微服务分布式协调Zookeeper选举原理总结
 本文主要总结了Zookeeper分布式协调选举的原理。
本文主要总结了Zookeeper分布式协调选举的原理。
一、分布式协调机制引用的场景
- 各个节点的数据一致性
- 保证任务只在一个节点上执行
最小节点(最先注册的节点)拿到执行权了之后,其他节点便没有权利执行。 - 如果一个节点挂了,怎么保证其他节点立刻知晓,并接替任务。
- 存在共享资源,互斥性,安全性如何保证。
二、zookeeper的设计
- 防止单点故障
集群方案(leader,follower).还能分担请求 - 每个节点的数据是一致的(必须要有leader)
leader,master; - leader选举机制,数据恢复
- 如何保证数据一致性?(分布式事务)
改进版本的2PC协议
结论:
- zab来实现选举:
集群内选举leader来调度简化集群的复杂度, - 为什么要做集群:
保证zookeeper协调工具的高性能和高可用(热备,同步) - 2pc做数据一致性:
引入了协调者(leader)和参与者(follower)的概念,具体见下方。
三、zookeeper集群
改进版的2PC事务:
- follower:处理读请求,转发写请求给leader
- leader接收到事务请求后会转发提议给集群中的每一个节点(observer除外)
- follwer节点收到提议后响应,返回ack
- leader收到过半节点响应ack,便会提交事务(commit),给客户端一个response。反之会执行回滚。
- 事务提交后会同步给Observer
3种角色特性:
- leader:集群的核心,起到了主导整个集群的作用,事务请求的调度和处理。
- follower:处理客户端的非事务请求,转发事务请求,参与事务的投票过程,参与leader选举投票
- observer:观察者角色,了解集群中的状态变化,进行状态同步。可以响应非事务请求。
备注:observer与follwer工作原理一致,区别是不参与事务请求的投票,投票会影响性能。当引入更多节点提升性能时候,多投票,多网络请求,但observer可以在不投票不增加网络请求的情况下提升性能,所以引入了observer。
节点数:2n+1节点,至少n+1个可用,满足投票机制过半机制的需要,所以是最少三个,奇数节点。
四、ZAB协议
ZAB(zookeeper atomic Broadcast)协议是为分布式协调服务zookeeper专门设计的一种支持崩溃恢复的原子广播协议,主要用于实现分布式数据一致性,通过主备模式的系统架构来保持集群中各个副本之间的数据一致性。
4.1 ZAB协议的两个基本模式,也是zab核心:
-
崩溃恢复:
-
原子广播:
场景:
当整个集群第一次启动,或者当leader节点出现网络中断或崩溃时,zab协议会起作用,进入恢复模式,重新选leader,选举完毕,leader节点得到集中群过半节点的响应(数据同步)便会恢复响应,
follwer节点选举成leader节点时候之后需要进行数据同步,数据同步完成,zab协议退出恢复模式,
此时进入原子广播模式,新的leader节点开始接收事务请求进行广播转发提议。
4.1.1 原子广播实现原理(消息广播):
事务提交的详细过程(实际上是一个简化版本的2pc提交过程):
-
当leader收到事务请求,会给每个请求(包括事务与非事务请求)生成一个zxid(64位自增id)
-
将带有zxid的消息作为一个propose(提案/提议)分发给集群中的每个follwer节点
-
每个follwer节点会把收到的propose写入磁盘,写入成功返回ack.
-
leader收到合法数量的请求(过半ack),再发起commit请求给每个follwer节点。
-
leader收到过半commit请求响应之后会直接响应客户端,不再等其他节点
注意:
投票是所有节点参与的,leader自己也不例外
但所有投票过程不需要observer ,但observer必须要和leader节点保持数据同步,保证正确的处理非事务请求。
4.1.2 崩溃恢复实现原理(恢复leader节点和恢复数据):
(1) 什么时候就会进入崩溃恢复阶段?
- 当leader失去了过半的follwer节点的联系
- 当leader服务自己挂了
(2)数据恢复要注意的点:
-
已经被处理的消息不能丢失原则
场景:
首先,leader收到合法数量follower的ack之后,会向各个follower广播commit命令,同时自己也会commit这条事务,但是:
当leader发起commit广播之后,follower收到commit请求之前(并非所有节点都受到commit请求),leader挂掉了怎么办?
此时zab协议要保证已经被处理的消息不能丢失。 -
被丢弃的消息不能再次出现原则
场景:
当leader收到事务请求,并且还未发起事务投票之前,leader挂了。怎么办?
旧的leader带领的上个朝代没有提交的事务会被全部丢弃。
此时zab协议要保证被丢弃的消息不能再出现。
( 3 ) zab的设计思想:
为了满足上面的两个原则,zab做了如下的设计:
-
zxid(消息id)是最大的。(新选举的leader的zxid是最大的,保证当前节点的消息是最新的)。比如leader挂了之后,follwer1收到了commit请求,follwer1的zxid就是最新的,最大的,follwer2没有收到commit请求,zxid不是最大的,选举时候依旧选举zxid是最大的那个节点作为leader,follwer1的提交之前的commit请求可以保证数据时最新的,不丢失,由此满足了上面的第一条原则。
-
epoch的概念,每产生一个leader,那么新的leader的epoch会+1,zxid是64位的数据,低32位表示消息计数器(自增),高32位(存储epoch编号)。tips:epoch概念可以联想各个朝代皇帝的年号。
tips:
新选举的leader的epoch会比上一轮leader的epoch高,这样保证上一轮leader再起来之后本一轮不会被选举成为leader,而变成了一个follwer,而且旧的leader的zxid会小于新leader的zxid,新的leader继任之后会把旧的leader所有没提交的事务清除,由此满足了上面的第二条原则。
五、Leader选举
基于fastleader选举:
-
选举指标:
zxid最大(64位)
myid (服务器id,sid; myid越大,在leader选举机制中的权重越大) -
选举阶段:
启动时
运行时崩溃后 -
选举状态:
looking(初始化选举过程)
leading
following
observing -
选举过程:
(1)启动时初始化
每个节点都初始化自己的myid,zxid,epoch
检查zxid(启动时zxid都为0)
myid较大会作为leader
统计投票
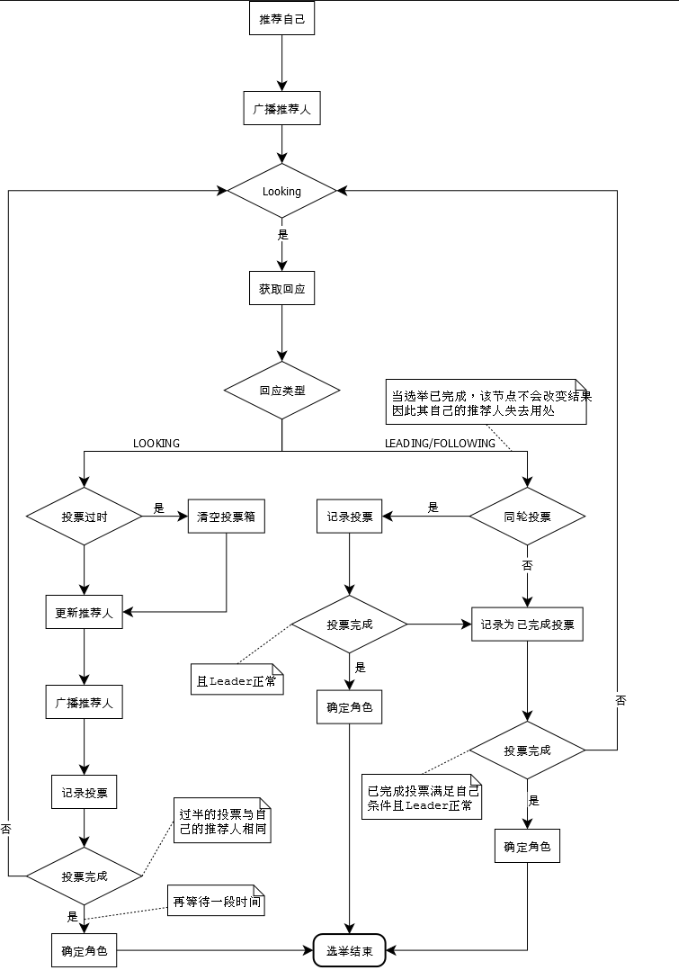
(2)投票过程:
1.检查节点状态是looking时投票给自己
投票逻辑源码在FastLeaderElection类的lookforleader(),可以自己再细看源码
- 各个节点互相广播vode信息(myid,zxid,epoch)
- 先判断epoch,再判断zxid,再判断myid
- 胜出的投票会更新到当前的结果中。
- 继续广播,让其他节点知道自己现在的票据(告诉别人胜出的那个票据信息)。
- epoch更新,进行下一轮选举
- 如果收到的消息epoch小于当前节点的epoch,则忽略这条消息(忽略旧的投票参数)
- epoch相同时比较zxid,myid,如果胜出就更新自己的票据,并发出广播
- 投票的结果都蠢到本机的投票集合中,用来判断是不是超过半数
投票过程的流程图:
本文转载自: CSDN Hepburn Yang的博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号