CompletableFuture 详情
创建 CompletableFuture 并执行
当我们需要进行异步处理的时候,我们可以通过CompletableFuture.supplyAsync方法,传入一个具体的要执行的处理逻辑函数,这样就轻松的完成了CompletableFuture的创建与触发执行。
| 方法名称 | 作用描述 |
|---|---|
| supplyAsync | 静态方法,用于构建一个CompletableFuture<T>对象,并异步执行传入的函数,允许执行函数有返回值T。 |
| runAsync | 静态方法,用于构建一个CompletableFuture<Void>对象,并异步执行传入函数,与supplyAsync的区别在于此方法传入的是Callable类型,仅执行,没有返回值。 |
使用示例:
public void testCreateFuture(String product) {
// supplyAsync, 执行逻辑有返回值PriceResult
CompletableFuture<PriceResult> supplyAsyncResult =
CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoPrice(product));
// runAsync, 执行逻辑没有返回值
CompletableFuture<Void> runAsyncResult =
CompletableFuture.runAsync(() -> System.out.println(product));
}
特别补充:
supplyAsync或者runAsync创建后便会立即执行,无需手动调用触发。
| 方法名称 | 作用描述 |
|---|---|
| thenApply | 对CompletableFuture的执行后的具体结果进行追加处理,并将当前的CompletableFuture泛型对象更改为处理后新的对象类型,返回当前CompletableFuture对象。 |
| thenCompose | 与thenApply类似。区别点在于:此方法的入参函数返回一个CompletableFuture类型对象。 |
| thenAccept | 与thenApply方法类似,区别点在于thenAccept返回void类型,没有具体结果输出,适合无需返回值的场景。 |
| thenRun | 与thenAccept类似,区别点在于thenAccept可以将前面CompletableFuture执行的实际结果作为入参进行传入并使用,但是thenRun方法没有任何入参,只能执行一个Runnable函数,并且返回void类型。 |
接收处理异常
| 方法名称 | 作用描述 |
|---|---|
| handle | 与thenApply类似,区别点在于handle执行函数的入参有两个,一个是CompletableFuture执行的实际结果,一个是是Throwable对象,这样如果前面执行出现异常的时候,可以通过handle获取到异常并进行处理。 |
| whenComplete | 与handle类似,区别点在于whenComplete执行后无返回值。 |
多个CompletableFuture组合操作
CompletableFuture相比于Future的一大优势,就是可以方便的实现多个并行环节的合并处理
| 方法名称 | 作用描述 |
|---|---|
| thenCombine | 将两个CompletableFuture对象组合起来进行下一步处理,可以拿到两个执行结果,并传给自己的执行函数进行下一步处理,最后返回一个新的CompletableFuture对象。 |
| thenAcceptBoth | 与thenCombine类似,区别点在于thenAcceptBoth传入的执行函数没有返回值,即thenAcceptBoth返回值为CompletableFuture<Void>。 |
| runAfterBoth | 等待两个CompletableFuture都执行完成后再执行某个Runnable对象,再执行下一个的逻辑,类似thenRun。 |
| applyToEither | 两个CompletableFuture中任意一个完成的时候,继续执行后面给定的新的函数处理。再执行后面给定函数的逻辑,类似thenApply。 |
| acceptEither | 两个CompletableFuture中任意一个完成的时候,继续执行后面给定的新的函数处理。再执行后面给定函数的逻辑,类似thenAccept。 |
| runAfterEither | 等待两个CompletableFuture中任意一个执行完成后再执行某个Runnable对象,可以理解为thenRun的升级版,注意与runAfterBoth对比理解。 |
| allOf | 静态方法,阻塞等待所有给定的CompletableFuture执行结束后,返回一个CompletableFuture<Void>结果。 |
| anyOf | 静态方法,阻塞等待任意一个给定的CompletableFuture对象执行结束后,返回一个CompletableFuture<Void>结果。 |
结果等待与获取
在执行线程中将任务放到工作线程中进行处理的时候,执行线程与工作线程之间是异步执行的模式,如果执行线程需要获取到共工作线程的执行结果,则可以通过get或者join方法,阻塞等待并从CompletableFuture中获取对应的值。
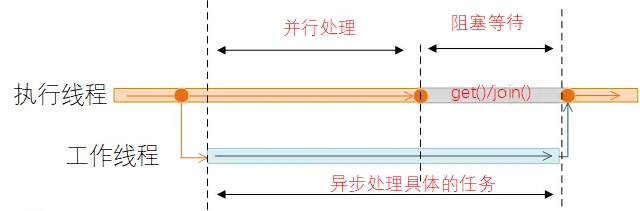
对get和join的方法功能含义说明归纳如下:
| 方法名称 | 作用描述 |
|---|---|
| get() | 等待CompletableFuture执行完成并获取其具体执行结果,可能会抛出异常,【需要】代码调用的地方手动try...catch进行处理。 |
| get(long, TimeUnit) | 与get()相同,只是允许设定阻塞等待超时时间,如果等待超过设定时间,则会抛出异常终止阻塞等待。 |
| join() | 等待CompletableFuture执行完成并获取其具体执行结果,可能会抛出运行时异常,【无需】代码调用的地方手动try...catch进行处理。 |
CompletableFuture方法及其Async版本
我们在使用CompletableFuture的时候会发现,有很多的方法,都会同时有两个以Async命名结尾的方法版本。以前面我们用的比较多的thenCombine方法为例:
thenCombine(CompletionStage, BiFunction)
thenCombineAsync(CompletionStage, BiFunction)
thenCombineAsync(CompletionStage, BiFunction, Executor)
从参数上看,区别并不大,仅第三个方法入参中多了线程池Executor对象。看下三个方法的源码实现,会发现其整体实现逻辑都是一致的,仅仅是使用线程池这个地方的逻辑有一点点的差异:
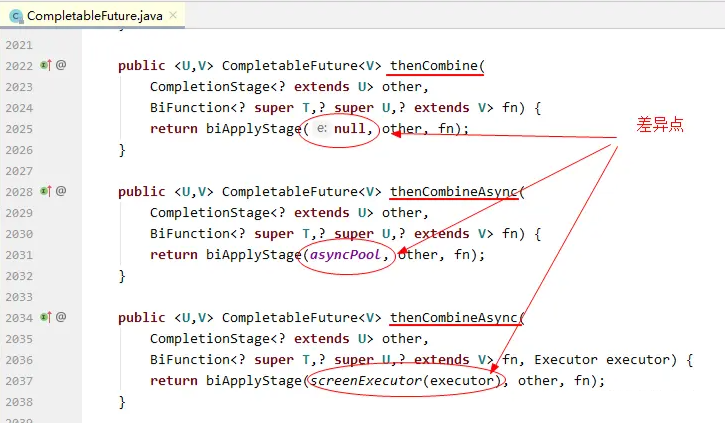
这里概括下三者的区别:
thenCombine方法,沿用上一个执行任务所使用的线程池进行处理
thenCombineAsync两个入参的方法,使用默认的ForkJoinPool线程池中的工作线程进行处理
themCombineAsync三个入参的方法,支持自定义线程池并指定使用自定义线程池中的线程作为工作线程去处理待执行任务。
- 用法1: 其中一个supplyAsync方法以及thenCombineAsync指定使用自定义线程池,另一个supplyAsync方法不指定线程池(使用默认线程池)
public PriceResult getCheapestPlatAndPrice4(String product) {
// 构造自定义线程池
ExecutorService executor = Executors.newFixedThreadPool(5);
return
CompletableFuture.supplyAsync(
() -> HttpRequestMock.getMouXiXiPrice(product),
executor
).thenCombineAsync(
CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouXiXiDiscounts(product)),
this::computeRealPrice,
executor
).join();
}
对上述代码实现策略的解读,以及与执行结果的关系展示如下图所示,可以看出,没有指定自定义线程池的supplyAsync方法,其使用了默认的ForkJoinPool工作线程来运行,而另外两个指定了自定义线程池的方法,则使用了自定义线程池来执行。
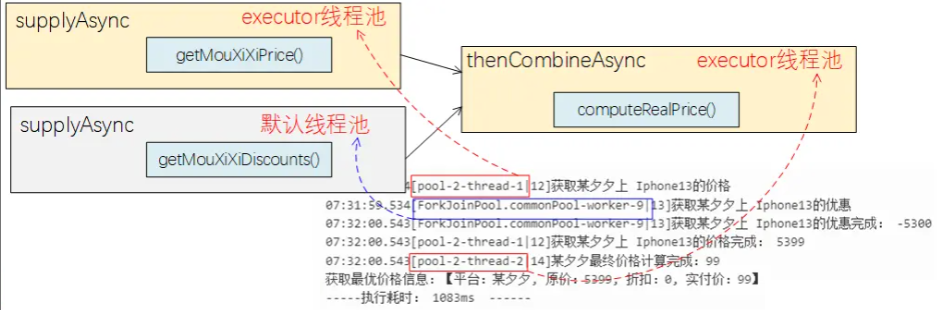
- 用法2: 不指定自定义线程池,使用默认线程池策略,使用thenCombine方法
public PriceResult getCheapestPlatAndPrice5(String product) {
return
CompletableFuture.supplyAsync(
() -> HttpRequestMock.getMouXiXiPrice(product)
).thenCombine(
CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouXiXiDiscounts(product)),
this::computeRealPrice
).join();
}
执行结果如下,可以看到执行线程名称与用法1示例相比发生了变化。因为没有指定线程池,所以两个supplyAsync方法都是用的默认的ForkJoinPool线程池,而thenCombine使用的是上一个任务所使用的线程池,所以也是用的ForkJoinPool。
14:34:27.815[ForkJoinPool.commonPool-worker-1|12]获取某夕夕上 Iphone13的价格
14:34:27.815[ForkJoinPool.commonPool-worker-2|13]获取某夕夕上 Iphone13的优惠
14:34:28.831[ForkJoinPool.commonPool-worker-2|13]获取某夕夕上 Iphone13的优惠完成: -5300
14:34:28.831[ForkJoinPool.commonPool-worker-1|12]获取某夕夕上 Iphone13的价格完成: 5399
14:34:28.831[ForkJoinPool.commonPool-worker-2|13]某夕夕最终价格计算完成:99
获取最优价格信息:【平台:某夕夕, 原价:5399, 折扣:0, 实付价:99】
-----执行耗时: 1083ms ------
现在,我们知道了方法名称带有Async和不带Async的实现策略上的差异点就在于【使用哪个线程池来执行】而已。那么,对我们实际的指导意义是啥呢?实际使用的时候,我们怎么判断自己应该使用带Async结尾的方法、还是不带Async结尾的方法呢?
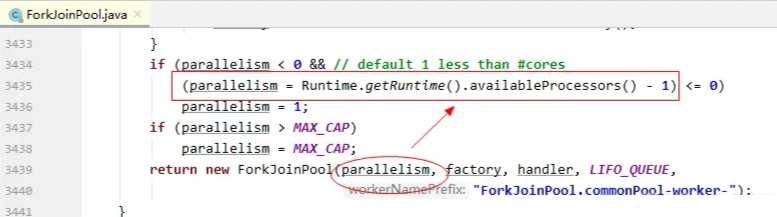
上面是Async结尾方法默认使用的ForkJoinPool创建的逻辑,这里可以看出,默认的线程池中的工作线程数是CPU核数 - 1,并且指定了默认的【丢弃策略】等,这就是一个主要关键点。
所以说,符合以下几个条件的时候,可以考虑使用带有Async后缀的方法,指定自定义线程池:
- 默认线程池的线程数满足不了实际诉求
- 默认线程池的类型不符合自己业务诉求
- 默认线程池的队列满处理策略不满足自己诉求
与Stream结合使用的注意点
需求场景: 在同一个平台内,传入多个商品,查询不同商品对应的价格与优惠信息,并选出实付价格最低的商品信息。
规划按照如下的策略来实现:
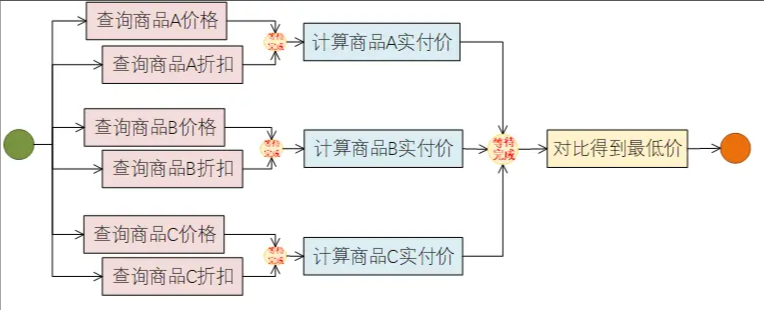
先看第一种编码实现:
public PriceResult comparePriceInOnePlat(List<String> products) {
return products.stream()
.map(product ->
CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoPrice(product))
.thenCombine(
CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoDiscounts(product)),
this::computeRealPrice))
.map(CompletableFuture::join)
.sorted(Comparator.comparingInt(PriceResult::getRealPrice))
.findFirst()
.get();
}
对于List的处理场景,这里采用了Stream方式来进行遍历与结果的收集、排序与返回。看似正常,但是执行的时候会发现,并没有达到我们预期的效果:
07:37:15.408[ForkJoinPool.commonPool-worker-9|12]获取某宝上 Iphone13黑色的价格完成: 5199
07:37:15.408[ForkJoinPool.commonPool-worker-2|13]获取某宝上 Iphone13黑色的优惠完成: -200
07:37:15.408[ForkJoinPool.commonPool-worker-2|13]某宝最终价格计算完成:4999
07:37:16.410[ForkJoinPool.commonPool-worker-9|12]获取某宝上 Iphone13白色的价格完成: 5199
07:37:16.410[ForkJoinPool.commonPool-worker-11|14]获取某宝上 Iphone13白色的优惠完成: -200
07:37:16.410[ForkJoinPool.commonPool-worker-11|14]某宝最终价格计算完成:4999
07:37:17.412[ForkJoinPool.commonPool-worker-11|14]获取某宝上 Iphone13红色的价格完成: 5199
07:37:17.412[ForkJoinPool.commonPool-worker-9|12]获取某宝上 Iphone13红色的优惠完成: -200
07:37:17.412[ForkJoinPool.commonPool-worker-9|12]某宝最终价格计算完成:4999
获取最优价格信息:【平台:某宝, 原价:5199, 折扣:0, 实付价:4999】
-----执行耗时: 3132ms ------
从上述执行结果可以看出,其具体处理的时候,其实是按照下面的逻辑去处理了:
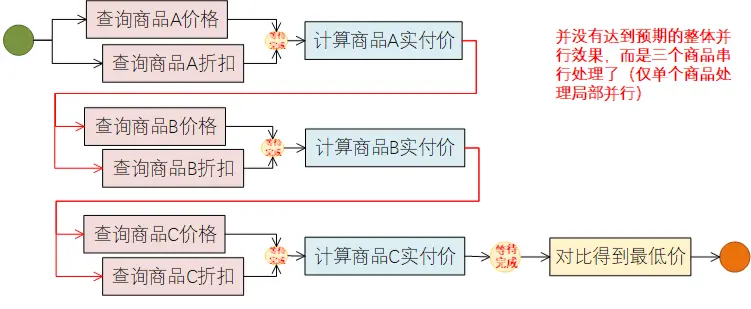
为什么会出现这种实际与预期的差异呢?原因就在于我们使用的Stream上面!虽然Stream中使用两个map方法,但Stream处理的时候并不会分别遍历两遍,其实写法等同于下面这种写到1个map中处理,改为下面这种写法,其实大家也就更容易明白为啥会没有达到我们预期的整体并行效果了:
public PriceResult comparePriceInOnePlat1(List<String> products) {
return products.stream()
.map(product -> CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoPrice(product)).thenCombine(CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoDiscounts(product)), this::computeRealPrice).join())
.sorted(Comparator.comparingInt(PriceResult::getRealPrice))
.findFirst()
.get();
}
既然如此,这种场景是不是就不能使用Stream了呢?也不是,其实我们拆开成两个Stream分步操作下其实就可以了。
再看下面的第二种实现代码:
public PriceResult comparePriceInOnePlat2(List<String> products) {
// 先触发各自平台的并行处理
List<CompletableFuture<PriceResult>> completableFutures = products.stream()
.map(product -> CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoPrice(product)).thenCombine(CompletableFuture.supplyAsync(() -> HttpRequestMock.getMouBaoDiscounts(product)), this::computeRealPrice))
.collect(Collectors.toList());
// 在独立的流中,等待所有并行处理结束,做最终结果处理
return completableFutures.stream()
.map(CompletableFuture::join)
.sorted(Comparator.comparingInt(PriceResult::getRealPrice))
.findFirst()
.get();
}
执行结果:
07:39:16.072[ForkJoinPool.commonPool-worker-6|17]获取某宝上 Iphone13红色的价格完成: 5199
07:39:16.072[ForkJoinPool.commonPool-worker-9|12]获取某宝上 Iphone13黑色的价格完成: 5199
07:39:16.072[ForkJoinPool.commonPool-worker-2|13]获取某宝上 Iphone13黑色的优惠完成: -200
07:39:16.072[ForkJoinPool.commonPool-worker-11|14]获取某宝上 Iphone13白色的价格完成: 5199
07:39:16.072[ForkJoinPool.commonPool-worker-4|15]获取某宝上 Iphone13白色的优惠完成: -200
07:39:16.072[ForkJoinPool.commonPool-worker-13|16]获取某宝上 Iphone13红色的优惠完成: -200
07:39:16.072[ForkJoinPool.commonPool-worker-2|13]某宝最终价格计算完成:4999
07:39:16.072[ForkJoinPool.commonPool-worker-4|15]某宝最终价格计算完成:4999
07:39:16.072[ForkJoinPool.commonPool-worker-13|16]某宝最终价格计算完成:4999
获取最优价格信息:【平台:某宝, 原价:5199, 折扣:0, 实付价:4999】
-----执行耗时: 1142ms ------
从执行结果可以看出,三个商品并行处理,整体处理耗时相比前面编码方式有很大提升,达到了预期的效果。
归纳下
因为Stream的操作具有延迟执行的特点,且只有遇到终止操作(比如collect方法)的时候才会真正的执行。所以遇到这种需要并行处理且需要合并多个并行处理流程的情况下,需要将并行流程与合并逻辑放到两个Stream中,这样分别触发完成各自的处理逻辑,就可以了
附加:并发和并行的区别
并发
关于并发的详细内容,可以参见我写的另一篇内容,也即本篇文章的姊妹篇《不堆概念,换个角度聊多线程并发编程》,下面这里简单的介绍下并发的概念
所谓并发,其关注的点是服务器的吞吐量情况,也就是服务器可以在单位时间内同时处理多少个请求。并发是通过多线程的方式来实现的,充分利用当前CPU多核能力,同时使用多个进程去处理业务,使得同一个机器在相同时间内可以处理更多的请求,提升吞吐量。
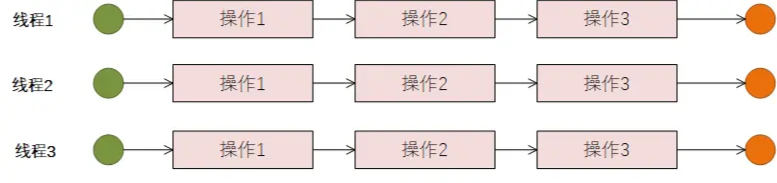
所有的操作在一个线程中串行推进,如果有多个线程同步处理,则同时有多个请求可以被处理。但是因为是串行处理,所以如果某个环节需要对外交互时,比如等待网络IO的操作,会使得当前线程处于阻塞状态,直到资源可用时被唤醒继续往后执行。

对于高并发场景,服务器的线程资源是非常宝贵的。如果频繁的处于阻塞则会导致浪费,且线程频繁的阻塞、唤醒切换动作,也会加剧整体系统的性能损耗。所以并发这种多线程场景,更适合CPU密集型的操作。
并行
所谓并行,就是将同一个处理流程没有相互依赖的部分放到多个线程中进行同时并行处理,以此来达到相对于串行模式更短的单流程处理耗时的效果,进而提升系统的整体响应时长与吞吐量。
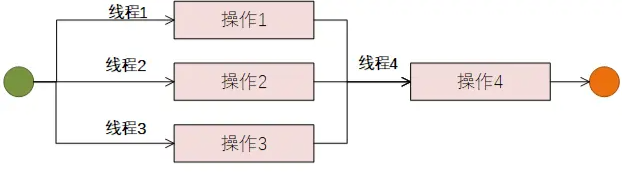
基于异步编程实现的并行操作也是借助线程池的方式,通过多线程同时执行来实现效率提升的。与并发的区别在于:并行通过将任务切分为一个个可独立处理的小任务块,然后基于系统调度策略,将需要执行的任务块分配给空闲可用工作线程去处理,如果出现需要等待的场景(比如IO请求)则工作线程会将此任务先放下,继续处理后续的任务,等之前的任务IO请求好了之后,系统重新分配可用的工作线程来处理。
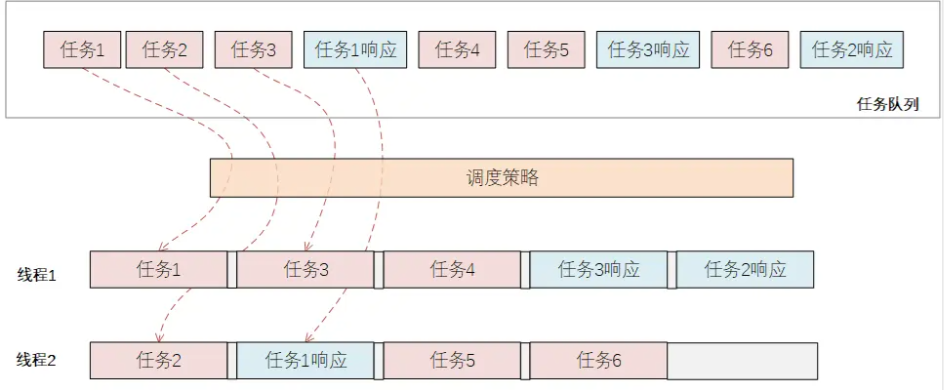
根据上面的示意图介绍可以看出,异步并行编程,对于工作线程的利用率上升,不会出现工作线程阻塞的情况,但是因为任务拆分、工作线程间的切换调度等系统层面的开销也会随之加大。
综合而言
- 如果业务处理逻辑是CPU密集型的操作,优先使用基于线程池实现并发处理方案(可以避免线程间切换导致的系统性能浪费)。
- 如果业务处理逻辑中存在较多需要阻塞等待的耗时场景、且相互之间没有依赖,比如本地IO操作、网络IO请求等等,这种情况优先选择使用并行处理策略(可以避免宝贵的线程资源被阻塞等待)。
本文作者:笔兴洽谈室 哔哩哔哩:笔兴洽谈室 GitHub:StarJava1024 Gitee:StarJava1024
本文链接:https://www.cnblogs.com/CrayonXiaoxing/articles/18382927
原创文章仅用于学习,不得修改原作品,不得再创作。若本文侵犯某版权,请私信联系删除!如需转载,请私信!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号