计算机网络-第四章-网络层(数据平面)
第四章 网络层:数据平面
4.1 导论
4.1.1 网络层服务
- 在发送主机和接收主机对之间 传送段(segment)
- 在发送端将段封装到数据报中
- 在接收端,将段上交给传输层 实体
- 网络层协议存在于每一个主机 和路由器
- 路由器检查每一个经过它的IP 数据报的头部
- 报是传输层封装好的分组
- 网络层在报的基础上加上首部就成了数据报
- 网络层的每个路由器都需要将分组传递到网络层解析后才能决定转发到哪个路由器
4.1.2 网络层功能
功能不同于服务,服务是对外的结构,功能是内部实现的逻辑
(1) 转发 & 路由
网络层功能:
- 转发: 将分组从路由器的输入接口转发到合适的输出接口
- 路由: 使用路由算法来决定分组从发送主机到目标接收主机的路径
- 路由选择算法
- 路由选择协议
- 转发是局部的,只是当前路由器决定接受到的分组往后传递给哪个路由器;属于数据平面
- 路由是全局的,属于控制平面
(2) 连接建立
对于某些网络而言,网络层提供的第三个服务就是连接建立,包括连接的维持和关闭(之前的两个服务是路由和转发)
-
在某些网络提供有连接的网络,如ATM, frame relay, X.25
有连接:在分组传输之前,在两个主机之间,在通过一些 路由器所构成的路径上建立一个网络层连接;涉及到路由器
面向连接不涉及路由器,仅仅是主机和主机之间
-
网络层和传输层连接服务区别:
- 网络层: 在2个主机之间,涉及到路径上的一些路由器 —— 有连接
- 传输层: 在2个进程之间,很可能只体现在端系统上 (TCP连接) —— 面向连接
4.1.3 数据平面 & 控制平面
-
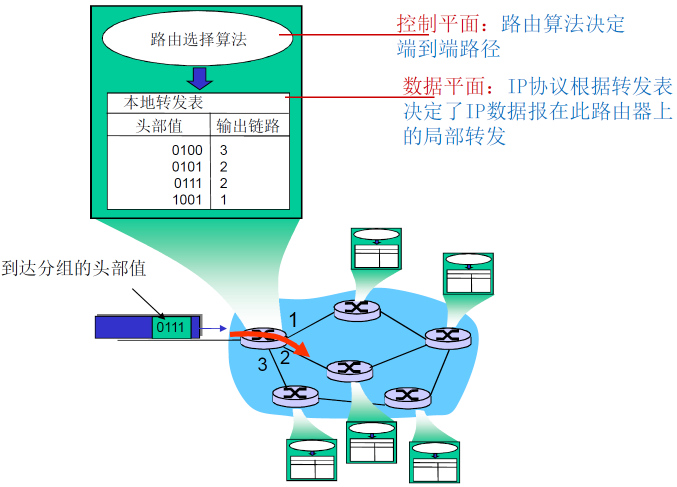
数据平面
- 本地,每个路由器功能
- 决定从路由器输入端口到达的分组如何转发到输出端口
- 转发功能:
- 传统方式:基于目标 地址+转发表
- SDN方式:基于多个字段+流表
可以回过头来看看区别在哪
-
控制平面
- 网络范围内的逻辑
- 决定数据报如何在路由器之间 路由,决定数据报从源到目标主机之间的端到端路径
- 2个控制平面方法:
- 传统的路由算法: 在路由器中被实现(功能单一:根据目标的IP地址进行转发)
- software-defined networking (SDN): 在远程的服务器中实现(匹配很多字段,功能更多:泛洪、转发、修改字段)
传统方式 & SDN方式
传统方式:每-路由器(Per-router)控制平面
- 在每一个路由器中的单独路由器算法元件,在控制平面进行交互
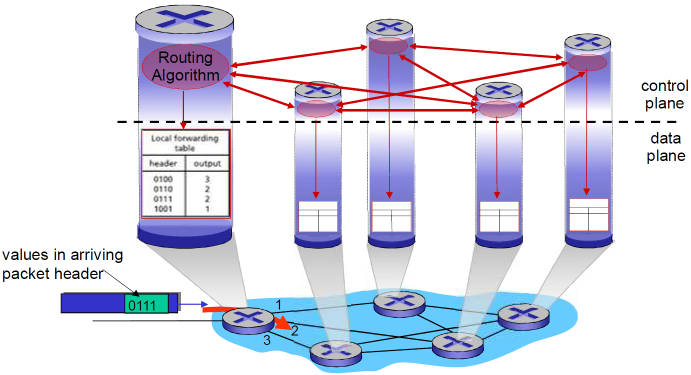
对于TCP/IP网络来说:
- IP协议实现了数据层面的转发功能
- 路由选择协议实体的实现体现了控制层面的路由功能
控制平面的结果体现在路由表,路由表交给IP协议,IP协议对到来的分组转发
路由表是控制平面和数据平面的粘合机
缺点:
- 控制平面和数据平面紧耦合,在一个设备上实现
- 计算路由表是分布式的
更改路由协议非常很难
SDN方式:逻辑集中的控制平面
- 一个不同的(通常是远程的)控制器与本地控制代理(CAs) 交互
- 网络操作系统运行在集中的控制器上
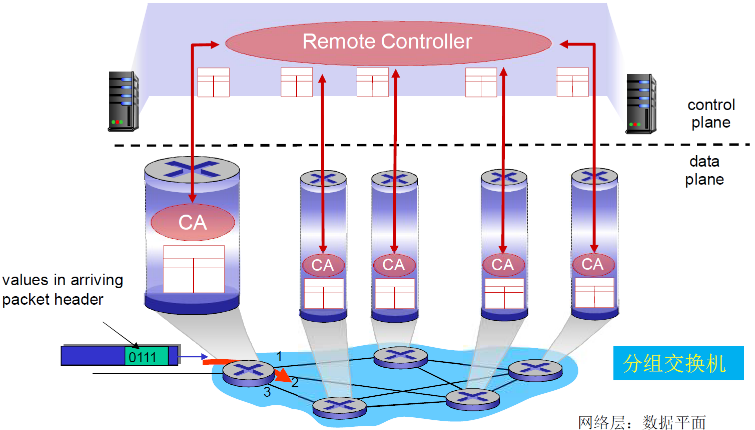
集中式、可编程
4.1.4 网络服务模型
网络向上层提供的服务的指标,可以分为两类
Q: 从发送方主机到接收方主机传输数据报的“通道” ,网络提供什么样的服务模型?
- 对于单个数据报的服务:
- 可靠传送
- 延迟保证,如:少于 40ms的延迟
- 对于数据报流的服务:
- 保序数据报传送
- 保证流的最小带宽
- 分组之间的延迟差(延迟差为0,那么发送就会立即接受到,对于多媒体来说很好)
当这些具体的指标等于相应的值的时候,那么网络层提供的服务可以用术语 "service model(服务模型)"表示
常见的网络服务模型
| 网络架构 | 服务模型 | 是否保证带宽 | 是否保证丢失 | 是否保序 | 是否保证延迟 | 拥塞反馈 |
|---|---|---|---|---|---|---|
| Internet | best effort(尽力而为) | none | no | no | no | no(inferred via loss) |
| ATM | CBR 恒定速率 | constant rate | yes | yes | yes | no congestion |
| ATM | VBR 变化速率 | guaranteed rate | yes | yes | yes | no congestion |
| ATM | ABR 可用比特率 | guaranteed rate | no | yes | no | yes |
| ATM | UBR 不指明比特率 | one | no | yes | no | no |
Internet的IP协议就是best effort,什么都不保证
4.2 路由器组成
高层面(非常简化的)通用路由器体系架构
- 路由:运行路由选择算法/协议 (RIP, OSPF, BGP) - 生成 路由表
- 转发:从输入到输出链路交换数据报 - 根据路由表进行分组的转发

- fabric:将输入端的分组交给输出端,完成局部的转发;根据是路由处理器router processor运行的路由协议的实体(运行当中的软件)运行得到的路由表
- 路由处理器routing processor以及上面运行的实体,运行路由选择算法, 实现了控制平面的功能
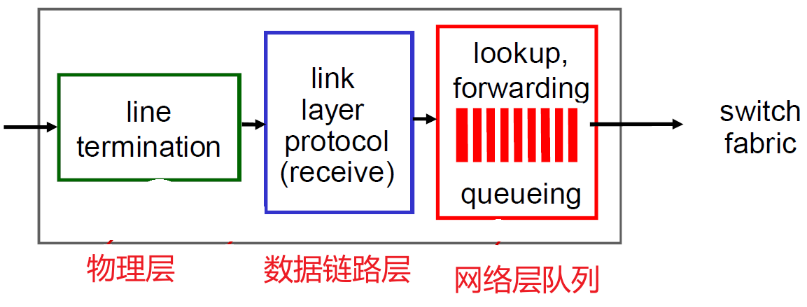
- 红色的是网络层,蓝色的是链路层,绿色的是物理层
一般路由器的输入输出端口是一个端口,这里为了讲原理分开了
4.2.1 输入端口
(1) 功能
输入端口有个队列
功能如下:
-
物理层:链路上的数字信号(比如电信号、光信号等)转换成bit(有的是bit,有的是word)
-
数据链路层:将转换成的bit分成帧(判断哪里是帧头,哪里是帧尾),检查有无出错,判断帧的目标Mac和网卡的Mac是否一致(判断是否接受这个帧),然后取出帧中的数据部分(也就是IP的分组,数据链路层将IP的分组包装成帧了)
-
数据链路层将IP分组交给网络层实体,网络层实体在链路当中排队,排到队头的按照路由表交给合适的端口输出
传统的IP分组是根据分组头部的目标ip,根据路由表来转发
如果是SDN,则会查头部的多个信息,匹配相应流表的字段,按照流标的操作
在网络层是实现的分布式交换
- 根据数据报(网络层分组)头部的信息如:目的地址,在输入端口内存中的转发表中查找合适的输出端口(匹配+行动)
- 基于目标的转发:仅仅依赖于IP数据报的目标IP地址(传统方法)
- 通用转发:基于头部字段的任意集合进行转发
(2) 缓存(队列)的目的
为什么要有队列呢?
缓存的目的:
- 匹配输入速率和输出速率的不一致性
- 因为分组到来的速率可能大于交换的速率(fabric的交换速度肯定比分组到来的速度快)
- 出现延迟原因之一:Head-of-the-Line (HOL) blocking: 排在队头的数据报 阻止了队列中其他数据报向前移动
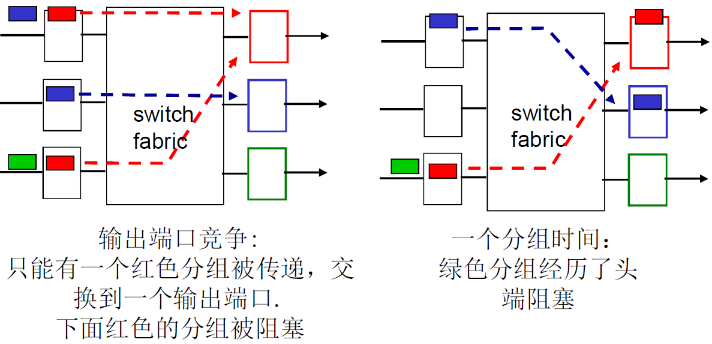
- 如图,开始时,两个红色的竞争上方的输出端口;然后下方的红色分组竞争失败等待,导致绿色分组阻塞了
- 结果是 输出端口的速率要小于输入端口的速率(输入端口的速率大于输出端口的速率)
- 因此需要queue来匹配速度的不一致性
造成的问题:
- 交换机构的速率小于输入端口的汇聚速率时, 在输入端口可能要排队
- 排队延迟
- 由于输入缓存溢出造成丢失
4.2.2 交换结构fabric
(1) 功能
- 任务:将分组从输入缓冲区传输到合适的输出端口
- 交换速率:分组可以按照该速率从输入传输到输 出
- 运行速度经常是输入/输出链路速率的若干倍 (因为输入端口和输出端口有多个)
- N 个输入端口:交换机构的交换速度是输入线路速度的N倍比较理 想,才不会成为瓶颈
(2) 交换结构
3种典型的交换机构
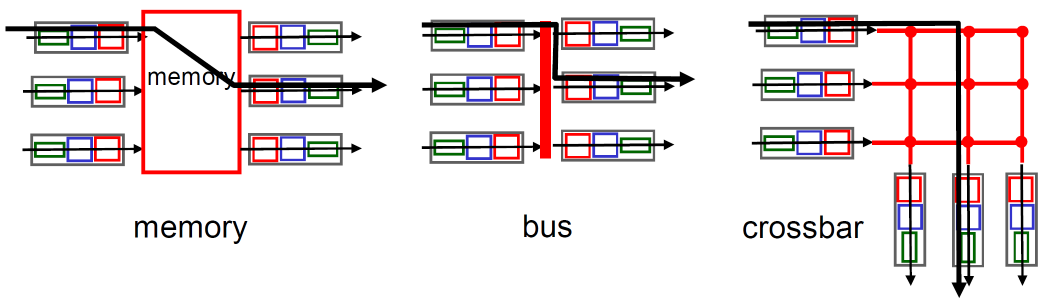
① 通过内存交换
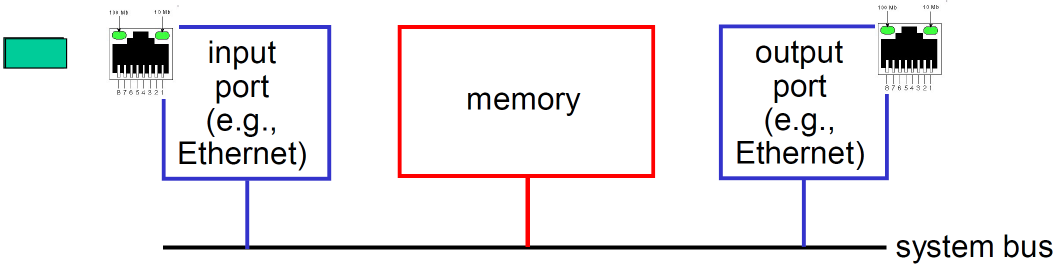
第一代路由器:
- 在CPU直接控制下的交换,采用传统的计算机(通过计算机的软件来实现)
- 分组被拷贝到系统内存,CPU从分组的头部提取出目标地址,查找转发表,找到对应的输出端口,拷贝到输出端口
- 分组要过系统总线两次(input→memory,memory→output),因此系统总线成为了速率的瓶颈(转发速率被内存的带宽限制)
- 一次只能转发一个分组
基于memory的分组交换的问题:分组要经过总线两次
② 通过总线交换
- 数据报通过共享总线,从输入端 转发到输出端口
- 分组加上输出端口的地址被送往总线,分组通过bus的时候所有的输出分组都能够读到,如果是本输出端口的地址就拿到
- 总线竞争: 交换速度受限于总线带宽
- 1次处理一个分组,分组只经过一次bus
- 1 Gbps bus, Cisco 1900; 32 Gbps bus, Cisco 5600;
对于接 入或企业级路由器,速度足够( 但不适合区域或骨干网络)

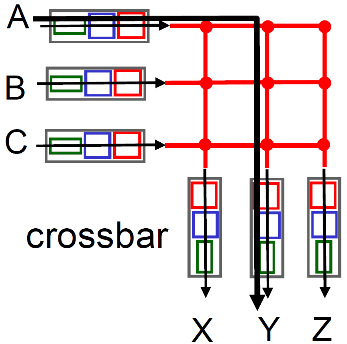
③ 通过互联网络(crossbar等)的交换
这里的互联网络并不是指互联网
-
同时并发转发多个分组,克服总线带宽限制
-
Banyan(榕树〉网络,crossbar(纵横)和其它的互联网络被开发,将多个处理器连接成多处理器
-
当分组从端口A到达,转给端口Y;控制器短接相应的两个总线
-
高级设计:将数据报分片为固定长度的信元,通过交换网络交换
-
Cisco12000:以60Gbps的交换速率通过互联网络
4.2.3 输出端口

- 数据链路层:将分组分成帧
- 物理层:将bit转成物理信号传输
- 当数据报从交换机构的到达速度比传输速率快就需要输出端口缓存(数据报(分组)可能会被丢弃,由于拥塞,缓冲区没有空间)
- 由调度规则选择排队的数据报进行传输
队列中的分组不一定按到达的先后顺序输出的
(1) 输出端口排队
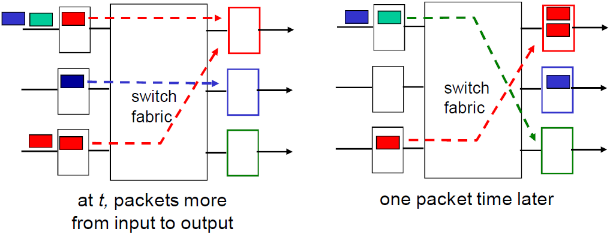
由图中可以看到,多个输入端口会向一个输出端口输出
- 假设交换速率Rswitch是Rline的N倍(N:输入端口的数量)
- 当多个输入端口同时向输出端口发送时,缓冲该分组(当通 过交换网络到达的速率超过输出速率则缓存)
- 排队带来延迟,由于输出端口缓存溢出则丢弃数据报
需要缓存的数量
RFC 3439 拇指规则(经验性规则):平均缓存大小=典型的RTT(例如:250ms)倍于链路容量C
例如:
- C = 10 Gpbs link
- 250ms *10Gbps=2.5 Gbit buffer
最近的一些推荐:有N(非常大)个流,缓存大小等于
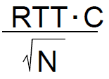
(2) 调度机制
由上所说:到达缓冲区的分组不是先到达先输出的顺序
- 调度: 选择下一个要通过链路传输的分组
① FIFO
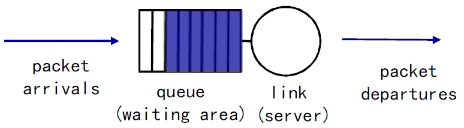
- FIFO (first in first out) scheduling: 按照分组到来的次序发送
- 丢弃策略: 如果分组到达一个满的队列,哪个分组将会 被抛弃?
- tail drop: 丢弃刚到达的分组
- priority: 根据优先权丢失/移除分组(分组是有优先权的,比如有VIP)
- random: 随机地丢弃/移除
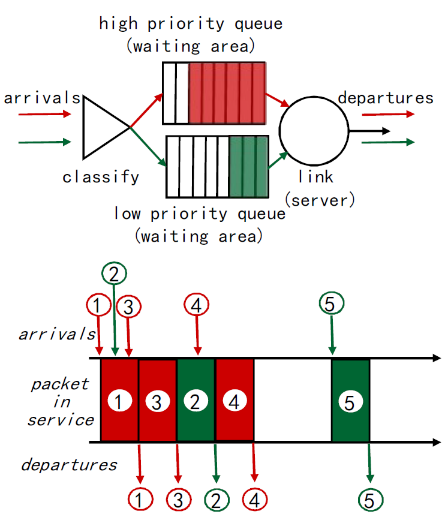
② 优先权
优先权调度:发送最高优先权的分组
- 多类,不同类别有不同的 优先权
- 类别可能依赖于标记或者其 他的头部字段, e.g. IP source/dest, port numbers, ds,etc.
- 先传高优先级的队列中的分 组,除非没有
- 高(低)优先权中的分组传 输次序:FIFO
有红的不传绿的
③ Round Robin (RR) scheduling
- 多类
- 循环扫描不同类型的队列, 发送完一类的一个分组 ,再发送下一个类的一个分组,循环所有类
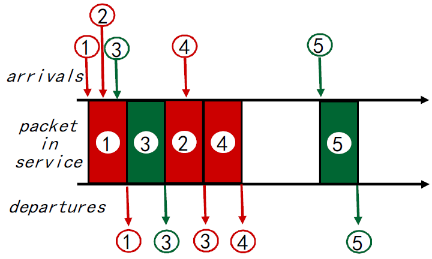
- 假如有红绿蓝三种颜色的分组(实际上代表三种分类),传一个红的再传一个绿的再传一个蓝的
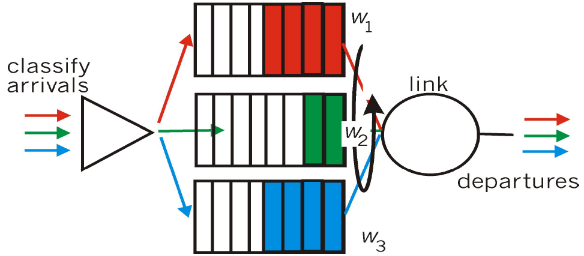
④ Weighted Fair Queuing (WFQ)
- 一般化的Round Robin
- 在一段时间内,每个队列得到的服务时间是: Wi /(XIGMA(Wi )) *t ,和权重成正比
- 每个类在每一个循环中获得不同权重的服务量
- 现实例子
4.3 IP协议
IP: Internet Protocol(这就是互联网的协议)
4.3.1 网络层协议组成及功能
主机,路由器中的网络层功能:
网络层主要就是如下三种协议并实现了功能
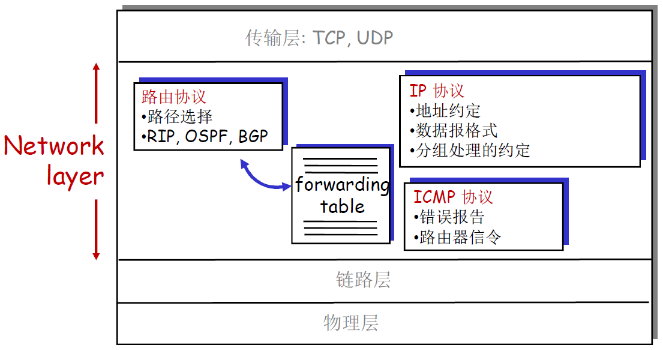
- 路由协议:RIP,OSPF,BGP实现控制平面的路由功能;其体现就是路由表/转发表
- IP协议:根据得到的转发表/路由表,查询分组头部的目标地址匹配路由表的表现;实现的是数据平面的转发功能
- ICMP:信令协议(比如测试往返延迟的测试,要发出一些测试的ICMP分组,当分组被路由器抛掉的时候,向源主机发送ICMP报告)
- ICMP分组并不是实现路由转发功能的
- 是进行测试延迟等功能而产生了ICMP协议,并且ICMP协议只有网络层即可
- ping的本质就是发送ICMP分组
4.3.2 IP数据报格式
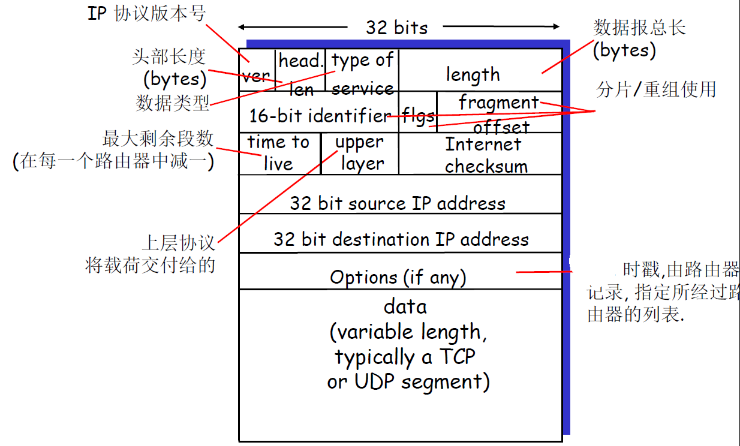
| 项目 | 说明 |
|---|---|
| ver | 版本号,如Ipv4就是0100 |
| head len | 头部的长度,一般头部是20个字节(也就是上图中的5行),但是也有可选项,也就是头部是变长的,因此可以使用head len来计算可选项 |
| type of service | 数据段的类型,本来为输出队列的调度机制提供参考的,但后来废弃了 |
| length | 数据报总厂 |
| 16-bit的id,flags fragment offset |
时候了后面的分片/重组 |
| time to live(TTL) | 可用以ICMP协议 |
| upper layer | 将负载交给的上层协议,比如说TCP,还是UDP,还是ICMP,实际上是根据端口号区分的 |
| Internet checksum | 校验头部的 |
IP数据报传输TCP段时头部有多少?
- 20 bytes of TCP
- 20 bytes of IP
- = 40 bytes + app layer overhead
4.3.3 IP分片和重组
(Fragmentation & Reassembly)
-
网络链路有MTU (最大传输单元) –链路层帧所携带的最大数据长度
-
不同网络的MTU也是不同的,比如FDDI的MTU是400个字节,以太网(Internet)的MTU是1500个字节
-
一个路由器可以插入多个网卡,也就可以接受或输出多个网络的分组
-
当接受的分组较大但是输出的网络的MTU较小时,就需要分组
这里将的MTU是指不包括IP头部的长度,但是包括传输层头部,比如TCP/IP头部
- 大的IP数据报在网络上被分片 (“fragmented”)
- 一个数据报被分割成若干个小 的数据报
- 相同的ID
- 不同的偏移量
- 最后一个分片标记为0
- 一个数据报被分割成若干个小 的数据报
- IP头部的信息被用于标识,排序相关分片
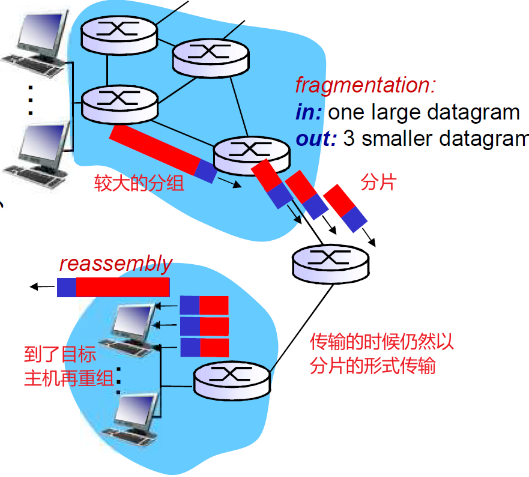
- “重组”只在最终的目标主机进行:减少路由器的负担,要是每个路由器都重组再分片压力太大
- 当目标主机收到了第一个分片的时候,会启动定时器,如果定时器接受还没有收到全部分片,那么就会丢弃这组的所有分片
例题
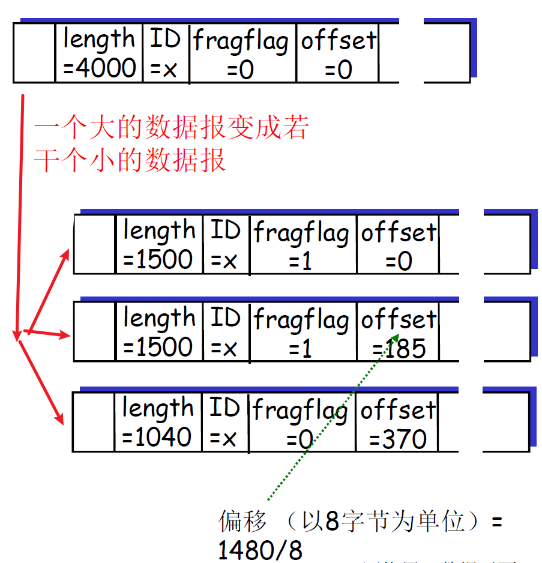
- (接受到了)4000 字节数据报:
- 20字节头部
- 3980字节数据
- MTU = 1500 bytes
- 第一片:20字节头部+1480字节数据;偏移量:0
- 第二片:20字节头部+1480字节数据(1480字节应用数据);偏移量:1480/8=185
- 第三片:20字节头部+1020字节数据(应用数据);偏移量:2960/8=370
传输层(如TCP)的头部都不变,照搬下来,数据段分片;最终还是都要加上网络层的头部
4.3.4 IP编址及转发
(1) IP地址基本概念
① IP地址概念
- 平常所说的主机的IP、路由器的IP都是不准确的
- IP地址是用来标识设备(主机设备、路由器设备等)和网络接口的点的表示
- 如下,一个路由器插了3个网卡,就有三个点,分别接入三个网络

- 一个路由器至少有两个网卡以上,否则无法进行转发
- 主机也可以有多个地址
- IP 地址: 32位标示,对主机或者路由器的接口编址
- 接口: 主机/路由器和物 理链路的连接处
- 路由器通常拥有多个接口
- 主机也有可能有多个接口
- IP地址和每一个接口关联
- 一个IP地址和一个接口相关联

同一个网络内的转发可以一跳实现
② 子网(Subnets)
a. 子网的特点
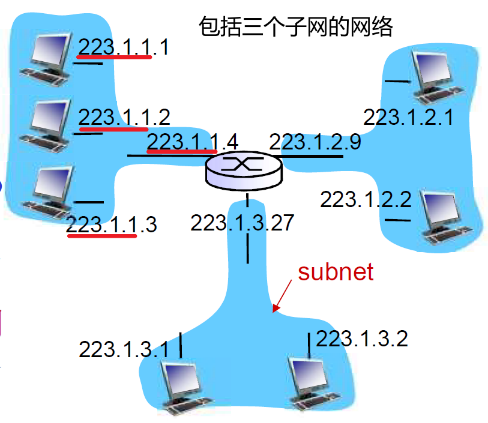
什么是子网(subnet) ?
- 一个子网内的节点(主 机或者路由器)它们的 IP地址的高位部分相同 ,这些节点构成的网络的一部分叫做子网
- 子网内节点的分组的收发无需路由器介入(借助交换机即可),子网内各主机可以在物理上相互直接到达 ——只需要交换机即可,一跳可达
b. 如何划分子网
如何划分子网?
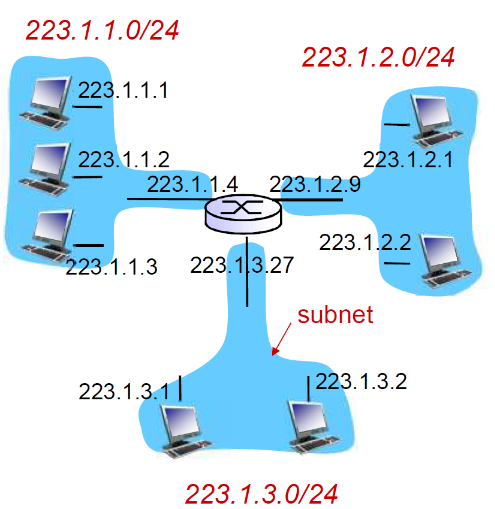
方法:
- 要判断一个子网, 将每一个接口从主机或者路由 器上分开,构成了一个个网络的孤岛
- 每一个孤岛(网络)都 是一个都可以被称之为 subnet.
这样划分得到的子网叫做
但是实际上三个纯子网合起来也可以叫做一个子网,因为它们的前缀(前两位)一样,对于外部来说就是一个子网
(这也符合透明性的特点)
例题:如下有几个子网
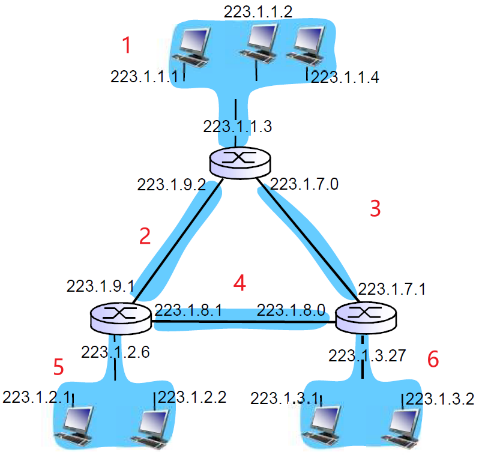
- 路由器之间的也叫作子网,也是一条可达的
- 点到点的链路一般用于长途链路
- 多点连接—计算机局域网
子网掩码:11111111 11111111 11111111 00000000
Subnet mask: /24
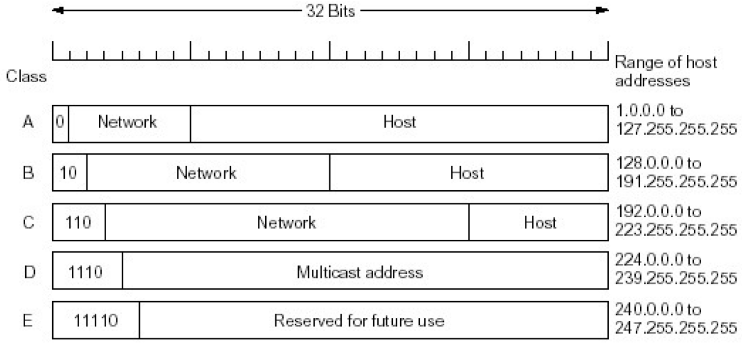
③ IP地址类型
a. IP地址分类
注意:全0的网络和全1的网络不用,所以计算得到的数量要-2
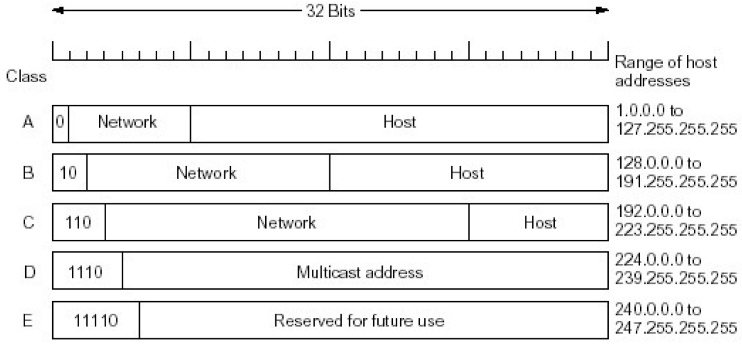
如果Host全为0的话,那么可以称之为某个网络,比如xxx.xxx.0.0
| 分类 | IP类型 | 特点 | 网络数 | 每个网络的主机数 | 说明 |
|---|---|---|---|---|---|
| 单播 | A类 | 第一位是0,后面7位是网络,剩下的是主机 | 126 ( = 27 - 2 ) | 16million ( = 224 - 2) | A类网络是一个巨大的网络,因为每个网络的主机数目很多 但是A类网络只有126个,早已经被分完了 |
| 单播 | B类 | 前两位是10,后面14位是网络号,剩下下的是网络号 | 16382 ( = 214 - 2) | 64K ( = 216 - 2) | 也很大,跨国公司等适用;等数目的但是也被分完了 |
| 单播 | C类 | 前面3位是100,后面的21位是网络号,剩下的是主机号 | 2 million ( = 2 21 - 2) | 254 ( = 28 - 2) | 一般使用的是这个网络 所以可以看到我们的值前缀一般都是192-224之内的网络,这些都是C类网络 |
| 主播 | D类 | 前缀是1110,后面是主播地址 | |||
| 预留 | E类 | 前缀是11110 |
- 单播是点到点的播送
- 广播是我到所有,一般是局域网内的广播
- 传统的IP地址方式,不需要掩码,只用判断前缀就可知道是哪种地址,从而进行解析
b. 特殊IP地址
- 一些约定:
- 子网(网络)部分全为0,表示本网络
- 主机部分全为0,表示本主机
- 主机部分全为1表示,广播地址,这个网络的所有主机
- 除了前面的类号 全为1——在本地网络广播

如上:
-
全为0,表示本主机
-
网络和主机全为1:表示本网络的所有节点
-
网络全为0,主机不全为0
-
网络部分全为0:表示本网络
-
主机不全为0:表示某个节点
因此表示本网络的某个节点
-
-
网络不全为0,主机全为1:
- 网络不全为0,表示某个网络
- 主机全为1,表示这个网络的所有主机
- 网络为127:即全1,表示回路地址Loopback
- 也就是分组从TCP/UDP到了IP之后,又反转朝上
- 也称为测试地址,一般ping 127.0.0.1就是在ping自己
- 当然127.后面可以跟任意的数据,比如127.13.24.11等
c. 内网(专用)IP地址
- 专用地址:地址空间的一部份供专用地址使用
- 永远不会被当做公用地址来分配, 不会与公用地址重复
- 只在局部网络中有意义,区分不同的设备
- 路由器不对目标地址是专用地址的分组进行转发
- 专用地址范围
| IP类型 | 专用地址范围 | MASK |
|---|---|---|
| A类 | 10.0.0.0-10.255.255.255 | 255.0.0.0 |
| B类 | 172.16.0.0-172.31.255.255 | 255.255.0.0 |
| C类 | 192.168.0.0-192.168.255.255 | 255.255.255.0 |
- 所以并不是看到10打头的就是一个A类网络
- 在A类中,11开始的才是作为公网吧
- 一般在子网内使用的192.168.0.1这个一定不是公网,只是局域网
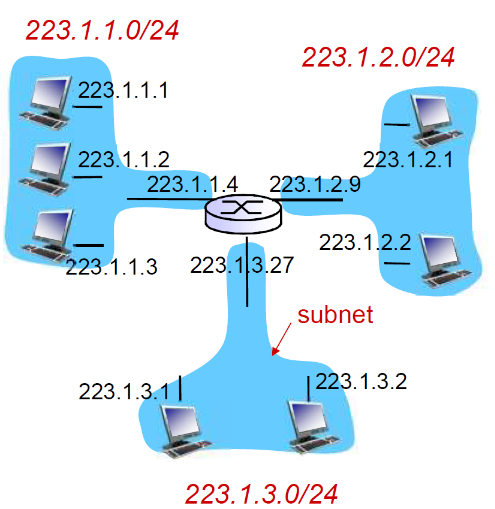
④ 路由单位
- 路由器路由的单位并是不一个节点,而是以网络为单位进行路由、传播和计算
- 网络总共有232个地址,如果使用IP作为路由单位,那么路由的计算量很大;由于在子网内部可以传输,因此以网络为路由表中的表象
- 路由聚集:如下,三个子网的前两个前缀是一样的
⑤ CIDR(无类域间路由)
解决问题:比如C类网络的host数太少了,CIDR可以按需分配
C类网络内只可分254个
CIDR: Classless InterDomain Routing (无类域间路由)
- 子网部分可以在任意的位置(而不必是固定的位置)
- 地址格式:
a.b.c.d/x, 其中 x 是 地址中子网号的长度
如下,200.23.16.0/23,表示子网只有前23位,9位是host位

所以对剩下B类地址的划分都是采用无类域间路由的方式划分
按需分配:
- 比如网络内有1000个地址,那么10位是host号,剩下的是网络号
⑥ 子网掩码(subnet mask)
- 32bits ,0 or 1 in each bit
- 1: bit位置表示子网部分
- 0: bit位置表示主机部分
- 原始的A、B、C类网络的子网掩码分别是
| 网络类型 | 子网掩码(2进制) | 子网掩码 |
|---|---|---|
| A类 | 255.0.0.0 | 11111111 00000000 00000000 00000000 |
| B类 | 255.255.0.0 | 11111111 11111111 0000000 00000000 |
| C类 | 255.255.255.0 | 11111111 11111111 11111111 00000000 |
上述所说,路由的单位是网络,因此得到IP后,根据子网掩码就能得到其网络号
子网掩码的表示方式:
-
CIDR下的子网掩码例子,表示后面的10位是主机部分
- 1111111111111111 11111100 00000000
-
另外的一种表示子网掩码的表达方式
- /#
- 例:/22:表示前面22个bit为子网部分
(2) 转发表和转发算法
| Destination Subnet Num | Mask | Next hop | Interface |
|---|---|---|---|
| 202.38.73.0 | 255.255.255.192 | IPx | Lan1 |
| 202.38.64.0 | 255.255.255.192 | IPy | Lan2 |
| ... | |||
| Default | IPz | Lan0 |
- 获得IP数据报的目标地址
IP Des addr - 遍历转发表中的每一个表项
- 如 (IP Des addr) & (mask) == destination, 则按照表项 对应的接口转发该数据报
- 如果都没有找到,则使用默认表项转发数据报,一般是整个网络的出口 default Gateway
4.3.5 如何获得一个IP地址
(1) 主机获取IP地址
Q: 主机如何获得一个IP地址?
① 手动配置
系统管理员将地址配置在一个文件中
- Wintel: control-panel->network- >configuration->tcp/ip->properties
- UNIX: /etc/rc.config
要配很多信息:
- ip地址
- default Gateway
- 子网掩码
- local ip server(域名解析系统DNS的ip地址)
② DHCP
a. 功能
DHCP: Dynamic Host Configuration Protocol: 从服务器中动态获得一个IP地址
- 子网内必须有DHCP服务器
- 可以为每个主机自动配置手动配置的4个信息
- 目标:允许主机在加入网络的时候,动态地从服务器那里获得IP地址
- 要求:
- 可以更新对主机在用IP地址的租用期-租期快到了
- 重新启动时,允许重新使用以前用过的IP地址
- 支持移动用户加入到该网络(短期在网)
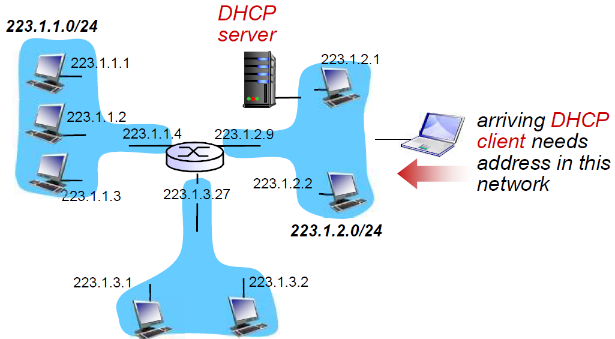
DHCP: 不仅仅获得IP addresses
DHCP 返回:
- IP 地址
- 第一跳路由器的IP地址(默认网关)
- DNS服务器的域名和IP地址
- 子网掩码(指示地址部分的网络号和主机号)
实际上就是手动配置的四项
b. 分配IP工作流程
DHCP是UDP服务
- DHCP工作概况:
| 阶段 | 含义 | 源地址 | 目标地址 |
|---|---|---|---|
| 主机上限时广播“DHCP discover”报文 | 问一下有活着的DHCP服务器吗 | 0.0.0.0 32全0的本机地址,因为此时还没有分配ip地址 |
255.255.255.255 (32位全1的广播地址,因为不知道DHCP服务在哪) |
| DHCP服务器用“DHCP offer”单播提供报文响应 | DHCP服务器表明自己的存在; 并且包含分配给主机的关于ip的配套信息(包括那四项) |
DHCP服务器的地址 | 255.255.255.255 也是全局广播,根据事务号来区分 |
| 主机单播请求IP地址:发送“DHCP request”报文 | 主机向DHCP服务器确定ipp配置信息 | 0.0.0.0 也是表示自己的地址 |
255.255.255.255 也是广播 |
| DHCP服务器发送地址:“DHCP ack”报文 | DHCP把配置信息给主机 | DHCP服务器的地址 | 255.255.255.255 广播 |
全部都是广播,通过事务号来划分
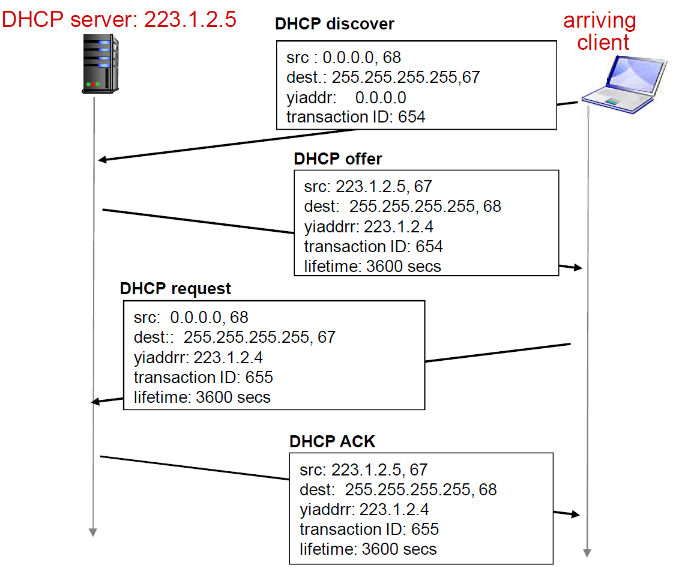
- lifetime:3600s表示3600s后会收回这个ip地址;3600s又要重新请求这个ip地址
- 要有第二次请求是因为一个机构中可能有多个DHCP,这样客户端表明使用其中一个
c. 实例
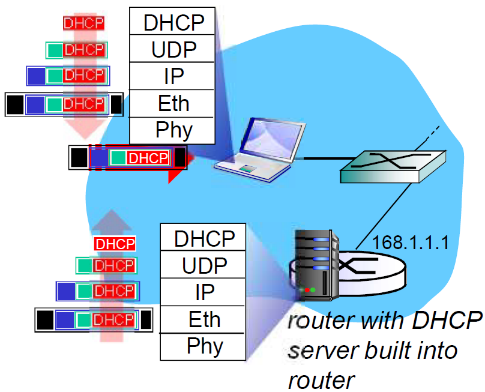
第一次握手:
-
客户端请求:
- 笔记本需要获取自己的IP地址、第一跳路由器地址、DNS服务器以及子网掩码:采用DHCP协议
- 笔记本发出的DHCP请求被封装在UDP段中,封装在IP数据报中,封装在以太网的帧中
- 以太网帧在局域网范围内广播(dest: FFFFFFFFFFFF)
被运行DHCP服务的路由器收到 - 在DHCP服务器中,以太网帧解封装成IP,IP解封装成UDP,解封装成DHCP
-
DHCP服务端响应
- DHCP服务器生成DHCP ACK,包含客户端的IP地址,第一跳路由器的IP地址和DNS域名服务器的IP地址
- DHCP服务器封装的报文所在的帧转发到客户端,在客户端解封装成DHCP报文
- 客户端知道它自己的IP地址,DNS服务器的名字和IP地址,第一跳路由器的IP地址
第二次握手:客户端向特定的DHCP服务器确认
/*request*/
Message type: Boot Request (1)
Hardware type: Ethernet
Hardware address length: 6
Hops: 0
Transaction ID: 0x6b3a11b7
Seconds elapsed: 0
Bootp flags: 0x0000 (Unicast)
Client IP address: 0.0.0.0 (0.0.0.0)
Your (client) IP address: 0.0.0.0 (0.0.0.0)
Next server IP address: 0.0.0.0 (0.0.0.0)
Relay agent IP address: 0.0.0.0 (0.0.0.0)
Client MAC address: Wistron_23:68:8a (00:16:d3:23:68:8a)
Server host name not given
Boot file name not given
Magic cookie: (OK)
Option: (t=53,l=1) DHCP Message Type = DHCP Request
Option: (61) Client identifier
Length: 7; Value: 010016D323688A;
Hardware type: Ethernet
Client MAC address: Wistron_23:68:8a (00:16:d3:23:68:8a)
Option: (t=50,l=4) Requested IP Address = 192.168.1.101
Option: (t=12,l=5) Host Name = "nomad"
Option: (55) Parameter Request List
Length: 11; Value: 010F03062C2E2F1F21F92B
1 = Subnet Mask; 15 = Domain Name
3 = Router; 6 = Domain Name Server
44 = NetBIOS over TCP/IP Name Server
/*reply*/
Message type: Boot Reply (2)
Hardware type: Ethernet
Hardware address length: 6
Hops: 0
Transaction ID: 0x6b3a11b7
Seconds elapsed: 0
Bootp flags: 0x0000 (Unicast)
Client IP address: 192.168.1.101 (192.168.1.101)
Your (client) IP address: 0.0.0.0 (0.0.0.0)
Next server IP address: 192.168.1.1 (192.168.1.1)
Relay agent IP address: 0.0.0.0 (0.0.0.0)
Client MAC address: Wistron_23:68:8a (00:16:d3:23:68:8a)
Server host name not given
Boot file name not given
Magic cookie: (OK)
Option: (t=53,l=1) DHCP Message Type = DHCP ACK
Option: (t=54,l=4) Server Identifier = 192.168.1.1
Option: (t=1,l=4) Subnet Mask = 255.255.255.0
Option: (t=3,l=4) Router = 192.168.1.1
Option: (6) Domain Name Server
Length: 12; Value: 445747E2445749F244574092;
IP Address: 68.87.71.226;
IP Address: 68.87.73.242;
IP Address: 68.87.64.146
Option: (t=15,l=20) Domain Name = "hsd1.ma.comcast.net."
(2) 机构获取ip子网部分
Q: 如何获得一个网络的子网部分?
A: 从ISP获得地址块中分配一个小地址块
假如某个学校,有八个校区,要获取ip子网
-
首先从ISP获取大的网络
ISP's block 11001000 00010111 00010000 00000000 200.23.16.0/20
-
然后再划分,由于有8个校区,也就是要划分成8个部分,用原有的20位后面的3位来表示子网,从而进行划分
| 组织序号 | ip | ip地址(二进制) |
|---|---|---|
| Organization 0 | 200.23.16.0/23 | 11001000 00010111 00010000 00000000 |
| Organization 1 | 200.23.18.0/23 | 11001000 00010111 00010010 00000000 |
| Organization 2 | 200.23.20.0/23 | 11001000 00010111 00010100 00000000 |
| ...... | ||
| Organization 7 | 200.23.30.0/23 | 11001000 00010111 00011110 00000000 |
(3) ISP获取地址块
ICANN: Internet Corporation for Assigned Names and Numbers
国际通用的机构,专门管理Name(域名)和Number(ip)
一个ISP如何获得一个地址块?
向ICANN申请
- 分配地址
- 管理DNS
- 分配域名,解决冲突
4.3.6 IP层次编址/路由聚集
目的:就是聚集路由
具体的算法在下一章,控制平面决定
(1) 路由聚集
路由聚集:route aggregation
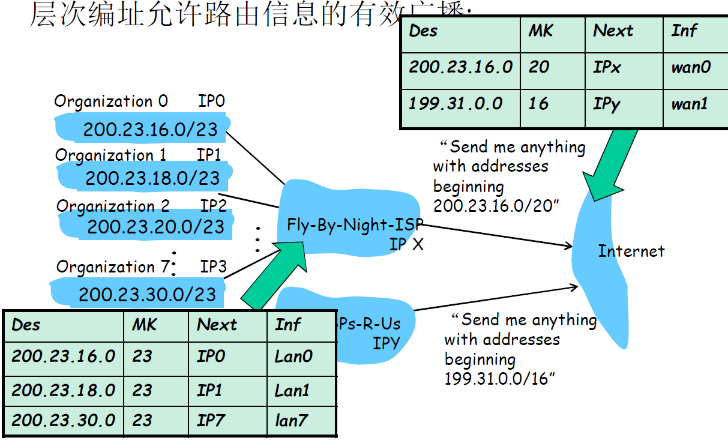
第一行的意思是,如果前缀是
200.23.16.0/23,那么下一跳是IP0,接口是LAN0
-
子网路由通告
-
Organization0向总机构的路由器发布通告,范式子网前缀是
200.23.16.0/23的分组,都发给我(Organization0)。 -
换句话说:ip0(也就是Organization0的IP),是前缀为
200.23.16.0/23的下一跳(hop)分组的每一跳都要具体到一个IP地址,而不是网络
-
其他Organization同理
-
-
路由聚集通告
-
总机构的路由器将8个分块的信息聚集之后,得到相同前缀
200.23.16.0/20(前缀只看20即可) -
机构向ISP的路由器发布通告,前缀为
200.23.16.0/20的分组,发给这个机构 -
IPx是机构的总路由器的ip
-
-
ISP路由器将对应的分组发给机构的路由器,再分给子网的路由器
(2) 最长精确匹配
(more specific routes)
情景如下:
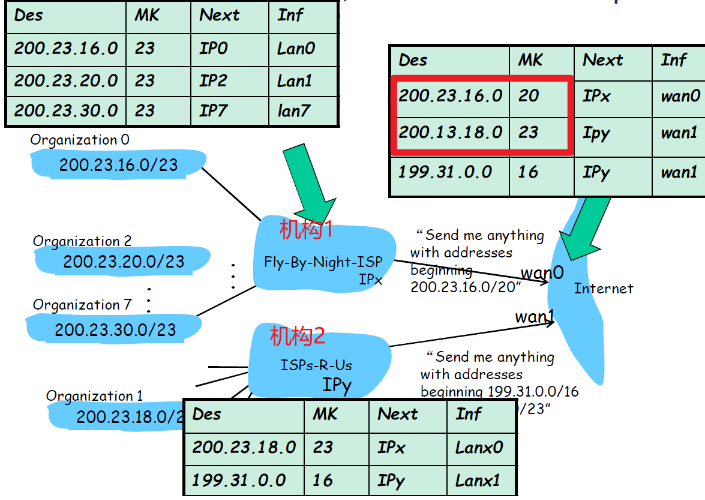
- 机构2将organization1收购了
- 此时机构1下面有7个子网,子网信息收到之后,也能进行聚集(尽管没有收到全部的,但是有相同的前缀,减少通报的数量和路由信息匹配的数量),然后通报
- 此时机构2也有一个相同的前缀
- 然后Internet收到一个分组的目标ip同时满足两个前缀,此时会选择最长的匹配路径
匹配冲突时候,采取的是最长前缀匹配
4.3.7 NAT: 网络地址转换
NAT:Network Address Translation(网络地址转换)
(1) 原理
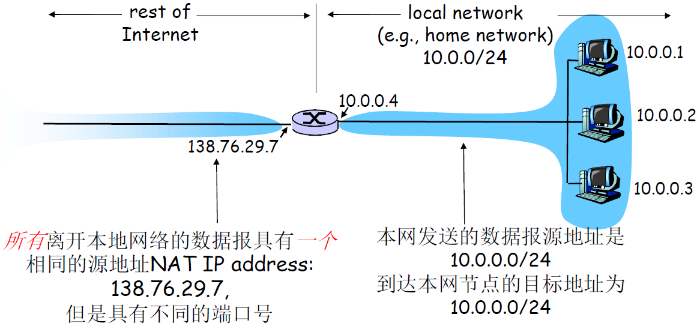
- 实际上就是用 外网端口号 代替 内网IP:端口号;端口有16位的字段,可以表示6万多个同时连接,表示一个局域网是足够的
- 并且要记录这个映射关系,使得接受信息的时候能识别发给哪个内网IP
特点本地网络只有一个有效IP地址(其余全是内网地址,内网地址是路由不会认可的)
NAT 路由器必须:
- 外出数据包:替换源地址:端口号为 NAT的IP地址:新的端口号,目标IP和端口不变;远端的C/S将会用NAP IP地址,新端口号作为目标地址
- 记住每个转换替换对(映射)(在NAT转换表中)源IP:端口 vs NAP IP:新端口
- 进入数据包:替换目标IP地址和端口号,采用存储在NAT表中的mapping表项,用(源IP,端口)
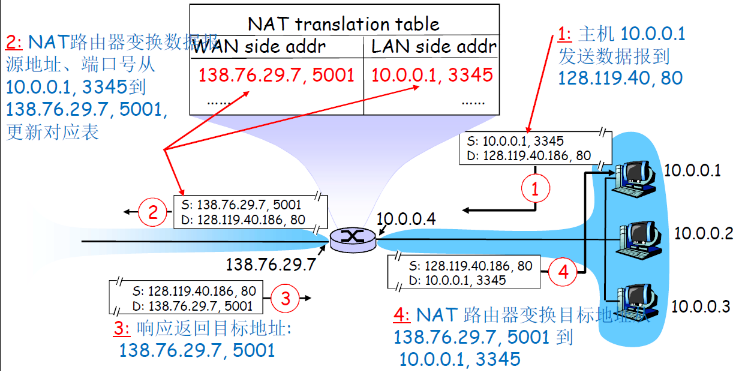
(2) 流程
(3) 优点
优点:
- 省钱:不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备
- 可以在局域网改变设备的地址情况下而无须通知 外界
- 可以改变ISP(地址变化)而不需要改变内部的 设备地址
- 安全:局域网内部的设备没有明确的地址,对外是不可 见的
(4) NAT的争议和问题
NAT能够篡改接受的分组的端口信息
- 路由器只应该对第3层做信息处理,而这里对端口号(4层)作了处理
- 违反了end-to-end 原则
- 端到端原则:复杂性放到网络边缘
- 无需借助中转和变换,就可以直接传送到目标主机
- NAT可能要被一些应用设计者考虑, eg, P2P applications
- 外网的机器无法主动连接到内网的机器上
- 端到端原则:复杂性放到网络边缘
- 问题,NAT穿越: 如果客户端需要连接在NAT后面的服务器,如何操作
地址短缺问题可以被IPv6 解决(因为NAT一开始解决的就是地址短缺的问题)
(5) NAT 穿越问题
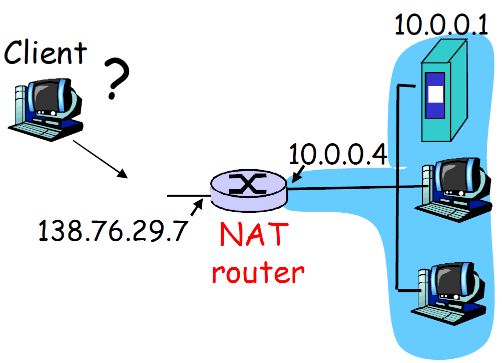
-
客户端需要连接地址为 10.0.0.1的服务器
- 服务器地址10.0.0.1 LAN本地地址 (客户端不能够使用其作为目标地址)
- 整网只有一个外部可见地址: 138.76.29.7
① 静态配置NAT
- 方案1: 静态配置NAT:转发 进来的对服务器特定端口连接 请求
- (123.76.29.7, port 2500) 总是转发到10.0.0.1 port 25000
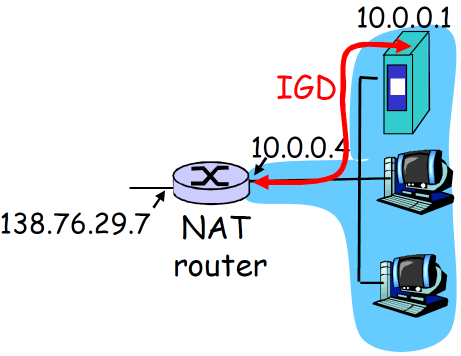
② IGD/UPnP
- 方案2: Universal Plug and Play (UPnP) Internet Gateway Device (IGD) 协议. 允许 NATted主机可以: 动态分配端口
- 获知网络的公共 IP地址 (138.76.29.7)
- 列举存在的端口映射
- 增/删端口映射 (在租用时间内 )
这个协议允许内网的设备查询NAT的表象,增加/删除响应的表象,比如10.0.0.1查询NAT router的表象的80号端口,如果没有用,那么就添加映射,将NAT router的80号端口映射到10.0.0.1的某个端口
自动化静态NAT端口映射配 置
③ 中继
中继(used in Skype)
方案3:中继(used in Skype)
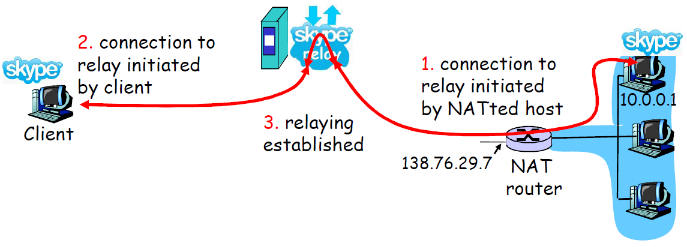
- NAT后面的服务器建立和中继的连接
- 外部的客户端链接到中继
- 中继在2个连接之间桥接
4.3.8 IPv6协议
- 一开始设计的时候根本没有想到IP协议会这么流行并且使用的这么快
- IPv5是一个实验室的协议,被废弃了
(1) IPv6目的
- 初始动机: 32-bit地址空间将会被很快用完,为了增加地址数量
- 另外的动机:
- 改变头部格式,帮助加速处理和转发
- TTL-1(之前的ICPM协议每次都要TTL-2)
- 头部checksum (之前都会校验头部)
- 分片 (当MTU小于分组的时候,要分片)
- 头部格式改变帮助QoS
- 改变头部格式,帮助加速处理和转发
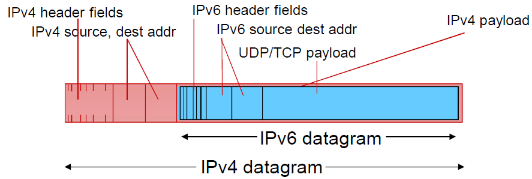
(2) IPv6数据报
IPv6 数据报格式:
- 固定的40字节头部
- IP地址由原先的32位改成了128位(16个字节)
- 数据报传输过程中,不允许分片
如果分组太大超过了MTU,那么路由器会扔到,并向源主机发送ICMPv6报告,告诉分组太大了,源主机将分组减小;
这样减轻了路由器的负担
IPv6 头部 (Cont)
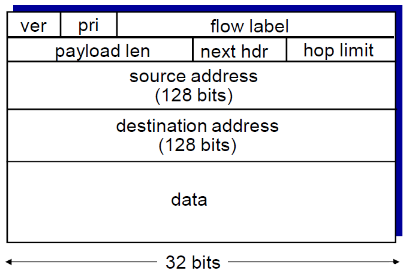
- Priority: 标示流中数据报的优先级(优先级是与非技术方面结合的,比如收费等)
- Flow Label: 标示多个数据报在一个“flow” ( “flow”的概念没有被严格的定义)
- Next header: 标示上层协议(就是网络层以上传给哪个协议,TCP/UDP)
和IPv4的其它变化
- Checksum: 被移除掉,降低在每一段中的处理 速度
- Options: 允许,但是在头部之外, 被 “Next Header” 字段标示 (Next Header的格式是TLV type-length-value)
- ICMPv6: ICMP的新版本
- 附加了报文类型, e.g. “Packet Too Big”
- 多播组管理功能
(3) 从IPv4到IPv6的过渡:隧道
- 不是所有的路由器都能够同时升级的
- 没有一个标记日 “flag days”宕机来全部更新
- 在IPv4和IPv6路由器混合时,网络如何运转?

- IPv4内部可以自由通信,IPv6内部也可以自由通信,但是两个IPv6子网之间的通信就需要借助IPv4
- IPv6的边缘路由器支持双栈协议,将IPv6的分组封装到IPv4的数据段中,然后借由IPv4的网络传给目标IPv6子网
- 这个技术就是隧道
- 隧道: 在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
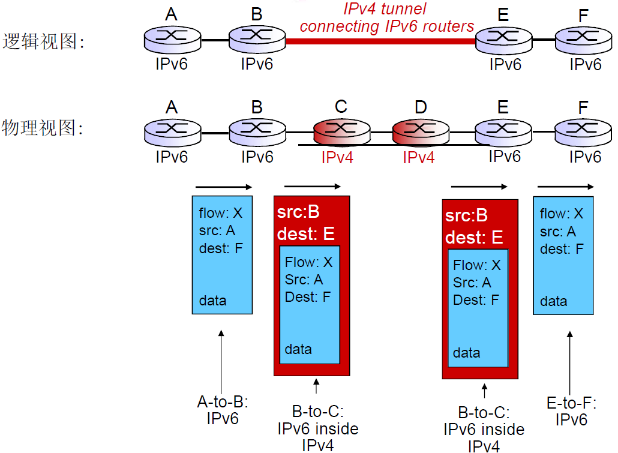
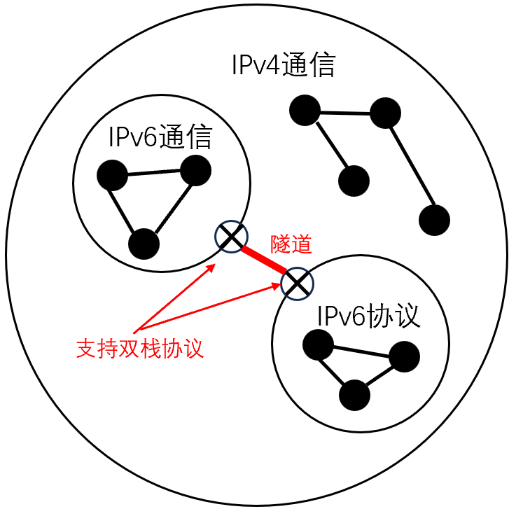
- 还是这个图,当IPv6的范围越来越到,IPv4的范围越来越小的时候,就成为了IPv4成为小圆,IPv6成为了大范围,v4借助v6通信
- 可以将IPv6比作小岛,IPv4比作海洋,整个过程就是海洋下降的过程
(4) IPv6的应用
- Google: 8% 的客户通过IPv6访问谷歌服务(当然现在还在增加)
- NIST: 全美国1/3的政府域支持IPv6
- 估计还需要很长时间进行部署 (20年)
4.4 通用转发和SDN
网络层功能:
- 转发: 对于从某个端口 到来的分组转发到合适的 输出端口
- 路由: 决定分组从源端 到目标端的路径
4.4.1 传统网络层
传统的方式,就是网络设备来实现控制平面
(1) 传统路由器的功能
每个路由器(Per Route)的控制平面 (传统)
- 每个路由器上都有实现路由算法元件(它们之间需要相互交 互)- 形成传统IP实现方式的控制平面
- 控制平面式分布式的,由各个路由器的各自完成,难于管理
网络维护员的薪资很高,因为要管理的网络设备很多,也很难
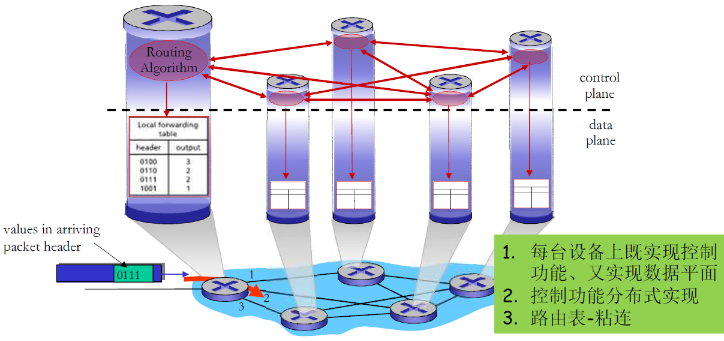
数量众多、功能各异的中间盒
- 路由器的网络层功能:
- IP转发:对于到来的分组按照路由表决定如何转发,数 据平面
- 路由:决定路径,计算路由表;处在控制平面
(2) 传统的网络设备
- 还有其他种类繁多网络设备(中间盒):
- 交换机;防火墙;NAT;IDS;负载均衡设备
- 未来:不断增加的需求和相应的网络设备
- 需要不同的设备去实现不同的网络功能
- 每台设备集成了控制平面和数据平面的功能
- 控制平面分布式地实现了各种控制平面功能
- 升级和部署网络设备非常困难
(3) 网络设备控制平面的实现方式特点
互联网网络设备:传统方式都是通过分布式,每台 备的方法来实现数据平面和控制平面功能
-
垂直集成:每台路由器或其他网络设备,包括:
- 硬件、在私有的操作系统;
- 互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现
- 从上到下都由一个厂商提供(代价大、被设备上“绑架”“)
-
每个设备都实现了数据平面和控制平面的事情
- 控制平面的功能是分布式实现的
-
设备基本上只能(分布式升级困难)按照固定方式工作, 控制逻辑固化。
-
不同的网络功能需要不同的 “middleboxes”:防火墙、负载均衡设备、NAT boxes, .
-
(数据+控制平面)集成>(控制逻辑)分布->固化
- 代价大;升级困难;管理困难等
(4) 问题
- 垂直集成造成价格昂贵
- 不便于创新的生态(垄断)
- 分布式、固化设备功能造成网络设备种类繁多
- 无法改变路由等工作逻辑,无法实现流量工程等高级 特性
- 配置错误影响全网运行;升级和维护会涉及到全网设 备:管理困难
- 要增加新的网络功能,需要设计、实现以及部署新的 特定设备,设备种类繁多
(5) 流量工程案例问题
这是传统网络层难以解决的问题

- Q: 网管如果需要u到z的流量走uvwz,x到z的流量走xwyz,怎么办?
- A: 需要定义链路的代价,流量路由算法以此运算( IP路由面向目标,无法操作) (或者需要新的路由算法)!
- 链路权重只是控制旋钮
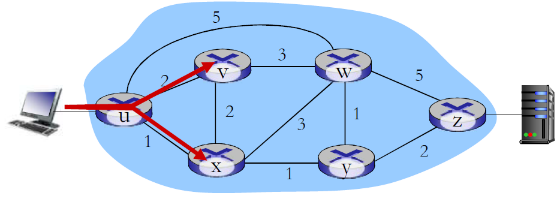
- Q: 如果网管需要将u到z的流量分成2路:uvwz 和uxyz ( 负载均衡),怎么办?(IP路由面向目标)
- A: 无法完成(在原有体系下只有使用新的路由选择算法 ,而在全网部署新的路由算法是个大的事情)
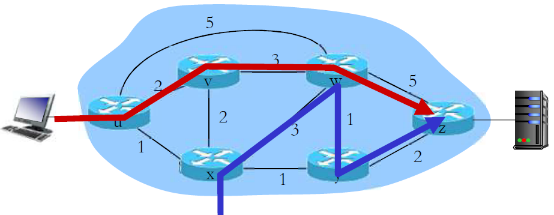
- Q:如果需要w对蓝色的和红色的流量采用不同的路由,怎么办?
- A: 无法操作 (基于目标的转发,采用LS, DV 路由)
- ~2005: 开始重新思考网络控制平面的处理方式
- 集中:远程的控制器集中实现控制逻辑
- 远程:数据平面和控制平面的分离
4.4.2 SDN概述
SDN:逻辑上集中的控制平面,仅仅是控制平面
(1) SDN的主要思路
一个不同的(通常是远程)控制器和CA交互,控制器决定分组 转发的逻辑(可编程),CA所在设备执行逻辑。
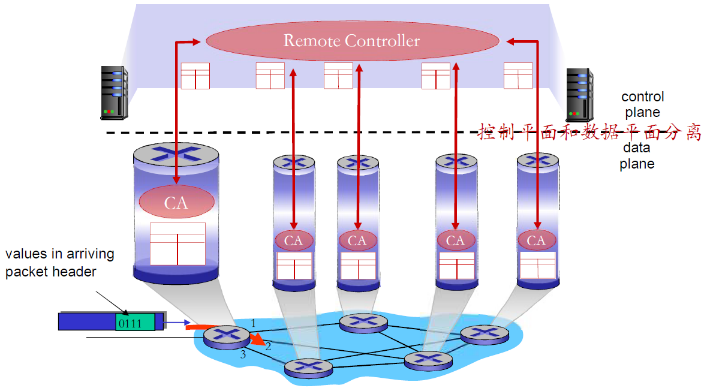
- 网络设备数据平面和控制平面分离
- 数据平面-分组交换机
- 将路由器、交换机和目前大多数网络设备的功能进一步抽 象成:按照流表(由控制平面设置的控制逻辑)进行PDU (帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻 塞)
- 统一化设备功能:SDN交换机(分组交换机),执行控制 逻辑
- 控制平面-控制器+网络应用
- 分离、集中
- 计算和下发控制逻辑:流表
(2) SDN控制平面和数据平面分离的优势
-
水平集成控制平面的开放实现(而非私有实 ),创造出好的产业生态,促进发展
- 分组交换机、控制器和各种控制逻辑网络应用app可由不同厂商生产,专业化,引入竞争形成良好生态
-
集中式实现控制逻辑,网络管理容易:
- 集中式控制器了解网络状况,编程简单,传统方式困难
- 避免路由器的误配置
-
基于流表的匹配+行动的工作方式允许“可编程的”分组交换机
-
实现流量工程等高级特性
-
在此框架下实现各种新型(未来)的网络设备
-
(3) 类比: 主框架到PC的演变
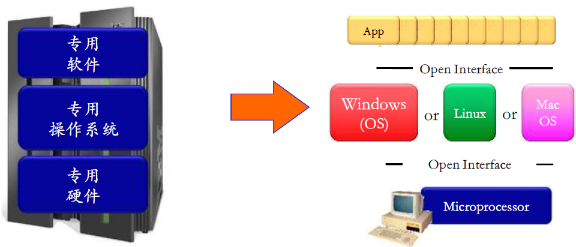
| 传统特点 | SDN特点 |
|---|---|
| 垂直继承 | 水平集成 |
| 封闭,私有 | 开放接口 |
| 创新缓慢 | 快速创新 |
| 产业规模小 | 产业巨大 |
- 在传统模式下,硬件,OS,软件都是一家厂商统一实现垄断,不利于行业的发展和创新
- 但是SDN的横向集合可以解决这种问题,不同厂家可以生产不同层次的东西
- 类似于Google推出安卓,就是防止苹果iOS的垄断,如果基于iOS开发软件,那么如果不合苹果的要求,就会被掐死
- 这也是国内为什么生成自主OS的原因之一吧
(4) SDN特点
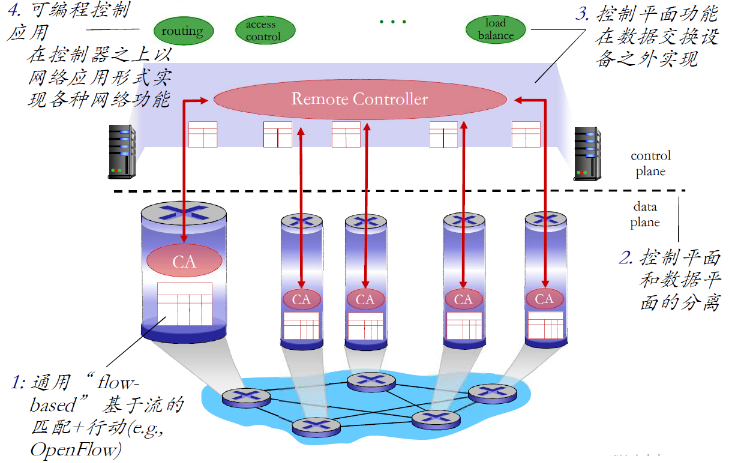
- 通用“ flowbased”基于流的匹配+行动(e.g.,OpenFlow协议)(底层基于某个协议,可以根据流表的结果行动)
- 控制平面和数据平面的分离
- 控制平面功能在数据交换设备之外实现
- 可编程控制应用在控制器之上以网络应用形式实现各种网络功能
4.4.3 SDN架构
本节主要讲解SDN的组成
(1) 数据平面交换机
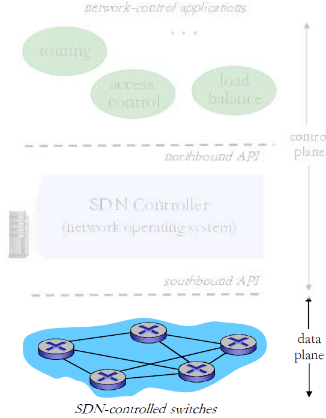
数据平面交换机
- 快速,简单,商业化交换设备 采用硬件实现通用转发功能
- 流表被控制器计算和安装
- 基于南向API(例如OpenFlow ),SDN控制器访问基于流的交换机
- 定义了哪些可以被控制哪些不能
- 也定义了和控制器的协议 (e.g., OpenFlow)
(2) SDN控制器(网络OS)
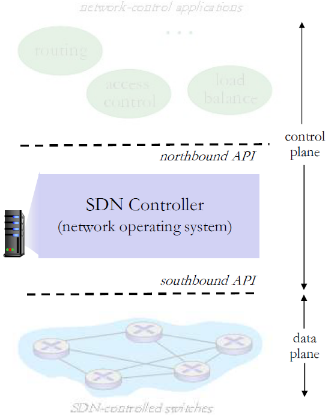
SDN 控制器(网络OS):
- 维护网络状态信息
- 通过上面的北向API和网络 控制应用交互
- 通过下面的南向API和网络 交换机交互
- 逻辑上集中,但是在实现上通常由于性能、可扩展性、 容错性以及鲁棒性采用分布式方法
(3) 控制应用
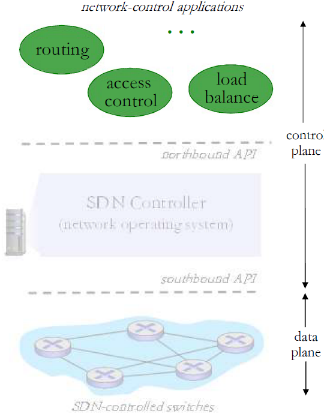
网络控制应用:
- 控制的大脑: 采用下层提供 的服务(SDN控制器提供的 API),实现网络功能
- 路由器交换机
- 接入控制 防火墙
- 负载均衡
- 其他功能
- 非绑定:可以被第三方提供 ,与控制器厂商以通常上不 同,与分组交换机厂商也可 以不同
(4) 数据平面的流标
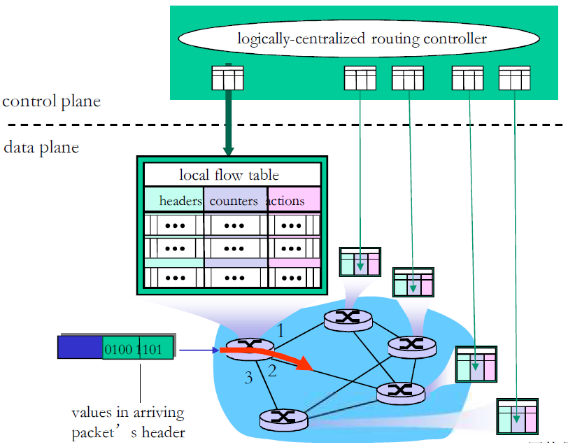
对于SDN来说,数据平面的就是流表
每个路由器包含一个流表(被逻辑上集中的控制器计算和分发)
4.4.4 OpenFlow协议
通用flow-bascd基于流的匹配+行动(c.g,DpcnFlow)
OpenFlow,一种网络通信协议,属于数据链路层,能够控制网上交换器或路由器的转发平面(forwarding plane),借此改变网络数据包所走的网络路径。
- OpenFlow能够启动远程的控制器,经由网络交换器,决定网络数据包要由何种路径通过网络交换机。这个协议的发明者,将它当成软件定义网络(Software-defined networking)的启动器。
- OpenFlow允许从远程控制网络交换器的数据包转送表,透过新增、修改与移除数据包控制规则与行动,来改变数据包转送的路径。比起用访问控制表(ACLs) 和路由协议,允许更复杂的流量管理。同时,OpenFlow允许不同供应商用一个简单,开源的协议去远程管理交换机(通常提供专有的接口和描述语言)。
- OpenFlow协议用来描述控制器和交换机之间交互所用信息的标准,以及控制器和交换机的接口标准。协议的核心部分是用于OpenFlow协议信息结构的集合。
- OpenFlow协议支持三种信息类型:Controller-to-Switch,Asynchronous和Symmetric,每一个类型都有多个子类型。Controller-to-Switch信息由控制器发起并且直接用于检测交换机的状态。Asynchronous信息由交换机发起并通常用于更新控制器的网络事件和改变交换机的状态。Symmetric信息可以在没有请求的情况下由控制器或交换机发起。
(1) OpenFlow:数据平面抽象
OpenFlow就是数据平面的抽象
- 流: 由分组(帧)头部字段所定义
- 通用转发: 简单的分组处理规则
- 模式: 将分组头部字段和流表进行匹配
- 行动:对于匹配上的分组,可以是丢弃、转发、修改、 将匹配的分组发送给控制器
- 优先权Priority: 几个模式匹配了,优先采用哪个,消除歧义
- 计数器Counters: #bytes 以及 #packets
路由器中的流表定义了路由器的匹配+行动规则(流表由控制器计算并下发)
如下

(2) 流表的表项结构
① 案例
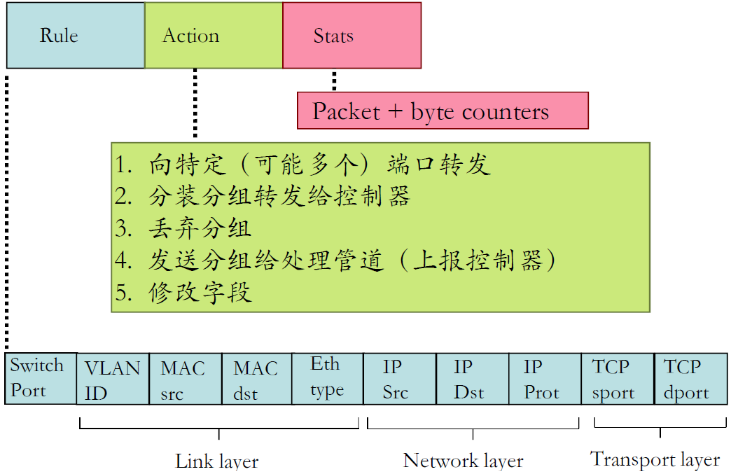
- Rule规则就是匹配规则
② 案例

(3) OpenFlow 抽象
就是将原来设备的行为进行抽象为程序可以做的事情
match+action: 统一化各种网络设备提供的功能
| 设备 | match | action |
|---|---|---|
| 路由器 | 最长前缀匹配 | 通过一条链路转发 |
| 交换机 | 目标MAC地址 | 转发或泛洪 |
| 防火墙 | IP地址和TCP/UDP端口号 | 允许或者进制 |
| NAT | IP地址和端口号 | 重写地址和端口号 |
目前几乎所有的网络设备都可以在这个匹配+行动模式框架进行描述,具体化为各种网络设备包括未来的网络设备
(4) 案例
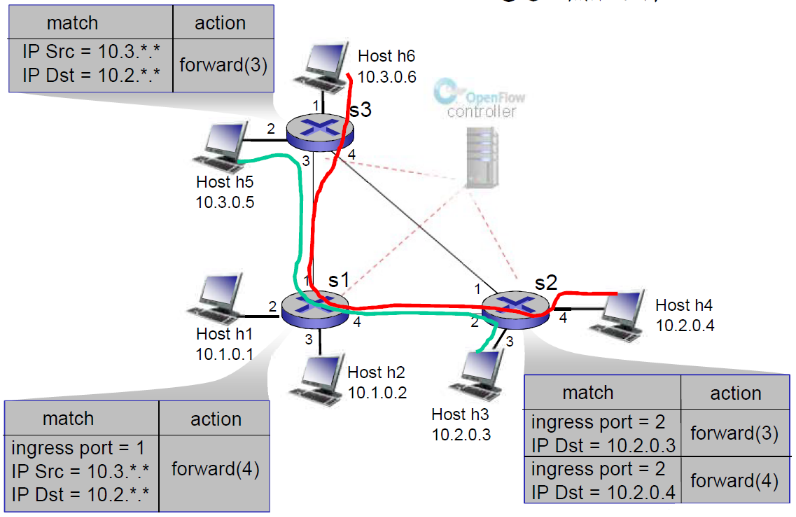
例子: 来自H5和H6的数据报应该被 发向H3 或者H4通过s1然后经由s2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号