

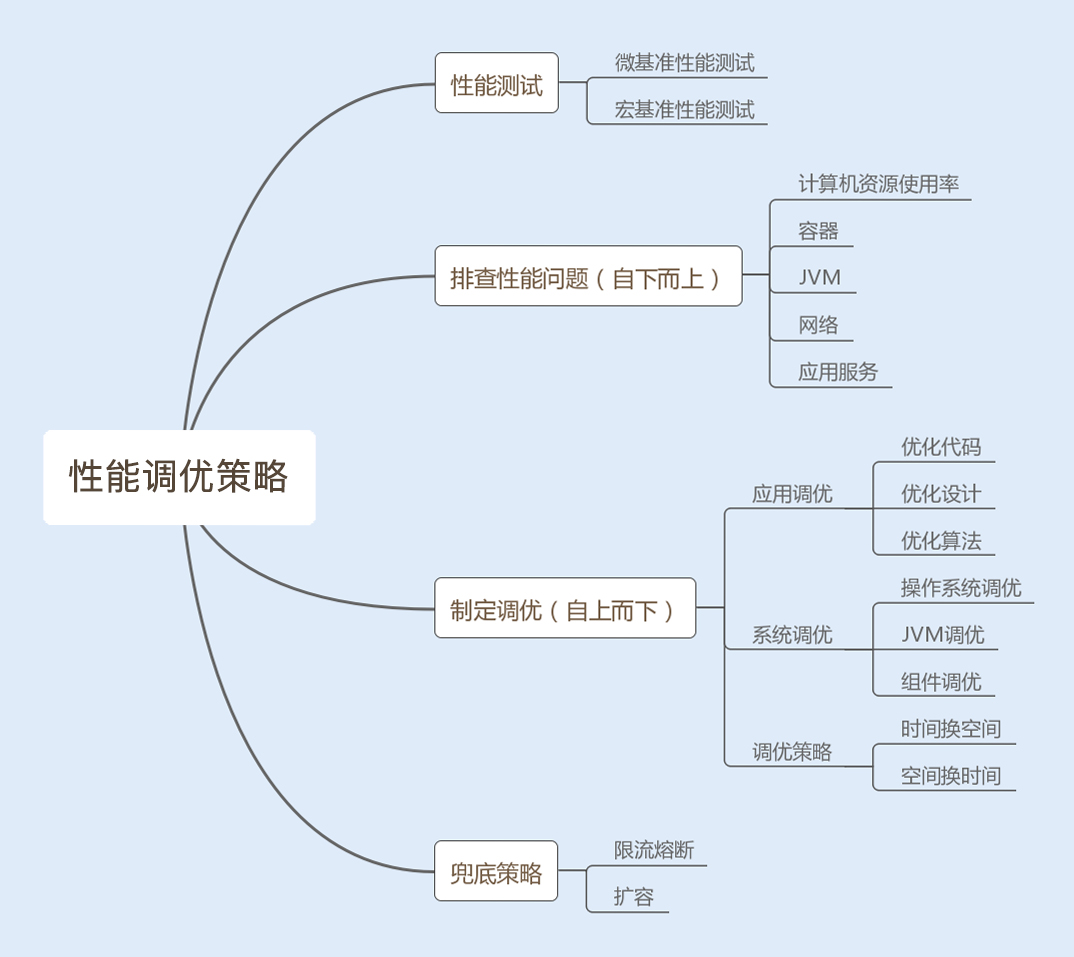
Java性能调优
1.如何定制性能调优标准?
在我们了解性能指标之前,我们先来了解下哪些计算机资源会成为系统的性能瓶颈。
CPU:有的应用需要大量计算,他们会长时间、不间断地占用 CPU 资源,导致其他资源无法争夺到 CPU 而响应缓慢,从而带来系统性能问题。例如,代码递归导致的无限循环,正则表达式引起的回溯,JVM 频繁的 FULL GC,以及多线程编程造成的大量上下文切换等,这些都有可能导致 CPU 资源繁忙。
内存:Java 程序一般通过 JVM 对内存进行分配管理,主要是用 JVM 中的堆内存来存储 Java 创建的对象。系统堆内存的读写速度非常快,所以基本不存在读写性能瓶颈。但是由于内存成本要比磁盘高,相比磁盘,内存的存储空间又非常有限。所以当内存空间被占满,对象无法回收时,就会导致内存溢出、内存泄露等问题。
磁盘 I/O:磁盘相比内存来说,存储空间要大很多,但磁盘 I/O 读写的速度要比内存慢,虽然目前引入的 SSD 固态硬盘已经有所优化,但仍然无法与内存的读写速度相提并论。
网络:网络对于系统性能来说,也起着至关重要的作用。如果你购买过云服务,一定经历过,选择网络带宽大小这一环节。带宽过低的话,对于传输数据比较大,或者是并发量比较大的系统,网络就很容易成为性能瓶颈。
异常:Java 应用中,抛出异常需要构建异常栈,对异常进行捕获和处理,这个过程非常消耗系统性能。如果在高并发的情况下引发异常,持续地进行异常处理,那么系统的性能就会明显地受到影响。
数据库:大部分系统都会用到数据库,而数据库的操作往往是涉及到磁盘 I/O 的读写。大量的数据库读写操作,会导致磁盘 I/O 性能瓶颈,进而导致数据库操作的延迟性。对于有大量数据库读写操作的系统来说,数据库的性能优化是整个系统的核心。
锁竞争:在并发编程中,我们经常会需要多个线程,共享读写操作同一个资源,这个时候为了保持数据的原子性(即保证这个共享资源在一个线程写的时候,不被另一个线程修改),我们就会用到锁。锁的使用可能会带来上下文切换,从而给系统带来性能开销。JDK1.6 之后,Java 为了降低锁竞争带来的上下文切换,对 JVM 内部锁已经做了多次优化,例如,新增了偏向锁、自旋锁、轻量级锁、锁粗化、锁消除等。而如何合理地使用锁资源,优化锁资源,就需要你了解更多的操作系统知识、Java 多线程编程基础,积累项目经验,并结合实际场景去处理相关问题。
了解了上面这些基本内容,我们可以得到下面几个指标,来衡量一般系统的性能。
响应时间
响应时间是衡量系统性能的重要指标之一,响应时间越短,性能越好,一般一个接口的响应时间是在毫秒级。在系统中,我们可以把响应时间自下而上细分为以下几种:
- 数据库响应时间:数据库操作所消耗的时间,往往是整个请求链中最耗时的;
- 服务端响应时间:服务端包括 Nginx 分发的请求所消耗的时间以及服务端程序执行所消耗的时间;
- 网络响应时间:这是网络传输时,网络硬件需要对传输的请求进行解析等操作所消耗的时间;
- 客户端响应时间:对于普通的 Web、App 客户端来说,消耗时间是可以忽略不计的,但如果你的客户端嵌入了大量的逻辑处理,消耗的时间就有可能变长,从而成为系统的瓶颈。
吞吐量
在测试中,我们往往会比较注重系统接口的 TPS(每秒事务处理量),因为 TPS 体现了接口的性能,TPS 越大,性能越好。在系统中,我们也可以把吞吐量自下而上地分为两种:磁盘吞吐量和网络吞吐量。
我们先来看磁盘吞吐量,磁盘性能有两个关键衡量指标。
一种是 IOPS(Input/Output Per Second),即每秒的输入输出量(或读写次数),这种是指单位时间内系统能处理的 I/O 请求数量,I/O 请求通常为读或写数据操作请求,关注的是随机读写性能。适应于随机读写频繁的应用,如小文件存储(图片)、OLTP 数据库、邮件服务器。
另一种是数据吞吐量,这种是指单位时间内可以成功传输的数据量。对于大量顺序读写频繁的应用,传输大量连续数据,例如,电视台的视频编辑、视频点播 VOD(Video On Demand),数据吞吐量则是关键衡量指标。
接下来看网络吞吐量,这个是指网络传输时没有帧丢失的情况下,设备能够接受的最大数据速率。网络吞吐量不仅仅跟带宽有关系,还跟 CPU 的处理能力、网卡、防火墙、外部接口以及 I/O 等紧密关联。而吞吐量的大小主要由网卡的处理能力、内部程序算法以及带宽大小决定。
计算机资源分配使用率
通常由 CPU 占用率、内存使用率、磁盘 I/O、网络 I/O 来表示资源使用率。这几个参数好比一个木桶,如果其中任何一块木板出现短板,任何一项分配不合理,对整个系统性能的影响都是毁灭性的。
负载承受能力
当系统压力上升时,你可以观察,系统响应时间的上升曲线是否平缓。这项指标能直观地反馈给你,系统所能承受的负载压力极限。例如,当你对系统进行压测时,系统的响应时间会随着系统并发数的增加而延长,直到系统无法处理这么多请求,抛出大量错误时,就到了极限。
2.如何定制性能调优策略
性能测试攻略
1. 微基准性能测试
微基准性能测试可以精准定位到某个模块或者某个方法的性能问题,特别适合做一个功能模块或者一个方法在不同实现方式下的性能对比。例如,对比一个方法使用同步实现和非同步实现的性能。
2. 宏基准性能测试
宏基准性能测试是一个综合测试,需要考虑到测试环境、测试场景和测试目标。
首先看测试环境,我们需要模拟线上的真实环境。
然后看测试场景。我们需要确定在测试某个接口时,是否有其他业务接口同时也在平行运行,造成干扰。如果有,请重视,因为你一旦忽视了这种干扰,测试结果就会出现偏差。
最后看测试目标。我们的性能测试是要有目标的,这里可以通过吞吐量以及响应时间来衡量系统是否达标。不达标,就进行优化;达标,就继续加大测试的并发数,探底接口的 TPS(最大每秒事务处理量),这样做,可以深入了解到接口的性能。除了测试接口的吞吐量和响应时间以外,我们还需要循环测试可能导致性能问题的接口,观察各个服务器的 CPU、内存以及 I/O 使用率的变化。
性能测试存在干扰因子,会使测试结果不准确。所以,我们在做性能测试时,还要注意一些问题。
1. 热身问题
当我们做性能测试时,我们的系统会运行得越来越快,后面的访问速度要比我们第一次访问的速度快上几倍。这是怎么回事呢?
在 Java 编程语言和环境中,.java 文件编译成为 .class 文件后,机器还是无法直接运行 .class 文件中的字节码,需要通过解释器将字节码转换成本地机器码才能运行。为了节约内存和执行效率,代码最初被执行时,解释器会率先解释执行这段代码。
随着代码被执行的次数增多,当虚拟机发现某个方法或代码块运行得特别频繁时,就会把这些代码认定为热点代码(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会通过即时编译器(JIT compiler,just-in-time compiler)把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,然后存储在内存中,之后每次运行代码时,直接从内存中获取即可。
所以在刚开始运行的阶段,虚拟机会花费很长的时间来全面优化代码,后面就能以最高性能执行了。
这就是热身过程,如果在进行性能测试时,热身时间过长,就会导致第一次访问速度过慢,你就可以考虑先优化,再进行测试。
2. 性能测试结果不稳定
我们在做性能测试时发现,每次测试处理的数据集都是一样的,但测试结果却有差异。这是因为测试时,伴随着很多不稳定因素,比如机器其他进程的影响、网络波动以及每个阶段 JVM 垃圾回收的不同等等。
我们可以通过多次测试,将测试结果求平均,或者统计一个曲线图,只要保证我们的平均值是在合理范围之内,而且波动不是很大,这种情况下,性能测试就是通过的。
3. 多 JVM 情况下的影响
如果我们的服务器有多个 Java 应用服务,部署在不同的 Tomcat 下,这就意味着我们的服务器会有多个 JVM。任意一个 JVM 都拥有整个系统的资源使用权。如果一台机器上只部署单独的一个 JVM,在做性能测试时,测试结果很好,或者你调优的效果很好,但在一台机器多个 JVM 的情况下就不一定了。所以我们应该尽量避免线上环境中一台机器部署多个 JVM 的情况。
合理分析结果,制定调优策略
我们在完成性能测试之后,需要输出一份性能测试报告,帮我们分析系统性能测试的情况。其中测试结果需要包含测试接口的平均、最大和最小吞吐量,响应时间,服务器的 CPU、内存、I/O、网络 IO 使用率,JVM 的 GC 频率等。
通过观察这些调优标准,可以发现性能瓶颈,我们再通过自下而上的方式分析查找问题。首先从操作系统层面,查看系统的 CPU、内存、I/O、网络的使用率是否存在异常,再通过命令查找异常日志,最后通过分析日志,找到导致瓶颈的原因;还可以从 Java 应用的 JVM 层面,查看 JVM 的垃圾回收频率以及内存分配情况是否存在异常,分析日志,找到导致瓶颈的原因。
如果系统和 JVM 层面都没有出现异常情况,我们可以查看应用服务业务层是否存在性能瓶颈,例如 Java 编程的问题、读写数据瓶颈等等。
分析查找问题是一个复杂而又细致的过程,某个性能问题可能是一个原因导致的,也可能是几个原因共同导致的结果。我们分析查找问题可以采用自下而上的方式,而我们解决系统性能问题,则可以采用自上而下的方式逐级优化。下面我来介绍下从应用层到操作系统层的几种调优策略。
1. 优化代码
应用层的问题代码往往会因为耗尽系统资源而暴露出来。例如,我们某段代码导致内存溢出,往往是将 JVM 中的内存用完了,这个时候系统的内存资源消耗殆尽了,同时也会引发 JVM 频繁地发生垃圾回收,导致 CPU 100% 以上居高不下,这个时候又消耗了系统的 CPU 资源。
还有一些是非问题代码导致的性能问题,这种往往是比较难发现的,需要依靠我们的经验来优化。例如,我们经常使用的 LinkedList 集合,如果使用 for 循环遍历该容器,将大大降低读的效率,但这种效率的降低很难导致系统性能参数异常。
这时有经验的同学,就会改用 Iterator (迭代器)迭代循环该集合,这是因为 LinkedList 是链表实现的,如果使用 for 循环获取元素,在每次循环获取元素时,都会去遍历一次 List,这样会降低读的效率。
2. 优化设计
面向对象有很多设计模式,可以帮助我们优化业务层以及中间件层的代码设计。优化后,不仅可以精简代码,还能提高整体性能。例如,单例模式在频繁调用创建对象的场景中,可以共享一个创建对象,这样可以减少频繁地创建和销毁对象所带来的性能消耗。
3. 优化算法
好的算法可以帮助我们大大地提升系统性能。例如,在不同的场景中,使用合适的查找算法可以降低时间复杂度。
4. 时间换空间
有时候系统对查询时的速度并没有很高的要求,反而对存储空间要求苛刻,这个时候我们可以考虑用时间来换取空间。
5. 空间换时间
这种方法是使用存储空间来提升访问速度。现在很多系统都是使用的 MySQL 数据库,较为常见的分表分库是典型的使用空间换时间的案例。
因为 MySQL 单表在存储千万数据以上时,读写性能会明显下降,这个时候我们需要将表数据通过某个字段 Hash 值或者其他方式分拆,系统查询数据时,会根据条件的 Hash 值判断找到对应的表,因为表数据量减小了,查询性能也就提升了。
6. 参数调优
以上都是业务层代码的优化,除此之外,JVM、Web 容器以及操作系统的优化也是非常关键的。
根据自己的业务场景,合理地设置 JVM 的内存空间以及垃圾回收算法可以提升系统性能。例如,如果我们业务中会创建大量的大对象,我们可以通过设置,将这些大对象直接放进老年代。这样可以减少年轻代频繁发生小的垃圾回收(Minor GC),减少 CPU 占用时间,提升系统性能。
Web 容器线程池的设置以及 Linux 操作系统的内核参数设置不合理也有可能导致系统性能瓶颈,根据自己的业务场景优化这两部分,可以提升系统性能。
兜底策略,确保系统稳定性
上边讲到的所有的性能调优策略,都是提高系统性能的手段,但在互联网飞速发展的时代,产品的用户量是瞬息万变的,无论我们的系统优化得有多好,还是会存在承受极限,所以为了保证系统的稳定性,我们还需要采用一些兜底策略。
第一,限流,对系统的入口设置最大访问限制。这里可以参考性能测试中探底接口的 TPS 。同时采取熔断措施,友好地返回没有成功的请求。
第二,实现智能化横向扩容。智能化横向扩容可以保证当访问量超过某一个阈值时,系统可以根据需求自动横向新增服务。
第三,提前扩容。这种方法通常应用于高并发系统,例如,瞬时抢购业务系统。这是因为横向扩容无法满足大量发生在瞬间的请求,即使成功了,抢购也结束了。
目前很多公司使用 Docker 容器来部署应用服务。这是因为 Docker 容器是使用 Kubernetes 作为容器管理系统,而 Kubernetes 可以实现智能化横向扩容和提前扩容 Docker 服务。
3.String性能优化
通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?代码如下:
String str1= "abc";
String str2= new String("abc");
String str3= str2.intern();
assertSame(str1str2); false
assertSame(str2str3); false
assertSame(str1==str3) true
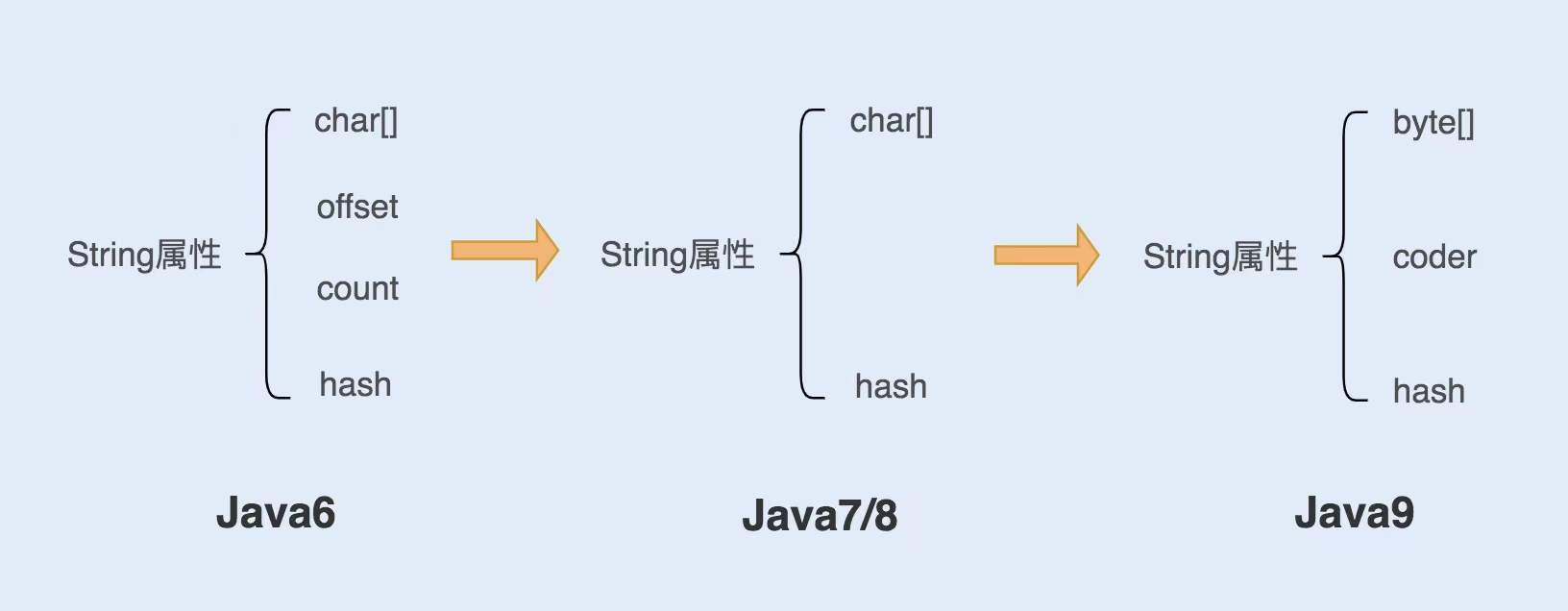
String 对象是如何实现的?
-
在 Java6 以及之前的版本中,String 对象是对 char 数组进行了封装实现的对象,主要有四个成员变量:char 数组、偏移量 offset、字符数量 count、哈希值 hash。
String 对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。 -
从 Java7 版本开始到 Java8 版本,Java 对 String 类做了一些改变。String 类中不再有 offset 和 count 两个变量了。这样的好处是 String 对象占用的内存稍微少了些,同时,String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。
-
从 Java9 版本开始,工程师将 char[] 字段改为了 byte[] 字段,又维护了一个新的属性 coder,它是一个编码格式的标识。
String 对象的不可变性
Java 这样做的好处在哪里呢?
第一,保证 String 对象的安全性。假设 String 对象是可变的,那么 String 对象将可能被恶意修改。
第二,保证 hash 属性值不会频繁变更,确保了唯一性,使得类似 HashMap 容器才能实现相应的 key-value 缓存功能。
第三,可以实现字符串常量池。在 Java 中,通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str=“abc”;另一种是字符串变量通过 new 形式的创建,如 String str = new String(“abc”)。
String 对象的优化
即使使用 + 号作为字符串的拼接,也一样可以被编译器优化成 StringBuilder 的方式。但再细致些,你会发现在编译器优化的代码中,每次循环都会生成一个新的 StringBuilder 实例,同样也会降低系统的性能。
所以平时做字符串拼接的时候,我建议你还是要显示地使用 String Builder 来提升系统性能。
如何使用 String.intern 节省内存?
在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用,这样一开始的对象就可以被回收掉。
在字符串常量中,默认会将对象放入常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。
如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串,如果没有,就在常量池中新增该对象,并返回该对象引用;如果有,就返回常量池中的字符串引用。堆内存中原有的对象由于没有引用指向它,将会通过垃圾回收器回收。
String 字符串的创建分配内存地址情况:
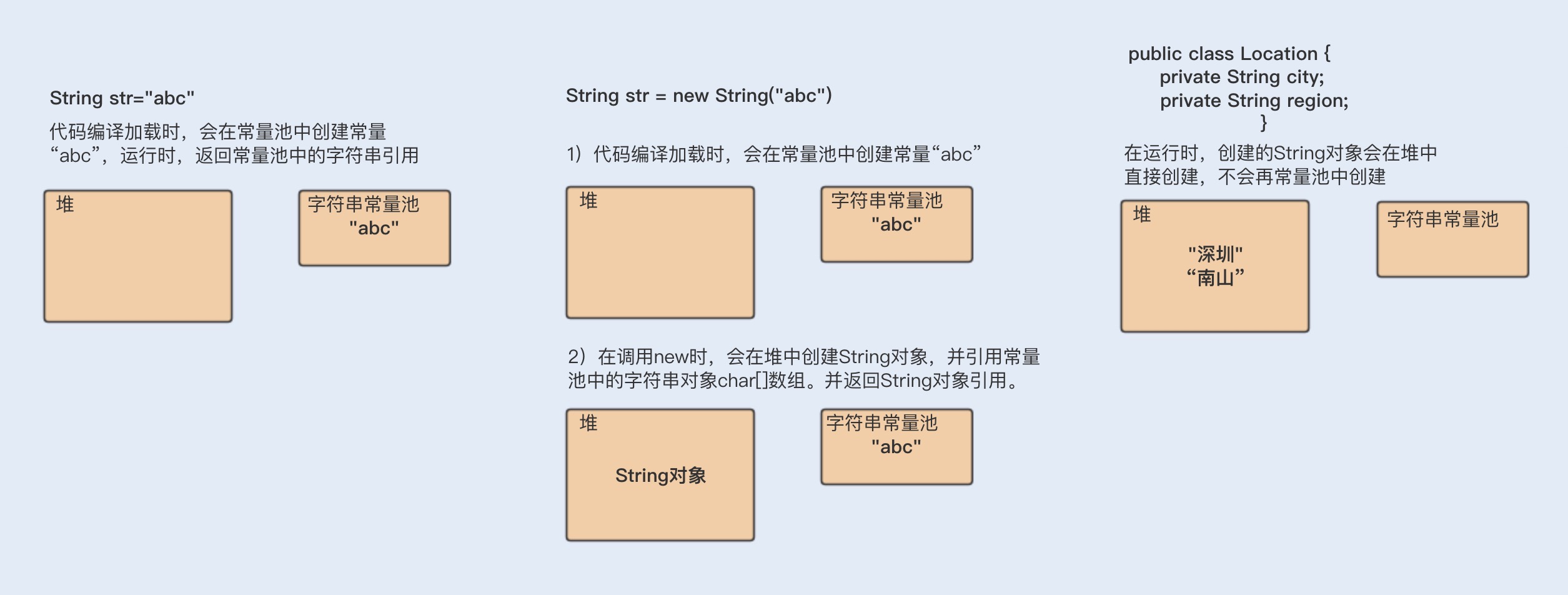
使用 intern 方法需要注意的一点是,一定要结合实际场景。因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。
如何使用字符串的分割方法?
Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
所以我们应该慎重使用 Split() 方法,我们可以用 String.indexOf() 方法代替 Split() 方法完成字符串的分割。如果实在无法满足需求,你就在使用 Split() 方法时,对回溯问题加以重视就可以了。
4. 慎重使用正则表达式
什么是正则表达式?
正则表达式是计算机科学的一个概念,很多语言都实现了它。正则表达式使用一些特定的元字符来检索、匹配以及替换符合规则的字符串。
构造正则表达式语法的元字符,由普通字符、标准字符、限定字符(量词)、定位字符(边界字符)组成。详情可见下图:

正则表达式引擎
正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配。
而这里的正则表达式引擎就是一套核心算法,用于建立状态机。
目前实现正则表达式引擎的方式有两种:DFA 自动机(Deterministic Final Automata 确定有限状态自动机)和 NFA 自动机(Non deterministic Finite Automaton 非确定有限状态自动机)。
对比来看,构造 DFA 自动机的代价远大于 NFA 自动机,但 DFA 自动机的执行效率高于 NFA 自动机。
NFA 自动机的优势是支持更多功能。例如,捕获 group、环视、占有优先量词等高级功能。这些功能都是基于子表达式独立进行匹配,因此在编程语言里,使用的正则表达式库都是基于 NFA 实现的。
NFA 自动机会读取正则表达式的每一个字符,拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,反之就继续和目标字符串的下一个字符进行匹配。分解一下过程。
NFA 自动机的回溯
用 NFA 自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,从而带来系统性能开销。
如何避免回溯问题?
1. 贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使用 +、 ? 、* 或{min,max} 等量词,正则表达式会匹配尽可能多的内容。
2. 懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符。如果匹配成功,它会继续匹配剩余的字符串。
例如,在上面例子的字符后面加一个“?”,就可以开启懒惰模式。
3. 独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。
在字符后面加一个“+”,就可以开启独占模式。
避免回溯的方法就是:使用懒惰模式和独占模式。
正则表达式的优化
1. 少用贪婪模式,多用独占模式
贪婪模式会引起回溯问题,我们可以使用独占模式来避免回溯。前面详解过了,这里我就不再解释了。
2. 减少分支选择
分支选择类型“(X|Y|Z)”的正则表达式会降低性能,我们在开发的时候要尽量减少使用。如果一定要用,我们可以通过以下几种方式来优化:
首先,我们需要考虑选择的顺序,将比较常用的选择项放在前面,使它们可以较快地被匹配;
其次,我们可以尝试提取共用模式,例如,将“(abcd|abef)”替换为“ab(cd|ef)”,后者匹配速度较快,因为 NFA 自动机会尝试匹配 ab,如果没有找到,就不会再尝试任何选项;
最后,如果是简单的分支选择类型,我们可以用三次 index 代替“(X|Y|Z)”,如果测试的话,你就会发现三次 index 的效率要比“(X|Y|Z)”高出一些。
3. 减少捕获嵌套
在讲这个方法之前,我先简单介绍下什么是捕获组和非捕获组。
捕获组是指把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,方便后面引用。一般一个 () 就是一个捕获组,捕获组可以进行嵌套。
非捕获组则是指参与匹配却不进行分组编号的捕获组,其表达式一般由(?:exp)组成。
减少不需要获取的分组,可以提高正则表达式的性能。
5.ArrayList与LinkedList性能解析
初识 List 接口
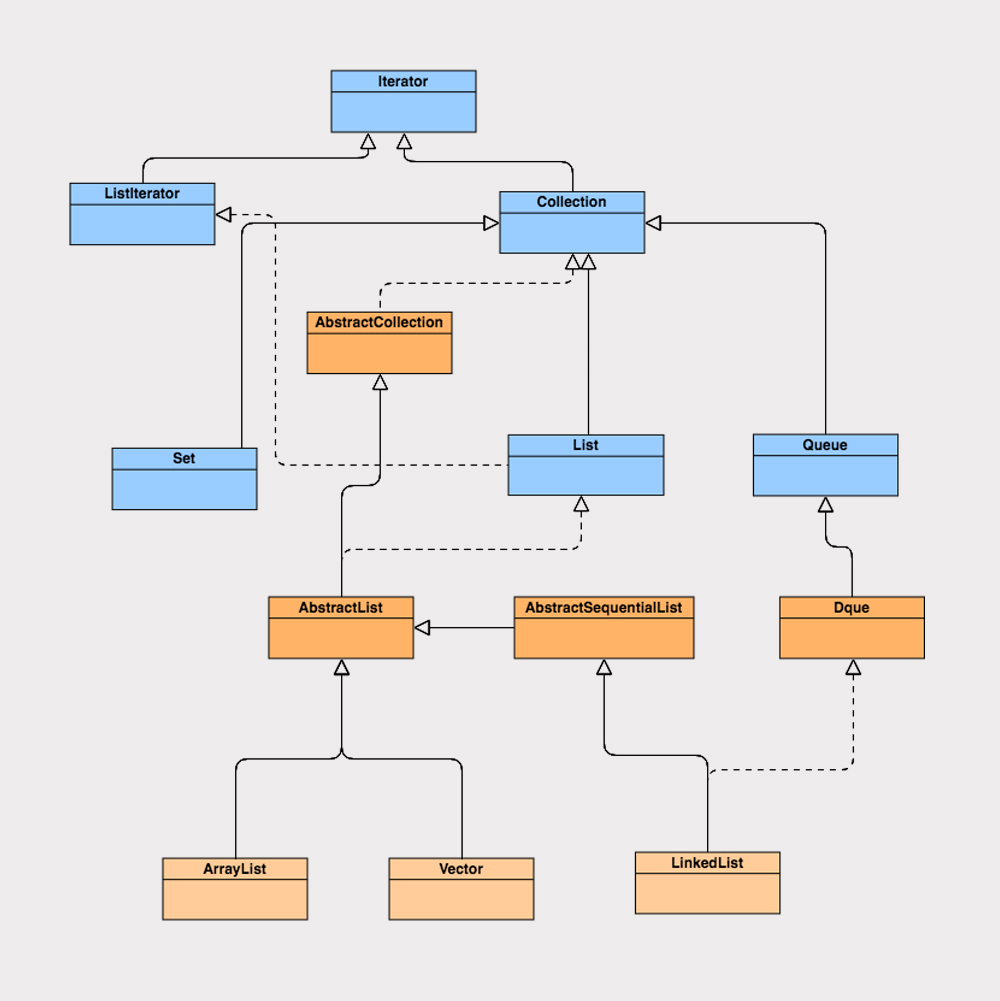
ArrayList 实现了 List 接口,继承了 AbstractList 抽象类,底层是数组实现的,并且实现了自增扩容数组大小。
ArrayList 还实现了 Cloneable 接口和 Serializable 接口,所以他可以实现克隆和序列化。
ArrayList 还实现了 RandomAccess 接口。RandomAccess 接口是一个标志接口,他标志着“只要实现该接口的 List 类,都能实现快速随机访问”。
ArrayList 属性主要由数组长度 size、对象数组 elementData、初始化容量 default_capacity 等组成, 其中初始化容量默认大小为 10。
从 ArrayList 属性来看,它没有被任何的多线程关键字修饰,但 elementData 被关键字 transient 修饰了。
如果采用外部序列化法实现数组的序列化,会序列化整个数组。ArrayList 为了避免这些没有存储数据的内存空间被序列化,内部提供了两个私有方法 writeObject 以及 readObject 来自我完成序列化与反序列化,从而在序列化与反序列化数组时节省了空间和时间。
因此使用 transient 修饰数组,是防止对象数组被其他外部方法序列化。
ArrayList 构造函数:ArrayList 类实现了三个构造函数,第一个是创建 ArrayList 对象时,传入一个初始化值;第二个是默认创建一个空数组对象;第三个是传入一个集合类型进行初始化。
当 ArrayList 新增元素时,如果所存储的元素已经超过其已有大小,它会计算元素大小后再进行动态扩容,数组的扩容会导致整个数组进行一次内存复制。因此,我们在初始化 ArrayList 时,可以通过第一个构造函数合理指定数组初始大小,这样有助于减少数组的扩容次数,从而提高系统性能。
ArrayList 新增元素
ArrayList 新增元素的方法有两种,一种是直接将元素加到数组的末尾,另外一种是添加元素到任意位置。
两个方法的相同之处是在添加元素之前,都会先确认容量大小,如果容量够大,就不用进行扩容;如果容量不够大,就会按照原来数组的 1.5 倍大小进行扩容,在扩容之后需要将数组复制到新分配的内存地址。
当然,两个方法也有不同之处,添加元素到任意位置,会导致在该位置后的所有元素都需要重新排列,而将元素添加到数组的末尾,在没有发生扩容的前提下,是不会有元素复制排序过程的。
ArrayList 删除元素
ArrayList 的删除方法和添加任意位置元素的方法是有些相同的。ArrayList 在每一次有效的删除元素操作之后,都要进行数组的重组,并且删除的元素位置越靠前,数组重组的开销就越大。
LinkedList 是如何实现的?
虽然 LinkedList 与 ArrayList 都是 List 类型的集合,但 LinkedList 的实现原理却和 ArrayList 大相径庭,使用场景也不太一样。
LinkedList 是基于双向链表数据结构实现的,LinkedList 定义了一个 Node 结构,Node 结构中包含了 3 个部分:元素内容 item、前指针 prev 以及后指针 next,代码如下。
private static class Node
{
E item;
Nodenext;
Nodeprev;
Node(Nodeprev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList 类实现了 List 接口、Deque 接口,同时继承了 AbstractSequentialList 抽象类,LinkedList 既实现了 List 类型又有 Queue 类型的特点;LinkedList 也实现了 Cloneable 和 Serializable 接口,同 ArrayList 一样,可以实现克隆和序列化。
由于 LinkedList 存储数据的内存地址是不连续的,而是通过指针来定位不连续地址,因此,LinkedList 不支持随机快速访问,LinkedList 也就不能实现 RandomAccess 接口。
LinkedList 新增元素
LinkedList 添加元素的实现很简洁,但添加的方式却有很多种。默认的 add (Ee) 方法是将添加的元素加到队尾,首先是将 last 元素置换到临时变量中,生成一个新的 Node 节点对象,然后将 last 引用指向新节点对象,之前的 last 对象的前指针指向新节点对象。
LinkedList 也有添加元素到任意位置的方法,如果我们是将元素添加到任意两个元素的中间位置,添加元素操作只会改变前后元素的前后指针,指针将会指向添加的新元素,所以相比 ArrayList 的添加操作来说,LinkedList 的性能优势明显。
LinkedList 删除元素
在 LinkedList 删除元素的操作中,我们首先要通过循环找到要删除的元素,如果要删除的位置处于 List 的前半段,就从前往后找;若其位置处于后半段,就从后往前找。
这样做的话,无论要删除较为靠前或较为靠后的元素都是非常高效的,但如果 List 拥有大量元素,移除的元素又在 List 的中间段,那效率相对来说会很低。
LinkedList 遍历元素
LinkedList 的获取元素操作实现跟 LinkedList 的删除元素操作基本类似,通过分前后半段来循环查找到对应的元素。但是通过这种方式来查询元素是非常低效的,特别是在 for 循环遍历的情况下,每一次循环都会去遍历半个 List。
所以在 LinkedList 循环遍历时,我们可以使用 iterator 方式迭代循环,直接拿到我们的元素,而不需要通过循环查找 List。
ArrayList 和 LinkedList 新增元素操作测试
从集合头部位置新增元素
从集合中间位置新增元素
从集合尾部位置新增元素
测试结果 (花费时间):
ArrayList>LinkedList
ArrayList<LinkedList
ArrayList<LinkedList
通过这组测试,我们可以知道 LinkedList 添加元素的效率未必要高于 ArrayList。
由于 ArrayList 是数组实现的,而数组是一块连续的内存空间,在添加元素到数组头部的时候,需要对头部以后的数据进行复制重排,所以效率很低;而 LinkedList 是基于链表实现,在添加元素的时候,首先会通过循环查找到添加元素的位置,如果要添加的位置处于 List 的前半段,就从前往后找;若其位置处于后半段,就从后往前找。因此 LinkedList 添加元素到头部是非常高效的。
同上可知,ArrayList 在添加元素到数组中间时,同样有部分数据需要复制重排,效率也不是很高;LinkedList 将元素添加到中间位置,是添加元素最低效率的,因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作。
而在添加元素到尾部的操作中,我们发现,在没有扩容的情况下,ArrayList 的效率要高于 LinkedList。这是因为 ArrayList 在添加元素到尾部的时候,不需要复制重排数据,效率非常高。而 LinkedList 虽然也不用循环查找元素,但 LinkedList 中多了 new 对象以及变换指针指向对象的过程,所以效率要低于 ArrayList。
说明一下,这里我是基于 ArrayList 初始化容量足够,排除动态扩容数组容量的情况下进行的测试,如果有动态扩容的情况,ArrayList 的效率也会降低。
ArrayList 和 LinkedList 遍历元素操作测试
for(; ; ) 循环
迭代器迭代循环
测试结果 (花费时间):
ArrayList
ArrayList≈LinkedList
我们可以看到,LinkedList 的 for 循环性能是最差的,而 ArrayList 的 for 循环性能是最好的。
这是因为 LinkedList 基于链表实现的,在使用 for 循环的时候,每一次 for 循环都会去遍历半个 List,所以严重影响了遍历的效率;ArrayList 则是基于数组实现的,并且实现了 RandomAccess 接口标志,意味着 ArrayList 可以实现快速随机访问,所以 for 循环效率非常高。
LinkedList 的迭代循环遍历和 ArrayList 的迭代循环遍历性能相当,也不会太差,所以在遍历 LinkedList 时,我们要切忌使用 for 循环遍历。
6.Stream如何提高遍历集合效率?
什么是 Stream?
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他可以通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的聚合操作了,而在数据操作方面,Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
Stream 如何优化遍历?
1.Stream 操作分类
官方将 Stream 中的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作,而终结操作是实现了计算操作。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
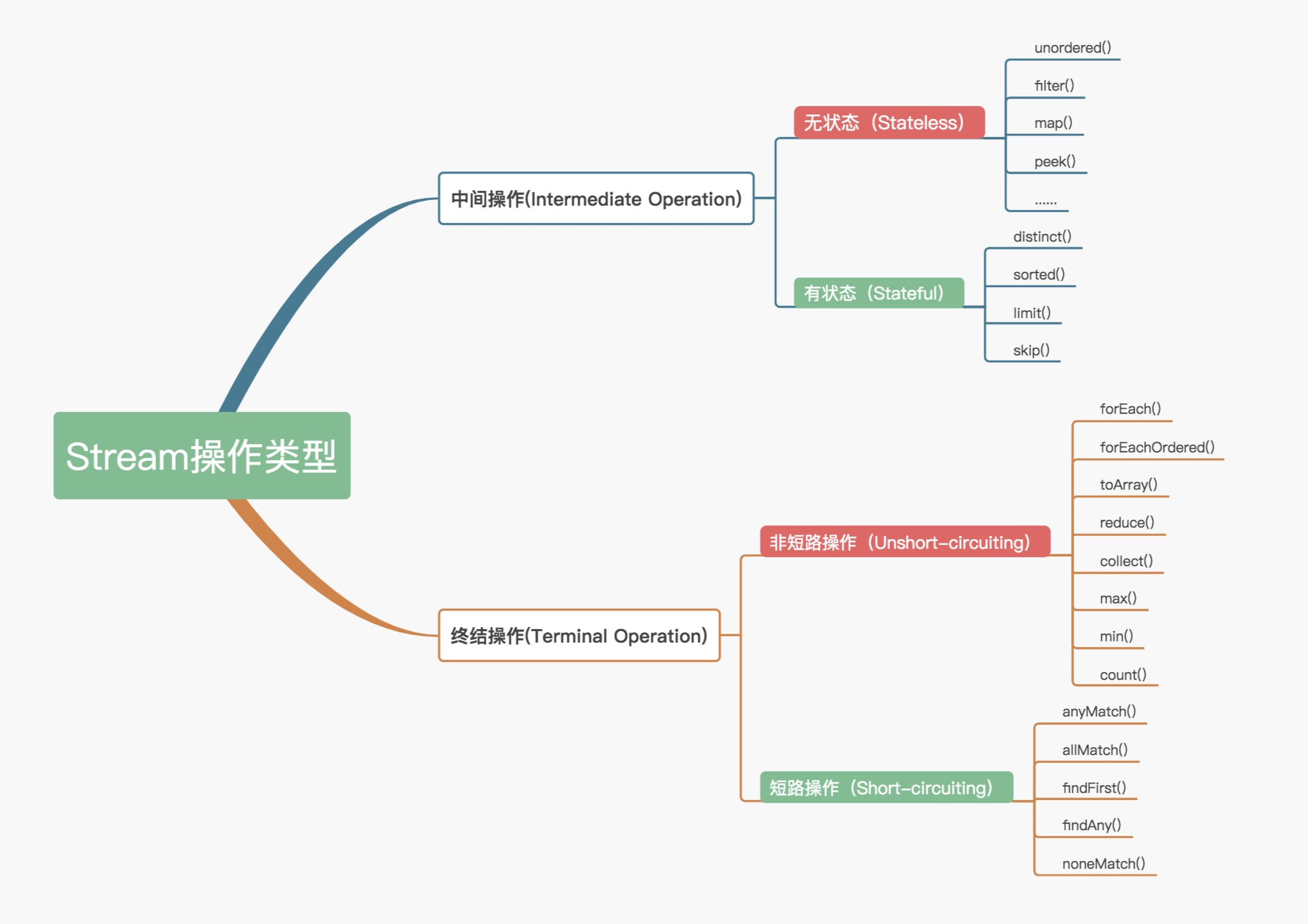
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了 Stream 的高效。
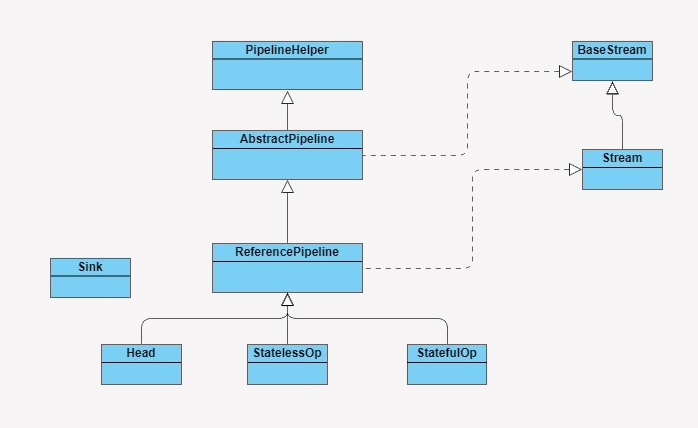
2.Stream 源码实现
在了解 Stream 如何工作之前,我们先来了解下 Stream 包是由哪些主要结构类组合而成的,各个类的职责是什么。参照下图:
3.Stream 操作叠加
我们知道,一个 Stream 的各个操作是由处理管道组装,并统一完成数据处理的。在 JDK 中每次的中断操作会以使用阶段(Stage)命名。
管道结构通常是由 ReferencePipeline 类实现的,前面讲解 Stream 包结构时,我提到过 ReferencePipeline 包含了 Head、StatelessOp、StatefulOp 三种内部类。
Head 类主要用来定义数据源操作,在我们初次调用 names.stream() 方法时,会初次加载 Head 对象,此时为加载数据源操作;接着加载的是中间操作,分别为无状态中间操作 StatelessOp 对象和有状态操作 StatefulOp 对象,此时的 Stage 并没有执行,而是通过 AbstractPipeline 生成了一个中间操作 Stage 链表;当我们调用终结操作时,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个 Stage 开始,递归产生一个 Sink 链。如下图所示:
4.Stream 并行处理
Stream 处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在stream()后新增一个 Parallel() 方法。
Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用 TerminalOp 的 evaluateParallel 方法进行并行处理。
这里的并行处理指的是,Stream 结合了 ForkJoin 框架,对 Stream 处理进行了分片,Splititerator 中的 estimateSize 方法会估算出分片的数据量。
通过预估的数据量获取最小处理单元的阀值,如果当前分片大小大于最小处理单元的阀值,就继续切分集合。每个分片将会生成一个 Sink 链表,当所有的分片操作完成后,ForkJoin 框架将会合并分片任何结果集。
合理使用 Stream
在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
用事实说话,我们看到其实使用 Stream 未必可以使系统性能更佳,还是要结合应用场景进行选择,也就是合理地使用 Stream。
从小的分类方向上来说,Stream 将遍历元素的操作和对元素的计算分为中间操作和终结操作,而中间操作又根据元素之间状态有无干扰分为有状态和无状态操作,实现了链结构中的不同阶段。
在串行处理操作中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8 中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在并行处理操作中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,ForkJoin 框架将每个切片的处理结果 Join 合并起来。
7.深入浅出HashMap的设计与优化
常用的数据结构
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为 O(1),但在数组中间以及头部插入数据时,需要复制移动后面的元素。
链表:一种在物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素)组成,结点可以在运行时动态生成。每个结点都包含“存储数据单元的数据域”和“存储下一个结点地址的指针域”这两个部分。
由于链表不用必须按顺序存储,所以链表在插入的时候可以达到 O(1) 的复杂度,但查找一个结点或者访问特定编号的结点需要 O(n) 的时间。
哈希表:根据关键码值(Key value)直接进行访问的数据结构。通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数,存放记录的数组就叫做哈希表。
树:由 n(n≥1)个有限结点组成的一个具有层次关系的集合,就像是一棵倒挂的树。
HashMap 的实现结构
哈希表将键的 Hash 值映射到内存地址,即根据键获取对应的值,并将其存储到内存地址。也就是说 HashMap 是根据键的 Hash 值来决定对应值的存储位置。通过这种索引方式,HashMap 获取数据的速度会非常快。
例如,存储键值对(x,“aa”)时,哈希表会通过哈希函数 f(x) 得到"aa"的实现存储位置。
但也会有新的问题。如果再来一个 (y,“bb”),哈希函数 f(y) 的哈希值跟之前 f(x) 是一样的,这样两个对象的存储地址就冲突了,这种现象就被称为哈希冲突。那么哈希表是怎么解决的呢?方式有很多,比如,开放定址法、再哈希函数法和链地址法。
开放定址法很简单,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把 key 存放到冲突位置的空位置上去。这种方法存在着很多缺点,例如,查找、扩容等,所以我不建议你作为解决哈希冲突的首选。
再哈希法顾名思义就是在同义词产生地址冲突时再计算另一个哈希函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但却增加了计算时间。如果我们不考虑添加元素的时间成本,且对查询元素的要求极高,就可以考虑使用这种算法设计。
HashMap 则是综合考虑了所有因素,采用链地址法解决哈希冲突问题。这种方法是采用了数组(哈希表)+ 链表的数据结构,当发生哈希冲突时,就用一个链表结构存储相同 Hash 值的数据。
HashMap 的重要属性
从 HashMap 的源码中,我们可以发现,HashMap 是由一个 Node 数组构成,每个 Node 包含了一个 key-value 键值对。
Node 类作为 HashMap 中的一个内部类,除了 key、value 两个属性外,还定义了一个 next 指针。当有哈希冲突时,HashMap 会用之前数组当中相同哈希值对应存储的 Node 对象,通过指针指向新增的相同哈希值的 Node 对象的引用。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
HashMap 还有两个重要的属性:加载因子(loadFactor)和边界值(threshold)。在初始化 HashMap 时,就会涉及到这两个关键初始化参数。
实际应用中,我们设置初始容量,一般得是 2 的整数次幂。通过将 Key 的 hash 值与 length-1 进行 & 运算,实现了当前 Key 的定位,2 的幂次方可以减少冲突(碰撞)的次数,提高 HashMap 查询效率。
LoadFactor 属性是用来间接设置 Entry 数组(哈希表)的内存空间大小,在初始 HashMap 不设置参数的情况下,默认 LoadFactor 值为 0.75。为什么是 0.75 这个值呢?
这是因为对于使用链表法的哈希表来说,查找一个元素的平均时间是 O(1+n),这里的 n 指的是遍历链表的长度,因此加载因子越大,对空间的利用就越充分,这就意味着链表的长度越长,查找效率也就越低。如果设置的加载因子太小,那么哈希表的数据将过于稀疏,对空间造成严重浪费。
entry 数组的 Threshold 是通过初始容量和 LoadFactor 计算所得,在初始 HashMap 不设置参数的情况下,默认边界值为 12。如果我们在初始化时,设置的初始化容量较小,HashMap 中 Node 的数量超过边界值,HashMap 就会调用 resize() 方法重新分配 table 数组。这将会导致 HashMap 的数组复制,迁移到另一块内存中去,从而影响 HashMap 的效率。
HashMap 添加元素优化
初始化完成后,HashMap 就可以使用 put() 方法添加键值对了。从下面源码可以看出,当程序将一个 key-value 对添加到 HashMap 中,程序首先会根据该 key 的 hashCode() 返回值,再通过 hash() 方法计算出 hash 值,再通过 putVal 方法中的 (n - 1) & hash 决定该 Node 的存储位置。
HashMap 扩容优化
HashMap 也是数组类型的数据结构,所以一样存在扩容的情况。
在 JDK1.7 中,HashMap 整个扩容过程就是分别取出数组元素,一般该元素是最后一个放入链表中的元素,然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标,然后进行交换。这样的扩容方式会将原来哈希冲突的单向链表尾部变成扩容后单向链表的头部。
而在 JDK 1.8 中,HashMap 对扩容操作做了优化。由于扩容数组的长度是 2 倍关系,所以对于假设初始 tableSize = 4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值和左移动的一位(newtable 的值)按位与操作是 0 或 1 就行,0 的话索引不变,1 的话索引变成原索引加上扩容前数组。
之所以能通过这种“与运算“来重新分配索引,是因为 hash 值本来就是随机的,而 hash 按位与上 newTable 得到的 0(扩容前的索引位置)和 1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的,所以扩容的过程就能把之前哈希冲突的元素再随机分布到不同的索引中去。
我们在使用 HashMap 时,可以结合自己的场景来设置初始容量和加载因子两个参数。当查询操作较为频繁时,我们可以适当地减少加载因子;如果对内存利用率要求比较高,我可以适当的增加加载因子。
我们还可以在预知存储数据量的情况下,提前设置初始容量(初始容量 = 预知数据量 / 加载因子)。这样做的好处是可以减少 resize() 操作,提高 HashMap 的效率。
8.网络通信优化之I/O模型
什么是 I/O
I/O 是机器获取和交换信息的主要渠道,而流是完成 I/O 操作的主要方式。
在计算机中,流是一种信息的转换。流是有序的,因此相对于某一机器或者应用程序而言,我们通常把机器或者应用程序接收外界的信息称为输入流(InputStream),从机器或者应用程序向外输出的信息称为输出流(OutputStream),合称为输入 / 输出流(I/O Streams)。
机器间或程序间在进行信息交换或者数据交换时,总是先将对象或数据转换为某种形式的流,再通过流的传输,到达指定机器或程序后,再将流转换为对象数据。因此,流就可以被看作是一种数据的载体,通过它可以实现数据交换和传输。
传统 I/O 的性能问题
我们知道,I/O 操作分为磁盘 I/O 操作和网络 I/O 操作。前者是从磁盘中读取数据源输入到内存中,之后将读取的信息持久化输出在物理磁盘上;后者是从网络中读取信息输入到内存,最终将信息输出到网络中。但不管是磁盘 I/O 还是网络 I/O,在传统 I/O 中都存在严重的性能问题。
1. 多次内存复制
在传统 I/O 中,我们可以通过 InputStream 从源数据中读取数据流输入到缓冲区里,通过 OutputStream 将数据输出到外部设备(包括磁盘、网络)。你可以先看下输入操作在操作系统中的具体流程,如下图所示:
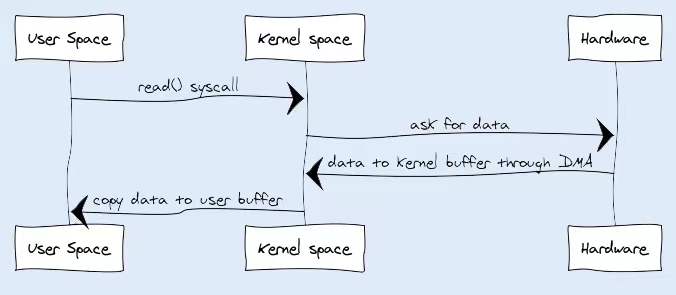
- JVM 会发出 read() 系统调用,并通过 read 系统调用向内核发起读请求;
- 内核向硬件发送读指令,并等待读就绪;
- 内核把将要读取的数据复制到指向的内核缓存中;
- 操作系统内核将数据复制到用户空间缓冲区,然后 read 系统调用返回。
在这个过程中,数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低 I/O 的性能。
2. 阻塞
在传统 I/O 中,InputStream 的 read() 是一个 while 循环操作,它会一直等待数据读取,直到数据就绪才会返回。这就意味着如果没有数据就绪,这个读取操作将会一直被挂起,用户线程将会处于阻塞状态。
在少量连接请求的情况下,使用这种方式没有问题,响应速度也很高。但在发生大量连接请求时,就需要创建大量监听线程,这时如果线程没有数据就绪就会被挂起,然后进入阻塞状态。一旦发生线程阻塞,这些线程将会不断地抢夺 CPU 资源,从而导致大量的 CPU 上下文切换,增加系统的性能开销。
如何优化 I/O 操作
面对以上两个性能问题,不仅编程语言对此做了优化,各个操作系统也进一步优化了 I/O。JDK1.4 发布了 java.nio 包(new I/O 的缩写),NIO 的发布优化了内存复制以及阻塞导致的严重性能问题。JDK1.7 又发布了 NIO2,提出了从操作系统层面实现的异步 I/O。下面我们就来了解下具体的优化实现。
1. 使用缓冲区优化读写流操作
传统 I/O 和 NIO 的最大区别就是传统 I/O 是面向流,NIO 是面向 Buffer。Buffer 可以将文件一次性读入内存再做后续处理,而传统的方式是边读文件边处理数据。虽然传统 I/O 后面也使用了缓冲块,例如 BufferedInputStream,但仍然不能和 NIO 相媲美。使用 NIO 替代传统 I/O 操作,可以提升系统的整体性能,效果立竿见影。
2. 使用 DirectBuffer 减少内存复制
NIO 的 Buffer 除了做了缓冲块优化之外,还提供了一个可以直接访问物理内存的类 DirectBuffer。普通的 Buffer 分配的是 JVM 堆内存,而 DirectBuffer 是直接分配物理内存。
我们知道数据要输出到外部设备,必须先从用户空间复制到内核空间,再复制到输出设备,而 DirectBuffer 则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
3. 避免阻塞,优化 I/O 操作
传统的 I/O 即使使用了缓冲块,依然存在阻塞问题。由于线程池线程数量有限,一旦发生大量并发请求,超过最大数量的线程就只能等待,直到线程池中有空闲的线程可以被复用。
而对 Socket 的输入流进行读取时,读取流会一直阻塞,直到发生以下三种情况的任意一种才会解除阻塞:
- 有数据可读;
- 连接释放;
- 空指针或 I/O 异常。
阻塞问题,就是传统 I/O 最大的弊端。NIO 发布后,通道和多路复用器这两个基本组件实现了 NIO 的非阻塞,下面我们就一起来了解下这两个组件的优化原理。
通道(Channel)
前面我们讨论过,传统 I/O 的数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
最开始,在应用程序调用操作系统 I/O 接口时,是由 CPU 完成分配,这种方式最大的问题是“发生大量 I/O 请求时,非常消耗 CPU“;之后,操作系统引入了 DMA(直接存储器存储),内核空间与磁盘之间的存取完全由 DMA 负责,但这种方式依然需要向 CPU 申请权限,且需要借助 DMA 总线来完成数据的复制操作,如果 DMA 总线过多,就会造成总线冲突。
通道的出现解决了以上问题,Channel 有自己的处理器,可以完成内核空间和磁盘之间的 I/O 操作。在 NIO 中,我们读取和写入数据都要通过 Channel,由于 Channel 是双向的,所以读、写可以同时进行。
多路复用器(Selector)
Selector 是 Java NIO 编程的基础。用于检查一个或多个 NIO Channel 的状态是否处于可读、可写。
Selector 是基于事件驱动实现的,我们可以在 Selector 中注册 accpet、read 监听事件,Selector 会不断轮询注册在其上的 Channel,如果某个 Channel 上面发生监听事件,这个 Channel 就处于就绪状态,然后进行 I/O 操作。
一个线程使用一个 Selector,通过轮询的方式,可以监听多个 Channel 上的事件。我们可以在注册 Channel 时设置该通道为非阻塞,当 Channel 上没有 I/O 操作时,该线程就不会一直等待了,而是会不断轮询所有 Channel,从而避免发生阻塞。
目前操作系统的 I/O 多路复用机制都使用了 epoll,相比传统的 select 机制,epoll 没有最大连接句柄 1024 的限制。所以 Selector 在理论上可以轮询成千上万的客户端。
9.网络通信优化之序列化
当前大部分后端服务都是基于微服务架构实现的。服务按照业务划分被拆分,实现了服务的解偶,但同时也带来了新的问题,不同业务之间通信需要通过接口实现调用。两个服务之间要共享一个数据对象,就需要从对象转换成二进制流,通过网络传输,传送到对方服务,再转换回对象,供服务方法调用。这个编码和解码过程我们称之为序列化与反序列化。
在大量并发请求的情况下,如果序列化的速度慢,会导致请求响应时间增加;而序列化后的传输数据体积大,会导致网络吞吐量下降。所以一个优秀的序列化框架可以提高系统的整体性能。
我们知道,Java 提供了 RMI 框架可以实现服务与服务之间的接口暴露和调用,RMI 中对数据对象的序列化采用的是 Java 序列化。而目前主流的微服务框架却几乎没有用到 Java 序列化,SpringCloud 用的是 Json 序列化,Dubbo 虽然兼容了 Java 序列化,但默认使用的是 Hessian 序列化。
Java 序列化
在说缺陷之前,你先得知道什么是 Java 序列化以及它的实现原理。
Java 提供了一种序列化机制,这种机制能够将一个对象序列化为二进制形式(字节数组),用于写入磁盘或输出到网络,同时也能从网络或磁盘中读取字节数组,反序列化成对象,在程序中使用。
JDK 提供的两个输入、输出流对象 ObjectInputStream 和 ObjectOutputStream,它们只能对实现了 Serializable 接口的类的对象进行反序列化和序列化。
ObjectOutputStream 的默认序列化方式,仅对对象的非 transient 的实例变量进行序列化,而不会序列化对象的 transient 的实例变量,也不会序列化静态变量。
在实现了 Serializable 接口的类的对象中,会生成一个 serialVersionUID 的版本号,这个版本号有什么用呢?它会在反序列化过程中来验证序列化对象是否加载了反序列化的类,如果是具有相同类名的不同版本号的类,在反序列化中是无法获取对象的。
具体实现序列化的是 writeObject 和 readObject,通常这两个方法是默认的,当然我们也可以在实现 Serializable 接口的类中对其进行重写,定制一套属于自己的序列化与反序列化机制。
另外,Java 序列化的类中还定义了两个重写方法:writeReplace() 和 readResolve(),前者是用来在序列化之前替换序列化对象的,后者是用来在反序列化之后对返回对象进行处理的。
Java 序列化的缺陷:1.无法跨语言,2.易被攻击,3.序列化后的流太大,4.序列化性能太差
使用 Protobuf 序列化替换 Java 序列化
目前业内优秀的序列化框架有很多,而且大部分都避免了 Java 默认序列化的一些缺陷。例如,最近几年比较流行的 FastJson、Kryo、Protobuf、Hessian 等。我们完全可以找一种替换掉 Java 序列化,这里我推荐使用 Protobuf 序列化框架。
Protobuf 是由 Google 推出且支持多语言的序列化框架,目前在主流网站上的序列化框架性能对比测试报告中,Protobuf 无论是编解码耗时,还是二进制流压缩大小,都名列前茅。
Protobuf 以一个 .proto 后缀的文件为基础,这个文件描述了字段以及字段类型,通过工具可以生成不同语言的数据结构文件。在序列化该数据对象的时候,Protobuf 通过.proto 文件描述来生成 Protocol Buffers 格式的编码。
Protocol Buffers 是一种轻便高效的结构化数据存储格式。它使用 T-L-V(标识 - 长度 - 字段值)的数据格式来存储数据,T 代表字段的正数序列 (tag),Protocol Buffers 将对象中的每个字段和正数序列对应起来,对应关系的信息是由生成的代码来保证的。在序列化的时候用整数值来代替字段名称,于是传输流量就可以大幅缩减;L 代表 Value 的字节长度,一般也只占一个字节;V 则代表字段值经过编码后的值。这种数据格式不需要分隔符,也不需要空格,同时减少了冗余字段名。
Protobuf 定义了一套自己的编码方式,几乎可以映射 Java/Python 等语言的所有基础数据类型。不同的编码方式对应不同的数据类型,还能采用不同的存储格式。如下图所示:
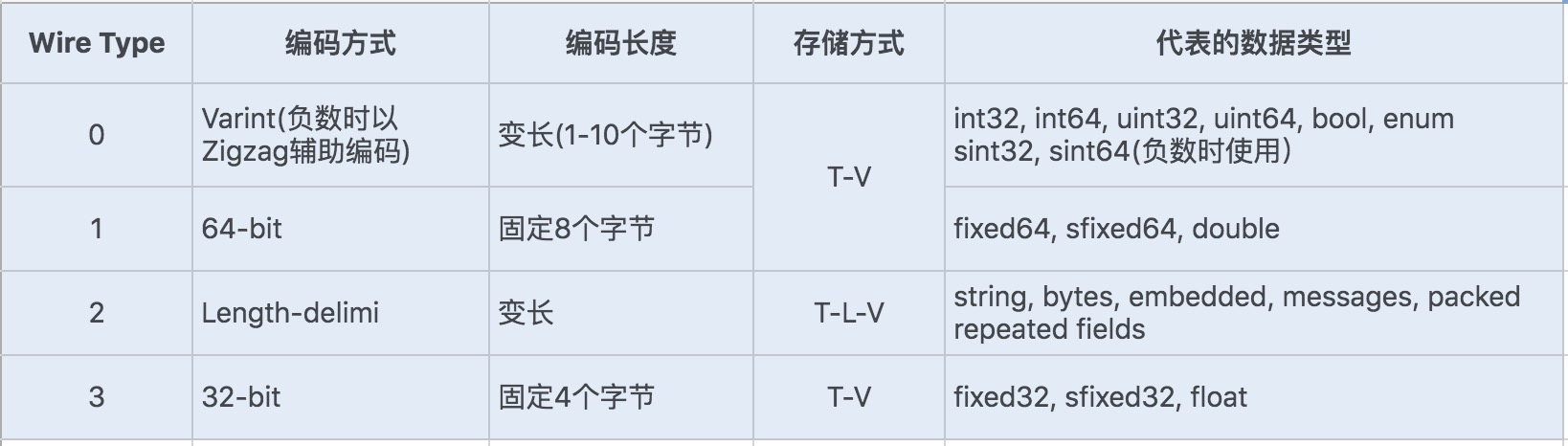
Protobuf 的这种数据存储格式,不仅压缩存储数据的效果好, 在编码和解码的性能方面也很高效。Protobuf 的编码和解码过程结合.proto 文件格式,加上 Protocol Buffer 独特的编码格式,只需要简单的数据运算以及位移等操作就可以完成编码与解码。可以说 Protobuf 的整体性能非常优秀。
10.网络通信优化之通信协议
RPC 通信是大型服务框架的核心
目前,很多微服务框架中的服务通信是基于 RPC 通信实现的,在没有进行组件扩展的前提下,SpringCloud 是基于 Feign 组件实现的 RPC 通信(基于 Http+Json 序列化实现),Dubbo 是基于 SPI 扩展了很多 RPC 通信框架,包括 RMI、Dubbo、Hessian 等 RPC 通信框架(默认是 Dubbo+Hessian 序列化)。不同的业务场景下,RPC 通信的选择和优化标准也不同。
无论从响应时间还是吞吐量上来看,单一 TCP 长连接 +Protobuf 序列化实现的 RPC 通信框架都有着非常明显的优势。
什么是 RPC 通信
RPC(Remote Process Call),即远程服务调用,是通过网络请求远程计算机程序服务的通信技术。RPC 框架封装好了底层网络通信、序列化等技术,我们只需要在项目中引入各个服务的接口包,就可以实现在代码中调用 RPC 服务同调用本地方法一样。正因为这种方便、透明的远程调用,RPC 被广泛应用于当下企业级以及互联网项目中,是实现分布式系统的核心。
RMI(Remote Method Invocation)是 JDK 中最先实现了 RPC 通信的框架之一,RMI 的实现对建立分布式 Java 应用程序至关重要,是 Java 体系非常重要的底层技术,很多开源的 RPC 通信框架也是基于 RMI 实现原理设计出来的,包括 Dubbo 框架中也接入了 RMI 框架。接下来我们就一起了解下 RMI 的实现原理,看看它存在哪些性能瓶颈有待优化。
RMI 远程代理对象是 RMI 中最核心的组件,除了对象本身所在的虚拟机,其它虚拟机也可以调用此对象的方法。而且这些虚拟机可以不在同一个主机上,通过远程代理对象,远程应用可以用网络协议与服务进行通信。
RMI 在高并发场景下的性能瓶颈
1. Java 默认序列化
RMI 的序列化采用的是 Java 默认的序列化方式,我们深知它的性能并不是很好,而且其它语言框架也暂时不支持 Java 序列化。
2. TCP 短连接
由于 RMI 是基于 TCP 短连接实现,在高并发情况下,大量请求会带来大量连接的创建和销毁,这对于系统来说无疑是非常消耗性能的。
3. 阻塞式网络 I/O
网络通信存在 I/O 瓶颈,如果在 Socket 编程中使用传统的 I/O 模型,在高并发场景下基于短连接实现的网络通信就很容易产生 I/O 阻塞,性能将会大打折扣。
一个高并发场景下的 RPC 通信优化路径
SpringCloud 的 RPC 通信和 RMI 通信的性能瓶颈就非常相似。SpringCloud 是基于 Http 通信协议(短连接)和 Json 序列化实现的,在高并发场景下并没有优势。 那么,在瞬时高并发的场景下,我们又该如何去优化一个 RPC 通信呢?
RPC 通信包括了建立通信、实现报文、传输协议以及传输数据编解码等操作,接下来我们就从每一层的优化出发,逐步实现整体的性能优化。
1. 选择合适的通信协议
基于 TCP 协议实现的 Socket 通信是有连接的,而传输数据是要通过三次握手来实现数据传输的可靠性,且传输数据是没有边界的,采用的是字节流模式。
基于 UDP 协议实现的 Socket 通信,客户端不需要建立连接,只需要创建一个套接字发送数据报给服务端,这样就不能保证数据报一定会达到服务端,所以在传输数据方面,基于 UDP 协议实现的 Socket 通信具有不可靠性。UDP 发送的数据采用的是数据报模式,每个 UDP 的数据报都有一个长度,该长度将与数据一起发送到服务端。
通过对比,我们可以得出优化方法:为了保证数据传输的可靠性,通常情况下我们会采用 TCP 协议。如果在局域网且对数据传输的可靠性没有要求的情况下,我们也可以考虑使用 UDP 协议,毕竟这种协议的效率要比 TCP 协议高。
2. 使用单一长连接
如果是基于 TCP 协议实现 Socket 通信,我们还能做哪些优化呢?
服务之间的通信不同于客户端与服务端之间的通信。客户端与服务端由于客户端数量多,基于短连接实现请求可以避免长时间地占用连接,导致系统资源浪费。
但服务之间的通信,连接的消费端不会像客户端那么多,但消费端向服务端请求的数量却一样多,我们基于长连接实现,就可以省去大量的 TCP 建立和关闭连接的操作,从而减少系统的性能消耗,节省时间。
3. 优化 Socket 通信
建立两台机器的网络通信,我们一般使用 Java 的 Socket 编程实现一个 TCP 连接。传统的 Socket 通信主要存在 I/O 阻塞、线程模型缺陷以及内存拷贝等问题。我们可以使用比较成熟的通信框架,比如 Netty。Netty4 对 Socket 通信编程做了很多方面的优化,具体见下方。
实现非阻塞 I/O:在 08 讲中,我们提到了多路复用器 Selector 实现了非阻塞 I/O 通信。
高效的 Reactor 线程模型:Netty 使用了主从 Reactor 多线程模型,服务端接收客户端请求连接是用了一个主线程,这个主线程用于客户端的连接请求操作,一旦连接建立成功,将会监听 I/O 事件,监听到事件后会创建一个链路请求。
链路请求将会注册到负责 I/O 操作的 I/O 工作线程上,由 I/O 工作线程负责后续的 I/O 操作。利用这种线程模型,可以解决在高负载、高并发的情况下,由于单个 NIO 线程无法监听海量客户端和满足大量 I/O 操作造成的问题。
串行设计:服务端在接收消息之后,存在着编码、解码、读取和发送等链路操作。如果这些操作都是基于并行去实现,无疑会导致严重的锁竞争,进而导致系统的性能下降。为了提升性能,Netty 采用了串行无锁化完成链路操作,Netty 提供了 Pipeline 实现链路的各个操作在运行期间不进行线程切换。
零拷贝:在 08 讲中,我们提到了一个数据从内存发送到网络中,存在着两次拷贝动作,先是从用户空间拷贝到内核空间,再是从内核空间拷贝到网络 I/O 中。而 NIO 提供的 ByteBuffer 可以使用 Direct Buffers 模式,直接开辟一个非堆物理内存,不需要进行字节缓冲区的二次拷贝,可以直接将数据写入到内核空间。
除了以上这些优化,我们还可以针对套接字编程提供的一些 TCP 参数配置项,提高网络吞吐量,Netty 可以基于 ChannelOption 来设置这些参数。
TCP_NODELAY:TCP_NODELAY 选项是用来控制是否开启 Nagle 算法。Nagle 算法通过缓存的方式将小的数据包组成一个大的数据包,从而避免大量的小数据包发送阻塞网络,提高网络传输的效率。我们可以关闭该算法,优化对于时延敏感的应用场景。
SO_RCVBUF 和 SO_SNDBUF:可以根据场景调整套接字发送缓冲区和接收缓冲区的大小。
SO_BACKLOG:backlog 参数指定了客户端连接请求缓冲队列的大小。服务端处理客户端连接请求是按顺序处理的,所以同一时间只能处理一个客户端连接,当有多个客户端进来的时候,服务端就会将不能处理的客户端连接请求放在队列中等待处理。
SO_KEEPALIVE:当设置该选项以后,连接会检查长时间没有发送数据的客户端的连接状态,检测到客户端断开连接后,服务端将回收该连接。我们可以将该时间设置得短一些,来提高回收连接的效率。
4. 量身定做报文格式
接下来就是实现报文,我们需要设计一套报文,用于描述具体的校验、操作、传输数据等内容。为了提高传输的效率,我们可以根据自己的业务和架构来考虑设计,尽量实现报体小、满足功能、易解析等特性。我们可以参考下面的数据格式:


5. 编码、解码
我们分析过序列化编码和解码的过程,对于实现一个好的网络通信协议来说,兼容优秀的序列化框架是非常重要的。如果只是单纯的数据对象传输,我们可以选择性能相对较好的 Protobuf 序列化,有利于提高网络通信的性能。
6. 调整 Linux 的 TCP 参数设置选项
如果 RPC 是基于 TCP 短连接实现的,我们可以通过修改 Linux TCP 配置项来优化网络通信。开始 TCP 配置项的优化之前,我们先来了解下建立 TCP 连接的三次握手和关闭 TCP 连接的四次握手,这样有助后面内容的理解。
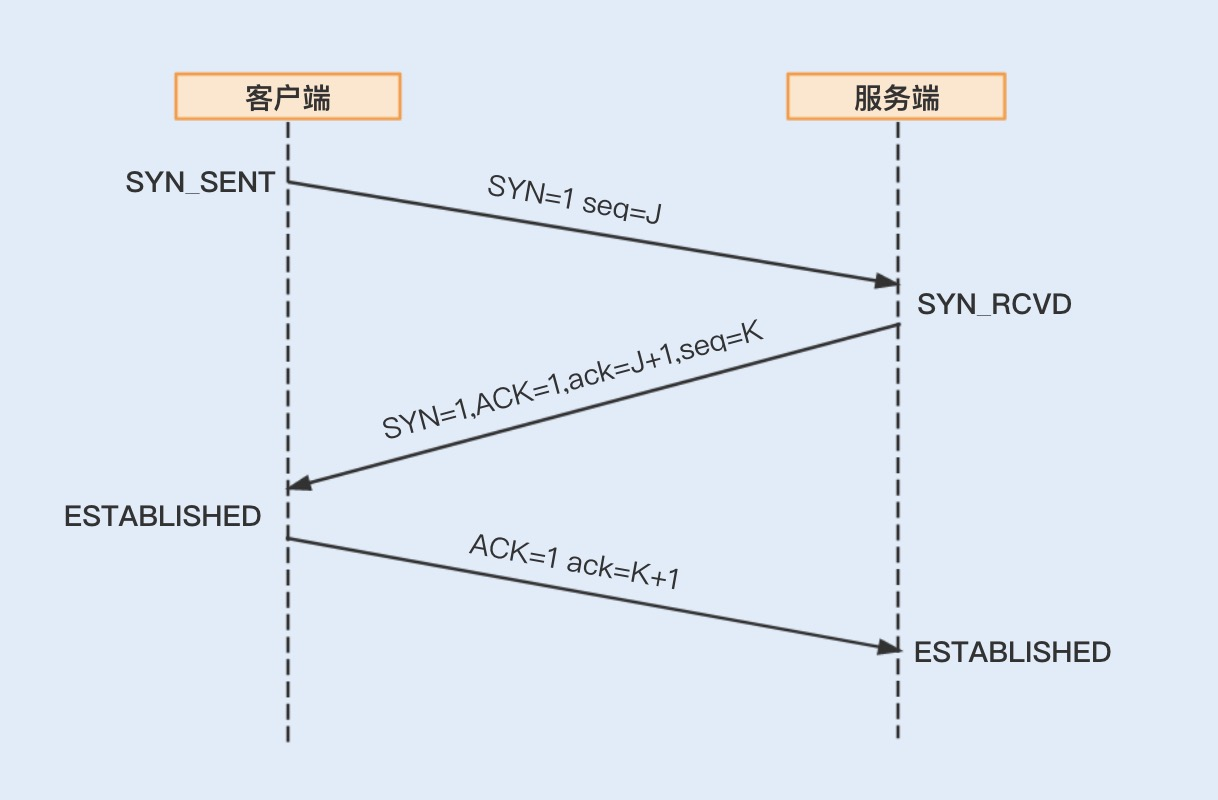
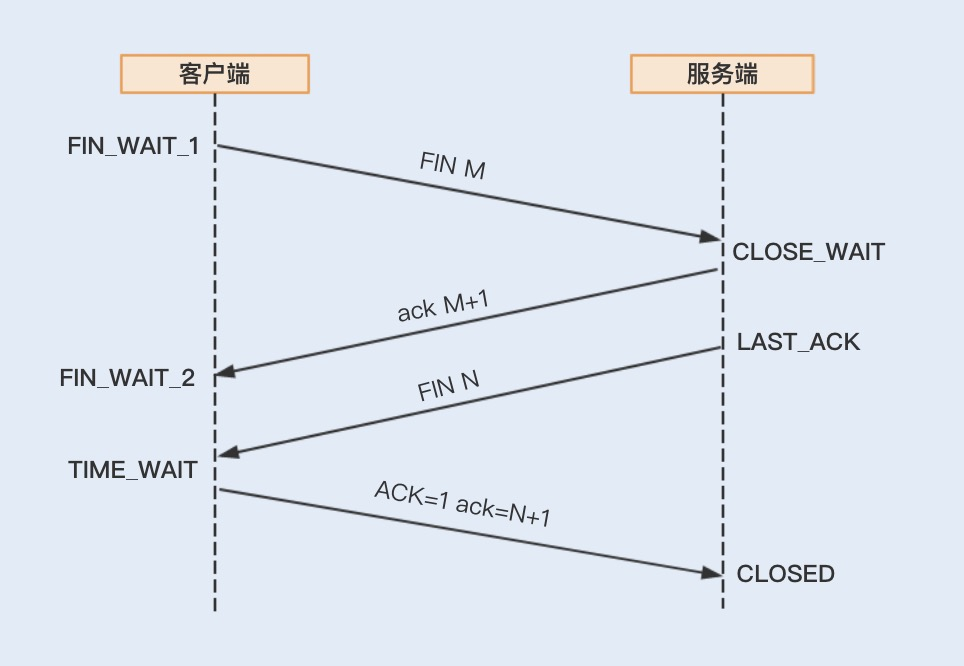
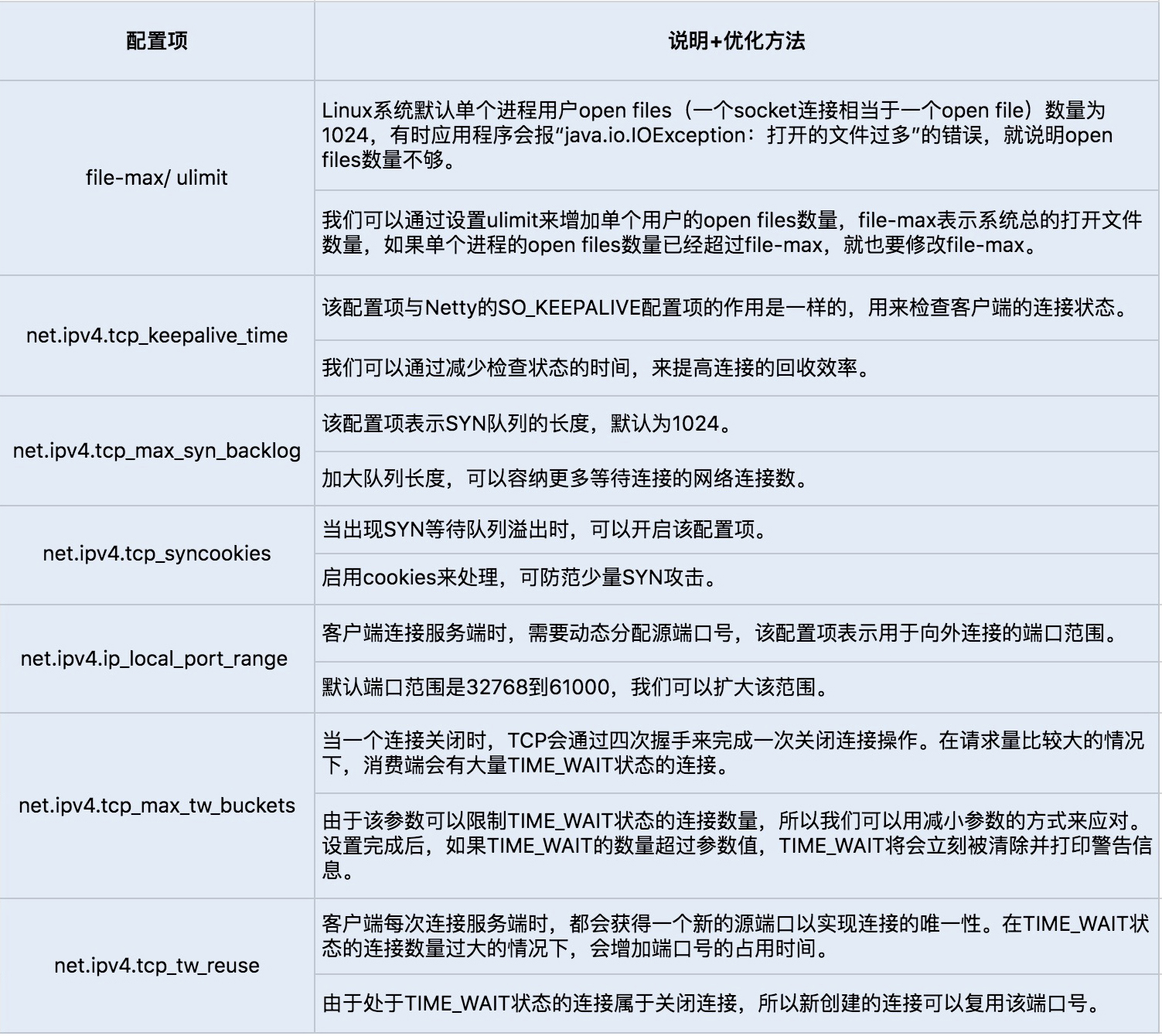
我们可以通过 sysctl -a | grep net.xxx 命令运行查看 Linux 系统默认的的 TCP 参数设置,如果需要修改某项配置,可以通过编辑 vim/etc/sysctl.conf,加入需要修改的配置项, 并通过 sysctl -p 命令运行生效修改后的配置项设置。通常我们会通过修改以下几个配置项来提高网络吞吐量和降低延时。
在一些并发场景比较多的系统中,我更偏向使用 Dubbo 实现的这一套 RPC 通信协议。Dubbo 协议是建立的单一长连接通信,网络 I/O 为 NIO 非阻塞读写操作,更兼容了 Kryo、FST、Protobuf 等性能出众的序列化框架,在高并发、小对象传输的业务场景中非常实用。
在企业级系统中,业务往往要比普通的互联网产品复杂,服务与服务之间可能不仅仅是数据传输,还有图片以及文件的传输,所以 RPC 的通信协议设计考虑更多是功能性需求,在性能方面不追求极致。其它通信框架在功能性、生态以及易用、易入门等方面更具有优势。
11. 深入了解NIO的优化实现原理
Tomcat 中经常被提到的一个调优就是修改线程的 I/O 模型。Tomcat 8.5 版本之前,默认情况下使用的是 BIO 线程模型,如果在高负载、高并发的场景下,可以通过设置 NIO 线程模型,来提高系统的网络通信性能。
Tomcat 在 I/O 读写操作比较多的情况下,使用 NIO 线程模型有明显的优势。
网络 I/O 模型优化
网络通信中,最底层的就是内核中的网络 I/O 模型了。随着技术的发展,操作系统内核的网络模型衍生出了五种 I/O 模型,《UNIX 网络编程》一书将这五种 I/O 模型分为阻塞式 I/O、非阻塞式 I/O、I/O 复用、信号驱动式 I/O 和异步 I/O。每一种 I/O 模型的出现,都是基于前一种 I/O 模型的优化升级。
最开始的阻塞式 I/O,它在每一个连接创建时,都需要一个用户线程来处理,并且在 I/O 操作没有就绪或结束时,线程会被挂起,进入阻塞等待状态,阻塞式 I/O 就成为了导致性能瓶颈的根本原因。
1. 阻塞式 I/O
在整个 socket 通信工作流程中,socket 的默认状态是阻塞的。也就是说,当发出一个不能立即完成的套接字调用时,其进程将被阻塞,被系统挂起,进入睡眠状态,一直等待相应的操作响应。从上图中,我们可以发现,可能存在的阻塞主要包括以下三种。
connect 阻塞:当客户端发起 TCP 连接请求,通过系统调用 connect 函数,TCP 连接的建立需要完成三次握手过程,客户端需要等待服务端发送回来的 ACK 以及 SYN 信号,同样服务端也需要阻塞等待客户端确认连接的 ACK 信号,这就意味着 TCP 的每个 connect 都会阻塞等待,直到确认连接。
accept 阻塞:一个阻塞的 socket 通信的服务端接收外来连接,会调用 accept 函数,如果没有新的连接到达,调用进程将被挂起,进入阻塞状态。
read、write 阻塞:当一个 socket 连接创建成功之后,服务端用 fork 函数创建一个子进程, 调用 read 函数等待客户端的数据写入,如果没有数据写入,调用子进程将被挂起,进入阻塞状态。
2. 非阻塞式 I/O
使用 fcntl 可以把以上三种操作都设置为非阻塞操作。如果没有数据返回,就会直接返回一个 EWOULDBLOCK 或 EAGAIN 错误,此时进程就不会一直被阻塞。
当我们把以上操作设置为了非阻塞状态,我们需要设置一个线程对该操作进行轮询检查,这也是最传统的非阻塞 I/O 模型。
3. I/O 复用
如果使用用户线程轮询查看一个 I/O 操作的状态,在大量请求的情况下,这对于 CPU 的使用率无疑是种灾难。 那么除了这种方式,还有其它方式可以实现非阻塞 I/O 套接字吗?
Linux 提供了 I/O 复用函数 select/poll/epoll,进程将一个或多个读操作通过系统调用函数,阻塞在函数操作上。这样,系统内核就可以帮我们侦测多个读操作是否处于就绪状态。
select() 函数:它的用途是,在超时时间内,监听用户感兴趣的文件描述符上的可读可写和异常事件的发生。Linux 操作系统的内核将所有外部设备都看做一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令,返回一个文件描述符(fd)。
调用后 select() 函数会阻塞,直到有描述符就绪或者超时,函数返回。当 select 函数返回后,可以通过函数 FD_ISSET 遍历 fdset,来找到就绪的描述符。
poll() 函数:在每次调用 select() 函数之前,系统需要把一个 fd 从用户态拷贝到内核态,这样就给系统带来了一定的性能开销。再有单个进程监视的 fd 数量默认是 1024,我们可以通过修改宏定义甚至重新编译内核的方式打破这一限制。但由于 fd_set 是基于数组实现的,在新增和删除 fd 时,数量过大会导致效率降低。
poll() 的机制与 select() 类似,二者在本质上差别不大。poll() 管理多个描述符也是通过轮询,根据描述符的状态进行处理,但 poll() 没有最大文件描述符数量的限制。
poll() 和 select() 存在一个相同的缺点,那就是包含大量文件描述符的数组被整体复制到用户态和内核的地址空间之间,而无论这些文件描述符是否就绪,他们的开销都会随着文件描述符数量的增加而线性增大。
epoll() 函数:select/poll 是顺序扫描 fd 是否就绪,而且支持的 fd 数量不宜过大,因此它的使用受到了一些制约。
Linux 在 2.6 内核版本中提供了一个 epoll 调用,epoll 使用事件驱动的方式代替轮询扫描 fd。epoll 事先通过 epoll_ctl() 来注册一个文件描述符,将文件描述符存放到内核的一个事件表中,这个事件表是基于红黑树实现的,所以在大量 I/O 请求的场景下,插入和删除的性能比 select/poll 的数组 fd_set 要好,因此 epoll 的性能更胜一筹,而且不会受到 fd 数量的限制。
4. 信号驱动式 I/O
信号驱动式 I/O 类似观察者模式,内核就是一个观察者,信号回调则是通知。用户进程发起一个 I/O 请求操作,会通过系统调用 sigaction 函数,给对应的套接字注册一个信号回调,此时不阻塞用户进程,进程会继续工作。当内核数据就绪时,内核就为该进程生成一个 SIGIO 信号,通过信号回调通知进程进行相关 I/O 操作。
信号驱动式 I/O 相比于前三种 I/O 模式,实现了在等待数据就绪时,进程不被阻塞,主循环可以继续工作,所以性能更佳。
信号驱动式 I/O 现在被用在了 UDP 通信上,UDP 只有一个数据请求事件,这也就意味着在正常情况下 UDP 进程只要捕获 SIGIO 信号,就调用 recvfrom 读取到达的数据报。如果出现异常,就返回一个异常错误。比如,NTP 服务器就应用了这种模型。
5. 异步 I/O
信号驱动式 I/O 虽然在等待数据就绪时,没有阻塞进程,但在被通知后进行的 I/O 操作还是阻塞的,进程会等待数据从内核空间复制到用户空间中。而异步 I/O 则是实现了真正的非阻塞 I/O。
当用户进程发起一个 I/O 请求操作,系统会告知内核启动某个操作,并让内核在整个操作完成后通知进程。这个操作包括等待数据就绪和数据从内核复制到用户空间。由于程序的代码复杂度高,调试难度大,且支持异步 I/O 的操作系统比较少见(目前 Linux 暂不支持,而 Windows 已经实现了异步 I/O),所以在实际生产环境中很少用到异步 I/O 模型。
在 NIO 服务端通信编程中,首先会创建一个 Channel,用于监听客户端连接;接着,创建多路复用器 Selector,并将 Channel 注册到 Selector,程序会通过 Selector 来轮询注册在其上的 Channel,当发现一个或多个 Channel 处于就绪状态时,返回就绪的监听事件,最后程序匹配到监听事件,进行相关的 I/O 操作。
由于信号驱动式 I/O 对 TCP 通信的不支持,以及异步 I/O 在 Linux 操作系统内核中的应用还不大成熟,大部分框架都还是基于 I/O 复用模型实现的网络通信。
零拷贝
在 I/O 复用模型中,执行读写 I/O 操作依然是阻塞的,在执行读写 I/O 操作时,存在着多次内存拷贝和上下文切换,给系统增加了性能开销。
零拷贝是一种避免多次内存复制的技术,用来优化读写 I/O 操作。
在网络编程中,通常由 read、write 来完成一次 I/O 读写操作。每一次 I/O 读写操作都需要完成四次内存拷贝,路径是 I/O 设备 -> 内核空间 -> 用户空间 -> 内核空间 -> 其它 I/O 设备。
Linux 内核中的 mmap 函数可以代替 read、write 的 I/O 读写操作,实现用户空间和内核空间共享一个缓存数据。mmap 将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址,不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理内存地址。这种方式避免了内核空间与用户空间的数据交换。I/O 复用中的 epoll 函数中就是使用了 mmap 减少了内存拷贝。
在 Java 的 NIO 编程中,则是使用到了 Direct Buffer 来实现内存的零拷贝。Java 直接在 JVM 内存空间之外开辟了一个物理内存空间,这样内核和用户进程都能共享一份缓存数据。
线程模型优化
除了内核对网络 I/O 模型的优化,NIO 在用户层也做了优化升级。NIO 是基于事件驱动模型来实现的 I/O 操作。Reactor 模型是同步 I/O 事件处理的一种常见模型,其核心思想是将 I/O 事件注册到多路复用器上,一旦有 I/O 事件触发,多路复用器就会将事件分发到事件处理器中,执行就绪的 I/O 事件操作。该模型有以下三个主要组件:
- 事件接收器 Acceptor:主要负责接收请求连接;
- 事件分离器 Reactor:接收请求后,会将建立的连接注册到分离器中,依赖于循环监听多路复用器 Selector,一旦监听到事件,就会将事件 dispatch 到事件处理器;
- 事件处理器 Handlers:事件处理器主要是完成相关的事件处理,比如读写 I/O 操作。
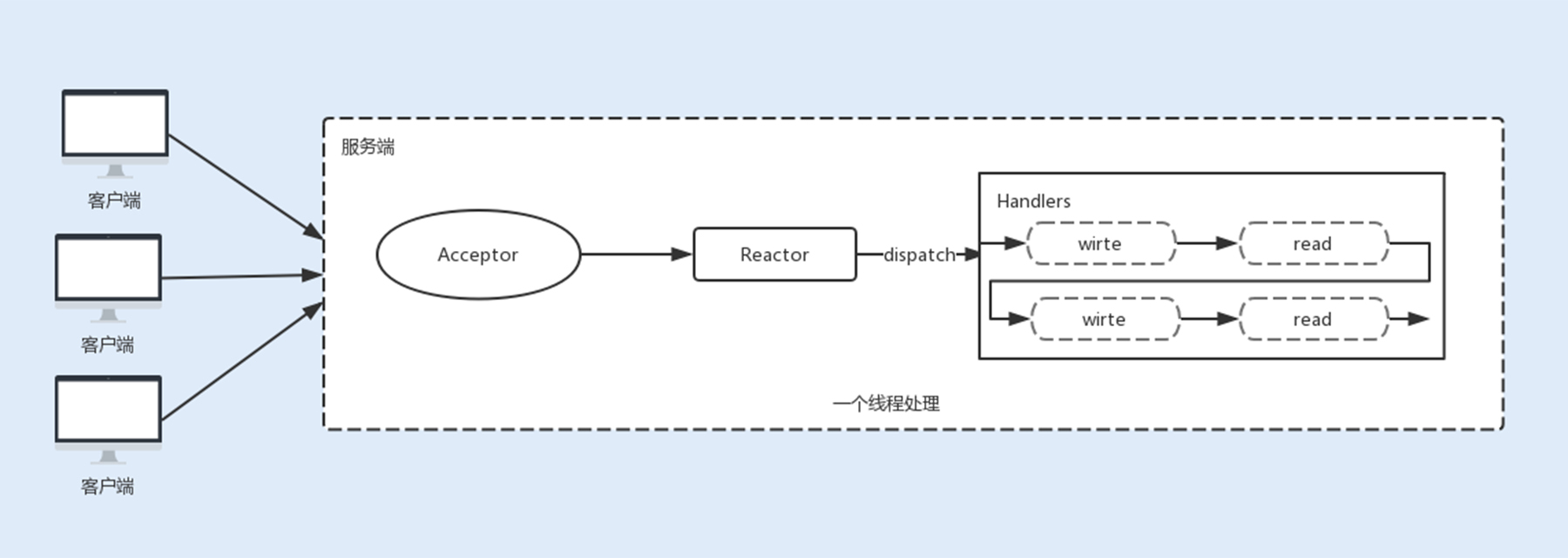
1. 单线程 Reactor 线程模型
最开始 NIO 是基于单线程实现的,所有的 I/O 操作都是在一个 NIO 线程上完成。由于 NIO 是非阻塞 I/O,理论上一个线程可以完成所有的 I/O 操作。
但 NIO 其实还不算真正地实现了非阻塞 I/O 操作,因为读写 I/O 操作时用户进程还是处于阻塞状态,这种方式在高负载、高并发的场景下会存在性能瓶颈,一个 NIO 线程如果同时处理上万连接的 I/O 操作,系统是无法支撑这种量级的请求的。
2. 多线程 Reactor 线程模型
为了解决这种单线程的 NIO 在高负载、高并发场景下的性能瓶颈,后来使用了线程池。
在 Tomcat 和 Netty 中都使用了一个 Acceptor 线程来监听连接请求事件,当连接成功之后,会将建立的连接注册到多路复用器中,一旦监听到事件,将交给 Worker 线程池来负责处理。大多数情况下,这种线程模型可以满足性能要求,但如果连接的客户端再上一个量级,一个 Acceptor 线程可能会存在性能瓶颈。
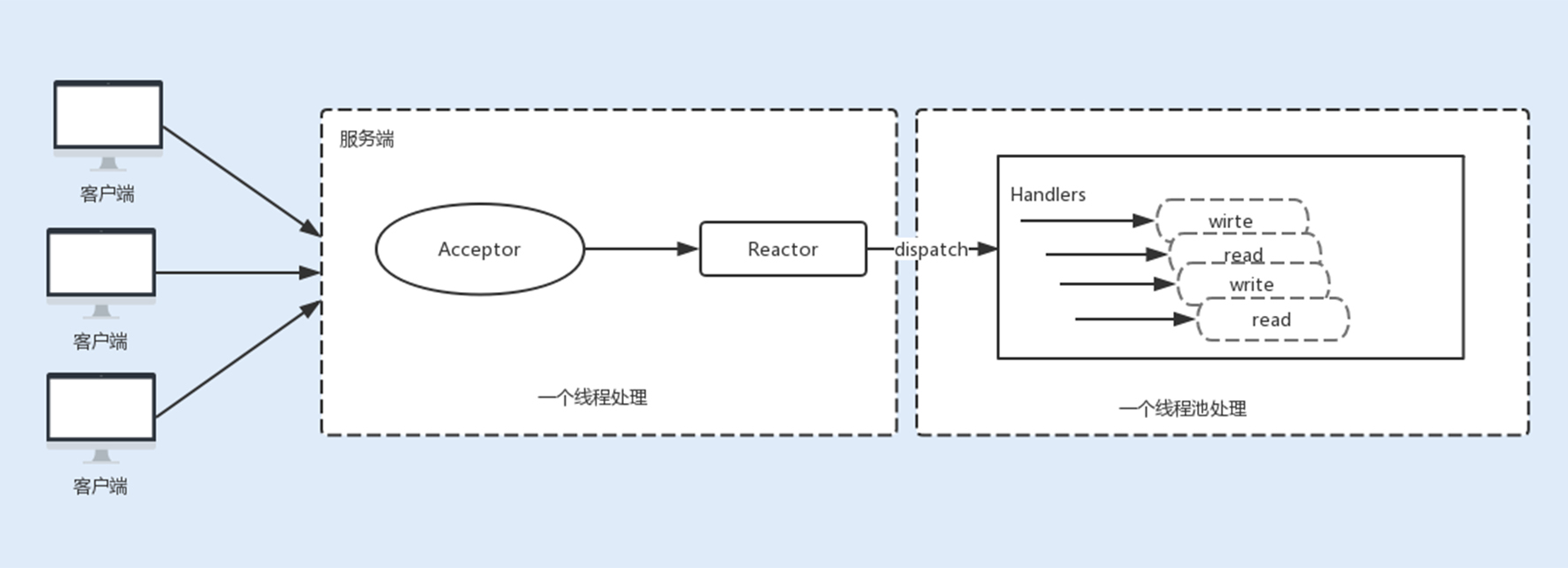
3. 主从 Reactor 线程模型
现在主流通信框架中的 NIO 通信框架都是基于主从 Reactor 线程模型来实现的。在这个模型中,Acceptor 不再是一个单独的 NIO 线程,而是一个线程池。Acceptor 接收到客户端的 TCP 连接请求,建立连接之后,后续的 I/O 操作将交给 Worker I/O 线程。
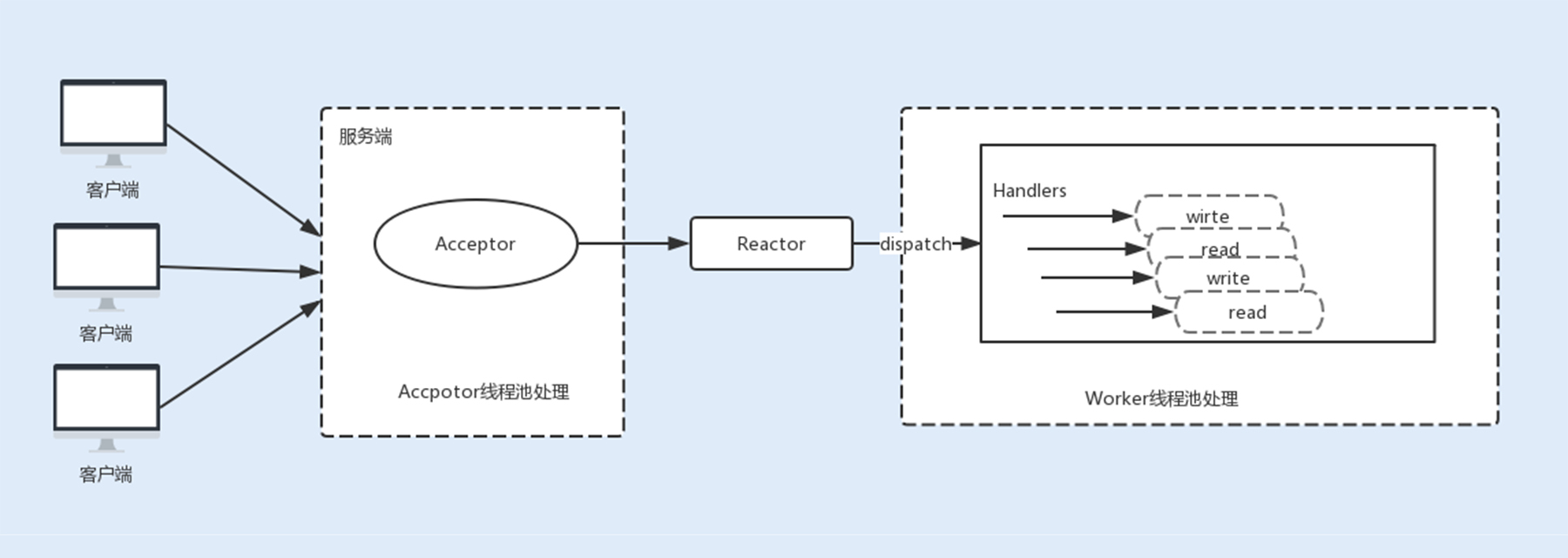
基于线程模型的 Tomcat 参数调优
Tomcat 中,BIO、NIO 是基于主从 Reactor 线程模型实现的。
在 BIO 中,Tomcat 中的 Acceptor 只负责监听新的连接,一旦连接建立监听到 I/O 操作,将会交给 Worker 线程中,Worker 线程专门负责 I/O 读写操作。
在 NIO 中,Tomcat 新增了一个 Poller 线程池,Acceptor 监听到连接后,不是直接使用 Worker 中的线程处理请求,而是先将请求发送给了 Poller 缓冲队列。在 Poller 中,维护了一个 Selector 对象,当 Poller 从队列中取出连接后,注册到该 Selector 中;然后通过遍历 Selector,找出其中就绪的 I/O 操作,并使用 Worker 中的线程处理相应的请求。
你可以通过以下几个参数来设置 Acceptor 线程池和 Worker 线程池的配置项。
-
acceptorThreadCount:该参数代表 Acceptor 的线程数量,在请求客户端的数据量非常巨大的情况下,可以适当地调大该线程数量来提高处理请求连接的能力,默认值为 1。
-
maxThreads:专门处理 I/O 操作的 Worker 线程数量,默认是 200,可以根据实际的环境来调整该参数,但不一定越大越好。
-
acceptCount:Tomcat 的 Acceptor 线程是负责从 accept 队列中取出该 connection,然后交给工作线程去执行相关操作,这里的 acceptCount 指的是 accept 队列的大小。
-
当 Http 关闭 keep alive,在并发量比较大时,可以适当地调大这个值。而在 Http 开启 keep alive 时,因为 Worker 线程数量有限,Worker 线程就可能因长时间被占用,而连接在 accept 队列中等待超时。如果 accept 队列过大,就容易浪费连接。
-
maxConnections:表示有多少个 socket 连接到 Tomcat 上。在 BIO 模式中,一个线程只能处理一个连接,一般 maxConnections 与 maxThreads 的值大小相同;在 NIO 模式中,一个线程同时处理多个连接,maxConnections 应该设置得比 maxThreads 要大的多,默认是 10000。
12.多线程之锁优化(上):深入了解Synchronized同步锁的优化方法
Synchronized 同步锁实现原理
Synchronized 在修饰同步代码块时,是由 monitorenter 和 monitorexit 指令来实现同步的。进入 monitorenter 指令后,线程将持有 Monitor 对象,退出 monitorenter 指令后,线程将释放该 Monitor 对象。
当 Synchronized 修饰同步方法时,并没有发现 monitorenter 和 monitorexit 指令,而是出现了一个 ACC_SYNCHRONIZED 标志。
这是因为 JVM 使用了 ACC_SYNCHRONIZED 访问标志来区分一个方法是否是同步方法。当方法调用时,调用指令将会检查该方法是否被设置 ACC_SYNCHRONIZED 访问标志。如果设置了该标志,执行线程将先持有 Monitor 对象,然后再执行方法。在该方法运行期间,其它线程将无法获取到该 Mointor 对象,当方法执行完成后,再释放该 Monitor 对象。
JVM 中的同步是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个 Monitor,Monitor 可以和对象一起创建、销毁。Monitor 是由 ObjectMonitor 实现,而 ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现。
当多个线程同时访问一段同步代码时,多个线程会先被存放在 EntryList 集合中,处于 block 状态的线程,都会被加入到该列表。接下来当线程获取到对象的 Monitor 时,Monitor 是依靠底层操作系统的 Mutex Lock 来实现互斥的,线程申请 Mutex 成功,则持有该 Mutex,其它线程将无法获取到该 Mutex。
如果线程调用 wait() 方法,就会释放当前持有的 Mutex,并且该线程会进入 WaitSet 集合中,等待下一次被唤醒。如果当前线程顺利执行完方法,也将释放 Mutex。
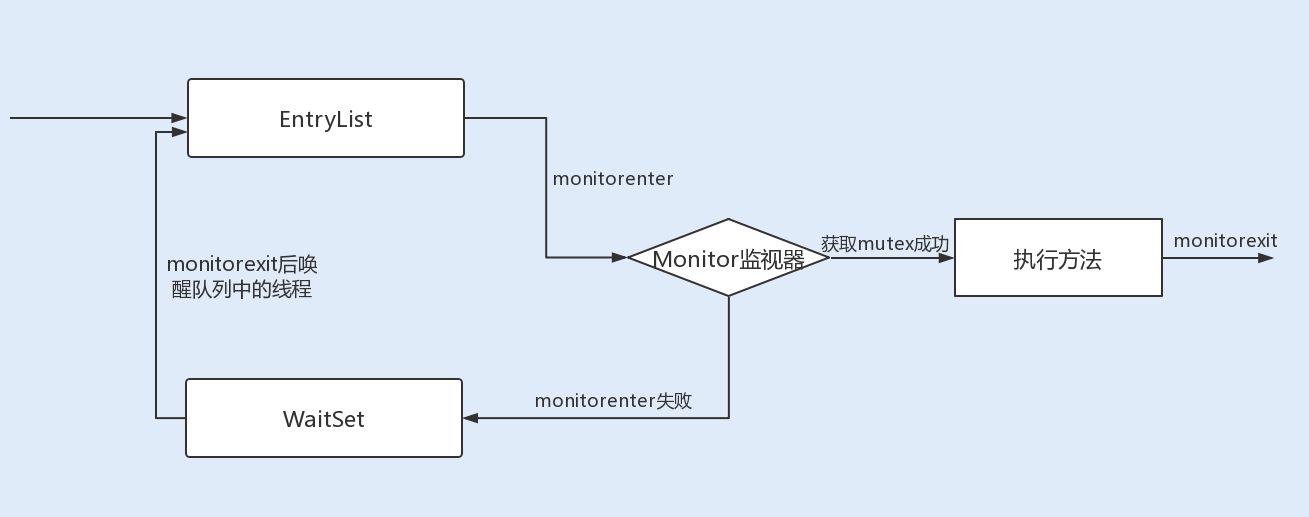
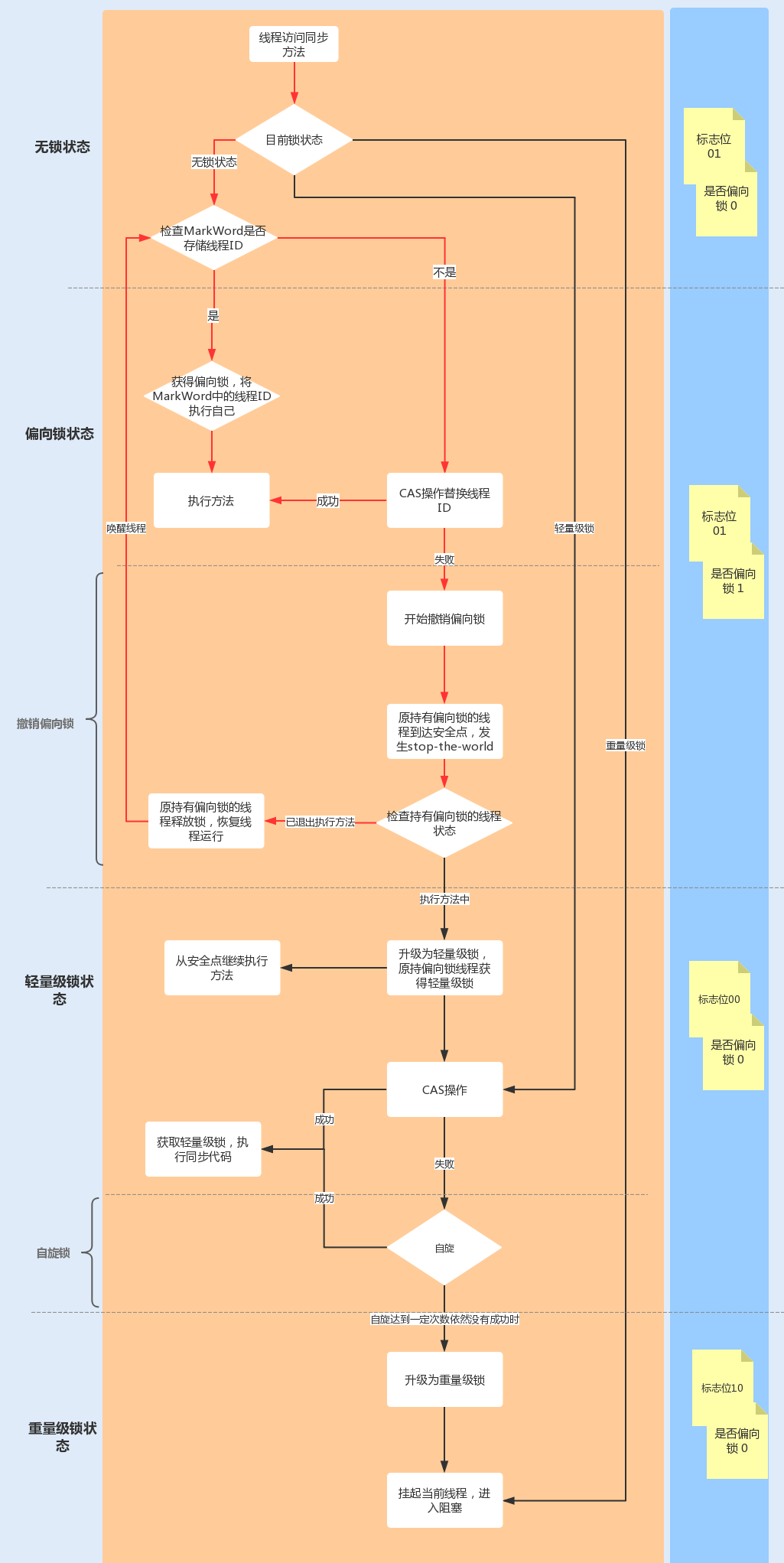
锁升级优化
为了提升性能,JDK1.6 引入了偏向锁、轻量级锁、重量级锁概念,来减少锁竞争带来的上下文切换,而正是新增的 Java 对象头实现了锁升级功能。
当 Java 对象被 Synchronized 关键字修饰成为同步锁后,围绕这个锁的一系列升级操作都将和 Java 对象头有关。
Java 对象头
在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。如下图所示:
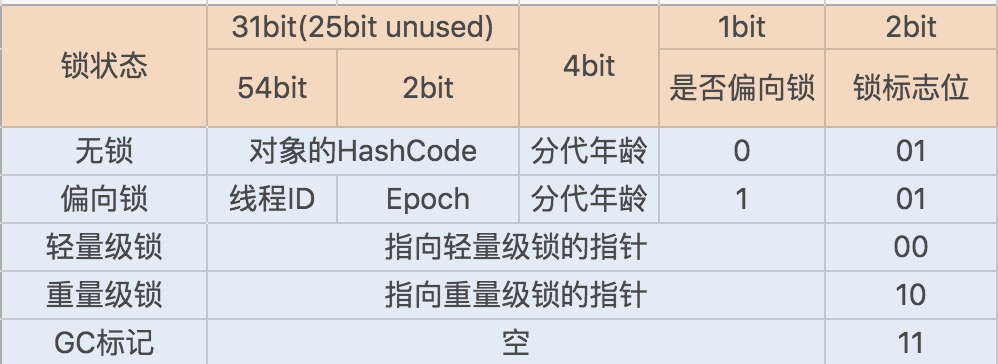
锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位,Synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。下面我们就沿着这条优化路径去看下具体的内容。
1. 偏向锁
偏向锁主要用来优化同一线程多次申请同一个锁的竞争。在某些情况下,大部分时间是同一个线程竞争锁资源,例如,在创建一个线程并在线程中执行循环监听的场景下,或单线程操作一个线程安全集合时,同一线程每次都需要获取和释放锁,每次操作都会发生用户态与内核态的切换。
偏向锁的作用就是,当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的 Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor 去竞争对象了。当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。
一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
因此,在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生 stop the word 后, 开启偏向锁无疑会带来更大的性能开销,这时我们可以通过添加 JVM 参数关闭偏向锁来调优系统性能,示例代码如下:
-XX:-UseBiasedLocking // 关闭偏向锁(默认打开)
-XX:+UseHeavyMonitors // 设置重量级锁
2. 轻量级锁
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁,如果获取成功,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。
轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
3. 自旋锁与重量级锁
轻量级锁 CAS 抢锁失败,线程将会被挂起进入阻塞状态。如果正在持有锁的线程在很短的时间内释放资源,那么进入阻塞状态的线程无疑又要申请锁资源。
JVM 提供了一种自旋锁,可以通过自旋方式不断尝试获取锁,从而避免线程被挂起阻塞。这是基于大多数情况下,线程持有锁的时间都不会太长,毕竟线程被挂起阻塞可能会得不偿失。
从 JDK1.7 开始,自旋锁默认启用,自旋次数由 JVM 设置决定,这里我不建议设置的重试次数过多,因为 CAS 重试操作意味着长时间地占用 CPU。
自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为 10。在这个状态下,未抢到锁的线程都会进入 Monitor,之后会被阻塞在 _WaitSet 队列中。
在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于 CAS 重试状态,占用 CPU 资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。
在高负载、高并发的场景下,我们可以通过设置 JVM 参数来关闭自旋锁,优化系统性能,示例代码如下:
-XX:-UseSpinning // 参数关闭自旋锁优化 (默认打开)
-XX:PreBlockSpin // 参数修改默认的自旋次数。JDK1.7 后,去掉此参数,由 jvm 控制
动态编译实现锁消除 / 锁粗化
除了锁升级优化,Java 还使用了编译器对锁进行优化。JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反复申请、释放同一个锁“所带来的性能开销。
减小锁粒度
了锁内部优化和编译器优化之外,我们还可以通过代码层来实现锁优化,减小锁粒度就是一种惯用的方法。
当我们的锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
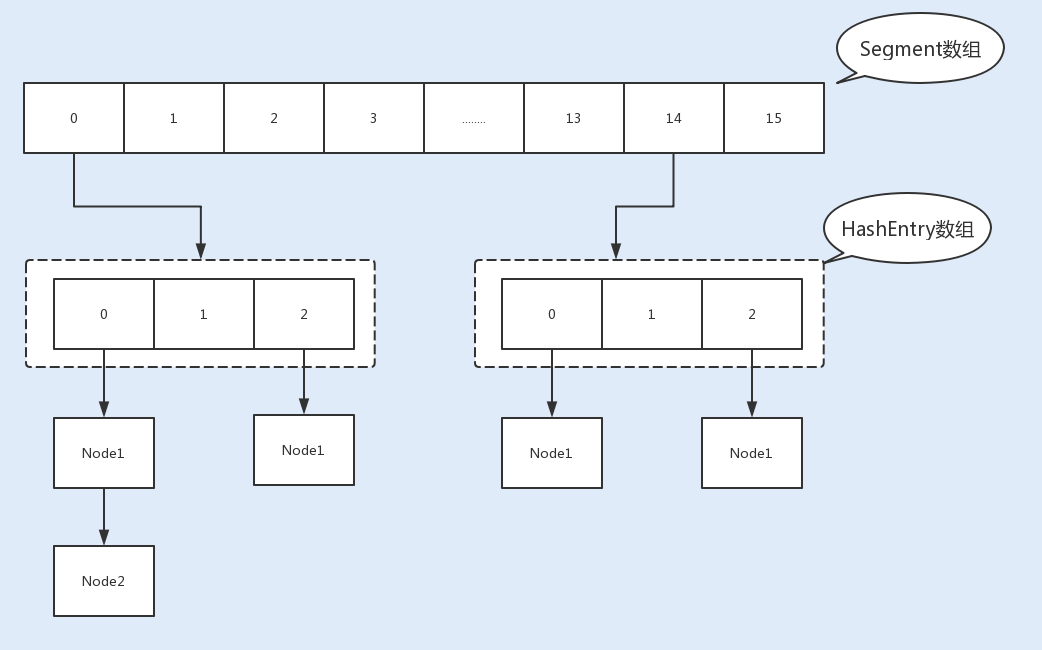
最经典的减小锁粒度的案例就是 JDK1.8 之前实现的 ConcurrentHashMap 版本。我们知道,HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争,如下图所示:
13.多线程之锁优化(中):深入了解同步锁Lock的优化方法
相对于需要 JVM 隐式获取和释放锁的 Synchronized 同步锁,Lock 同步锁(以下简称 Lock 锁)需要的是显示获取和释放锁,这就为获取和释放锁提供了更多的灵活性。Lock 锁的基本操作是通过乐观锁来实现的,但由于 Lock 锁也会在阻塞时被挂起,因此它依然属于悲观锁。
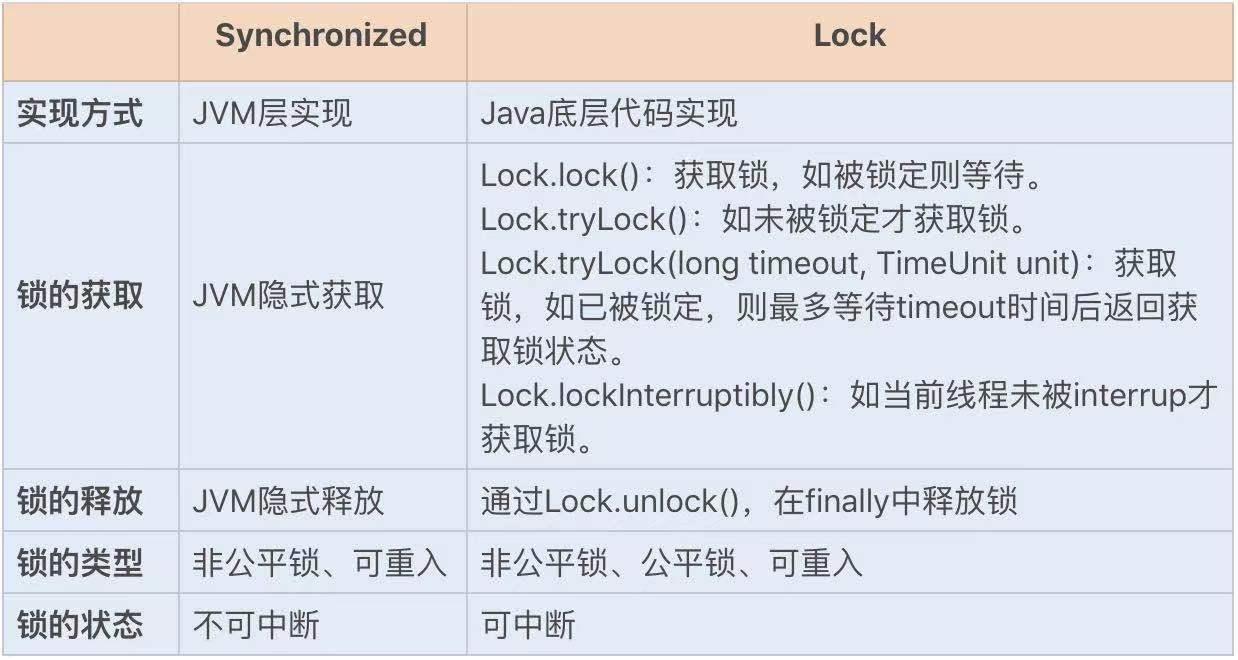
从性能方面上来说,在并发量不高、竞争不激烈的情况下,Synchronized 同步锁由于具有分级锁的优势,性能上与 Lock 锁差不多;但在高负载、高并发的情况下,Synchronized 同步锁由于竞争激烈会升级到重量级锁,性能则没有 Lock 锁稳定。
Lock 锁的实现原理
Lock 锁是基于 Java 实现的锁,Lock 是一个接口类,常用的实现类有 ReentrantLock、ReentrantReadWriteLock(RRW),它们都是依赖 AbstractQueuedSynchronizer(AQS)类实现的。
AQS 类结构中包含一个基于链表实现的等待队列(CLH 队列),用于存储所有阻塞的线程,AQS 中还有一个 state 变量,该变量对 ReentrantLock 来说表示加锁状态。
锁分离优化 Lock 同步锁
虽然 Lock 锁的性能稳定,但也并不是所有的场景下都默认使用 ReentrantLock 独占锁来实现线程同步。
1. 读写锁 ReentrantReadWriteLock
针对这种读多写少的场景,Java 提供了另外一个实现 Lock 接口的读写锁 RRW。我们已知 ReentrantLock 是一个独占锁,同一时间只允许一个线程访问,而 RRW 允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。读写锁内部维护了两个锁,一个是用于读操作的 ReadLock,一个是用于写操作的 WriteLock。
RRW 也是基于 AQS 实现的,它的自定义同步器(继承 AQS)需要在同步状态 state 上维护多个读线程和一个写线程的状态,该状态的设计成为实现读写锁的关键。RRW 很好地使用了高低位,来实现一个整型控制两种状态的功能,读写锁将变量切分成了两个部分,高 16 位表示读,低 16 位表示写。
一个线程尝试获取写锁时,会先判断同步状态 state 是否为 0。如果 state 等于 0,说明暂时没有其它线程获取锁;如果 state 不等于 0,则说明有其它线程获取了锁。
此时再判断同步状态 state 的低 16 位(w)是否为 0,如果 w 为 0,则说明其它线程获取了读锁,此时进入 CLH 队列进行阻塞等待;如果 w 不为 0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入 CLH 队列进行阻塞等待;若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态。
一个线程尝试获取读锁时,同样会先判断同步状态 state 是否为 0。如果 state 等于 0,说明暂时没有其它线程获取锁,此时判断是否需要阻塞,如果需要阻塞,则进入 CLH 队列进行阻塞等待;如果不需要阻塞,则 CAS 更新同步状态为读状态。
如果 state 不等于 0,会判断同步状态低 16 位,如果存在写锁,则获取读锁失败,进入 CLH 阻塞队列;反之,判断当前线程是否应该被阻塞,如果不应该阻塞则尝试 CAS 同步状态,获取成功更新同步锁为读状态。
2. 读写锁再优化之 StampedLock
RRW 被很好地应用在了读大于写的并发场景中,然而 RRW 在性能上还有可提升的空间。在读取很多、写入很少的情况下,RRW 会使写入线程遭遇饥饿(Starvation)问题,也就是说写入线程会因迟迟无法竞争到锁而一直处于等待状态。
在 JDK1.8 中,Java 提供了 StampedLock 类解决了这个问题。StampedLock 不是基于 AQS 实现的,但实现的原理和 AQS 是一样的,都是基于队列和锁状态实现的。与 RRW 不一样的是,StampedLock 控制锁有三种模式: 写、悲观读以及乐观读,并且 StampedLock 在获取锁时会返回一个票据 stamp,获取的 stamp 除了在释放锁时需要校验,在乐观读模式下,stamp 还会作为读取共享资源后的二次校验。
相比于 RRW,StampedLock 获取读锁只是使用与或操作进行检验,不涉及 CAS 操作,即使第一次乐观锁获取失败,也会马上升级至悲观锁,这样就可以避免一直进行 CAS 操作带来的 CPU 占用性能的问题,因此 StampedLock 的效率更高。
StampedLock 同 RRW 一样,都适用于读大于写操作的场景,但是在写多读少的情况,由于StampedLock不可重入,会导致死锁或饥饿问题。
14.多线程之锁优化:使用乐观锁优化并行操作
乐观锁,顾名思义,就是说在操作共享资源时,它总是抱着乐观的态度进行,它认为自己可以成功地完成操作。但实际上,当多个线程同时操作一个共享资源时,只有一个线程会成功,那么失败的线程呢?它们不会像悲观锁一样在操作系统中挂起,而仅仅是返回,并且系统允许失败的线程重试,也允许自动放弃退出操作。
所以,乐观锁相比悲观锁来说,不会带来死锁、饥饿等活性故障问题,线程间的相互影响也远远比悲观锁要小。更为重要的是,乐观锁没有因竞争造成的系统开销,所以在性能上也是更胜一筹。
乐观锁的实现原理
CAS 是实现乐观锁的核心算法,它包含了 3 个参数:V(需要更新的变量)、E(预期值)和 N(最新值)。
只有当需要更新的变量等于预期值时,需要更新的变量才会被设置为最新值,如果更新值和预期值不同,则说明已经有其它线程更新了需要更新的变量,此时当前线程不做操作,返回 V 的真实值。
CAS 是调用处理器底层指令来实现原子操作的。
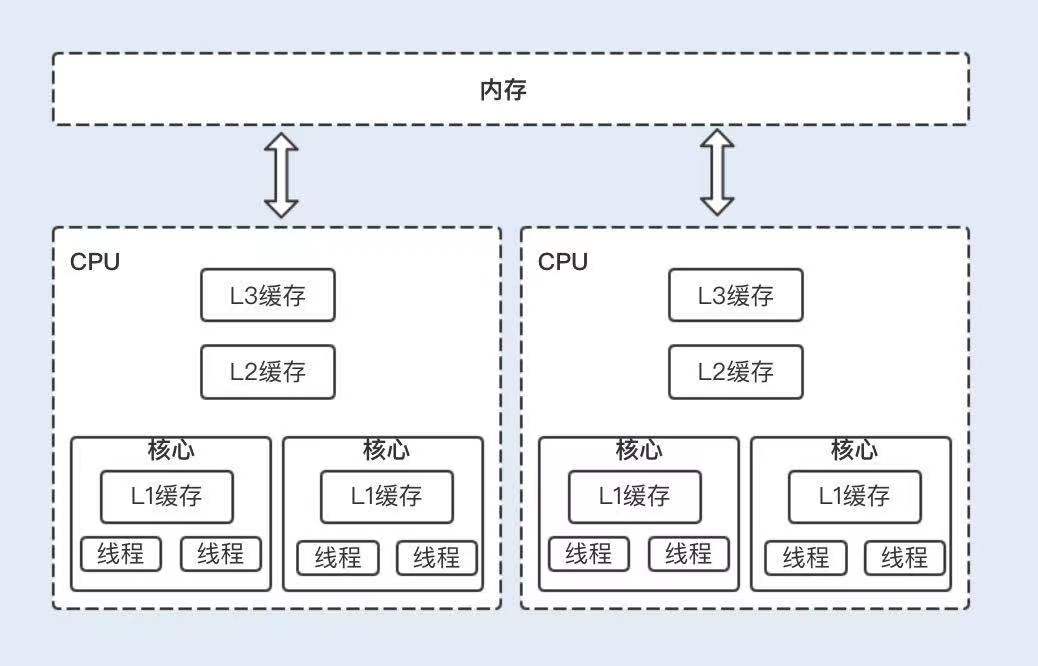
一般情况下,一个单核处理器能自我保证基本的内存操作是原子性的,当一个线程读取一个字节时,所有进程和线程看到的字节都是同一个缓存里的字节,其它线程不能访问这个字节的内存地址。
但现在的服务器通常是多处理器,并且每个处理器都是多核的。每个处理器维护了一块字节的内存,每个内核维护了一块字节的缓存,这时候多线程并发就会存在缓存不一致的问题,从而导致数据不一致。
这个时候,处理器提供了总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
当处理器要操作一个共享变量的时候,其在总线上会发出一个 Lock 信号,这时其它处理器就不能操作共享变量了,该处理器会独享此共享内存中的变量。但总线锁定在阻塞其它处理器获取该共享变量的操作请求时,也可能会导致大量阻塞,从而增加系统的性能开销。
于是,后来的处理器都提供了缓存锁定机制,也就说当某个处理器对缓存中的共享变量进行了操作,就会通知其它处理器放弃存储该共享资源或者重新读取该共享资源。目前最新的处理器都支持缓存锁定机制。
优化 CAS 乐观锁
虽然乐观锁在并发性能上要比悲观锁优越,但是在写大于读的操作场景下,CAS 失败的可能性会增大,如果不放弃此次 CAS 操作,就需要循环做 CAS 重试,这无疑会长时间地占用 CPU。
在 JDK1.8 中,Java 提供了一个新的原子类 LongAdder。LongAdder 在高并发场景下会比 AtomicInteger 和 AtomicLong 的性能更好,代价就是会消耗更多的内存空间。
LongAdder 的原理就是降低操作共享变量的并发数,也就是将对单一共享变量的操作压力分散到多个变量值上,将竞争的每个写线程的 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的 value 值进行 CAS 操作,最后在读取值的时候会将原子操作的共享变量与各个分散在数组的 value 值相加,返回一个近似准确的数值。
LongAdder 内部由一个 base 变量和一个 cell[] 数组组成。当只有一个写线程,没有竞争的情况下,LongAdder 会直接使用 base 变量作为原子操作变量,通过 CAS 操作修改变量;当有多个写线程竞争的情况下,除了占用 base 变量的一个写线程之外,其它各个线程会将修改的变量写入到自己的槽 cell[] 数组中。
我们可以发现,LongAdder 在操作后的返回值只是一个近似准确的数值,但是 LongAdder 最终返回的是一个准确的数值, 所以在一些对实时性要求比较高的场景下,LongAdder 并不能取代 AtomicInteger 或 AtomicLong。
总结
在读大于写的场景下,读写锁 ReentrantReadWriteLock、StampedLock 以及乐观锁的读写性能是最好的;在写大于读的场景下,乐观锁的性能是最好的,其它 4 种锁的性能则相差不多;在读和写差不多的场景下,两种读写锁以及乐观锁的性能要优于 Synchronized 和 ReentrantLock。
15.多线程调优(上):哪些操作导致了上下文切换?
其实在单个处理器的时期,操作系统就能处理多线程并发任务。处理器给每个线程分配 CPU 时间片(Time Slice),线程在分配获得的时间片内执行任务。
CPU 时间片是 CPU 分配给每个线程执行的时间段,一般为几十毫秒。在这么短的时间内线程互相切换,我们根本感觉不到,所以看上去就好像是同时进行的一样。
时间片决定了一个线程可以连续占用处理器运行的时长。当一个线程的时间片用完了,或者因自身原因被迫暂停运行了,这个时候,另外一个线程(可以是同一个线程或者其它进程的线程)就会被操作系统选中,来占用处理器。这种一个线程被暂停剥夺使用权,另外一个线程被选中开始或者继续运行的过程就叫做上下文切换(Context Switch)。
具体来说,一个线程被剥夺处理器的使用权而被暂停运行,就是“切出”;一个线程被选中占用处理器开始或者继续运行,就是“切入”。在这种切出切入的过程中,操作系统需要保存和恢复相应的进度信息,这个进度信息就是“上下文”了。
那上下文都包括哪些内容呢?具体来说,它包括了寄存器的存储内容以及程序计数器存储的指令内容。CPU 寄存器负责存储已经、正在和将要执行的任务,程序计数器负责存储 CPU 正在执行的指令位置以及即将执行的下一条指令的位置。
在当前 CPU 数量远远不止一个的情况下,操作系统将 CPU 轮流分配给线程任务,此时的上下文切换就变得更加频繁了,并且存在跨 CPU 上下文切换,比起单核上下文切换,跨核切换更加昂贵。
多线程上下文切换诱因
自发性上下文切换指线程由 Java 程序调用导致切出,在多线程编程中,执行调用以下方法或关键字,常常就会引发自发性上下文切换。
- sleep()
- wait()
- yield()
- join()
- park()
- synchronized
- lock
非自发性上下文切换指线程由于调度器的原因被迫切出。常见的有:线程被分配的时间片用完,虚拟机垃圾回收导致或者执行优先级的问题导致。
这里重点说下“虚拟机垃圾回收为什么会导致上下文切换”。在 Java 虚拟机中,对象的内存都是由虚拟机中的堆分配的,在程序运行过程中,新的对象将不断被创建,如果旧的对象使用后不进行回收,堆内存将很快被耗尽。Java 虚拟机提供了一种回收机制,对创建后不再使用的对象进行回收,从而保证堆内存的可持续性分配。而这种垃圾回收机制的使用有可能会导致 stop-the-world 事件的发生,这其实就是一种线程暂停行为。
发现上下文切换
串联的执行速度比并发的执行速度要快。这就是因为线程的上下文切换导致了额外的开销,使用 Synchronized 锁关键字,导致了资源竞争,从而引起了上下文切换,但即使不使用 Synchronized 锁关键字,并发的执行速度也无法超越串联的执行速度,这是因为多线程同样存在着上下文切换。Redis、NodeJS 的设计就很好地体现了单线程串行的优势。
系统开销具体发生在切换过程中的哪些具体环节,总结如下:
- 操作系统保存和恢复上下文;
- 调度器进行线程调度;
- 处理器高速缓存重新加载;
- 上下文切换也可能导致整个高速缓存区被冲刷,从而带来时间开销。
总结
上下文切换就是一个工作的线程被另外一个线程暂停,另外一个线程占用了处理器开始执行任务的过程。系统和 Java 程序自发性以及非自发性的调用操作,就会导致上下文切换,从而带来系统开销。
线程越多,系统的运行速度不一定越快。那么我们平时在并发量比较大的情况下,什么时候用单线程,什么时候用多线程呢?
一般在单个逻辑比较简单,而且速度相对来非常快的情况下,我们可以使用单线程。例如,我们前面讲到的 Redis,从内存中快速读取值,不用考虑 I/O 瓶颈带来的阻塞问题。而在逻辑相对来说很复杂的场景,等待时间相对较长又或者是需要大量计算的场景,我建议使用多线程来提高系统的整体性能。例如,NIO 时期的文件读写操作、图像处理以及大数据分析等。
16. 多线程调优(下):如何优化多线程上下文切换?
竞争锁优化:1. 减少锁的持有时间 2. 降低锁的粒度 3. 非阻塞乐观锁替代竞争锁
wait/notify 的使用导致了较多的上下文切换
当生产者获取到锁并执行 notifyAll() 之后,会唤醒处于阻塞状态的消费者线程,此时这里又发生了一次上下文切换。
被唤醒的等待线程在继续运行时,需要再次申请相应对象的内部锁,此时等待线程可能需要和其它新来的活跃线程争用内部锁,这也可能会导致上下文切换。
如果有多个消费者线程同时被阻塞,用 notifyAll() 方法,将会唤醒所有阻塞的线程。而某些商品依然没有库存,过早地唤醒这些没有库存的商品的消费线程,可能会导致线程再次进入阻塞状态,从而引起不必要的上下文切换。
建议使用 Lock 锁结合 Condition 接口替代 Synchronized 内部锁中的 wait / notify,实现等待/通知。这样做不仅可以解决上述的 Object.wait(long) 无法区分的问题,还可以解决线程被过早唤醒的问题。
Condition 接口定义的 await 方法 、signal 方法和 signalAll 方法分别相当于 Object.wait()、 Object.notify() 和 Object.notifyAll()。
合理地设置线程池大小,避免创建过多线程
线程池的线程数量设置不宜过大,因为一旦线程池的工作线程总数超过系统所拥有的处理器数量,就会导致过多的上下文切换。更多关于如何合理设置线程池数量的内容,我将在第 18 讲中详解。
还有一种情况就是,在有些创建线程池的方法里,线程数量设置不会直接暴露给我们。比如,用 Executors.newCachedThreadPool() 创建的线程池,该线程池会复用其内部空闲的线程来处理新提交的任务,如果没有,再创建新的线程(不受 MAX_VALUE 限制),这样的线程池如果碰到大量且耗时长的任务场景,就会创建非常多的工作线程,从而导致频繁的上下文切换。因此,这类线程池就只适合处理大量且耗时短的非阻塞任务。
使用协程实现非阻塞等待
协程是一种比线程更加轻量级的东西,相比于由操作系统内核来管理的进程和线程,协程则完全由程序本身所控制,也就是在用户态执行。协程避免了像线程切换那样产生的上下文切换,在性能方面得到了很大的提升。
减少 Java 虚拟机的垃圾回收
很多 JVM 垃圾回收器(serial 收集器、ParNew 收集器)在回收旧对象时,会产生内存碎片,从而需要进行内存整理,在这个过程中就需要移动存活的对象。而移动内存对象就意味着这些对象所在的内存地址会发生变化,因此在移动对象前需要暂停线程,在移动完成后需要再次唤醒该线程。因此减少 JVM 垃圾回收的频率可以有效地减少上下文切换。
17. 并发容器的使用:识别不同场景下最优容器
并发场景下的 Map 容器
为了保证容器的线程安全,Java 实现了 Hashtable、ConcurrentHashMap 以及 ConcurrentSkipListMap 等 Map 容器。
Hashtable、ConcurrentHashMap 是基于 HashMap 实现的,对于小数据量的存取比较有优势。
ConcurrentSkipListMap 是基于 TreeMap 的设计原理实现的,略有不同的是前者基于跳表实现,后者基于红黑树实现,ConcurrentSkipListMap 的特点是存取平均时间复杂度是 O(log(n)),适用于大数据量存取的场景,最常见的是基于跳跃表实现的数据量比较大的缓存。
在数据不断地写入和删除,且不存在数据量累积以及数据排序的场景下,我们可以选用 Hashtable 或 ConcurrentHashMap。
Hashtable 使用 Synchronized 同步锁修饰了 put、get、remove 等方法,因此在高并发场景下,读写操作都会存在大量锁竞争,给系统带来性能开销。
相比 Hashtable,ConcurrentHashMap 在保证线程安全的基础上兼具了更好的并发性能。在 JDK1.7 中,ConcurrentHashMap 就使用了分段锁 Segment 减小了锁粒度,最终优化了锁的并发操作。
到了 JDK1.8,ConcurrentHashMap 做了大量的改动,摒弃了 Segment 的概念。由于 Synchronized 锁在 Java6 之后的性能已经得到了很大的提升,所以在 JDK1.8 中,Java 重新启用了 Synchronized 同步锁,通过 Synchronized 实现 HashEntry 作为锁粒度。这种改动将数据结构变得更加简单了,操作也更加清晰流畅。
与 JDK1.7 的 put 方法一样,JDK1.8 在添加元素时,在没有哈希冲突的情况下,会使用 CAS 进行添加元素操作;如果有冲突,则通过 Synchronized 将链表锁定,再执行接下来的操作。
但要注意一点,虽然 ConcurrentHashMap 的整体性能要优于 Hashtable,但在某些场景中,ConcurrentHashMap 依然不能代替 Hashtable。例如,在强一致的场景中 ConcurrentHashMap 就不适用,原因是 ConcurrentHashMap 中的 get、size 等方法没有用到锁,ConcurrentHashMap 是弱一致性的,因此有可能会导致某次读无法马上获取到写入的数据。
ConcurrentHashMap VS ConcurrentSkipListMap
ConcurrentHashMap 该容器在数据量比较大的时候,链表会转换为红黑树。红黑树在并发情况下,删除和插入过程中有个平衡的过程,会牵涉到大量节点,因此竞争锁资源的代价相对比较高。
而跳跃表的操作针对局部,需要锁住的节点少,因此在并发场景下的性能会更好一些。你可能会问了,在非线程安全的 Map 容器中,我并没有看到基于跳跃表实现的 SkipListMap 呀?这是因为在非线程安全的 Map 容器中,基于红黑树实现的 TreeMap 在单线程中的性能表现得并不比跳跃表差。
因此就实现了在非线程安全的 Map 容器中,用 TreeMap 容器来存取大数据;在线程安全的 Map 容器中,用 SkipListMap 容器来存取大数据。
如果对数据有强一致要求,则需使用 Hashtable;在大部分场景通常都是弱一致性的情况下,使用 ConcurrentHashMap 即可;如果数据量在千万级别,且存在大量增删改操作,则可以考虑使用 ConcurrentSkipListMap。
并发场景下的 List 容器
ArrayList 是非线程安全容器,在并发场景下使用很可能会导致线程安全问题。这时,我们就可以考虑使用 Java 在并发编程中提供的线程安全数组,包括 Vector 和 CopyOnWriteArrayList。
Vector 也是基于 Synchronized 同步锁实现的线程安全,Synchronized 关键字几乎修饰了所有对外暴露的方法,所以在读远大于写的操作场景中,Vector 将会发生大量锁竞争,从而给系统带来性能开销。
相比之下,CopyOnWriteArrayList 是 java.util.concurrent 包提供的方法,它实现了读操作无锁,写操作则通过操作底层数组的新副本来实现,是一种读写分离的并发策略。我们可以通过以下图示来了解下 CopyOnWriteArrayList 的具体实现原理。
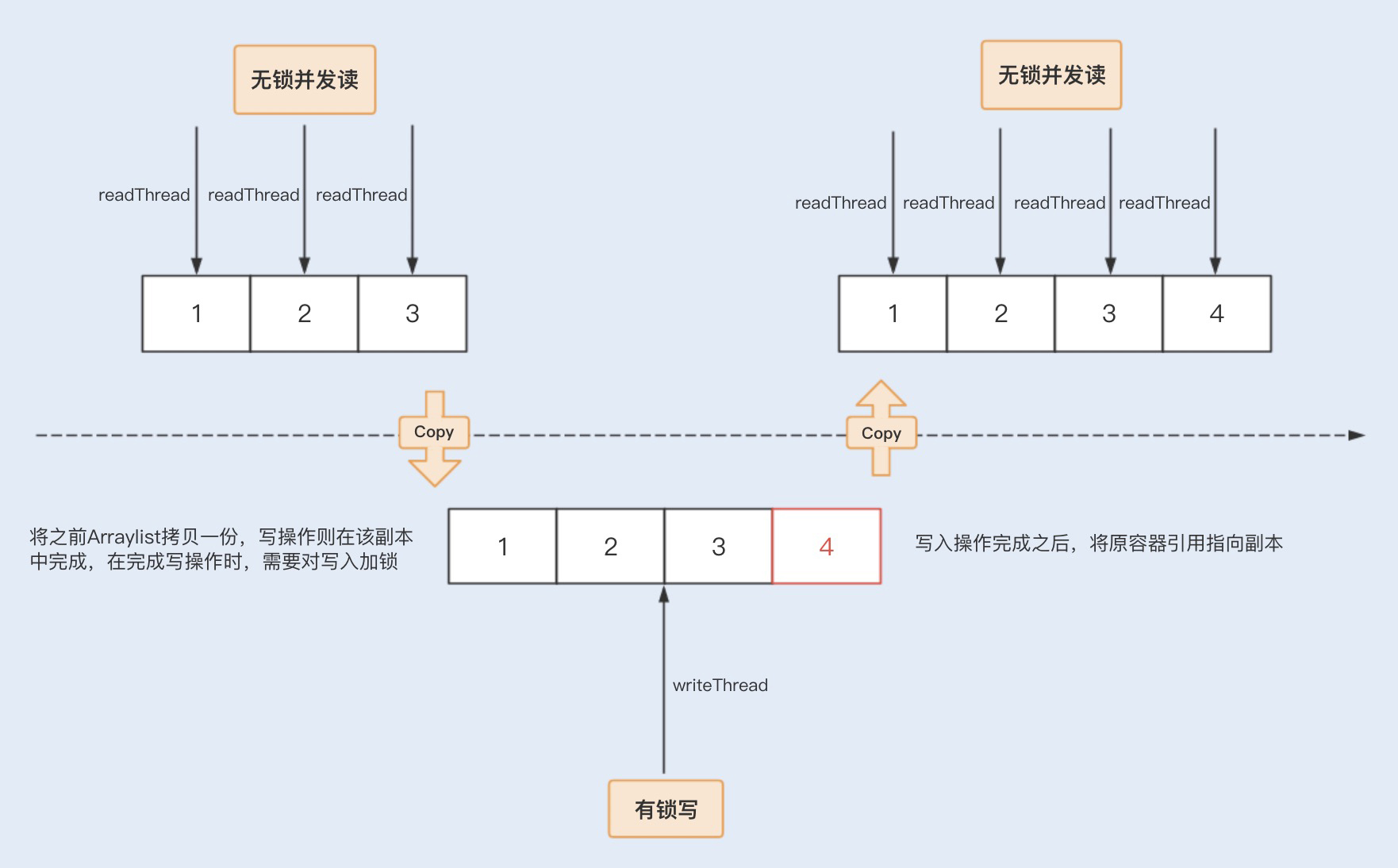
总结
18.如何设置线程池大小?
线程池框架 Executor
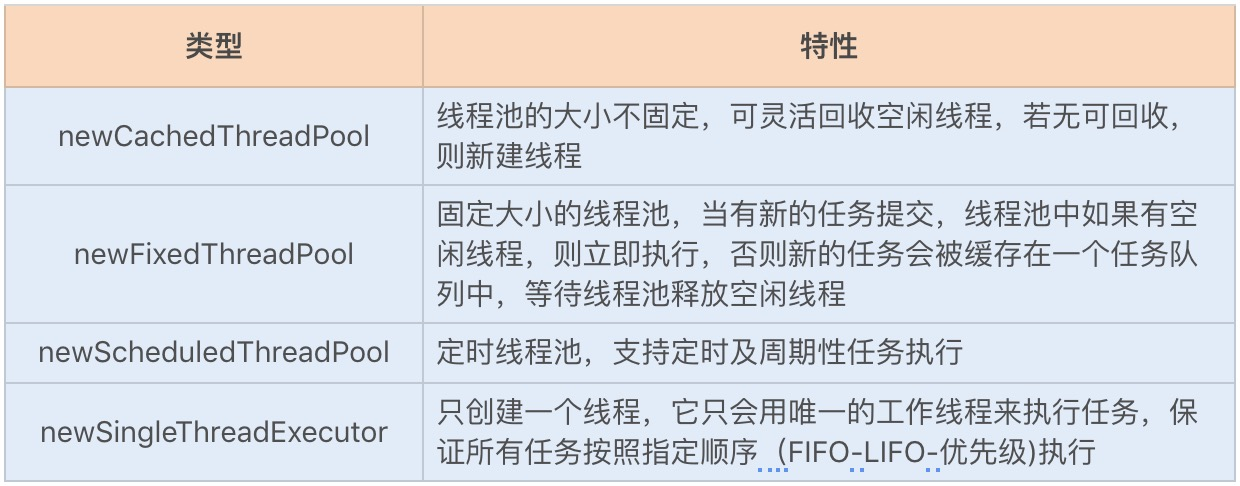
自定义线程池配置参数
public ThreadPoolExecutor(int corePoolSize,// 线程池的核心线程数量
int maximumPoolSize,// 线程池的最大线程数
long keepAliveTime,// 当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,// 时间单位
BlockingQueue<Runnable> workQueue,// 任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,// 线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler) // 拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
默认情况下,线程池中并没有任何线程,等到有任务来才创建线程去执行任务。
但有一种情况排除在外,就是调用 prestartAllCoreThreads() 或者 prestartCoreThread() 方法的话,可以提前创建等于核心线程数的线程数量,这种方式被称为预热,在抢购系统中就经常被用到。
当创建的线程数等于 corePoolSize 时,提交的任务会被加入到设置的阻塞队列中。当队列满了,会创建线程执行任务,直到线程池中的数量等于 maximumPoolSize。
当线程数量已经等于 maximumPoolSize 时, 新提交的任务无法加入到等待队列,也无法创建非核心线程直接执行,我们又没有为线程池设置拒绝策略,这时线程池就会抛出 RejectedExecutionException 异常,即线程池拒绝接受这个任务。
当线程池中创建的线程数量超过设置的 corePoolSize,在某些线程处理完任务后,如果等待 keepAliveTime 时间后仍然没有新的任务分配给它,那么这个线程将会被回收。线程池回收线程时,会对所谓的“核心线程”和“非核心线程”一视同仁,直到线程池中线程的数量等于设置的 corePoolSize 参数,回收过程才会停止。
即使是 corePoolSize 线程,在一些非核心业务的线程池中,如果长时间地占用线程数量,也可能会影响到核心业务的线程池,这个时候就需要把没有分配任务的线程回收掉。
我们可以通过 allowCoreThreadTimeOut 设置项要求线程池:将包括“核心线程”在内的,没有任务分配的所有线程,在等待 keepAliveTime 时间后全部回收掉。
计算线程数量
一般多线程执行的任务类型可以分为 CPU 密集型和 I/O 密集型,根据不同的任务类型,我们计算线程数的方法也不一样。
CPU 密集型任务:这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务:这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
那么碰上一些常规的业务操作,比如,通过一个线程池实现向用户定时推送消息的业务,我们又该如何设置线程池的数量呢?
此时我们可以参考以下公式来计算线程数:
线程数 =N(CPU 核数)*(1+WT(线程等待时间)/ST(线程时间运行时间))
我们可以通过 JDK 自带的工具 VisualVM 来查看 WT/ST 比例,以下例子是基于运行纯 CPU 运算的例子,我们可以看到:
WT(线程等待时间)= 36788ms [线程运行总时间] - 36788ms[ST(线程时间运行时间)]= 0
线程数 =N(CPU 核数)*(1+ 0 [WT(线程等待时间)]/36788ms[ST(线程时间运行时间)])= N(CPU 核数)
综合来看,我们可以根据自己的业务场景,从“N+1”和“2N”两个公式中选出一个适合的,计算出一个大概的线程数量,之后通过实际压测,逐渐往“增大线程数量”和“减小线程数量”这两个方向调整,然后观察整体的处理时间变化,最终确定一个具体的线程数量。
20. 了解JVM内存模型
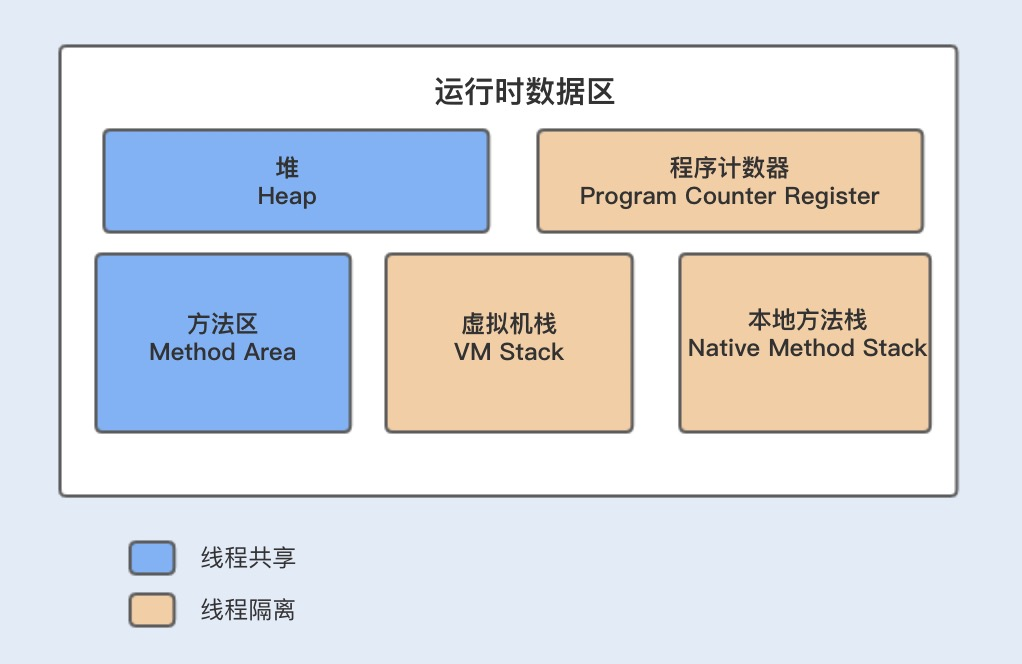
JVM 内存模型的具体设计
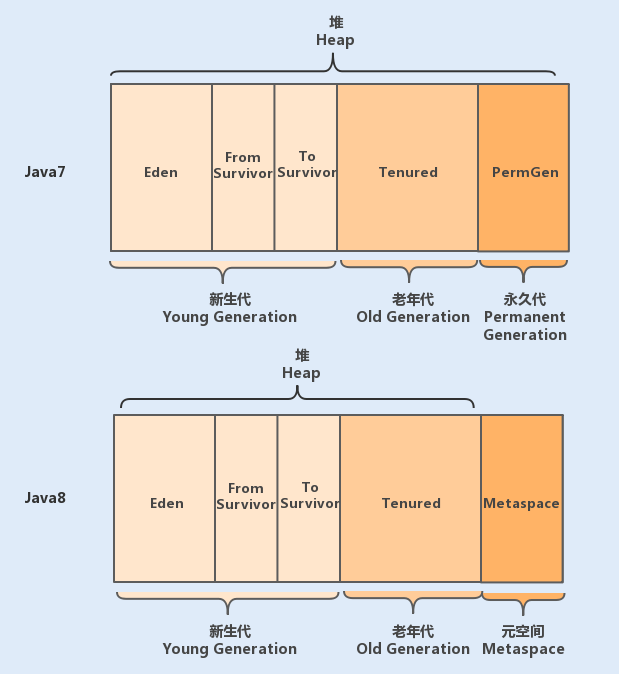
我们先通过一张 JVM 内存模型图,来熟悉下其具体设计。在 Java 中,JVM 内存模型主要分为堆、程序计数器、方法区、虚拟机栈和本地方法栈。
1. 堆(Heap)
堆是 JVM 内存中最大的一块内存空间,该内存被所有线程共享,几乎所有对象和数组都被分配到了堆内存中。堆被划分为新生代和老年代,新生代又被进一步划分为 Eden 和 Survivor 区,最后 Survivor 由 From Survivor 和 To Survivor 组成。
在 Java6 版本中,永久代在非堆内存区;到了 Java7 版本,永久代的静态变量和运行时常量池被合并到了堆中;而到了 Java8,永久代被元空间取代了。 结构如下图所示:
2. 程序计数器(Program Counter Register)
程序计数器是一块很小的内存空间,主要用来记录各个线程执行的字节码的地址,例如,分支、循环、跳转、异常、线程恢复等都依赖于计数器。
由于 Java 是多线程语言,当执行的线程数量超过 CPU 数量时,线程之间会根据时间片轮询争夺 CPU 资源。如果一个线程的时间片用完了,或者是其它原因导致这个线程的 CPU 资源被提前抢夺,那么这个退出的线程就需要单独的一个程序计数器,来记录下一条运行的指令。
3. 方法区(Method Area)
方法区主要是用来存放已被虚拟机加载的类相关信息,包括类信息、运行时常量池、字符串常量池。类信息又包括了类的版本、字段、方法、接口和父类等信息。
JVM 在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。在加载类的时候,JVM 会先加载 class 文件,而在 class 文件中除了有类的版本、字段、方法和接口等描述信息外,还有一项信息是常量池 (Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用。
方法区与堆空间类似,也是一个共享内存区,所以方法区是线程共享的。假如两个线程都试图访问方法区中的同一个类信息,而这个类还没有装入 JVM,那么此时就只允许一个线程去加载它,另一个线程必须等待。
4. 虚拟机栈(VM stack)
Java 虚拟机栈是线程私有的内存空间,它和 Java 线程一起创建。当创建一个线程时,会在虚拟机栈中申请一个线程栈,用来保存方法的局部变量、操作数栈、动态链接方法和返回地址等信息,并参与方法的调用和返回。每一个方法的调用都伴随着栈帧的入栈操作,方法的返回则是栈帧的出栈操作。
5. 本地方法栈(Native Method Stack)
本地方法栈跟 Java 虚拟机栈的功能类似,Java 虚拟机栈用于管理 Java 函数的调用,而本地方法栈则用于管理本地方法的调用。但本地方法并不是用 Java 实现的,而是由 C 语言实现的。
JVM 的运行原理
public class JVMCase {
// 常量
public final static String MAN_SEX_TYPE = "man";
// 静态变量
public static String WOMAN_SEX_TYPE = "woman";
public static void main(String[] args) {
Student stu = new Student();
stu.setName("nick");
stu.setSexType(MAN_SEX_TYPE);
stu.setAge(20);
JVMCase jvmcase = new JVMCase();
// 调用静态方法
print(stu);
// 调用非静态方法
jvmcase.sayHello(stu);
}
// 常规静态方法
public static void print(Student stu) {
System.out.println("name: " + stu.getName() + "; sex:" + stu.getSexType() + "; age:" + stu.getAge());
}
// 非静态方法
public void sayHello(Student stu) {
System.out.println(stu.getName() + "say: hello");
}
}
class Student{
String name;
String sexType;
int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSexType() {
return sexType;
}
public void setSexType(String sexType) {
this.sexType = sexType;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
当我们通过 Java 运行以上代码时,JVM 的整个处理过程如下:
1.JVM 向操作系统申请内存,JVM 第一步就是通过配置参数或者默认配置参数向操作系统申请内存空间,根据内存大小找到具体的内存分配表,然后把内存段的起始地址和终止地址分配给 JVM,接下来 JVM 就进行内部分配。
2.JVM 获得内存空间后,会根据配置参数分配堆、栈以及方法区的内存大小。
3.class 文件加载、验证、准备以及解析,其中准备阶段会为类的静态变量分配内存,初始化为系统的初始值。

- 完成上一个步骤后,将会进行最后一个初始化阶段。在这个阶段中,JVM 首先会执行构造器
方法,编译器会在.java 文件被编译成.class 文件时,收集所有类的初始化代码,包括静态变量赋值语句、静态代码块、静态方法,收集在一起成为 () 方法。
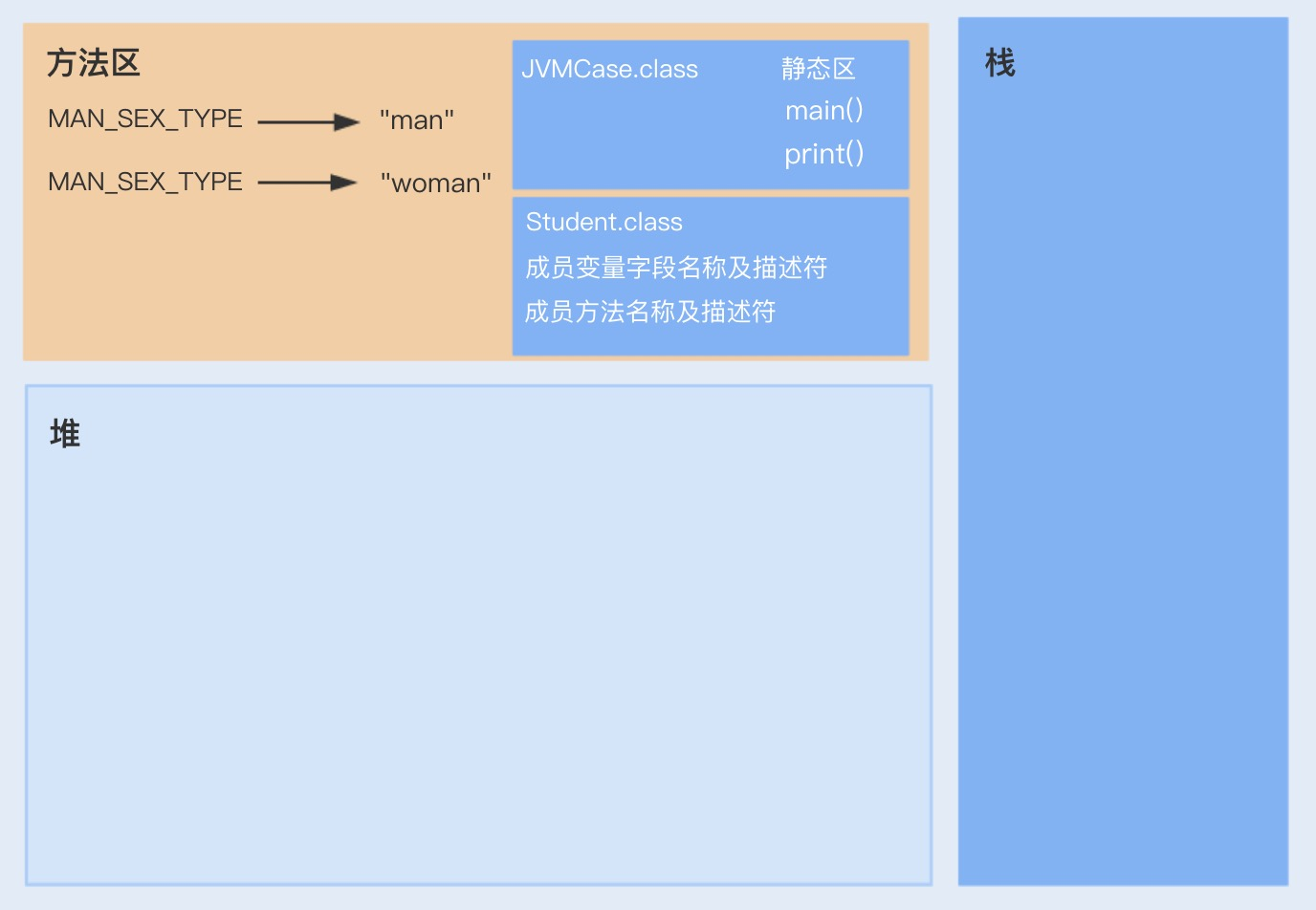
- 执行方法。启动 main 线程,执行 main 方法,开始执行第一行代码。此时堆内存中会创建一个 student 对象,对象引用 student 就存放在栈中。
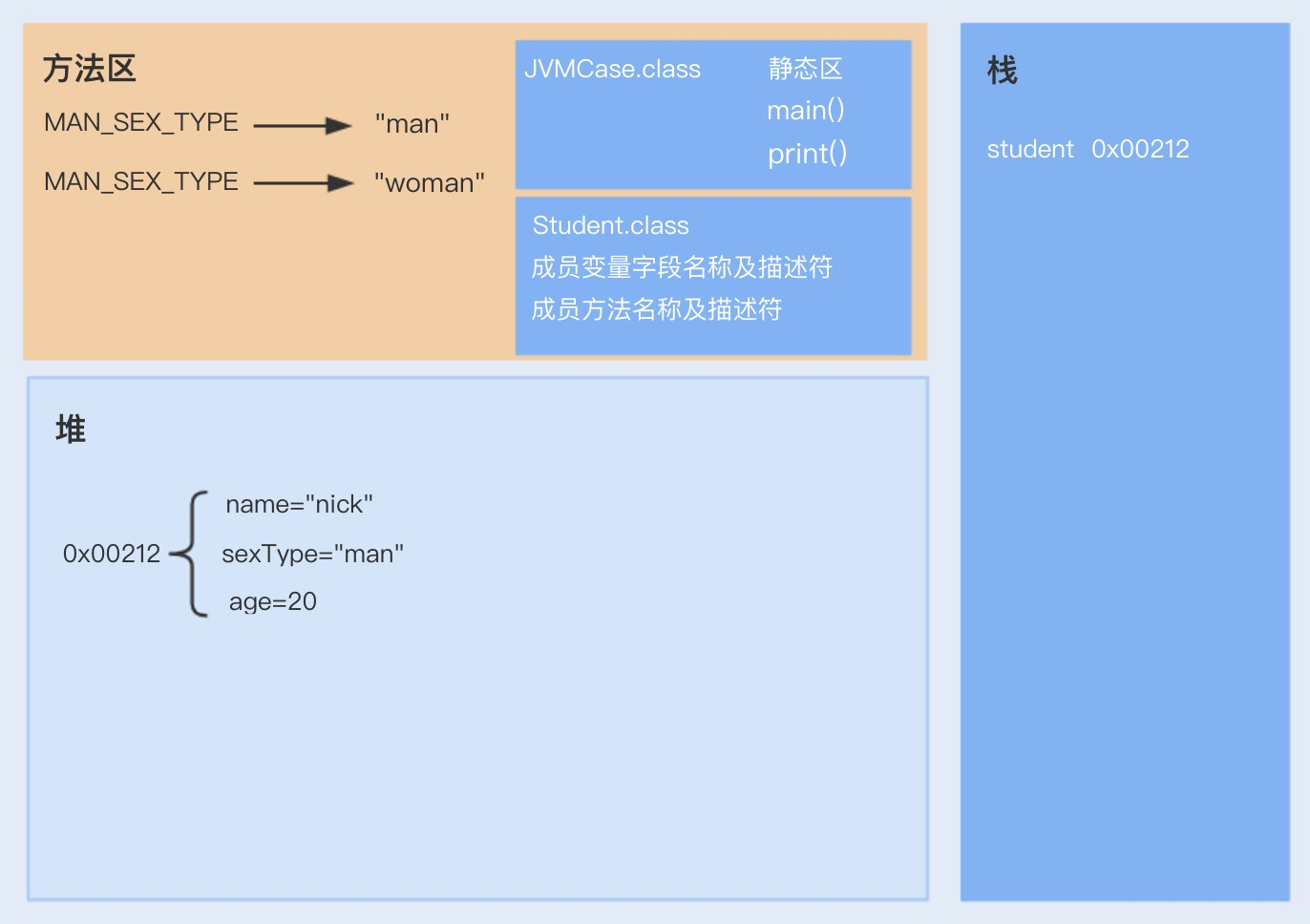
- 此时再次创建一个 JVMCase 对象,调用 sayHello 非静态方法,sayHello 方法属于对象 JVMCase,此时 sayHello 方法入栈,并通过栈中的 student 引用调用堆中的 Student 对象;之后,调用静态方法 print,print 静态方法属于 JVMCase 类,是从静态方法中获取,之后放入到栈中,也是通过 student 引用调用堆中的 student 对象。

21.深入JVM即时编译器JIT,优化Java编译
说到编译,我猜你一定会想到 .java 文件被编译成 .class 文件的过程,这个编译我们一般称为前端编译。Java 的编译和运行过程非常复杂,除了前端编译,还有运行时编译。由于机器无法直接运行 Java 生成的字节码,所以在运行时,JIT 或解释器会将字节码转换成机器码,这个过程就叫运行时编译。
类文件在运行时被进一步编译,它们可以变成高度优化的机器代码,由于 C/C++ 编译器的所有优化都是在编译期间完成的,运行期间的性能监控仅作为基础的优化措施则无法进行,例如,调用频率预测、分支频率预测、裁剪未被选择的分支等,而 Java 在运行时的再次编译,就可以进行基础的优化措施。因此,JIT 编译器可以说是 JVM 中运行时编译最重要的部分之一。
类编译加载执行过程

在编写好代码之后,我们需要将 .java 文件编译成 .class 文件,才能在虚拟机上正常运行代码。文件的编译通常是由 JDK 中自带的 Javac 工具完成,一个简单的 .java 文件,我们可以通过 javac 命令来生成 .class 文件。
编译后的字节码文件主要包括常量池和方法表集合这两部分。
常量池主要记录的是类文件中出现的字面量以及符号引用。字面常量包括字符串常量(例如 String str=“abc”,其中"abc"就是常量),声明为 final 的属性以及一些基本类型(例如,范围在 -127-128 之间的整型)的属性。符号引用包括类和接口的全限定名、类引用、方法引用以及成员变量引用(例如 String str=“abc”,其中 str 就是成员变量引用)等。
方法表集合中主要包含一些方法的字节码、方法访问权限(public、protect、prviate 等)、方法名索引(与常量池中的方法引用对应)、描述符索引、JVM 执行指令以及属性集合等。
类加载
当一个类被创建实例或者被其它对象引用时,虚拟机在没有加载过该类的情况下,会通过类加载器将字节码文件加载到内存中。
不同的实现类由不同的类加载器加载,JDK 中的本地方法类一般由根加载器(Bootstrp loader)加载进来,JDK 中内部实现的扩展类一般由扩展加载器(ExtClassLoader )实现加载,而程序中的类文件则由系统加载器(AppClassLoader )实现加载。
在类加载后,class 类文件中的常量池信息以及其它数据会被保存到 JVM 内存的方法区中。
类连接
类在加载进来之后,会进行连接、初始化,最后才会被使用。在连接过程中,又包括验证、准备和解析三个部分。
验证:验证类符合 Java 规范和 JVM 规范,在保证符合规范的前提下,避免危害虚拟机安全。
准备:为类的静态变量分配内存,初始化为系统的初始值。对于 final static 修饰的变量,直接赋值为用户的定义值。例如,private final static int value=123,会在准备阶段分配内存,并初始化值为 123,而如果是 private static int value=123,这个阶段 value 的值仍然为 0。
解析:将符号引用转为直接引用的过程。我们知道,在编译时,Java 类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。类结构文件的常量池中存储了符号引用,包括类和接口的全限定名、类引用、方法引用以及成员变量引用等。如果要使用这些类和方法,就需要把它们转化为 JVM 可以直接获取的内存地址或指针,即直接引用。
类初始化
类初始化阶段是类加载过程的最后阶段,在这个阶段中,JVM 首先将执行构造器
初始化类的静态变量和静态代码块为用户自定义的值,初始化的顺序和 Java 源码从上到下的顺序一致。
子类初始化时会首先调用父类的
即时编译
初始化完成后,类在调用执行过程中,执行引擎会把字节码转为机器码,然后在操作系统中才能执行。在字节码转换为机器码的过程中,虚拟机中还存在着一道编译,那就是即时编译。
最初,虚拟机中的字节码是由解释器( Interpreter )完成编译的,当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会把这些代码认定为“热点代码”。
为了提高热点代码的执行效率,在运行时,即时编译器(JIT)会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,然后保存到内存中。
在 HotSpot 虚拟机中,内置了两个 JIT,分别为 C1 编译器和 C2 编译器,这两个编译器的编译过程是不一样的。
C1 编译器是一个简单快速的编译器,主要的关注点在于局部性的优化,适用于执行时间较短或对启动性能有要求的程序,例如,GUI 应用对界面启动速度就有一定要求。
C2 编译器是为长期运行的服务器端应用程序做性能调优的编译器,适用于执行时间较长或对峰值性能有要求的程序。根据各自的适配性,这两种即时编译也被称为 Client Compiler 和 Server Compiler。
Java7 引入了分层编译,这种方式综合了 C1 的启动性能优势和 C2 的峰值性能优势,我们也可以通过参数 “-client”“-server” 强制指定虚拟机的即时编译模式。分层编译将 JVM 的执行状态分为了 5 个层次:
- 第 0 层:程序解释执行,默认开启性能监控功能(Profiling),如果不开启,可触发第二层编译;
- 第 1 层:可称为 C1 编译,将字节码编译为本地代码,进行简单、可靠的优化,不开启 Profiling;
- 第 2 层:也称为 C1 编译,开启 Profiling,仅执行带方法调用次数和循环回边执行次数 profiling 的 C1 编译;
- 第 3 层:也称为 C1 编译,执行所有带 Profiling 的 C1 编译;
- 第 4 层:可称为 C2 编译,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
在 Java8 中,默认开启分层编译,-client 和 -server 的设置已经是无效的了。如果只想开启 C2,可以关闭分层编译(-XX:-TieredCompilation),如果只想用 C1,可以在打开分层编译的同时,使用参数:-XX:TieredStopAtLevel=1。
除了这种默认的混合编译模式,我们还可以使用“-Xint”参数强制虚拟机运行于只有解释器的编译模式下,这时 JIT 完全不介入工作;我们还可以使用参数“-Xcomp”强制虚拟机运行于只有 JIT 的编译模式下。
热点探测
在 HotSpot 虚拟机中的热点探测是 JIT 优化的条件,热点探测是基于计数器的热点探测,采用这种方法的虚拟机会为每个方法建立计数器统计方法的执行次数,如果执行次数超过一定的阈值就认为它是“热点方法” 。
虚拟机为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发 JIT 编译。
当循环达到回边计数器阈值时,JVM 会认为这段是热点代码,JIT 编译器就会将这段代码编译成机器语言并缓存,在该循环时间段内,会直接将执行代码替换,执行缓存的机器语言。
编译优化技术
1. 方法内联
调用一个方法通常要经历压栈和出栈。调用方法是将程序执行顺序转移到存储该方法的内存地址,将方法的内容执行完后,再返回到执行该方法前的位置。
那么对于那些方法体代码不是很大,又频繁调用的方法来说,这个时间和空间的消耗会很大。方法内联的优化行为就是把目标方法的代码复制到发起调用的方法之中,避免发生真实的方法调用。
热点方法的优化可以有效提高系统性能,一般我们可以通过以下几种方式来提高方法内联:
- 通过设置 JVM 参数来减小热点阈值或增加方法体阈值,以便更多的方法可以进行内联,但这种方法意味着需要占用更多地内存;
- 在编程中,避免在一个方法中写大量代码,习惯使用小方法体;
- 尽量使用 final、private、static 关键字修饰方法,编码方法因为继承,会需要额外的类型检查。
2. 逃逸分析
逃逸分析(Escape Analysis)是判断一个对象是否被外部方法引用或外部线程访问的分析技术,编译器会根据逃逸分析的结果对代码进行优化。
我们知道,在 Java 中默认创建一个对象是在堆中分配内存的,而当堆内存中的对象不再使用时,则需要通过垃圾回收机制回收,这个过程相对分配在栈中的对象的创建和销毁来说,更消耗时间和性能。这个时候,逃逸分析如果发现一个对象只在方法中使用,就会将对象分配在栈上。
锁消除
在局部方法中创建的对象只能被当前线程访问,无法被其它线程访问,这个变量的读写肯定不会有竞争,这个时候 JIT 编译会对这个对象的方法锁进行锁消除。
标量替换
逃逸分析证明一个对象不会被外部访问,如果这个对象可以被拆分的话,当程序真正执行的时候可能不创建这个对象,而直接创建它的成员变量来代替。将对象拆分后,可以分配对象的成员变量在栈或寄存器上,原本的对象就无需分配内存空间了。这种编译优化就叫做标量替换。
public void foo() {
TestInfo info = new TestInfo();
info.id = 1;
info.count = 99;
...//to do something
}
逃逸分析后,代码会被优化为:
public void foo() {
id = 1;
count = 99;
...//to do something
}
22.如何优化垃圾回收机制?
回收发生在哪里?
JVM 的内存区域中,程序计数器、虚拟机栈和本地方法栈这 3 个区域是线程私有的,随着线程的创建而创建,销毁而销毁;栈中的栈帧随着方法的进入和退出进行入栈和出栈操作,每个栈帧中分配多少内存基本是在类结构确定下来的时候就已知的,因此这三个区域的内存分配和回收都具有确定性。
那么垃圾回收的重点就是关注堆和方法区中的内存了,堆中的回收主要是对象的回收,方法区的回收主要是废弃常量和无用的类的回收。
对象在什么时候可以被回收?
那 JVM 又是怎样判断一个对象是可以被回收的呢?一般一个对象不再被引用,就代表该对象可以被回收。目前有以下两种算法可以判断该对象是否可以被回收。
引用计数算法:这种算法是通过一个对象的引用计数器来判断该对象是否被引用了。每当对象被引用,引用计数器就会加 1;每当引用失效,计数器就会减 1。当对象的引用计数器的值为 0 时,就说明该对象不再被引用,可以被回收了。这里强调一点,虽然引用计数算法的实现简单,判断效率也很高,但它存在着对象之间相互循环引用的问题。
可达性分析算法:GC Roots 是该算法的基础,GC Roots 是所有对象的根对象,在 JVM 加载时,会创建一些普通对象引用正常对象。这些对象作为正常对象的起始点,在垃圾回收时,会从这些 GC Roots 开始向下搜索,当一个对象到 GC Roots 没有任何引用链相连时,就证明此对象是不可用的。目前 HotSpot 虚拟机采用的就是这种算法。
以上两种算法都是通过引用来判断对象是否可以被回收。在 JDK 1.2 之后,Java 对引用的概念进行了扩充,将引用分为了以下四种:
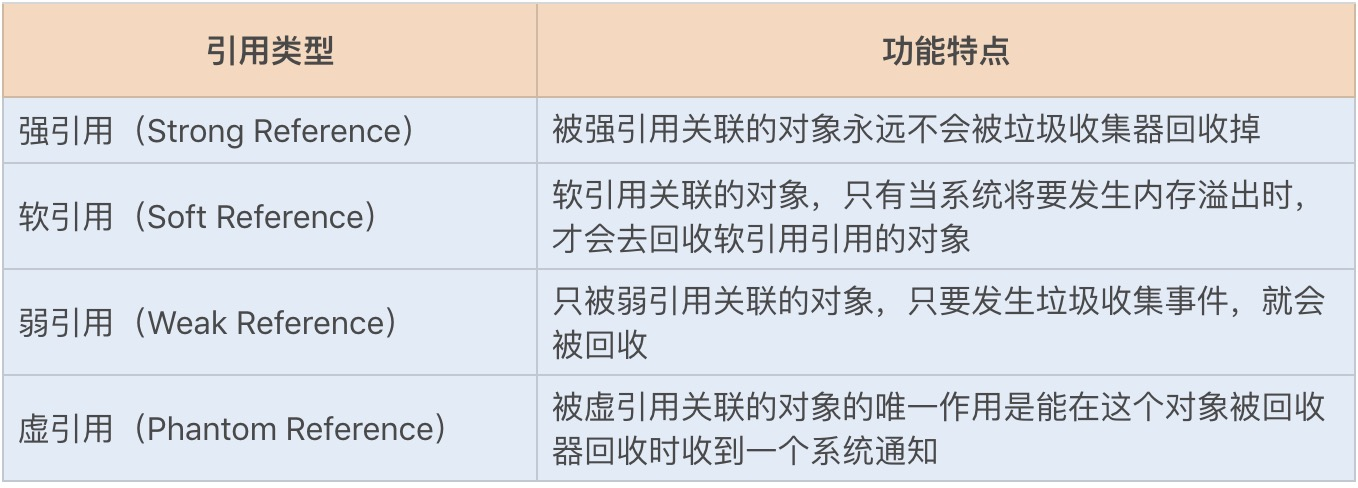
如何回收这些对象?
解完 Java 程序中对象的回收条件,那么垃圾回收线程又是如何回收这些对象的呢?JVM 垃圾回收遵循以下两个特性。
自动性:Java 提供了一个系统级的线程来跟踪每一块分配出去的内存空间,当 JVM 处于空闲循环时,垃圾收集器线程会自动检查每一块分配出去的内存空间,然后自动回收每一块空闲的内存块。
不可预期性:一旦一个对象没有被引用了,该对象是否立刻被回收呢?答案是不可预期的。我们很难确定一个没有被引用的对象是不是会被立刻回收掉,因为有可能当程序结束后,这个对象仍在内存中。
垃圾回收线程在 JVM 中是自动执行的,Java 程序无法强制执行。我们唯一能做的就是通过调用 System.gc 方法来"建议"执行垃圾收集器,但是否可执行,什么时候执行?仍然不可预期。
GC 算法
JVM 提供了不同的回收算法来实现这一套回收机制,通常垃圾收集器的回收算法可以分为以下几种:
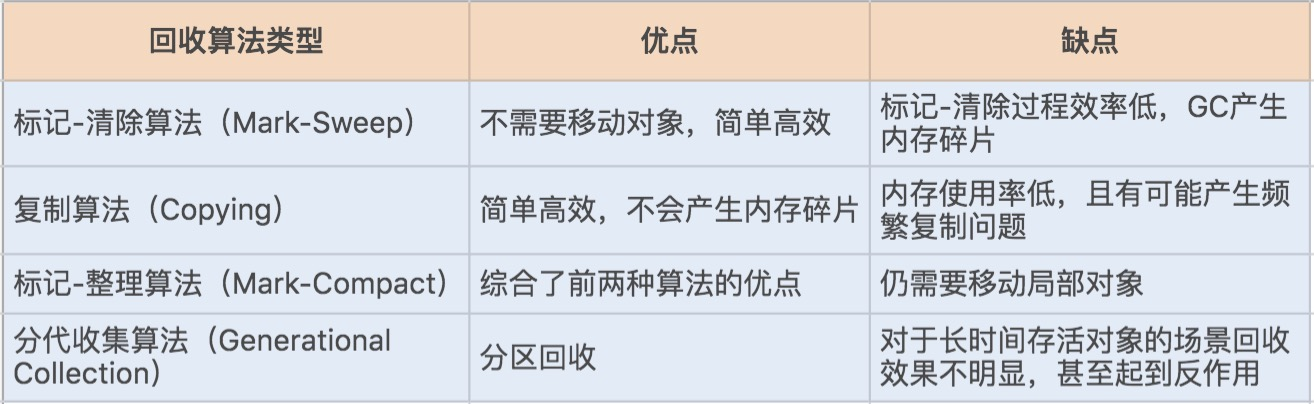
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现,JDK1.7 update14 之后 Hotspot 虚拟机所有的回收器整理如下(以下为服务端垃圾收集器):
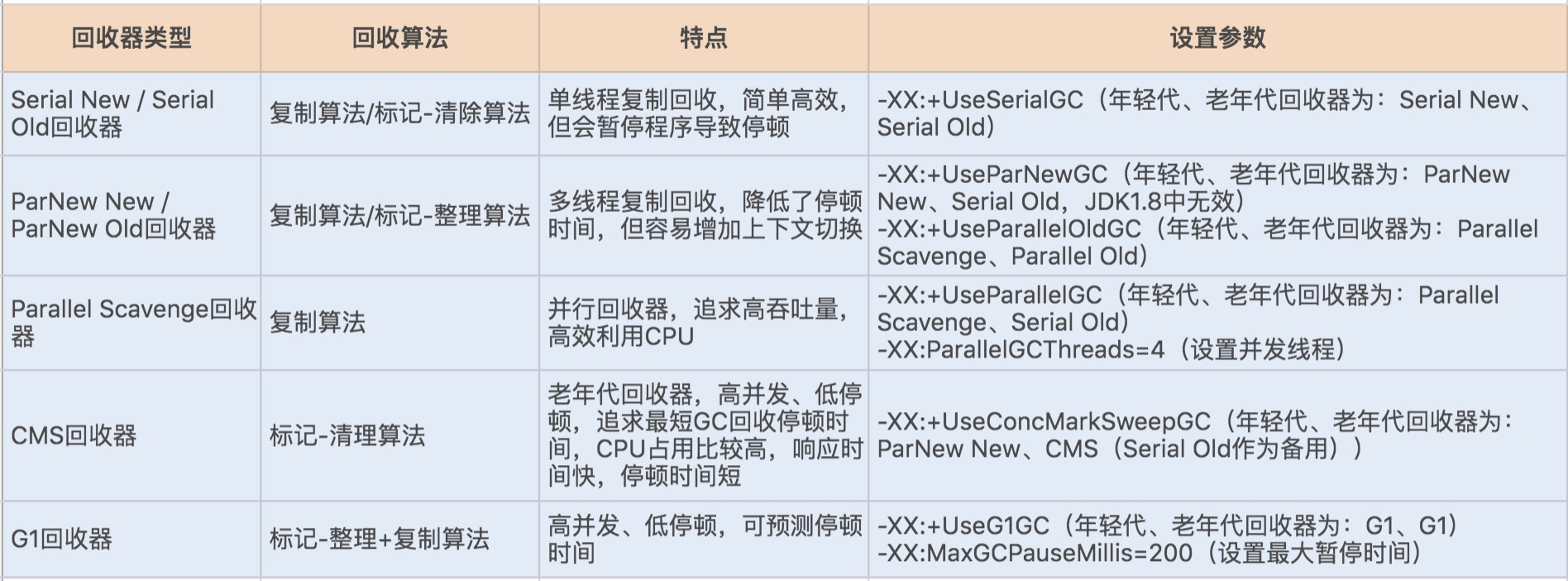
其实在 JVM 规范中并没有明确 GC 的运作方式,各个厂商可以采用不同的方式实现垃圾收集器。我们可以通过 JVM 工具查询当前 JVM 使用的垃圾收集器类型,首先通过 ps 命令查询出经常 ID,再通过 jmap -heap ID 查询出 JVM 的配置信息,其中就包括垃圾收集器的设置类型。
GC 性能衡量指标
一个垃圾收集器在不同场景下表现出的性能也不一样,那么如何评价一个垃圾收集器的性能好坏呢?我们可以借助一些指标。
吞吐量:这里的吞吐量是指应用程序所花费的时间和系统总运行时间的比值。我们可以按照这个公式来计算 GC 的吞吐量:系统总运行时间 = 应用程序耗时 +GC 耗时。如果系统运行了 100 分钟,GC 耗时 1 分钟,则系统吞吐量为 99%。GC 的吞吐量一般不能低于 95%。
停顿时间:指垃圾收集器正在运行时,应用程序的暂停时间。对于串行回收器而言,停顿时间可能会比较长;而使用并发回收器,由于垃圾收集器和应用程序交替运行,程序的停顿时间就会变短,但其效率很可能不如独占垃圾收集器,系统的吞吐量也很可能会降低。
垃圾回收频率:多久发生一次指垃圾回收呢?通常垃圾回收的频率越低越好,增大堆内存空间可以有效降低垃圾回收发生的频率,但同时也意味着堆积的回收对象越多,最终也会增加回收时的停顿时间。所以我们只要适当地增大堆内存空间,保证正常的垃圾回收频率即可。
GC 调优策略
1. 降低 Minor GC 频率
通常情况下,由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
2. 降低 Full GC 的频率
通常情况下,由于堆内存空间不足或老年代对象太多,会触发 Full GC,频繁的 Full GC 会带来上下文切换,增加系统的性能开销。我们可以使用哪些方法来降低 Full GC 的频率呢?
减少创建大对象:在平常的业务场景中,我们习惯一次性从数据库中查询出一个大对象用于 web 端显示。例如,我之前碰到过一个一次性查询出 60 个字段的业务操作,这种大对象如果超过年轻代最大对象阈值,会被直接创建在老年代;即使被创建在了年轻代,由于年轻代的内存空间有限,通过 Minor GC 之后也会进入到老年代。这种大对象很容易产生较多的 Full GC。
我们可以将这种大对象拆解出来,首次只查询一些比较重要的字段,如果还需要其它字段辅助查看,再通过第二次查询显示剩余的字段。
增大堆内存空间:在堆内存不足的情况下,增大堆内存空间,且设置初始化堆内存为最大堆内存,也可以降低 Full GC 的频率。
选择合适的 GC 回收器
假设我们有这样一个需求,要求每次操作的响应时间必须在 500ms 以内。这个时候我们一般会选择响应速度较快的 GC 回收器,CMS(Concurrent Mark Sweep)回收器和 G1 回收器都是不错的选择。
而当我们的需求对系统吞吐量有要求时,就可以选择 Parallel Scavenge 回收器来提高系统的吞吐量。
垃圾收集器的种类很多,我们可以将其分成两种类型,一种是响应速度快,一种是吞吐量高。通常情况下,CMS 和 G1 回收器的响应速度快,Parallel Scavenge 回收器的吞吐量高。
在 JDK1.8 环境下,默认使用的是 Parallel Scavenge(年轻代)+Serial Old(老年代)垃圾收集器,你可以通过文中介绍的查询 JVM 的 GC 默认配置方法进行查看。
通常情况,JVM 是默认垃圾回收优化的,在没有性能衡量标准的前提下,尽量避免修改 GC 的一些性能配置参数。如果一定要改,那就必须基于大量的测试结果或线上的具体性能来进行调整。
23.如何优化JVM内存分配?
谈到 JVM 内存表现出的性能问题时,你可能会想到一些线上的 JVM 内存溢出事故。但这方面的事故往往是应用程序创建对象导致的内存回收对象难,一般属于代码编程问题。
但其实很多时候,在应用服务的特定场景下,JVM 内存分配不合理带来的性能表现并不会像内存溢出问题这么突出。可以说如果你没有深入到各项性能指标中去,是很难发现其中隐藏的性能损耗。
JVM 内存分配不合理最直接的表现就是频繁的 GC,这会导致上下文切换等性能问题,从而降低系统的吞吐量、增加系统的响应时间。因此,如果你在线上环境或性能测试时,发现频繁的 GC,且是正常的对象创建和回收,这个时候就需要考虑调整 JVM 内存分配了,从而减少 GC 所带来的性能开销。
对象在堆中的生存周期
在 JVM 内存模型的堆中,堆被划分为新生代和老年代,新生代又被进一步划分为 Eden 区和 Survivor 区,最后 Survivor 由 From Survivor 和 To Survivor 组成。
当我们新建一个对象时,对象会被优先分配到新生代的 Eden 区中,这时虚拟机会给对象定义一个对象年龄计数器(通过参数 -XX:MaxTenuringThreshold 设置)。
同时,也有另外一种情况,当 Eden 空间不足时,虚拟机将会执行一个新生代的垃圾回收(Minor GC)。这时 JVM 会把存活的对象转移到 Survivor 中,并给对象的年龄 +1。对象在 Survivor 中同样也会经历 MinorGC,每经过一次 MinorGC,对象的年龄将会 +1。
当然了,内存空间也是有设置阈值的,可以通过参数 -XX:PetenureSizeThreshold 设置直接被分配到老年代的最大对象,这时如果分配的对象超过了设置的阀值,对象就会直接被分配到老年代,这样做的好处就是可以减少新生代的垃圾回收。
查看 JVM 堆内存分配
我们知道了一个对象从创建至回收到堆中的过程,接下来我们再来了解下 JVM 堆内存是如何分配的。在默认不配置 JVM 堆内存大小的情况下,JVM 根据默认值来配置当前内存大小。我们可以通过以下命令来查看堆内存配置的默认值:
java -XX:+PrintFlagsFinal -version | grep HeapSize
jmap -heap 17284
在 JDK1.8 中,不要随便关闭 UseAdaptiveSizePolicy 配置项,除非你已经对初始化堆内存 / 最大堆内存、年轻代 / 老年代以及 Eden 区 /Survivor 区有非常明确的规划了。否则 JVM 将会分配最小堆内存,年轻代和老年代按照默认比例 1:2 进行分配,年轻代中的 Eden 和 Survivor 则按照默认比例 8:2 进行分配。这个内存分配未必是应用服务的最佳配置,因此可能会给应用服务带来严重的性能问题。
JVM 内存分配的调优过程
参考指标
GC 频率:高频的 FullGC 会给系统带来非常大的性能消耗,虽然 MinorGC 相对 FullGC 来说好了许多,但过多的 MinorGC 仍会给系统带来压力。
内存:这里的内存指的是堆内存大小,堆内存又分为年轻代内存和老年代内存。首先我们要分析堆内存大小是否合适,其实是分析年轻代和老年代的比例是否合适。如果内存不足或分配不均匀,会增加 FullGC,严重的将导致 CPU 持续爆满,影响系统性能。
吞吐量:频繁的 FullGC 将会引起线程的上下文切换,增加系统的性能开销,从而影响每次处理的线程请求,最终导致系统的吞吐量下降。
延时:JVM 的 GC 持续时间也会影响到每次请求的响应时间。
具体调优方法
调整堆内存空间减少 FullGC:通过日志分析,堆内存基本被用完了,而且存在大量 FullGC,这意味着我们的堆内存严重不足,这个时候我们需要调大堆内存空间。
java -jar -Xms4g -Xmx4g heapTest-0.0.1-SNAPSHOT.jar
- -Xms:堆初始大小;
- -Xmx:堆最大值。
- -Xmn:年轻代大小
- -Xss:线程的堆栈大小
调整年轻代减少 MinorGC:通过调整堆内存大小,我们已经提升了整体的吞吐量,降低了响应时间。那还有优化空间吗?我们还可以将年轻代设置得大一些,从而减少一些 MinorG。
设置 Eden、Survivor 区比例:在 JVM 中,如果开启 AdaptiveSizePolicy,则每次 GC 后都会重新计算 Eden、From Survivor 和 To Survivor 区的大小,计算依据是 GC 过程中统计的 GC 时间、吞吐量、内存占用量。这个时候 SurvivorRatio 默认设置的比例会失效。
26.单例模式优化
饿汉模式
// 饿汉模式
public final class Singleton {
private static Singleton instance=new Singleton();// 自行创建实例
private Singleton(){}// 构造函数
public static Singleton getInstance(){// 通过该函数向整个系统提供实例
return instance;
}
}
以上第一种实现单例的代码中,使用了 static 修饰了成员变量 instance,所以该变量会在类初始化的过程中被收集进类构造器即
等到唯一的一次
这种方式实现的单例模式,在类加载阶段就已经在堆内存中开辟了一块内存,用于存放实例化对象,所以也称为饿汉模式。
饿汉模式实现的单例的优点是,可以保证多线程情况下实例的唯一性,而且 getInstance 直接返回唯一实例,性能非常高。
然而,在类成员变量比较多,或变量比较大的情况下,这种模式可能会在没有使用类对象的情况下,一直占用堆内存。试想下,如果一个第三方开源框架中的类都是基于饿汉模式实现的单例,这将会初始化所有单例类,无疑是灾难性的。
懒汉模式
懒汉模式就是为了避免直接加载类对象时提前创建对象的一种单例设计模式。该模式使用懒加载方式,只有当系统使用到类对象时,才会将实例加载到堆内存中。通过以下代码,我们可以简单地了解下懒加载的实现方式:
// 懒汉模式 + synchronized 同步锁 + double-check
public final class Singleton {
private volatile static Singleton instance= null;// 不实例化
public List
private Singleton(){
list = new ArrayList
}// 构造函数
public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例
if(null == instance){// 第一次判断,当 instance 为 null 时,则实例化对象,否则直接返回对象
synchronized (Singleton.class){// 同步锁
if(null == instance){// 第二次判断
instance = new Singleton();// 实例化对象
}
}
}
return instance;// 返回已存在的对象
}
}
通过内部类实现
以上这种同步锁 +Double-Check 的实现方式相对来说,复杂且加了同步锁,那有没有稍微简单一点儿的可以实现线程安全的懒加载方式呢?
我们知道,在饿汉模式中,我们使用了 static 修饰了成员变量 instance,所以该变量会在类初始化的过程中被收集进类构造器即
如果我们在 Singleton 类中创建一个内部类来实现成员变量的初始化,则可以避免多线程下重复创建对象的情况发生。这种方式,只有在第一次调用 getInstance() 方法时,才会加载 InnerSingleton 类,而只有在加载 InnerSingleton 类之后,才会实例化创建对象。具体实现如下:
// 懒汉模式 内部类实现
public final class Singleton {
public List
private Singleton() {// 构造函数
list = new ArrayList
}
// 内部类实现
public static class InnerSingleton {
private static Singleton instance=new Singleton();// 自行创建实例
}
public static Singleton getInstance() {
return InnerSingleton.instance;// 返回内部类中的静态变量
}
}
27. 原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢?
其实不然,它们的使用是分场景的。在有些场景下,我们需要重复创建多个实例,例如在循环体中赋值一个对象,此时我们就可以采用原型模式来优化对象的创建过程;而在有些场景下,我们则可以避免重复创建多个实例,在内存中共享对象就好了。
原型模式
原型模式是通过给出一个原型对象来指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象,该模式就是用这种方式来创建出更多同类型的对象。
使用这种方式创建新的对象的话,就无需再通过 new 实例化来创建对象了。这是因为 Object 类的 clone 方法是一个本地方法,它可以直接操作内存中的二进制流,所以性能相对 new 实例化来说,更佳。
// 实现 Cloneable 接口的原型抽象类 Prototype
class Prototype implements Cloneable {
// 重写 clone 方法
public Prototype clone(){
Prototype prototype = null;
try{
prototype = (Prototype)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return prototype;
}
}
// 实现原型类
class ConcretePrototype extends Prototype{
public void show(){
System.out.println(" 原型模式实现类 ");
}
}
public class Client {
public static void main(String[] args){
ConcretePrototype cp = new ConcretePrototype();
for(int i=0; i< 10; i++){
ConcretePrototype clonecp = (ConcretePrototype)cp.clone();
clonecp.show();
}
}
}
要实现一个原型类,需要具备三个条件:
- 实现 Cloneable 接口:Cloneable 接口与序列化接口的作用类似,它只是告诉虚拟机可以安全地在实现了这个接口的类上使用 clone 方法。在 JVM 中,只有实现了 Cloneable 接口的类才可以被拷贝,否则会抛出 CloneNotSupportedException 异常。
- 重写 Object 类中的 clone 方法:在 Java 中,所有类的父类都是 Object 类,而 Object 类中有一个 clone 方法,作用是返回对象的一个拷贝。
- 在重写的 clone 方法中调用 super.clone():默认情况下,类不具备复制对象的能力,需要调用 super.clone() 来实现。
原型模式的主要特征就是使用 clone 方法复制一个对象。通常,有些人会误以为 Object a=new Object();Object b=a; 这种形式就是一种对象复制的过程,然而这种复制只是对象引用的复制,也就是 a 和 b 对象指向了同一个内存地址,如果 b 修改了,a 的值也就跟着被修改了。
深拷贝和浅拷贝
在调用 super.clone() 方法之后,首先会检查当前对象所属的类是否支持 clone,也就是看该类是否实现了 Cloneable 接口。
如果支持,则创建当前对象所属类的一个新对象,并对该对象进行初始化,使得新对象的成员变量的值与当前对象的成员变量的值一模一样,但对于其它对象的引用以及 List 等类型的成员属性,则只能复制这些对象的引用了。所以简单调用 super.clone() 这种克隆对象方式,就是一种浅拷贝。
其实深拷贝就是基于浅拷贝来递归实现具体的每个对象。
public Student clone() {
Student student = null;
try {
student = (Student) super.clone();
Teacher teacher = this.teacher.clone();// 克隆 teacher 对象
student.setTeacher(teacher);
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return student;
}
原型模式在开源框架中的应用也非常广泛。例如 Spring 中,@Service 默认都是单例的。用了私有全局变量,若不想影响下次注入或每次上下文获取 bean,就需要用到原型模式,我们可以通过以下注解来实现,@Scope(“prototype”)。
享元模式
享元模式是运用共享技术有效地最大限度地复用细粒度对象的一种模式。该模式中,以对象的信息状态划分,可以分为内部数据和外部数据。内部数据是对象可以共享出来的信息,这些信息不会随着系统的运行而改变;外部数据则是在不同运行时被标记了不同的值。
享元模式一般可以分为三个角色,分别为 Flyweight(抽象享元类)、ConcreteFlyweight(具体享元类)和 FlyweightFactory(享元工厂类)。抽象享元类通常是一个接口或抽象类,向外界提供享元对象的内部数据或外部数据;具体享元类是指具体实现内部数据共享的类;享元工厂类则是主要用于创建和管理享元对象的工厂类。
// 抽象享元类
interface Flyweight {
// 对外状态对象
void operation(String name);
// 对内对象
String getType();
}
// 具体享元类
class ConcreteFlyweight implements Flyweight {
private String type;
public ConcreteFlyweight(String type) {
this.type = type;
}
@Override
public void operation(String name) {
System.out.printf("[类型 (内在状态)] - [%s] - [名字 (外在状态)] - [%s]\n", type, name);
}
@Override
public String getType() {
return type;
}
}
// 享元工厂类
class FlyweightFactory {
private static final Map<String, Flyweight> FLYWEIGHT_MAP = new HashMap<>();// 享元池,用来存储享元对象
public static Flyweight getFlyweight(String type) {
if (FLYWEIGHT_MAP.containsKey(type)) {// 如果在享元池中存在对象,则直接获取
return FLYWEIGHT_MAP.get(type);
} else {// 在响应池不存在,则新创建对象,并放入到享元池
ConcreteFlyweight flyweight = new ConcreteFlyweight(type);
FLYWEIGHT_MAP.put(type, flyweight);
return flyweight;
}
}
}
public class Client {
public static void main(String[] args) {
Flyweight fw0 = FlyweightFactory.getFlyweight("a");
Flyweight fw1 = FlyweightFactory.getFlyweight("b");
Flyweight fw2 = FlyweightFactory.getFlyweight("a");
Flyweight fw3 = FlyweightFactory.getFlyweight("b");
fw1.operation("abc");
System.out.printf("[结果 (对象对比)] - [%s]\n", fw0 == fw2);
System.out.printf("[结果 (内在状态)] - [%s]\n", fw1.getType());
}
}
观察以上代码运行结果,我们可以发现:如果对象已经存在于享元池中,则不会再创建该对象了,而是共用享元池中内部数据一致的对象。这样就减少了对象的创建,同时也节省了同样内部数据的对象所占用的内存空间。
享元模式在实际开发中的应用也非常广泛。例如 Java 的 String 字符串,在一些字符串常量中,会共享常量池中字符串对象,从而减少重复创建相同值对象,占用内存空间
还有,在日常开发中的应用。例如,线程池就是享元模式的一种实现;将商品存储在应用服务的缓存中,那么每当用户获取商品信息时,则不需要每次都从 redis 缓存或者数据库中获取商品信息,并在内存中重复创建商品信息了。
29.生产者消费者模式:电商库存设计优化
Object 的 wait/notify/notifyAll 实现生产者消费者
这种方式是基于 Object 的 wait/notify/notifyAll 与对象监视器(Monitor)实现线程间的等待和通知。
这种方式实现的生产者消费者模式是基于内核来实现的,有可能会导致大量的上下文切换,所以性能并不是最理想的。
Lock 中 Condition 的 await/signal/signalAll 实现生产者消费者
相对 Object 类提供的 wait/notify/notifyAll 方法实现的生产者消费者模式,我更推荐使用 java.util.concurrent 包提供的 Lock && Condition 实现的生产者消费者模式。
在接口 Condition 类中定义了 await/signal/signalAll 方法,其作用与 Object 的 wait/notify/notifyAll 方法类似,该接口类与显示锁 Lock 配合,实现对线程的阻塞和唤醒操作。
显示锁 ReentrantLock 或 ReentrantReadWriteLock 都是基于 AQS 实现的,而在 AQS 中有一个内部类 ConditionObject 实现了 Condition 接口。
我们知道 AQS 中存在一个同步队列(CLH 队列),当一个线程没有获取到锁时就会进入到同步队列中进行阻塞,如果被唤醒后获取到锁,则移除同步队列。
除此之外,AQS 中还存在一个条件队列,通过 addWaiter 方法,可以将 await() 方法调用的线程放入到条件队列中,线程进入等待状态。当调用 signal 以及 signalAll 方法后,线程将会被唤醒,并从条件队列中删除,之后进入到同步队列中。条件队列是通过一个单向链表实现的,所以 Condition 支持多个等待队列。
由上可知,Lock 中 Condition 的 await/signal/signalAll 实现的生产者消费者模式,是基于 Java 代码层实现的,所以在性能和扩展性方面都更有优势。
BlockingQueue 实现生产者消费者
相对前两种实现方式,BlockingQueue 实现是最简单明了的,也是最容易理解的。
因为 BlockingQueue 是线程安全的,且从队列中获取或者移除元素时,如果队列为空,获取或移除操作则需要等待,直到队列不为空;同时,如果向队列中添加元素,假设此时队列无可用空间,添加操作也需要等待。所以 BlockingQueue 非常适合用来实现生产者消费者模式。
生产者消费者优化电商库存设计
电商系统中经常会有抢购活动,在这类促销活动中,抢购商品的库存实际是存在库存表中的。为了提高抢购性能,我们通常会将库存存放在缓存中,通过缓存中的库存来实现库存的精确扣减。在提交订单并付款之后,我们还需要再去扣除数据库中的库存。如果遇到瞬时高并发,我们还都去操作数据库的话,那么在单表单库的情况下,数据库就很可能会出现性能瓶颈。
而我们库存表如果要实现分库分表,势必会增加业务的复杂度。试想一个商品的库存分别在不同库的表中,我们在扣除库存时,又该如何判断去哪个库中扣除呢?
如果随意扣除表中库存,那么就会出现有些表已经扣完了,有些表中还有库存的情况,这样的操作显然是不合理的,此时就需要额外增加逻辑判断来解决问题。
在不分库分表的情况下,为了提高订单中扣除库存业务的性能以及吞吐量,我们就可以采用生产者消费者模式来实现系统的性能优化。
创建订单等于生产者,存放订单的队列则是缓冲容器,而从队列中消费订单则是数据库扣除库存操作。其中存放订单的队列可以极大限度地缓冲高并发给数据库带来的压力。
我们还可以基于消息队列来实现生产者消费者模式,如今 RabbitMQ、RocketMQ 都实现了事务,我们只需要将订单通过事务提交到 MQ 中,扣除库存的消费方只需要通过消费 MQ 来逐步操作数据库即可。
30. 装饰器模式:如何优化电商系统中复杂的商品价格策略?
装饰器模式包括了以下几个角色:接口、具体对象、装饰类、具体装饰类。
优化电商系统中的商品价格策略
相信你一定不陌生,购买商品时经常会用到的限时折扣、红包、抵扣券以及特殊抵扣金等,种类很多,如果换到开发视角,实现起来就更复杂了。
例如,每逢双十一,为了加大商城的优惠力度,开发往往要设计红包 + 限时折扣或红包 + 抵扣券等组合来实现多重优惠。而在平时,由于某些特殊原因,商家还会赠送特殊抵扣券给购买用户,而特殊抵扣券 + 各种优惠又是另一种组合方式。
要实现以上这类组合优惠的功能,最快、最普遍的实现方式就是通过大量 if-else 的方式来实现。但这种方式包含了大量的逻辑判断,致使其他开发人员很难读懂业务, 并且一旦有新的优惠策略或者价格组合策略出现,就需要修改代码逻辑。
这时,刚刚介绍的装饰器模式就很适合用在这里,其相互独立、自由组合以及方便动态扩展功能的特性,可以很好地解决 if-else 方式的弊端。下面我们就用装饰器模式动手实现一套商品价格策略的优化方案。
首先,我们先建立订单和商品的属性类,在本次案例中,为了保证简洁性,我只建立了几个关键字段。以下几个重要属性关系为,主订单包含若干详细订单,详细订单中记录了商品信息,商品信息中包含了促销类型信息,一个商品可以包含多个促销类型(本案例只讨论单个促销和组合促销):
通常,装饰器模式用于扩展一个类的功能,且支持动态添加和删除类的功能。在装饰器模式中,装饰类和被装饰类都只关心自身的业务,不相互干扰,真正实现了解耦。
32. MySQL调优之SQL语句:如何写出高性能SQL语句?
慢 SQL 语句的几种常见诱因
1. 无索引、索引失效导致慢查询
如果在一张几千万数据的表中以一个没有索引的列作为查询条件,大部分情况下查询会非常耗时,这种查询毫无疑问是一个慢 SQL 查询。所以对于大数据量的查询,我们需要建立适合的索引来优化查询。
虽然我们很多时候建立了索引,但在一些特定的场景下,索引还有可能会失效,所以索引失效也是导致慢查询的主要原因之一
2. 锁等待
我们常用的存储引擎有 InnoDB 和 MyISAM,前者支持行锁和表锁,后者只支持表锁。
如果数据库操作是基于表锁实现的,试想下,如果一张订单表在更新时,需要锁住整张表,那么其它大量数据库操作(包括查询)都将处于等待状态,这将严重影响到系统的并发性能。
这时,InnoDB 存储引擎支持的行锁更适合高并发场景。但在使用 InnoDB 存储引擎时,我们要特别注意行锁升级为表锁的可能。在批量更新操作时,行锁就很可能会升级为表锁。
MySQL 认为如果对一张表使用大量行锁,会导致事务执行效率下降,从而可能造成其它事务长时间锁等待和更多的锁冲突问题发生,致使性能严重下降,所以 MySQL 会将行锁升级为表锁。还有,行锁是基于索引加的锁,如果我们在更新操作时,条件索引失效,那么行锁也会升级为表锁。
因此,基于表锁的数据库操作,会导致 SQL 阻塞等待,从而影响执行速度。在一些更新操作(insert\update\delete)大于或等于读操作的情况下,MySQL 不建议使用 MyISAM 存储引擎。
除了锁升级之外,行锁相对表锁来说,虽然粒度更细,并发能力提升了,但也带来了新的问题,那就是死锁。因此,在使用行锁时,我们要注意避免死锁。
3. 不恰当的 SQL 语句
使用不恰当的 SQL 语句也是慢 SQL 最常见的诱因之一。例如,习惯使用 <SELECT >,<SELECT COUNT()> SQL 语句,在大数据表中使用 <LIMIT M,N> 分页查询,以及对非索引字段进行排序等等。
通过 EXPLAIN 分析 SQL 执行计划
- id:每个执行计划都有一个 id,如果是一个联合查询,这里还将有多个 id。
- select_type:表示 SELECT 查询类型,常见的有 SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。
- table:当前执行计划查询的表,如果给表起别名了,则显示别名信息。
- partitions:访问的分区表信息。
- type:表示从表中查询到行所执行的方式,查询方式是 SQL 优化中一个很重要的指标,结果值从好到差依次是:system > const > eq_ref > ref > range > index > ALL。
- system/const:表中只有一行数据匹配,此时根据索引查询一次就能找到对应的数据。如果是 B + 树索引,我们知道此时索引构造成了多个层级的树,当查询的索引在树的底层时,查询效率就越低。const 表示此时索引在第一层,只需访问一层便能得到数据。
- eq_ref:使用唯一索引扫描,常见于多表连接中使用主键和唯一索引作为关联条件。
- ref:非唯一索引扫描,还可见于唯一索引最左原则匹配扫描。
- range:索引范围扫描,比如,<,>,between 等操作。
- index:索引全表扫描,此时遍历整个索引树。
- ALL:表示全表扫描,需要遍历全表来找到对应的行。
- possible_keys:可能使用到的索引。
- key:实际使用到的索引。
- key_len:当前使用的索引的长度。
- ref:关联 id 等信息。
- rows:查找到记录所扫描的行数。
- filtered:查找到所需记录占总扫描记录数的比例。
- Extra:额外的信息。
通过 Show Profile 分析 SQL 执行性能
上述通过 EXPLAIN 分析执行计划,仅仅是停留在分析 SQL 的外部的执行情况,如果我们想要深入到 MySQL 内核中,从执行线程的状态和时间来分析的话,这个时候我们就可以选择 Profile。
Profile 除了可以分析执行线程的状态和时间,还支持进一步选择 ALL、CPU、MEMORY、BLOCK IO、CONTEXT SWITCHES 等类型来查询 SQL 语句在不同系统资源上所消耗的时间。以下是相关命令的注释:
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type 参数:
| ALL:显示所有开销信息
| BLOCK IO:阻塞的输入输出次数
| CONTEXT SWITCHES:上下文切换相关开销信息
| CPU:显示 CPU 的相关开销信息
| IPC:接收和发送消息的相关开销信息
| MEMORY :显示内存相关的开销,目前无用
| PAGE FAULTS :显示页面错误相关开销信息
| SOURCE :列出相应操作对应的函数名及其在源码中的调用位置 (行数)
| SWAPS:显示 swap 交换次数的相关开销信息
Show Profiles 只显示最近发给服务器的 SQL 语句,默认情况下是记录最近已执行的 15 条记录,我们可以重新设置 profiling_history_size 增大该存储记录,最大值为 100。
获取到 Query_ID 之后,我们再通过 Show Profile for Query ID 语句,就能够查看到对应 Query_ID 的 SQL 语句在执行过程中线程的每个状态所消耗的时间了。
优化分页查询
通常我们是使用 <LIMIT M,N> + 合适的 order by 来实现分页查询,这种实现方式在没有任何索引条件支持的情况下,需要做大量的文件排序操作(file sort),性能将会非常得糟糕。如果有对应的索引,通常刚开始的分页查询效率会比较理想,但越往后,分页查询的性能就越差。
这是因为我们在使用 LIMIT 的时候,偏移量 M 在分页越靠后的时候,值就越大,数据库检索的数据也就越多。例如 LIMIT 10000,10 这样的查询,数据库需要查询 10010 条记录,最后返回 10 条记录。也就是说将会有 10000 条记录被查询出来没有被使用到。
select * from demo.order order by order_no limit 10000, 20;
以上分页查询的问题在于,我们查询获取的 10020 行数据结果都返回给我们了,我们能否先查询出所需要的 20 行数据中的最小 ID 值,然后通过偏移量返回所需要的 20 行数据给我们呢?我们可以通过索引覆盖扫描,使用子查询的方式来实现分页查询:
select * from demo.order where id> (select id from demo.order order by order_no limit 10000, 1) limit 20;
优化 SELECT COUNT(*)
COUNT() 是一个聚合函数,主要用来统计行数,有时候也用来统计某一列的行数量(不统计 NULL 值的行)。我们平时最常用的就是 COUNT(*) 和 COUNT(1) 这两种方式了,其实两者没有明显的区别,在拥有主键的情况下,它们都是利用主键列实现了行数的统计。
但 COUNT() 函数在 MyISAM 和 InnoDB 存储引擎所执行的原理是不一样的,通常在没有任何查询条件下的 COUNT(*),MyISAM 的查询速度要明显快于 InnoDB。
这是因为 MyISAM 存储引擎记录的是整个表的行数,在 COUNT(*) 查询操作时无需遍历表计算,直接获取该值即可。而在 InnoDB 存储引擎中就需要扫描表来统计具体的行数。而当带上 where 条件语句之后,MyISAM 跟 InnoDB 就没有区别了,它们都需要扫描表来进行行数的统计。
使用近似值
有时候某些业务场景并不需要返回一个精确的 COUNT 值,此时我们可以使用近似值来代替。我们可以使用 EXPLAIN 对表进行估算,要知道,执行 EXPLAIN 并不会真正去执行查询,而是返回一个估算的近似值。
增加汇总统计
如果需要一个精确的 COUNT 值,我们可以额外新增一个汇总统计表或者缓存字段来统计需要的 COUNT 值,这种方式在新增和删除时有一定的成本,但却可以大大提升 COUNT() 的性能。
优化 SELECT *
MySQL 常用的存储引擎有 MyISAM 和 InnoDB,其中 InnoDB 在默认创建主键时会创建主键索引,而主键索引属于聚族索引,即在存储数据时,索引是基于 B + 树构成的,具体的行数据则存储在叶子节点。
而 MyISAM 默认创建的主键索引、二级索引以及 InnoDB 的二级索引都属于非聚族索引,即在存储数据时,索引是基于 B + 树构成的,而叶子节点存储的是主键值。
假设我们的订单表是基于 InnoDB 存储引擎创建的,且存在 order_no、status 两列组成的组合索引。此时,我们需要根据订单号查询一张订单表的 status,如果我们使用 select * from order where order_no='xxx’来查询,则先会查询组合索引,通过组合索引获取到主键 ID,再通过主键 ID 去主键索引中获取对应行所有列的值。
如果我们使用 select order_no, status from order where order_no='xxx’来查询,则只会查询组合索引,通过组合索引获取到对应的 order_no 和 status 的值。
在开发中,我们要尽量写出高性能的 SQL 语句,但也无法避免一些慢 SQL 语句的出现,或因为疏漏,或因为实际生产环境与开发环境有所区别,这些都是诱因。面对这种情况,我们可以打开慢 SQL 配置项,记录下都有哪些 SQL 超过了预期的最大执行时间。首先,我们可以通过以下命令行查询是否开启了记录慢 SQL 的功能,以及最大的执行时间是多少:
Show variables like 'slow_query%';
Show variables like 'long_query_time';
如果没有开启,我们可以通过以下设置来开启:
set global slow_query_log='ON'; // 开启慢 SQL 日志
set global slow_query_log_file='/var/lib/mysql/test-slow.log';// 记录日志地址
set global long_query_time=1;// 最大执行时间
除此之外,很多数据库连接池中间件也有分析慢 SQL 的功能。总之,我们要在编程中避免低性能的 SQL 操作出现,除了要具备一些常用的 SQL 优化技巧之外,还要充分利用一些 SQL 工具,实现 SQL 性能分析与监控。
假设有一张订单表 order,主要包含了主键订单编码 order_no、订单状态 status、提交时间 create_time 等列,并且创建了 status 列索引和 create_time 列索引。此时通过创建时间降序获取状态为 1 的订单编码,以下是具体实现代码:
select order_no from order where status =1 order by create_time desc
status和create_time单独建索引,在查询时只会遍历status索引对数据进行过滤,不会用到create_time列索引,将符合条件的数据返回到server层,在server对数据通过快排算法进行排序,Extra列会出现file sort,应该建立联合索引。
33 MySQL调优之事务:高并发场景下的数据库事务调优
并发事务带来的问题
1. 数据丢失

2. 脏读

3. 不可重复读

4. 幻读

事务隔离解决并发问题
以上 4 个并发事务带来的问题,其中,数据丢失可以基于数据库中的悲观锁来避免发生,即在查询时通过在事务中使用 select xx for update 语句来实现一个排他锁,保证在该事务结束之前其他事务无法更新该数据。
当然,我们也可以基于乐观锁来避免,即将某一字段作为版本号,如果更新时的版本号跟之前的版本一致,则更新,否则更新失败。剩下 3 个问题,其实是数据库读一致性造成的,需要数据库提供一定的事务隔离机制来解决。
我们通过加锁的方式,可以实现不同的事务隔离机制。在了解事务隔离机制之前,我们不妨先来了解下 MySQL 都有哪些锁机制。
InnoDB 实现了两种类型的锁机制:共享锁(S)和排他锁(X)。共享锁允许一个事务读数据,不允许修改数据,如果其他事务要再对该行加锁,只能加共享锁;排他锁是修改数据时加的锁,可以读取和修改数据,一旦一个事务对该行数据加锁,其他事务将不能再对该数据加任务锁。
在操作数据的事务中,不同的锁机制会产生以下几种不同的事务隔离级别,不同的隔离级别分别可以解决并发事务产生的几个问题,对应如下:
未提交读(Read Uncommitted):在事务 A 读取数据时,事务 B 读取和修改数据加了共享锁。这种隔离级别,会导致脏读、不可重复读以及幻读。
已提交读(Read Committed):在事务 A 读取数据时增加了共享锁,一旦读取,立即释放锁,事务 B 读取修改数据时增加了行级排他锁,直到事务结束才释放锁。也就是说,事务 A 在读取数据时,事务 B 只能读取数据,不能修改。当事务 A 读取到数据后,事务 B 才能修改。这种隔离级别,可以避免脏读,但依然存在不可重复读以及幻读的问题。
可重复读(Repeatable Read):在事务 A 读取数据时增加了共享锁,事务结束,才释放锁,事务 B 读取修改数据时增加了行级排他锁,直到事务结束才释放锁。也就是说,事务 A 在没有结束事务时,事务 B 只能读取数据,不能修改。当事务 A 结束事务,事务 B 才能修改。这种隔离级别,可以避免脏读、不可重复读,但依然存在幻读的问题。
可序列化(Serializable):在事务 A 读取数据时增加了共享锁,事务结束,才释放锁,事务 B 读取修改数据时增加了表级排他锁,直到事务结束才释放锁。可序列化解决了脏读、不可重复读、幻读等问题,但隔离级别越来越高的同时,并发性会越来越低。
InnoDB 中的 RC 和 RR 隔离事务是基于多版本并发控制(MVVC)实现高性能事务。一旦数据被加上排他锁,其他事务将无法加入共享锁,且处于阻塞等待状态,如果一张表有大量的请求,这样的性能将是无法支持的。
MVVC 对普通的 Select 不加锁,如果读取的数据正在执行 Delete 或 Update 操作,这时读取操作不会等待排它锁的释放,而是直接利用 MVVC 读取该行的数据快照(数据快照是指在该行的之前版本的数据,而数据快照的版本是基于 undo 实现的,undo 是用来做事务回滚的,记录了回滚的不同版本的行记录)。MVVC 避免了对数据重复加锁的过程,大大提高了读操作的性能。
锁具体实现算法
我们知道,InnoDB 既实现了行锁,也实现了表锁。行锁是通过索引实现的,如果不通过索引条件检索数据,那么 InnoDB 将对表中所有的记录进行加锁,其实就是升级为表锁了。
行锁的具体实现算法有三种:record lock、gap lock 以及 next-key lock。record lock 是专门对索引项加锁;gap lock 是对索引项之间的间隙加锁;next-key lock 则是前面两种的组合,对索引项以其之间的间隙加锁。
只在可重复读或以上隔离级别下的特定操作才会取得 gap lock 或 next-key lock,在 Select 、Update 和 Delete 时,除了基于唯一索引的查询之外,其他索引查询时都会获取 gap lock 或 next-key lock,即锁住其扫描的范围。
优化高并发事务
- 结合业务场景,使用低级别事务隔离: 在高并发业务中,为了保证业务数据的一致性,操作数据库时往往会使用到不同级别的事务隔离。隔离级别越高,并发性能就越低。
- 避免行锁升级表锁: 行锁是通过索引实现的,如果不通过索引条件检索数据,行锁将会升级到表锁。我们知道,表锁是会严重影响到整张表的操作性能的,所以我们应该避免他。
- 控制事务的大小,减少锁定的资源量和锁定时间长度
其实 MySQL 的并发事务调优和 Java 的多线程编程调优非常类似,都是可以通过减小锁粒度和减少锁的持有时间进行调优。在 MySQL 的并发事务调优中,我们尽量在可以使用低事务隔离级别的业务场景中,避免使用高事务隔离级别。
在功能业务开发时,开发人员往往会为了追求开发速度,习惯使用默认的参数设置来实现业务功能。例如,在 service 方法中,你可能习惯默认使用 transaction,很少再手动变更事务隔离级别。但要知道,transaction 默认是 RR 事务隔离级别,在某些业务场景下,可能并不合适。因此,我们还是要结合具体的业务场景,进行考虑。
34.MySQL调优之索引:索引的失效与优化
MySQL 索引存储结构
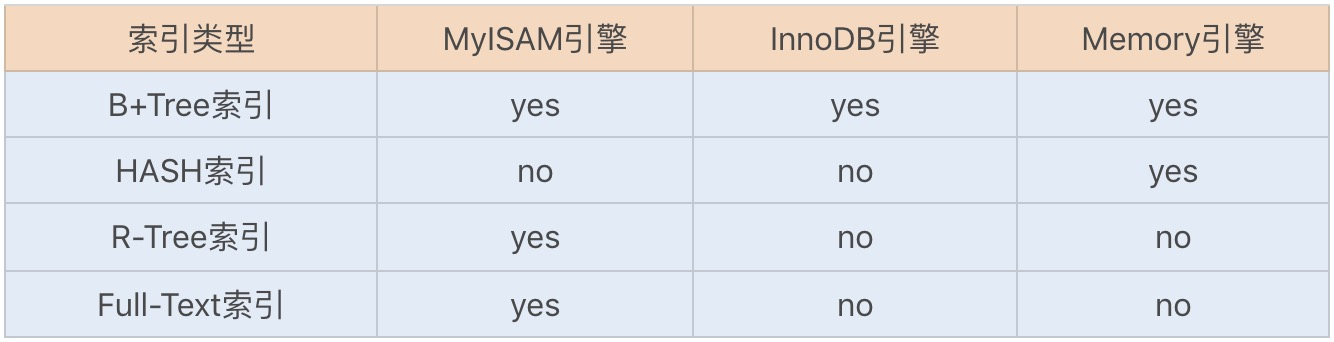
B+Tree 索引和 Hash 索引是我们比较常用的两个索引数据存储结构,B+Tree 索引是通过 B+ 树实现的,是有序排列存储,所以在排序和范围查找方面都比较有优势。
Hash 索引相对简单些,只有 Memory 存储引擎支持 Hash 索引。Hash 索引适合 key-value 键值对查询,无论表数据多大,查询数据的复杂度都是 O(1),且直接通过 Hash 索引查询的性能比其它索引都要优越。
在创建表时,无论使用 InnoDB 还是 MyISAM 存储引擎,默认都会创建一个主键索引,而创建的主键索引默认使用的是 B+Tree 索引。不过虽然这两个存储引擎都支持 B+Tree 索引,但它们在具体的数据存储结构方面却有所不同。
InnoDB 默认创建的主键索引是聚族索引(Clustered Index),其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚族索引。
覆盖索引优化查询
假设我们只需要查询商品的名称、价格信息,我们有什么方式来避免回表呢?我们可以建立一个组合索引,即商品编码、名称、价格作为一个组合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
从辅助索引中查询得到记录,而不需要通过聚族索引查询获得,MySQL 中将其称为覆盖索引。使用覆盖索引的好处很明显,我们不需要查询出包含整行记录的所有信息,因此可以减少大量的 I/O 操作。
通常在 InnoDB 中,除了查询部分字段可以使用覆盖索引来优化查询性能之外,统计数量也会用到。例如我们讲 SELECT COUNT(*) 时,如果不存在辅助索引,此时会通过查询聚族索引来统计行数,如果此时正好存在一个辅助索引,则会通过查询辅助索引来统计行数,减少 I/O 操作。
自增字段作主键优化查询
上面我们讲了 InnoDB 创建主键索引默认为聚族索引,数据被存放在了 B+ 树的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为不需要重新移动数据,因此这种插入数据的方法效率非常高。
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
因此,在使用 InnoDB 存储引擎时,如果没有特别的业务需求,建议使用自增字段作为主键。
前缀索引优化
前缀索引顾名思义就是使用某个字段中字符串的前几个字符建立索引,那我们为什么需要使用前缀来建立索引呢?
我们知道,索引文件是存储在磁盘中的,而磁盘中最小分配单元是页,通常一个页的默认大小为 16KB,假设我们建立的索引的每个索引值大小为 2KB,则在一个页中,我们能记录 8 个索引值,假设我们有 8000 行记录,则需要 1000 个页来存储索引。如果我们使用该索引查询数据,可能需要遍历大量页,这显然会降低查询效率。
减小索引字段大小,可以增加一个页中存储的索引项,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
不过,前缀索引是有一定的局限性的,例如 order by 就无法使用前缀索引,无法把前缀索引用作覆盖索引。
防止索引失效
当我们习惯建立索引来实现查询 SQL 的性能优化后,是不是就万事大吉了呢?当然不是,有时候我们看似使用到了索引,但实际上并没有被优化器选择使用。
对于 Hash 索引实现的列,如果使用到范围查询,那么该索引将无法被优化器使用到。也就是说 Memory 引擎实现的 Hash 索引只有在“=”的查询条件下,索引才会生效。我们将 order 表设置为 Memory 存储引擎,分析查询条件为 id<10 的 SQL,可以发现没有使用到索引。 >
如果是以 % 开头的 LIKE 查询将无法利用节点查询数据.
当我们在使用复合索引时,需要使用索引中的最左边的列进行查询,才能使用到复合索引,这也是我们经常听过的最左匹配原则。
如果查询条件中使用 or,且 or 的前后条件中有一个列没有索引,那么涉及的索引都不会被使用到。
总结
在大多数情况下,我们习惯使用默认的 InnoDB 作为表存储引擎。在使用 InnoDB 作为存储引擎时,创建的索引默认为 B+ 树数据结构,如果是主键索引,则属于聚族索引,非主键索引则属于辅助索引。基于主键查询可以直接获取到行信息,而基于辅助索引作为查询条件,则需要进行回表,然后再通过主键索引获取到数据。
如果只是查询一列或少部分列的信息,我们可以基于覆盖索引来避免回表。覆盖索引只需要读取索引,且由于索引是顺序存储,对于范围或排序查询来说,可以极大地极少磁盘 I/O 操作。
除了了解索引的具体实现和一些特性,我们还需要注意索引失效的情况发生。如果觉得这些规则太多,难以记住,我们就要养成经常检查 SQL 执行计划的习惯。
假设我们有一个订单表 order_detail,其中有主键 id、主订单 order_id、商品 sku 等字段,其中该表有主键索引、主订单 id 索引。
现在有一个查询订单详情的 SQL 如下,查询订单号范围在 5000~10000,请问该查询选择的索引是什么?有什么方式可以强制使用我们期望的索引呢?
select * from order_detail where order_id between 5000 and 10000;
答:因为order_id不是聚簇索引,所以叶子节点上只有主键id,需要回表查询才能返回所有字段;在返回的条数过多的时候,会有大量的回表操作,所以mysql一般判断在查询超过整个表20%的数据时,就会考虑使用聚族索引来查找数据,这种方式顺序读取数据的可能性要大于使用辅助索引的随机读。
在查询少量数据的情况下,使用辅助索引性能更加,而查询大量数据时,就未必了。
如果我们发现在查询一定量数据使用辅助索引要比主键索引快,而数据库又没有按照我们期望的去使用辅助索引,则我们可以通过子查询或force index来强制使用辅助索引。
35. 如何避免死锁?
死锁是如何产生的?
行锁的具体实现算法有三种:record lock、gap lock 以及 next-key lock。record lock 是专门对索引项加锁;gap lock 是对索引项之间的间隙加锁;next-key lock 则是前面两种的组合,对索引项以其之间的间隙加锁。
只在可重复读或以上隔离级别下的特定操作才会取得 gap lock 或 next-key lock,在 Select、Update 和 Delete 时,除了基于唯一索引的查询之外,其它索引查询时都会获取 gap lock 或 next-key lock,即锁住其扫描的范围。主键索引也属于唯一索引,所以主键索引是不会使用 gap lock 或 next-key lock。
在 MySQL 中,gap lock 默认是开启的,即 innodb_locks_unsafe_for_binlog 参数值是 disable 的,且 MySQL 中默认的是 RR 事务隔离级别。
当我们执行以下查询 SQL 时,由于 order_no 列为非唯一索引,此时又是 RR 事务隔离级别,所以 SELECT 的加锁类型为 gap lock,这里的 gap 范围是 (4,+∞)。
SELECT id FROM demo.order_record where order_no = 4 for update;
执行查询 SQL 语句获取的 gap lock 并不会导致阻塞,而当我们执行以下插入 SQL 时,会在插入间隙上再次获取插入意向锁。插入意向锁其实也是一种 gap 锁,它与 gap lock 是冲突的,所以当其它事务持有该间隙的 gap lock 时,需要等待其它事务释放 gap lock 之后,才能获取到插入意向锁。
以上事务 A 和事务 B 都持有间隙 (4,+∞)的 gap 锁,而接下来的插入操作为了获取到插入意向锁,都在等待对方事务的 gap 锁释放,于是就造成了循环等待,导致死锁。
INSERT INTO demo.order_record(order_no, status, create_date) VALUES (5, 1, ‘2019-07-13 10:57:03’);
我们可以通过以下锁的兼容矩阵图,来查看锁的兼容性:
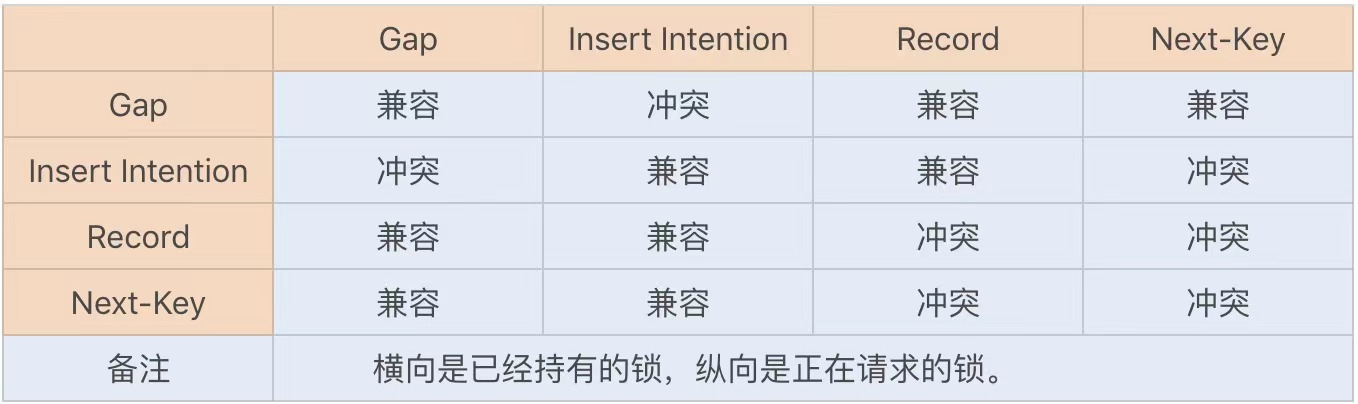
避免死锁的措施
知道了死锁问题源自哪儿,就可以找到合适的方法来避免它了。
避免死锁最直观的方法就是在两个事务相互等待时,当一个事务的等待时间超过设置的某一阈值,就对这个事务进行回滚,另一个事务就可以继续执行了。这种方法简单有效,在 InnoDB 中,参数 innodb_lock_wait_timeout 是用来设置超时时间的。
另外,我们还可以将 order_no 列设置为唯一索引列。虽然不能防止幻读,但我们可以利用它的唯一性来保证订单记录不重复创建,这种方式唯一的缺点就是当遇到重复创建订单时会抛出异常。
我们还可以使用其它的方式来代替数据库实现幂等性校验。例如,使用 Redis 以及 ZooKeeper 来实现,运行效率比数据库更佳。
其它常见的 SQL 死锁问题
这里再补充一些常见的 SQL 死锁问题,以便你遇到时也能知道其原因,从而顺利解决。
我们知道死锁的四个必要条件:互斥、占有且等待、不可强占用、循环等待。只要系统发生死锁,这些条件必然成立。所以在一些经常需要使用互斥共用一些资源,且有可能循环等待的业务场景中,要特别注意死锁问题。
接下来,我们再来了解一个出现死锁的场景。
我们讲过,InnoDB 存储引擎的主键索引为聚簇索引,其它索引为辅助索引。如果使用辅助索引来更新数据库,就需要使用聚簇索引来更新数据库字段。如果两个更新事务使用了不同的辅助索引,或一个使用了辅助索引,一个使用了聚簇索引,就都有可能导致锁资源的循环等待。由于本身两个事务是互斥,也就构成了以上死锁的四个必要条件了。
数据库发生死锁的概率并不是很大,一旦遇到了,就一定要彻查具体原因,尽快找出解决方案,老实说,过程不简单。我们只有先对 MySQL 的 InnoDB 存储引擎有足够的了解,才能剖析出造成死锁的具体原因。
解决死锁的最佳方式当然就是预防死锁的发生了,我们平时编程中,可以通过以下一些常规手段来预防死锁的发生:
- 在编程中尽量按照固定的顺序来处理数据库记录,假设有两个更新操作,分别更新两条相同的记录,但更新顺序不一样,有可能导致死锁;
- 在允许幻读和不可重复读的情况下,尽量使用 RC 事务隔离级别,可以避免 gap lock 导致的死锁问题;
- 更新表时,尽量使用主键更新;
- 避免长事务,尽量将长事务拆解,可以降低与其它事务发生冲突的概率;
- 设置锁等待超时参数,我们可以通过 innodb_lock_wait_timeout 设置合理的等待超时阈值,特别是在一些高并发的业务中,我们可以尽量将该值设置得小一些,避免大量事务等待,占用系统资源,造成严重的性能开销。
36.什么时候需要分表分库?
假设我们基于单表来实现,每天产生上百万的数据量,不到一个月的时间就要承受上亿的数据,这时单表的性能将会严重下降。因为 MySQL 在 InnoDB 存储引擎下创建的索引都是基于 B+ 树实现的,所以查询时的 I/O 次数很大程度取决于树的高度,随着 B+ 树的树高增高,I/O 次数增加,查询性能也就越差。
当我们面对一张海量数据的表时,通常有分区、NoSQL 存储、分表分库等优化方案。
分区的底层虽然也是基于分表的原理实现的,即有多个底层表实现,但分区依然是在单库下进行的,在一些需要提高并发的场景中的优化空间非常有限,且一个表最多只能支持 1024 个分区。面对日益增长的海量数据,优化存储能力有限。不过在一些非海量数据的大表中,我们可以考虑使用分区来优化表性能。
分区表是由多个相关的底层表实现的,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表,还是一个分区表的一部分。
而 NoSQL 存储是基于键值对存储,虽然查询性能非常高,但在一些方面仍然存在短板。例如,不是关系型数据库,不支持事务以及稳定性方面相对 RDBMS 差一些。虽然有些 NoSQL 数据库也实现了事务,宣传具有可靠的稳定性,但目前 NoSQL 还是主要用作辅助存储。
什么时候要分表分库?
在我看来,能不分表分库就不要分表分库。在单表的情况下,当业务正常时,我们使用单表即可,而当业务出现了性能瓶颈时,我们首先考虑用分区的方式来优化,如果分区优化之后仍然存在后遗症,此时我们再来考虑分表分库。
我们知道,如果在单表单库的情况下,当数据库表的数据量逐渐累积到一定的数量时(5000W 行或 100G 以上),操作数据库的性能会出现明显下降,即使我们使用索引优化或读写库分离,性能依然存在瓶颈。此时,如果每日数据增长量非常大,我们就应该考虑分表,避免单表数据量过大,造成数据库操作性能下降。
面对海量数据,除了单表的性能比较差以外,我们在单表单库的情况下,数据库连接数、磁盘 I/O 以及网络吞吐等资源都是有限的,并发能力也是有限的。所以,在一些大数据量且高并发的业务场景中,我们就需要考虑分表分库来提升数据库的并发处理能力,从而提升应用的整体性能。
如何分表分库?
通常,分表分库分为垂直切分和水平切分两种。
垂直分库是指根据业务来分库,不同的业务使用不同的数据库。例如,订单和消费券在抢购业务中都存在着高并发,如果同时使用一个库,会占用一定的连接数,所以我们可以将数据库分为订单库和促销活动库。
而垂直分表则是指根据一张表中的字段,将一张表划分为两张表,其规则就是将一些不经常使用的字段拆分到另一张表中。例如,一张订单详情表有一百多个字段,显然这张表的字段太多了,一方面不方便我们开发维护,另一方面还可能引起跨页问题。这时我们就可以拆分该表字段,解决上述两个问题。
水平分表则是将表中的某一列作为切分的条件,按照某种规则(Range 或 Hash 取模)来切分为更小的表。
水平分表只是在一个库中,如果存在连接数、I/O 读写以及网络吞吐等瓶颈,我们就需要考虑将水平切换的表分布到不同机器的库中,这就是水平分库分表了。
结合以上垂直切分和水平切分,我们一般可以将数据库分为:单库单表 - 单库多表 - 多库多表。在平时的业务开发中,我们应该优先考虑单库单表;如果数据量比较大,且热点数据比较集中、历史数据很少访问,我们可以考虑表分区;如果访问热点数据分散,基本上所有的数据都会访问到,我们可以考虑单库多表;如果并发量比较高、海量数据以及每日新增数据量巨大,我们可以考虑多库多表。
这里还需要注意一点,我刚刚强调过,能不分表分库,就不要分表分库。这是因为一旦分表,我们可能会涉及到多表的分页查询、多表的 JOIN 查询,从而增加业务的复杂度。而一旦分库了,除了跨库分页查询、跨库 JOIN 查询,还会存在跨库事务的问题。这些问题无疑会增加我们系统开发的复杂度。
分表分库之后面临的问题
- 分布式事务问题
- 跨节点 JOIN 查询问题
- 跨节点分页查询问题
- 全局主键 ID 问题
- 扩容问题
随着用户的订单量增加,根据用户 ID Hash 取模的分表中,数据量也在逐渐累积。此时,我们需要考虑动态增加表,一旦动态增加表了,就会涉及到数据迁移问题。
我们在最开始设计表数据量时,尽量使用 2 的倍数来设置表数量。当我们需要扩容时,也同样按照 2 的倍数来扩容,这种方式可以减少数据的迁移量。
37. 电商系统表设计优化案例分析
1. 不同商品类别存在差异,如何设计商品表结构?
我们知道,一个手机商品的详细信息跟一件衣服的详细信息差别很大,手机的 SKU 包括了颜色、运行内存、存储内存等,而一件衣服则包含了尺码、颜色。
如果我们需要将这些商品都存放在一张表中,要么就使用相同字段来存储不同的信息,要么就新增字段来维护各自的信息。前者会导致程序设计复杂化、表宽度大,从而减少磁盘单页存储行数,影响查询性能,且维护成本高;后者则会导致一张表中字段过多,如果有新的商品类型出现,又需要动态添加字段。
比较好的方式是通过一个公共表字段来存储一些具有共性的字段,创建单独的商品类型表,例如手机商品一个表、服饰商品一个表。但这种方式也有缺点,那就是可能会导致表非常多,查询商品信息的时候不够灵活,不好实现全文搜索。
这时候,我们可以基于一个公共表来存储商品的公共信息,同时结合搜索引擎,将商品详细信息存储到键值对数据库,例如 ElasticSearch、Solr 中。
2. 双十一购物车商品数量大增,购物车系统出现性能瓶颈怎么办?
在用户没有登录系统的情况下,我们是通过 cookie 来保存购物车的商品信息,而在用户登录系统之后,购物车的信息会保存到数据库中。
在双十一期间,大部分用户都会提前将商品加入到购物车中,在加入商品到购物车的这段操作中,由于时间比较长,操作会比较分散,所以对数据库的写入并不会造成太大的压力。但在购买时,由于多数属于抢购商品,用户对购物车的访问则会比较集中了,如果都去数据库中读取,那么数据库的压力就可想而知了。
此时我们应该考虑冷热数据方案来存储购物车的商品信息,用户一般都会首选最近放入购物车的商品,这些商品信息则是热数据,而较久之前放入购物车中的商品信息则是冷数据,我们需要提前将热数据存放在 Redis 缓存中,以便提高系统在活动期间的并发性能。例如,可以将购物车中近一个月的商品信息都存放到 Redis 中,且至少为一个分页的信息。
当在缓存中没有查找到购物车信息时,再去数据库中查询,这样就可以大大降低数据库的压力。
3. 订单表海量数据,如何设计订单表结构?
通常我们的订单表是系统数据累计最快的一张表,无论订单是否真正付款,只要订单提交了就会在订单表中创建订单。如果公司的业务发展非常迅速,那么订单表的分表分库就只是迟早的事儿了。
在没有分表之前,订单的主键 ID 都是自增的,并且关联了一些其它业务表。一旦要进行分表分库,就会存在主键 ID 与业务耦合的情况,而且分表后新自增 ID 与之前的 ID 也可能会发生冲突,后期做表升级的时候我们将会面临巨大的工作量。如果我们确定后期做表升级,建议提前使用 snowflake 来生成主键 ID。
如果订单表要实现水平分表,那我们基于哪个字段来实现分表呢?
通常我们是通过计算用户 ID 字段的 Hash 值来实现订单的分表,这种方式可以优化用户购买端对订单的操作性能。如果我们需要对订单表进行水平分库,那就还是基于用户 ID 字段来实现。
在分表分库之后,对于我们的后台订单管理系统来说,查询订单就是一个挑战了。通常后台都是根据订单状态、创建订单时间进行查询的,且需要支持分页查询以及部分字段的 JOIN 查询,如果需要在分表分库的情况下进行这些操作,无疑是一个巨大的挑战了。
对于 JOIN 查询,我们一般可以通过冗余一些不常修改的配置表来实现。例如,商品的基础信息,我们录入之后很少修改,可以在每个分库中冗余该表,如果字段信息比较少,我们可以直接在订单表中冗余这些字段。
而对于分页查询,通常我们建议冗余订单信息到大数据中。后台管理系统通过大数据来查询订单信息,用户在提交订单并且付款之后,后台将会同步这条订单到大数据。用户在 C 端修改或运营人员在后台修改订单时,会通过异步方式通知大数据更新该订单数据,这种方式可以解决分表分库后带来的分页查询问题。
4. 抢购业务,如何解决库存表的性能瓶颈?
在平时购买商品时,我们一般是直接去数据库检查、锁定库存,但如果是在促销活动期间抢购商品,我们还是直接去数据库检查、更新库存的话,面对高并发,系统无疑会产生性能瓶颈。
一般我们会将促销活动的库存更新到缓存中,通过缓存来查询商品的实时库存,并且通过分布式锁来实现库存扣减、锁定库存。
5. 促销活动也存在抢购场景,如何设计表?
促销活动中的优惠券和红包交易,很多时候跟抢购活动有些类似。
在一些大型促销活动之前,我们一般都会定时发放各种商品的优惠券和红包,用户需要点击领取才能使用。所以在一定数量的优惠券和红包放出的同时,也会存在同一时间抢购这些优惠券和红包的情况,特别是一些热销商品。
我们可以参考库存的优化设计方式,使用缓存和分布式锁来查询、更新优惠券和红包的数量,通过缓存获取数量成功以后,再通过异步方式更新数据库中优惠券和红包的数量。
我们结合电商系统实战练习了如何进行表设计,可以总结为以下几个要点:
- 在字段比较复杂、易变动、不方便统一的情况下,建议使用键值对来代替关系数据库表存储;
- 在高并发情况下的查询操作,可以使用缓存代替数据库操作,提高并发性能;
- 数据量叠加比较快的表,需要考虑水平分表或分库,避免单表操作的性能瓶颈;
- 除此之外,我们应该通过一些优化,尽量避免比较复杂的 JOIN 查询操作,例如冗余一些字段,减少 JOIN 查询;创建一些中间表,减少 JOIN 查询。
38.数据库参数设置优化
我们知道,数据库主要是用来存取数据的,而存取数据涉及到了磁盘 I/O 的读写操作,所以数据库系统主要的性能瓶颈就是 I/O 读写的瓶颈了。MySQL 数据库为了减少磁盘 I/O 的读写操作,应用了大量内存管理来优化数据库操作,包括内存优化查询、排序以及写入操作。
也许你会想,我们把内存设置得越大越好,数据刷新到磁盘越快越好,不就对了吗?其实不然,内存设置过大,同样会带来新的问题。例如,InnoDB 中的数据和索引缓存,如果设置过大,就会引发 SWAP 页交换。还有数据写入到磁盘也不是越快越好,我们期望的是在高并发时,数据能均匀地写入到磁盘中,从而避免 I/O 性能瓶颈。
SWAP 页交换:SWAP 分区在系统的物理内存不够用的时候,就会把物理内存中的一部分空间释放出来,以供当前运行的程序使用。被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间的数据被临时保存到 SWAP 分区中,等到那些程序要运行时,再从 SWAP 分区中恢复保存的数据到内存中。
所以,这些参数的设置跟我们的应用服务特性以及服务器硬件有很大的关系。MySQL 是一个高定制化的数据库,我们可以根据需求来调整参数,定制性能最优的数据库。
MySQL 体系结构
我们一般可以将 MySQL 的结构分为四层,最上层为客户端连接器,主要包括了数据库连接、授权认证、安全管理等,该层引用了线程池,为接入的连接请求提高线程处理效率。
第二层是 Server 层,主要实现 SQL 的一些基础功能,包括 SQL 解析、优化、执行以及缓存等,其中与我们这一讲主要相关的就是缓存。
第三层包括了各种存储引擎,主要负责数据的存取,这一层涉及到的 Buffer 缓存,也和这一讲密切相关。
最下面一层是数据存储层,主要负责将数据存储在文件系统中,并完成与存储引擎的交互。
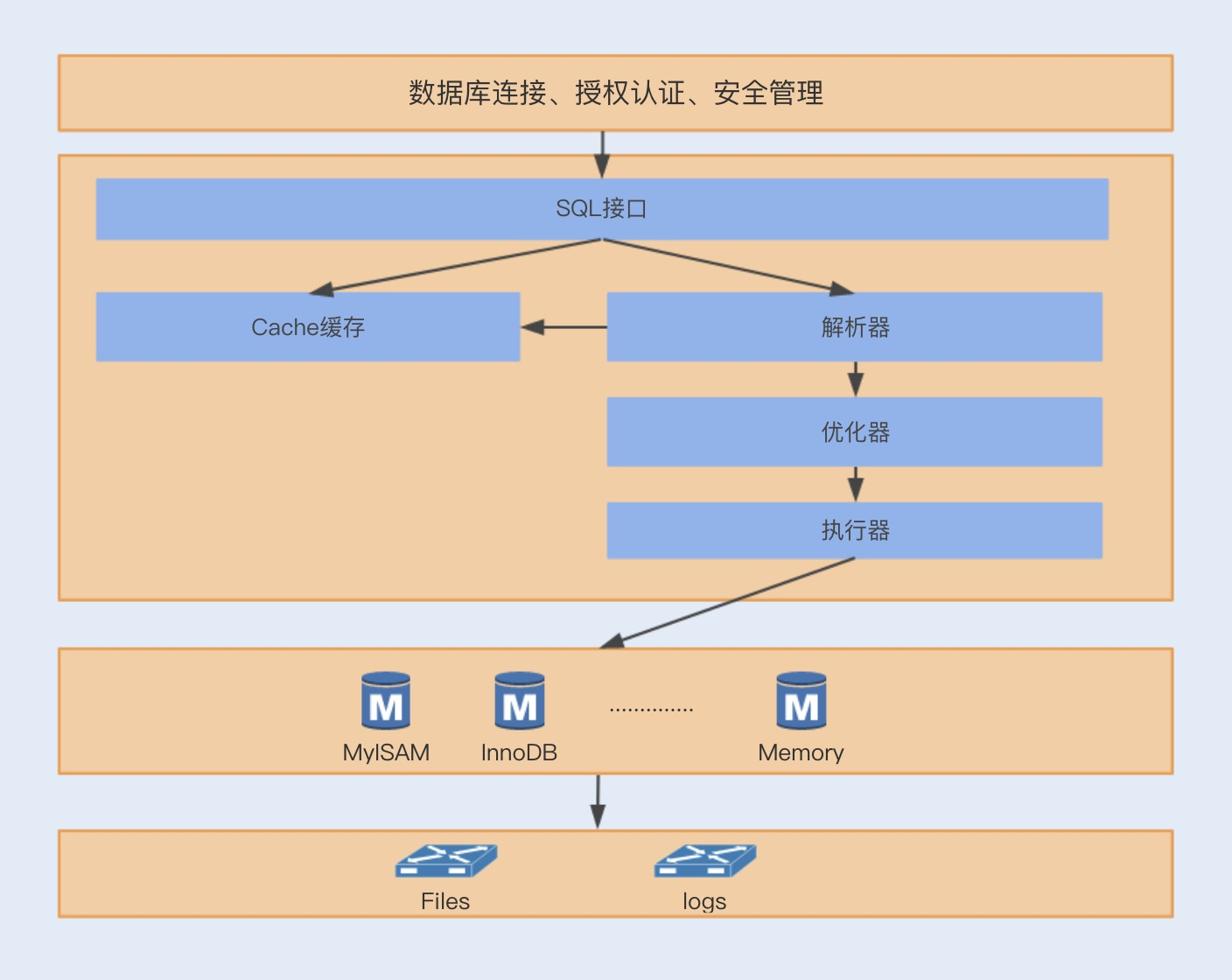
1. 查询语句
一个应用服务需要通过第一层的连接和授权认证,再将 SQL 请求发送至 SQL 接口。SQL 接口接收到请求之后,会先检查查询 SQL 是否命中 Cache 缓存中的数据,如果命中,则直接返回缓存中的结果;否则,需要进入解析器。
解析器主要对 SQL 进行语法以及词法分析,之后,便会进入到优化器中,优化器会生成多种执行计划方案,并选择最优方案执行。
确定了最优执行计划方案之后,执行器会检查连接用户是否有该表的执行权限,有则查看 Buffer 中是否存在该缓存,存在则获取锁,查询表数据;否则重新打开表文件,通过接口调用相应的存储引擎处理,这时存储引擎就会进入到存储文件系统中获取相应的数据,并返回结果集。
2. 更新语句
数据库更新 SQL 的执行流程其实跟查询 SQL 差不多,只不过执行更新操作的时候多了记录日志的步骤。在执行更新操作时 MySQL 会将操作的日志记录到 binlog(归档日志)中,这个步骤所有的存储引擎都有。而 InnoDB 除了要记录 binlog 之外,还需要多记录一个 redo log(重做日志)。
redo log 主要是为了解决 crash-safe 问题而引入的。我们知道,当数据库在存储数据时发生异常重启,我们需要保证存储的数据要么存储成功,要么存储失败,也就是不会出现数据丢失的情况,这就是 crash-safe 了。
我们在执行更新操作时,首先会查询相关的数据,之后通过执行器执行更新操作,并将执行结果写入到内存中,同时记录更新操作到 redo log 的缓存中,此时 redo log 中的记录状态为 prepare,并通知执行器更新完成,随时可以提交事务。执行器收到通知后会执行 binlog 的写入操作,此时的 binlog 是记录在缓存中的,写入成功后会调用引擎的提交事务接口,更新记录状态为 commit。之后,内存中的 redo log 以及 binlog 都会刷新到磁盘文件中。
内存调优
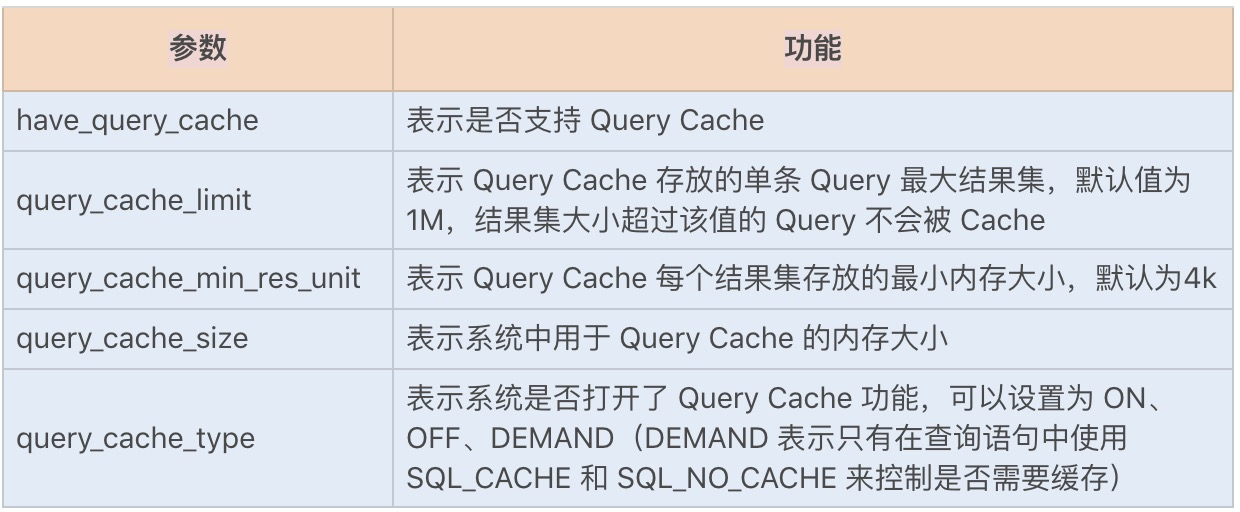
1. MyISAM 存储引擎参数设置调优
MyISAM 存储引擎使用 key buffer 缓存索引块,MyISAM 表的数据块则没有缓存,它是直接存储在磁盘文件中的。
我们可以通过 key_buffer_size 设置 key buffer 缓存的大小,而它的大小并不是越大越好。正如我前面所讲的,key buffer 缓存设置过大,实际应用却不大的话,就容易造成内存浪费,而且系统也容易发生 SWAP 页交换,一般我是建议将服务器内存中可用内存的 1/4 分配给 key buffer。
- InnoDB 存储引擎参数设置调优
InnoDB Buffer Pool(简称 IBP)是 InnoDB 存储引擎的一个缓冲池,与 MyISAM 存储引擎使用 key buffer 缓存不同,它不仅存储了表索引块,还存储了表数据。查询数据时,IBP 允许快速返回频繁访问的数据,而无需访问磁盘文件。InnoDB 表空间缓存越多,MySQL 访问物理磁盘的频率就越低,这表示查询响应时间更快,系统的整体性能也有所提高。
我们一般可以通过多个设置参数来调整 IBP,优化 InnoDB 表性能。
MySQL 数据库的参数设置非常多,今天我们仅仅是了解了与内存优化相关的参数设置。除了这些参数设置,我们还有一些常用的提高 MySQL 并发的相关参数设置,总结如下:

40.如何设计更优的分布式锁?
数据库实现分布式锁
select 的 for update 操作是基于间隙锁 gap lock 实现的,这是一种悲观锁的实现方式,所以存在阻塞问题。
因此在高并发情况下,当有大量的请求进来时,大部分的请求都会进行排队等待。为了保证数据库的稳定性,事务的超时时间往往又设置得很小,所以就会出现大量事务被中断的情况。
除了阻塞等待之外,因为订单没有删除操作,所以这张锁表的数据将会逐渐累积,我们需要设置另外一个线程,隔一段时间就去删除该表中的过期订单,这就增加了业务的复杂度。
除了这种幂等性校验的分布式锁,有一些单纯基于数据库实现的分布式锁代码块或对象,是需要在锁释放时,删除或修改数据的。如果在获取锁之后,锁一直没有获得释放,即数据没有被删除或修改,这将会引发死锁问题。
Zookeeper 实现分布式锁
除了数据库实现分布式锁的方式以外,我们还可以基于 Zookeeper 实现。Zookeeper 是一种提供“分布式服务协调“的中心化服务,正是 Zookeeper 的以下两个特性,分布式应用程序才可以基于它实现分布式锁功能。
顺序临时节点:Zookeeper 提供一个多层级的节点命名空间(节点称为 Znode),每个节点都用一个以斜杠(/)分隔的路径来表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。
节点类型可以分为持久节点(PERSISTENT )、临时节点(EPHEMERAL),每个节点还能被标记为有序性(SEQUENTIAL),一旦节点被标记为有序性,那么整个节点就具有顺序自增的特点。一般我们可以组合这几类节点来创建我们所需要的节点,例如,创建一个持久节点作为父节点,在父节点下面创建临时节点,并标记该临时节点为有序性。
Watch 机制:Zookeeper 还提供了另外一个重要的特性,Watcher(事件监听器)。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知给用户。
我们熟悉了 Zookeeper 的这两个特性之后,就可以看看 Zookeeper 是如何实现分布式锁的了。
首先,我们需要建立一个父节点,节点类型为持久节点(PERSISTENT) ,每当需要访问共享资源时,就会在父节点下建立相应的顺序子节点,节点类型为临时节点(EPHEMERAL),且标记为有序性(SEQUENTIAL),并且以临时节点名称 + 父节点名称 + 顺序号组成特定的名字。
在建立子节点后,对父节点下面的所有以临时节点名称 name 开头的子节点进行排序,判断刚刚建立的子节点顺序号是否是最小的节点,如果是最小节点,则获得锁。
如果不是最小节点,则阻塞等待锁,并且获得该节点的上一顺序节点,为其注册监听事件,等待节点对应的操作获得锁。
当调用完共享资源后,删除该节点,关闭 zk,进而可以触发监听事件,释放该锁。
以上实现的分布式锁是严格按照顺序访问的并发锁。一般我们还可以直接引用 Curator 框架来实现 Zookeeper 分布式锁。
Zookeeper 实现的分布式锁,例如相对数据库实现,有很多优点。Zookeeper 是集群实现,可以避免单点问题,且能保证每次操作都可以有效地释放锁,这是因为一旦应用服务挂掉了,临时节点会因为 session 连接断开而自动删除掉。
由于频繁地创建和删除结点,加上大量的 Watch 事件,对 Zookeeper 集群来说,压力非常大。且从性能上来说,其与接下来我要讲的 Redis 实现的分布式锁相比,还是存在一定的差距。
Redis 实现分布式锁
相对于前两种实现方式,基于 Redis 实现的分布式锁是最为复杂的,但性能是最佳的。
这种方式实现的分布式锁,是通过 setnx() 方法设置锁,如果 lockKey 存在,则返回失败,否则返回成功。设置成功之后,为了能在完成同步代码之后成功释放锁,方法中还需要使用 expire() 方法给 lockKey 值设置一个过期时间,确认 key 值删除,避免出现锁无法释放,导致下一个线程无法获取到锁,即死锁问题。
虽然 SETNX 方法保证了设置锁和过期时间的原子性,但如果我们设置的过期时间比较短,而执行业务时间比较长,就会存在锁代码块失效的问题。我们需要将过期时间设置得足够长,来保证以上问题不会出现。
这个方案是目前最优的分布式锁方案,但如果是在 Redis 集群环境下,依然存在问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Master 节点获取到锁后,在没有同步到其它节点时,Master 节点崩溃了,此时新的 Master 节点依然可以获取锁,所以多个应用服务可以同时获取到锁。
Redlock 算法
Redisson 由 Redis 官方推出,它是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务。Redisson 是基于 netty 通信框架实现的,所以支持非阻塞通信,性能相对于我们熟悉的 Jedis 会好一些。
Redisson 中实现了 Redis 分布式锁,且支持单点模式和集群模式。在集群模式下,Redisson 使用了 Redlock 算法,避免在 Master 节点崩溃切换到另外一个 Master 时,多个应用同时获得锁。我们可以通过一个应用服务获取分布式锁的流程,了解下 Redlock 算法的实现:
在不同的节点上使用单个实例获取锁的方式去获得锁,且每次获取锁都有超时时间,如果请求超时,则认为该节点不可用。当应用服务成功获取锁的 Redis 节点超过半数(N/2+1,N 为节点数) 时,并且获取锁消耗的实际时间不超过锁的过期时间,则获取锁成功。
一旦获取锁成功,就会重新计算释放锁的时间,该时间是由原来释放锁的时间减去获取锁所消耗的时间;而如果获取锁失败,客户端依然会释放获取锁成功的节点。
实现分布式锁的方式有很多,有最简单的数据库实现,还有 Zookeeper 多节点实现和缓存实现。我们可以分别对这三种实现方式进行性能压测,可以发现在同样的服务器配置下,Redis 的性能是最好的,Zookeeper 次之,数据库最差。
从实现方式和可靠性来说,Zookeeper 的实现方式简单,且基于分布式集群,可以避免单点问题,具有比较高的可靠性。因此,在对业务性能要求不是特别高的场景中,我建议使用 Zookeeper 实现的分布式锁。
42.电商系统的分布式事务调优
我们讲过,在单个数据库的情况下,数据事务操作具有 ACID 四个特性,但如果在一个事务中操作多个数据库,则无法使用数据库事务来保证一致性。
也就是说,当两个数据库操作数据时,可能存在一个数据库操作成功,而另一个数据库操作失败的情况,我们无法通过单个数据库事务来回滚两个数据操作。
而分布式事务就是为了解决在同一个事务下,不同节点的数据库操作数据不一致的问题。在一个事务操作请求多个服务或多个数据库节点时,要么所有请求成功,要么所有请求都失败回滚回去。通常,分布式事务的实现有多种方式,例如 XA 协议实现的二阶提交(2PC)、三阶提交 (3PC),以及 TCC 补偿性事务。
在了解 2PC 和 3PC 之前,我们有必要先来了解下 XA 协议。XA 协议是由 X/Open 组织提出的一个分布式事务处理规范,目前 MySQL 中只有 InnoDB 存储引擎支持 XA 协议。
XA 规范
DTP 规范中主要包含了 AP、RM、TM 三个部分,其中 AP 是应用程序,是事务发起和结束的地方;RM 是资源管理器,主要负责管理每个数据库的连接数据源;TM 是事务管理器,负责事务的全局管理,包括事务的生命周期管理和资源的分配协调等。
XA 则规范了 TM 与 RM 之间的通信接口,在 TM 与多个 RM 之间形成一个双向通信桥梁,从而在多个数据库资源下保证 ACID 四个特性。
这里强调一下,JTA 是基于 XA 规范实现的一套 Java 事务编程接口,是一种两阶段提交事务。我们可以通过源码简单了解下 JTA 实现的多数据源事务提交。
二阶提交和三阶提交
XA 规范实现的分布式事务属于二阶提交事务,顾名思义就是通过两个阶段来实现事务的提交。
在第一阶段,应用程序向事务管理器(TM)发起事务请求,而事务管理器则会分别向参与的各个资源管理器(RM)发送事务预处理请求(Prepare),此时这些资源管理器会打开本地数据库事务,然后开始执行数据库事务,但执行完成后并不会立刻提交事务,而是向事务管理器返回已就绪(Ready)或未就绪(Not Ready)状态。如果各个参与节点都返回状态了,就会进入第二阶段。
到了第二阶段,如果资源管理器返回的都是就绪状态,事务管理器则会向各个资源管理器发送提交(Commit)通知,资源管理器则会完成本地数据库的事务提交,最终返回提交结果给事务管理器。
在第二阶段中,如果任意资源管理器返回了未就绪状态,此时事务管理器会向所有资源管理器发送事务回滚(Rollback)通知,此时各个资源管理器就会回滚本地数据库事务,释放资源,并返回结果通知。
但事实上,二阶事务提交也存在一些缺陷。
第一,在整个流程中,我们会发现各个资源管理器节点存在阻塞,只有当所有的节点都准备完成之后,事务管理器才会发出进行全局事务提交的通知,这个过程如果很长,则会有很多节点长时间占用资源,从而影响整个节点的性能。
一旦资源管理器挂了,就会出现一直阻塞等待的情况。类似问题,我们可以通过设置事务超时时间来解决。
第二,仍然存在数据不一致的可能性,例如,在最后通知提交全局事务时,由于网络故障,部分节点有可能收不到通知,由于这部分节点没有提交事务,就会导致数据不一致的情况出现。
而三阶事务(3PC)的出现就是为了减少此类问题的发生。
3PC 把 2PC 的准备阶段分为了准备阶段和预处理阶段,在第一阶段只是询问各个资源节点是否可以执行事务,而在第二阶段,所有的节点反馈可以执行事务,才开始执行事务操作,最后在第三阶段执行提交或回滚操作。并且在事务管理器和资源管理器中都引入了超时机制,如果在第三阶段,资源节点一直无法收到来自资源管理器的提交或回滚请求,它就会在超时之后,继续提交事务。
所以 3PC 可以通过超时机制,避免管理器挂掉所造成的长时间阻塞问题,但其实这样还是无法解决在最后提交全局事务时,由于网络故障无法通知到一些节点的问题,特别是回滚通知,这样会导致事务等待超时从而默认提交。
事务补偿机制(TCC)
以上这种基于 XA 规范实现的事务提交,由于阻塞等性能问题,有着比较明显的低性能、低吞吐的特性。所以在抢购活动中使用该事务,很难满足系统的并发性能。
除了性能问题,JTA 只能解决同一服务下操作多数据源的分布式事务问题,换到微服务架构下,可能存在同一个事务操作,分别在不同服务上连接数据源,提交数据库操作。
而 TCC 正是为了解决以上问题而出现的一种分布式事务解决方案。TCC 采用最终一致性的方式实现了一种柔性分布式事务,与 XA 规范实现的二阶事务不同的是,TCC 的实现是基于服务层实现的一种二阶事务提交。
TCC 分为三个阶段,即 Try、Confirm、Cancel 三个阶段。
- Try 阶段:主要尝试执行业务,执行各个服务中的 Try 方法,主要包括预留操作;
- Confirm 阶段:确认 Try 中的各个方法执行成功,然后通过 TM 调用各个服务的 Confirm 方法,这个阶段是提交阶段;
- Cancel 阶段:当在 Try 阶段发现其中一个 Try 方法失败,例如预留资源失败、代码异常等,则会触发 TM 调用各个服务的 Cancel 方法,对全局事务进行回滚,取消执行业务。
以上执行只是保证 Try 阶段执行时成功或失败的提交和回滚操作,你肯定会想到,如果在 Confirm 和 Cancel 阶段出现异常情况,那 TCC 该如何处理呢?此时 TCC 会不停地重试调用失败的 Confirm 或 Cancel 方法,直到成功为止。
但 TCC 补偿性事务也有比较明显的缺点,那就是对业务的侵入性非常大。
首先,我们需要在业务设计的时候考虑预留资源;然后,我们需要编写大量业务性代码,例如 Try、Confirm、Cancel 方法;最后,我们还需要为每个方法考虑幂等性。这种事务的实现和维护成本非常高,但综合来看,这种实现是目前大家最常用的分布式事务解决方案。
业务无侵入方案——Seata(Fescar)
Seata 是阿里去年开源的一套分布式事务解决方案,开源一年多已经有一万多 star 了,可见受欢迎程度非常之高。
Seata 的基础建模和 DTP 模型类似,只不过前者是将事务管理器分得更细了,抽出一个事务协调器(Transaction Coordinator 简称 TC),主要维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。而 TM 则负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。如下图所示:
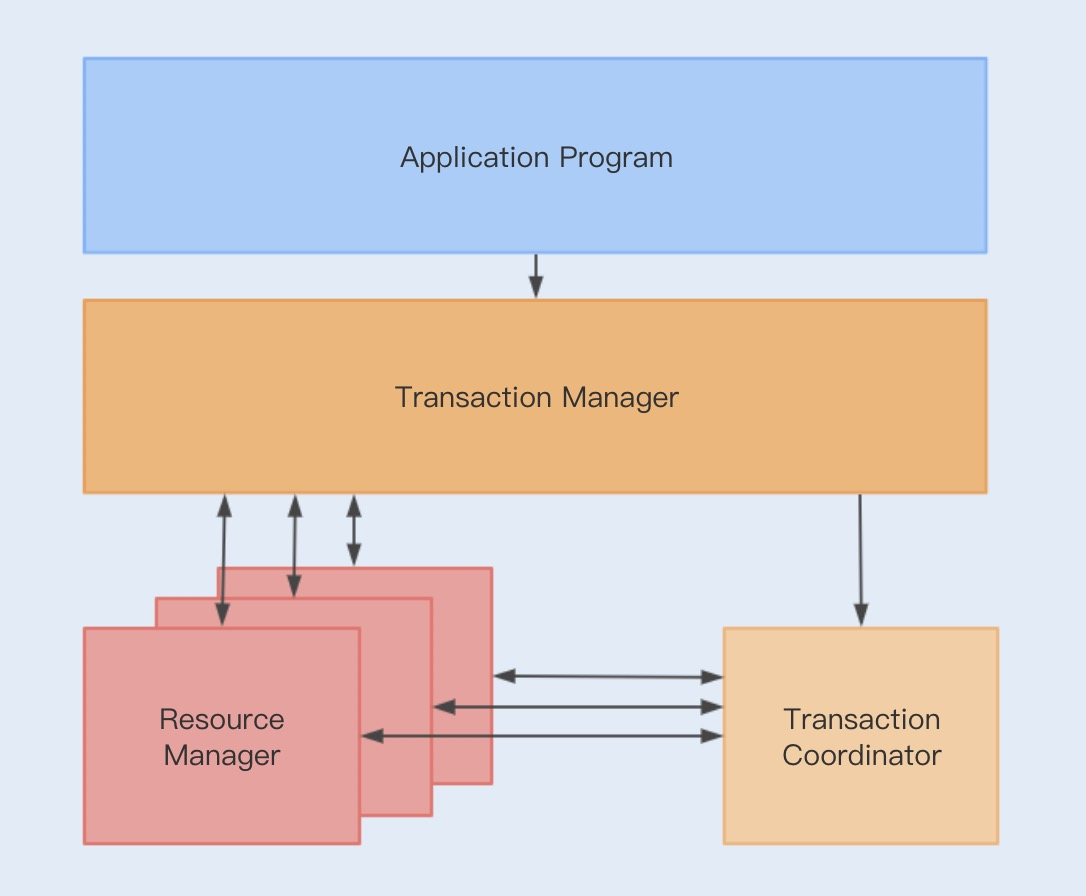
整个事务流程为:
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
- XID 在微服务调用链路的上下文中传播;
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
- TM 向 TC 发起针对 XID 的全局提交或回滚决议;
- TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
Seata 与其它分布式最大的区别在于,它在第一提交阶段就已经将各个事务操作 commit 了。Seata 认为在一个正常的业务下,各个服务提交事务的大概率是成功的,这种事务提交操作可以节约两个阶段持有锁的时间,从而提高整体的执行效率。
Seata 将 RM 提升到了服务层,通过 JDBC 数据源代理解析 SQL,把业务数据在更新前后的数据镜像组织成回滚日志,利用本地事务的 ACID 特性,将业务数据的更新和回滚日志的写入在同一个本地事务中提交。
如果 RM 决议要全局回滚,会通知 RM 进行回滚操作,通过 XID 找到对应的回滚日志记录,通过回滚记录生成反向更新 SQL,进行更新回滚操作。
Seata 设计通过事务协调器维护的全局写排它锁,来保证事务间的写隔离,而读写隔离级别则默认为未提交读的隔离级别。
在同服务多数据源操作不同数据库的情况下,我们可以使用基于 XA 规范实现的分布式事务,在 Spring 中有成熟的 JTA 框架实现了 XA 规范的二阶事务提交。事实上,二阶事务除了性能方面存在严重的阻塞问题之外,还有可能导致数据不一致,我们应该慎重考虑使用这种二阶事务提交。
在跨服务的分布式事务下,我们可以考虑基于 TCC 实现的分布式事务,常用的中间件有 TCC-Transaction。TCC 也是基于二阶事务提交原理实现的,但 TCC 的二阶事务提交是提到了服务层实现。TCC 方式虽然提高了分布式事务的整体性能,但也给业务层带来了非常大的工作量,对应用服务的侵入性非常强,但这是大多数公司目前所采用的分布式事务解决方案。
Seata 是一种高效的分布式事务解决方案,设计初衷就是解决分布式带来的性能问题以及侵入性问题。但目前 Seata 的稳定性有待验证,例如,在 TC 通知 RM 开始提交事务后,TC 与 RM 的连接断开了,或者 RM 与数据库的连接断开了,都不能保证事务的一致性。
43.如何使用缓存优化系统性能?
前端缓存技术
1. 本地缓存
平时使用拦截器(例如 Fiddler)或浏览器 Debug 时,我们经常会发现一些接口返回 304 状态码 + Not Modified 字符串,如下图中的极客时间 Web 首页。
如果我们对前端缓存技术不了解,就很容易对此感到困惑。浏览器常用的一种缓存就是这种基于 304 响应状态实现的本地缓存了,通常这种缓存被称为协商缓存。
协商缓存,顾名思义就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
一般协商缓存可以基于请求头部中的 If-Modified-Since 字段与返回头部中的 Last-Modified 字段实现,也可以基于请求头部中的 If-None-Match 字段与返回头部中的 ETag 字段来实现。
两种方式的实现原理是一样的,前者是基于时间实现的,后者是基于一个唯一标识实现的,相对来说后者可以更加准确地判断文件内容是否被修改,避免由于时间篡改导致的不可靠问题。
本地缓存中除了这种协商缓存,还有一种就是强缓存的实现。
强缓存指的是只要判断缓存没有过期,则直接使用浏览器的本地缓存。如下图中,返回的是 200 状态码,但在 size 项中标识的是 memory cache。
强缓存是利用 Expires 或者 Cache-Control 这两个 HTTP Response Header 实现的,它们都用来表示资源在客户端缓存的有效期。
2. 网关缓存
除了以上本地缓存,我们还可以在网关中设置缓存,也就是我们熟悉的 CDN。
CDN 缓存是通过不同地点的缓存节点缓存资源副本,当用户访问相应的资源时,会调用最近的 CDN 节点返回请求资源,这种方式常用于视频资源的缓存。
服务层缓存技术
前端缓存一般用于缓存一些不常修改的常量数据或一些资源文件,大部分接口请求的数据都缓存在了服务端,方便统一管理缓存数据。
服务端缓存的初衷是为了提升系统性能。例如,数据库由于并发查询压力过大,可以使用缓存减轻数据库压力;在后台管理中的一些报表计算类数据,每次请求都需要大量计算,消耗系统 CPU 资源,我们可以使用缓存来保存计算结果。
服务端的缓存也分为进程缓存和分布式缓存,在 Java 中进程缓存就是 JVM 实现的缓存,常见的有我们经常使用的容器类,ArrayList、ConcurrentHashMap 等,分布式缓存则是基于 Redis 实现的缓存。
1. 进程缓存
对于进程缓存,虽然数据的存取会更加高效,但 JVM 的堆内存数量是有限的,且在分布式环境下很难同步各个服务间的缓存更新,所以我们一般缓存一些数据量不大、更新频率较低的数据。
除了 Java 自带的容器可以实现进程缓存,我们还可以基于 Google 实现的一套内存缓存组件 Guava Cache 来实现。
Guava Cache 适用于高并发的多线程缓存,它和 ConcurrentHashMap 一样,都是基于分段锁实现的并发缓存。
Guava Cache 同时也实现了数据淘汰机制,当我们设置了缓存的最大值后,当存储的数据超过了最大值时,它就会使用 LRU 算法淘汰数据。
2. 分布式缓存
由于高并发对数据一致性的要求比较严格,我一般不建议使用 Ehcache 缓存有一致性要求的数据。对于分布式缓存,我们建议使用 Redis 来实现,Redis 相当于一个内存数据库,由于是纯内存操作,又是基于单线程串行实现,查询性能极高,读速度超过了 10W 次 / 秒。
Redis 除了高性能的特点之外,还支持不同类型的数据结构,常见的有 string、list、set、hash 等,还支持数据淘汰策略、数据持久化以及事务等。
数据库与缓存数据一致性问题
在查询缓存数据时,我们会先读取缓存,如果缓存中没有该数据,则会去数据库中查询,之后再放入到缓存中。
当我们的数据被缓存之后,一旦数据被修改(修改时也是删除缓存中的数据)或删除,我们就需要同时操作缓存和数据库。这时,就会存在一个数据不一致的问题。
所以,我们还是需要先做缓存删除操作,再去完成数据库操作。那我们又该如何避免高并发下,数据更新删除操作所带来的数据不一致的问题呢?
通常的解决方案是,如果我们需要使用一个线程安全队列来缓存更新或删除的数据,当 A 操作变更数据时,会先删除一个缓存数据,此时通过线程安全的方式将缓存数据放入到队列中,并通过一个线程进行数据库的数据删除操作。
当有另一个查询请求 B 进来时,如果发现缓存中没有该值,则会先去队列中查看该数据是否正在被更新或删除,如果队列中有该数据,则阻塞等待,直到 A 操作数据库成功之后,唤醒该阻塞线程,再去数据库中查询该数据。
但其实这种实现也存在很多缺陷,例如,可能存在读请求被长时间阻塞,高并发时低吞吐量等问题。所以我们在考虑缓存时,如果数据更新比较频繁且对数据有一定的一致性要求,我通常不建议使用缓存。
缓存穿透、缓存击穿、缓存雪崩
对于分布式缓存实现大数据的存储,除了数据不一致的问题以外,还有缓存穿透、缓存击穿、缓存雪崩等问题,我们平时实现缓存代码时,应该充分、全面地考虑这些问题。
缓存穿透是指大量查询没有命中缓存,直接去到数据库中查询,如果查询量比较大,会导致数据库的查询流量大,对数据库造成压力。
通常有两种解决方案,一种是将第一次查询的空值缓存起来,同时设置一个比较短的过期时间。但这种解决方案存在一个安全漏洞,就是当黑客利用大量没有缓存的 key 攻击系统时,缓存的内存会被占满溢出。
另一种则是使用布隆过滤算法(BloomFilter),该算法可以用于检查一个元素是否存在,返回结果有两种:可能存在或一定不存在。这种情况很适合用来解决故意攻击系统的缓存穿透问题,在最初缓存数据时也将 key 值缓存在布隆过滤器的 BitArray 中,当有 key 值查询时,对于一定不存在的 key 值,我们可以直接返回空值,对于可能存在的 key 值,我们会去缓存中查询,如果没有值,再去数据库中查询。
BloomFilter 的实现原理与 Redis 中的 BitMap 类似,首先初始化一个 m 长度的数组,并且每个 bit 初始化值都是 0,当插入一个元素时,会使用 n 个 hash 函数来计算出 n 个不同的值,分别代表所在数组的位置,然后再将这些位置的值设置为 1。
假设我们插入两个 key 值分别为 20,28 的元素,通过两次哈希函数取模后的值分别为 4,9 以及 14,19,因此 4,9 以及 14,19 都被设置为 1。
那为什么说 BloomFilter 返回的结果是可能存在和一定不存在呢?
假设我们查找一个元素 25,通过 n 次哈希函数取模后的值为 1,9,14。此时在 BitArray 中肯定是不存在的。而当我们查找一个元素 21 的时候,n 次哈希函数取模后的值为 9,14,此时会返回可能存在的结果,但实际上是不存在的。
BloomFilter 不允许删除任何元素的,为什么?假设以上 20,25,28 三个元素都存在于 BitArray 中,取模的位置值分别为 4,9、1,9,14 以及 14,19,如果我们要删除元素 25,此时需要将 1,9,14 的位置都置回 0,这样就影响 20,28 元素了。
因此,BloomFilter 是不允许删除任何元素的,这样会导致已经删除的元素依然返回可能存在的结果,也会影响 BloomFilter 判断的准确率,解决的方法则是重建一个 BitArray。
那什么缓存击穿呢?在高并发情况下,同时查询一个 key 时,key 值由于某种原因突然失效(设置过期时间或缓存服务宕机),就会导致同一时间,这些请求都去查询数据库了。这种情况经常出现在查询热点数据的场景中。通常我们会在查询数据库时,使用排斥锁来实现有序地请求数据库,减少数据库的并发压力。
缓存雪崩则与缓存击穿差不多,区别就是失效缓存的规模。雪崩一般是指发生大规模的缓存失效情况,例如,缓存的过期时间同一时间过期了,缓存服务宕机了。对于大量缓存的过期时间同一时间过期的问题,我们可以采用分散过期时间来解决;而针对缓存服务宕机的情况,我们可以采用分布式集群来实现缓存服务。
44.记一次双十一抢购性能瓶颈调优
抢购业务流程
在进行具体的性能问题讨论之前,我们不妨先来了解下一个常规的抢购业务流程,这样方便我们更好地理解一个抢购系统的性能瓶颈以及调优过程。
- 用户登录后会进入到商品详情页面,此时商品购买处于倒计时状态,购买按钮处于置灰状态。
- 当购买倒计时间结束后,用户点击购买商品,此时用户需要排队等待获取购买资格,如果没有获取到购买资格,抢购活动结束,反之,则进入提交页面。
- 用户完善订单信息,点击提交订单,此时校验库存,并创建订单,进入锁定库存状态,之后,用户支付订单款。
- 当用户支付成功后,第三方支付平台将产生支付回调,系统通过回调更新订单状态,并扣除数据库的实际库存,通知用户购买成功。
抢购系统中的性能瓶颈
1. 商品详情页面
如果你有过抢购商品的经验,相信你遇到过这样一种情况,在抢购马上到来的时候,商品详情页面几乎是无法打开的。
这是因为大部分用户在抢购开始之前,会一直疯狂刷新抢购商品页面,尤其是倒计时一分钟内,查看商品详情页面的请求量会猛增。此时如果商品详情页面没有做好,就很容易成为整个抢购系统中的第一个性能瓶颈。
类似这种问题,我们通常的做法是提前将整个抢购商品页面生成为一个静态页面,并 push 到 CDN 节点,并且在浏览器端缓存该页面的静态资源文件,通过 CDN 和浏览器本地缓存这两种缓存静态页面的方式来实现商品详情页面的优化。
2. 抢购倒计时
在商品详情页面中,存在一个抢购倒计时,这个倒计时是服务端时间的,初始化时间需要从服务端获取,并且在用户点击购买时,还需要服务端判断抢购时间是否已经到了。
如果商品详情每次刷新都去后端请求最新的时间,这无疑将会把整个后端服务拖垮。我们可以改成初始化时间从客户端获取,每隔一段时间主动去服务端刷新同步一次倒计时,这个时间段是随机时间,避免集中请求服务端。这种方式可以避免用户主动刷新服务端的同步时间接口。
3. 获取购买资格
可能你会好奇,在抢购中我们已经通过库存数量限制用户了,那为什么会出现一个获取购买资格的环节呢?
我们知道,进入订单详情页面后,需要填写相关的订单信息,例如收货地址、联系方式等,在这样一个过程中,很多用户可能还会犹豫,甚至放弃购买。如果把这个环节设定为一定能购买成功,那我们就只能让同等库存的用户进来,一旦用户放弃购买,这些商品可能无法再次被其他用户抢购,会大大降低商品的抢购销量。
增加购买资格的环节,选择让超过库存的用户量进来提交订单页面,这样就可以保证有足够提交订单的用户量,确保抢购活动中商品的销量最大化。
获取购买资格这步的并发量会非常大,还是基于分布式的,通常我们可以通过 Redis 分布式锁来控制购买资格的发放。
4. 提交订单
由于抢购入口的请求量会非常大,可能会占用大量带宽,为了不影响提交订单的请求,我建议将提交订单的子域名与抢购子域名区分开,分别绑定不同网络的服务器。
用户点击提交订单,需要先校验库存,库存足够时,用户先扣除缓存中的库存,再生成订单。如果校验库存和扣除库存都是基于数据库实现的,那么每次都去操作数据库,瞬时的并发量就会非常大,对数据库来说会存在一定的压力,从而会产生性能瓶颈。与获取购买资格一样,我们同样可以通过分布式锁来优化扣除消耗库存的设计。
由于我们已经缓存了库存,所以在提交订单时,库存的查询和冻结并不会给数据库带来性能瓶颈。但在这之后,还有一个订单的幂等校验,为了提高系统性能,我们同样可以使用分布式锁来优化。
而保存订单信息一般都是基于数据库表来实现的,在单表单库的情况下,碰到大量请求,特别是在瞬时高并发的情况下,磁盘 I/O、数据库请求连接数以及带宽等资源都可能会出现性能瓶颈。此时我们可以考虑对订单表进行分库分表,通常我们可以基于 userid 字段来进行 hash 取模,实现分库分表,从而提高系统的并发能力。
5. 支付回调业务操作
在用户支付订单完成之后,一般会有第三方支付平台回调我们的接口,更新订单状态。
除此之外,还可能存在扣减数据库库存的需求。如果我们的库存是基于缓存来实现查询和扣减,那提交订单时的扣除库存就只是扣除缓存中的库存,为了减少数据库的并发量,我们会在用户付款之后,在支付回调的时候去选择扣除数据库中的库存。
此外,还有订单购买成功的短信通知服务,一些商城还提供了累计积分的服务。
在支付回调之后,我们可以通过异步提交的方式,实现订单更新之外的其它业务处理,例如库存扣减、积分累计以及短信通知等。通常我们可以基于 MQ 实现业务的异步提交。
性能瓶颈调优
1. 限流实现优化
限流是我们常用的兜底策略,无论是倒计时请求接口,还是抢购入口,系统都应该对它们设置最大并发访问数量,防止超出预期的请求集中进入系统,导致系统异常。
通常我们是在网关层实现高并发请求接口的限流,如果我们使用了 Nginx 做反向代理的话,就可以在 Nginx 配置限流算法。Nginx 是基于漏桶算法实现的限流,这样做的好处是能够保证请求的实时处理速度。
2. 流量削峰
瞬间有大量请求进入到系统后台服务之后,首先是要通过 Redis 分布式锁获取购买资格,这个时候我们看到了大量的“JedisConnectionException Could not get connection from pool”异常。
这个异常是一个 Redis 连接异常,由于我们当时的 Redis 集群是基于哨兵模式部署的,哨兵模式部署的 Redis 也是一种主从模式,我们在写 Redis 的时候都是基于主库来实现的,在高并发操作一个 Redis 实例就很容易出现性能瓶颈。
你可能会想到使用集群分片的方式来实现,但对于分布式锁来说,集群分片的实现只会增加性能消耗,这是因为我们需要基于 Redission 的红锁算法实现,需要对集群的每个实例进行加锁。
后来我们使用 Redission 插件替换 Jedis 插件,由于 Jedis 的读写 I/O 操作还是阻塞式的,方法调用都是基于同步实现,而 Redission 底层是基于 Netty 框架实现的,读写 I/O 是非阻塞 I/O 操作,且方法调用是基于异步实现。
但在瞬时并发非常大的情况下,依然会出现类似问题,此时,我们可以考虑在分布式锁前面新增一个等待队列,减缓抢购出现的集中式请求,相当于一个流量削峰。当请求的 key 值放入到队列中,请求线程进入阻塞状态,当线程从队列中获取到请求线程的 key 值时,就会唤醒请求线程获取购买资格。
3. 数据丢失问题
无论是服务宕机,还是异步发送给 MQ,都存在请求数据丢失的可能。例如,当第三方支付回调系统时,写入订单成功了,此时通过异步来扣减库存和累计积分,如果应用服务刚好挂掉了,MQ 还没有存储到该消息,那即使我们重启服务,这条请求数据也将无法还原。
重试机制是还原丢失消息的一种解决方案。在以上的回调案例中,我们可以在写入订单时,同时在数据库写入一条异步消息状态,之后再返回第三方支付操作成功结果。在异步业务处理请求成功之后,更新该数据库表中的异步消息状态。
假设我们重启服务,那么系统就会在重启时去数据库中查询是否有未更新的异步消息,如果有,则重新生成 MQ 业务处理消息,供各个业务方消费处理丢失的请求数据。
减少抢购中操作数据库的次数,缩短抢购流程,是抢购系统设计和优化的核心点。
抢购系统的性能瓶颈主要是在数据库,即使我们对服务进行了横向扩容,当流量瞬间进来,数据库依然无法同时响应处理这么多的请求操作。我们可以对抢购业务表进行分库分表,通过提高数据库的处理能力,来提升系统的并发处理能力。
除此之外,我们还可以分散瞬时的高并发请求,流量削峰是最常用的方式,用一个队列,让请求排队等待,然后有序且有限地进入到后端服务,最终进行数据库操作。当我们的队列满了之后,可以将溢出的请求放弃,这就是限流了。通过限流和削峰,可以有效地保证系统不宕机,确保系统的稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号