【大数据】Hadoop实验报告
链接地址:【大数据】Hadoop实验报告
实验一 熟悉常用的Linux操作和Hadoop操作
1.实验目的
Hadoop运行在Linux系统上,因此,需要学习实践一些常用的Linux命令。本实验旨在熟悉常用的Linux操作和Hadoop操作,为顺利开展后续其他实验奠定基础。
2.实验平台
- 操作系统:Linux;
- Hadoop版本:2.7.1。
3.实验内容和要求
(一)熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
(1)切换到目录 /usr/local

(2)切换到当前目录的上一级目录

(3)切换到当前登录Linux系统的用户的自己的主文件夹

ls命令:查看文件与目录
(4)查看目录/usr下所有的文件

mkdir命令:新建新目录
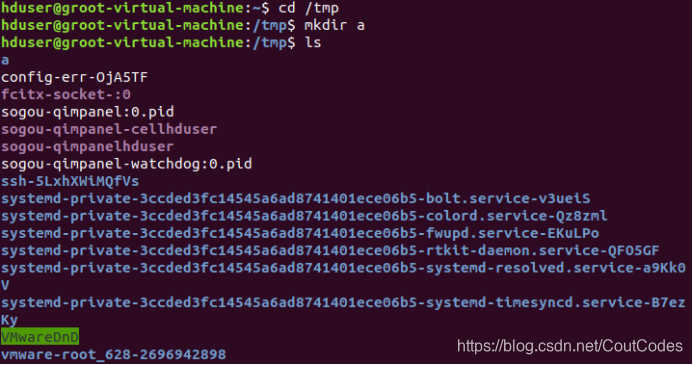
(5)进入“/tmp”目录,创建一个名为“a”的目录,并查看“/tmp”目录下已经存在哪些目录
(6)进入“/tmp”目录,创建目录“a1/a2/a3/a4”

rmdir命令:删除空的目录
(7)将上面创建的目录a(在“/tmp”目录下面)删除

(8)删除上面创建的目录“a1/a2/a3/a4” (在“/tmp”目录下面),然后查看“/tmp”目录下面存在哪些目录

cp命令:复制文件或目录
(9)将当前用户的主文件夹下的文件.bashrc复制到目录“/usr”下,并重命名为bashrc1

(10)在目录“/tmp”下新建目录test,再把这个目录复制到“/usr”目录下

mv命令:移动文件与目录,或更名字
(11)将“/usr”目录下的文件bashrc1移动到“/usr/test”目录下

(12)将“/usr”目录下的test目录重命名为test2

rm命令:移除文件或目录
(13)将“/usr/test2”目录下的bashrc1文件删除
$ sudo rm /usr/test2/bashrc1

(14)将“/usr”目录下的test2目录删除
$ sudo rm –r /usr/test2

cat命令:查看文件内容
(15)查看当前用户主文件夹下的.bashrc文件内容

tac命令:反向查看文件内容
(16)反向查看当前用户主文件夹下的.bashrc文件的内容

more命令:一页一页翻动查看
(17)翻页查看当前用户主文件夹下的.bashrc文件的内容

head命令:取出前面几行
(18)查看当前用户主文件夹下.bashrc文件内容前20行

(19)查看当前用户主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行

tail命令:取出后面几行
(20)查看当前用户主文件夹下.bashrc文件内容最后20行
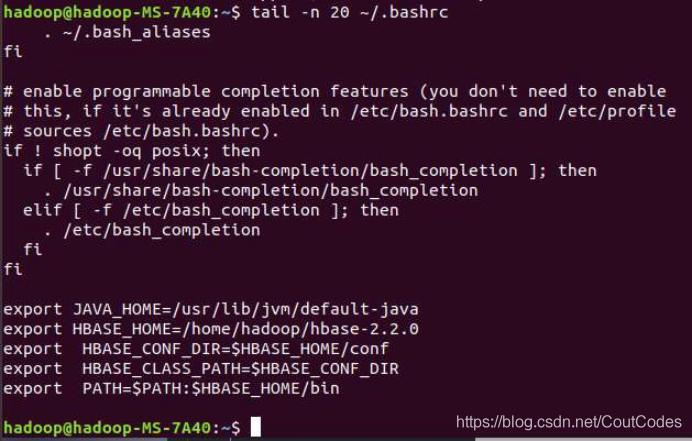
(21) 查看当前用户主文件夹下.bashrc文件内容,并且只列出50行以后的数据

touch命令:修改文件时间或创建新文件
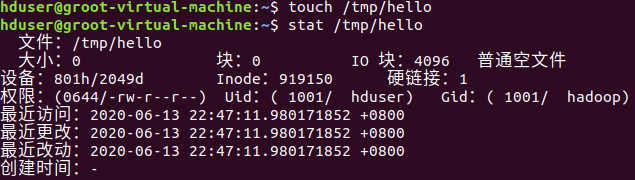
(22)在“/tmp”目录下创建一个空文件hello,并查看文件时间
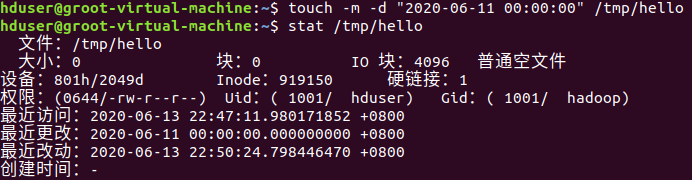
(23)修改hello文件,将文件时间整为5天前
chown命令:修改文件所有者权限
(24)将hello文件所有者改为root帐号,并查看属性

find命令:文件查找
(25)找出主文件夹下文件名为.bashrc的文件

tar命令:压缩命令
(26)在根目录“/”下新建文件夹test,然后在根目录“/”下打包成test.tar.gz
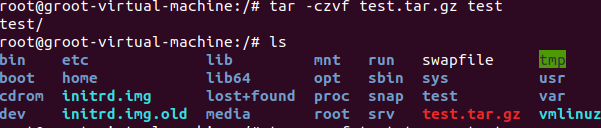
(27)把上面的test.tar.gz压缩包,解压缩到“/tmp”目录
$ sudo tar -zxv -f /test.tar.gz -C /tmp

grep命令:查找字符串
(28)从“~/.bashrc”文件中查找字符串'examples'

(29)请在“~/.bashrc”中设置,配置Java环境变量
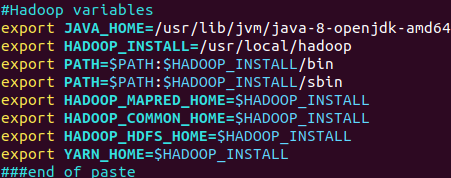
(30)查看JAVA_HOME变量的值

(二)熟悉常用的Hadoop操作
(31)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/usr/local/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/hadoop”

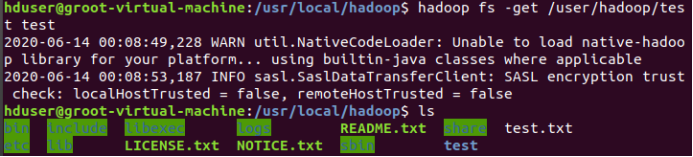
(32)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表

(33)将Linux系统本地的“~/.bashrc”文件上传到HDFS的test文件夹中,并查看test

(34)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下
实验二 熟悉常用的HDFS操作
1.实验目的
- 理解HDFS在Hadoop体系结构中的角色;
- 熟练使用HDFS操作常用的Shell命令;
2.实验平台
- 操作系统:Linux(建议Ubuntu16.04);
- Hadoop版本:2.7.1;
- JDK版本:1.7或以上版本;
- Java IDE:Eclipse。
3.实验步骤
(一)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务:
(1)向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;
Shell命令:
追加到末尾
hadoop fs -appendToFile /usr/local/hadoop/test.txt /user/text.txt
覆盖原文件
hadoop fs -copyFromLocal -f /usr/local/hadoop/test.txt /user/text.txt
Java代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
public static boolean test(Configuration conf, String path) throws IOException { FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath); fs.copyFromLocalFile(false, true, localPath, remotePath);
fs.close();
}
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FileInputStream in = new FileInputStream(localFilePath);
FSDataOutputStream out = fs.append(remotePath);
byte[] data = new byte[1024];
int read = -1;
while ( (read = in.read(data)) > 0 ) { out.write(data, 0, read);
}
out.close(); in.close(); fs.close();
}
public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/home/hadoop/text.txt";
String remoteFilePath = "/user/hadoop/text.txt";
String choice = "append";
String choice = "overwrite";
try {
Boolean fileExists = false;
if (HDFSApi.test(conf, remoteFilePath)) {
fileExists = true;
System.out.println(remoteFilePath + " 已存在.");
} else {
System.out.println(remoteFilePath + " 不存在.");
}
if ( !fileExists) { // 文件不存在,则上传
HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已上传至 " + remoteFilePath);
} else if ( choice.equals("overwrite") ) { // 选择覆盖
HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);
} else if ( choice.equals("append") ) { // 选择追加
HDFSApi.appendToFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已追加至 " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
(2)从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
Shell命令:
if $(hadoop fs -test -e /usr/local/hadoop/test.txt);
then $(hadoop fs -copyToLocal /user/test.txt /usr/local/hadoop/test.txt);
else $(hadoop fs -copyToLocal /user/test.txt /usr/local/hadoop/test2.txt);
Java代码:
Import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
public static void copyToLocal(Configuration conf, String remoteFilePath, localFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
File f = new File(localFilePath);
if(f.exists()) {
System.out.println(localFilePath + " 已存在.");
Integer i = 0;
while (true) {
f = new File(localFilePath + "_" + i.toString());
if (!f.exists()) {
localFilePath = localFilePath + "_" + i.toString();
break;
}
}
System.out.println("将重新命名为: " + localFilePath); ());
} Path localPath = new Path(localFilePath);
fs.copyToLocalFile(remotePath, localPath);
fs.close();
}
public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/home/hadoop/text.txt";
String remoteFilePath = "/user/hadoop/text.txt";
try {
HDFSApi.copyToLocal(conf, remoteFilePath, localFilePath);
System.out.println("下载完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(3)将HDFS中指定文件的内容输出到终端中;
Shell命令:
hadoop fs -cat text.txt
Java代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.*;
public class HDFSApi {
/**
* 读取文件内容
*/
public static void cat(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataInputStream in = fs.open(remotePath);
BufferedReader d = new BufferedReader(new InputStreamReader(in)); String line = null;
while ( (line = d.readLine()) != null ) {
System.out.println(line);
}
d.close(); in.close(); fs.close();
}
public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/user/local/hadoop/text.txt"; // HDFS 路径
try {
System.out.println("读取文件: " + remoteFilePath);
HDFSApi.cat(conf, remoteFilePath);
System.out.println("\n 读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(4)显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
Shell命令:
hadoop fs -ls -h /user/test.txt
Java代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.*; import java.text.SimpleDateFormat;
public class HDFSApi {
public static void ls(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath); FileStatus[] fileStatuses = fs.listStatus(remotePath); for (FileStatus s : fileStatuses) {
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = format.format(timeStamp);
System.outprintln("时间: " + date); } fs.close();
}
public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/text.txt";
try {
System.out.println("读取文件信息: " + remoteFilePath);
HDFSApi.ls(conf, remoteFilePath);
System.out.println("\n 读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(5)给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
Shell命令:
hadoop fs -ls -R -h /user
Java代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.*;
import java.text.SimpleDateFormat;
public class HDFSApi {
/**
* 显示指定文件夹下所有文件的信息(递归)
*/
public static void lsDir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
/* 递归获取目录下的所有文件 */
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);
/* 输出每个文件的信息 */
while (remoteIterator.hasNext()) {
FileStatus s = remoteIterator.next();
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = format.format(timeStamp);
System.out.println("时间: " + date);
System.out.println();
} fs.close();
}
/**
* 主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteDir = "/user/hadoop"; // HDFS 路径
try {
System.out.println("(递归)读取目录下所有文件的信息: " + remoteDir);
HDFSApi.lsDir(conf, remoteDir);
System.out.println("读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(6)提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
Shell命令:
if $(hadoop fs -test -d /dir1/dir2);
then $(hadoop fs -touch /dir1/dir2/filename)
else $(hadoop fs -mkdir -p /dir1/dir2 && hdfs dfs -touch /dir1/dir2/filename)
Java代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*;
import java.i;
public class HDFSApi {
public static boolean test(Configuration conf, String path) throws IOException { FileSystem fs = FileSystem.get(conf); return fs.exists(new Path(path));
}
public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf); Path dirPath = new Path(remoteDir); boolean result = fs.mkdirs(dirPath); fs.close(); return result;
}
public static void touchz(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream outputStream = fs.create(remotePath); outputStream.close(); fs.close();
}
public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); boolean result = fs.delete(remotePath, false); fs.close(); return result;
}
public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/input/text.txt"; // HDFS 路径
String remoteDir = "/user/hadoop/input"; // HDFS 路径对应的目录
try {
/* 判断路径是否存在,存在则删除,否则进行创建 */
if ( HDFSApi.test(conf, remoteFilePath) ) {
HDFSApi.rm(conf, remoteFilePath); // 删除
System.out.println("删除路径: " + remoteFilePath);
} else {
if ( !HDFSApi.test(conf, remoteDir) ) { // 若目录不存在,则进行创建
HDFSApi.mkdir(conf, remoteDir);
System.out.println("创建文件夹: " + remoteDir);
}
HDFSApi.touchz(conf, remoteFilePath);
System.out.println("创建路径: " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
(7)提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
Shell命令:
创建目录的命令如下:
$ ./bin/hdfs dfs –mkdir –p dir1/dir2
删除目录的命令如下:
$ ./bin/hdfs dfs –rmdir dir1/dir2
强制删除非空目录的命令如下:
$ ./bin/hdfs dfs –rm –R dir1/dir2
Java代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
public static boolean test(Configuration conf, String path) throws IOException { FileSystem fs = FileSystem.get(conf); return fs.exists(new Path(path));
}
public static boolean isDirEmpty(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true); return !remoteIterator.hasNext();
}
public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf); Path dirPath = new Path(remoteDir); boolean result = fs.mkdirs(dirPath); fs.close(); return result;
}
public static boolean rmDir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
boolean result = fs.delete(dirPath, true); fs.close(); return result;
}
public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteDir = "/user/hadoop/input"; // HDFS 目录
Boolean forceDelete = false; // 是否强制删除
try {
/* 判断目录是否存在,不存在则创建,存在则删除 */
if ( !HDFSApi.test(conf, remoteDir) ) {
HDFSApi.mkdir(conf, remoteDir); // 创建目录
System.out.println("创建目录: " + remoteDir);
} else {
if ( HDFSApi.isDirEmpty(conf, remoteDir) || forceDelete ) {
HDFSApi.rmDir(conf, remoteDir);
System.out.println("删除目录: " + remoteDir);
} else { // 目录不为空
System.out.println("目录不为空,不删除: " + remoteDir);
}
}
} catch (Exception e) {
e.printStackTrace(); } } }
(8)向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
Shell命令:
追加带文件末尾:
hadoop fs -appendToFile /usr/local/hadoop/test.txt /user/test.txt
追加到文件开头:
hadoop fs -get text.txt
cat text.txt >> local.txt
hadoop fs -copyFromLocal -f text.txt text.txt
Java代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
public static boolean test(Configuration conf, String path) throws IOException { FileSystem fs = FileSystem.get(conf); return fs.exists(new Path(path));
}
public static void appendContentToFile(Configuration conf, String content, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream out = fs.append(remotePath);
out.write(content.getBytes()); out.close(); fs.close();
}
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FileInputStream in = new FileInputStream(localFilePath);
FSDataOutputStream out = fs.append(remotePath);
byte[] data = new byte[1024]; int read = -1; while ( (read = in.read(data)) > 0 ) { out.write(data, 0, read);
} out.close();
in.close();
fs.close();
}
public static void moveToLocalFile(Configuration conf, String remoteFilePath, String localFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath); Path localPath = new Path(localFilePath); fs.moveToLocalFile(remotePath, localPath);
}
public static void touchz(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream outputStream = fs.create(remotePath); outputStream.close(); fs.close();
}
public static void main(String[] args) {
Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 文件
String content = "新追加的内容\n";
String choice = "after";
String choice = "before";
try {
if ( !HDFSApi.test(conf, remoteFilePath) ) {
System.out.println("文件不存在: " + remoteFilePath);
} else {
if ( choice.equals("after") ) { // 追加在文件末尾
HDFSApi.appendContentToFile(conf, content, remoteFilePath);
System.out.println("已追加内容到文件末尾" + remoteFilePath);
} else if ( choice.equals("before") ) {
String localTmpPath = "/user/hadoop/tmp.txt";
HDFSApi.moveToLocalFile(conf, remoteFilePath, localTmpPath);
HDFSApi.touchz(conf, remoteFilePath);
HDFSApi.appendContentToFile(conf, content, remoteFilePath);
HDFSApi.appendToFile(conf, localTmpPath, remoteFilePath);
System.out.println("已追加内容到文件开头: " + remoteFilePath);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
(9)删除HDFS中指定的文件;
Shell命令:
hadoop fs -rm -R /user/test.txt
Java代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath); boolean result = fs.delete(remotePath, false); fs.close(); return result;
}
public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 文件
try {
if ( HDFSApi.rm(conf, remoteFilePath) ) {
System.out.println("文件删除: " + remoteFilePath);
} else {
System.out.println("操作失败(文件不存在或删除失败)");
}
} catch (Exception e) {
e.printStackTrace();
}
} }
(10)在HDFS中,将文件从源路径移动到目的路径。
Shell命令:
hadoop fs -mv /user/hadoop/test/test.txt /user
Java代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public static boolean mv(Configuration conf,remoteToFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path srcPath = new Path(remoteFilePath);
Path dstPath = new Path(remoteToFilePath);
boolean result = fs.rename(srcPath, dstPath);
fs.close();
return result;
}
public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "hdfs:///user/hadoop/text.txt"; // 源文件 HDFS 路径
String remoteToFilePath = "hdfs:///user/hadoop/new.txt"; // 目的 HDFS 路径
try {
if ( HDFSApi.mv(conf, remoteFilePath, remoteToFilePath) ) {
System.out.println(" 将文件 " + remoteFilePath + " 移动到 " +remoteToFilePath);
} else {
System.out.println("操作失败(源文件不存在或移动失败)");
}
} catch (Exception e) {
e.printStackTrace();
} } }
实验三 熟悉常用的HBase操作
1.实验目的
- 理解HBase在Hadoop体系结构中的角色;
- 熟练使用HBase操作常用的Shell命令;
2.实验平台
- 操作系统:Linux(建议Ubuntu16.04);
- Hadoop版本:2.7.1;
- HBase版本:1.1.5;
- JDK版本:1.7或以上版本;
- Java IDE:Eclipse。
3.实验步骤
(一)编程实现以下指定功能,并用Hadoop提供的HBase Shell命令完成相同任务:
(1)列出HBase所有的表的相关信息,例如表名;
shell语句:
List
Java 代码:
public static void listTables() throws IOException { init();//建立连接
HTableDescriptor hTableDescriptors[] = admin.listTables(); for(HTableDescriptor hTableDescriptor :hTableDescriptors){
System.out.println("表名:"+hTableDescriptor.getNameAsString());
}
close();//关闭连接
}
(2)在终端打印出指定的表的所有记录数据;
shell语句:
scan ‘s1’
结果:
Java代码:
public static void getData(String tableName)throws IOException{ init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan); for (Result result:scanner){ printRecoder(result);
} close();
}
//打印一条记录的详情
public static void printRecoder(Result result)throws IOException{ for(Cell cell:result.rawCells()){
System.out.print("行健: "+new String(CellUtil.cloneRow(cell)));
System.out.print("列簇: "+new String(CellUtil.cloneFamily(cell)));
System.out.print(" 列: "+new String(CellUtil.cloneQualifier(cell)));
System.out.print(" 值: "+new String(CellUtil.cloneValue(cell)));
System.out.println("时间戳: "+cell.getTimestamp()); }
}
(3)向已经创建好的表添加和删除指定的列族或列;
shell语句
put 's1',zhangsan','Score:Math','69'
Java代码:
public static void insertRow(String tableName,String rowKey,String colFamily,String col,String val) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put(rowKey.getBytes()); put.addColumn(colFamily.getBytes(), col.getBytes(), val.getBytes()); table.put(put); table.close(); close();
}
insertRow("s1",'zhangsan','score','Math','69')
public static void deleteRow(String tableName,String rowKey,String colFamily,String col) throws IOException { init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(rowKey.getBytes());
delete.addFamily(Bytes.toBytes(colFamily));
delete.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col)); table.delete(delete); table.close(); close();
}
deleteRow("s1",'zhangsan','score','Math') ;
(4)清空指定的表的所有记录数据;
shell语句:
truncate ‘s1’
Java代码:
public static void clearRows(String tableName)throws IOException{
init();
TableName tablename = TableName.valueOf(tableName);
admin.disableTable(tablename);
admin.deleteTable(tablename);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
admin.createTable(hTableDescriptor);
close();
}
(5)统计表的行数。
shell语句:
count 's1'
Java代码:
public static void countRows(String tableName)throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
int num = 0;
for (Result result = scanner.next();result!=null;result=scanner.next()){
num++;
}
System.out.println("行数:"+ num);
scanner.close();
close();
}
实验四 MapReduce/Spark编程初级实践
1.实验目的
- 通过实验掌握基本的MapReduce/Spark编程方法;
- 掌握用MapReduce/Spark解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
2.实验平台
- 操作系统:Linux(建议Ubuntu16.04)
- Hadoop版本:2.7.1
- Spark版本2.0以上
3.实验步骤
(一)编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件A和B合并得到的输出文件C的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
Java代码
package com.Merge;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
public class Merge {
/**
* @param args
* 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
*/
//重载map函数,直接将输入中的value复制到输出数据的key上
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text text = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
text = value;
context.write(text, new Text(""));
}
}
//重载reduce函数,直接将输入中的key复制到输出数据的key上
public static class Reduce extends Reducer<Text, Text, Text, Text>{ public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException,InterruptedException{
context.write(key, new Text(""));
} }
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{"input","output"}; /* 直接设置输入参数
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and duplicate removal"); job.setJarByClass(Merge.class); job.setMapperClass(Map.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(二)编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
输入文件1的样例如下:
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
Java代码如下:
package com.MergeSort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
public class MergeSort {
public static class Map extends Mapper<Object, Text, IntWritable, IntWritable>{
private static IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException{
String text = value.toString(); data.set(Integer.parseInt(text));
context.write(data, new IntWritable(1));
} }
public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
private static IntWritable line_num = new IntWritable(1);
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{ for(IntWritable val : values){ context.write(line_num, key);
line_num = new IntWritable(line_num.get() + 1);
} } }
Partiton ID
public static class Partition extends Partitioner<IntWritable, IntWritable>{ public int getPartition(IntWritable key, IntWritable value, int num_Partition){
int Maxnumber = 65223;
int bound = Maxnumber/num_Partition+1; int keynumber = key.get(); for (int i = 0; i<num_Partition; i++){ if(keynumber<bound * (i+1) && keynumber>=bound * i){
return i; }
}
return -1;
} }
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{"input","output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and sort"); job.setJarByClass(MergeSort.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setPartitionerClass(Partition.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); }
}
(三)对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
Java代码
package com.simple_data_mining;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class simple_data_mining { public static int time = 0;
public static class Map extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException{
String child_name = new String();
String parent_name = new String();
String relation_type = new String();
String line = value.toString(); int i = 0;
while(line.charAt(i) != ' '){ i++;
}
String[] values = {line.substring(0,i),line.substring(i+1)}; if(values[0].compareTo("child") != 0){
child_name = values[0];
parent_name = values[1];
relation_type = "1";
context.write(new Text(values[1]),
new Text(relation_type+"+"+child_name+"+"+parent_name));
relation_type = "2";
context.write(new Text(values[0]), new Text(relation_type+"+"+child_name+"+"+parent_name));
} } }
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException{
if(time == 0){
context.write(new Text("grand_child"), new
Text("grand_parent"));
time++;
}
int grand_child_num = 0;
String grand_child[] = new String[10]; int grand_parent_num = 0;
String grand_parent[]= new String[10]; Iterator ite = values.iterator();
while(ite.hasNext()){
String record = ite.next().toString();
int len = record.length(); int i = 2;
if(len == 0) continue;
char relation_type = record.charAt(0);
String child_name = new String();
String parent_name = new String();
while(record.charAt(i) != '+'){
child_name = child_name + record.charAt(i);
i++;
}
i=i+1;
while(i<len){
parent_name = parent_name+record.charAt(i);
i++;
}
if(relation_type == '1'){
grand_child[grand_child_num] = child_name;
grand_child_num++;
}
else{
grand_parent[grand_parent_num] = parent_name;
grand_parent_num++;
} }
if(grand_parent_num != 0 && grand_child_num != 0 ){
for(int m = 0;m<grand_child_num;m++){ for(int n=0;n<grand_parent_num;n++){
context.write(new Text(grand_child[m]), new
Text(grand_parent[n]));
} } } } }
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{"input","output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Single table join"); job.setJarByClass(simple_data_mining.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} }
如有不足之处,还望指正 [1]。
如果对您有帮助可以点赞、收藏、关注,将会是我最大的动力 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号