计算机网络-第三章-传输层
第3章 传输层
目标:
-
理解传输层的工作原理
- 多路复用/解复用
- 可靠数据传输(网络中的非常核心的内容,将网络层提供的不可靠的服务转变为可靠的服务)
- 流量控制(点到点的问题)
- 拥塞控制 (路径的问题)
-
学习Internet的传输层协议
-
UDP:无连接传输
-
TCP:面向连接的可靠传 输
-
TCP的拥塞控制
-
3.1 概述和传输层服务
3.1.1 基本概念
传输服务和协议
- 为运行在不同主机上的应用进程提供逻辑通信
- 逻辑通信是指进程直接看做进程直接可以直接通信;
- 但是实际上进程要依次传递给下层,然后下层再依次网上传递给另外的进程
- 传输层是应用进程之间的通信,而不是主机与主机之间的
- 传输协议运行在端系统
- 发送方:将应用层的报文分成报文段,然后传递给网络层
- 接收方:将报文段重组成报文,然后传递给应用层
- 有多个传输层协议可供应用选择
- Internet: TCP(字节流的服务,不保证界限) 和 UDP
- Internet以外还有其他的协议
3.1.2 传输层 & 网络层
-
网络层服务:主机之间的逻辑通信
-
传输层服务:进程间的逻辑通信
- 依赖于网络层的服务
- 延时、带宽
- 并对网络层的服务进行增强
- 数据丢失、顺序混乱、 加密
- 依赖于网络层的服务
传输层在网络层的基础上,加强了网络层的服务
- 主机之间 → 进程之间
- 丢失、乱序 → 可靠
有些服务是可以加强的:不可靠 -> 可靠;安全
但有些服务是不可以被加强的:带宽,延迟
3.1.3 Internet传输层协议
可靠的、保序的传输: TCP(字节流的服务)
- 多路复用、解复用
- 拥塞控制
- 流量控制
- 建立连接
不可靠、不保序的传输:UDP(数据包的服务)
-
多路复用、解复用
-
没有为尽力而为的IP服务添加更多的其它额外服务
可以理解为UDP仅仅是将主机到主机的服务转变为进程到进程的服务,除此之外没有其他作用
都不提供的服务: 延时保证 带宽保证
3.2 多路复用与解复用
3.2.1 概念
- 多路(复用/解复用):一个TCP/UDP实体上有很多应用进程借助其发送
- 复用:就是指多个进程可以使用一个实体来发送/接受
- 根据端口来进行复用的,但是TCP和UDP使用的端口不一样,TCP是四元组,UDP是二元组
在发送方主机多路复用
- 从多个套接字接收来自多个进程的报文,根据套接字对应的IP地址和端口号等信息对报文段用头部加以封装 (该头部信息用于以后的解复用)
在接收方主机多路解复用
- 根据报文段的头部信息中的IP地址和端口号将接收到的报文段发给正确的套接字(和对应的应用进程)
3.2.3 复用工作原理
当应用层交给传输层数据的时候,还会提供信息
- 对于TCP,提交给传输层的有
- 数据本身
- socket(表示src IP, src port, des IP, des port)
- 对于UDP,提交给传输层的有
- 数据本身
- socket (表示src IP,src port)
- cad(表示 desc IP,des port)
区别就在于UDP的socket是不表示目标ip和port的,需要收动传入
当传输层收到信息之后,会对数据进行封装,即在数据前面加上需要的信息,再交给网络层,网络层也能解析头部信息从而进行封装
3.2.3 解复用工作原理
- 解复用作用:TCP或者UDP实体采 用哪些信息,将报文段的数据部分 交给正确的socket,从而交给正确 的进程
- 主机收到IP数据报
- 每个数据报有源IP地址和目标地 址
- 每个数据报承载一个传输层报 文段
- 每个报文段有一个源端口号和 目标端口号 (特定应用有著名的端口号)
- 主机联合使用IP地址和端口号将报文段发送给合适的套接字
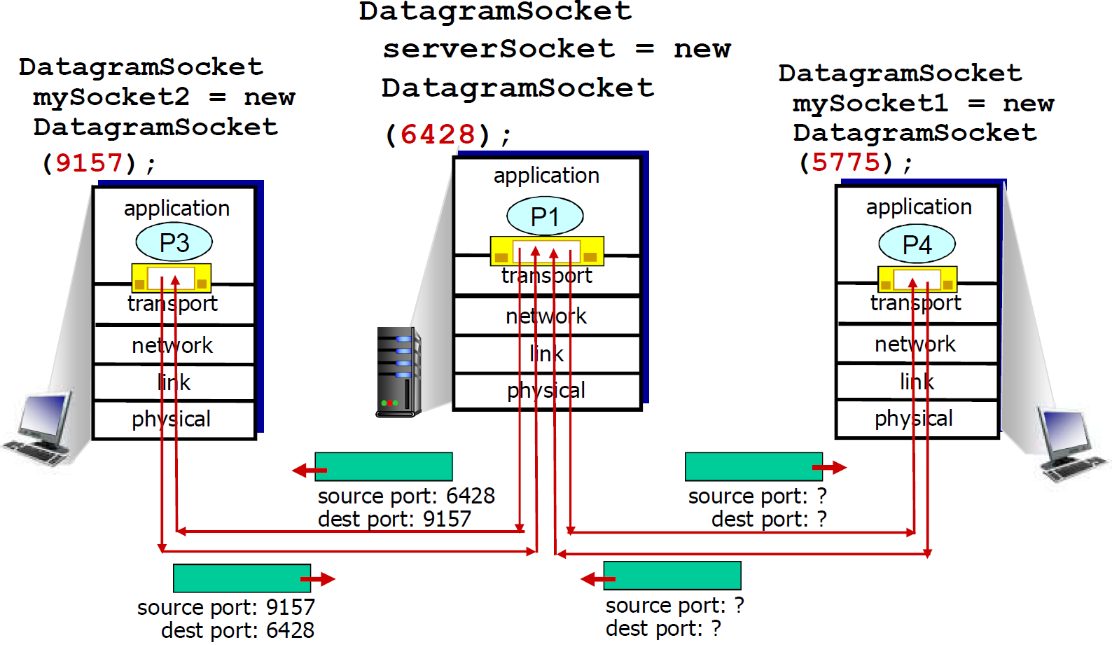
(1) UDP多路解复用
- 在接收端,UDP套接字用二元组标识(目标IP地址、目标端口号)
- 当主机接收到UDP段时:
- 检查UDP段中的目标端 口号
- 将UDP段交给具备那个端口号的套接字
- 目标IP地址,目标端口号一样发送给同一个进程
回顾:创建拥有本地端口号的套接字
DatagramSocket mySocket1 = new DatagramSocket(12534);
回顾:当创建UDP段采用端口号,可以指定:
- 目标IP地址
- 目标端口号
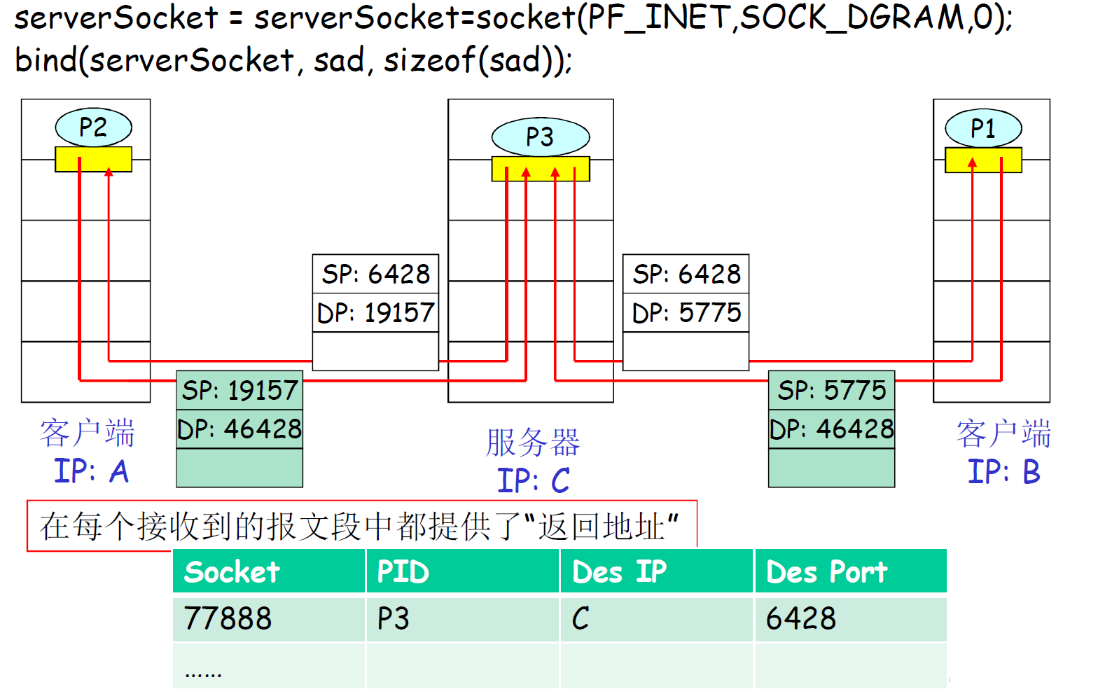
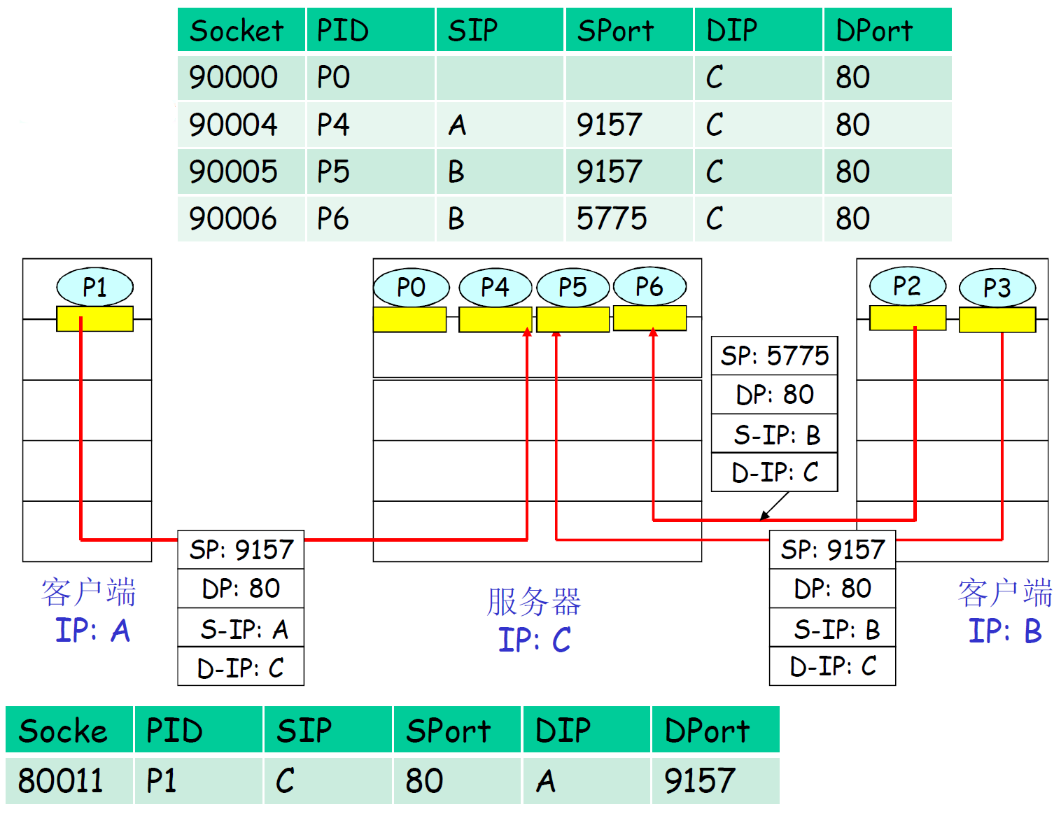
(2) TCP多路复用
TCP套接字:四元组本 地标识:
- 源IP地址
- 源端口号
- 目的IP地址
- 目的端口号
解复用:接收主机用 这四个值来将数据报 定位到合适的套接字
-
服务器能够在一个TCP端口上同时支持多个TCP套接字:
- 每个套接字由其四元组标识(有不同的源IP和源PORT)
-
Web服务器对每个连接客户端有不同的套接字
- 非持久对每个请求有不同的套接字
下面是例子
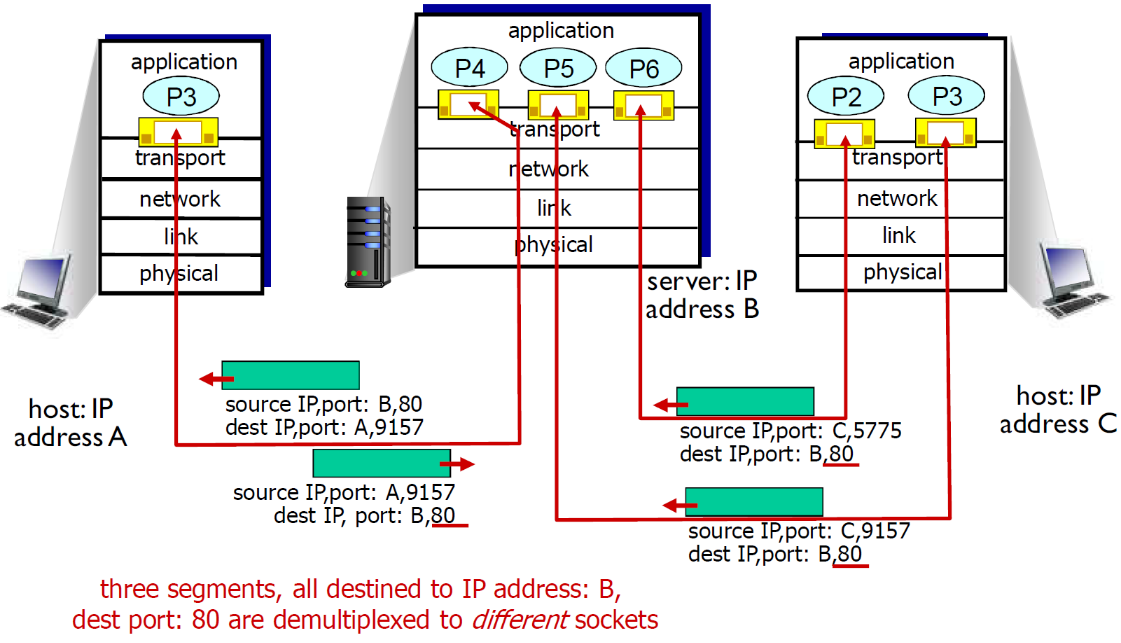
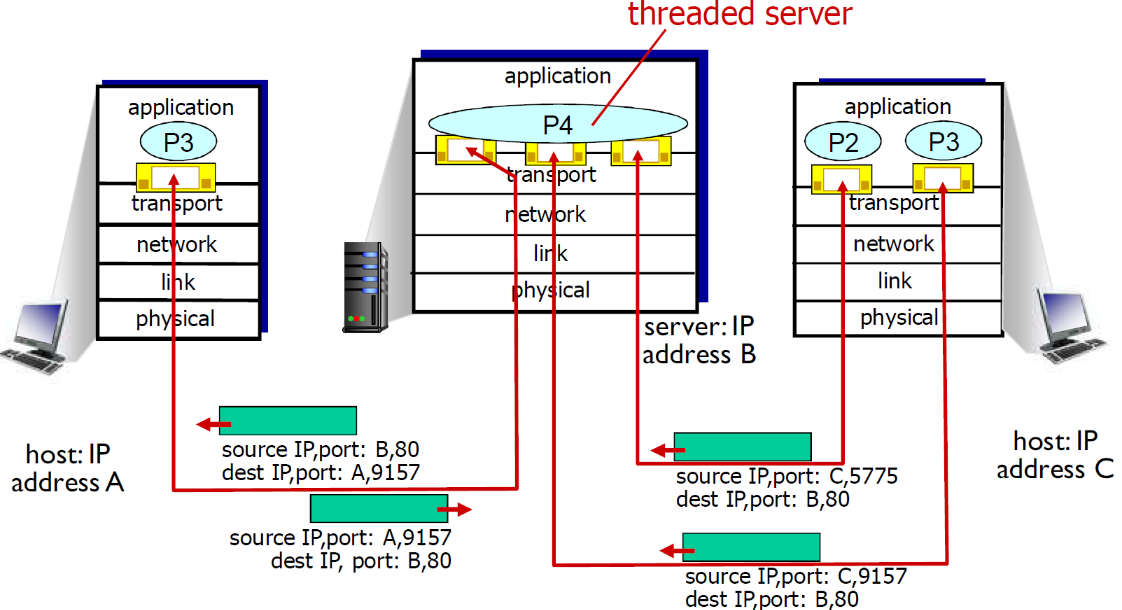
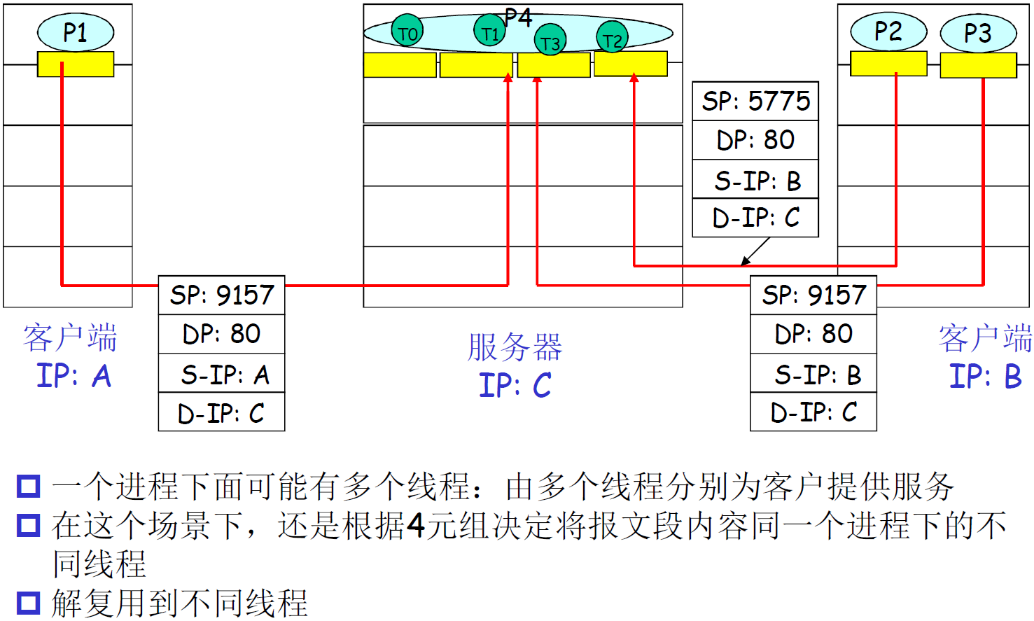
多线程Web Server
3.3 无连接传输:UDP
UDP仅仅在网络层的基础上实现了多路复用/解复用,因此讲完多路复用/解复用就讲UDP
3.3.1 UDP介绍
UDP: User Datagram Protocol 用户数据包协议
- 为什么叫数据报:因为是无连接的,每个UDP协议数据单元都是独立发送的
- IP也是独立的,也叫数据报
- 因此数据报可能指UDP,也可能指IP
在IP(主机到主机)所提供的基础上增加了一个多路复用/解复用(进程到进程)的服务
- “尽力而为”的服务,报文 段可能
- 丢失
- 送到应用进程的报文段乱序(延迟不一样)
- 无连接:
- UDP发送端和接收端之间没有握手
- 每个UDP报文段都被独立地处理
- UDP 被用于:
- (实时)流媒体(丢失不敏感, 速率敏感、应用可控制 传输速率)
- 事务性的应用(一次性往返搞定):DNS、SNMP
- 如何在UDP上可行可靠传输:
- 在应用层增加可靠性
- 应用特定的差错恢复
- UDP和TCP各有优劣,为什么没有第三个协议折中?
- 因为TCP和UDP可以满足大多数的应用,增加第三个协议,协议之间的协调会更麻烦,这是架构问题
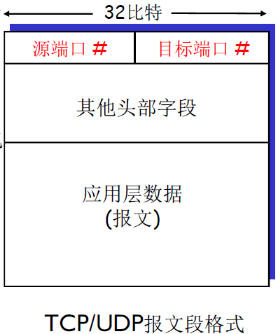
UDP报文格式
UDP的报文的格式如下
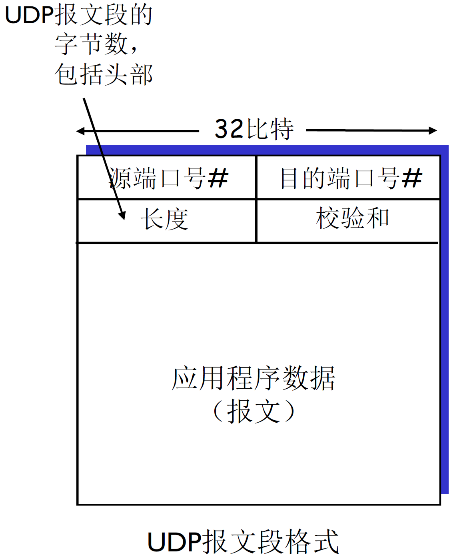
3.3.2 UDP优点
-
不建立连接 (会增加延时)
-
简单:在发送端和接收端没有连接状态
-
报文段的头部很小(开销小)
-
无拥塞控制和流量控制:UDP可以尽可能快的发送报文段
-
不考虑流量控制:应用->传输的速率 = 主机->网络的速率 (忽略头部时)
最后一个特性对实时多媒体是很有用的:
- 比如app是一个web camera实时摄像头
- 使用UDP就会一直发送
3.3.3 UDP校验和
目标: 检测在被传输报文段中的差错 (如比特反转)
发送方:
- 将报文段的内容视为16 比特的整数段
- 校验和:报文段的加法和(1的补运算)
- 发送方将校验和放在 UDP的校验和字段
接收方:
- 计算接收到的报文段的校验和
- 检查计算出的校验和与校验和字段的内容是否相等:
- 不相等:检测到差错
- 相等:没有检测到差错 ,但也许还是有差错 (残存错误,为检测出来)
- 不通过校验和肯定是错误的
- 但是通过并不说明就是一定正确的
Internet校验和的例子
注意:当数字相加时,在最高位的进位要回卷(加到最低位上),再加到结果上
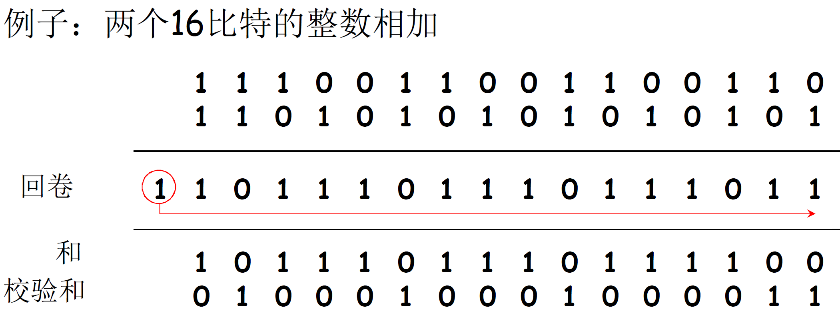
- 目标端:校验范围+校验和=1111111111111111 通过校验;否则没有通过校验
- 注:求和时,必须将进位回卷到结果上(进位回滚)
3.4 可靠数据传输RDT
RDT (Reliable Data Transfer)
3.4.1 概述
- rdt在某些应用层、传输层和某些网络的数据链路层都很重要
- 是网络Top 10问题之一
- 作用位置如下
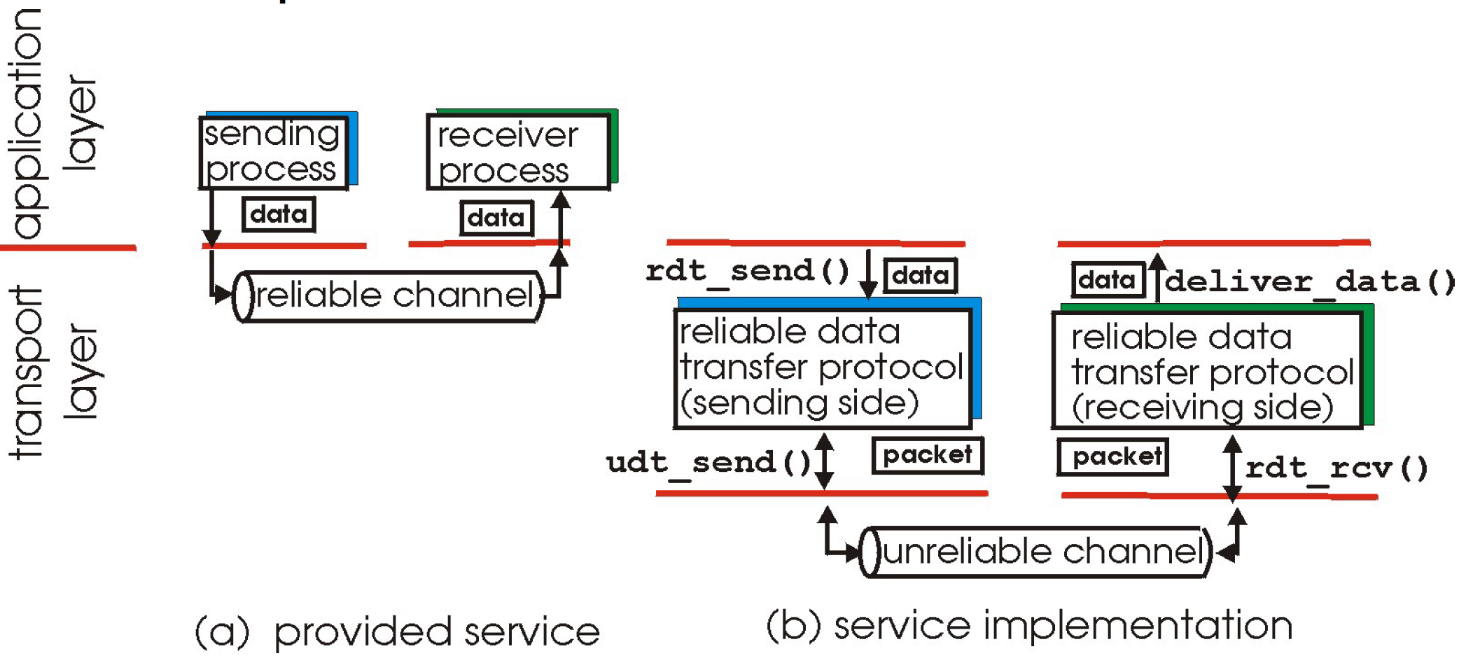
是在数据进入到channel之前,将数据加工成package
信道的不可靠特点决定了可靠数据传输协议( rdt )的复杂性
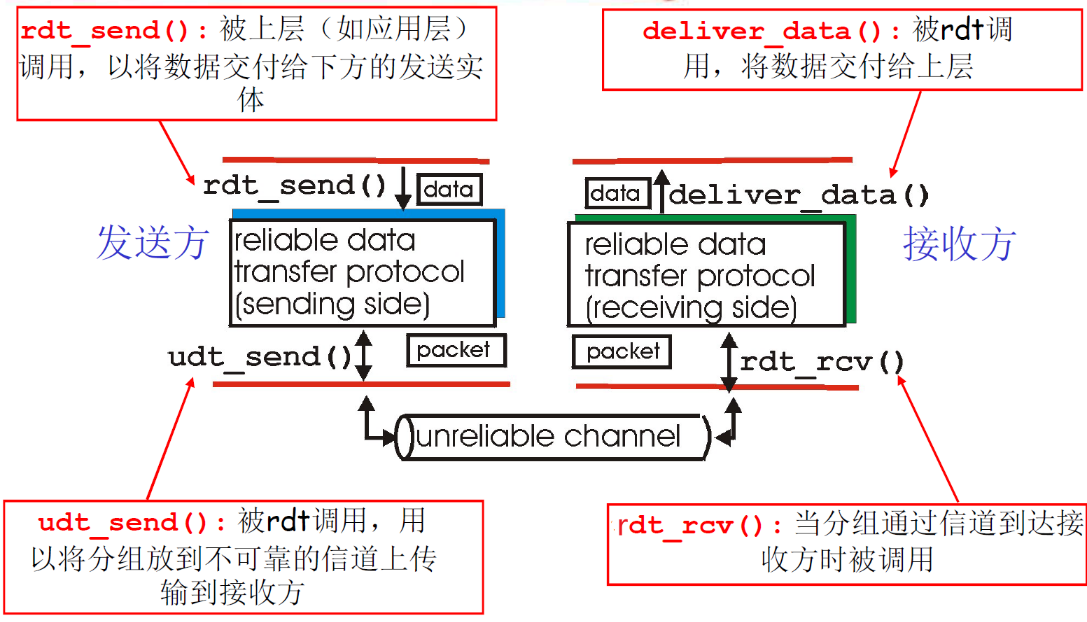
rdt_send(): 被上层(如应用层)调用,以将数据交付给下方的发送实体udt_send(): 被rdt调用,用以将分组放到不可靠的信道上传输到接收方rdt_rcv(): 当分组通过信道到达接收方时被调用deliver_data(): 被rdt调用,将数据交付给上层
下面学习RDT
- 渐增式地开发可靠数据传输协议( rdt )的发送方和接收方(逐渐增加对管道的限制,在此基础上优化rdt)
- 只考虑单向数据传输 ;但控制信息是双向流动的!
- 双向的数据传输问题实际上是2个单向数据传输问题的综合
- 使用有限状态机 (FSM) 来描述发送方和接收方

状态:在该状态时,下一个状态只由下一个事件唯一确定
3.4.2 stop-wait停止等待协议
停止等待协议:发送方发送一个分组, 然后等待接收方的应答然后发送下一个分组
(1) Rdt1.0:在可靠信道上的可靠数据传输
① 前提
下层的信道是完全可靠的
- 没有比特出错
- 没有分组丢失
② 流程(FSM描述)
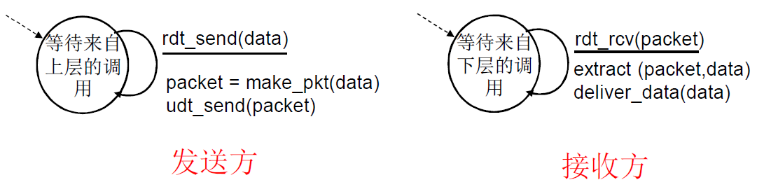
发送方和接收方的FSM
- 发送方将数据发送到下层信道
- 接收方从下层信道接收数据
发送方:接收→封装→打走 接收方:解封装→交付 什么都不用干
(2) Rdt2.0:具有比特差错的信道
① 前提
下层信道可能会出错:将分组中的比特翻转
② 解决方法
用校验和来检测比特差错
问题:怎样从差错中恢复:
- 确认(ACK):接收方显式地告诉发送方分组已被正确接收
- 否定确认( NAK): 接收方显式地告诉发送方分组发生了差错
发送方收到NAK后,发送方重传分组
rdt2.0中的新机制:采用差错控制编码进行差错检测
- 发送方差错控制编码、缓存(缓存是为了出错后再次发送)
- 接收方使用编码检错
- 接收方的反馈:控制报文(ACK,NAK):接收方->发送方
- 发送方收到反馈相应的动作
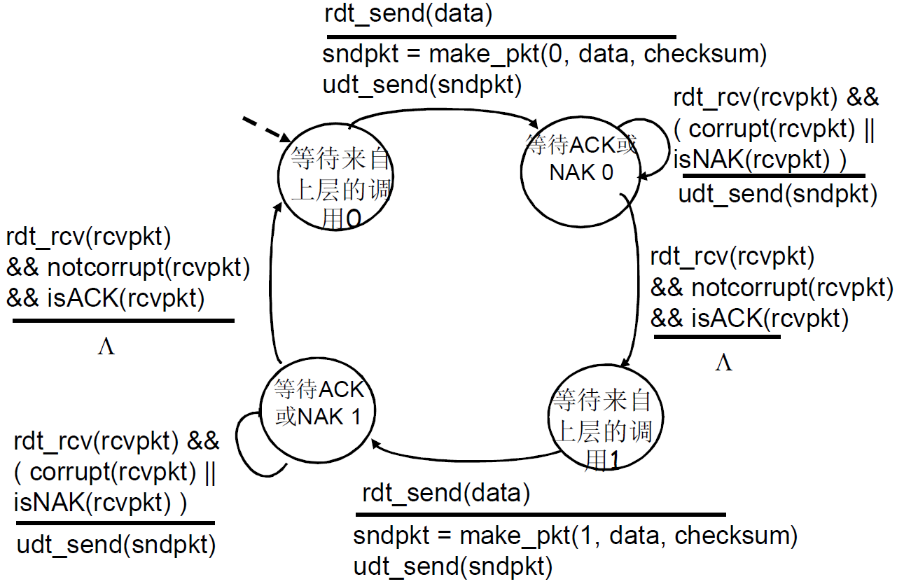
③ FSM描述
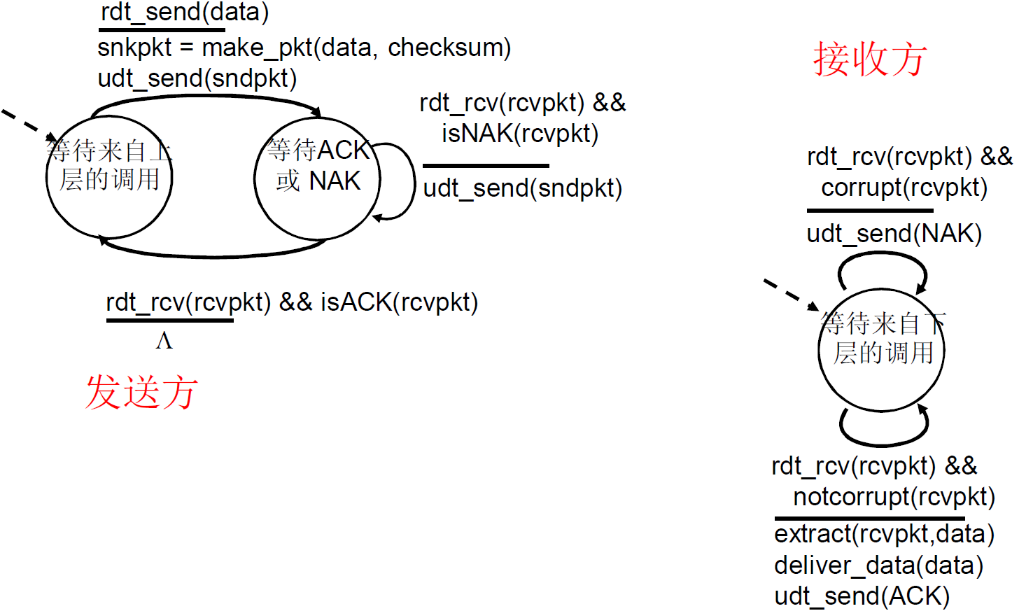
FSM解析如下
发送方
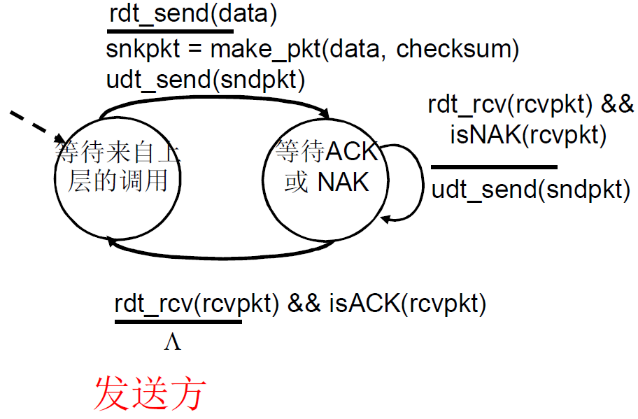
- 初始:等到来自上层的调用
- 上层调用 rdt_send(data),然后rdt进行打包
snkpkt = make_pkt(data, checksum),此时打包加入了校验和checksum,然后调用udt_send(sndpkt)发送 - 到达等待ACK或NAK状态
- 如果
rdt_rcv(rcvpkt) && isNAK(rcvpkt)即收到了响应并且响应是NAK,则重新发送udt_send(sndpkt),然后继续等待 - 如果
rdt_rcv(rcvpkt) && isACK(rcvpkt),则什么都不做,回到初始状态
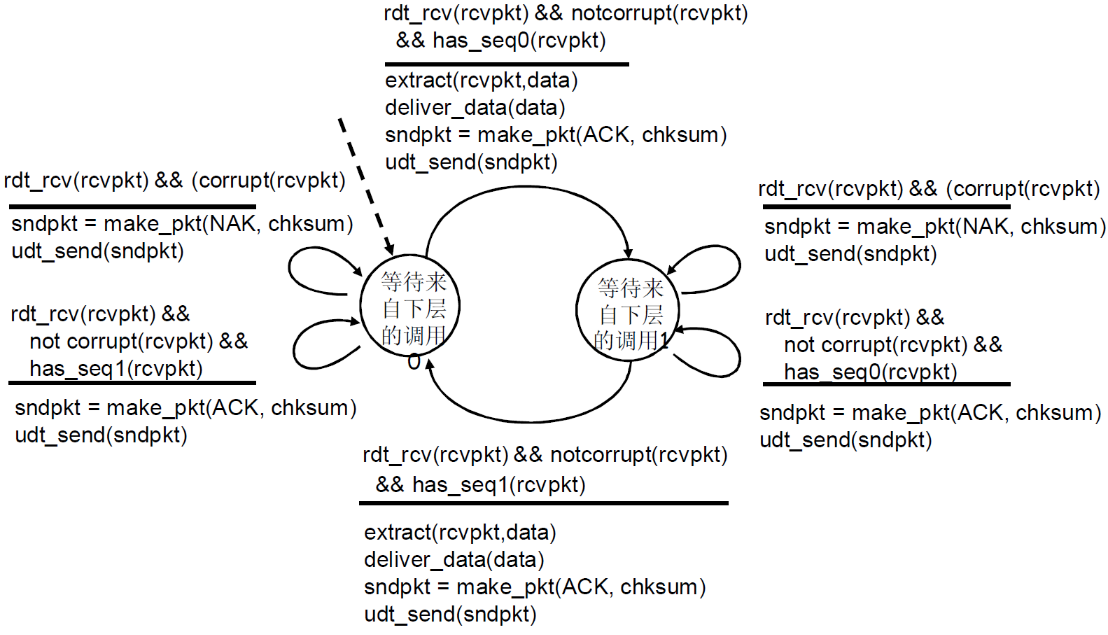
接收方
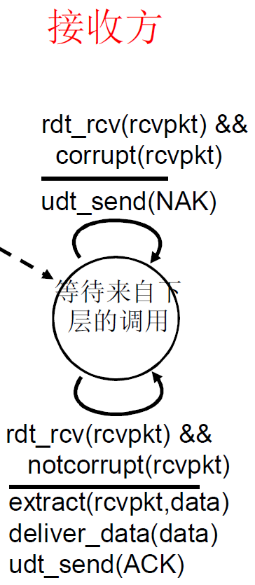
- 初始状态:等待来自下层的调用
- 如果
rdt_rcv(rcvpkt) && corrupt(rcvpkt),即收到了文件并且文件出错的话,udt_send(NAK)发出NAK - 如果
rdt_rcv(rcvpkt) && notcorrupt(rcvpkt),即收到了文件并且文件没有出错extract(rcvpkt,data)解析文件deliver_data(data)向上层发送数据udt_send(ACK)发送ACK
④ 流程

(3) Rdt2.1: ACK/NAK出错
发送方接受到ACK/NAK之后也是会进行验证的
如果ACK/NAK出错?
- 发送方不知道接收方发生了什么事情!
- 发送方如何做?
- 重传?可能重复
- 不重传?可能死锁(或出 错)
- 需要引入新的机制 :序号
① 思路
处理重复:
- 发送方在每个分组中加 入序号
- 如果ACK/NAK出错,发送方重传当前分组
- 接收方丢弃(不发给上层)重复分组
- 接收方通过序号判断,是否重复接收同样的包,在进行下一次流程/发送ack
停等协议(等待停止协议): 发送方发送一个分组, 然后等待接收方的应答
发送方:
-
在分组中加入序列号
-
两个序列号(0,1)就 足够了
- 一次只发送一个未经确认 的分组
-
必须检测ACK/NAK是否 出错(需要EDC )
-
状态数变成了两倍
- 必须记住当前分组的序列号为0还是1
接收方:
- 必须检测接收到的分组是否是重复的
- 状态会指示希望接收到的 分组的序号为0还是1
注意:接收方并不知道 发送方是否正确收到了其ACK/NAK
② 流程
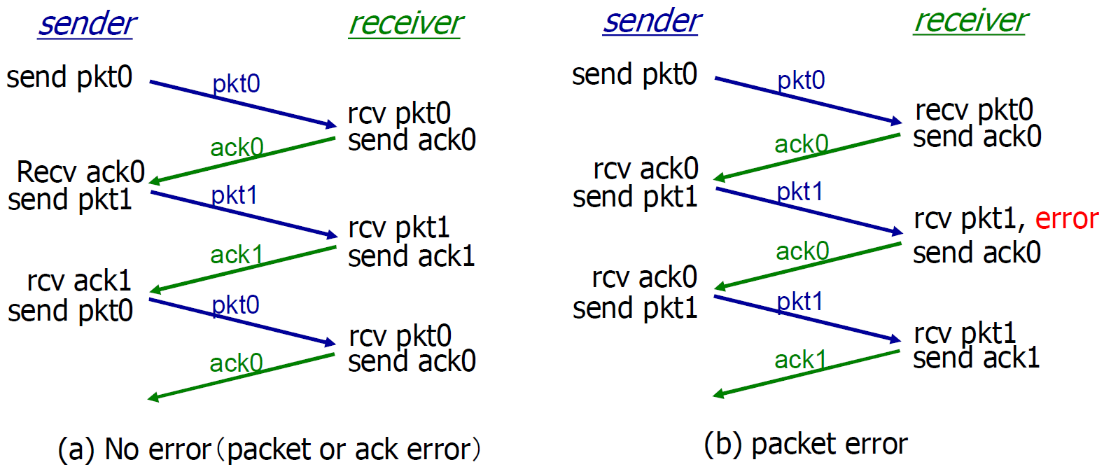
rdt2.1的运行
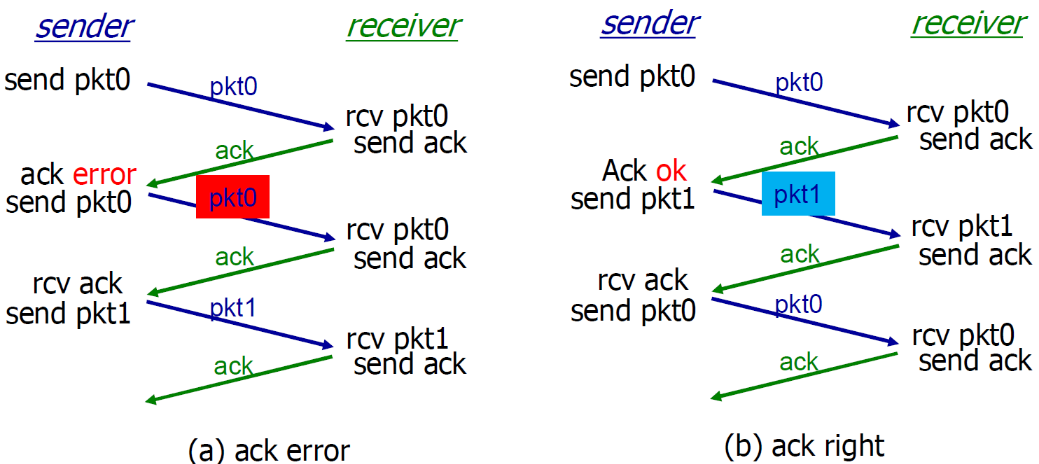
接收方不知道它最后发送的ACK/NAK是否被正确地收到
- 发送方不对收到的ack/nak给确认,没有所谓的确认的确认(如果有确认的确认,是不是还要有确认的确认的确认)
- 接收方发送ack,如果后面接收方收到的是:
- 老分组p0?则ack 错误
- 下一个分组?P1,ack正确(则P0被传递上去)
01仅仅是标识老旧的符号,并不表示顺序,如果上方右侧的pkt1的ack错误的话,下次sender返回的还是pkt1
③ FSM
a. 发送方
b. 接收方
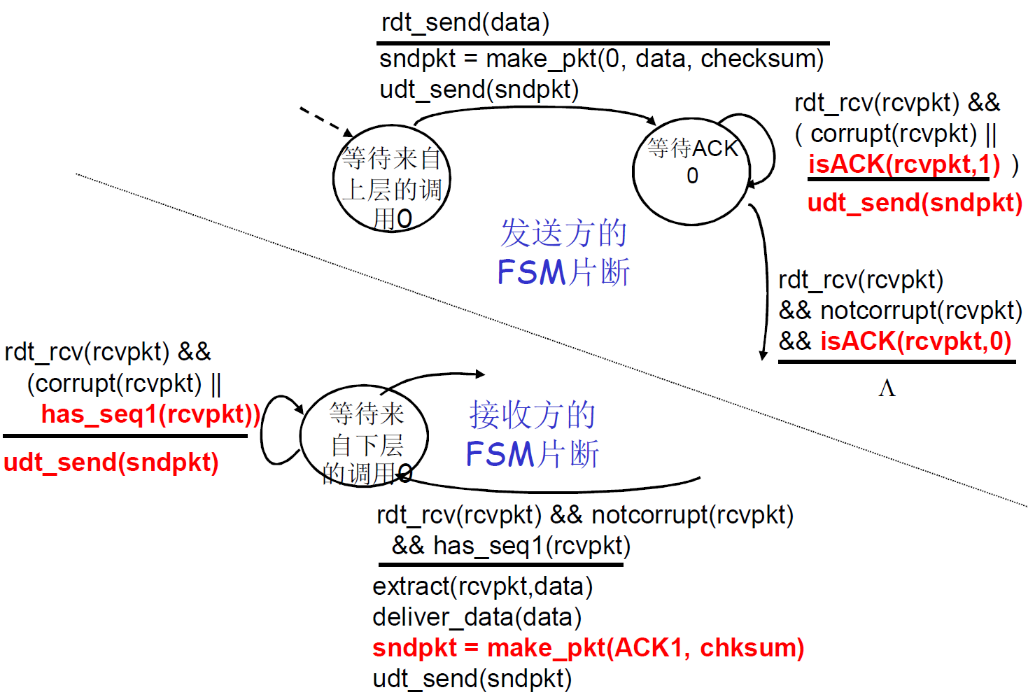
(4) Rdt2.2:无NAK的协议
① 思路
- 功能同rdt2.1,但只使用ACK(ack 要编号)
- 接收方对最后正确接收的分组发ACK,以替代NAK
- 接收方必须显式地包含被正确接收分组的序号
- 对当前分组的反向确认(NAK)可以用前面一个分组的正向确认代替
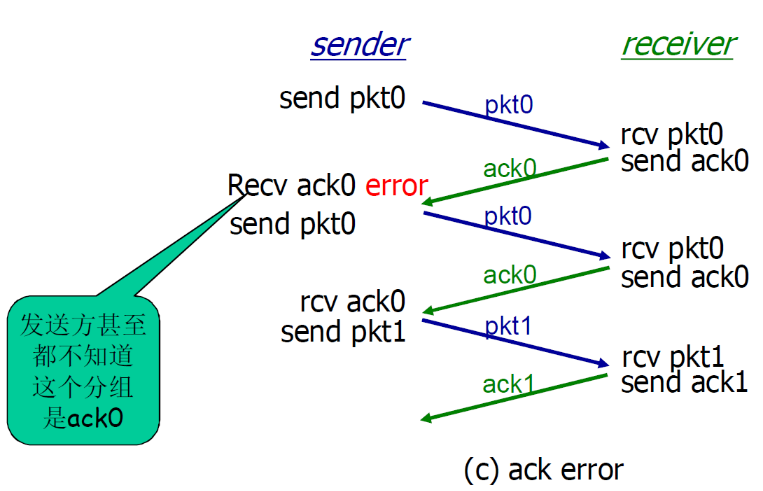
- 比如已经ACK0了,接受到了分组错误,sender本来应该收到ACK1,但是收到了ACK0,说明ACK1不会发过来,就错误
- 当收到重复的ACK(如:再次收到ack0)时,发送方与收到NAK采取相同的动作:重传当前分组
- 为后面的一次发送多个数据单位做一个准备
- 一次能够发送多个
- 每一个的应答都有:ACK,NACK;麻烦
- 使用对前一个数据单位的ACK,代替本数据单位的nak
- 确认信息减少一半,协议处理简单
② 流程
这种方法也能解决ACK出错的问题
③ FSM
(5) Rdt3.0:具有比特差错和分组丢失的信道
分组丢失的原因:分组发送到路由器时,路由器的队列满了,就会丢掉分组
① 思路
新的假设:下层信道可 能会丢失分组(数据或ACK)
- 会死锁(加入sender给receiver分组p,但是p丢失了,那么接收方一直等待p,发送方一直等待ACK,陷入死锁)
方法:发送方等待ACK一段合理的时间
- 发送端超时重传:如果到时没有 收到ACK->重传
重传的时间应该略大于正常时间(即发送方发出分组并接受ACK的时间)
- 问题:如果分组(或ACK )只 是被延迟了: 重传将会导致数据重复,但利用序列号已经可以处理这 个问题
- 接收方必须指明被正确接收的序列号
需要一个倒计数定时器
链路层的timeout时间确定的 (比较集中)
传输层timeout时间是适应式的 (不太集中)
② 流程图
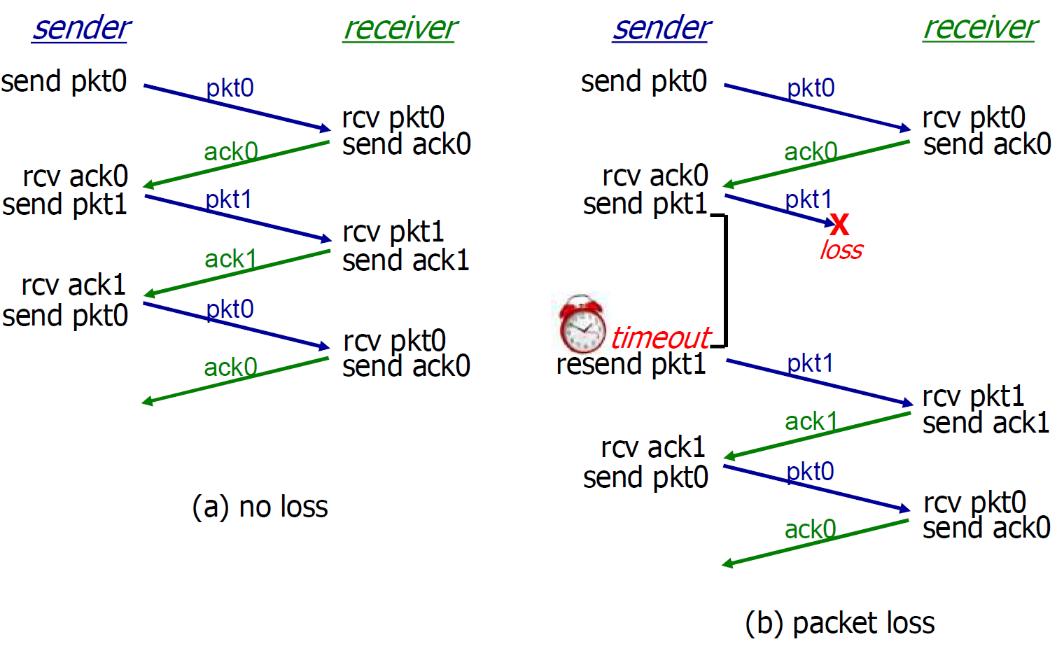
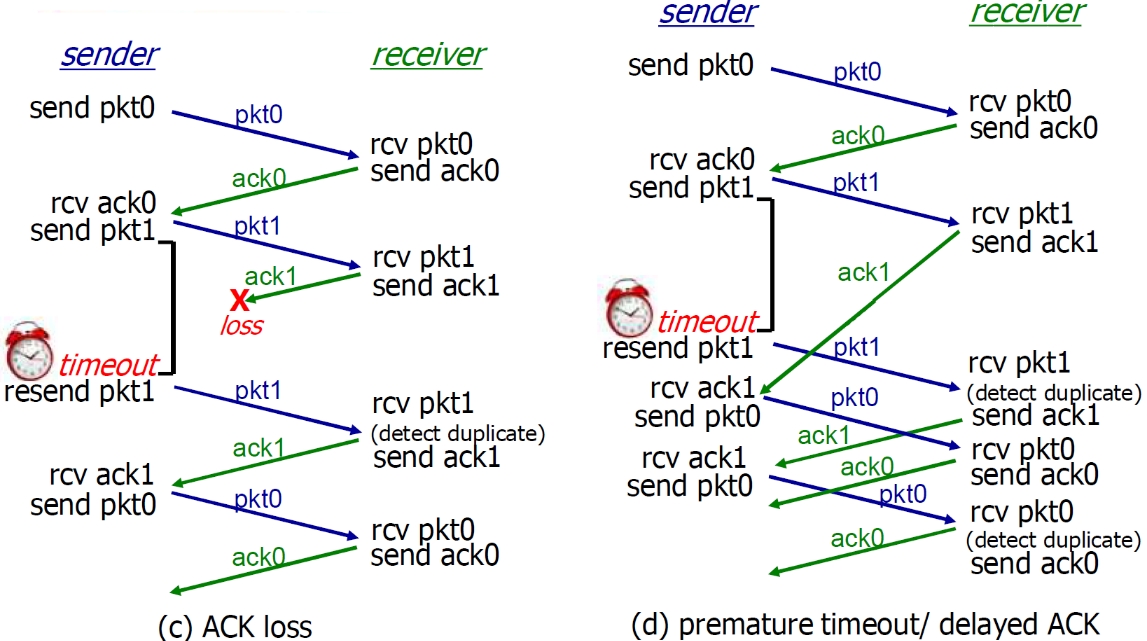
- b:可以看到p丢失的情况下可以正常工作
- c:可以看到ACK丢失的情况下依旧可以正常工作(sender发送了pkt1,然后receiver收到pkt1发现是旧的之后,接收,发哦送了ack1)
- d:超时时间设置的过短了
- 过早超时(延迟的ACK)也能够正常工作;但是效率较低,一半的分组和确认是重复的;
- 设置一个合理的超时时间也是比较重要的;
此刻,stop-wait的上限已经如此了,已经能解决了碰到的问题了
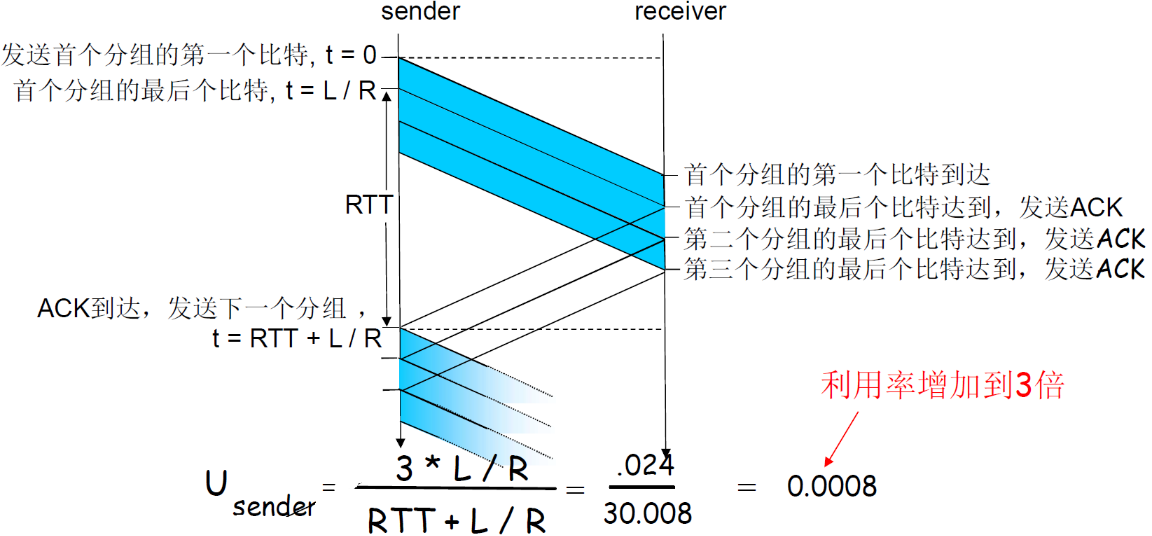
(6) stop-wait性能分析
rdt3.0可以工作,但链路容量比较大的情况下,性能很差
- 链路容量比较大,一次发一个PDU 的不能够充分利用链路的传输能力

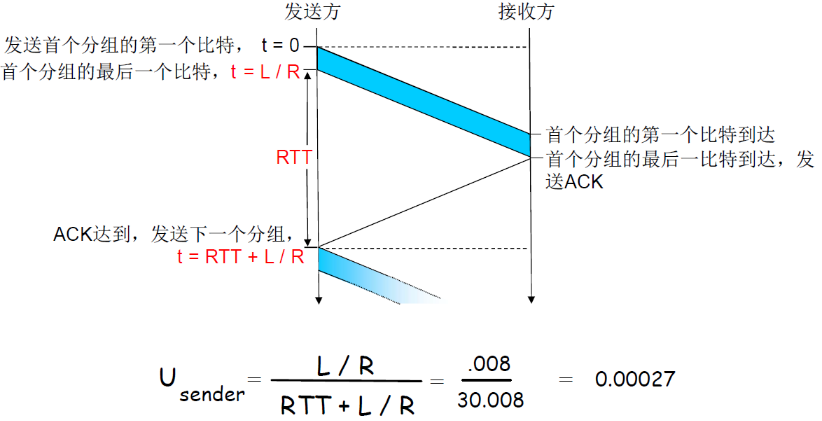
- Usender:利用率 – 忙于发送的时间比例
- 每30ms发送1KB的分组 -> 270kbps=33.75kB/s 的吞吐量(在1 Gbps 链路上)
- 瓶颈在于:网络协议限制了物理资源的利用!
在信道比较大的情况下,信道利用率比较低
- 信道可以看做一个管道,发送的bit可以看作管道里面的水流
如果链路容量比较小的时候,stop-wait还是可以的
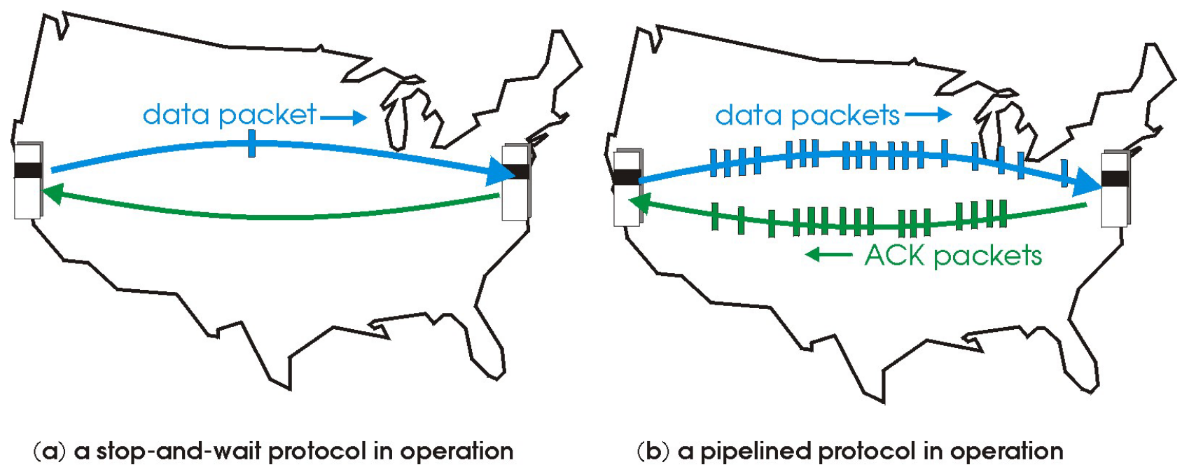
3.4.3 pipeline流水线协议
(1) 流水线(管道化)协议概述
目的:提高链路利用率
- 增加n(也就是发送分组的数量),能提高链路利用率
- 但当达到某个n,其u=100%时,无法再通过增加n,提高利用率
- 此时瓶颈转移了,由协议转为链路带宽
流水线:允许发送方在未得到对方确认的情况下一次发送多个分组
- 必须增加序号的范围:用多个bit表示分组的序号(用n位表示序号,那么序号的空间为2n)
- 在发送方/接收方要有缓冲区
- 发送方缓冲的作用:未得到确认,可能需要重传(以便于检错重发和超时重发);
- 接收方缓存的作用:上层用户取用数据的速率≠接收到的数据速率;接收到的数据可能乱序,排序交付(可靠)
两种通用的流水线协议:回退N步(GBN)和选择重传(SR)
(2) 通用:滑动窗口SW协议
在介绍GBN和SR协议之前,先介绍一个通用的协议,滑动窗口(slide window)协议
slide window sw(sending window) rw(receiving window) 协议 说明 =1 =1 stop-wait 如果发送窗口和接收窗口数量都为1,是stop-wait协议 流水线协议 >1 =1 GBN 如果发送窗口>1,接收窗口=1,是GBN协议 流水线协议 >1 >1 SR 如果发送窗口和接受窗口都 > 1 是SR协议
① 发送缓冲区
- 形式:内存中的一个区域,落入缓冲区的分组可以发送
- 功能:用于存放已发送,但是没有得到确认的分组
- 必要性:需要重发时可用
发送缓冲区的大小:一次最多可以发送多少个未经确认的分组
- 停止等待协议=1
- 流水线协议>1,合理的值,不能很大,链路利用率不能够超100%
发送缓冲区中的分组
- 未发送的:落入发送缓冲区的分组,可以连续发送出去;
- 已经发送出去的、等待对方确认的分组:发送缓冲区的分组只有得到确认才能删除
发送缓冲区的大小是固定的
② 发送窗口
发送窗口:发送缓冲区内容的一个范围
- 那些已发送但是未经确认分组的序号构成的空间
发送窗口的最大值<=发送缓冲区的值
采用相对移动方式表示,分组不动,可缓冲范围移动,代表一段可以发送的权力
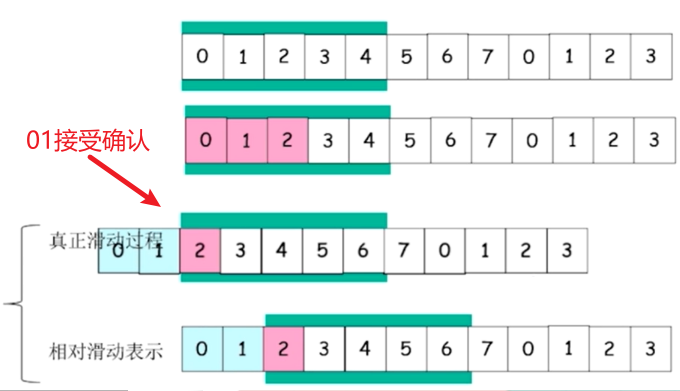
相对滑动表示:就是队列不变,但是缓冲区向前移动了
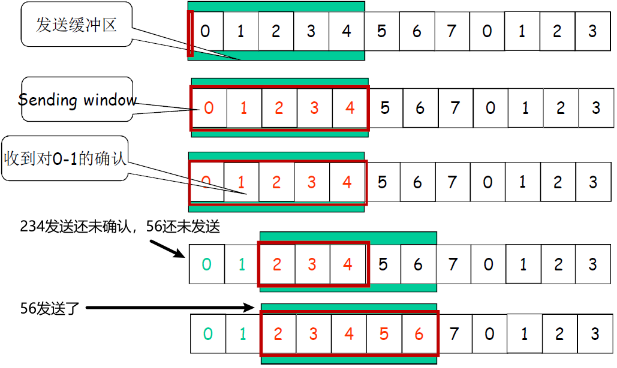
③ 发送缓冲区和窗口的移动
一开始:没有发送任何一个分组
- 后沿=前沿
- 之间为发送窗口的尺寸=0

前沿移动:
每发送一个分组,前沿前移一个单位

发送窗口前沿移动的极限:不能够超过发送缓冲区的大小

发送窗口后沿移动
- 条件:收到老分组的确认
- 结果:发送缓冲区罩住新的分组,来了分组可以发送
- 移动的极限:不能够超过前沿

④ 接收窗口
| slide window | sw (sending window) | rw (receiving window) | |
|---|---|---|---|
| =1 | =1 | stop-wait | |
| 流水线协议 | >1 | =1 | GBN |
| 流水线协议 | >1 | >1 | SR |
两种通用的流水线协议:回退N步(GBN)和选择重传(SR)
接收窗口 (receiving window)=接收缓冲区
接受窗口等同于接受缓冲区
- 接收窗口用于控制哪些分组可以接收;
- 只有收到的分组序号落入接收窗口内才允许接收
- 若序号在接收窗口之外,则丢弃;
- 接收窗口尺寸Wr=1,则只能顺序接收;
- 接收窗口尺寸Wr>1 ,则可以乱序接收
- 但提交给上层的分组,要按序
例子:Wr=1,在0的位置;只有0号分组可以接收;向前滑动一个,罩在1的位置,如果来了第2号分组,则丢 弃。
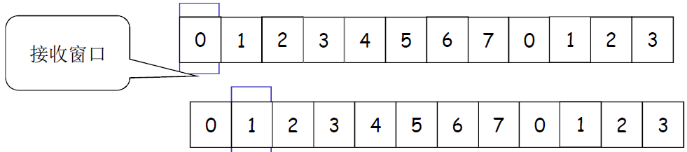
接收窗口的滑动和发送确认
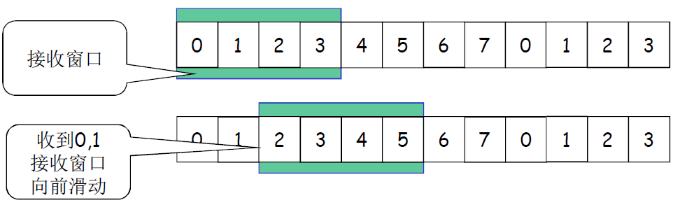
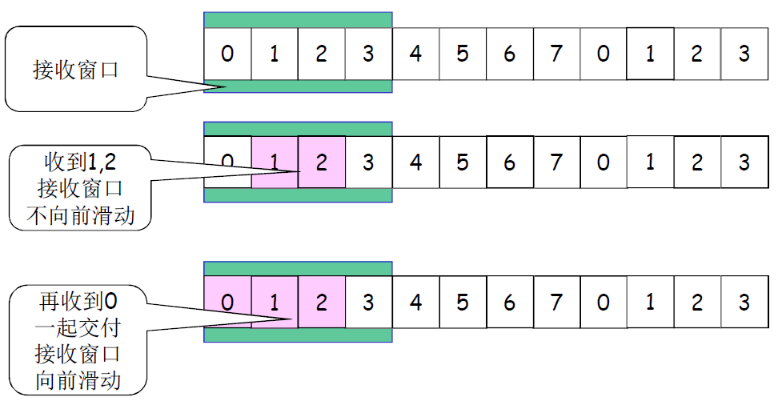
- 滑动:
- 低序号的分组到来,接收窗口移动;
- 高序号分组乱序到,缓存但不交付(因为要实现rdt,不允许失序),不滑动
- 发送确认:
- 接收窗口尺寸=1 ; 发送连续收到的最大的分组确认(累计确认)
- 接收窗口尺寸>1 ; 收到分组,发送那个分组的确认(非累计确认,比如发送ACK3表示收到3分组,但是并不代表2分组就收到了)
⑤ 正常情况下的2个窗口互动
- 接受窗口 = 1 → GBN
- 接收窗口 > 1 → SR
(3) GBN协议
Go-back-N协议
① 窗口互动
异常情况下GBN的2窗口互动
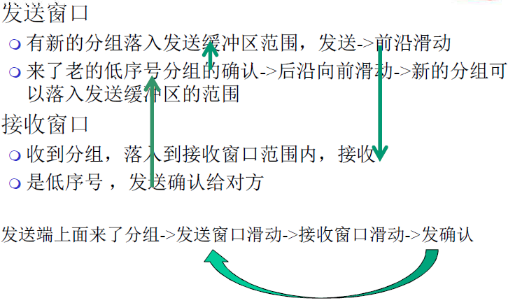
发送窗口
-
新分组落入发送缓冲区范围,发送->前沿滑动
-
超时重发机制让发送端将发送窗口中的所有分组发送出去(就是将所有已发送但是未确认的分组都发送出去)
-
来了老分组的重复确认→后沿不向前滑动→新的分组无法落入发送缓冲区的范围团(此时如果发送缓冲区有新的分组可以发送)
接收窗口
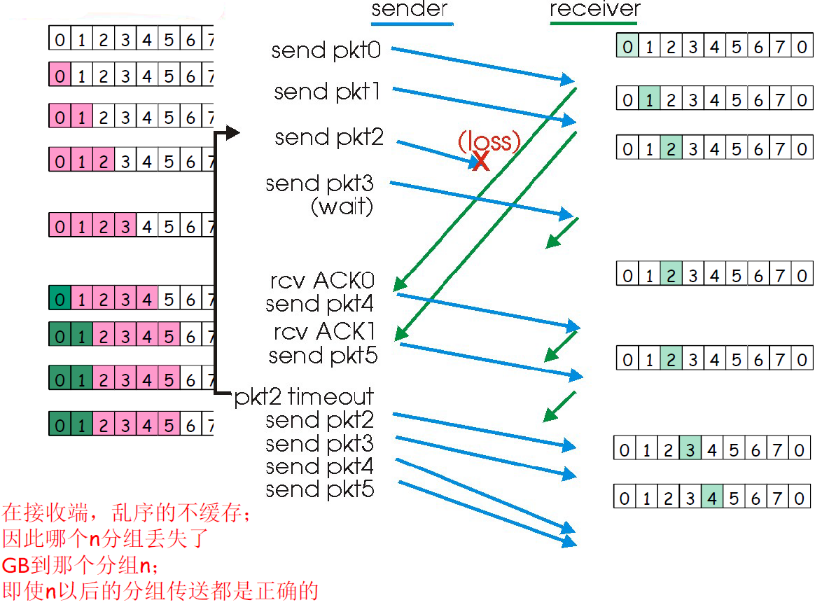
- 收到乱序分组,没有落入到接收窗口范界内,抛弃(假如现在接收窗口罩到了2,表明收到了1,但是收到了3,即收到乱序分组,则会抛弃3)
- (重复)发送老分组的确认,累计确认(已经收到了1,此时会发送ACK1)

② FSM
发送方

接收方
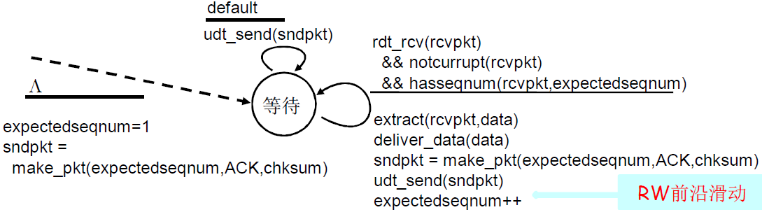
只发送ACK:对顺序接收的最高序号的分组
- 可能会产生重复的ACK
- 只需记住expectedseqnum;接收窗口=1
- 只一个变量就可表示接收窗口
对乱序的分组:
- 丢弃(不缓存)→ 在接收方不被缓存!
- 对顺序接收的最高序号的分组进行确认-累计确认

③ 运行流程图
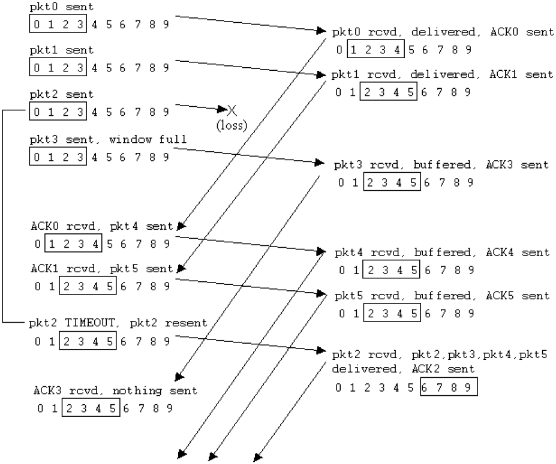
(4) SR协议
Selective Repeat 选择重传协议
① 窗口互动
异常情况下SR的2窗口互动
发送窗口
- 新分组落入发送缓冲区范围,发送 → 前沿滑动
- 超时重发机制让发送端将超时的分组重新发送出去(假如收到了 3 4号分组的确认但是没有收到2号分组的确认,那么只有2号分组超时,只重发送2号分组)
- 来了乱序分组的确认 → 后沿不向前滑动 → 新的分组无法落入发送缓冲区的范围(此时如果发送缓冲率有新的分组可以发送)
接收窗口
- 收到乱序分组,落入到接收窗口范围内,接收
- 发送该分组的确认,单独确认

接收方对每个正确接收的分组,分别发送ACKn(非累积确认)
- 接收窗口>1:可以缓存乱序的分组
- 最终将分组按顺序交付给上层
发送方只对那些没有收到ACK的分组进行重发-选择性重发
- 发送方为每个未确认的分组设定一个定时器
- 发送窗口的最大值(发送缓冲区)限制发送未确认分组的个数
发送方:
- 从上层接受数据:如果下一个可用于该分组的序号可在发送窗口中,则发送
- timeout(n):重新发送分组n,重新设定定时器
- ACK(n) in [sendbase,sendbase+N]:
- 将分组n标记为已接收
- 如n为最小未确认的分组序号,将base移到下一个未确认序号
接收方:
- 分组n [rcvbase, rcvbase+N-1]
- 发送ACK(n)
- 乱序:缓存
- 有序:该分组及以前缓存的序号连续的分组交付给上层,然后将窗口移到下一个仍未被接收的分组
- 分组n [rcvbase-N, rcvbase-1]
- ACK(n)
- 其它:
- 忽略该分组
② 运行流程图
(5) GBN vs SR
① 异同
相同之处
- 发送窗口>1
- 一次能够可发送多个 未经确认的分组
不同之处
-
GBN :接收窗口尺寸=1
-
接收端:只能顺序接收
-
发送端:从表现来看,一旦一个 分组没有发成功,如:0,1,2,3,4 ; 假如1未成功,234都发送出去 了,要返回1再发送;GB1(go back 1)
-
-
SR: 接收窗口尺寸>1
- 接收端:可以乱序接收
- 发送端:发送0,1,2,3,4,一旦1 未成功,2,3,4,已发送,无需重发,选择性发送1
Go-back-N:
- 发送端最多在流水线中有N个未确认的分组
- 接收端只是发送累计型确认(cumulative ack);接收端如果发现gap,不确认新到来的分组
- 发送端拥有对最老的 未确认分组的定时器
- 只需设置一个定时器
- 当定时器到时时,重传所有未确认分组
Selective Repeat:
-
发送端最多在流水线中有N个未确认的分组
-
接收方对每个到来的分组单独确认individual ack (非累计确认)
-
发送方为每个未确认的分组保持一个定时器
当超时定时器到时,只是重发到时的未确认分组
② 优缺点
| GBN | SR | |
|---|---|---|
| 优点 | 简单,所需资源少(接收方一个 缓存单元) | 出错时,重传一个代价小 |
| 缺点 | 一旦出错,回退N步代价大 | 复杂,所需要资源多(接收方多个 缓存单元) |
③ 适用范围
- 出错率低:比较适合GBN,出错非常罕见,没有必 要用复杂的SR,为罕见的事件做日常的准备和复杂处理
- 链路容量大(延迟大、带宽大、出错率也就比较大):比较适合SR而不 是GBN,一点出错代价太大
(6) 发送窗口的最大尺寸
假设用n bit表示序号,则发送窗口的最大尺寸如下(超过这个尺寸会出问题)
- GBN: 2n -1
- SR:2n-1
例
如:n=2; 序列号:0, 1, 2, 3
- GBN =3
- SR=2
SR的例子:
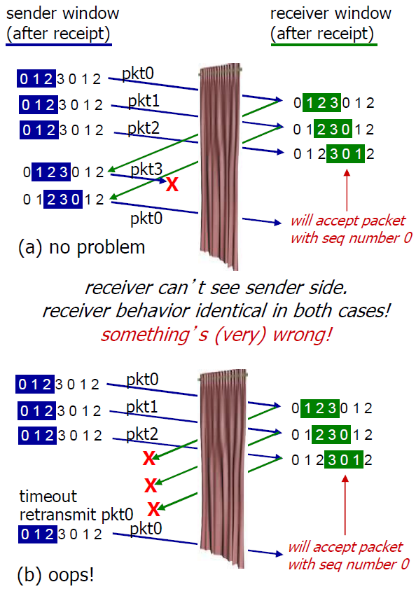
- 接收方看不到二者的区别!
- 将重复数据误认为新数据 (a)
3.5 拥塞控制原理
拥塞控制的目的:在不使得拥塞的情况下,尽可能的利用带宽
3.5.1 概述
拥塞
-
非正式的定义: “太多的数据需要网络传输,超过了网络的处理能力”
-
与流量控制不同:(流量控制是服务端负载过大)
-
拥塞的表现:
- 分组丢失 (路由器缓冲区溢出)
- 分组经历比较长的延迟(在路由器的队列中排队)
-
网络中前10位的问题!
3.5.2 拥塞的原因和代价
(1) 场景一:缓冲无限大、无重传
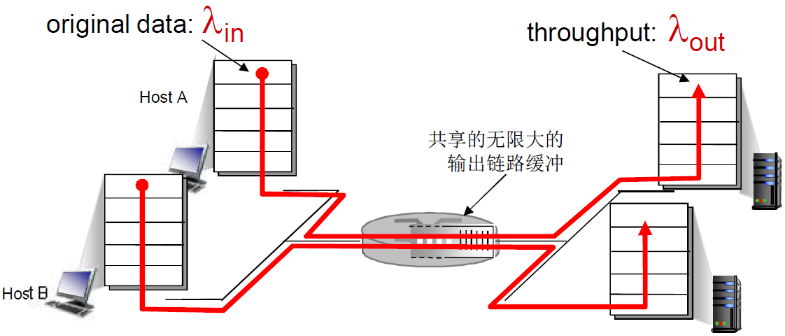
情景:
- 2个发送端,2个接收端
- 一个路由器,具备无限大的缓冲
- 输出链路带宽:R(bps)
- 没有重传(表示客户端没有数据的缓存,也没有重传数据的流量)
- λin为输入的速率,λout为输出的速率
则有

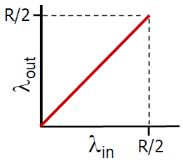
从吞吐量角度
- 由于缓冲无穷大,那么输入λin多少,输出λout就为多少
- 但是当 λin = R/2的时候,链路的吞吐量达到饱和(每个连接的最大吞吐量:R/2)
- 此时λin再大,也接受不了那么多了
- 算是好处:输入有多少,输出就有多少(在达到最大吞吐量之前)
从延迟角度
- 流量强度越接近1,延迟陡增
(2) 场景二:缓冲有限、有重传
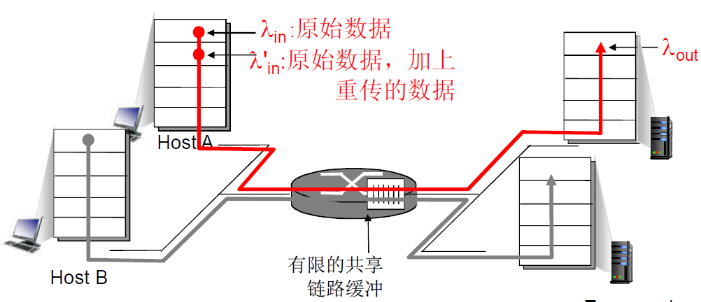
- 一个路由器,有限的缓冲
- 分组丢失时,发送端重传
- 应用层的输入=应用层输出: λin = λout
- 传输层的输入包括重传: λin' >= λin
- 最终的结果:λin' >= λout,数据会在缓冲区阻塞
当流量强度越接近于1,也就是λin越接近 R/2,那么重传的比例也就越大
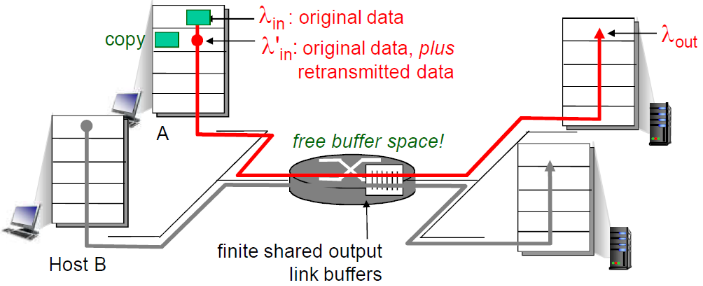
① 理想化: 发送端有完美的信息
发送端知道什么时候路由器的缓冲是可用的,因此当缓冲区满的时候就不会传输局了,因此也不会有数据丢失
- 只在缓冲可用时发送
- 不会丢失: λin' = λin
② 理想化:掌握丢失信息
理想化: 掌握丢失信息
- 分组可以丢失,在路由器由 于缓冲器满而被丢弃
- 如果知道分组丢失了,发送方重传分组
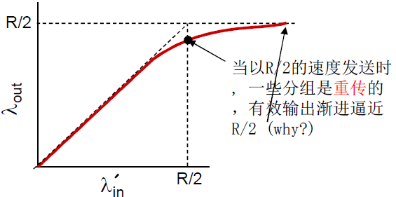
- λin'越接近 R/2,那么重传的比例越多,那么有效的输出速率λout也就越难达到同样的值
③ 现实情况: 重复
- 分组可能丢失,由于缓冲器 满而被丢弃
- 发送端最终超时,发送第2 个拷贝,2个分组都被传出
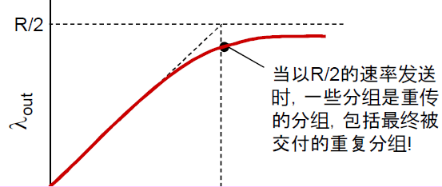
输出比输入少原因:
- 重传的丢失分组
- 没有必要重传的重复分组
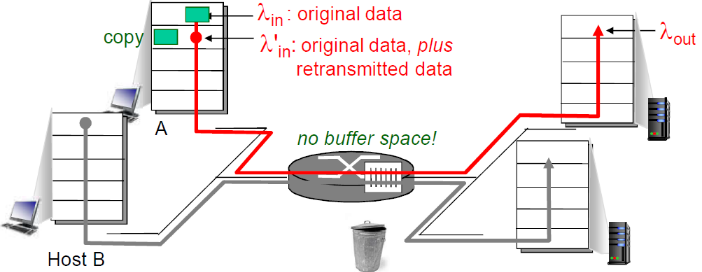
(3) 场景三:死锁
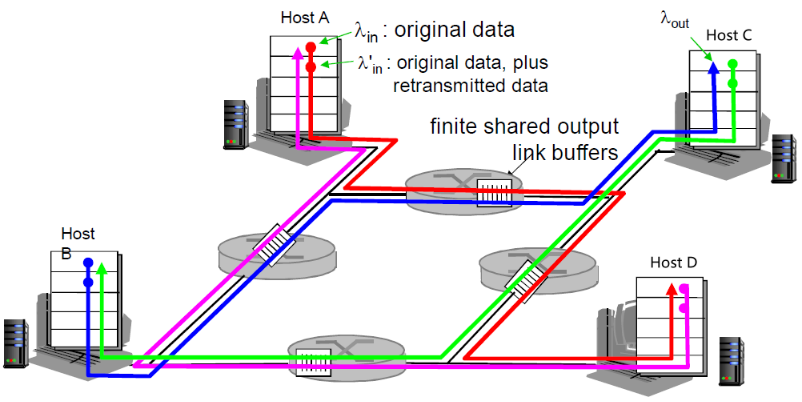
场景:
- 四个发送端:A→D,D→A,B→C,C→B(就是AD,BC相互连接)
情况:
- 当红色的增加时,所有到来的蓝色分组都在最上方的队列中丢弃了,蓝色吞吐->0
- 同理,绿色的也可能抢走红色的(在右边的路由器)
- 粉色的可能抢走绿色的(下边的路由器)
- 蓝色的抢走粉色的(左边的路由器)
- 总之,网络中有输入,但是没有输出
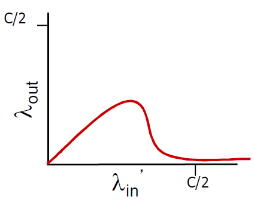
上图中右半部分 λin与λout不为1的情况都是拥塞的情况
又一个拥塞的代价:
- 当分组丢失时,任何“关于这个分组的上游传输能力” 都被浪费了
(4) 拥塞的代价
- 延迟大
- 为了达到一个有效输出,网络需要更多的输入速率(重传)
- 没有必要的重传(加剧了网络的拥塞),链路中包括了多个分组的拷贝
- 是那些没有丢失,经历的时间比较长(拥塞状态)但是超时的分组
- 降低了的“goodput”
- 当分组丢失时,任何“关于这个分组的上游传输能力” 都被浪费了
3.5.3 拥塞控制方法
2种常用的拥塞控制方法:
-
端到端拥塞控制:
- 没有来自网络的显式反馈
- 端系统根据延迟和丢失事件推断是否有拥塞
- (TCP采用的方法)
-
网络辅助的拥塞控制:
- 路由器提供给端系统以反馈信息
- 单个bit置位,显示有拥塞 (SNA, DECbit, TCP/IP ECN, ATM)
- 显式提供发送端可以采用的速率
3.5.4: ATM ABR 拥塞控制
(1) ATM网络介绍
ATM:异步传输网络,是物联网掺杂的网络
- 数据传输单元(分组)是信元:53个字节,5个字节的头部,另外48个字节是数据部
- 分组很小(53个字节),而且是固定长度
- 所以在每个交换节点的存储转发时间很小而且可以控制
- 线路交换在数据交换节点的延迟是1bit的延迟,分组交换的延迟是1个分组的延迟
- 由于ATM的分组—信元大于1bit,但是远小于普通的一个分组,因此其延迟位于线路交换和分组交换之间
- 而且延迟时间固定(一位信元字节数固定),而且容易调度
- 因此具有线路交换和分组交换的特性
- ATM本来认为是很有希望的网络形式
- 后来因为网络技术比较复杂并没有流行开来
- 但是在一些专用网络,比如银行网络使用的还是比较多的
ATM有很多模式,ABR是其中一直
(2) ABR模式
ABR: available bit rate:
- 弹性服务:
- 如果网络轻载(不发送拥塞),可以尽可能使用网络带宽
- 如果网络拥塞了 ,发送方限制其发送的速度到一个 最小保障速率 上
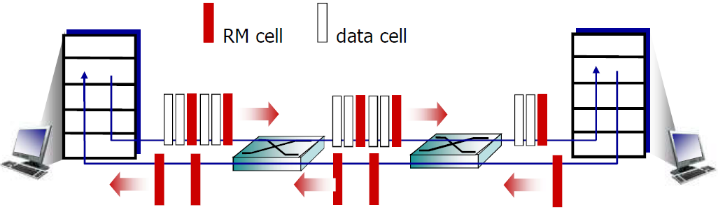
这个是交换机设置的,不是路由器
在ATM网络中有两种信元:数据信元(data cell)和资源信元(RM cell)
RM (资源管理) 信元:
- 由发送端发送,在数据信元中间隔插入
- RM信元中的比特被交换机设置 (网络辅助)
- NI bit: no increase in rate (轻微拥塞)速率不要增加了
- CI bit: congestion indication 拥塞指示(表明已经拥塞了)
- 发送端发送的RM 信元被接收端返回, 接收端不做任何 改变
也就是
- 发送端会发送RM cell资源信元
- 交换机对经过的RM cell,根据拥塞情况对 NI和CI 位置位
- 然后RM cell到达接收端之后接收端仅仅起返回作用
- 发送端根据返回的RM cell来调整发送速率
数据信元中的EFCI bit: 被拥塞的交换机设置成1
- 如果在管理信元RM前面的数据信元EFCI被设置成了1, 接收端在 返回的RM信元中设置CI bit
在RM信元中的2个字节 ER (explicit rate)字段 多大带宽
- 拥塞的交换机可能会降低信元中ER的值(但是不会提高)
- 发送端接受到的RM的ER字段表示路由器可以支持的最低的速率
- 发送端发送速度因此是最低的可支持速率
3.6 面向连接的传输: TCP
3.6.1 TCP的特点
| 序号 | 特点 | 说明 |
|---|---|---|
| 1 | 点对点 | 一个发送方,一个接收方(不支持一对多) |
| 2 | 可靠的、按顺序的字节流 | 可靠:不出错,不丢失,不乱序; 没有报文边界:A→B,A提供两个报文,则B可能收到1个大的报文,或者4个小的报文;报文接线要靠应用进程自己维护 |
| 3 | 管道化(流水线) | TCP拥塞控制和流量控制设置窗口大小 |
| 4 | 发送和接收缓存 | 发送缓存:为了重复发送 接受缓存:为了跳转发送和接受的速度差 |
| 5 | 全双工数据 | 在同一连接中数据流双向 流动 MSS:最大报文段大小 MSS的大小 + TCP头部 + IP头部 = 一个报文段(TCP实体会将应用层传来的数据打成若干MSS大小,然后加上TCP头部) |
| 6 | 面向连接 | 在数据交换之前,通过握 手(交换控制报文) 初始 化发送方、接收方的状态 变量 |
| 7 | 有流量控制 | 发送方不会淹没接收方 |
3.6.2 TCP报文段
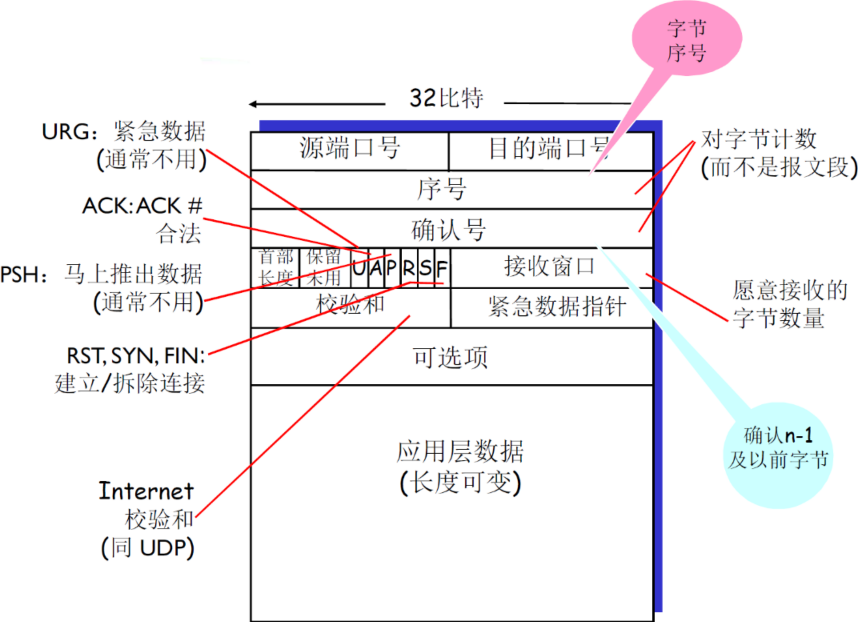
(1) 报文段结构及首部含义
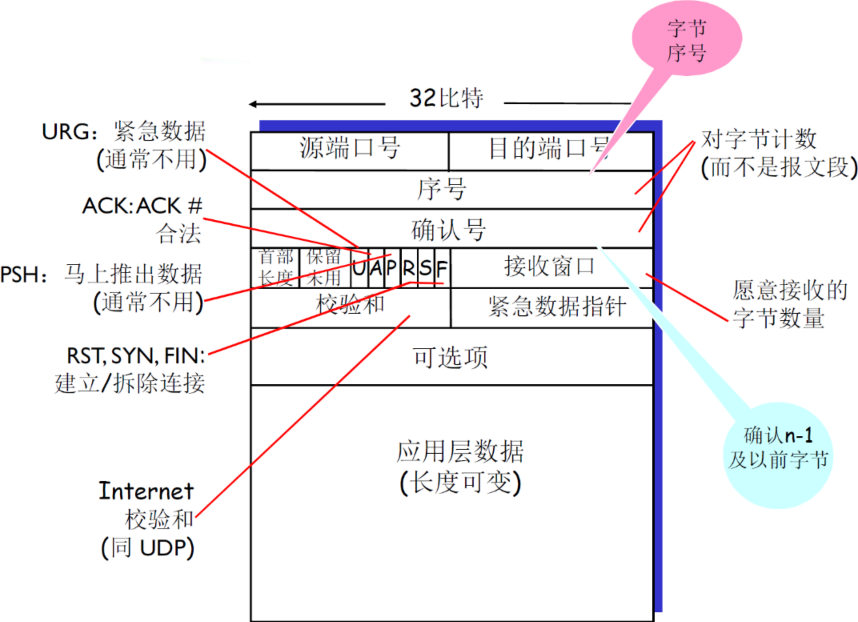
| 项目 | 说明 | 补充 |
|---|---|---|
| 序号 | 报文段首字节的在整个字节流的偏移量(offset),如是X,X+MSS,X+2*MSS等 | 两个应用进程的初始序号X不一定是从0开始,为了防止老的连接上的,滞留在网络中的分组,对新的连接的分组造成影响 是字节流的偏移量,不是一个文件的偏移量,应用层给TCP的都是字节流 初始序号X是自己定,并没有实际意义 |
| 确认号 | 期望从另一方收到的下一个字节的序号 累积确认 |
比如receiver发送ACK=5,表明receiver已经接受到了4及以前的报文段,希望接受到5 |
| 首部长度 | 以4个字节为单位 | 根据首部长度来判断 载荷(实际数据)从哪里开始,因为后面的可选项是不确定的 |
| 保留未用 | 未来可能使用的位,但是现在还没有用到 |
没有规定接收方如何处理乱序的报文段:可以缓存,也可以抛弃掉
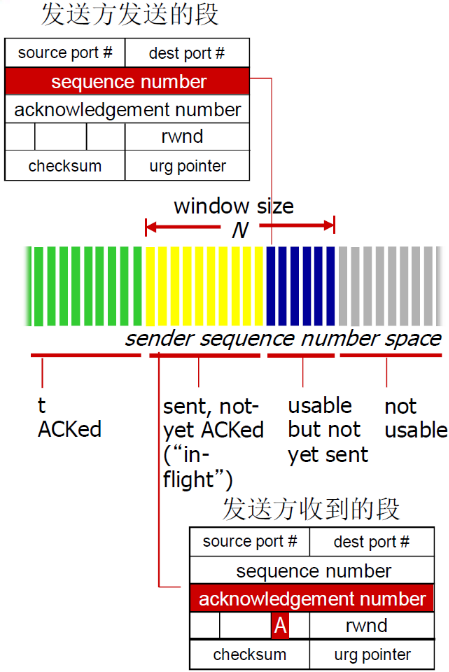
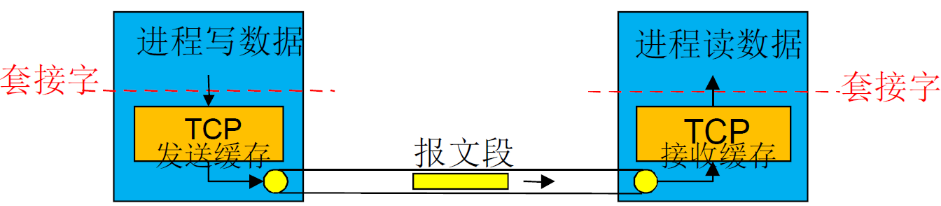
(2) 捎带技术(piggybacking)
这个思路值得学习,可以用到其他地方
- 之前对单纯的RDT的研究中,Sender和Receiver是分开的
- 因此发送方只发送data,接收方只发送ACK,如下
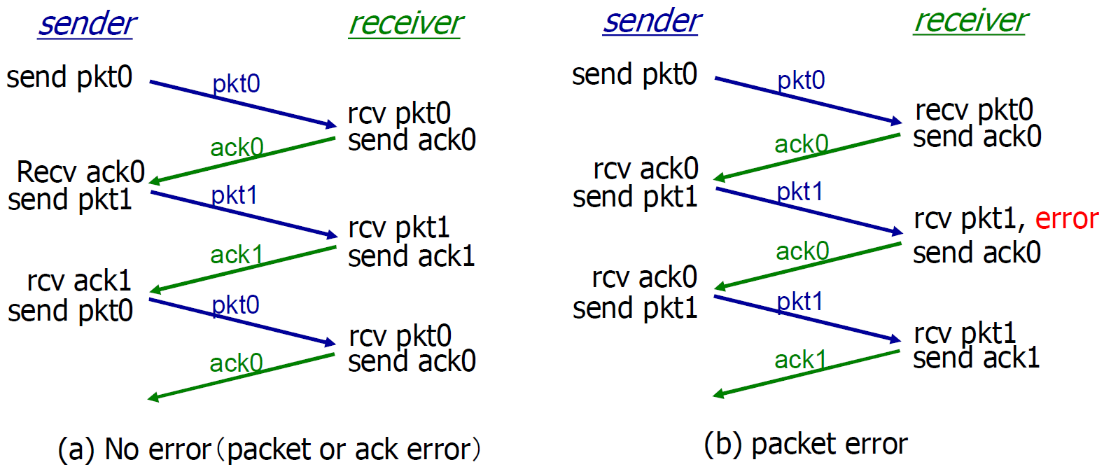
- 但是在TCP中,数据是双向传输的,每一方既可以看做sender,又可以看做receiver
- 假如AB通信,那么A作为sender要发送数据data,又要作为receiver要发送ACK,这样就很麻烦了
- 因此,可以将一些信息(不仅仅是ACK)包含在数据中心,在发数据的时候捎带发送
看下面的结构
- 可以用确认号来表示ACK
- 也可以用接收窗口来表示缓冲区的剩余大小(用于流量控制)
在后面讨论的时候,我们会研究单向传递,但是实际上是双向的,如下
- 尽管主机B发送ACK,但是ACK是包含在B给A的data当中的
- 这里是只研究A→B的单向传递
3.6.3 TCP序号和确认号
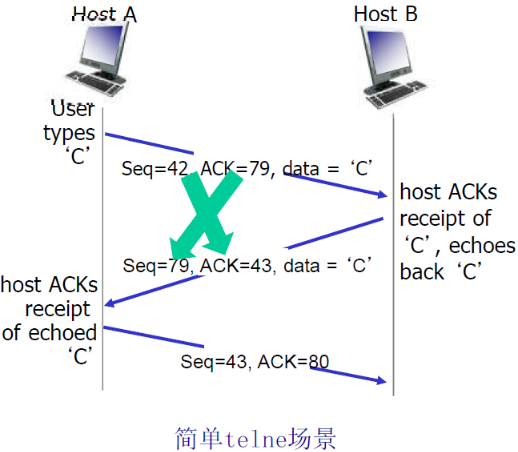
| 方向 | Seq | ACK | 说明 |
|---|---|---|---|
| A→B | 42 | 79 | 'C'所在的首字节的序列号为42;现在A已经收到了78及以前的字节了,希望收到79开始的字节 |
| B→A | 79 | 43 | 根据A的ACK,发送79开头的字节;又由于收到了42开始的字节,期望收到43 |
主要还是记住ACK的含义:
- ACK=100
- 表明接受到99及以前的字节
- 请求100开始的字节,就是告诉Sender感觉发送100开始的段
- TCP以前的例子说明ACK=100,表明100已经接受了,但是在TCP协议中有区别,是请求100
3.6.4 TCP往返延时(RTT)和超时
RTT是实际传输的时间,要根据RTT来设置超时
(1) 设置超时思路
怎样设置TCP 超时?
- 比RTT要长 ,但RTT是变化的
- 如果太短:太早超时 ,不必要的重传
- 如果太长:对报文段丢失反应太慢,消极
- 局域网中的两个计算机的延迟很小,而且稳定,可以设置成固定值
- 当两个主机所处的位置非常远(不在一个局域网内)的时候,它们的长时间RTT的分布是非常分散的(因为很不稳定),选用哪一个值都不合适
- 但是在短时间内是很集中的,可以采用短时间内最集中的值来作为超时时间
- 超时时间的设置是动态的、自适应的
- 要定期的测量RTT,测量器平均值和方差
- 超时时间 = 平均值 + 4*方差
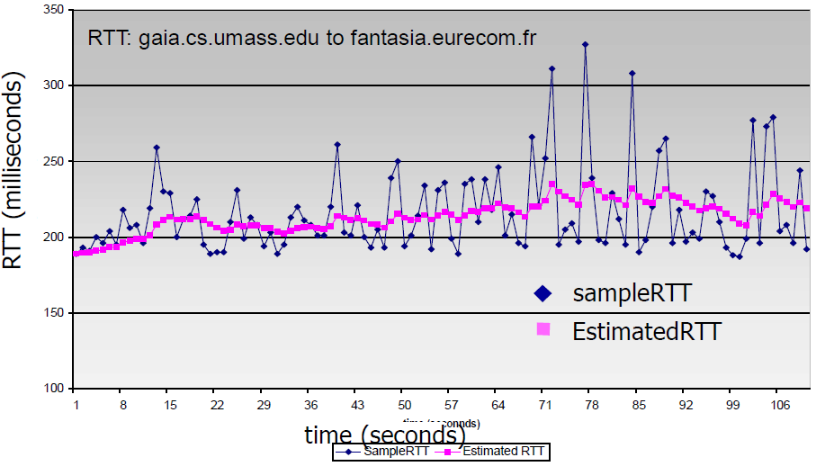
(2) 怎样估计RTT
上面说了,在很远范围内,RTT的变化是很快的,首先要能够估计出RTT的值,而且这个估计是动态的
怎样估计RTT?
- SampleRTT:测量从报文段发出到 收到确认的时间
- 如果有重传,忽略此次测量
如果是流水线协议,一次发送多个段,那么只测第一个就行,得到一个SampleRTT
- SampleRTT会变化,因此估计的 RTT应该比较平滑
- 对几个最近的测量值求平均,而 不是仅用当前的SampleRTT
EstimatedRTT = (1- a)*EstimatedRTT + a*SampleRTT
(1- a)*EstimatedRTT:EstimatedRTT是以前的平均值- 采用加权来获取平均值,当前采样值对平均值的影响越大,越往前影响越小
- 指数加权移动平均
- 过去样本的影响呈指数衰减
- 推荐值:a = 0.125
(3) 设置超时
EstimtedRTT + 安全边界时间
- EstimatedRTT变化大(方差大) → 较大的安全边界时间
SampleRTT会偏离EstimatedRTT多远:
DevRTT = (1-β)*DevRTT + β*|SampleRTT-EstimatedRTT|
- 推荐值:β = 0.25
DevRTT可以看做是方差了
超时时间间隔设置为:
TimeoutInterval = EstimatedRTT + 4*DevRTT
4*DevRTT就是安全边界时间
3.6.5 TCP可靠数据传输
3.4仅仅研究了通用的RDT,和TCP的RDT还是有所区别的
(1) 概述
TCP在IP不可靠服务的基础上 建立了rdt
- 管道化(流水线)的报文段;TCP是GBN和SR的结合
| 流水线特点 | 说明 | 类似协议 |
|---|---|---|
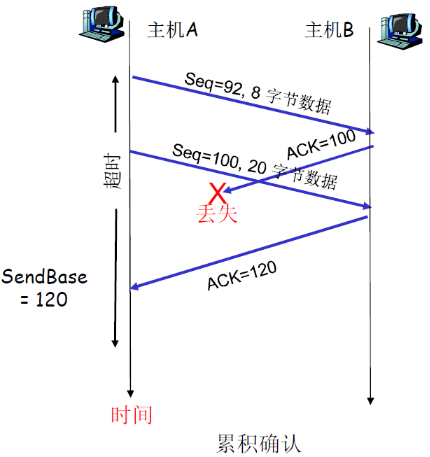
| 累积确认 | R发送ACK=100,说明请求100,表明前面的99个已经全部接受了 | GBN |
| 单个重传定时器 | 一次发送多个段(segment)的时候,只有第一段计时 | GBN |
| 超时 | 只重发那个最早的未确认段 | SR |
TCP没有规定是否可以接受乱序的,当接受到乱序的段的时候,可以抛弃,也可以缓存
-
重复的确认
例子:收到了ACK50,之后又收到3 个ACK50,这时候会重传50开头的段
这叫做快速重传
首先考虑简化的TCP发送方:
- 忽略重复的确认
- 忽略流量控制和拥塞控制
(2) TCP发送方(简化)
此时不考虑 重复的确认、流量控制和拥塞控制
① FSM
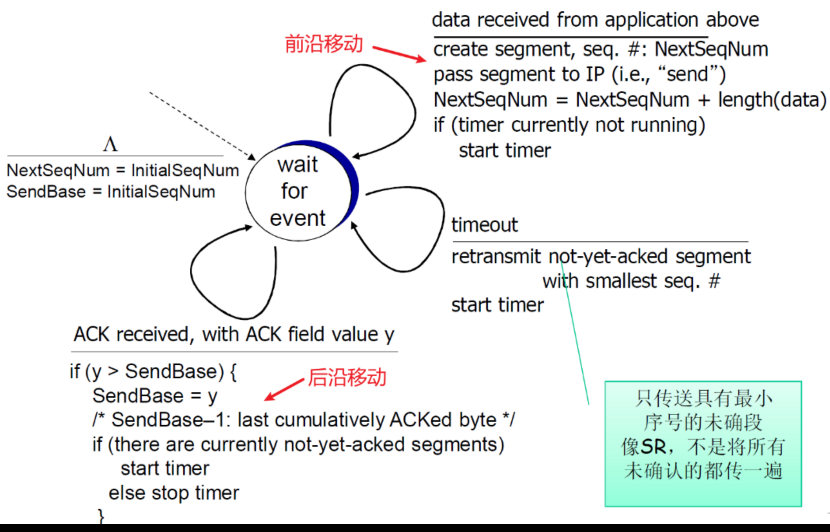
NextSeqnum:可以看做是前沿,表示下一次可以发送的字节SendBase:看做是后延,表示发送还未确认的
② 发送方动作
从应用层接收数据:
- 用nextseq创建报文段
- 序号nextseq为报文段首字节的字节流编号
- 如果还没有运行,启动定时器
- 定时器与最早未确认的报文段关联(单个重传定时器)
- 过期间隔:TimeOutInterval
超时:
- 重传后沿最老的报文段
- 重新启动定时器
收到确认:
- 如果是对尚未确认的报文段确认
- 更新已被确认的报文序号(后沿移动)
- 如果当前还有未被确认的报文段,重新启动定时器 (发完,就关掉定时器)
③ 伪代码
就是上面操作的伪代码
// 初始化
NextSeqNum = InitialSeqNum
SendBase = InitialSeqNum
// 一直循环
loop (forever) {
// 判断事件
switch(event)
// 如果收到了应用层的数据
event: data received from application above
// 用NextSeqNum创建TCPsegment
create TCP segment with sequence number NextSeqNum
// 如果定时器不在运行的话,开始
if (timer currently not running)
start timer
// 传给IP
pass segment to IP
// 前沿移动
NextSeqNum = NextSeqNum + length(data)
event: timer timeout
retransmit not-yet-acknowledged segment with
smallest sequence number
start timer
event: ACK received, with ACK field value of y
if (y > SendBase) {
SendBase = y
if (there are currently not-yet-acknowledged segments)
start timer
}
} /* end of loop forever */
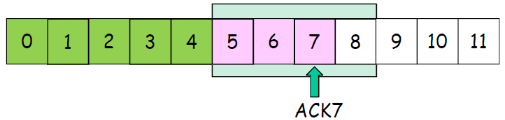
注释:
- SendBase-1: 最后一个累积确认的字节
- 例:
- SendBase-1 = 71;y= 73, 因此接收方期望73+ ; y是ACK的值
- y > SendBase,因此新的数据被确认
④ TCP重传流程
此处仍然是不考虑快速重传
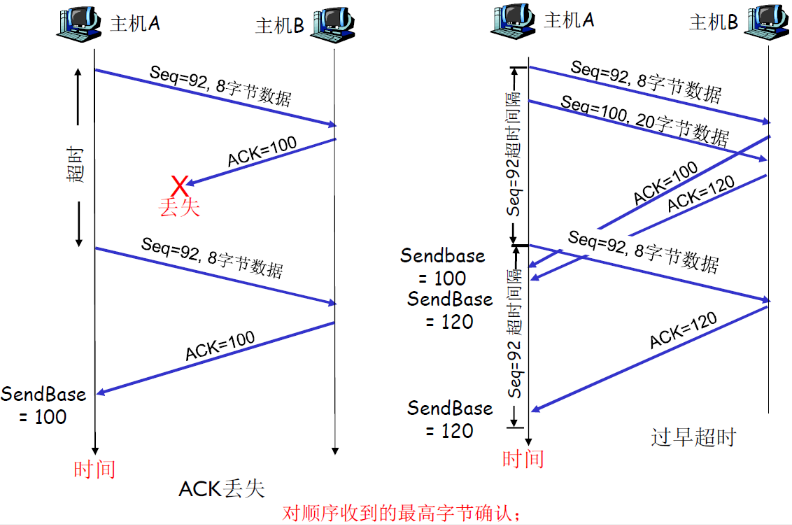
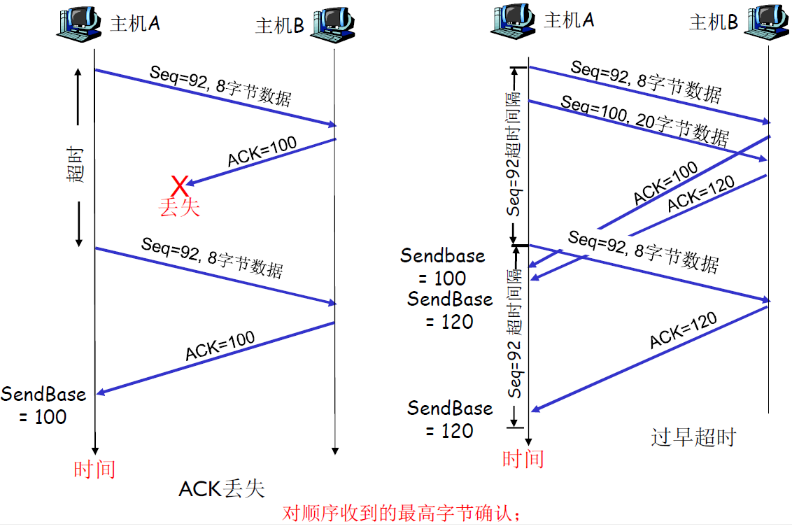
ACK丢失情况;
- A→B:Seq=92,8字节,B收到
- B→A:ACK=100,表明B已经收到了99以前的字节,想要收到Seq=100的数据
- ACK丢失,并且超时,则A重新传递Seq=92,8字节
过早超时:
- 最后一步,A→B:Seq=92,8字节,为什么B不传ACK=120了?
- 因为主机B不会确认ACK=100是否发送给A了,只管发送即可,如果B发送了ACK=100,就不会再发送了
- ACK=120表示起到获取120开始的字节,如果没有120,那么就会一直请求(累计确认)
- 这就是上方所说的
⑤ 接收方产生ACK的建议
前面只说了发送方,还没有说接收方
- ACK=100表明:已经接受了99及以前的字节,请求100的字节
| 序号 | 接收方的事件 | TCP接收方动作 | 补充 |
|---|---|---|---|
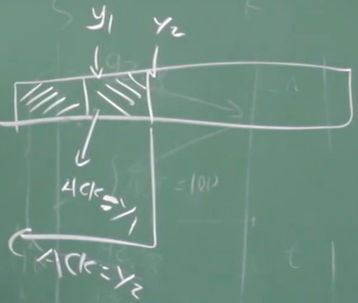
| 1 | 所期望序号的报文段按序到达。 所有在期望序号之前的数据都已经被确认 | 延迟发送ACK(提高效率,少发一个ACK)。对另一个按序报文段的到达最多等待500ms。如果下一个报文段在这个时间间隔内没有到达,则发送一个ACK。 | 就是当接受到y0之后,不发送ACK=y0+1,而是当顺序接受到y1之后,发送ACK=y1+1 注意必须是顺序接受到,如果是乱序,仍然请求y0+1 如果超时还未接受到,再发y0+1 |
| 2 | 有期望序号的报文段到达。 另一个按序报文段等待发送ACK | 立即发送单个累积ACK,以确认两个按序报文段。 | 就是上一条说的情况 |
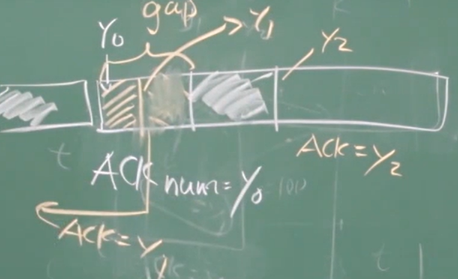
| 3 | 比期望序号大的报文段乱序到达。 检测出数据流中的间隔 | 立即发送重复的ACK,指明下一个期待字节的序号 | 如果收到了y0,然后乱序收到了y2,那么重新请求ACK=y0 + 1 |
| 4 | 能部分或完全填充接收数据间隔 的报文段到达 | 若该报文段起始于间隔(gap)的低端, 则立即发送ACK(给确认。反映下一段的需求)。 | 请求ACK=y0+1,此时已经乱序收到了y2的内容 请求之后得到的gap并不能填充y0到y2的空间,只能达到y1,因此重新请求ACK=y1 + 1 |
(3) 快速重传
- 超时周期往往太长:在重传丢失报文段之前的延时太长
- 通过重复的ACK来检测 报文段丢失
- 发送方通常连续发送大量 报文段
- 如果报文段丢失,通常会引起多个重复的ACK
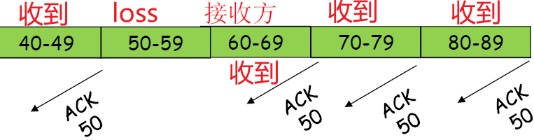
- 如果发送方收到同一数据 的3个冗余ACK,重传最 小序号的段:
- 快速重传:在定时器过时之前重发报文段
- 它假设跟在被确认的数据 后面的数据丢失了
- 第一个ACK是正常的;(比如第一个ACK=50,表明收到了49,是正常的,请求50)
- 收到第二个该段的ACK,表 示接收方收到一个该段后的乱序段; (因为再次请求50)
- 收到第3,4个该段的ack,表 示接收方收到该段之后的2个 ,3个乱序段,可能性非常大段丢失了
三重ACK接收后的快速重传

快速重传算法
event: ACK received, with ACK field value of y
if (y > SendBase) {
SendBase = y
if (there are currently not-yet-acknowledged segments)
start timer
}
else { // 已确认报文段的一个重复确认
increment count of dup ACKs received for y
if (count of dup ACKs received for y = 3) {
resend segment with sequence number y // 快速重传
}
3.6.6 TCP流量控制
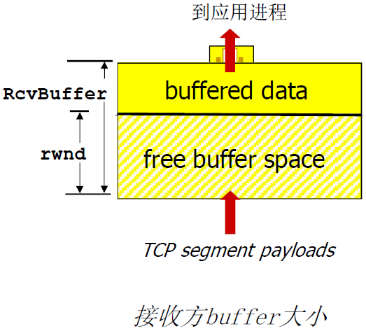
流量控制是为了防止发送方发送太快,超过接收方的接受能力
流量控制目的
- 接收方控制发送方,不让发送方发送的太多、太快以至于让 接收方的缓冲区溢出
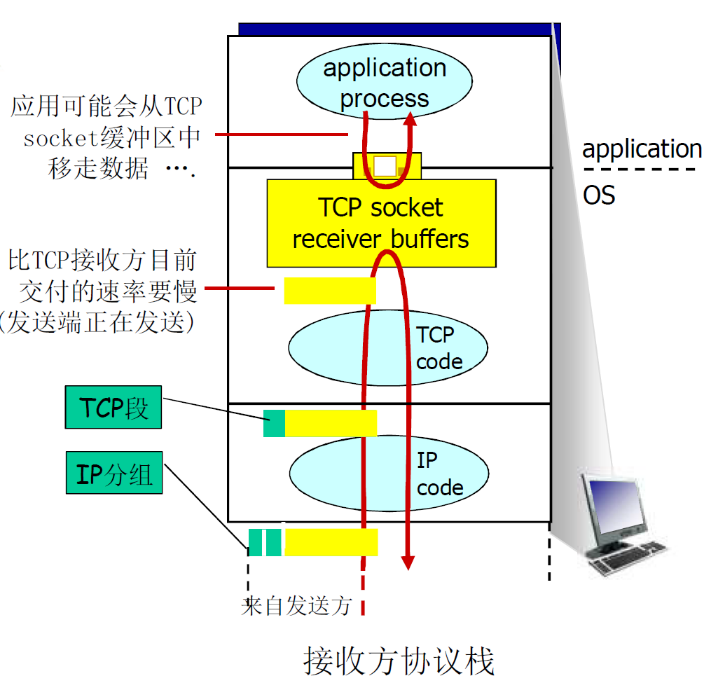
接收方在其向发送方的TCP段 头部的rwnd字段“通告”其空闲buffer大小
-
RcvBuffer大小通过socket选项设置 (典型默认大小为4096 字节)
-
很多操作系统自动调整 RcvBuffer
-
发送方限制未确认(“inflight”)字节的个数≤接收 方发送过来的 rwnd 值,保证接收方不会被淹没
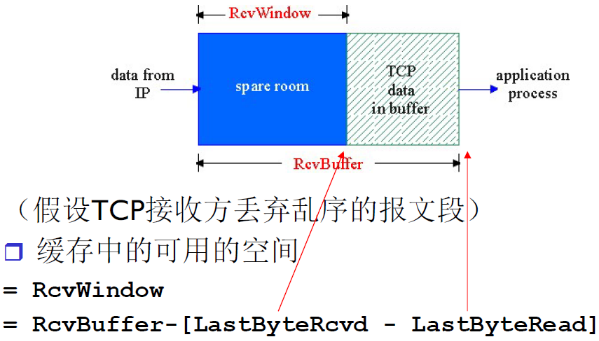
RcvWindow = 缓冲区空间 - 已经接收到未读取的空间
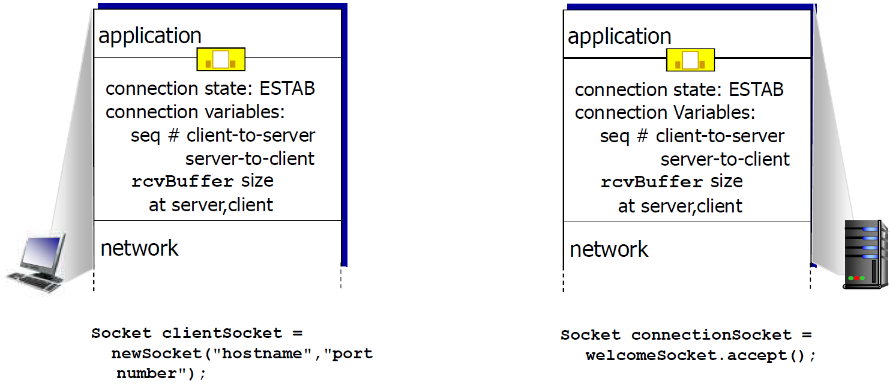
3.6.7 TCP连接管理
(1) 连接建立的本质
AB建立连接,表明三点:
- AB知道要和彼此通信(知道要通信的目标)
- 准备资源(比如缓冲区)
- 控制变量的置位(比如初始序号,初始化的receive buffer大小等)
在正式交换数据之前,发送方和接收方握手建立通 信关系:
- 同意建立连接(每一方都知道对方愿意建立连接)
- 同意连接参数
(2) 两次握手的问题
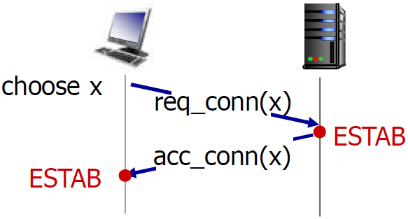
在网络中,2次握手建 立连接总是可行吗?
- 变化的延迟(连接请求的段没有丢,但可能超时)
- 由于丢失造成的重传 (e.g. req_conn(x))
- 报文乱序
- 相互看不到对方
以下是两次握手的问题:
- 半连接
- 接受老数据问题
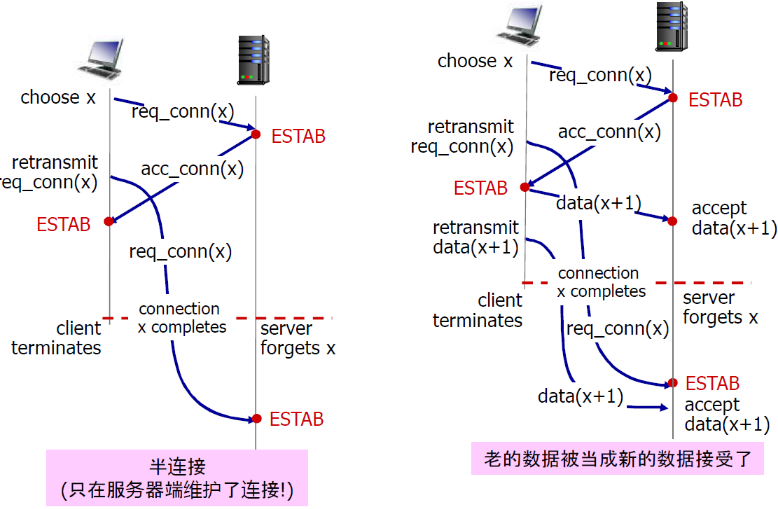
① 半连接
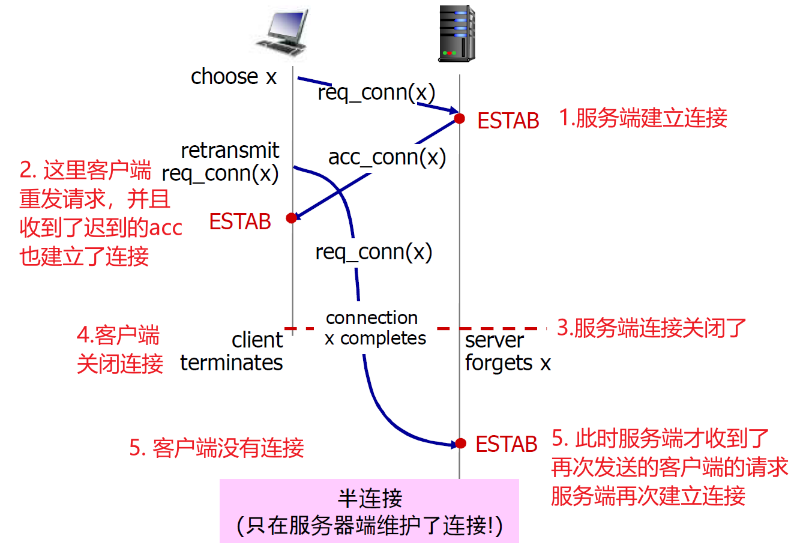
② 接收老数据
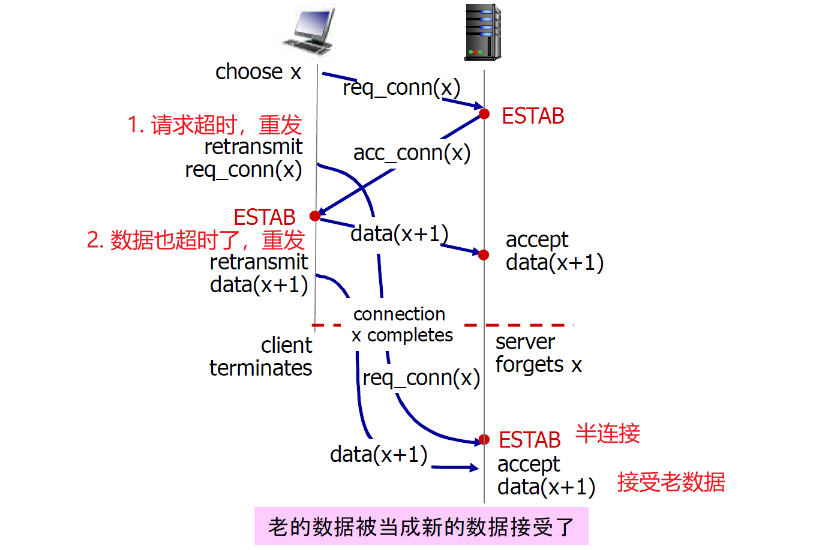
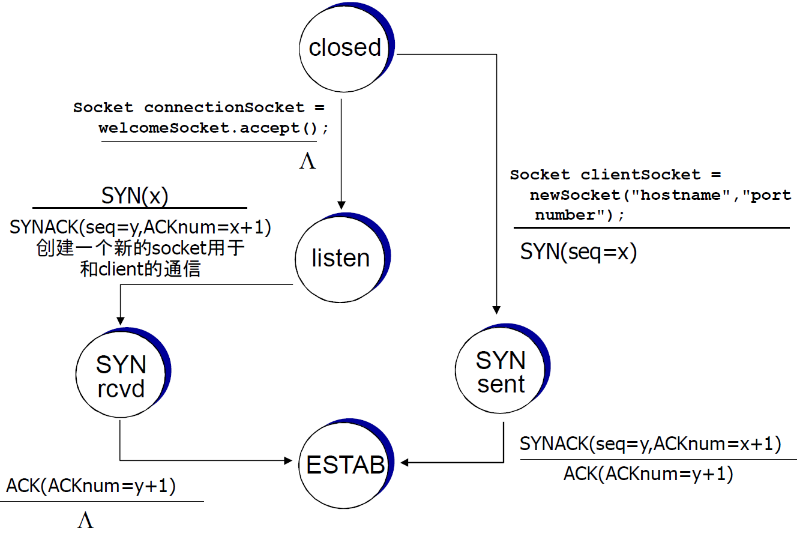
TCP 3次握手
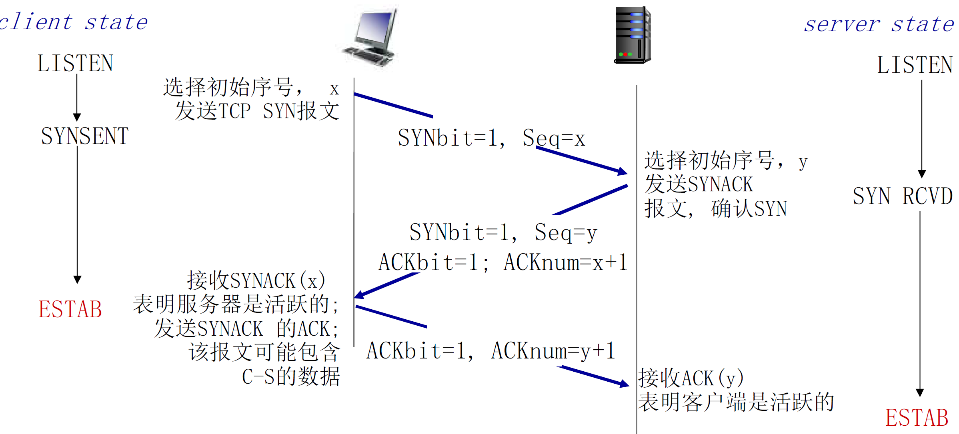
解决方案:变化的初始序号+双方确认对方的序号(3次握手)
(3) 三次握手
来回顾一下TCP的报文段
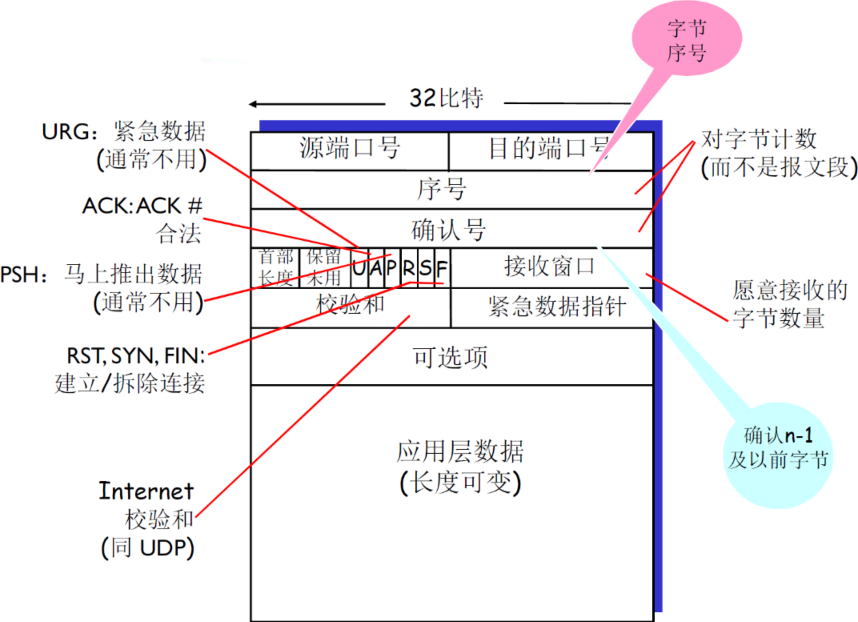
- 其中,SYN=1的时候,表示连接请求
① 流程
解决方案:变化的初始序号+双方确认对方的序号 (3次握手)
建立两个请求实际上应该有两个来回
- C→S:选择初始信号x S→C:ACK=x+1确认初始信号
- S→C:选择初始信号y C→S:ACK=y+1确认初始信号
又由于TCP协议的捎带技术,可以将两个S→C合并起来,因此有三次握手
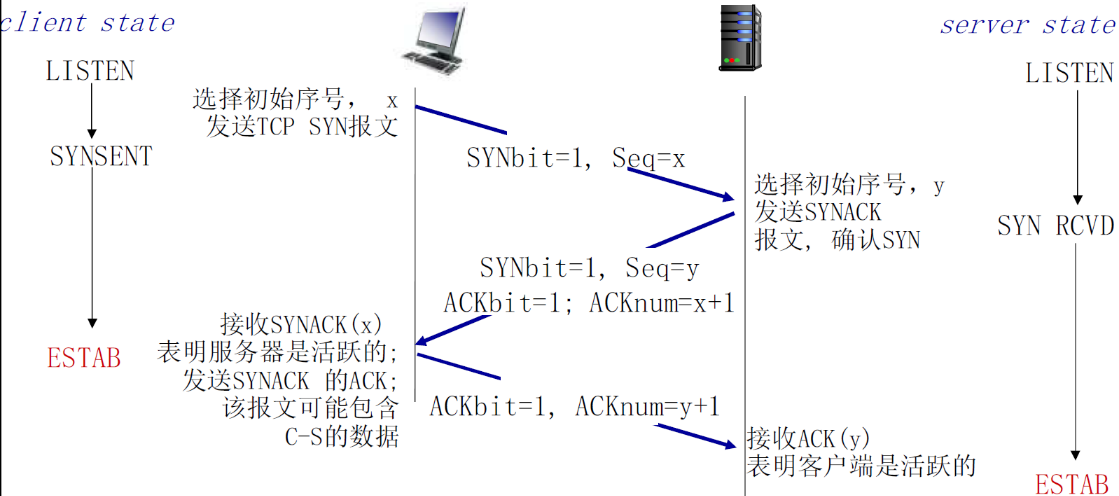
- 第一次:SYNbit + seq
- 第二次:(SYNbit + seq) + (ACKbit + + ACKnum)
- 第三次:ACKbit + ACKnum(+ data)
第三次握手也会捎带将数据传过去的
| 属性 | 说明 |
|---|---|
| SYNbit=1 | 请求建立连接 |
| Seq = x | 建立请求的时候选择初始信号 |
| ACKbit = 1 | 表明该信号是ACK信号 |
| ACKnum = x + 1 | 表示同意Seq=x的请求 |
② 解决二次握手问题
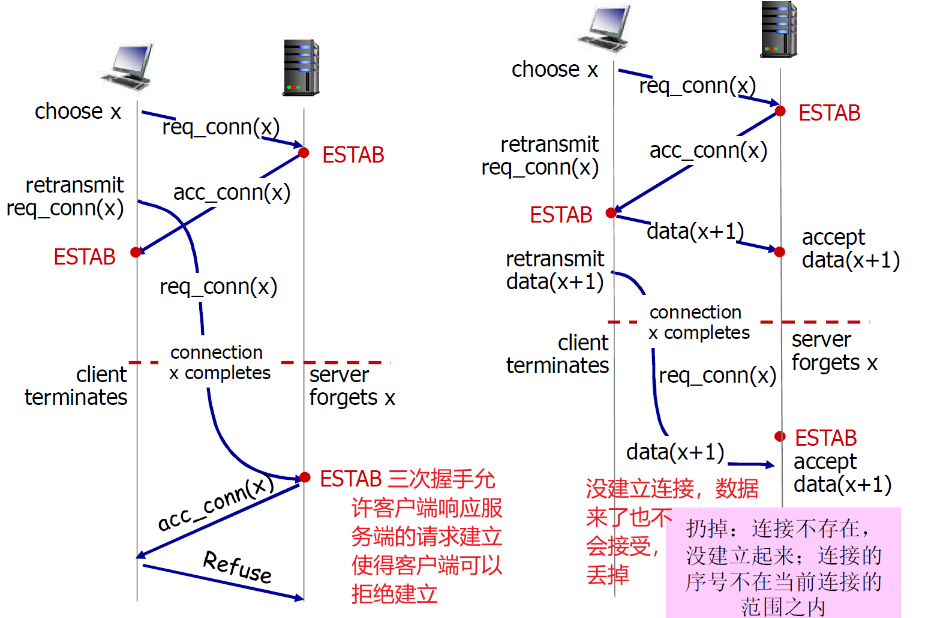
这里第三次握手的时候顺带穿了数据
当然还有一种可能
- 上图中的data(x+1)并没有传给server,而是滞留在网络中
- 然后client和server再次建立了请求之后,data(x+1)才发送到了server,data(x+1)会被看做新数据
- 此时,初始信号就起作用了,server发现data(x+1)与本次连接的初始信号不匹配,就不会接受
初始信号的选择,可能选择当前时钟的前32位(seq与时钟有关),可能会重复,但是概率极低
③ FSM
(4) TCP关闭连接
分为两段:
-
A→B请求拆除,B→A同意拆除
此时B→A的还能进行数据通信
-
B→A请求拆除,A→B同意拆除
- TCP的连接拆除并不完美,可能存在一方拆除,另一方不拆除
- 客户端,服务器分别关闭它自己这一侧的连接
- 发送FIN bit = 1的TCP段
- 一旦接收到FIN,用ACK回应
- 接到FIN段,ACK可以和它自己发出的FIN段一起发 送
- 可以处理同时的FIN交换
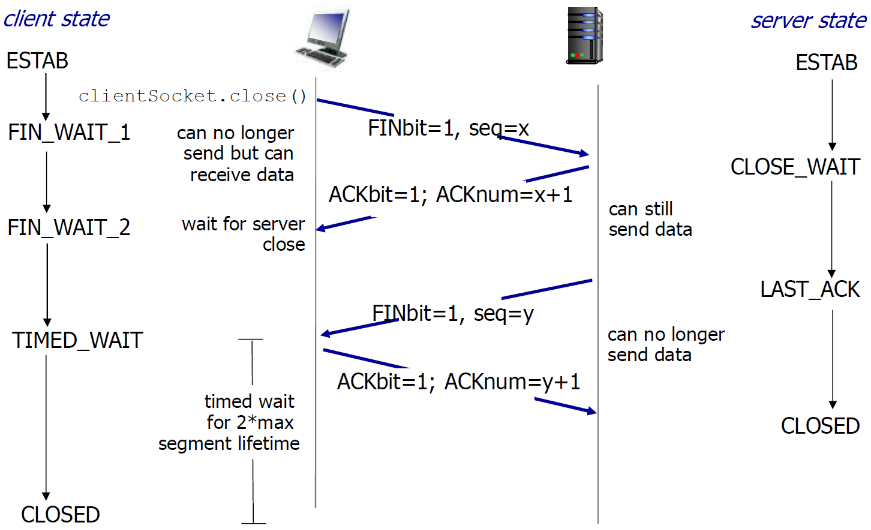
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
3.6.8 TCP拥塞控制
网络辅助的拥塞控制 缺点:数据交换节点的压力比较大,得评估压力和速率,置位等
因此TCP采用端到端的拥塞控制(上述的ATM采用网络辅助的拥塞控制)
(1) 概述
端到端的拥塞控制机制
- 路由器不向主机有关拥塞的反馈信息
- 路由器的负担较轻
- 符合网络核心简单的 TCP/IP架构原则(网络核心只提供最基础的服务,复制的服务由边缘完成)
- 端系统根据自身得到的信息 ,判断是否发生拥塞,从而 采取动作
拥塞控制的几个问题
- 如何检测拥塞
- 轻微拥塞
- 拥塞
- 控制策略
- 在拥塞发送时如何动 作,降低速率
- 轻微拥塞,如何降低
- 拥塞时,如何降低
- 在拥塞缓解时如何动 作,增加速率
- 在拥塞发送时如何动 作,降低速率
以下重点讲解这几个问题
(2) TCP拥塞感知
发送端如何探测到拥塞?
① 感知拥塞
感知拥塞
某个段超时了(丢失事件 ):拥塞
- 超时时间到,某个段的确认没有来
- 原因1:网络拥塞(某个路由器缓冲区没空间了,被丢弃)概率大
- 原因2:出错被丢弃了(各级错误,没有通过校验,被丢弃)概率小
- 一旦超时,就认为拥塞了,有一定误判,但是总体控制方向是对的
② 感知轻微拥塞
感知轻微拥塞
有关某个段的3次重复ACK:轻微拥塞
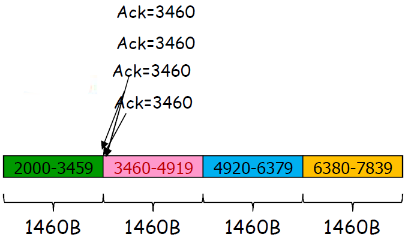
- 段的第1个ack,正常,确认绿段,期待红段
- 段的第2个重复ack,意味着红段的后一段收到了,蓝段乱序到达
- 段的第2、3、4个ack重复,意味着红段的后第2、3、4个段收到了 ,橙段乱序到达,同时红段丢失的可能性很大(后面3个段都到了, 红段都没到)
- 网络这时还能够进行一定程度的传输,拥塞但情况要比上面好
(3) 发送速度控制策略
当感受到拥塞/轻微拥塞之后,如何控制侧罗
① 控制发送端的发送速率
如何控制发送端发送的速率
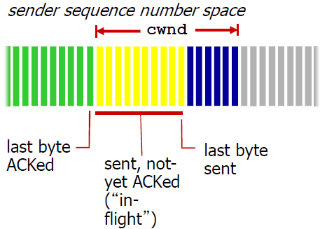
- 维持一个拥塞窗口的值(主要手段) :CongWin (表示发送方往网络中的注入字节数)
- 发送端限制 已发送但是未确认 的数据量(的上限):
LastByteSent - LastByteAcked ≤ CongWin - 从而粗略地控制发送方的往网络中注入的速率
② 发送速度控制策略
如何根据感知到的 拥塞/轻微拥塞 来调整发送端的发送速率
首先回顾几个概念
- MSS:TCP报文打包的数据的字节的数量
- SS(slow-start,慢增长)阶段:加倍增加(每个RTT) ,即每个RTT加倍
- CA(congestion-avoidance,拥塞控制)阶段:线性增加(每个RTT),即每个RTT加一个MSS
CongWin是动态的,是感知到的网络拥塞程度的函数
- 超时或者3个重复ack,CongWin下降
- 超时时:CongWin降为1MSS,进入SS阶段然后再倍增到 CongWin(原) / 2(每个RTT),从而进入CA阶段
- 3个重复ack :CongWin降为CongWin/2,CA阶段
- 否则(正常收到Ack,没有发送以上情况):CongWin跃跃欲试上升(这是为了满足“在不发生拥塞的情况下提高吞吐率”的目的)
(4) TCP拥塞控制和流量控制的联合动作
联合控制的方法:
- 发送端控制发送但是未确认的量同时也不能够超过接收 窗口,满足流量控制要求
SendWin = min { CongWin , RecvWin }- 同时满足 拥塞控制和流量控制要求
- SendWin是实际的发送量
- CongWin是拥塞控制的字节数,是由拥塞控制机制调整的
- RecvWin是流量控制的字节数,是由接收方根据接收窗口可以接受的数量,通过TCP的首部返回给发送端的
(5) TCP拥塞控制策略
- 慢启动
- AIMD:线性增、乘性减少
- 超时事件后的保守策略
① 慢启动
连接刚建立, CongWin = 1 MSS
- 如: MSS = 1460bytes & RTT = 200 msec
- 初始速率 = 58.4kbps
可用带宽可能 >> MSS/RTT
- 应该尽快加速,到达希望的速率
因此慢启动开时候,成倍数增加
- 当连接开始时,指数性增加发送速率,直到发生丢失的事件
- 特点
- 启动初值很低
- 但是速度很快
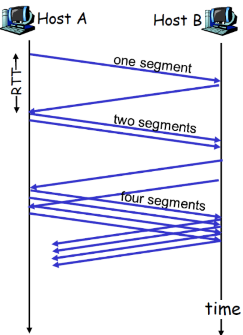
当连接开始时,指数性增 加(每个RTT)发送速率 直到发生丢失事件
- 每一个RTT, CongWin加倍
- 每收到一个ACK时, CongWin加1(相当于每个RTT,CongWin加倍)
- 慢启动阶段:只要不超时或 3个重复ack,一个RTT, CongWin加倍
总结:
- 初始速率很慢,但是加速却是指数性的
- 指数增加,SS时间很短,长期来看可以忽略
② AIMD
- 乘性减: 丢失事件后将CongWin降为1(ss阶段通常可忽略,故相当于直接减少到 CongWin/2 ),将CongWin/2作为阈值,进入慢启动阶段(倍增直到 CongWin/2)
- 加性增: 当 CongWin >阈值时,一个 RTT 如没有发生丢失事件,将 CongWin 加1MSS : 探测(也就是主键添加,探测是否到达阈值)
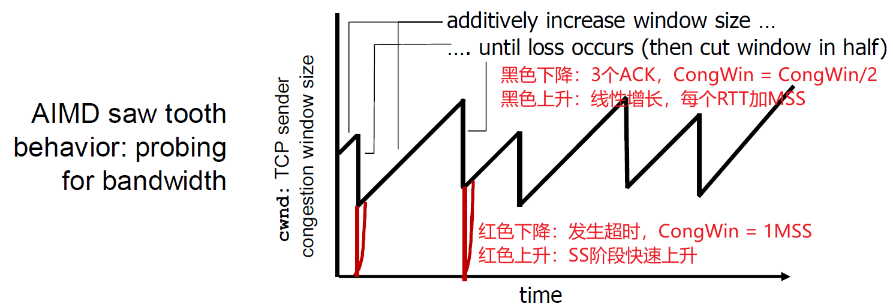
-
当收到3个重复的ACKs:
-
CongWin 减半
-
窗口(缓冲区大小)之后 线性增长
-
-
当超时事件发生时:
-
CongWin被设置成 1 MSS,进入SS阶段
-
之后窗口指数增长
-
增长到一个阈值(上次发 生拥塞的窗口的一半)时 ,再线性增加
-
- 3个重复的ACK表示网络还有一定的段传输能力
- 超时之前的3个重复的ACK表示“警报”
③ 改进
- Q:什么时候应该将指数性增长变成线性?
- A:在超时之前,当CongWin变成上次发生超时的窗口的一半
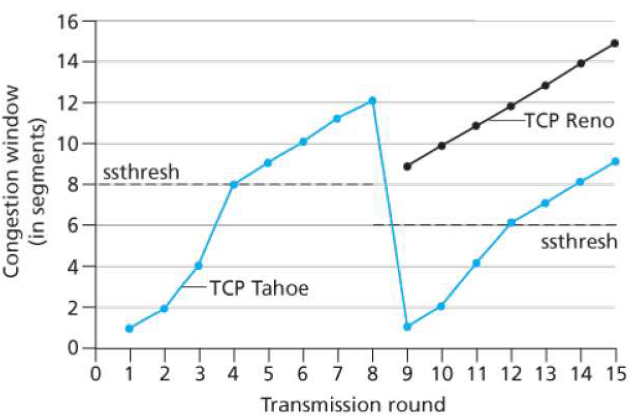
实现:
- 变量:Threshold
- 出现丢失(超时或者3个ACK),Threshold设置成CongWin的1/2
- 就是阈值随着上次下降的时候也在不断改变
出现丢失,Threshold(阈值)设置成 CongWin的1/2
-
当CongWin<Threshold, 发送端处于慢启动阶段( slow-start), 窗口指数性增长.
-
当CongWin > Threshold, 发送端处于拥塞避免阶段 (congestion-avoidance), 窗口线性增长.
-
当收到三个重复的ACKs (triple duplicate ACK), Threshold设置成 CongWin/2, CongWin=Threshold+3.
-
当超时事件发生时timeout, Threshold=CongWin/2 CongWin=1 MSS,进入SS阶段
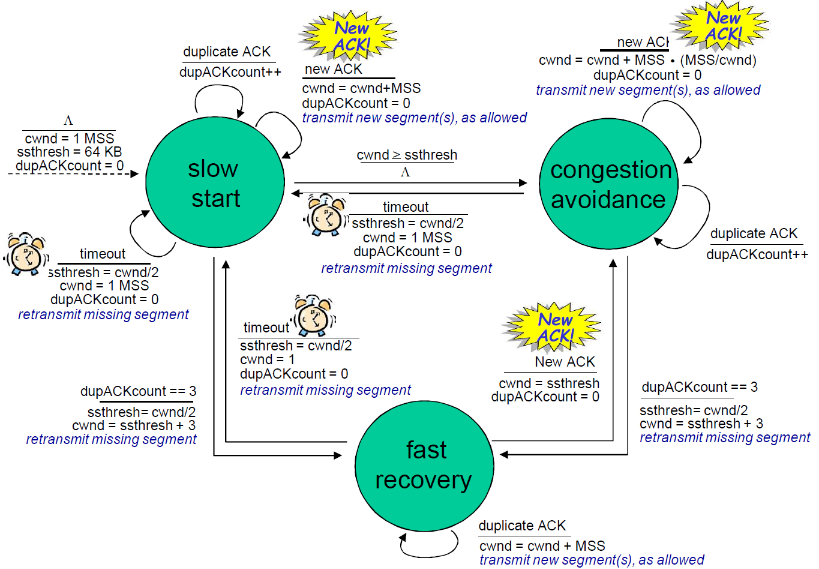
(6) TCP发送端拥塞控制
① 状态转换
| 事件 | 状态 | TCP发送端行为 | 解释 |
|---|---|---|---|
| 以前没有收到ACK的data,被ACKed | 慢启动(SS) | CongWin = CongWin + MSS If (CongWin > Threshold) 状态变成“CA” |
每一个RTT CongWin 加倍 |
| 以前没有收到ACK的data,被ACKed | 拥塞避免(CA) | CongWin = CongWin+MSS * (MSS/CongWin) | 线性增加, 每一个RTT对CongWin 加一个1 MSS |
| 通过收到3个重复的ACK,发现丢失的事件 | SS or CA | Threshold = CongWin/2, CongWin = Threshold+3, 状态变成“CA” | 快速重传, 实现乘性的减,CongWin 没有变成1MSS. |
| 超时 | SS or CA | Threshold = CongWin/2,CongWin = 1 MSS,状态变成“SS” | 进入slow start |
| 重复的ACK | SS or CA | 对被ACKed 的segment, 增加重复ACK的计数 | CongWin and Threshold不变 |
② FSM
(7) 拥塞控制决定的TCP吞吐量
TCP的平均吞吐量是多少,使用窗口window尺寸W和RTT来 描述?
(忽略慢启动阶段,假设发送端总有数据传输)
W:发生丢失事件时的窗口尺寸(单位:字节)
- 平均窗口尺寸(#in-flight字节):3/4W
- 平均吞吐量:一个RTT时间吞吐3/4W, avg TCP thruput = 3/4 * (W/RTT) bytes/sec
由下图所示,w/2→w所需要的时间是2RTT
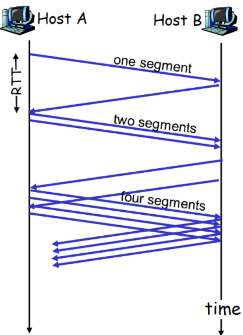
因此 T = (w/2 + w) / (2*RTT) = 3w/4RTT
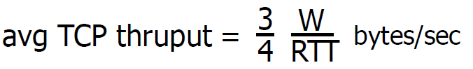
(8) TCP公平性
TCP的拥塞控制策略能够使同一条链路上的多个TCP连接享有公平性(这里只是TCP连接,并是不主机与主机间,因为主机之间可以有多个TCP连接)
公平性目标: 如果 K个TCP会话分享一个链路带宽为R的 瓶颈,每一个会话的有效带宽为 R/K
2个竞争的TCP会话:
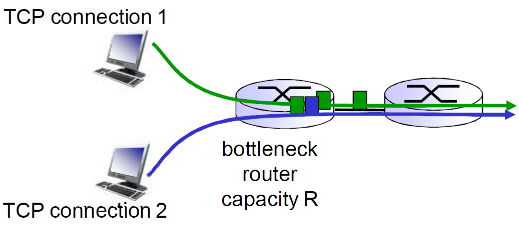
原理如下
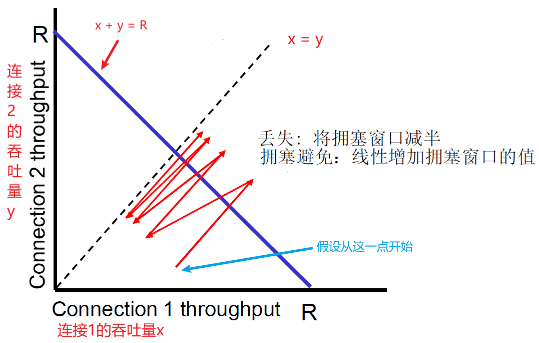
- 假设处开始时,x > y,连接1的吞吐量 > 连接2
- 然后加性增加,斜率为1, 吞吐量增加(x和y都+1MSS,所以斜率为1)
- 当超出边界之后,发生了丢失,乘性减,吞吐量比例减少(此时x超出了,要乘性减)
- 总之最后一直趋近到了 x = y
但是TCP的公平性只是相对的,并不是绝对的
-
公平性和 UDP
- 多媒体应用通常不是用 TCP
- 应用发送的数据速率希望 不受拥塞控制的节制
- 使用UDP:
- 音视频应用泵出数据的速率是恒定的, 忽略数据的丢失
也就是UDP会抢占TCP的资源
- 多媒体应用通常不是用 TCP
-
公平性和并行TCP连接
- 2个主机间可以打开多个并行的TCP连接
- 例如: 带宽为R的链路支持了 9个连接;
- 如果新的应用要求建1个TCP连接,获得带宽R/10
- 如果新的应用要求建11个TCP连接,获得带宽R/2
3.6.9 TCP未来

第三章 总结
-
传输层提供的服务
- 应用进程间的逻辑通信
- Vs 网络层提供的是主机到主机的通信服务
- 互联网上传输层协议:UDP TCP
- 特性
- 应用进程间的逻辑通信
-
多路复用和解复用
- 端口:传输层的SAP
- 无连接的多路复用和解复用
- 面向连接的多路复用和解复用
-
实例1:无连接传输层协议 UDP
- 多路复用解复用
- UDP报文格式
- 检错机制:校验和
-
可靠数据传输原理
- 问题描述
- 停止等待协议
- Rdt1.0 rdt2.0,2.1 ,2.2 Rdt 3.0
- 流水线协议
- GBN
- SR(Selective Repeat)
-
实例2:面向连接的 传输层协议-TCP
- 概述:TCP特性
- 报文段格式
- 序号,超时机制及时间
- TCP可靠传输机制
- 重传,快速重传
- 流量控制
- 连接管理
- 三次握手
- 对称连接释放
- 拥塞控制原理
- 网络辅助的拥塞控制
- 端到端的拥塞控制
- TCP的拥塞控制
- AIMD
- 慢启动
- 超时之后的保守策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号