SQL Server-聚焦NOT EXISTS AND NOT IN性能分析(十五)
前言
上一节我们分析了INNER JOIN和IN,对于不同场景其性能是不一样的,本节我们接着分析NOT EXISTS和NOT IN,简短的内容,深入的理解,Always to review the basics。
初步探讨NOT EXISTS和NOT IN
NOT EXISTS和NOT IN有很大的不同,尤其是对NULL的处理,为何这样说,当子查询中有NULL时,此时NOT IN不会返回任何行,下面我们来看下简单的示例。
USE TSQL2012 GO WITH table1 AS ( SELECT 1 AS value UNION ALL SELECT NULL AS nullcol1 ), table2 AS ( SELECT 2 AS value UNION ALL SELECT NULL AS nullcol2 )
首先我们来通过NOT EXISTS来进行查询
SELECT * FROM table1 AS a
WHERE NOT EXISTS(SELECT * FROM table2 AS b WHERE a.value = b.value)

接下来我们再来进行NOT IN查询
SELECT * FROM table1 AS a
WHERE value NOT IN(SELECT * FROM table2)

为何会出现不一样的结果呢,我们来分析下EXISTS和IN,EXISTS使用的是两值谓词逻辑,也就说说EXISTS总是返回TRUE或者FALSE,绝对不会返回UNKNOWN,而IN使用的三值谓词逻辑即返回的是TRUE或者FALSE或者UNKNOWN。当我们进行NOT EXISTS查询时,此时用1和NULL两行数据,此时1与table2中的值进行等值比较,此时没有相同的返回FALSE,接着NOT EXISTS则返回TRUE,所以此时返回1,同理返回NULL,当利用上述NOT IN进行查询时,我们可以将上述进行如下等价
SELECT * FROM table1 AS a
WHERE value NOT IN(SELECT * FROM table2)
等价于
WHERE ( value != (SELECT value FROM table2 WHERE value = 2) AND value != (SELECT value FROM table2 WHERE value = NULL) )
当value = 1时,此时则有TRUE AND UNKNOWN结果还是UNKNOWN,同理当value = NULL时也是返回UNKNOWN,所以最终结果都未匹配上没有任何数据返回。
进一步探讨NOT EXISTS和NOT IN
接下来我们来进行NOT EXISTS和NOT IN的性能分析,接下来我们通过三种情况来进行分析。
(1)未建立索引情况比较NOT EXISTS和NOT IN
我们还是利用上一节的BigTable和SmallerTable来进行测试。
USE TSQL2012
GO
SELECT ID, SomeColumn FROM BigTable
WHERE SomeColumn NOT IN (SELECT LookupColumn FROM SmallerTable)
SELECT ID, SomeColumn FROM BigTable
WHERE NOT EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)
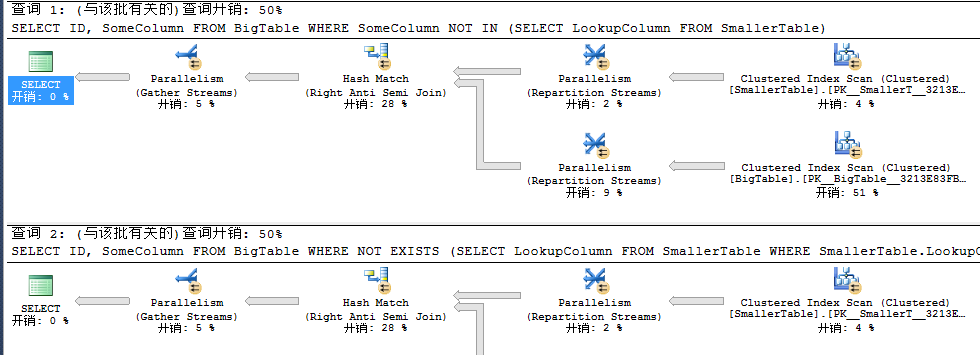
此时发现NOT EXISTS和NOT IN开销一致,解下来我们创建索引看看。
(2)创建索引比较NOT EXISTS和NOT IN
CREATE INDEX idx_BigTable_SomeColumn ON BigTable (SomeColumn)
CREATE INDEX idx_SmallerTable_LookupColumn ON SmallerTable (LookupColumn)
继续进行上述查询
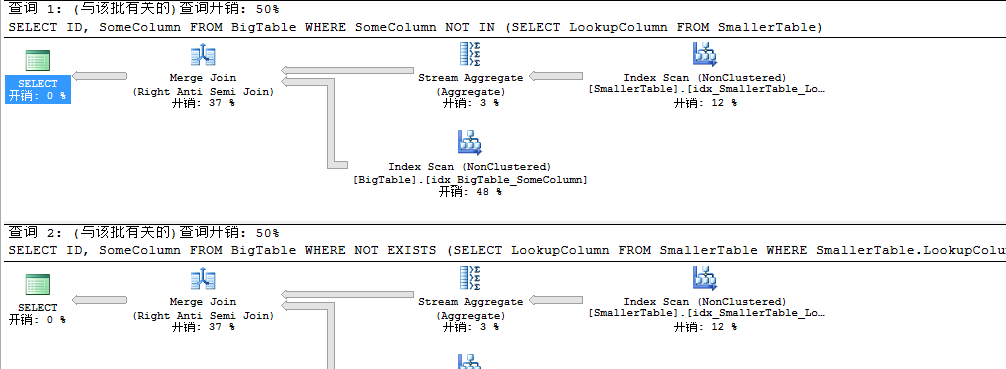
创建了索引结果还是一致和上一节我们讨论的INNER JOIN和IN的情况有点不太一样,即使是创建唯一非聚集索引二者性能开销还是一致。到这里我们是不是可以下结论说二者性能一致呢,我们继续往下看,不知道大家发现了没有我们在上一节开始时对查询列的约束是不为空的,那要是为空结果又会是怎样的呢,我们看看。
(3)将查询列修改为可空
我们将SomeTable表和SmallerTable表中的SomeCloumn和LookupColumn修改为可空
USE TSQL2012
GO
ALTER TABLE BigTable
ALTER COLUMN SomeColumn UNIQUEIDENTIFIER NULL
ALTER TABLE SmallerTable
ALTER COLUMN LookupColumn UNIQUEIDENTIFIER NULL
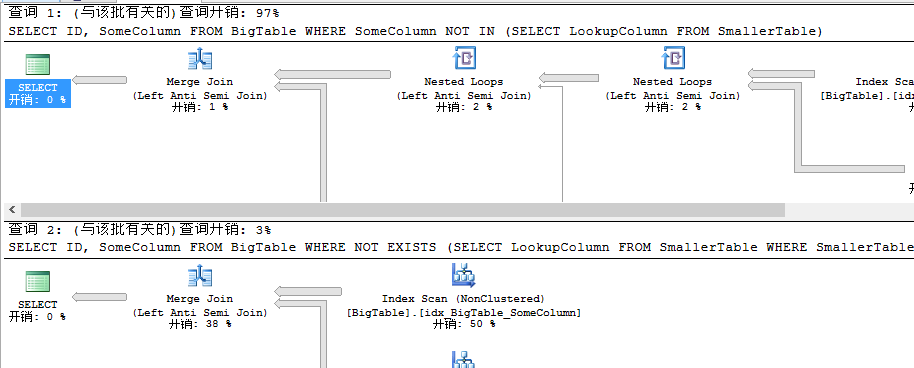
查询计划显示结果大大出乎我们意料,为什么将列修改为可空的,此时NOT IN的性能开销接近是NOT EXISTS的33倍,猜测的话数据量越大这个差距应该是越来越明显。不知道为何如此,反正查询计划是如此,欺骗不了我们。在SQL Server 2012基础教程后续中无意中看到这样一句话:对EXISTS来说它会过滤掉NULL值。是不是当列定义为NULL时,IN不会过滤掉NULL,而EXISTS即使定义为NULL也会被自然过滤呢,不得而知。通过上述我们明确知道,有时候将列定义为空会减少我们的不必要的判断,但是在NOT EXISTS和NOT IN比较中,此时通过定义为NULL将会得到巨大的差异,至此,我们可以得出如下结论。
NOT EXISTS和NOT IN性能分析结论:当将查询列定义为NULL时,NOT EXISTS比NOT IN性能要好很多,当定义为非NULL时此时二者查询开销一样。当然如没有特殊情况,还是建议将查询列定义为非NULL,这样既可以保证查询性能,也可以保证在使用过程中NOT IN的安全性,减少不必要的性能开销。
总结
本节我们详细探讨了NOT EXISTS和NOT IN的性能情况,下一节我们开始探讨EXIST和IN的性能分析,简短的内容,深入的理解,我们下节再会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号