缓存与缓存一致性协议
前言
先引入一下场景,大家都知道CPU速度奇快,之前一直以为大概就比内存高一个数量级吧,后面了解了才知道,CPU与内存的速度差异,比人跟蜗牛的还大,CPU一个时钟周期不高于10纳秒,约等于\(10^{-8}\)秒,什么概念呢,如果以光速运行,\(3 * 10 ^{8} m/s\),光能走的距离也就二三十厘米而已,想想,你在这儿坐着,等着蜗牛往这儿运东西你开始工作,能行吗。
计算机底层很多设计都是为了IO而生,为了解决CPU与内存之间速度不匹配的问题,为了解决CPU与内存不匹配的问题,根据离CPU距离的远近分配了缓存(Cache),特点是越近缓存的越小,速度越快。
Cache存储数据是固定大小为单位的,称为一个Cache entry,这个单位称为Cache line(缓存行)或Cache block(缓存块)。给定Cache容量大小和Cache line size的情况下,它能存储的条目个数(number of cache entries)就是固定的。因为Cache是固定大小的,所以它从DRAM(动态随机存取存储器)获取数据也是固定大小。
对于X86来讲,它的Cache line大小与DDR3、4一次访存能得到的数据大小是一致的,即64Bytes。对于ARM来讲,较旧的架构(新的不知道有没有改)的Cache line是32Bytes,但一次内存访存只访问一半的数据也不太合适,所以它经常是一次填两个Cache line,叫做double fill。
通常L1和L2缓存都是每个CPU一个的, L1缓存有分为L1i和L1d,分别用来存储指令和数据。L2缓存是不区分指令和数据的。L3缓存多个核心共用一个,通常也不区分指令和数据。L1,2,3关系如图所示:
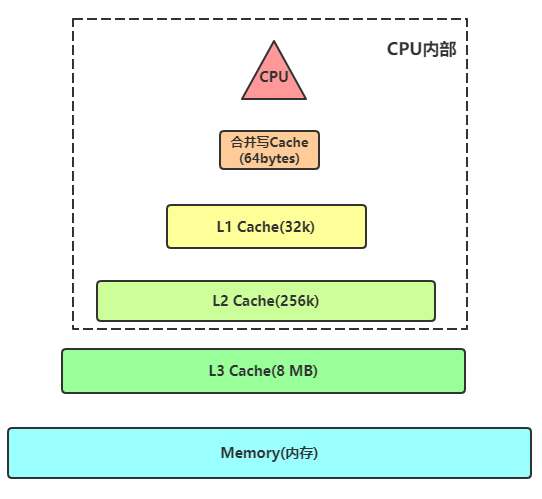
CPU从Cache拿数据的最小单位是字节,Cache从Memory拿数据的最小单位是64Bytes,Memory从硬盘拿数据通常最小是4092Bytes。
替换策略
Cache里存的数据是Memory中的常用数据一个拷贝,Cache比较小,不可以缓存Memory中的所有数据。当Cache存满后,再需要存入一个新的条目时,就需要把一个旧的条目从缓存中拿掉,这个过程称为evict,一个被evict的条目称为victim。缓存管理单元通过一定的算法决定哪些数据有资格留在Cache里,哪些数据需要从Cache里移出去。这个策略称为替换策略(replacement policy)。最简单的替换策略称为LRU(least recently used,其他策略可以参考:常见页面置换算法图解),即Cache管理单元记录每个Cache line最近被访问的时间,每次需要evict时,选最近一次访问时间最久远的那一条做为victim。在实际使用中,LRU并不一定是最好的替换策略,在CPU设计的过程中,通常会不段对替换策略进行改进,每一款芯片几乎都使用了不同的替换策略。
写入策略与一致性
CPU需要读写一个地址的时候,先去Cache中查找,如果数据不在Cache中,称为Cache miss,就需要从Memory中把这个地址所在的那个Cache line上的数据加载到Cache中。然后再把数返回给CPU。这时会伴随着另一个Cache 条目成为victim被替换出去。如果CPU需要访问的数据在Cache中,则称为Cache hit。
针对写操作,有两种写入策略,分别为write back和write through。write through策略下,数据直接同时被写入到Memory中,在write back策略中,数据仅写到Cache中,此时Cache中的数据与Memory中的数据不一致,Cache中的数据就变成了脏数据(dirty)。如果其他部件(DMA, 另一个核)访问这段数据的时候,就需要通过C缓存一致性协议(Cache coherency protocol)保证取到的是最新的数据。另外这个Cache被替换出去的时候就需要写回到内存中。
缓存一致性协议(MESI)
MESI协议将cache line的状态分成modify、exclusive、shared、invalid,分别是修改、独占、共享和失效。
modify:修改,当前CPU cache拥有最新数据(最新的cache line),其他CPU拥有失效数据(cache line的状态是 invalid),虽然当前CPU中的数据和主存是不一致的,但是以当前CPU的数据为准;
exclusive:独占,只有当前CPU中有数据,其他CPU中没有改数据,当前CPU的数据和主存中的数据是一致的;
shared:共享,当前CPU和其他CPU中都有共同数据,并且和主存中的数据一致;
invalid:失效,当前CPU中的数据失效,数据应该从主存中获取,其他CPU中可能有数据也可能无数据,当前CPU 中的数据和主存被认为是不一致的;对于invalid而言,在MESI协议中采取的是写失效(write invalidate)。
合并写缓冲区
如果一个cpu在执行的时候需要访问的内存都不在cache中,cpu必须要通过内存总线到主存中取,那么在数据返回到cpu这段时间内(这段时间大致为cpu执行成百上千条指令的时间,至少两个数据量级)干什么呢? 答案是cpu会继续执行其他的符合条件的指令。比如cpu有一个指令序列 指令1 指令2 指令3 …, 在指令1时需要访问主存,在数据返回前cpu会继续后续的和指令1在逻辑关系上没有依赖的”独立指令”,cpu一般是依赖指令间的内存引用关系来判断的指令间的”独立关系”,具体细节可参见各cpu的文档。这也是导致cpu乱序执行指令的根源之一。
以上方案是cpu对于读取数据延迟所做的性能补救的办法。对于写数据则会显得更加复杂一点: 当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区(Write combining)。这一技术称为合并写入技术。在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区,该缓冲区大小和一个cache line大小,一般都是64字节。但是Intel的CPU依次只能拿4个字节,这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响。
当后续的写操作需要修改相同的缓存行时,这些缓冲区变得非常有趣。在将后续的写操作提交到L2缓存之前,可以进行缓冲区写合并。 这些64字节的缓冲区维护了一个64位的字段,每更新一个字节就会设置对应的位,来表示将缓冲区交换到外部缓存时哪些数据是有效的。当然,如果程序读取已被写入到该缓冲区的某些数据,那么在读取缓存数据之前会先去读取本缓冲区的。
代码验证(不是本人写的,我写不出这么牛逼的代码......):
package com.courage;
import static java.lang.System.out;
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++)
{
out.println(i + " SingleLoop duration (ns) = "
+ runCaseOne());
out.println(i + " SplitLoop duration (ns) = "
+ runCaseTwo());
}
int result = arrayA[1] + arrayB[2] + arrayC[3] +
arrayD[4] + arrayE[5] + arrayF[6];
out.println("result = " + result);
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0)
{
int slot = i & MASK;
byte b = (byte)i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0)
{
int slot = i & MASK;
byte b = (byte)i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0)
{
int slot = i & MASK;
byte b = (byte)i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
结果:
1 SingleLoop duration (ns) = 7776117900
1 SplitLoop duration (ns) = 4142768900
2 SingleLoop duration (ns) = 7159003200
2 SplitLoop duration (ns) = 4085567700
3 SingleLoop duration (ns) = 4927917800
3 SplitLoop duration (ns) = 4182084100
我们要尽可能要合并写操作,而且上限是4个,如果循环中存缓存行的数量超过4个,那么建议折分。
经过上述步骤后,缓冲区的数据还是会在某个延时的时刻更新到外部的缓存(L2_cache).如果我们能在缓冲区传输到缓存之前将其尽可能填满,这样的效果就会提高各级传输总线的效率,以提高程序性能。
原理:上面提到的合并写存入缓冲区离cpu很近,容量为64字节,因此,run_one_case_for_8函数中连续写入8个不同位置的内存,那么当4个数据写满了合并写缓冲时,cpu就要等待合并写缓冲区更新到L2cache中,因此cpu就被强制暂停了。然而在run_two_case_for_4函数中是每次写入4个不同位置的内存,可以很好的利用合并写缓冲区,因合并写缓冲区满到引起的cpu暂停的次数会大大减少,当然如果每次写入的内存位置数目小于4,也是一样的。虽然多了一次循环的i++操作(实际上你可能会问,i++也是会写入内存的啊,其实i这个变量保存在了寄存器上), 但是它们之间的性能差距依然非常大。
从上面的例子可以看出,这些cpu底层特性对程序员并不是透明的。程序的稍微改变会带来显著的性能提升。对于存储密集型的程序,更应当考虑到此到特性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号