

牛客笔记
2020(一)—— 2022.10.3
普及组
A
string 练习题,复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define rep(i,l,r) for (int i=l;i<=r;i++)
int tag[4];
string s,s1,s2,s3,s4;
int main()
{
cin>>s;
rep(i,0,s.size()-1)
if (isdigit(s[i])) tag[0]=1,s3.push_back(s[i]);
else if (s[i]>='a'&&s[i]<='z') tag[1]=1,s1.push_back(s[i]);
else if (s[i]>='A'&&s[i]<='Z') tag[2]=1,s2.push_back(s[i]);
else tag[3]=1,s4.push_back(s[i]);
printf("password level:%d\n",tag[0]+tag[1]+tag[2]+tag[3]);
if (s1.size()) cout<<s1<<'\n';
else printf("(Null)\n");
if (s2.size()) cout<<s2<<'\n';
else printf("(Null)\n");
if (s3.size()) cout<<s3<<'\n';
else printf("(Null)\n");
if (s4.size()) cout<<s4<<'\n';
else printf("(Null)\n");
return 0;
}
B
贪心题。
一个位置能够被跳到,它之前的所有位置都能被跳到。
对于当前能被跳到的位置 ,考虑它能否更新当前能跳到的最右端位置,能就更新并记录这个位置 。
不能跳到就提升 ,显然这之后会更新 ,满足不重复,字典序最小,次数最少。
复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,t,r=1,fr=1,ans,A[MAXN],sta[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
int main()
{
n=read();
rep(i,1,n) A[i]=read();
rep(i,1,n+1)
{
if (i>r) ans++,sta[++t]=fr;
if (A[i]+i>r) r=A[i]+i,fr=i;
}
printf("%d\n",ans);
rep(i,1,t) printf("%d ",sta[i]);
return 0;
}
C
好玩的数学题。
对每个数筛去立方因子,筛出每对积为立方数的两者取最大就好。
筛因子按立方根内的质数筛。
复杂度为 。
Code
#include <iostream>
#include <cstring>
#include <cstdio>
#include <map>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,cnt,ans,p[MAXN];
bool is[MAXN];
map<int,int> mp;
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int sq(int x) { return x*x; }
inline int tr(int x) { return x*x*x; }
inline int cut(int x)
{
for (int j=1;j<=cnt&&tr(p[j])<=x;j++)
while (x%tr(p[j])==0) x/=tr(p[j]);
return x;
}
void solve(int n)
{
memset(is,1,sizeof(is));
is[1]=0;
rep(i,2,n)
{
if (is[i]) p[++cnt]=i;
for (int j=1;j<=cnt&&i*p[j]<=n;j++)
{
is[i*p[j]]=0;
if (!(i%p[j])) break;
}
}
}
signed main()
{
solve(2022);
n=read();
rep(i,1,n) mp[cut(read())]++;
for (auto x=mp.begin();x!=mp.end();x++)
{
if (x->first==1) ans++;
else
{
int t=cut(sq(x->first));
ans+=crq_max(x->second,mp[t]);
x->second=mp[t]=0;
}
}
printf("%lld",ans);
return 0;
}
D
两个单调栈维护区间 ,因为值域不超 ,双指针扫单调栈,求出 相同的区间长度范围 ,再开个差分数组,c[L]-=max*min,c[r]+=max*min,统计答案时前缀和回来即可。
复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define mk make_pair
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
int n,l,ma,mi,pma,pmi,tma,tmi,A[MAXN],C[MAXN];
pair<int,int> sma[MAXN],smi[MAXN];
int main()
{
n=read();
rep(i,1,n) A[i]=read();
rep(i,1,n)
{
while (tma&&sma[tma].first<=A[i]) tma--;
while (tmi&&smi[tmi].first>=A[i]) tmi--;
sma[++tma]=mk(A[i],i),smi[++tmi]=mk(A[i],i);
pma=tma-1,pmi=tmi-1;
ma=mi=A[i],l=i;
while (pma||pmi)
{
if ((pma&&pmi&&sma[pma].second>=smi[pmi].second)||(pma&&!pmi))
{
C[i-l+1]+=ma*mi;
l=sma[pma].second;
C[i-l+1]-=ma*mi;
ma=sma[pma].first;
--pma;
}
else
{
C[i-l+1]+=ma*mi;
l=smi[pmi].second;
C[i-l+1]-=ma*mi;
mi=smi[pmi].first;
--pmi;
}
}
C[i-l+1]+=ma*mi;
C[i+1]-=ma*mi;
}
rep(i,1,n) printf("%d%c",(C[i]+=C[i-1]),(i==n)?'\n':' ');
return 0;
}
提高组
A
对于 , 给定,当 时方程有解。
注意特判 。
复杂度为 。
Code
#include <cstdio>
#define int long long
int T,a,b,c,d;
int gcd(int x,int y) { return y?gcd(y,x%y):x; }
void R()
{
scanf("%lld%lld%lld%lld",&a,&b,&c,&d);
if (a==0&&b==0&&c==0)
{
if (d) printf("NO\n");
else printf("YES\n");
}
else if (d%gcd(gcd(a,b),c)==0) printf("YES\n");
else printf("NO\n");
}
signed main()
{
scanf("%lld",&T);
while (T--) R();
return 0;
}
B
倍增维护交换操作即可。
复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,m,f[MAXN][10][21],tmp[10],tmp2[10];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
int main()
{
n=read(),m=read();
rep(i,0,n-1)
{
rep(j,0,9) f[i][j][0]=j;
int a=read(),b=read();
f[i][a][0]=b,f[i][b][0]=a;
}
rep(t,1,20)
rep(i,0,n-1)
rep(j,0,9)
if (i+(1<<(t-1))<=n)
f[i][j][t]=f[i+(1<<(t-1))][f[i][j][t-1]][t-1];
rep(i,1,m)
{
int l=read(),r=read(),x=l-1,y=r-l+1;
rep(j,0,9) tmp[j]=j;
for (int i=0;y;y>>=1,i++)
if (y&1)
{
rep(j,0,9) tmp2[f[x][j][i]]=tmp[j];
rep(j,0,9) tmp[j]=tmp2[j];
x+=(1<<i);
}
rep(j,0,9) printf("%d ",tmp[j]);
putchar('\n');
}
return 0;
}
C
一个区间能表示的数一定是 ,以及之后几段零散的区间。
记空集能表示的数为 ,当前能表示的数为集合 ,把区间里的数丢到集合里,显然当 丢进去时, 会变成 。
假如我们把数从小到大往里面丢,当 比原来 里最大的数 大时,原来 里最大的数 就是 。
记 里最大的数 为 ,扫一遍区间,把 的数并且没被丢进 里的数丢进 里(中途不更新 ),如果这轮扫描有数被丢进去就更新 再扫一次,每次扫描后 至少翻倍,所以至多扫描 次。
把询问离线下来,用树状数组维护区间答案前缀和即可。
复杂度为 。
码后补。
D
赛时想的是按 更新,开 棵李超树,每次更新时暴力找之前扫完的 行各取答案再取 更新,复杂度为 ,寄了。
其实可以按 更新,然后根号分治:直接开 棵李超树,复杂度为 ,应该能过。
放个赛时 码,根号码有缘再补。
Code
#include <algorithm>
#include <iostream>
#include <vector>
#include <cstdio>
#define MAXN (int)(2e5+233)
using namespace std;
#define ls (now<<1)
#define rs (now<<1|1)
#define mid ((l+r)>>1)
#define rep(i,l,r) for (int i=l;i<=r;i++)
struct Seg
{
int l,r,id;
int k,b;
} tmp;
int n,m,cnt;
vector<int> buf[MAXN],val[MAXN],g[MAXN];
vector<Seg> ans[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int f(Seg i,int x) { return i.k*x+i.b; }
inline bool gr(Seg a,Seg b,int x) { return f(a,x)>f(b,x); }
Seg query(int t,int now,int l,int r,int k)
{
Seg *x=&ans[t][now];
if (l==r) return *x;
if (k<=mid) tmp=query(t,ls,l,mid,k);
else tmp=query(t,rs,mid+1,r,k);
return f(tmp,k)>f(*x,k)?tmp:*x;
}
void update(int t,int now,int l,int r,Seg add)
{
Seg *x=&ans[t][now];
if (add.l<=l&&r<=add.r)
{
if (!x->id) { *x=add; return; }
if (gr(add,*x,mid)) swap(*x,add);
if (gr(add,*x,l)) update(t,ls,l,mid,add);
if (gr(add,*x,r)) update(t,rs,mid+1,r,add);
return;
}
if (add.l<=mid) update(t,ls,l,mid,add);
if (add.r>mid) update(t,rs,mid+1,r,add);
}
int main()
{
n=read(),m=read();
rep(i,1,n)
rep(j,1,m)
buf[i].push_back(read());
rep(i,1,n)
rep(j,1,m)
val[i].push_back(read());
if (n<=m)
{
rep(i,1,n) ans[i]=vector<Seg>((n+m)<<2);
rep(i,1,n+1) g[i]=vector<int>(m<<1);
rep(i,1,n)
{
rep(j,1,m)
{
update(i,1,0,n+m,(Seg){j-1,n+m,++cnt,buf[i][j-1],g[i][j]+val[i][j-1]-buf[i][j-1]*(i+j-2)});
rep(k,i+1,n) g[k][j]=crq_max(g[k][j],f(query(i,1,0,n+m,k+j-2),k+j-2));
g[i][j+1]=crq_max(g[i][j+1],f(query(i,1,0,n+m,i+j-1),i+j-1));
}
}
printf("%d",g[n][m]+crq_max(0,val[n][m-1]));
}
else
{
rep(i,1,m) ans[i]=vector<Seg>((n+m)<<2);
rep(i,1,n+1) g[i]=vector<int>(m<<1);
rep(i,1,m)
rep(j,1,n)
{
update(i,1,0,n+m,(Seg){j-1,n+m,++cnt,buf[j][i-1],g[j][i]+val[j][i-1]-buf[j][i-1]*(i+j-2)});
rep(k,i+1,m) g[j][k]=crq_max(g[j][k],f(query(i,1,0,n+m,k+j-2),k+j-2));
g[j+1][i]=crq_max(g[j+1][i],f(query(i,1,0,n+m,i+j-1),i+j-1));
}
printf("%d",g[n][m]+crq_max(0,val[n][m-1]));
}
return 0;
}
2020(二)—— 2022.10.5
普及组
A
甚至不如 string 练习题,复杂度为 。
Code
#include <iostream>
#include <string>
#include <cstdio>
using namespace std;
#define rep(i,l,r) for (int i=l;i<=r;i++)
int T,A,B,C,D;
string s;
inline void R()
{
A=B=C=D=0;
cin>>s;
rep(i,0,3)
if (s[i]=='A') A++;
else if (s[i]=='B') B++;
else if (s[i]=='C') C++;
else D++;
if (D>=1||C>=2) printf("failed\n");
else if (D==0&&A>=3) printf("sp offer\n");
else printf("offer\n");
}
int main()
{
cin>>T;
while (T--) R();
return 0;
}
B
按 排序即可,赛时蠢了,按 排序,还写了个二分 + 。
复杂度为 。
Code
#include <algorithm>
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN=1e5+233;
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,ans,A[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
int main()
{
n=read();
rep(i,1,n) A[i]=read();
sort(A+1,A+n+1);
rep(i,1,n)
if (A[n-i+1]>=i-1) ans=i;
else break;
printf("%d",ans);
}
C
贪心快速幂,蠢题。
复杂度为 。
Code
#include <algorithm>
#include <iostream>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
const int mod=1e9+7;
int n,m,x,y,ans,tmp,A[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline bool cmp(int x,int y) { return x>y; }
int ksm(int a,int b,int ret=1)
{
for (;b;b>>=1,a=a*a%mod)
if (b&1) ret=ret*a%mod;
return ret;
}
signed main()
{
n=read(),m=read(),x=read(),y=read();
rep(i,1,n) A[i]=read();
sort(A+1,A+n+1,cmp);
if (m==1)
{
rep(i,1,x) ans=(ans+A[i]*3%mod)%mod;
rep(i,x+1,x+y) ans=(ans+A[i]*2%mod)%mod;
rep(i,x+y+1,n) ans=(ans+A[i])%mod;
printf("%lld",ans);
return 0;
}
rep(i,1,x) ans=(ans+A[i])%mod;
rep(i,x+1,x+y) tmp=(tmp+A[i])%mod;
ans=ans*ksm(3,m)%mod,tmp=tmp*ksm(2,m)%mod;
printf("%lld",(ans+tmp)%mod);
return 0;
}
D
出锅题,只有乘法操作,除 后暴力筛因子即可过,实际上对除 后的数计重再算,才不会超 。
带除(答案可为分数)的话 的做法没问题,对每个质因子取幂次中位数为答案的该质因子幂次即可。
复杂度均为 ,不去重筛质因子那步最坏次数是 ,去重后大因子 只会出现 次而非 次,优化明显。
写个筛可以发现,最坏次数降至约 次,可以通过。
Code
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
#define MAXN (int)(1e6+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,t,top,tot,get,ans,tmp,A[MAXN],cnt[MAXN],sta[MAXN],p[MAXN];
bool is[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
void solve(int n)
{
memset(is,1,sizeof(is));
is[1]=0;
rep(i,2,n)
{
if (is[i]) p[++tot]=i;
for (int j=1;j<=tot&&i*p[j]<=n;++j)
{
is[i*p[j]]=0;
if (!(i%p[j])) break;
}
}
}
inline int gcd(int x,int y) { return y?gcd(y,x%y):x; }
int main()
{
solve(1000);
n=read(),t=A[1]=read();
rep(i,2,n) A[i]=read(),t=gcd(t,A[i]);
rep(i,1,n)
{
A[i]/=t;
if (A[i]<=1000&&is[A[i]]) { ans++; continue; }
if (!cnt[A[i]]) sta[++top]=A[i];
cnt[A[i]]++;
}
rep(i,1,top)
{
tmp=sta[i];
for (int j=1;j<=168&&p[j]*p[j]<=sta[i];j++)
{
get=0;
while (tmp%p[j]==0) tmp/=p[j],get++;
ans+=get*cnt[sta[i]];
if (tmp==1) break;
}
if (tmp>1) ans+=cnt[sta[i]];
}
printf("%d",ans);
return 0;
}
2022(一)—— 2022.10.6
提高组
A
理论复杂度 可过,但是被卡常乐。
好像先二分后 会比先 后二分快。
但是我写的是三分(
瞎调下步长日了过去。
复杂度依旧为 。
可能还打不过爬山算法。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define MAXN (int)(2e3+7)
#define rep(i,l,r) for (int i=l;i<=r;i++)
int a,b,c,d,ans=1e6,f[MAXN];
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int crq_max(int x,int y,int z,int oth) { return crq_max(x,crq_max(y,crq_max(z,oth))); }
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int check(int lc,int ret=1e6)
{
if (f[lc]) return f[lc];
rep(la,0,a)
rep(lb,0,b)
ret=crq_min(ret,crq_max((a-(la+(lb>>1)+(lc>>1)))<<2,(b-((la>>1)+lb+(lc>>2)))<<1,(c-((la>>1)+(lb>>2)+lc))<<1,crq_max(d-((la>>2)+(lb>>1)+(lc>>1)),0))+la+lb+lc);
return f[lc]=ret;
}
int main()
{
cin>>a>>b>>c>>d;
int l=-1,r=c+1;
while (l+1<r)
{
int k=crq_min(crq_max((r-l+1)/3-1,1),(r-l-3)/3+1),tl=l+k,tr=r-k;
int x=check(tl),y=check(tr);
if (x<=y) r=tr;
else l=tl;
ans=crq_min(crq_min(x,crq_min(check(l),check(r))),y);
}
printf("%d",ans);
return 0;
}
B
拆位考虑贡献,显然一个节点有奇数只该位为 的蚂蚁就能产生贡献。
求 ,相当于让一个人只抓奇数个娃娃,另一个人只抓偶数个娃娃,求他们各自所有结果数的差值。
那怎么确定是奇是偶呢?
我们同样假设,这 只玩偶里有一只 crq 很喜欢,需要决定它抓不抓。
我们发现,剩下 只,无论我们抓几只,都可以通过改变 crq 喜欢的一只抓或不抓,使得最后抓的只数一定是奇数或一定是偶数。
所以从 只中抓奇数只或偶数只的结果数都等于从 只中抓任意只的结果数。
根据 ,我们就可以知道,在 只玩偶种,只抓奇数只或只抓偶数只,结果数都是 种。
还要对根节点分讨,烦。
复杂度为 。
Code
#include <algorithm>
#include <iostream>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
struct Edge
{
int to,nex;
} E[MAXN];
const int mod=1e9+7;
int n,cnt,ans,A[MAXN],pw[MAXN],head[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline void add(int u,int v)
{
E[++cnt].to=v;
E[cnt].nex=head[u];
head[u]=cnt;
}
void dfs(int x)
{
int son=1,f,g,sum[31]={};
for (int i=0,t=A[x];t;t>>=1,i++)
if (t&1) sum[i]++;
for (int i=head[x];i;i=E[i].nex)
{
int y=E[i].to;
dfs(y);
for (int j=0,t=A[y];t;t>>=1,j++)
if (t&1) sum[j]++;
son++;
}
if (son==1) return;
f=pw[son-1-(x==1)],g=pw[n-son-(x!=1)];
rep(i,0,29)
if (sum[i])
ans=(ans+f*pw[i+(x==1&&((A[x]>>i)&1)&&sum[i]==1)]%mod*g%mod)%mod;
ans=(ans-A[x]*g%mod)%mod;
if (x!=1)
for (int i=head[x];i;i=E[i].nex)
ans=(ans-A[E[i].to]*g%mod)%mod;
}
signed main()
{
pw[0]=1;
n=read();
rep(i,1,n) A[i]=read(),pw[i]=(pw[i-1]<<1)%mod;
rep(i,2,n) add(read(),i);
dfs(1);
printf("%lld",(ans+mod)%mod);
return 0;
}
C
贪心题,赛时敢不敢写正解属实看胆子了。
小数据是 的 ,记 ,为已选 个字母,有 个 ,第 位选 ,暴力枚举断点转移。
正解枚举 变换次数,头放 尾放 ,中间放类似 这样,剩的 往最后插, 往之前一截一截的 后面插。
复杂度为 。
感觉不如模拟退火。
破案力,这场是Rand Round。
Code
#include <cstdio>
#define rep(i,l,r) for (int i=l;i<=r;i++)
int T,n,m,a,b,c,ans;
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int check(int x,int ret=2)
{
if (!x) ret+=(n-1)/a+(m-1)/b;
else
{
ret+=(x-1)<<1;
if (n-x>=1) ret+=(n-x-1)/a+1;
if (c>=b+1) ret+=(c-1)/b*x;
if (m-c*x>=1)
{
ret++;
int cur=m-c*x-1,y=((c-1)/b+1)*b-c+1;
if (cur/y>=x) ret+=x,cur-=x*y;
else ret+=cur/y,cur%=y;
ret+=cur/b;
}
}
return ret;
}
void R()
{
ans=0;
scanf("%d%d%d%d%d",&n,&m,&a,&b,&c);
rep(i,0,crq_min(n,m/c))
ans=crq_max(ans,check(i));
printf("%d\n",ans);
}
int main()
{
scanf("%d",&T);
while (T--) R();
return 0;
}
D
#1 是 暴力捏。
#2 到 #6 是“不难看出” 维护的是一个常函数 + 一次函数 + 常函数,然后二分断点, 回答询问。
#7 到 #11 是树状数组维护加操作的前缀和, 修改与回答询问。
#12 到 #16 可以 DDP 做,但是这个想法被我赛时掐掉了x
想了另一个:
写棵线段树维护区间加法与区间 就是了, 修改与回答询问。
#17 到 #20 用线段树去维护分段函数的断点。
复杂度也是 的。
可以分块,但是按照基本不懂式,块长小于 ,准确来说是 ,膜一下 。
Why not 根号。——xgf
T4 没码。
2022(二)—— 2022.10.9
提高组
A
类似点分治,经过一条边的次数是它所连子树内关键点与账号的个数差(绝对值)。

为了让你写高精,出题人甚至直接把输入倒了过来。
复杂度为 。
Code
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int crq_abs(int x) { return x<0?-x:x; }
struct Big
{
int len;
int a[114];
void input()
{
char c[114];
scanf(" %s",c);
len=strlen(c);
rep(i,0,len-1) a[i]=c[i]-'0';
rep(i,len,113) a[i]=0;
}
void output() { per(i,len-1,0) putchar(a[i]+'0'); }
} ans;
struct Edge
{
int to,nex;
Big val;
} E[MAXN<<1];
inline Big operator + (Big x,Big y)
{
int up=0;
rep(i,0,crq_max(x.len,y.len)-1) x.a[i]+=y.a[i];
for (int i=0;i<crq_max(x.len,y.len)||up;i++)
{
if (i+1>x.len) x.len=i+1;
x.a[i]+=up;
up=x.a[i]/10;
x.a[i]%=10;
}
return x;
}
inline Big operator * (Big x,int y)
{
int up=0;
rep(i,0,x.len-1) x.a[i]*=y;
for (int i=0;i<x.len||up;i++)
{
if (i+1>x.len) x.len=i+1;
x.a[i]+=up;
up=x.a[i]/10;
x.a[i]%=10;
}
return x;
}
int n,m,A[MAXN],B[MAXN];
int cnt,head[MAXN];
string s;
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline void add(int u,int v,Big w)
{
E[++cnt].to=v;
E[cnt].val=w;
E[cnt].nex=head[u];
head[u]=cnt;
}
inline int rev(int ret=0)
{
cin>>s;
per(i,s.size()-1,0) ret=ret*10+(s[i]-'0');
return ret;
}
void dfs(int x,int f)
{
for (int i=head[x];i;i=E[i].nex)
{
int y=E[i].to;
if (y==f) continue;
dfs(y,x);
A[x]+=A[y],B[x]+=B[y];
ans=ans+E[i].val*crq_abs(A[y]-B[y]);
}
}
signed main()
{
n=read(),m=read();
rep(i,1,m) A[read()]++;
rep(i,1,m) B[read()]++;
rep(i,2,n)
{
int a=read(),b=read();
Big c;
c.input();
add(a,b,c),add(b,a,c);
}
dfs(1,0);
ans.output();
return 0;
}
B
设奶茶价格为 ,假设能单独买它,记浪费的钱为 ,再和一杯价格为 的一起买,浪费的钱就是 。
所以对于单独买浪费钱为 的奶茶,我们找一杯浪费 的来配,并贪心让 尽可能小即可。
然后就变成 map 练习题了,每次配对至少一个价格的奶茶被买光,复杂度为 。
Code
#include <iostream>
#include <cstdio>
#include <map>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
int n,m,ans;
map<int,int> mp;
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
signed main()
{
n=read(),m=read();
rep(i,1,n)
{
int a=read(),b=read();
mp[(m-b%m)%m]+=a;
}
for (auto it=--mp.end();;it--)
{
int x=it->first;
auto head=mp.lower_bound(m-x),tp=head;
while (tp!=mp.end())
{
if (it->second<=0) break;
if (tp==it&&tp->second<=1)
{
tp++;
continue;
}
int t=(tp!=it)?crq_min(tp->second,it->second):(tp->second>>1);
it->second-=t,tp->second-=t;
ans+=((tp->first)+(it->first))%m*t;
if (tp->second<=0)
{
auto lst=tp;
tp++;
mp.erase(lst);
}
else tp++;
}
tp=mp.begin();
while (tp!=head)
{
if (it->second<=0) break;
if (tp==it&&tp->second<=1)
{
tp++;
continue;
}
int t=(tp!=it)?crq_min(tp->second,it->second):(tp->second>>1);
it->second-=t,tp->second-=t;
ans+=((tp->first)+(it->first))%m*t;
if (tp->second<=0)
{
auto lst=tp;
tp++;
mp.erase(lst);
}
else tp++;
}
if (it==mp.begin()) break;
}
printf("%lld",ans);
return 0;
}
C
设 为成绩为 的学生愿意向成绩为 的学生提供帮助的题目数。
值域过大,直接把什么 统统丢去离散化。
然后发现 的变化总次数是 的,直接树状数组维护就好。
复杂度为 。
Code
#include <algorithm>
#include <iostream>
#include <vector>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(1e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define pb push_back
#define mk make_pair
int n,len,tr[MAXN*5],f[MAXN],t[MAXN],a[MAXN],b[MAXN],c[MAXN],d[MAXN];
int ot[MAXN*5],mp[MAXN*5],ans[MAXN];
vector< pair<int,int> > ins[MAXN*5];
vector<int> son[MAXN*5];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline int lb(int x) { return x&-x; }
void add(int x,int k) { while (x<=n*5) tr[x]+=k,x+=lb(x); }
int qry(int x,int ret=0) { while (x) ret+=tr[x],x-=lb(x); return ret; }
signed main()
{
n=read();
rep(i,1,n) f[i]=read();
rep(i,1,n) ot[i]=t[i]=read();
rep(i,1,n) ot[n*3+i]=a[i]=read(),ot[(n<<2)+i]=b[i]=read(),ot[n+i]=c[i]=read(),ot[(n<<1)+i]=d[i]=read();
sort(ot+1,ot+n*5+1);
len=unique(ot+1,ot+n*5+1)-(ot+1);
rep(i,1,n) son[lower_bound(ot+1,ot+len+1,t[i])-ot].pb(i);
rep(i,1,n)
{
ins[lower_bound(ot+1,ot+len+1,c[i])-ot].pb(mk(lower_bound(ot+1,ot+len+1,t[i])-ot,f[i]));
ins[lower_bound(ot+1,ot+len+1,d[i])-ot+1].pb(mk(lower_bound(ot+1,ot+len+1,t[i])-ot,-f[i]));
}
rep(i,1,len)
{
for (auto x:ins[i]) add(x.first,x.second);
for (int x:son[i])
ans[x]=qry(lower_bound(ot+1,ot+len+1,b[x])-ot)-qry(lower_bound(ot+1,ot+len+1,a[x])-ot-1);
}
rep(i,1,n)
{
if (!(a[i]<=t[i]&&t[i]<=b[i]&&c[i]<=t[i]&&t[i]<=d[i])) ans[i]+=f[i];
printf("%lld ",ans[i]);
}
return 0;
}
D
首先痛斥 Haohao 的题面出错,值域是 而不是 ,不然枚举 以内的质因子显然超时。
#1 到 #5, 暴力模拟。
#6 到 #10:
先筛出 内的质数。
对于询问涉及的每个数,我们都进行质因数分解,会产生 个 以内的质因子以及至多一个 以上的质因子。
预处理 以内质因子 的乘法逆元(), 以内的质因子数组计数, 以上的质因子 计数,可以在 复杂度内解决单次询问。
#11 到 #15:
值域很小,筛跑满 也就那点,维护每个因子出现次数前缀和即可,复杂度为 。
#16 到 #20:
最暴力的数学部分分,三个函数都是积性函数, 筛出答案, 作个前缀积,对每个询问就能 应答,注意莫比乌斯函数的 应该输出为 。
#21 到 #25:
用分块维护答案与块中质因子出现次数即可,复杂度为 。
贴一个单点求约数和的式子:
不写分块,所以是 的码。
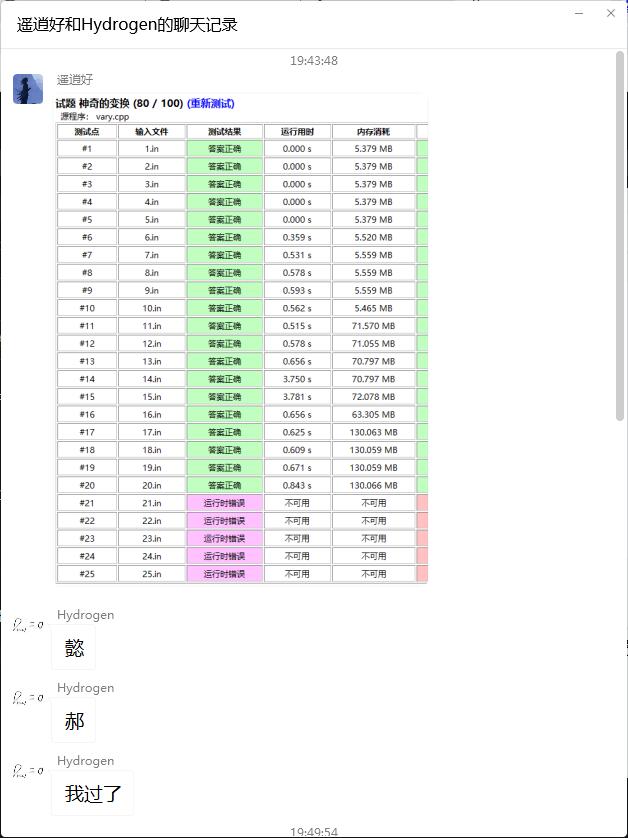

Code(Array)
#include <iostream>
#include <vector>
#include <cstdio>
#include <map>
using namespace std;
#define int long long
#define MAXN (int)(1e7+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
const int mod=1e9+7;
int n,q,mx,type,lst,tot,A[MAXN],sum[MAXN],pref[(int)(1e5+233)][170];
int sta[(int)(1e5+233)],cnt[(int)(1e5+233)];
bool v[MAXN];
vector<int> mu,p,num,d,f,g;
map<int,int> ocnt;
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
void pre(int ed)
{
if (type==1) mu[1]=1;
else if (type==2) d[1]=1;
else f[1]=g[1]=1;
rep(i,2,ed)
{
if (!v[i])
{
v[i]=1,p[++tot]=i;
if (type==1) mu[i]=-1;
else if (type==2) d[i]=2,num[i]=1;
else f[i]=g[i]=i+1;
}
for (int j=1;j<=tot&&i<=ed/p[j];j++)
{
v[p[j]*i]=1;
if (i%p[j]==0)
{
if (type==1) mu[i*p[j]]=0;
else if (type==2)
{
num[i*p[j]]=num[i]+1;
d[i*p[j]]=d[i]/num[i*p[j]]*(num[i*p[j]]+1);
}
else
{
g[i*p[j]]=g[i]*p[j]+1;
f[i*p[j]]=f[i]/g[i]*g[i*p[j]];
}
break;
}
else
{
if (type==2)
{
num[i*p[j]]=1;
d[i*p[j]]=d[i]<<1;
}
else if (type==3)
{
f[i*p[j]]=f[i]*f[p[j]];
g[i*p[j]]=p[j]+1;
}
}
if (type==1) mu[i*p[j]]=-mu[i];
}
}
}
int ksm(int a,int b,int ret=1)
{
for (;b;b>>=1,a=a*a%mod)
if (b&1) ret=ret*a%mod;
return ret;
}
void R2()
{
const int N=1e3+233;
p=vector<int>(N);
if (type==1) mu=vector<int>(N);
else if (type==2) num=vector<int>(N),d=vector<int>(N);
else f=vector<int>(N),g=vector<int>(N);
pre((int)1e3+123);
int top=0,inv[N];
rep(i,1,tot) inv[i]=ksm(p[i]-1,mod-2);
rep(i,1,q)
{
ocnt.clear();
int l=read(),r=read();
l^=lst,r^=lst;
lst=1;
rep(j,l,r)
{
int tmp=A[j];
for (int k=1;k<=tot&&p[k]<=tmp;k++)
while (tmp%p[k]==0)
{
if (!cnt[k]) sta[++top]=k;
tmp/=p[k],cnt[k]++;
}
if (tmp!=1) ocnt[tmp]++;
}
while (top>0)
{
if (type==1)
{
if (cnt[sta[top]]>=2) lst=0;
else lst*=-1;
}
else if (type==2) lst=lst*(cnt[sta[top]]+1ll)%mod;
else lst=lst*(ksm(p[sta[top]],cnt[sta[top]]+1ll)-1ll)%mod*inv[sta[top]]%mod;
cnt[sta[top]]=0;
top--;
}
for (auto x:ocnt)
{
if (type==1)
{
if (x.second>=2) lst=0;
else lst*=-1;
}
else if (type==2) lst=lst*(x.second+1ll)%mod;
else lst=lst*(ksm(x.first,x.second+1ll)-1ll)%mod*ksm(x.first-1ll,mod-2)%mod;
}
lst=(lst%mod+mod)%mod;
printf("%lld\n",lst);
}
}
void R3()
{
const int N=1e3+7;
p=vector<int>(N);
if (type==1) mu=vector<int>(N);
else if (type==2) num=vector<int>(N),d=vector<int>(N);
else f=vector<int>(N),g=vector<int>(N);
pre((int)(1e3));
rep(i,1,n)
rep(j,1,tot)
{
pref[i][j]=pref[i-1][j];
int tmp=A[i];
while (tmp%p[j]==0) tmp/=p[j],pref[i][j]++;
}
rep(i,1,q)
{
int l=read(),r=read();
l^=lst,r^=lst;
lst=1;
if (type==1)
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j]>=2) lst=0;
else if (pref[r][j]-pref[l-1][j]) lst*=-1;
}
else if (type==2)
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j])
lst=lst*(pref[r][j]-pref[l-1][j]+1)%mod;
}
else
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j])
lst=lst*(ksm(p[j],pref[r][j]-pref[l-1][j]+1)-1)%mod*ksm(p[j]-1,mod-2)%mod;
}
lst=(lst+mod)%mod;
printf("%lld\n",lst);
}
}
void R4()
{
p=vector<int>(MAXN);
if (type==1) mu=vector<int>(MAXN);
else if (type==2) num=vector<int>(MAXN),d=vector<int>(MAXN);
else f=vector<int>(MAXN),g=vector<int>(MAXN);
pre((int)(1e7));
rep(i,1,q)
{
int l=read(),r=read(),x;
l^=lst,r^=lst;
x=sum[r]*ksm(sum[l-1],mod-2)%mod;
if (type==1) lst=(mu[x]+mod)%mod;
else if (type==2) lst=d[x];
else lst=f[x];
printf("%lld\n",lst);
}
}
signed main()
{
n=read(),q=read(),type=read();
sum[0]=1;
rep(i,1,n) A[i]=read(),sum[i]=sum[i-1]*A[i]%mod,mx=crq_max(mx,A[i]);
if (n<=1e3) R2();
else if (mx<=1e3) R3();
else R4();
return 0;
}
在计算静态内存的评测机上,上面这份 Code 是会喜提 MLE 的,下面是 vector 版的 Code。
Code(Vector)
#include <iostream>
#include <vector>
#include <cstdio>
#include <map>
using namespace std;
#define int long long
#define MAXN (int)(1e7+7)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
const int mod=1e9+7;
int n,q,mx,type,lst,tot;
signed A[MAXN],sum[MAXN];
bool v[MAXN];
vector<char> mu;
vector<signed> num,d,p,f,g,sta,cnt,pref[(int)(1e5+7)];
map<int,int> ocnt;
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int crq_max(int x,int y) { return x>y?x:y; }
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
void pre(int ed,bool t)
{
if (t)
{
if (type==1) mu[1]=1;
else if (type==2) d[1]=1;
else f[1]=g[1]=1;
}
rep(i,2,ed)
{
if (!v[i])
{
v[i]=1,p[++tot]=i;
if (t)
{
if (type==1) mu[i]=-1;
else if (type==2) d[i]=2,num[i]=1;
else f[i]=g[i]=i+1;
}
}
for (int j=1;j<=tot&&i<=ed/p[j];j++)
{
v[p[j]*i]=1;
if (i%p[j]==0)
{
if (t)
{
if (type==1) mu[i*p[j]]=0;
else if (type==2)
{
num[i*p[j]]=num[i]+1;
d[i*p[j]]=d[i]/num[i*p[j]]*(num[i*p[j]]+1);
}
else
{
g[i*p[j]]=g[i]*p[j]+1;
f[i*p[j]]=f[i]/g[i]*g[i*p[j]];
}
}
break;
}
else
{
if (t)
{
if (type==2)
{
num[i*p[j]]=1;
d[i*p[j]]=d[i]<<1;
}
else if (type==3)
{
f[i*p[j]]=f[i]*f[p[j]];
g[i*p[j]]=p[j]+1;
}
}
}
if (t&&type==1) mu[i*p[j]]=-mu[i];
}
}
}
int ksm(int a,int b,int ret=1)
{
for (;b;b>>=1,a=a*a%mod)
if (b&1) ret=ret*a%mod;
return ret;
}
void R2()
{
const int N=1e3+7;
p=vector<signed>(N);
sta=vector<signed>(n+7);
cnt=vector<signed>(n+7);
pre((int)1e3+3,0);
int top=0,inv[N];
rep(i,1,tot) inv[i]=ksm(p[i]-1,mod-2);
rep(i,1,q)
{
ocnt.clear();
int l=read(),r=read();
l^=lst,r^=lst;
lst=1;
rep(j,l,r)
{
int tmp=A[j];
for (int k=1;k<=tot&&p[k]<=tmp;k++)
while (tmp%p[k]==0)
{
if (!cnt[k]) sta[++top]=k;
tmp/=p[k],cnt[k]++;
}
if (tmp!=1) ocnt[tmp]++;
}
while (top>0)
{
if (type==1)
{
if (cnt[sta[top]]>=2) lst=0;
else lst*=-1;
}
else if (type==2) lst=lst*(cnt[sta[top]]+1ll)%mod;
else lst=lst*(ksm(p[sta[top]],cnt[sta[top]]+1ll)-1ll)%mod*inv[sta[top]]%mod;
cnt[sta[top]]=0;
top--;
}
for (auto x:ocnt)
{
if (type==1)
{
if (x.second>=2) lst=0;
else lst*=-1;
}
else if (type==2) lst=lst*(x.second+1ll)%mod;
else lst=lst*(ksm(x.first,x.second+1ll)-1ll)%mod*ksm(x.first-1ll,mod-2)%mod;
}
lst=(lst%mod+mod)%mod;
printf("%lld\n",lst);
}
}
void R3()
{
const int N=1e3+7;
p=vector<signed>(N);
pre((int)(1e3),0);
pref[0]=vector<signed>(170);
rep(i,1,n)
{
pref[i]=vector<signed>(170);
rep(j,1,tot)
{
pref[i][j]=pref[i-1][j];
int tmp=A[i];
while (tmp%p[j]==0) tmp/=p[j],pref[i][j]++;
}
}
rep(i,1,q)
{
int l=read(),r=read();
l^=lst,r^=lst;
lst=1;
if (type==1)
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j]>=2) lst=0;
else if (pref[r][j]-pref[l-1][j]) lst*=-1;
}
else if (type==2)
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j])
lst=lst*(pref[r][j]-pref[l-1][j]+1)%mod;
}
else
{
rep(j,1,tot)
if (pref[r][j]-pref[l-1][j])
lst=lst*(ksm(p[j],pref[r][j]-pref[l-1][j]+1)-1)%mod*ksm(p[j]-1,mod-2)%mod;
}
lst=(lst+mod)%mod;
printf("%lld\n",lst);
}
}
void R4()
{
p=vector<signed>(MAXN);
if (type==1) mu=vector<char>(MAXN);
else if (type==2) num=vector<signed>(MAXN),d=vector<signed>(MAXN);
else f=vector<signed>(MAXN),g=vector<signed>(MAXN);
pre((int)(1e7),1);
rep(i,1,q)
{
int l=read(),r=read(),x;
l^=lst,r^=lst;
x=sum[r]*ksm(sum[l-1],mod-2)%mod;
if (type==1) lst=(mu[x]+mod)%mod;
else if (type==2) lst=d[x];
else lst=f[x];
printf("%lld\n",lst);
}
}
signed main()
{
// freopen("vary.in","r",stdin);
// freopen("vary.out","w",stdout);
n=read(),q=read(),type=read();
sum[0]=1;
rep(i,1,n) A[i]=read(),sum[i]=sum[i-1]*(int)A[i]%mod,mx=crq_max(mx,A[i]);
if (n<=1e3) R2();
else if (mx<=1e3) R3();
else R4();
return 0;
}
2022(三)—— 2022.10.12
提高组
是 No DS Round,某种意义上来说,赛前奶中了三题(但是花样挂分了)。
A
一眼结论题,选的一对一定是排序后相邻的一对,然后可以 DP 或反悔贪心。
复杂度为 或 。
DP
#include <algorithm>
#include <cstdio>
#define MAXN 5007
#define rep(i,l,r) for (int i=l;i<=r;i++)
int n,m,A[MAXN],f[MAXN][MAXN];
int mi(int x,int y) { return x<y?x:y; }
int main()
{
scanf("%d%d",&n,&m);
rep(i,1,n) scanf("%d",A+i);
std::sort(A+1,A+n+1);
rep(i,1,n)
rep(j,1,m)
f[i][j]=1e9;
rep(i,2,n)
rep(j,1,i>>1)
f[i][j]=mi(f[i-1][j],f[i-2][j-1]+A[i]-A[i-1]);
printf("%d",f[n][m]);
return 0;
}
反悔贪心
#include <functional>
#include <algorithm>
#include <iostream>
#include <cstdio>
#include <queue>
using namespace std;
#define MAXN 5007
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define mk make_pair
int n,m,ans,A[MAXN],d[MAXN],lst[MAXN],nxt[MAXN];
bool vis[MAXN];
priority_queue<pair<int,int>,vector< pair<int,int> >,greater< pair<int,int> >> q;
inline int crq_min(int x,int y) { return x<y?x:y; }
inline int crq_abs(int x) { return x<0?-x:x; }
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline void ins(pair<int,int> x)
{
int l=lst[x.second],r=nxt[x.second];
vis[l]=vis[r]=1;
lst[x.second]=lst[l],nxt[lst[l]]=x.second;
nxt[x.second]=nxt[r],lst[nxt[r]]=x.second;
d[x.second]=(l&&r)?(d[l]+d[r]-d[x.second]):(int)(1e9);
q.push(mk(d[x.second],x.second));
}
int main()
{
n=read(),m=read();
rep(i,1,n) A[i]=read();
sort(A+1,A+n+1);
rep(i,1,n-1) d[i]=crq_abs(A[i+1]-A[i]),lst[i]=i-1,nxt[i]=i+1;
nxt[n-1]=0;
rep(i,1,n-1) q.push(mk(d[i],i));
rep(i,1,m)
{
while (vis[q.top().second]) q.pop();
ans+=q.top().first;
ins(q.top());
q.pop();
}
printf("%d",ans);
return 0;
}
B
分讨题,显然要么从后面拿一个小的插到最前面的 那里,要不然在前面抽掉一个数,使得后面有一个更小的数顶上来。
然后对 与 ,与可能插到 里的数的大小关系分讨。
刚开始想的用 set 维护可能插到 里的数。后面发现 set 的操作都可以用队列替代,复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define MAXN (int)(2e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
int T,n,A[MAXN],suf[MAXN],arr[MAXN<<1];
bool vis[MAXN];
struct Que
{
int s,t;
int *q;
inline void clear(int a[]) { s=MAXN,t=s-1; q=a; }
inline int front() { return *(q+s); }
inline void pop_front() { s++; }
inline void push_back(int x) { *(q+(++t))=x; }
} que;
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
void R()
{
n=read();
que.clear(arr);
rep(i,1,n) vis[i]=0;
rep(i,1,n) vis[A[i]=read()]=1;
rep(i,1,n)
if (!vis[i]) que.push_back(i);
else vis[i]=0;
suf[n+1]=A[n+1]=n+1;
per(i,n,1)
if (A[i]&&A[i]<A[suf[i+1]]) suf[i]=i;
else suf[i]=suf[i+1];
rep(i,1,n)
{
if ((i==n)||(A[i]&&A[i+1]&&A[i]>A[i+1]))
{
A[i]=-1;
break;
}
if (!A[i])
{
if (A[suf[i]]<que.front())
{
A[suf[i]]=-1;
break;
}
}
else if (!A[i+1])
{
int x=que.front();
if (A[i]<x&&A[i]) x=A[i];
if (x<A[i])
{
A[i]=-1;
break;
}
}
if (!A[i]) que.pop_front();
}
que.clear(arr);
rep(i,1,n)
{
if (A[i]==-1) continue;
if (A[i]) vis[A[i]]=1;
}
rep(i,1,n) if (!vis[i]) que.push_back(i);
rep(i,1,n)
{
if (A[i]==-1) continue;
if (A[i]) printf("%d ",A[i]);
else printf("%d ",que.front()),que.pop_front();
}
putchar('\n');
}
int main()
{
T=read();
while (T--) R();
return 0;
}
C
显然,一个点集在树上的斯坦纳树就是这个点集在这棵树上的虚树。
当虚树上有一个虚点的度大于等于 时,乱搞做法就会将至少一条边重复经过,答案就是错误的。
所以问题转变为虚树上是否存在度大于等于 的虚点。
两种写法:如果点集正着拓展要记得以 为根;倒着删点要记得删去度为 的虚点时把两头的实点连上。
度为 的连通块合并为一个点算,当连通块内至少一个点被选入点集,这个连通块合并的点就被选入点集。
我写的是倒着删点的做法。
Code
#include <iostream>
#include <vector>
#include <cstdio>
using namespace std;
#define MAXN (int)(5e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
struct Edge
{
int to,nex;
} E[MAXN<<1];
struct Con
{
int to,nex;
bool w;
} G[MAXN<<1];
int n,vir,P[MAXN],cut[MAXN],siz[MAXN],top[MAXN],deg[MAXN];
int cnt,tot,head[MAXN],fir[MAXN];
bool ans[MAXN],isv[MAXN],del[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline void add(int u,int v)
{
E[++cnt].to=v;
E[cnt].nex=head[u];
head[u]=cnt;
}
inline void add(int u,int v,bool w)
{
G[++tot].to=v;
G[tot].nex=fir[u];
G[tot].w=w;
fir[u]=tot;
}
void dfs(int x,int tf)
{
top[x]=tf,siz[tf]++;
for (int i=fir[x];i;i=G[i].nex)
{
int y=G[i].to;
bool w=G[i].w;
if (top[y]) continue;
if (!w) dfs(y,tf);
else add(tf,y),add(y,tf),deg[tf]++,deg[y]++,dfs(y,y);
}
}
void JI(int x)
{
int a=0,b=0;
del[x]=1;
for (int i=head[x];i;i=E[i].nex)
{
int y=E[i].to;
if (del[y]) continue;
if (a) b=y;
else a=y;
deg[y]--;
}
if (deg[x]==2) add(a,b),add(b,a),deg[a]++,deg[b]++;
for (int i=head[x];i;i=E[i].nex)
{
int y=E[i].to;
if (del[y]) continue;
if (deg[y]<=2&&isv[y])
{
vir--,isv[y]=0;
JI(y);
}
}
}
signed main()
{
n=read();
rep(i,2,n)
{
int a=read(),b=read();
bool c=read();
add(a,b,c),add(b,a,c);
}
dfs(1,1);
rep(i,1,n) P[i]=read();
per(i,n,1)
{
ans[i]=(vir==0);
int x=top[P[i]];
cut[x]++;
if (cut[x]==siz[x])
{
if (deg[x]>=3) vir++,isv[x]=1;
else JI(x);
}
}
rep(i,1,n) printf("%d",ans[i]);
return 0;
}
D
赛时没看,赛后发现题解挺阴间的,自己口胡一发得了。
记 为包含 个点,直径长为 ,有 条直径,深度为 的无标号有根二叉树。
记 为包含 个点,直径长为 ,有 条直径,深度为 的无标号有根多叉树。
记 为 的约数个数。
的递推复杂度相同。
发现我们可以对 做一次 两维独立, 二维前缀和,将 的转移优化。
的转移复杂度降至 , 转移复杂度不变。
对于 ,有 。
所以 的转移复杂度已经可以接受,再来考虑 的优化。
md 我不会。
然后你会发现这个式子假了,可能合出同构的无标号无根树。
比如下面两个 序列:
遗憾离场,什么 玩意。
2022(四)—— 2022.10.16
提高组
A
XOR-Hashing,XOR Hashing [TUTORIAL]。
LOJ 上有道 Trick 一样的:LOJ 6187 Odd。
用了 map,所以是 ,可以做到 。
B
Hint 1
我们的跳跃流程一定是在一个当前可达的子段和最大的段内反复横跳(可能是 次),再跳到子段和更大的段内反复横跳,直到步数跳完或者没有比当前横跳子段的子段和更大的子段。
Hint 2
在奇数跳跃中,我们跳到一个点;下一次跳跃,一定跳到这个点作为右端点,子段和最大子段的左端点处。
Hint 3
我们只会在向右跳跃时更新当前可能会反复横跳的子段。
换句话说,我们不可能在向左跳时去更新当前要横跳的子段,否则上次向右跳时直接跳到该子段的右端点更优。
Solution
所以,我们可以 DP 向右跳到点 的最少操作次数 ,以该次数抵达点 时的最大得分 ,点 作为右端点的最大子段和 。
对于跳满 次,我们用 更新答案。
对于不跳满 次,我们用 更新答案。
可以发现,对于 显然有 均为奇数,所以可以考虑设初态 ,更新答案时记得考虑 对答案的贡献就好。
注意 为负不可转移。
时间复杂度为 。
C
原题就没什么好讲了。
DFS 过程中,满 块即合并,剩到根的再作一块,复杂度为 。
D
Hint 1
区间循环右移就是把这个区间中间切一刀,左右互换,显然用 FHQ Treap 很好做。
Hint 2
对于维护是否存在二元上升子序列,我们只要维护区间是否存在二元上升子序列,区间 ,区间 即可。
Hint 3
三元上升子序列呢?
很自然的想法是在维护区间 ,区间 的基础上再维护区间内二元上升子序列的首位 与末位 ,区间内是否存在三元上升子序列。
Hint 4
怎么维护它们的合并?
不妨记区间内二元上升子序列的首位 为 ,末位 为 。
当区间存在三元上升子序列时,我们完全可以不理它们,因为答案一定为 YES。
当区间不存在三元上升子序列时,对于整个二元上升子序列在单棵子树内的情况,直接对应更新即可。
对于二元上升子序列一部分在左子树,一部分在右子树的情况,因为区间内不存在三元上升子序列,以右子树中的 作为二元上升子序列的末位时,左子树小于 的元素非严格递减。
相对应的,以左子树中的 作为二元上升子序列的首位时,右子树大于 的元素非严格递减。
Solution
利用 Hint 4,我们可以找出左子树中最左侧的小于 的元素来更新 ,右子树中最右侧的大于 的元素来更新 。
因为维护了区间 与区间 ,对于更新 的过程,我们可以在区间 时向左子树查找,否则向右子树查找;更新 反之。
查找复杂度为 ,所以算法总时间复杂度为 。
2022(五)—— 2022.10.20
提高组
A
初中数学题, 为圆心与直线的垂线的垂足到圆心距离减去半径, 为两头到圆心距离最大值加上半径。
复杂度为 。
Code
#include <algorithm>
#include <iostream>
#include <cstdio>
#include <cmath>
using namespace std;
#define ld long double
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
int T;
ld xa,ya,xb,yb,xc,yc,r,k,xd,yd;
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline ld dis(ld xa,ld ya,ld xb,ld yb) { return sqrtl((xa-xb)*(xa-xb)+(ya-yb)*(ya-yb)); }
inline ld ca(ld x,ld y) { return x>y?x:y; }
inline void R()
{
scanf("%LF %LF %LF %LF %LF %LF %LF",&xa,&ya,&xb,&yb,&xc,&yc,&r);
if (ya!=yb&&xa!=xb)
{
k=(yb-ya)/(xb-xa);
xd=(k*xa+xc/k-ya+yc)/(k+1.0/k);
yd=k*(xd-xa)+ya;
printf("%.2LF ",dis(xc,yc,xd,yd)-r);
}
else if (ya==yb) printf("%.2LF ",ca(ya-yc,yc-ya)-r);
else printf("%.2LF ",ca(xa-xc,xc-xa)-r);
printf("%.2LF\n",ca(dis(xa,ya,xc,yc),dis(xb,yb,xc,yc))+r);
}
int main()
{
T=read();
while (T--) R();
return 0;
}
B
记答案数组为 ,每个红绿灯对答案的影响是 。
发现每次操作如果答案数组发生变化, 变为至多 块,之后的答案一定也是相同的,可以用铁砂掌把答案数组拍到链表上,减少更新答案次数。
对于不发生变化的情况,,判一下直接 continue 就好。
复杂度为 。
Code
#include <iostream>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(2e5+233)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
int n,m,ng=1,pre,A[MAXN],val[MAXN],nxt[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
int gcd(int x,int y) { return y?gcd(y,x%y):x; }
signed main()
{
n=read(),m=read();
rep(i,1,m) A[i]=read();
rep(i,1,n) nxt[i]=i+1,val[i]=i;
nxt[0]=1;
rep(i,1,m)
{
if (ng%A[i])
{
int x=0;
ng=(val[1]/A[i]+(val[1]%A[i]!=0))*A[i],pre=0;
while ((x=nxt[x])<=n)
{
val[x]=(val[x]/A[i]+(val[x]%A[i]!=0))*A[i];
ng=gcd(ng,val[x]);
if (val[x]==val[pre]) nxt[pre]=nxt[x];
else pre=x;
}
}
}
int x=0;
while ((x=nxt[x])<=n)
rep(i,x,nxt[x]-1) printf("%lld ",val[x]);
return 0;
}
C
关键 Trick 在于 。
我也不会证。
讲一下赛时怎么猜的。
对于 的情况进行讨论。
显然有 。
对于 ,一个元素钦定被选,其它元素有 种情况,答案为 。
对于 ,大小为 的子集 有 个, 个,答案为 ,二项式定理揉一揉就是 。
以此类推,有 。
试图摆脱掉 的限制,把一个 换成 看看,发现有 ,就这么草率的胡出来了。
然后就是把这个式子搞成 DP 做,类似背包,记 为已考虑 个元素,选取元素和为 的情况对 的贡献,,第一维可以滚掉。
复杂度为 。
Code
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
#define int long long
#define MAXN (int)(1e4+7)
#define rep(i,l,r) for (int i=l;i<=r;i++)
#define per(i,r,l) for (int i=r;i>=l;i--)
const int mod=1e9+7;
int T,n,m,k,A[MAXN],f[MAXN];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline int ksm(int a,int b,int ret=1)
{
for (;b;b>>=1,a=a*a%mod)
if (b&1) ret=ret*a%mod;
return ret;
}
inline void R()
{
memset(f,0,sizeof(f));
n=read(),m=read(),k=read();
rep(i,1,n) A[i]=read();
f[0]=ksm(k,n);
int ik=ksm(k,mod-2);
rep(i,1,n)
per(j,m,A[i])
f[j]=(f[j]+f[j-A[i]]*ik%mod)%mod;
printf("%lld\n",f[m]);
}
signed main()
{
T=read();
while (T--) R();
return 0;
}
D
最小值最大,果断二分。
发现 check 不会写,时限除掉一个多测一个二分剩的还挺多,考虑随机化骗分。
先把元素按 分组后排序,随机化要选的元素的 序列,可以 完成一发检验,搞个 unordered_map 去重,每次 check 跑个 可以保证不超时。
骗了 55,前两个点都没过,补个暴搜就 65。
Add:把 unordered_map 删了,达成理论 90,unordered_map __都不用。

Code(含 \#1 与 \#2)
#include <algorithm>
#include <iostream>
#include <cstring>
#include <random>
#include <cstdio>
#include <ctime>
using namespace std;
#define MAXN (int)(1e4+7)
#define rep(i,l,r) for (register int i=l;i<=r;i++)
#define per(i,r,l) for (register int i=r;i>=l;i--)
mt19937 rd(time(0));
vector<int> v[MAXN];
int T,n,k,tp,cnt,A[MAXN],B[MAXN];
bool vis[MAXN];
int pool[MAXN];
int cmp[5];
inline int read()
{
int x=0,f=1;char c;
while (!isdigit(c=getchar())) if (c=='-') f=-1;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f*x;
}
inline void swp(int &x,int &y) { int t=x;x=y,y=t; }
bool check2(int x)
{
rep(a,1,cnt)
rep(b,1,cnt)
{
if (b==a) continue;
rep(c,1,cnt)
{
if (c==b||c==a) continue;
rep(d,1,cnt)
{
if (d==c||d==b||d==a) continue;
rep(e,1,cnt)
{
if (e==d||e==c||e==b||e==a) continue;
cmp[0]=pool[a],cmp[1]=pool[b],cmp[2]=pool[c],cmp[3]=pool[d],cmp[4]=pool[e];
int lst=v[cmp[0]][0];
rep(j,1,k-1)
{
auto it=lower_bound(v[cmp[j]].begin(),v[cmp[j]].end(),lst+x);
if (it!=v[cmp[j]].end())
{
if (j==k-1) return 1;
else lst=*it;
}
else break;
}
}
}
}
}
return 0;
}
bool check(int x)
{
double tb=clock();
if (n<=100) return check2(x);
while (((double)clock()-tb)/CLOCKS_PER_SEC<0.06)
{
rep(i,1,MAXN)
{
rep(j,0,k-1)
{
int t=rd()%(cnt-j)+1;
cmp[j]=pool[t];
swp(pool[t],pool[cnt-j]);
}
int lst=v[cmp[0]][0];
rep(j,1,k-1)
{
auto it=lower_bound(v[cmp[j]].begin(),v[cmp[j]].end(),lst+x);
if (it!=v[cmp[j]].end())
{
if (j==k-1) return 1;
else lst=*it;
}
else break;
}
}
}
return 0;
}
inline void R()
{
n=read(),k=read(),tp=read();
rep(i,1,n) A[i]=read(),B[i]=read();
cnt=0;
rep(i,1,n) vis[i]=0;
rep(i,1,n) if (!vis[A[i]]) vis[A[i]]=1,pool[++cnt]=A[i];
rep(i,1,cnt) v[pool[i]].clear();
rep(i,1,n) v[A[i]].push_back(B[i]);
rep(i,1,cnt) sort(v[pool[i]].begin(),v[pool[i]].end());
int l=0,r=1e6+1;
while (l<r)
{
int mid=(l+r+1)>>1;
if (check(mid)) l=mid;
else r=mid-1;
}
printf("%d\n",l);
}
int main()
{
T=read();
while (T--) R();
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现