读懂操作系统(x86)之堆栈帧(过程调用)
前言
为进行基础回炉,接下来一段时间我将持续更新汇编和操作系统相关知识,希望通过屏蔽底层细节能让大家明白每节所阐述内容。当我们写下如下C代码时背后究竟发生了什么呢?
#include <stdio.h> int main() { int a = 2, b = 3; int func(int a, int b); int c = func(a, b); printf("%d\n%d\n%d\n",a, b, c); } int func(int a, int b) { int c = 20; return a + b + c; }
接下来我们gcc编译器通过如下命令
gcc -S fileName.c
将其转换为如下AT&T语法的汇编代码(看不懂的童鞋可自行忽略,接下来我会屏蔽细节,从头开始分析如下汇编代码的本质)
_main: LFB13: .cfi_startproc pushl %ebp movl %esp, %ebp andl $-16, %esp subl $32, %esp call ___main movl $2, 28(%esp) movl $3, 24(%esp) movl 24(%esp), %eax movl %eax, 4(%esp) movl 28(%esp), %eax movl %eax, (%esp) call _func movl %eax, 20(%esp) movl 20(%esp), %eax movl %eax, 12(%esp) movl 24(%esp), %eax movl %eax, 8(%esp) movl 28(%esp), %eax movl %eax, 4(%esp) movl $LC0, (%esp) call _printf movl $0, %eax leave .cfi_restore 5 .cfi_def_cfa 4, 4 ret .cfi_endproc LFE13: .globl _func .def _func; .scl 2; .type 32; .endef _func: LFB14: .cfi_startproc pushl %ebp movl %esp, %ebp subl $16, %esp movl $20, -4(%ebp) movl 8(%ebp), %edx movl 12(%ebp), %eax addl %eax, %edx movl -4(%ebp), %eax addl %edx, %eax leave .cfi_restore 5 .cfi_def_cfa 4, 4 ret .cfi_endproc LFE14: .ident "GCC: (MinGW.org GCC Build-20200227-1) 9.2.0" .def _printf; .scl 2; .type 32; .endef
CPU提供了基于栈的数据结构,当我们利用push和pop指令时说明会将寄存器上某一块地址作为栈来使用,但是当我们执行push或者pop指令时怎么知道哪一个单元是栈顶呢?此时将涉及到两个寄存器,段寄存器SS和寄存器SP,栈顶的段地址存放在SS中,而偏移地址存放在SP中,通过SS:SP即(段地址/基础地址 + 偏移地址 = 物理地址),因为堆栈是向下增长,所以当我们进行比如push ax(操作数和结果数据的累加器)即将ax压入栈时,会进行如下两步操作:(1)SP = SP - 2,SS:SP指向当前栈顶前面的单元,以当前栈顶前面的单元作为新的栈顶(画外音:SP就是堆栈指针)(2)将ax中的内容送入SS:SP指向的内存单元处,SS:SP指向新栈顶。
那么CPU提供基于堆栈的数据结构可以用来做什么呢?堆栈的主要用途在于过程调用,一个堆栈将由一个或多个堆栈帧组成,每个堆栈帧(也称作活动记录)对应于对尚未以返回终止的函数或过程的调用,堆栈帧本质就是函数或者方法。我们知道对于函数或者方法有参数、局部变量、返回值。所以对于堆栈帧由函数参数、指向前一个堆栈帧的反向指针、局部变量组成。有了上述基础知识铺垫,接下来我们来分析在主函数中对函数调用如何利用汇编代码实现
int c = func(a, b); int func(int a, int b) { int c = 20; return a + b + c; }
参数
当调用func时,我们需要通过push指令将参数压入堆栈,此时在堆栈中入栈顺序如下
push b
push a
call func
当每个参数被推到堆栈上时,由于堆栈会向下生长,所以将堆栈指针寄存器减4个字节(在32位模式下),并将该参数复制到堆栈指针寄存器所指向的存储位置。注意:指令会隐式将返回地址压入堆栈。
栈帧
接下来进入被调用函数即进入栈帧,如果我们想要访问参数,可以像如下访问(注意:sp为早期处理器堆栈指针,如下esp为intel x86堆栈指针,只是名称不同而已)
[esp + 0] - return address [esp + 4] - parameter 'a' [esp + 8] - parameter 'b'
然后我们开始为局部变量c分配空间,但是如果我们还是利用esp来指向函数局部变量将会出现问题,因为esp作为堆栈指针,若在其过程中执行push(推送)或者pop(弹出)操作时,esp堆栈指针将会发生变化,此时将导致esp无法真正引用其中任何变量即通过esp表示的局部变量的偏移地址不再有效,偏移量由编译器所计算并在指令中为其硬编码,所以在执行程序期间很难对其进行更改。
为了解决这个问题,我们引入帧指针寄存器(bp),当被调用函数或方法开始执行时,我们将其设置为堆栈帧的地址,如果代码将局部变量称为相对于帧指针的偏移量而不是相对于堆栈指针的偏移量,则程序可以使用堆栈指针而不会使对自动变量的访问复杂化,然后,我们将堆栈帧中的某些内容称为offset($ fp)而不是offset($ sp)。
上述帧指针寄存器从严格意义上来说称作为堆栈基指针寄存器(bp:base pointer),我们希望将堆栈基指针寄存器设置为当前帧,而不是先前的函数,因此,我们将旧的保存在堆栈上(这将修改堆栈上参数的偏移量),然后将当前的堆栈指针寄存器复制到堆栈基指针寄存器。
push ebp ; 保存之前的堆栈基指针寄存器
mov ebp, esp ; ebp = esp
局部变量
局部变量存在堆栈中,所以接下来我们通过esp为局部变量分配内存单元空间,如下:
sub esp, bytes ; bytes为局部变量所需的字节大小
如上意思则是,sub为单词(subtraction)相减缩写,堆栈向下增长(根据处理器不同可能方向有所不同,但通常是向下增长比如x86-64),若局部变量为3个(int)即双字,则字节大小为12,则堆栈指帧向上减去12即esp-12(注:这种说法不是很准确,涉及到具体细节,可暂且这样理解)。 如上所述最终将完成堆栈帧调用,最终我们将所有内容放在一起,则是如下这般
[ebp + 12] - parameter 'b' [ebp + 8] - parameter 'a' [ebp + 4] - return address [ebp + 0] - saved stackbase-pointer register
当调用函数或方法完毕后,对堆栈帧必须进行清理即进行内存释放和恢复先前堆栈帧指针寄存器继续往下执行,如下:
mov esp, ebp ; 释放局部变量内存空间
pop ebp ; 恢复先前的堆栈帧指针寄存器
如上只是从整体上去对堆栈帧调用的大概说明,我们来看看局部变量和参数基于ebp的偏移量是为正值还是负值
void func() { int a, b, c; a = 1; b = 2; c = 3; } 执行: push ebp mov ebp, esp 高地址 | |<-------------- ebp = esp | | 低地址 执行: sub esp, 12 高地址 | |<-------------- ebp | |<-------------- esp | | 低地址 执行: mov [ebp-4], 1 mov [ebp-8], 2 mov [ebp-12], 3 高地址 | | | <-------------- ebp |1 |2 |3 | <--------------- esp 低地址
如上所述在进入函数后,旧的ebp值将被压入堆栈,并将ebp设置为esp的值,然后esp递减(因为堆栈在内存中向下增长),以便为函数的局部变量和临时变量分配空间。从那一刻起,在函数执行期间,函数的参数位于堆栈上,因为它们在函数调用之前被压入,所以与ebp的偏移量为正值,而局部变量位于与ebp的偏移量为负值的位置,因为它们是在函数输入之后分配在堆栈上(如上图分析)。到这里我们将开始所写的函数最终在堆栈中的内存位置是怎样的呢?图解如下:

最后我们将上述通过AT&T语法转换的汇编代码转换为intel语法汇编代码可能会更好理解一点
gcc -S -masm=intel 1.c
二者只不过是对应指令所使用符号有所不同而已,比如操作数为立即数时,AT&T语法将添加$符号,而intel语法不会,对上述函数调用进行详细解释,如下
//主函数栈帧 _main: LFB13: push ebp mov ebp, esp and esp, -16 sub esp, 32 call ___main //将立即数2写入【esp+28】 mov DWORD PTR [esp+28], 2 //将立即数3写入【esp+24】 mov DWORD PTR [esp+24], 3 //将【esp+24】值写入寄存器eax mov eax, DWORD PTR [esp+24] //将寄存器eax中的值(即3)写入【esp+4】 mov DWORD PTR [esp+4], eax //将[esp+28]值写入eax寄存器 mov eax, DWORD PTR [esp+28] //将寄存器eax中的值(即2)写入【esp+0】 mov DWORD PTR [esp], eax //调用_func函数,此时将返回地址压入栈 call _func //将eax寄存器的值结果(即25)写入【esp+20】 mov DWORD PTR [esp+20], eax //将【esp+20】值写入eax寄存器 mov eax, DWORD PTR [esp+20] //将寄存器eax中的值写入【esp+12】 = 25 mov DWORD PTR [esp+12], eax //将【esp+24】值写入eax寄存器 mov eax, DWORD PTR [esp+24] //将寄存器eax中的值写入【esp+8】 = 3 mov DWORD PTR [esp+8], eax //将【esp+28】值写入eax寄存器 mov eax, DWORD PTR [esp+28] //将寄存器eax中的值写入【esp+4】 = 2 mov DWORD PTR [esp+4], eax mov DWORD PTR [esp], OFFSET FLAT:LC0 call _printf mov eax, 0 leave ret //被调用函数(_func)栈帧 _func: LFB14: push ebp mov ebp, esp //为函数局部变量分配16个字节空间 sub esp, 16 //将立即数写入偏移栈帧4位的地址上 mov DWORD PTR [ebp-4], 20 //将偏移栈帧8位上的地址值(即2)写入edx寄存器 mov edx, DWORD PTR [ebp+8] //将偏移栈帧12位上的地址值(即3)写入eax寄存器 mov eax, DWORD PTR [ebp+12] //将eax寄存器中的值和edx寄存器中的值相加即(a+b) = 5 add edx, eax //将偏移栈帧地址4位上的地址值(即20)写入寄存器eax mov eax, DWORD PTR [ebp-4] //将eax寄存器值和edx寄存器存储的值相加即(20+c) = 25 add eax, edx //相当于执行(move esp,ebp; pop ebp;)有效清除堆栈帧空间 leave //相当于执行(pop ip),从堆栈中弹出返回地址,并将控制权返回到该位置 ret
上述对汇编代码的详细解释可能对零基础的汇编童鞋理解起来还是有很大困难,接下来我将再一次通过图解方式一步步给大家做出明确的解释,通过对堆栈帧的学习我们能够知道函数或方法调用的具体细节以及高级语言中值类型复制的原理,它的本质是什么呢?接下来我们一起来看看。(注:英特尔架构上的堆栈从高内存增长到低内存,因此堆栈的顶部(最新内容)位于低内存地址中)。
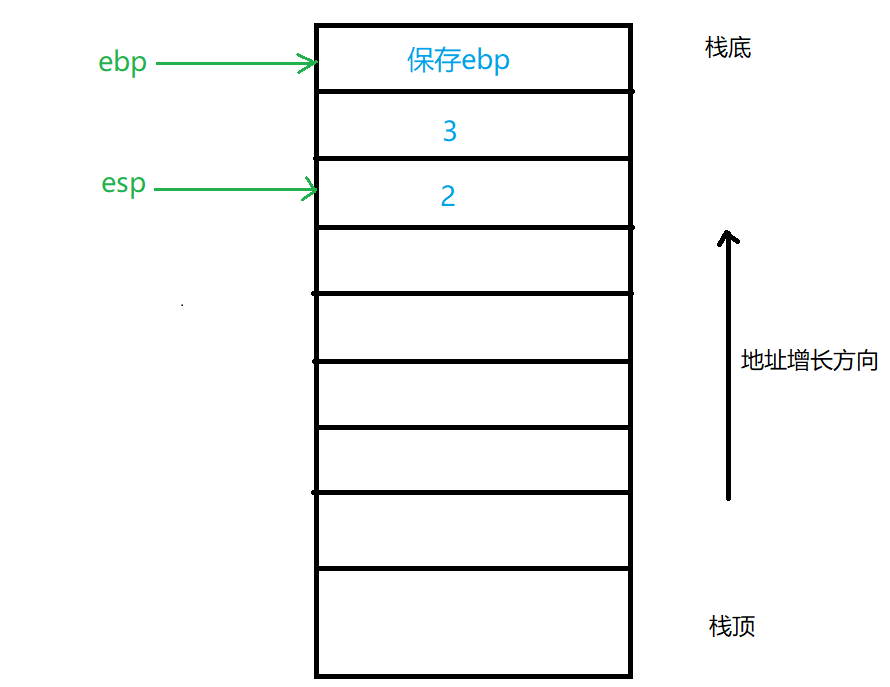
在主函数栈帧如图所示,首先分配局部变量内存空间,然后保存主函数的堆栈帧,最后将2和3分别压入栈,接下来进入调用函数,如下图所示
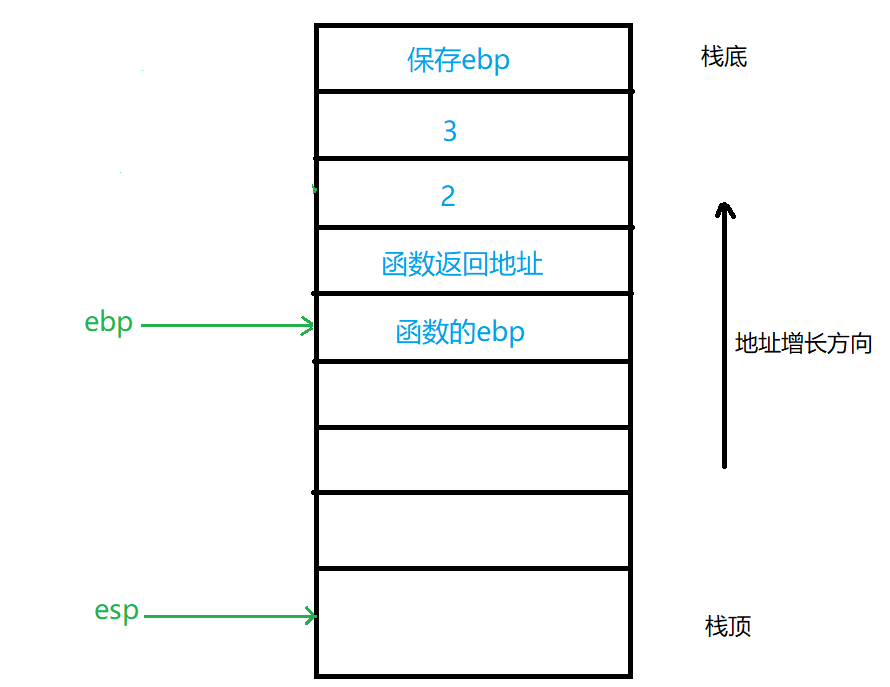
然后开始调用函数,当执行call指令时会将返回地址压入栈以便执行栈帧上的ret指令时进行返回,将当前堆栈针移动到堆栈针,定义了堆栈帧的开始,从此刻开始进行函数调用内部,如下图
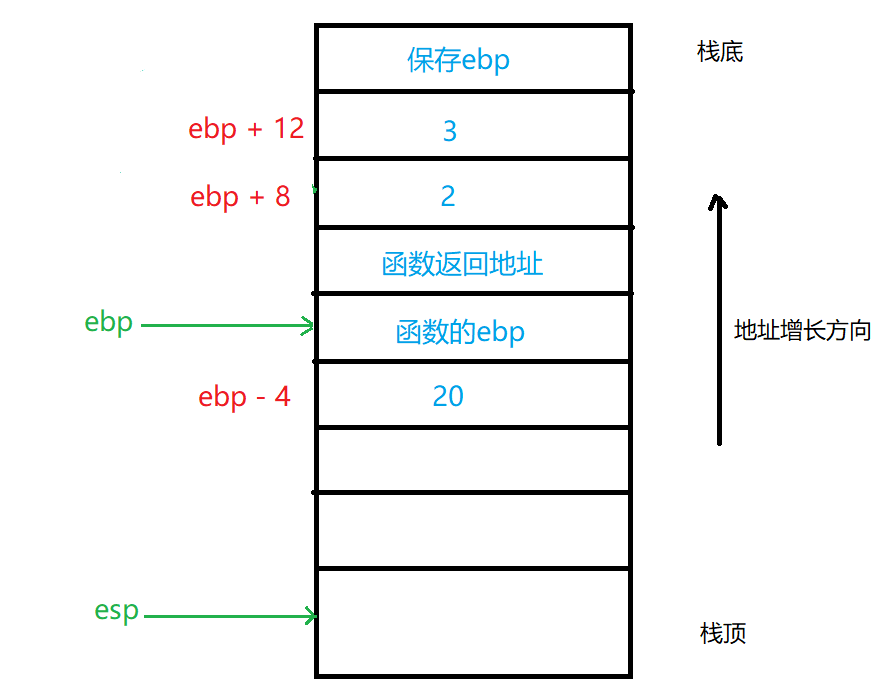
首先我们保存先前的ebp值,并将堆栈帧指针设置为堆栈的顶部(堆栈指针的当前位置),然后我们通过从堆栈指针中减去16个字节来增加堆栈为局部变量分配空间,在此堆栈框架中,包含该函数的本地数据、帧指针ebp的负偏移量(栈的顶部,到较低的内存中)r表示本地变量、ebp的正偏移量将使我们能够读取传入的参数,接下来则是将局部变量c设置为20,完成后,通过leave指令将堆栈指针设置为帧指针的值(ebp),并弹出保存的帧指针值,有效地释放堆栈帧内存空间,此时,堆栈指针指向函数返回地址,执行ret指令时弹出堆栈,并将控制转移到call指令压入栈的返回地址,继续往下执行。
堆栈帧解惑
通过如上图解对比汇编代码分析可以为我们解惑两大问题,我们看到将操作数为立即数的a = 2和 b = 3入栈【esp+28】和【esp+24】的地址上,如下:
//将立即数2写入【esp+28】 mov DWORD PTR [esp+28], 2 //将立即数3写入【esp+24】 mov DWORD PTR [esp+24], 3
但是我们会发现接下来会将2和3将通过寄存器eax分别写入到栈为【esp+4】和【esp+0】的地址上,但是最终获取变量a和b的值依然是对应地址【esp+28】和【esp+24】,这就是高级语言中值类型的原理即深度复制(副本):通过寄存器传递(比如eax)将值副本存储到堆栈帧上其他内存单元地址,参数值即从该内存单元获取。
//将【esp+24】值写入寄存器eax mov eax, DWORD PTR [esp+24] //将寄存器eax中的值(即3)写入【esp+4】 mov DWORD PTR [esp+4], eax //将[esp+28]值写入eax寄存器 mov eax, DWORD PTR [esp+28] //将寄存器eax中的值(即2)写入【esp+0】 mov DWORD PTR [esp], eax 调用完函数后: //将【esp+24】值写入eax寄存器 mov eax, DWORD PTR [esp+24] //将寄存器eax中的值写入【esp+8】 = 3 mov DWORD PTR [esp+8], eax //将【esp+28】值写入eax寄存器 mov eax, DWORD PTR [esp+28] //将寄存器eax中的值写入【esp+4】 = 2 mov DWORD PTR [esp+4], eax
将变量a和b复制到栈【esp+0】和【esp+4】地址上,就是将其作为函数或方法的调用参数,即使进行修改操作也不会修改原有变量的值,但是我们会发现在函数中当获取变量a和b的值是通过【ebp+8】和【ebp+12】来获取
//将偏移栈帧8位上的地址值(即2)写入edx寄存器 mov edx, DWORD PTR [ebp+8] //将偏移栈帧12位上的地址值(即3)写入eax寄存器 mov eax, DWORD PTR [ebp+12]
若是看到上述汇编代码时存在看不懂的情况,结合图解3将一目了然,参数通过基于当前堆栈帧的偏移位移来获取,因为在调用函数时也将返回地址和函数的ebp压入栈,最终将堆栈针指向当前函数的ebp,所以相对于当前函数的堆栈帧而言,变量a和b的地址自然而然就变成了【ebp+8】和【ebp+12】。
总结
经典的书籍针对栈顶的定义实际上是指堆栈所占内存区域中的最低地址,和我们自然习惯有所不同,有些文章若是指向堆栈内存高地址,这种说法是错误的。存在帧指针寄存器(ebp)存在的主要原因在于堆栈指针(sp)的值会发生变化,但是这只是历史遗留问题针对早期的处理器而言,现如今处理器对于sp有些已具备offset(相对寻址)属性,所以对于帧指针寄存器是可选的,不过利用bp在跟踪和调试函数的参数和局部变量更加方便。一个调用堆栈由1个或多个堆栈帧组成,每个堆栈帧对应于对尚未以返回终止的函数或过程的调用。要使用栈帧,线程保留两个指针,一个称为堆栈指针(SP),另一个称为帧指针(FP)。SP始终指向堆栈的顶部,而FP始终指向帧的顶部。此外,该线程还维护一个程序计数器(PC),该计数器指向要执行的下一条指令。栈帧中局部变量为负偏移量,参数为正偏移量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号