一、腾讯AI开放平台
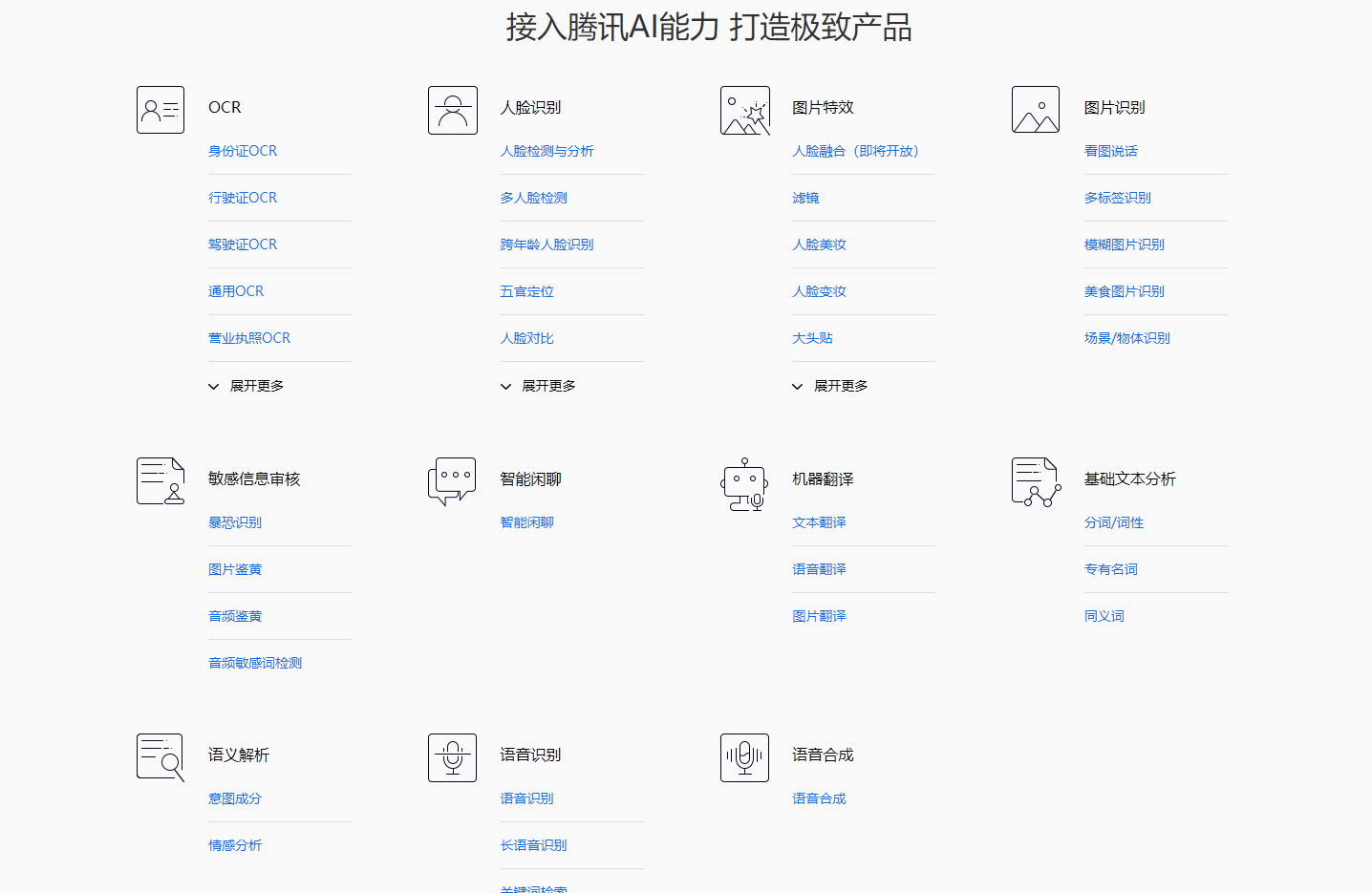
二、腾讯AI平台支持的功能
![]()
三、签名机制
1.计算步骤
用于计算签名的参数在不同接口之间会有差异,但算法过程固定如下4个步骤。
1.将<key, value>请求参数对按key进行字典升序排序,得到有序的参数对列表N
2.将列表N中的参数对按URL键值对的格式拼接成字符串,得到字符串T(如:key1=value1&key2=value2),URL键值拼接过程value部分需要URL编码,URL编码算法用大写字母,例如%E8,而不是小写%e8
3.将应用密钥以app_key为键名,组成URL键值拼接到字符串T末尾,得到字符串S(如:key1=value1&key2=value2&app_key=密钥)
4.对字符串S进行MD5运算,将得到的MD5值所有字符转换成大写,得到接口请求签名
2.注意事项
1.不同接口要求的参数对不一样,计算签名使用的参数对也不一样
2.参数名区分大小写,参数值为空不参与签名
3.URL键值拼接过程value部分需要URL编码
4.签名有效期5分钟,需要请求接口时刻实时计算签名信息
3.参考代码
import time
import random
import string
import base64
import hashlib
import requests
from urllib.parse import urlencode
from collections import OrderedDict
class Sign:
def __init__(self):
self.app_id = 12345 # APP_ID
self.app_key = '12345' # APP_KEY
@property
def time_stamp(self):
t = time.time()
return int(t)
def random_string(self, num=16):
s = string.ascii_lowercase + string.digits
r = random.sample(s, num)
return ''.join(r)
def add_field(self, dic):
dic['app_id'] = self.app_id
# 生成时间戳
dic['time_stamp'] = self.time_stamp
# 生成随机字符串
dic['nonce_str'] = self.random_string()
return dic
def add_sign(self, dic):
d = OrderedDict()
# 将字典进行排序
for k in sorted(dic):
d[k] = dic[k]
# 将排序后的字典进行urlencode编码,得到字符串
s = urlencode(d, encoding='utf-8')
# 把app_key拼接到字符串
s += '&app_key={}'.format(self.app_key)
md = hashlib.md5()
md.update(s.encode('utf-8'))
# 将字符串进行md5运算得到签名
m = md.hexdigest().upper()
dic['sign'] = m
return dic
四、语音合成功能的使用
import time
import random
import string
import base64
import hashlib
import requests
from urllib.parse import urlencode
from collections import OrderedDict
class Sound:
def __init__(self):
self.app_id = 12345 # APP_ID
self.app_key = '12345' # APP_KEY
@property
def time_stamp(self):
t = time.time()
return int(t)
def random_string(self, num=16):
s = string.ascii_lowercase + string.digits
r = random.sample(s, num)
return ''.join(r)
def add_field(self, dic):
dic['app_id'] = self.app_id
dic['time_stamp'] = self.time_stamp
dic['nonce_str'] = self.random_string()
return dic
def add_sign(self, dic):
d = OrderedDict()
for k in sorted(dic):
d[k] = dic[k]
s = urlencode(d, encoding='utf-8')
s += '&app_key={}'.format(self.app_key)
md = hashlib.md5()
md.update(s.encode('utf-8'))
m = md.hexdigest().upper()
dic['sign'] = m
return dic
# 合成语音
def speech_synthesis(self, file_name=None, speaker=6, format=3, volume=0, speed=100, text=None, aht=0, apc=58):
if text == None:
text = '请输入想要转换的文字!'
if file_name == None:
file_name = 'test.mp3'
dic = {
'aht': aht,
'apc': apc,
'text': text,
'speed': speed,
'format': format,
'volume': volume,
'speaker': speaker,
}
# 生成字典
dic = self.add_field(dic)
# 获得签名后的字典
dic = self.add_sign(dic)
# 发post请求,把获得签名后的字典作为data
ret = requests.post(url='https://api.ai.qq.com/fcgi-bin/aai/aai_tts', data=dic).json()
# 将请求结果中的音频数据进行base64解码,然后写入文件
with open(file_name, 'wb') as f:
audio = base64.b64decode(ret['data']['speech'])
f.write(audio)
if __name__ == '__main__':
s = Sound()
s.speech_synthesis(file_name='001.mp3', text='我爱你,中国!')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号