
Ext3文件读写流程概述
Ext3文件系统在进行读写操作的时候,首先需要open相应的文件,然后再进行读写操作。在open操作时,Linux kernel会创建一个file对象描述这个文件。File对象和文件的dentry和inode对象建立联系,并且将ext3的文件操作方法、映射处理方法(address space)注册到file对象中。
Ext3文件读写过程会涉及到VFS层的page cache,并且通常的读写操作都会使用到这层page cache,目的是提高磁盘的IO性能。在Linux中后台会运行writeback线程定时同步pagecache和设备之间的数据。Page cache的方式虽然能够提高IO性能,但是也对数据的安全性带来了潜在影响。
本文的目的是分析ext3文件系统读写流程中的关键函数,对于page cache原理以及writeback机制将在后继文章中做深入分析。
关键数据结构
File数据结构是Linux用来描述文件的关键数据结构,该对象在一个文件被进程打开的时候被创建。当一个文件被关闭的时候,file对象也会被立即销毁。file数据结构不会被作为元数据信息持久化保存至设备。该数据结构定义如下:
- struct file {
- /*
- * fu_list becomes invalid after file_free is called and queued via
- * fu_rcuhead for RCU freeing
- */
- union {
- struct list_head fu_list;
- struct rcu_head fu_rcuhead;
- } f_u;
- struct path f_path; /* 文件路径,包含文件dentry目录项和vfsmount信息 */
- #define f_dentry f_path.dentry
- #define f_vfsmnt f_path.mnt
- const struct file_operations *f_op; /* 文件操作函数集 */
- /*
- * Protects f_ep_links, f_flags, f_pos vs i_size in lseek SEEK_CUR.
- * Must not be taken from IRQ context.
- */
- spinlock_t f_lock;
- #ifdef CONFIG_SMP
- int f_sb_list_cpu;
- #endif
- atomic_long_t f_count;
- unsigned int f_flags;
- fmode_t f_mode; /* 文件操作模式 */
- loff_t f_pos;
- struct fown_struct f_owner;
- const struct cred *f_cred;
- struct file_ra_state f_ra;
- u64 f_version;
- #ifdef CONFIG_SECURITY
- void *f_security;
- #endif
- /* needed for tty driver, and maybe others */
- void *private_data;
- #ifdef CONFIG_EPOLL
- /* Used by fs/eventpoll.c to link all the hooks to this file */
- struct list_head f_ep_links;
- struct list_head f_tfile_llink;
- #endif /* #ifdef CONFIG_EPOLL */
- struct address_space *f_mapping; /* address space映射信息,指向inode中的i_mapping */
- #ifdef CONFIG_DEBUG_WRITECOUNT
- unsigned long f_mnt_write_state;
- #endif
- };
每个文件在内存中都会对应一个inode对象。在设备上也会保存每个文件的inode元数据信息,通过inode元数据信息可以找到该文件所占用的所有文件数据块(block)。VFS定义了一个通用的inode数据结构,同时ext3定义了ext3_inode元数据结构。在创建内存inode对象时,需要采用ext3_inode元数据信息初始化inode对象。Inode数据结构定义如下:
- struct inode {
- umode_t i_mode;
- unsigned short i_opflags;
- uid_t i_uid;
- gid_t i_gid;
- unsigned int i_flags;
- #ifdef CONFIG_FS_POSIX_ACL
- struct posix_acl *i_acl;
- struct posix_acl *i_default_acl;
- #endif
- const struct inode_operations *i_op; /* inode操作函数集 */
- struct super_block *i_sb; /* 指向superblock */
- struct address_space *i_mapping; /* 指向当前使用的页缓存的映射信息 */
- #ifdef CONFIG_SECURITY
- void *i_security;
- #endif
- /* Stat data, not accessed from path walking */
- unsigned long i_ino;
- /*
- * Filesystems may only read i_nlink directly. They shall use the
- * following functions for modification:
- *
- * (set|clear|inc|drop)_nlink
- * inode_(inc|dec)_link_count
- */
- union {
- const unsigned int i_nlink;
- unsigned int __i_nlink;
- };
- dev_t i_rdev; /* 设备号,major&minor */
- struct timespec i_atime;
- struct timespec i_mtime;
- struct timespec i_ctime;
- spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
- unsigned short i_bytes;
- blkcnt_t i_blocks; /* 文件块数量 */
- loff_t i_size;
- #ifdef __NEED_I_SIZE_ORDERED
- seqcount_t i_size_seqcount;
- #endif
- /* Misc */
- unsigned long i_state;
- struct mutex i_mutex;
- unsigned long dirtied_when; /* jiffies of first dirtying */
- struct hlist_node i_hash; /* 连接到inode Hash Table中 */
- struct list_head i_wb_list; /* backing dev IO list */
- struct list_head i_lru; /* inode LRU list */
- struct list_head i_sb_list;
- union {
- struct list_head i_dentry;
- struct rcu_head i_rcu;
- };
- atomic_t i_count;
- unsigned int i_blkbits; /* 块大小,通常磁盘块大小为512字节,因此i_blkbits为9 */
- u64 i_version;
- atomic_t i_dio_count;
- atomic_t i_writecount;
- const struct file_operations *i_fop; /* former ->i_op->default_file_ops,文件操作函数集 */
- struct file_lock *i_flock;
- struct address_space i_data; /* 页高速缓存映射信息 */
- #ifdef CONFIG_QUOTA
- struct dquot *i_dquot[MAXQUOTAS];
- #endif
- struct list_head i_devices;
- union {
- struct pipe_inode_info *i_pipe; /* 管道设备 */
- struct block_device *i_bdev; /* block device块设备 */
- struct cdev *i_cdev; /* 字符设备 */
- };
- __u32 i_generation;
- #ifdef CONFIG_FSNOTIFY
- __u32 i_fsnotify_mask; /* all events this inode cares about */
- struct hlist_head i_fsnotify_marks;
- #endif
- #ifdef CONFIG_IMA
- atomic_t i_readcount; /* struct files open RO */
- #endif
- void *i_private; /* fs or device private pointer */
- };
读过程源码分析
Ext3文件系统读过程相对比较简单,函数调用关系如下图所示:

读过程可以分为两大类:Direct_io方式和page_cache方式。对于Direct_io方式,首先通过filemap_write_and_wait_range函数将page cache中的数据与设备同步并且无效掉page cache中的内容,然后再通过ext3提供的direct_io方法从设备读取数据。
另一种是直接从page cache中获取数据,通过do_generic_file_read函数实现该方式。该函数的主要流程说明如下:
1,通过读地址从page cache的radix树中获取相应的page页。
2,如果对应的page页不存在,那么需要创建一个page,然后再从设备读取相应的数据更新至page页。
3,当page页准备完毕之后,从页中拷贝数据至用户空间,page_cache方式的读操作完成。
写过程源码分析
Ext3的写过程主要分为direct_io写过程和page cache写过程两大类,整个写过程的函数调用关系如下图所示:
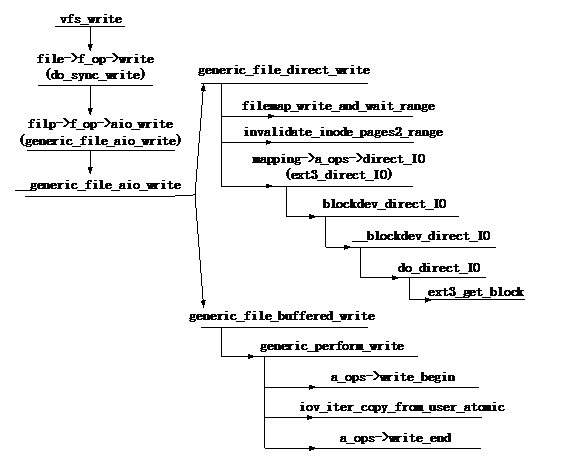
写操作的核心函数是__generic_file_aio_write,该函数实现如下:
- ssize_t __generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
- unsigned long nr_segs, loff_t *ppos)
- {
- struct file *file = iocb->ki_filp;
- /* 获取address space映射信息 */
- struct address_space * mapping = file->f_mapping;
- size_t ocount; /* original count */
- size_t count; /* after file limit checks */
- struct inode *inode = mapping->host; /* 获取文件inode索引节点 */
- loff_t pos;
- ssize_t written;
- ssize_t err;
- ocount = 0;
- /* 检验数据区域是否存在问题,数据由iov数据结构管理 */
- err = generic_segment_checks(iov, &nr_segs, &ocount, VERIFY_READ);
- if (err)
- return err;
- /* ocount为可以写入的数据长度 */
- count = ocount;
- pos = *ppos;
- vfs_check_frozen(inode->i_sb, SB_FREEZE_WRITE);
- /* We can write back this queue in page reclaim */
- current->backing_dev_info = mapping->backing_dev_info;
- written = 0;
- /* 边界检查,需要判断写入数据是否超界、小文件边界检查以及设备是否是read-only。如果超界,那么降低写入数据长度 */
- err = generic_write_checks(file, &pos, &count, S_ISBLK(inode->i_mode));
- if (err)
- goto out;
- /* count为实际可以写入的数据长度,如果写入数据长度为0,直接结束 */
- if (count == 0)
- goto out;
- err = file_remove_suid(file);
- if (err)
- goto out;
- file_update_time(file);
- /* coalesce the iovecs and go direct-to-BIO for O_DIRECT */
- if (unlikely(file->f_flags & O_DIRECT)) {
- /* Direct IO操作模式,该模式会bypass Page Cache,直接将数据写入磁盘设备 */
- loff_t endbyte;
- ssize_t written_buffered;
- /* 将对应page cache无效掉,然后将数据直接写入磁盘 */
- written = generic_file_direct_write(iocb, iov, &nr_segs, pos,
- ppos, count, ocount);
- if (written < 0 || written == count)
- /* 所有数据已经写入磁盘,正确返回 */
- goto out;
- /*
- * direct-io write to a hole: fall through to buffered I/O
- * for completing the rest of the request.
- */
- pos += written;
- count -= written;
- /* 有些请求由于没有和块大小(通常为512字节)对齐,那么将无法正确完成direct-io操作。在__blockdev_direct_IO 函数中会检查逻辑地址是否和块大小对齐,__blockdev_direct_IO无法处理不对齐的请求。另外,在ext3逻辑地址和物理块地址映射操作函数ext3_get_block返回失败时,无法完成buffer_head的映射,那么request请求也将无法得到正确处理。所有没有得到处理的请求通过 buffer写的方式得到处理。从这点来看,direct_io并没有完全bypass page cache,在有些情况下是一种写无效模式。generic_file_buffered_write函数完成buffer写,将数据直接写入page cache */
- written_buffered = generic_file_buffered_write(iocb, iov,
- nr_segs, pos, ppos, count,
- written);
- /*
- * If generic_file_buffered_write() retuned a synchronous error
- * then we want to return the number of bytes which were
- * direct-written, or the error code if that was zero. Note
- * that this differs from normal direct-io semantics, which
- * will return -EFOO even if some bytes were written.
- */
- if (written_buffered < 0) {
- /* 如果page cache写失败,那么返回写成功的数据长度 */
- err = written_buffered;
- goto out;
- }
- /*
- * We need to ensure that the page cache pages are written to
- * disk and invalidated to preserve the expected O_DIRECT
- * semantics.
- */
- endbyte = pos + written_buffered - written - 1;
- /* 将page cache中的数据同步到磁盘 */
- err = filemap_write_and_wait_range(file->f_mapping, pos, endbyte);
- if (err == 0) {
- written = written_buffered;
- /* 将page cache无效掉,保证下次读操作从磁盘获取数据 */
- invalidate_mapping_pages(mapping,
- pos >> PAGE_CACHE_SHIFT,
- endbyte >> PAGE_CACHE_SHIFT);
- } else {
- /*
- * We don't know how much we wrote, so just return
- * the number of bytes which were direct-written
- */
- }
- } else {
- /* 将数据写入page cache。绝大多数的ext3写操作都会采用page cache写方式,通过后台writeback线程将page cache同步到硬盘 */
- written = generic_file_buffered_write(iocb, iov, nr_segs,
- pos, ppos, count, written);
- }
- out:
- current->backing_dev_info = NULL;
- return written ? written : err;
- }
从__generic_file_aio_write函数可以看出,ext3写操作主要分为两大类:一类为direct_io;另一类为buffer_io (page cache write)。Direct IO可以bypass page cache,直接将数据写入设备。下面首先分析一下direct_io的处理流程。
如果操作地址对应的page页存在于page cache中,那么首先需要将这些page页中的数据同磁盘进行同步,然后将这些page缓存页无效掉,从而保证后继读操作能够从磁盘获取最新数据。在代码实现过程中,还需要考虑预读机制引入的page缓存页,所以在数据写入磁盘之后,需要再次查找page cache的radix树,保证写入的地址范围没有数据被缓存。
Generic_file_direct_write是处理direct_io的主要函数,该函数的实现如下:
- ssize_t
- generic_file_direct_write(struct kiocb *iocb, const struct iovec *iov,
- unsigned long *nr_segs, loff_t pos, loff_t *ppos,
- size_t count, size_t ocount)
- {
- struct file *file = iocb->ki_filp;
- struct address_space *mapping = file->f_mapping;
- struct inode *inode = mapping->host;
- ssize_t written;
- size_t write_len;
- pgoff_t end;
- if (count != ocount)
- *nr_segs = iov_shorten((struct iovec *)iov, *nr_segs, count);
- write_len = iov_length(iov, *nr_segs);
- end = (pos + write_len - 1) >> PAGE_CACHE_SHIFT;
- /* 将对应区域page cache中的新数据页刷新到设备,这个操作是同步的 */
- written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1);
- if (written)
- goto out;
- /*
- * After a write we want buffered reads to be sure to go to disk to get
- * the new data. We invalidate clean cached page from the region we're
- * about to write. We do this *before* the write so that we can return
- * without clobbering -EIOCBQUEUED from ->direct_IO().
- */
- /* 将page cache对应page 缓存无效掉,这样可以保证后继的读操作能从磁盘获取最新数据 */
- if (mapping->nrpages) {
- /* 无效对应的page缓存 */
- written = invalidate_inode_pages2_range(mapping,
- pos >> PAGE_CACHE_SHIFT, end);
- /*
- * If a page can not be invalidated, return 0 to fall back
- * to buffered write.
- */
- if (written) {
- if (written == -EBUSY)
- return 0;
- goto out;
- }
- }
- /* 调用ext3文件系统的direct io方法,将数据写入磁盘 */
- written = mapping->a_ops->direct_IO(WRITE, iocb, iov, pos, *nr_segs);
- /*
- * Finally, try again to invalidate clean pages which might have been
- * cached by non-direct readahead, or faulted in by get_user_pages()
- * if the source of the write was an mmap'ed region of the file
- * we're writing. Either one is a pretty crazy thing to do,
- * so we don't support it 100%. If this invalidation
- * fails, tough, the write still worked...
- */
- /* 再次无效掉由于预读操作导致的对应地址的page cache缓存页 */
- if (mapping->nrpages) {
- invalidate_inode_pages2_range(mapping,
- pos >> PAGE_CACHE_SHIFT, end);
- }
- if (written > 0) {
- pos += written;
- if (pos > i_size_read(inode) && !S_ISBLK(inode->i_mode)) {
- i_size_write(inode, pos);
- mark_inode_dirty(inode);
- }
- *ppos = pos;
- }
- out:
- return written;
- }
generic_file_direct_write函数中刷新page cache的函数调用关系描述如下:
filemap_write_and_wait_range à__filemap_fdatawrite_rangeà do_writepages
do_writepages函数的作用是将page页中的数据同步到设备,该函数实现如下:
- int do_writepages(struct address_space *mapping, struct writeback_control *wbc)
- {
- int ret;
- if (wbc->nr_to_write <= 0)
- return 0;
- if (mapping->a_ops->writepages)
- /* 如果文件系统定义了writepages方法,调用该方法刷新page cache页 */
- ret = mapping->a_ops->writepages(mapping, wbc);
- else
- /* ext3没有定义writepages方法,因此调用generic_writepages()函数将page cache中的脏页刷新到磁盘 */
- ret = generic_writepages(mapping, wbc);
- return ret;
- }
从上述分析可以看出,direct_io需要块大小对齐,否则还会调用page cache的路径。为了提高I/O性能,通常情况下ext3都会采用page cache异步写的方式。这也就是ext3的第二种写操作方式,该方式实现的关键函数是generic_file_buffered_write,其实现如下:
- ssize_t
- generic_file_buffered_write(struct kiocb *iocb, const struct iovec *iov,
- unsigned long nr_segs, loff_t pos, loff_t *ppos,
- size_t count, ssize_t written)
- {
- struct file *file = iocb->ki_filp;
- ssize_t status;
- struct iov_iter i;
- iov_iter_init(&i, iov, nr_segs, count, written);
- /* 执行page cache写操作 */
- status = generic_perform_write(file, &i, pos);
- if (likely(status >= 0)) {
- written += status;
- *ppos = pos + status;
- }
- return written ? written : status;
- }
generic_file_buffered_write其实是对generic_perform_write函数的封装,generic_perform_write实现了page cache写的所有流程,该函数实现如下:
- static ssize_t generic_perform_write(struct file *file,
- struct iov_iter *i, loff_t pos)
- {
- struct address_space *mapping = file->f_mapping;
- const struct address_space_operations *a_ops = mapping->a_ops; /* 映射处理函数集 */
- long status = 0;
- ssize_t written = 0;
- unsigned int flags = 0;
- /*
- * Copies from kernel address space cannot fail (NFSD is a big user).
- */
- if (segment_eq(get_fs(), KERNEL_DS))
- flags |= AOP_FLAG_UNINTERRUPTIBLE;
- do {
- struct page *page;
- unsigned long offset; /* Offset into pagecache page */
- unsigned long bytes; /* Bytes to write to page */
- size_t copied; /* Bytes copied from user */
- void *fsdata;
- offset = (pos & (PAGE_CACHE_SIZE - 1));
- bytes = min_t(unsigned long, PAGE_CACHE_SIZE - offset,
- iov_iter_count(i));
- again:
- /*
- * Bring in the user page that we will copy from _first_.
- * Otherwise there's a nasty deadlock on copying from the
- * same page as we're writing to, without it being marked
- * up-to-date.
- *
- * Not only is this an optimisation, but it is also required
- * to check that the address is actually valid, when atomic
- * usercopies are used, below.
- */
- if (unlikely(iov_iter_fault_in_readable(i, bytes))) {
- status = -EFAULT;
- break;
- }
- /* 调用ext3中的write_begin函数(inode.c中)ext3_write_begin, 如果写入的page页不存在,那么ext3_write_begin会创建一个Page页,然后从硬盘中读入相应的数据 */
- status = a_ops->write_begin(file, mapping, pos, bytes, flags,
- &page, &fsdata);
- if (unlikely(status))
- break;
- if (mapping_writably_mapped(mapping))
- flush_dcache_page(page);
- pagefault_disable();
- /* 将数据拷贝到page cache中 */
- copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
- pagefault_enable();
- flush_dcache_page(page);
- mark_page_accessed(page);
- /* 调用ext3的write_end函数(inode.c中),写完数据之后会将page页标识为dirty,后台writeback线程会将dirty page刷新到设备 */
- status = a_ops->write_end(file, mapping, pos, bytes, copied,
- page, fsdata);
- if (unlikely(status < 0))
- break;
- copied = status;
- cond_resched();
- iov_iter_advance(i, copied);
- if (unlikely(copied == 0)) {
- /*
- * If we were unable to copy any data at all, we must
- * fall back to a single segment length write.
- *
- * If we didn't fallback here, we could livelock
- * because not all segments in the iov can be copied at
- * once without a pagefault.
- */
- bytes = min_t(unsigned long, PAGE_CACHE_SIZE - offset,
- iov_iter_single_seg_count(i));
- goto again;
- }
- pos += copied;
- written += copied;
- balance_dirty_pages_ratelimited(mapping);
- if (fatal_signal_pending(current)) {
- status = -EINTR;
- break;
- }
- } while (iov_iter_count(i));
- return written ? written : status;
- }
本文出自 “存储之道” 博客,请务必保留此出处http://alanwu.blog.51cto.com/3652632/1106506

 浙公网安备 33010602011771号
浙公网安备 33010602011771号