深入理解Spring注解机制(一):注解的搜索与处理机制
前言
众所周知,spring 从 2.5 版本以后开始支持使用注解代替繁琐的 xml 配置,到了 springboot 更是全面拥抱了注解式配置。平时在使用的时候,点开一些常见的等注解,会发现往往在一个注解上总会出现一些其他的注解,比如 @Service:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component // @Component
public @interface Service {
@AliasFor(annotation = Component.class)
String value() default "";
}
大部分情况下,我们可以将 @Service 注解等同于 @Component 注解使用,则是因为 spring 基于其 JDK 对元注解的机制进行了扩展。
在 java 中,元注解是指可以注解在其他注解上的注解,spring 中通过对这个机制进行了扩展,实现了一些原生 JDK 不支持的功能,比如允许在注解中让两个属性互为别名,或者将一个带有元注解的子注解直接作为元注解看待,或者在这个基础上,通过 @AliasFor 或者同名策略让子注解的值覆盖元注解的值。
本文将基于 spring 源码 5.2.x 分支,解析 spring 如何实现这套功能的。
这是系列的第一篇文章,将详细介绍 Spring 是如何从 AnnotatedElement 的层级结构中完成对注解的搜索与处理的。
相关文章:
一、层级结构
当我们点开 Spring 提供两个注解工具类 AnnotationUtils 或者 AnnotatedElementUtils 时,我们可以从类注释上了解到,Spring 支持 find 和 get 开头的两类方法:
get:指从AnnotatedElement上寻找直接声明的注解;find:指从AnnotatedElement的层级结构(类或方法)上寻找存在的注解;
大部分情况下,get 开头的方法与 AnnotatedElement 本身直接提供的方法效果一致,比较特殊的 find 开头的方法,此类方法会从AnnotatedElement 的层级结构中寻找存在的注解,关于“层级结构”,Spring 给出了一套定义:
- 当
AnnotatedElement是Class时:层级结构指类本身,以及类和它的父类,父接口,以及父类的父类,父类的父接口......整个继承树中的所有Class文件; - 当
AnnotatedElement是Method是:层级结构指方法本身,以及声明该方法的类它的父类,父接口,以及父类的父类,父类的父接口......整个继承树中所有Class文件中,那些与搜索的Method具有完全相同签名的方法; - 当
AnnotatedElement不是上述两者中的一种时,它没有层级结构,搜索将仅限于AnnotatedElement这个对象本身;
举个例子,假设我们现在有如下结构:
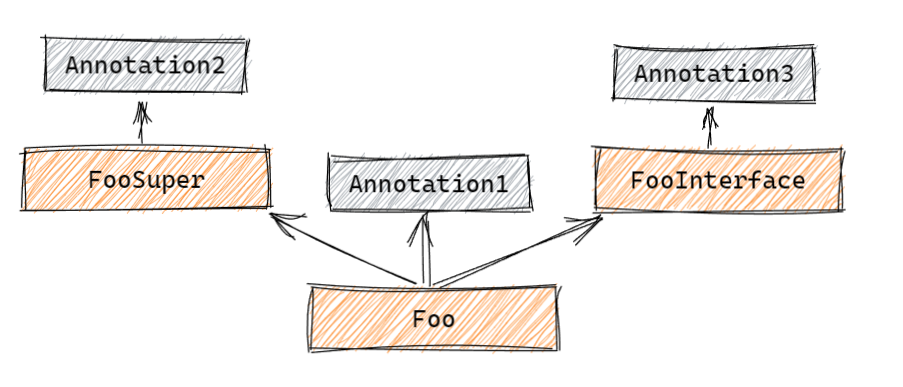
则对 Foo.class 使用 get 开头的方法,或者 AnnotatedElement 本身提供的方法,都只能获得 Annotation1,而使用 find 方法除了可以获得 Foo 本身的注解,还可以获得 FooSuper 和 FooInterface 上的注解。
同理,假如我们扫描的是 Foo.class 中一个名为 foo,没有参数且没有返回值的方法,则 find 除了扫描 Foo.foo() 外,还会扫描器 FooSuper 和 FooInterface 中没有参数且没有返回值的方法上的注解。
二、合并注解
当我们点进 AnnotationUtil 中的任意一个方法,比如 findAnnotation :
public static <A extends Annotation> A findAnnotation(Method method, @Nullable Class<A> annotationType) {
if (annotationType == null) {
return null;
}
// 如果不需要对层级结构进行搜索也能找到注解
if (AnnotationFilter.PLAIN.matches(annotationType) ||
AnnotationsScanner.hasPlainJavaAnnotationsOnly(method)) {
return method.getDeclaredAnnotation(annotationType);
}
// 注解无法直接获取,需要对层级结构进行搜索
return MergedAnnotations.from(method, SearchStrategy.TYPE_HIERARCHY, RepeatableContainers.none())
.get(annotationType).withNonMergedAttributes()
.synthesize(MergedAnnotation::isPresent).orElse(null);
}
这个方法很清晰的描述了一个注解的查找流程:
- 先对
AnnotatedElement本身进行查找,并且使用注解过滤器AnnotationFilter进行处理; - 找不到再通过一个叫
MergedAnnotations的东西对AnnotatedElement进行查找,这玩意需要指定三个东西:- 查找的
AnnotatedElement; - 搜索策略
SearchStrategy; - 可重复注解容器
RepeatableContainers;
- 查找的
可见,真正的搜索过程发生在合并注解 MergedAnnotations。
1、注解过滤器
其中,AnnotationFilter 是我们见到的第一个组件。该类是一个函数式接口,用于匹配传入的注解实例、类型或名称。
@FunctionalInterface
public interface AnnotationFilter {
// 根据实例匹配
default boolean matches(Annotation annotation) {
return matches(annotation.annotationType());
}
// 根据类型匹配
default boolean matches(Class<?> type) {
return matches(type.getName());
}
// 根据名称匹配
boolean matches(String typeName);
}
AnnotationFilter默认提供三个可选的静态实例:
PLAIN:类是否属于java.lang、org.springframework.lang包;JAVA:类是否属于java、javax包;ALL:任何类;
此处过滤器选择了 PLAIN,即当查找的注解属于 java.lang、org.springframework.lang 包的时候就不进行查找,而是直接从被查找的元素直接声明的注解中获取。这个选择不难理解,java.lang包下提供的都是诸如@Resource或者 @Target 这样的注解,而springframework.lang包下提供的则都是 @Nonnull 这样的注解,这些注解基本不可能作为有特殊业务意义的元注解使用,因此默认忽略也是合理的。
实际上,PLAIN 也是大部分情况下的使用的默认过滤器。
2、合并注解
当对 AnnotatedElement 直接搜索无法获得符合条件的注解时,Spring 就会尝试通过 MergedAnnotations 对层级结构进行搜索,并对获得的注解进行聚合。在这个过程中,被聚合的注解就会被封装为 MergedAnnotation,而结束搜索后,获得的全部 MergedAnnotation 又会被聚合为 MergedAnnotations。
MergedAnnotation
MergedAnnotation 直译叫合并注解,MergedAnnotation 通常与一个注解对象一对一,但是它的属性可能来自于子注解或者元注解,甚至是同一个注解中通过 @AliasFor 绑定其他属性,因此称为“合并”注解——这里的合并指的是属性上的合并。
MergedAnnotations
而 MergedAnnotations 则用于提供一个基于 AnnotatedElement 快速扫描并创建一组 MergedAnnotation 的功能,在 AnnotationUtils.findAnnotation 中,使用了 MergedAnnotations.from 方法创建一个 TypeMappedAnnotations 实现类:
static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy,
RepeatableContainers repeatableContainers) {
// 3、过滤属于`java`、`javax`或者`org.springframework.lang`包的注解
return from(element, searchStrategy, repeatableContainers, AnnotationFilter.PLAIN);
}
static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy,
RepeatableContainers repeatableContainers, AnnotationFilter annotationFilter) {
Assert.notNull(repeatableContainers, "RepeatableContainers must not be null");
Assert.notNull(annotationFilter, "AnnotationFilter must not be null");
return TypeMappedAnnotations.from(element, searchStrategy, repeatableContainers, annotationFilter);
}
具体细节我们我们先不看,光看最后调用的方法,我们知道 MergedAnnotations 的创建需要四样东西:
- 查找的
AnnotatedElement; - 搜索策略
SearchStrategy; - 可重复注解容器
RepeatableContainers; - 注解过滤器
AnnotationFilter;
二、注解的搜索
当 MergedAnnotations 被创建后,并不会立刻就触发对 AnnotatedElement 的搜索,而是等到调用 MergedAnnotations.get 时才开始,我们以 TypeMappedAnnotations 为例:
public <A extends Annotation> MergedAnnotation<A> get(Class<A> annotationType,
@Nullable Predicate<? super MergedAnnotation<A>> predicate,
@Nullable MergedAnnotationSelector<A> selector) {
// 如果查找的注解类型直接通不过过滤器,就没必要继续搜索了
if (this.annotationFilter.matches(annotationType)) {
return MergedAnnotation.missing();
}
// 使用AnnotationScanner对元素层级结构进行查找
MergedAnnotation<A> result = scan(annotationType,
new MergedAnnotationFinder<>(annotationType, predicate, selector));
return (result != null ? result : MergedAnnotation.missing());
}
再点开 TypeMappedAnnotations.scan 方法,我们会发现它通过创建时指定的 SearchStrategy,去使用 AnnotationScanner 对元素进行搜索:
private <C, R> R scan(C criteria, AnnotationsProcessor<C, R> processor) {
if (this.annotations != null) {
R result = processor.doWithAnnotations(criteria, 0, this.source, this.annotations);
return processor.finish(result);
}
if (this.element != null && this.searchStrategy != null) {
return AnnotationsScanner.scan(criteria, this.element, this.searchStrategy, processor);
}
return null;
}
AnnotationScanner 是 Spring 注解包使用的一个内部类,它根据 SearchStrategy 指定的搜索策略对 AnnotatedElement 的层级结构进行搜索,并且使用 AnnotationsProcessor 在获得注解后进行回调。
1、搜索策略
其中,SearchStrategy 提供了五种搜索范围:
-
DIRECT:只查找元素上直接声明的注解,不包括通过@Inherited继承的注解; -
INHERITED_ANNOTATIONS:只查找元素直接声明或通过@Inherited继承的注解; -
SUPERCLASS:查找元素直接声明或所有父类的注解; -
TYPE_HIERARCHY:查找元素、所有父类以及实现的父接口的全部注解; -
TYPE_HIERARCHY_AND_ENCLOSING_CLASSES:查找查找元素、所有父类以及实现的父接口、封闭类以及其子类的全部注解。封闭类是 JDK17 的新特性,可参考 详解 Java 17中的新特性:“密封类”,本章将不过多涉及该内容;
2、注解扫描器
AnnotationScanner 扫描扫描行为的直接发起者,它只提供了唯一允许外部调用的静态方法 scan :
static <C, R> R scan(C context, AnnotatedElement source, SearchStrategy searchStrategy,
AnnotationsProcessor<C, R> processor) {
R result = process(context, source, searchStrategy, processor);
return processor.finish(result);
}
private static <C, R> R process(C context, AnnotatedElement source,
SearchStrategy searchStrategy, AnnotationsProcessor<C, R> processor) {
if (source instanceof Class) {
return processClass(context, (Class<?>) source, searchStrategy, processor);
}
if (source instanceof Method) {
return processMethod(context, (Method) source, searchStrategy, processor);
}
return processElement(context, source, processor);
}
扫描器从层级结构中的 AnnotatedElement 获得注解后,会调用 AnnotationsProcessor 对注解对象进行处理。
这里根据 AnnotatedElement 类型的不同,又区分 Method、Class 以及其他 AnnotatedElement ,这三种对象会有不同的扫描方式。 AnnotationScanner 对这三者的扫描方式大同小异,基本都是没层级结构就直接返回,有层级结构就通过反射遍历按深度优先扫描层级结构。
不过需要重点关注一下对方法的扫描,Spring 针对方法的扫描制定了比较严格的标准,假设扫描的原始方法称为 A,则被扫描的方法 B,要允许获得 B 上的注解 ,则必须满足如下规则:
B不能是桥接方法;A不能是私有方法;A和B的名称、参数类型、数量皆必须相等 ==>hasSameParameterTypes/isOverride;- 若
A和B参数有泛型,则要求泛型也一致 ==>hasSameGenericTypeParameters();
3、注解处理器
AnnotationsProcessor 的本体是一个用于函数式接口:
interface AnnotationsProcessor<C, R> {
@Nullable
default R doWithAggregate(C context, int aggregateIndex) {
return null;
}
// 扫描后的回调,返回的对象将用于下一次扫描,当返回为空时中断扫描
@Nullable
R doWithAnnotations(C context, int aggregateIndex, @Nullable Object source, Annotation[] annotations);
@Nullable
default R finish(@Nullable R result) {
return result;
}
}
当扫描到元素后,AnnotationScanner 会获得该元素上的注解,将其与元素一起作为入参传入 doWithAnnotations,若 doWithAnnotations 返回了一个非空元素,则 AnnotationScanner 将继续扫描元素的层级结构,然后直到doWithAnnotations 返回 null 为止或者全部层级结构都被扫描为止。
注解处理器是实现各种查找和收集等操作最核心的部分,这里我们先简单了解一下,知道它是个配合 AnnotationScanner 使用的回调接口即可。
4、聚合索引
在 AnnotationsProcessor 中, doWithAggregate 和 doWithAnnotations 都会传入一个名为 aggregateIndex 的参数,该参数用于扫描过程中扫描的层级数,通过该参数,我们可以区分注解之间被扫描到的先后顺序。
比如说,我们现在还是有一个如下结构:
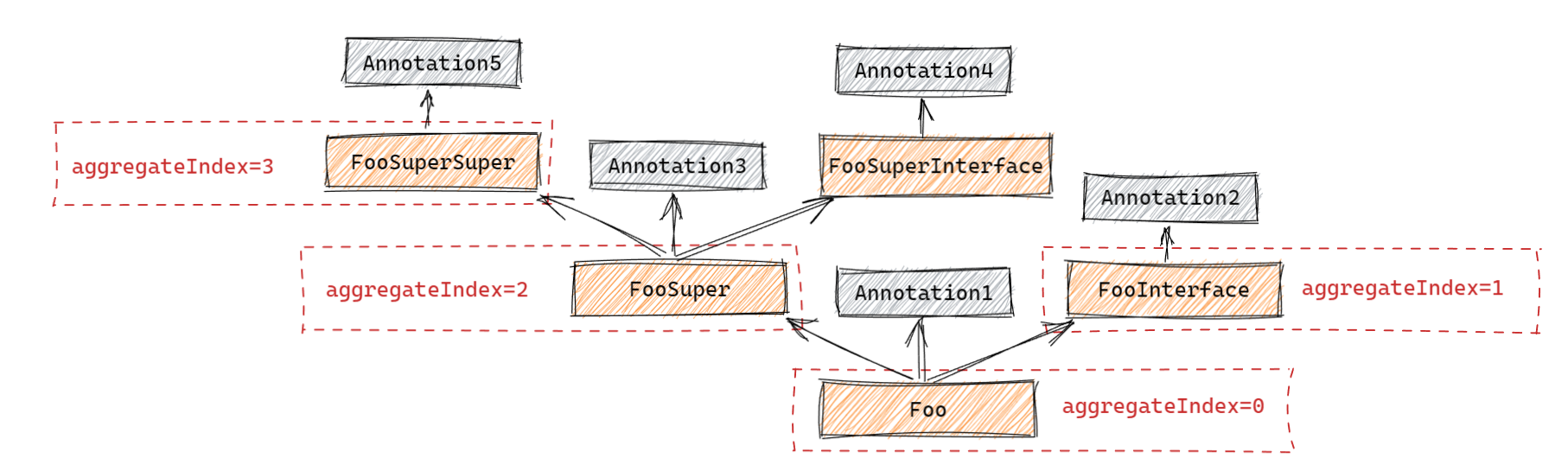
AnnotationScanner 在扫描时,以 0 为起始值,每进入一个层级就递增,现在我们对 Foo.class 进行扫描,则有:
-
aggregateIndex= 0,扫描
Foo.class,获得Annotation1; -
aggregateIndex= 1,扫描
FooInterface.class,获得Annotation2; -
aggregateIndex= 2,扫描
FooSuper.class,获得Annotation3; -
aggregateIndex= 4:
先扫描
FooSuperInterface.class,获得Annotation4,再扫描
FooSuperSuper.class,获得Annotation5;
从理论上来说,聚合索引越小,则该注解最优先被扫描到。因此聚合索引一般用于在出现重复注解的时候用来区分优先级,比如层级结构中出现了多个类型相同的注解,而用户仅需要获得其中一个,此时就可以通过比较聚合索引,返回其中最小或者最大的那个注解。后续我们还会看到一个叫 AnnotationSelector 的玩意,它就是用来做这个事情的。
三、注解的处理
注解处理器 AnnotationsProcessor 的实现类是完成注解操作最核心的部分,前面提到 AnnotationScanner 负责提供注解扫描的功能,但是扫描到注解以后要怎么处理?是否继续扫描后续注解?这些都取决于使用的 AnnotationsProcessor 规定要怎么做。
在 TypeMappedAnnotations 中,以内部类的形式提供了多数 AnnotationsProcessor 的实现,它们提供类三类功能:
-
TypeMappedAnnotations.IsPresent:判断注解是否直接或间接(即不存在可重复注解,但是存在可重复注解的容器注解这种情况)存在。关于注解的“直接”或“间接”存在,可以参照
AnnotatedElement类上注释的定义; -
TypeMappedAnnotations.MergedAnnotationFinder:用于找到一个唯一的指定类型的注解; -
TypeMappedAnnotations.AggregatesCollector:用于收集全部扫描到的注解;
1、判断注解是否存在
该处理器对应 TypeMappedAnnotations.IsPresent,它用于确定一个注解是否在 AnnotationScanner 支持扫描的范围内存在。
需要注意的是,IsPresent 中支持基于两种“存在”的定义进行查询:
- directly:注解在
AnnotatedElement上直接存在,包括两种情况- 注解 X 在 A 上直接存在;
- 注解 X 是可重复注解,它存在可重复容器注解 Y,现在在类 A 上存在 Y 但是不存在 X,则说 X 在 A 上直接存在;
- Indirectly:注解 X 在
AnnotatedElement上不直接存在,但是在能够扫描到的注解的元注解中存在;
注解处理器
我们直接看看 IsPresent.doWithAnnotations 方法:
public Boolean doWithAnnotations(Object requiredType, int aggregateIndex,
@Nullable Object source, Annotation[] annotations) {
for (Annotation annotation : annotations) {
if (annotation != null) {
Class<? extends Annotation> type = annotation.annotationType();
// 若注解类型不为空,且能通过过滤器校验,则开始判断过程
if (type != null && !this.annotationFilter.matches(type)) {
// 1.该注解类型就是要查找的类型
if (type == requiredType || type.getName().equals(requiredType)) {
return Boolean.TRUE;
}
// 2.该注解不是要查找的类型,但是它是一个容器注解,则将其全部平摊
Annotation[] repeatedAnnotations =
this.repeatableContainers.findRepeatedAnnotations(annotation);
if (repeatedAnnotations != null) {
// 递归判断平摊后的注解是否符合条件
Boolean result = doWithAnnotations(
requiredType, aggregateIndex, source, repeatedAnnotations);
if (result != null) {
return result;
}
}
// 3.如果上述两者情况都不满足,则且并不限制值仅查找直接存在的注解
// 则查找这个注解的元注解,判断其所有元注解是否存在该指定注解
if (!this.directOnly) {
AnnotationTypeMappings mappings = AnnotationTypeMappings.forAnnotationType(type);
for (int i = 0; i < mappings.size(); i++) {
AnnotationTypeMapping mapping = mappings.get(i);
if (isMappingForType(mapping, this.annotationFilter, requiredType)) {
return Boolean.TRUE;
}
}
}
}
}
}
return null;
}
private static boolean isMappingForType(AnnotationTypeMapping mapping,
AnnotationFilter annotationFilter, @Nullable Object requiredType) {
Class<? extends Annotation> actualType = mapping.getAnnotationType();
return (!annotationFilter.matches(actualType) &&
(requiredType == null || actualType == requiredType || actualType.getName().equals(requiredType)));
}
这个方法依次进行三次判断:
- 当前注解是否就是要找的注解?
- 当前注解如果是个可从重复注解的容器注解,则将其内部的可重复注解全部取出平摊后,是否存在要找的注解?
- 如果当不限制只查找注解本身,则继续搜索它的所有元注解,这些元注解是否存在要找的注解?
只要这三个条件任意一个满足,则就会认为该注解在 AnnotationScanner 的扫描范围内存在。
AnnotationTypeMappings
这里引入了一个新类 AnnotationTypeMappings,它是一组 AnnotationTypeMapping 的聚合。
后续讲解属性映射与合并注解的合成的时候会具体介绍这两者,现在先简单的认为一个注解对应一个 AnnotationTypeMapping,而一个注解与它的元注解的聚合对应一个 AnnotationTypeMappings 即可。
可重复容器
此处第一次用到的可重复注解容器 RepeatableContainers,这个它表示一个可以容纳可重复注解的容器注解与该可重复注解的嵌套关系,比如我们现在 a -> b -> c 的套娃关系,则通过 RepeatableContainers 注解,我们可以直接通过它从将 c 转成 b,然后再把 b 转成 a,这就是上文所说的“平摊”过程。
2、收集注解
TypeMappedAnnotations.AggregatesCollector 用于收集 AnnotationScanner 扫描到的注解。
我们关注其 doWithAnnotations 方法的实现:
@Override
@Nullable
public List<Aggregate> doWithAnnotations(Object criteria, int aggregateIndex,
@Nullable Object source, Annotation[] annotations) {
// 创建一个Aggregate
this.aggregates.add(createAggregate(aggregateIndex, source, annotations));
return null;
}
private Aggregate createAggregate(int aggregateIndex, @Nullable Object source, Annotation[] annotations) {
List<Annotation> aggregateAnnotations = getAggregateAnnotations(annotations);
return new Aggregate(aggregateIndex, source, aggregateAnnotations);
}
private List<Annotation> getAggregateAnnotations(Annotation[] annotations) {
List<Annotation> result = new ArrayList<>(annotations.length);
addAggregateAnnotations(result, annotations);
return result;
}
private void addAggregateAnnotations(List<Annotation> aggregateAnnotations, Annotation[] annotations) {
for (Annotation annotation : annotations) {
if (annotation != null && !annotationFilter.matches(annotation)) {
// 若是容器注解就全部摊平
Annotation[] repeatedAnnotations = repeatableContainers.findRepeatedAnnotations(annotation);
if (repeatedAnnotations != null) {
addAggregateAnnotations(aggregateAnnotations, repeatedAnnotations);
}
else {
// 收集该注解
aggregateAnnotations.add(annotation);
}
}
}
}
这段方法跳了好多层,不过基本流程还是很清晰的,即获取扫描到的注解数组,然后再把数组中那些容器注解摊平,全部处理完以后封装为一个 Aggregate 对象。
Aggregate
Aggregate 也是 TypeMappedAnnotations 的内部类,它的代码和功能一样简单:
- 接受一组注解数组
annotations; - 遍历注解数组,解析这些注解的元注解,并将其与解析得到的元注解转为
AnnotationTypeMappings; - 把
AnnotationTypeMappings放到对应的源注解在annotations中的下标的位置;
private static class Aggregate {
private final int aggregateIndex;
@Nullable
private final Object source;
private final List<Annotation> annotations;
private final AnnotationTypeMappings[] mappings;
Aggregate(int aggregateIndex, @Nullable Object source, List<Annotation> annotations) {
this.aggregateIndex = aggregateIndex;
this.source = source;
this.annotations = annotations;
this.mappings = new AnnotationTypeMappings[annotations.size()];
for (int i = 0; i < annotations.size(); i++) {
this.mappings[i] = AnnotationTypeMappings.forAnnotationType(annotations.get(i).annotationType());
}
}
int size() {
return this.annotations.size();
}
@Nullable
AnnotationTypeMapping getMapping(int annotationIndex, int mappingIndex) {
AnnotationTypeMappings mappings = getMappings(annotationIndex);
return (mappingIndex < mappings.size() ? mappings.get(mappingIndex) : null);
}
AnnotationTypeMappings getMappings(int annotationIndex) {
return this.mappings[annotationIndex];
}
@Nullable
<A extends Annotation> MergedAnnotation<A> createMergedAnnotationIfPossible(
int annotationIndex, int mappingIndex, IntrospectionFailureLogger logger) {
return TypeMappedAnnotation.createIfPossible(
this.mappings[annotationIndex].get(mappingIndex), this.source,
this.annotations.get(annotationIndex), this.aggregateIndex, logger);
}
}
简而言之,通过 AggregatesCollector + Aggregate,我们最终就可以得到:
- 所有
AnnotationScanner扫描到的注解; - 所有
AnnotationScanner扫描到的注解中的容器注解摊平后的可重复注解; - 上述注解的元注解;
可谓应有尽有。
3、查找注解
TypeMappedAnnotations.MergedAnnotationFinder 用于从 AnnotationScanner 扫描的注解中,找到一个指定类型的注解/合并注解:
private class MergedAnnotationFinder<A extends Annotation>
implements AnnotationsProcessor<Object, MergedAnnotation<A>> {
private final Object requiredType;
@Nullable
private final Predicate<? super MergedAnnotation<A>> predicate;
// 合并注解选择器
private final MergedAnnotationSelector<A> selector;
@Nullable
private MergedAnnotation<A> result;
MergedAnnotationFinder(Object requiredType, @Nullable Predicate<? super MergedAnnotation<A>> predicate,
@Nullable MergedAnnotationSelector<A> selector) {
this.requiredType = requiredType;
this.predicate = predicate;
this.selector = (selector != null ? selector : MergedAnnotationSelectors.nearest());
}
@Override
@Nullable
public MergedAnnotation<A> doWithAggregate(Object context, int aggregateIndex) {
return this.result;
}
@Override
@Nullable
public MergedAnnotation<A> doWithAnnotations(Object type, int aggregateIndex,
@Nullable Object source, Annotation[] annotations) {
for (Annotation annotation : annotations) {
if (annotation != null && !annotationFilter.matches(annotation)) {
MergedAnnotation<A> result = process(type, aggregateIndex, source, annotation);
if (result != null) {
return result;
}
}
}
return null;
}
@Nullable
private MergedAnnotation<A> process(
Object type, int aggregateIndex, @Nullable Object source, Annotation annotation) {
// 若注解是可重复注解的容器注解则平摊
Annotation[] repeatedAnnotations = repeatableContainers.findRepeatedAnnotations(annotation);
if (repeatedAnnotations != null) {
return doWithAnnotations(type, aggregateIndex, source, repeatedAnnotations);
}
// 获取这个注解的元注解,并将自己及这些元注解都转为AnnotationTypeMappings
AnnotationTypeMappings mappings = AnnotationTypeMappings.forAnnotationType(
annotation.annotationType(), repeatableContainers, annotationFilter);
for (int i = 0; i < mappings.size(); i++) {
// 遍历这些注解,如果有注解符合条件,则将其转为合并注解
AnnotationTypeMapping mapping = mappings.get(i);
if (isMappingForType(mapping, annotationFilter, this.requiredType)) {
MergedAnnotation<A> candidate = TypeMappedAnnotation.createIfPossible(
mapping, source, annotation, aggregateIndex, IntrospectionFailureLogger.INFO);
// 如果当前已经存在符合条件的合并注解了,则使用选择器判断两个注解到底谁会更合适,然后将其更新到成员变量result中
if (candidate != null && (this.predicate == null || this.predicate.test(candidate))) {
// 判断该注解是否是最符合的结果,如果是就没必要再比较了,直接返回
if (this.selector.isBestCandidate(candidate)) {
return candidate;
}
updateLastResult(candidate);
}
}
}
return null;
}
private void updateLastResult(MergedAnnotation<A> candidate) {
MergedAnnotation<A> lastResult = this.result;
this.result = (lastResult != null ? this.selector.select(lastResult, candidate) : candidate);
}
@Override
@Nullable
public MergedAnnotation<A> finish(@Nullable MergedAnnotation<A> result) {
return (result != null ? result : this.result);
}
}
// 判断AnnotationTypeMapping对应的注解是否符合要求
private static boolean isMappingForType(AnnotationTypeMapping mapping,
AnnotationFilter annotationFilter, @Nullable Object requiredType) {
Class<? extends Annotation> actualType = mapping.getAnnotationType();
return (!annotationFilter.matches(actualType) &&
(requiredType == null || actualType == requiredType || actualType.getName().equals(requiredType)));
}
MergedAnnotationFinder 主要干了这几件事:
- 遍历入参的数组
annotations,如果存在容器注解则将其全部平摊为可重复注解; - 遍历上述注解,解析它们的元注解,将全部的元注解与该注解都转为
AnnotationTypeMapping; - 将
AnnotationTypeMapping转为合并注解MergedAnnotation,然后判断这个合并注解是否符合要求; - 若该合并注解经过合并注解选择器
MergedAnnotationSelector确认,是最符合条件的结果,则直接返回; - 若该合并注解符合条件但是不是最符合条件的结果,则使用合并注解选择器
MergedAnnotationSelector判断该合并注解与上一个找到的符合条件的合并注解到底谁更合适一点; - 将更合适的合并注解更新到成员变量
result上;
合并注解选择器
这里又出现了一个新类 MergedAnnotationSelector,直译叫做合并注解选择器,它用于在 MergedAnnotationFinder 找到了多个符合条件的结果时,从这些结果中挑选出最优的作为 MergedAnnotationFinder 的最终返回值。
public interface MergedAnnotationSelector<A extends Annotation> {
// 该合并注解是否是最符合的结果,如果是直接跳过select
default boolean isBestCandidate(MergedAnnotation<A> annotation) {
return false;
}
// 二选一
MergedAnnotation<A> select(MergedAnnotation<A> existing, MergedAnnotation<A> candidate);
}
它默认提供了 FirstDirectlyDeclared 和 Nearest 两个实现,它们都需要借助上文提到的聚合索引:
private static class Nearest implements MergedAnnotationSelector<Annotation> {
// 聚合索引为0,说明注解直接出现在被扫描的AnnotatedElement上,是最符合的
@Override
public boolean isBestCandidate(MergedAnnotation<Annotation> annotation) {
return annotation.getDistance() == 0;
}
// 聚合索引不为0,则挑一个聚合索引比较小的,也就是先被扫描的
@Override
public MergedAnnotation<Annotation> select(
MergedAnnotation<Annotation> existing, MergedAnnotation<Annotation> candidate) {
if (candidate.getDistance() < existing.getDistance()) {
return candidate;
}
return existing;
}
}
private static class FirstDirectlyDeclared implements MergedAnnotationSelector<Annotation> {
// 聚合索引为0,说明注解直接出现在被扫描的AnnotatedElement上,是最符合的
@Override
public boolean isBestCandidate(MergedAnnotation<Annotation> annotation) {
return annotation.getDistance() == 0;
}
// 仅当已有注解没有直接出现在被扫描的AnnotatedElement上,但是新注解直接出现在了扫描的AnnotatedElement上的时候,才返回新注解
@Override
public MergedAnnotation<Annotation> select(
MergedAnnotation<Annotation> existing, MergedAnnotation<Annotation> candidate) {
if (existing.getDistance() > 0 && candidate.getDistance() == 0) {
return candidate;
}
return existing;
}
}
两个选择器判断规则不尽相同,但是大体思路是相同的,即:越接近被 AnnotationScanner 扫描的 AnnotatedElement 的注解,优先级越高。
总结
本篇文章主要分析的 Spring 对 AnnotatedElement 层级结构中注解的搜索与处理机制。
Spring 为我们提供的注解支持 get 和 find 两者语义的查询:
get与AnnotatedElement本身提供的方法类似,用于从元素本身直接搜索注解;find除了与get一样搜索元素本身外,若AnnotatedElement是Class或者Method,还会搜索的它们的类/声明类的层级结构;
当我们通过 find 语义的方法搜索层级结构时,实际上会先生成一个合成注解聚合对象 MergedAnnotations,它会在被操作时,根据我们在创建时传入的注解过滤器 AnnotationFilter 及注解搜索策略 SearchStrategy,使用注解扫描器 AnnotationScanner 对目标元素进行扫描。因此,find 和 get 区别只是来自于注解扫描时使用的搜索策略的不同。
而当 AnnotationScanner 扫描到注解后,会根据操作类型,调用指定的注解处理器 AnnotationProcessor,Spring 默认提供了三种类型的处理器,以便支持三种不同类型的操作:
TypeMappedAnnotations.IsPresent:判断注解是否存在;TypeMappedAnnotations.AggregatesCollector:收集全部被扫描到的注解;TypeMappedAnnotations.MergedAnnotationFinder:从元素被扫描的注解中找到符合条件的唯一合并注解;
此外,在上述过程中,Spring 还考虑到的可重复注解,在进行上述处理的时候,若操作的注解是可重复注解的容器注解,则 Spring 还会将其展开摊平后,再对最终获得的可重复注解进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号