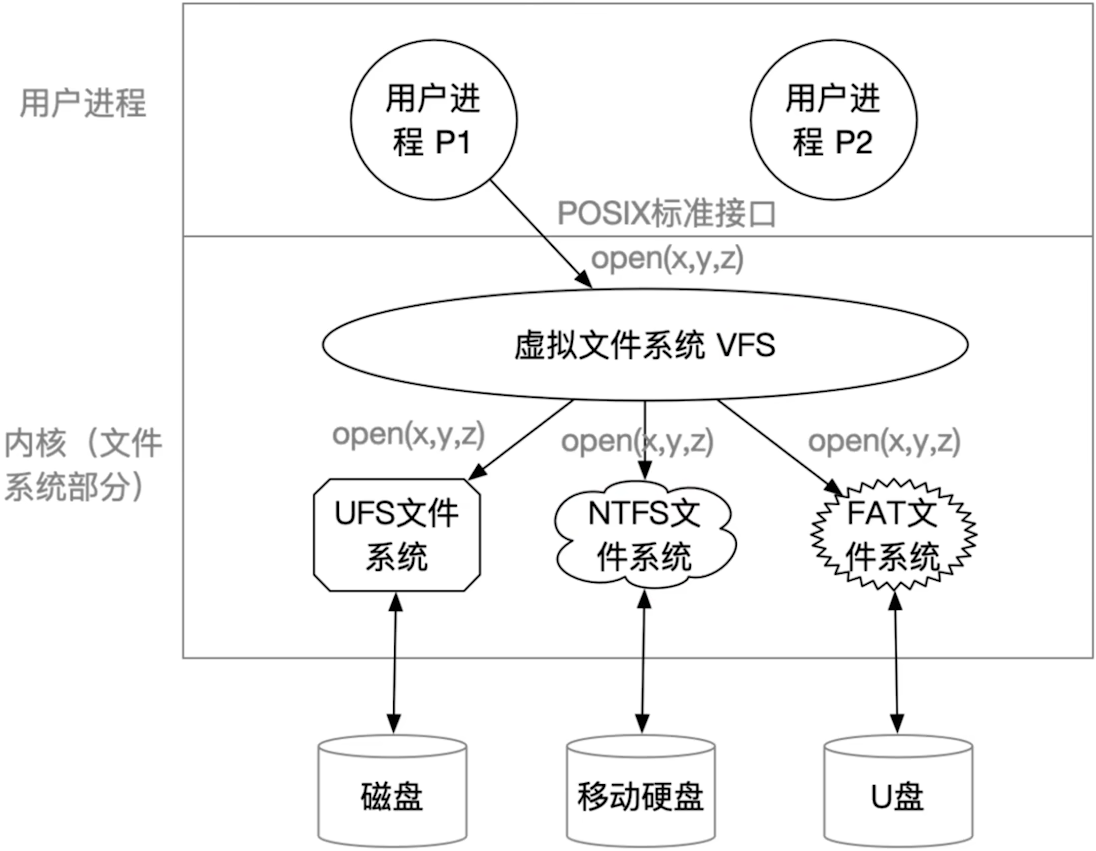
虚拟文件系统的特点:
向上层用户进程提供统一标准的系统调用接口,屏蔽底层具体文件系统的实现差异- VFS
要求下层的文件系统必须实现某些规定的函数功能,如: open/read/write。一个新的文件系统想要在某操作系统上被使用,就必须满足该操作系统VFS的要求
存在的问题:不同的文件系统,表示文件数据结构各不相同。打开文件后,其在内存中的表示就不同
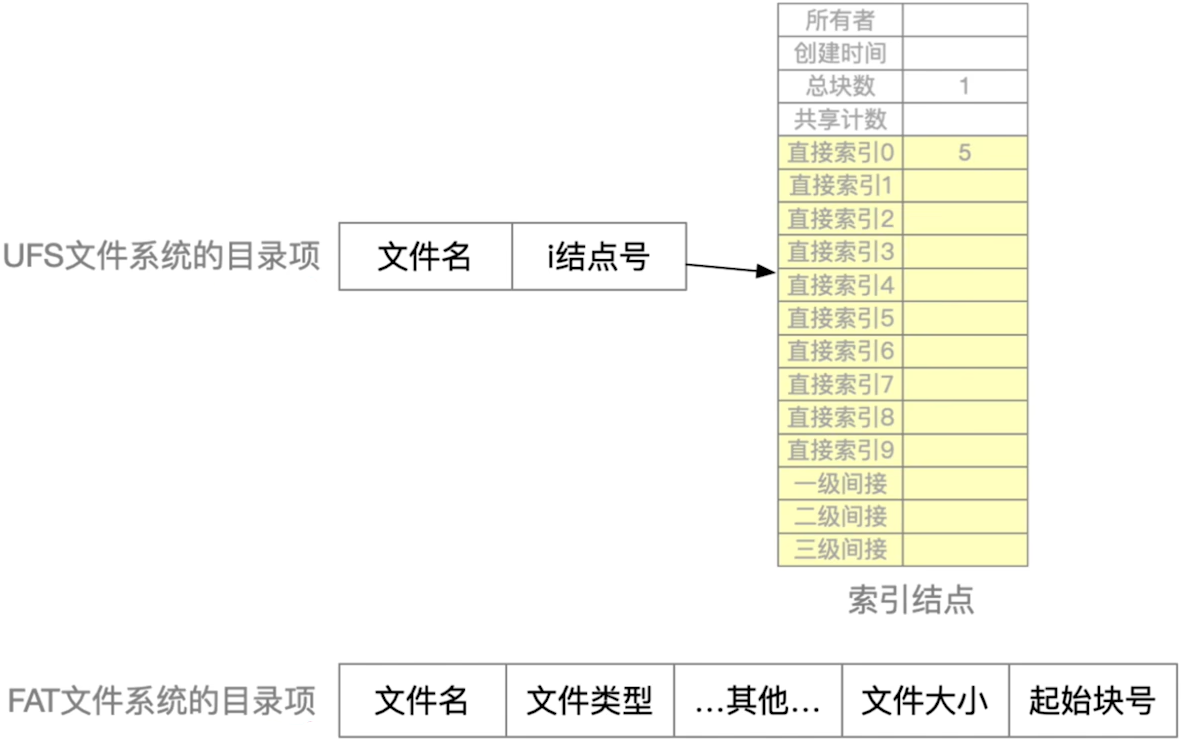
- 目录项就是FCB
- 以U盘为例,U盘插入之后,可以将其看做一个等同于磁盘的硬件,会产生一个新的卷,可以将其看做一个新的目录,里面有自己的目录系统,当然包括文件目录
虚拟文件系统的特点:
- 每打开一个文件,
VFS就在主存中新建一个vnode,用统一的数据结构表示文件,无论该文件存储在哪个文件系统。

- 注意: vnode只存在于主存中,而inode既会被调入主存,也会在外存中存储
如下:打开文件后,创建vnode,并将文件信息复制到vnode中,vnode的功能指针指向具体文件系统的函数功能。
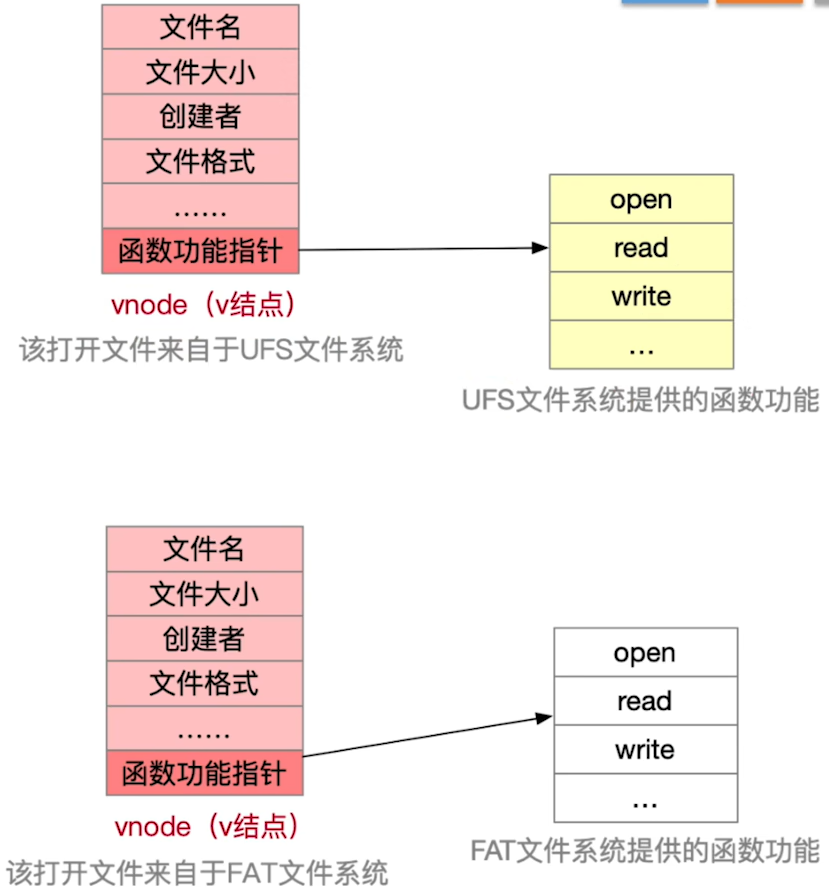
4.12 文件系统挂载
- 文件系统挂载( mounting),即文件系统安装/装载――如何将一个文件系统挂载到操作系统中?
理解文件系统挂载 和 虚拟文件系统的关系 ,挂载是将新的文件系统加入到整个文件当中,虚拟文件系统是统一不同的文件系统,将其整合,为上层提供统一的接口
文件系统挂载要做的事:
- 在
VFS中注册新挂载的文件系统。内存中的挂载表(mount table)包含每个文件系统的相关信息,包括文件系统类型、容量大小等。 新挂载的文件系统,要向VFS提供一个函数地址列表将新文件系统加到挂载点( mountpoint) ,也就是将新文件系统挂载在某个父目录下
将U盘插入到电脑上,那么U盘的文件系统就需要挂载到操作系统上
下面来看挂载点
| Windows | Mac |
|---|---|
 |
 |
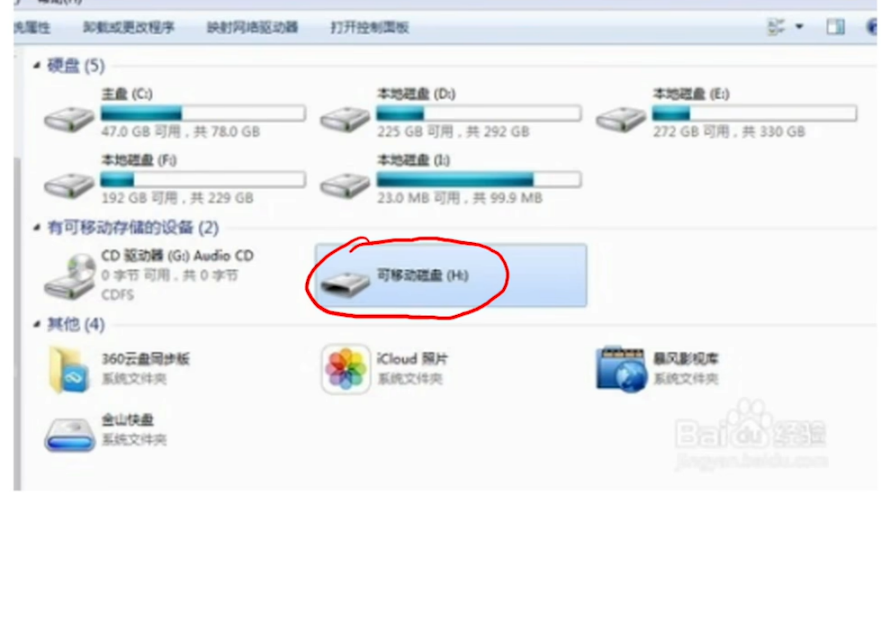
- Windows挂载到磁盘下,与C盘D盘是同等的
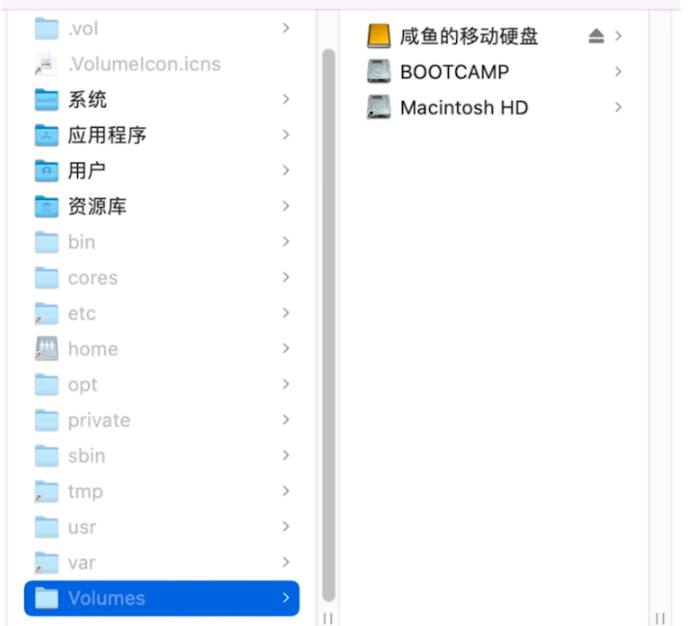
- Mac挂载带Volume目录下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号