Jieba库使用和好玩的词云
jieba(结巴)是一个强大的分词库,完美支持中文分词
一、
结巴分词分为三种模式:精确模式(默认)、全模式和搜索引擎模式
精确模式:试图将句子最精确地切开,适合文本分析;
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
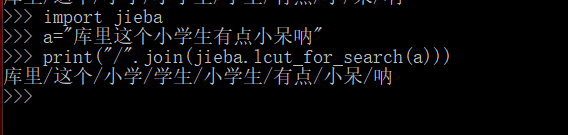
首先尝试一下精确模式

Perfect!
接下来试试全模式
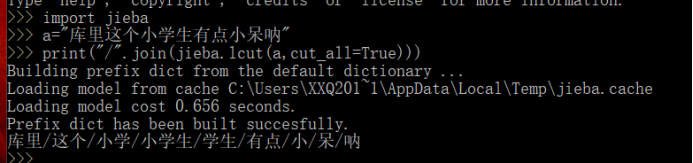
emmmm小学生分成三个部分
然后是搜索引擎模式
def get_text(): txt = open("English.txt", "r", encoding='UTF-8').read() txt = txt.lower() for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格 return txt file_txt = get_text() words = file_txt.split() # 对字符串进行分割,获得单词列表 counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) for i in range(5): word, count = items[i] print("{0:<5}->{1:>5}".format(word, count))
选择了一篇英语六级考试的阅读理解,然后用着代码去计算里面一些长度的词的个数
结果如下:

二、
词云的制作
完成安装jieba , wordcloud ,matplotlib
(1)打开taglue官网,点击import words,把运行的结果copy过来。
(2)选择形状,在这里是网上下载的图片进行的导入。
(3)选择字体。
(4)点击Visualize生成图片。
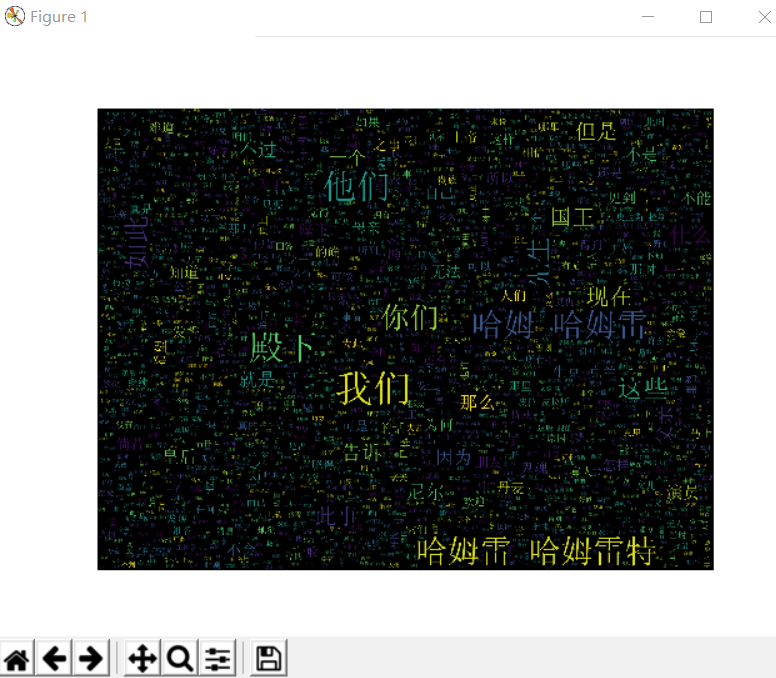
from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba def create_word_cloud(filename): text = open("哈姆雷特.txt".format(filename)).read() wordlist = jieba.cut(text, cut_all=True) wl = " ".join(wordlist) wc = WordCloud( background_color="black", max_words=2000, font_path='simsun.ttf', height=1200, width=1600, max_font_size=100, random_state=100, ) myword = wc.generate(wl) plt.imshow(myword) plt.axis("off") plt.show() wc.to_file('img_book.png') if __name__ == '__main__': create_word_cloud('mytext')
这里选择了一篇哈姆雷特
运行后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号