分布式一致性Hash算法
介绍一致性Hash算法之前,先简单回顾一下分布式以及Hash算法,便于理解为什么要有一致性Hash算法。
分布式
当我们也无需求很复杂时,单台机器IO以及带宽等都会成为瓶颈,所以对业务进行拆分,部署在不同的机器上,当有请求访问时,根据某些特点将这些请求分散到各个服务器上,这所有的服务器组成的网络,我们称之为集群,这能提高服务器的性能以及利用率。
如果有一个请求过来存数据,调度器将数据存在了A服务器上,下次客户端再来请求这份数据,该如何迅速判断数据存在哪台服务器呢?这时候引出了哈希的概念。
哈希函数
对于一个函数:
如果两个哈希值是不相同的,那么这两个哈希值的原始输入也是不相同的。这个特性是哈希函数具有确定性的结果,具有这种性质的哈希函数称为单向哈希函数。
但另一方面,哈希函数的输入和输出不是唯一对应关系的,如果两个哈希值相同,两个输入值很可能是相同的,但也可能不同,如果值相同称为“哈希碰撞(collision)”,这通常是两个不同长度的输入值,刻意计算出相同的输出值。输入一些数据计算出哈希值,然后部分改变输入值,一个具有强混淆特性的哈希函数会产生一个完全不同的哈希值。哈希函数是不可逆的,也就是没法根据哈希值来反推输入值。
那么对于集群而言,每一个请求都有一个标识ID,如果构造标识到服务器的哈希函数,就可以让同一请求固定的达到服务器,因为ID是不变的:
为了均匀分布在不同的服务器上,这是一个跟服务器数量N有关的哈希函数,常见的有取模运算,即:
但是这时候有个问题,由于是集群,那么服务器数量可能会有变化,例如今天请求量非常大要增加服务器数量,N变大之后,原有的Hash值就失效了,需要重新对存储的请求值做哈希,由于请求值是一个庞大的数据集.这样造成了巨大的不便,需要改进我们的Hash算法。这时候引出了一致性Hash的思路。
一致性Hash
一致性哈希的思路是,将哈希函数与服务器数量解绑,如果我们用16个二进制标识哈希值,那么哈希值有一个范围区间\([0,65536]\),我们将这个区间65536平均分成N份,N是服务器数量:
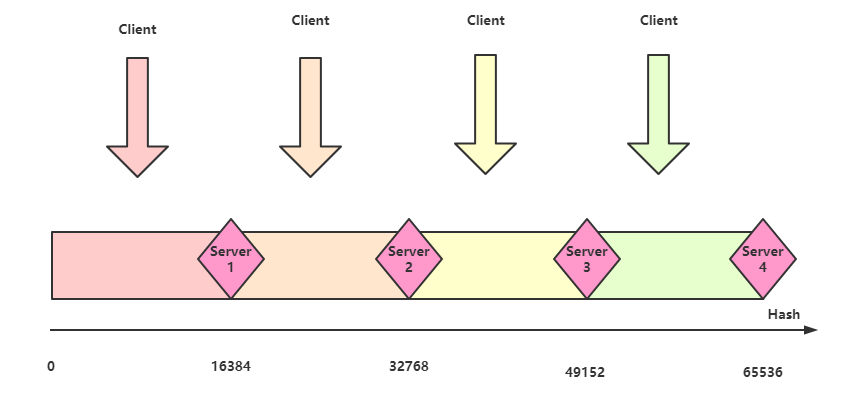
假设服务器数量是4,那么对于所有请求,当请求哈希值介于\([0,16384]\)之间时,将请求分配到Server 1,如果请求哈希值介于\((16384,32768]\)之间时,将请求分配到Server 2,后面同理,这样做有一个什么好处呢,如果这时候需要新增加一个服务器,假设是Server 5:

那么需要重新计算Hash值的仅仅为\([0,8192]\)这部分请求,将其分配到Server 5上。
虚拟节点的引入
我们已经知道,添加和删除节点都会影响缓存数据的分布。尽管hash算法具有分布均匀的特性,但是当集群中server数量很少时,他们可能在环中的分布并不是特别均匀,进而导致缓存数据不能均匀分布到所有的server上,例如都分配在某一个或几个哈希区间,那么有很多服务器可能就没在这个分布式系统中提供作用。
为解决这个问题,需要使用虚拟节点, 虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。另外,如果每个实际server节点的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号