

JVM虚拟机知识汇总
1. Java代码运行
Java 和 C++ 在运行方式上的区别
Java 代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至可以在网页中运行。当然,这些执行方式都离不开 JRE,也就是 Java 运行时环境。
C++:运行 C++ 代码则无需额外的运行时。我们往往把这些代码直接编译成 CPU 所能理解的代码格式,也就是机器码。
Java 虚拟机具体是怎样运行 Java 字节码的?
从硬件视角来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。
在 HotSpot 里面,上述翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。
前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
之所以要在虚拟机中运行,是因为它提供了可移植性。一旦 Java 代码被编译为 Java 字节码,便可以在不同平台上的 Java 虚拟机实现上运行。此外,虚拟机还提供了一个代码托管的环境,代替我们处理部分冗长而且容易出错的事务,例如内存管理。
Java 虚拟机将运行时内存区域划分为五个部分,分别为方法区、堆、PC 寄存器、Java 方法栈和本地方法栈。Java 程序编译而成的 class 文件,需要先加载至方法区中,方能在 Java 虚拟机中运行。
为了提高运行效率,标准 JDK 中的 HotSpot 虚拟机采用的是一种混合执行的策略。
它会解释执行 Java 字节码,然后会将其中反复执行的热点代码,以方法为单位进行即时编译,翻译成机器码后直接运行在底层硬件之上。
HotSpot 装载了多个不同的即时编译器,以便在编译时间和生成代码的执行效率之间做取舍。
2.Java的基本类型
Java 虚拟机的 boolean 类型
在 Java 语言规范中,boolean 类型的值只有两种可能,它们分别用符号“true”和“false”来表示。显然,这两个符号是不能被虚拟机直接使用的。
在 Java 虚拟机规范中,boolean 类型则被映射成 int 类型。具体来说,“true”被映射为整数 1,而“false”被映射为整数 0。这个编码规则约束了 Java 字节码的具体实现。
对于 Java 虚拟机来说,它看到的 boolean 类型,早已被映射为整数类型。因此,将原本声明为 boolean 类型的局部变量,赋值为除了 0、1 之外的整数值,在 Java 虚拟机看来是“合法”的。
Java 的基本类型
除了上面提到的 boolean 类型外,Java 的基本类型还包括整数类型 byte、short、char、int 和 long,以及浮点类型 float 和 double。
在这些基本类型中,boolean 和 char 是唯二的无符号类型。在不考虑违反规范的情况下,boolean 类型的取值范围是 0 或者 1。char 类型的取值范围则是 [0, 65535]。通常我们可以认定 char 类型的值为非负数。这种特性十分有用,比如说作为数组索引等。
我们能够将整数 2 存储到一个声明为 boolean 类型的局部变量中。那么,声明为 byte、char 以及 short 的局部变量,是否也能够存储超出它们取值范围的数值呢?
答案是可以的。而且,这些超出取值范围的数值同样会带来一些麻烦。比如说,声明为 char 类型的局部变量实际上有可能为负数。当然,在正常使用 Java 编译器的情况下,生成的字节码会遵守 Java 虚拟机规范对编译器的约束,因此你无须过分担心局部变量会超出它们的取值范围。
Java 的浮点类型采用 IEEE 754 浮点数格式。以 float 为例,浮点类型通常有两个 0,+0.0F 以及 -0.0F。
前者在 Java 里是 0,后者是符号位为 1、其他位均为 0 的浮点数,在内存中等同于十六进制整数 0x8000000(即 -0.0F 可通过 Float.intBitsToFloat(0x8000000) 求得)。尽管它们的内存数值不同,但是在 Java 中 +0.0F == -0.0F 会返回真。
在有了 +0.0F 和 -0.0F 这两个定义后,我们便可以定义浮点数中的正无穷及负无穷。正无穷就是任意正浮点数(不包括 +0.0F)除以 +0.0F 得到的值,而负无穷是任意正浮点数除以 -0.0F 得到的值。在 Java 中,正无穷和负无穷是有确切的值,在内存中分别等同于十六进制整数 0x7F800000 和 0xFF800000。
[0x7F800001, 0x7FFFFFFF] 和 [0xFF800001, 0xFFFFFFFF] 对应的都是 NaN。当然,一般我们计算得出的 NaN,比如说通过 +0.0F/+0.0F,在内存中应为 0x7FC00000。这个数值,我们称之为标准的 NaN,而其他的我们称之为不标准的 NaN。
NaN 有一个有趣的特性:除了“!=”始终返回 true 之外,所有其他比较结果都会返回 false。
举例来说,“NaN<1.0F”返回 false,而“NaN>=1.0F”同样返回 false。对于任意浮点数 f,不管它是 0 还是 NaN,“f!=NaN”始终会返回 true,而“f==NaN”始终会返回 false。
Java 基本类型的大小
在 Java 虚拟机规范中,局部变量区等价于一个数组,并且可以用正整数来索引。除了 long、double 值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。
也就是说,boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。
除 long 和 double 外,其他基本类型与引用类型在解释执行的方法栈帧中占用的大小是一致的,但它们在堆中占用的大小确不同。在将 boolean、byte、char 以及 short 的值存入字段或者数组单元时,Java 虚拟机会进行掩码操作。在读取时,Java 虚拟机则会将其扩展为 int 类型。
3.Java虚拟机加载类
Java 将引用类型其细分为四种:类、接口、数组类和泛型参数。由于泛型参数会在编译过程中被擦除(我会在专栏的第二部分详细介绍),因此 Java 虚拟机实际上只有前三种。在类、接口和数组类中,数组类是由 Java 虚拟机直接生成的,其他两种则有对应的字节流。
字节流,最常见的形式要属由 Java 编译器生成的 class 文件。除此之外,我们也可以在程序内部直接生成,或者从网络中获取(例如网页中内嵌的小程序 Java applet)字节流。这些不同形式的字节流,都会被加载到 Java 虚拟机中,成为类或接口。
加载
加载,是指查找字节流,并且据此创建类的过程。前面提到,对于数组类来说,它并没有对应的字节流,而是由 Java 虚拟机直接生成的。对于其他的类来说,Java 虚拟机则需要借助类加载器来完成查找字节流的过程。
启动类加载器是由 C++ 实现的,没有对应的 Java 对象,因此在 Java 中只能用 null 来指代。
除了启动类加载器之外,其他的类加载器都是 java.lang.ClassLoader 的子类,因此有对应的 Java 对象。这些类加载器需要先由另一个类加载器,比如说启动类加载器,加载至 Java 虚拟机中,方能执行类加载。
在 Java 9 之前,启动类加载器负责加载最为基础、最为重要的类,比如存放在 JRE 的 lib 目录下 jar 包中的类(以及由虚拟机参数 -Xbootclasspath 指定的类)。除了启动类加载器之外,另外两个重要的类加载器是扩展类加载器(extension class loader)和应用类加载器(application class loader),均由 Java 核心类库提供。
扩展类加载器的父类加载器是启动类加载器。它负责加载相对次要、但又通用的类,比如存放在 JRE 的 lib/ext 目录下 jar 包中的类(以及由系统变量 java.ext.dirs 指定的类)。
应用类加载器的父类加载器则是扩展类加载器。它负责加载应用程序路径下的类。(这里的应用程序路径,便是指虚拟机参数 -cp/-classpath、系统变量 java.class.path 或环境变量 CLASSPATH 所指定的路径。)默认情况下,应用程序中包含的类便是由应用类加载器加载的。
Java 9 引入了模块系统,并且略微更改了上述的类加载器1。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE 中除了少数几个关键模块,比如说 java.base 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
除了由 Java 核心类库提供的类加载器外,我们还可以加入自定义的类加载器,来实现特殊的加载方式。举例来说,我们可以对 class 文件进行加密,加载时再利用自定义的类加载器对其解密。
除了加载功能之外,类加载器还提供了命名空间的作用。在 Java 虚拟机中,类的唯一性是由类加载器实例以及类的全名一同确定的。即便是同一串字节流,经由不同的类加载器加载,也会得到两个不同的类。在大型应用中,我们往往借助这一特性,来运行同一个类的不同版本。
链接
链接,是指将创建成的类合并至 Java 虚拟机中,使之能够执行的过程。它可分为验证、准备以及解析三个阶段。
验证阶段的目的,在于确保被加载类能够满足 Java 虚拟机的约束条件。通常而言,Java 编译器生成的类文件必然满足 Java 虚拟机的约束条件。
准备阶段的目的,则是为被加载类的静态字段分配内存。Java 代码中对静态字段的具体初始化,则会在稍后的初始化阶段中进行。
除了分配内存外,部分 Java 虚拟机还会在此阶段构造其他跟类层次相关的数据结构,比如说用来实现虚方法的动态绑定的方法表。
在 class 文件被加载至 Java 虚拟机之前,这个类无法知道其他类及其方法、字段所对应的具体地址,甚至不知道自己方法、字段的地址。因此,每当需要引用这些成员时,Java 编译器会生成一个符号引用。在运行阶段,这个符号引用一般都能够无歧义地定位到具体目标上。
解析阶段的目的,正是将这些符号引用解析成为实际引用。如果符号引用指向一个未被加载的类,或者未被加载类的字段或方法,那么解析将触发这个类的加载(但未必触发这个类的链接以及初始化。)
Java 虚拟机规范并没有要求在链接过程中完成解析。它仅规定了:如果某些字节码使用了符号引用,那么在执行这些字节码之前,需要完成对这些符号引用的解析。
初始化
如果直接赋值的静态字段被 final 所修饰,并且它的类型是基本类型或字符串时,那么该字段便会被 Java 编译器标记成常量值(ConstantValue),其初始化直接由 Java 虚拟机完成。除此之外的直接赋值操作,以及所有静态代码块中的代码,则会被 Java 编译器置于同一方法中,并把它命名为 < clinit >。
类加载的最后一步是初始化,便是为标记为常量值的字段赋值,以及执行 < clinit > 方法的过程。Java 虚拟机会通过加锁来确保类的 < clinit > 方法仅被执行一次。
只有当初始化完成之后,类才正式成为可执行的状态。
类的初始化触发情况:
-
当虚拟机启动时,初始化用户指定的主类;
-
当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类;
-
当遇到调用静态方法的指令时,初始化该静态方法所在的类;
-
当遇到访问静态字段的指令时,初始化该静态字段所在的类;
-
子类的初始化会触发父类的初始化;
-
如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
-
使用反射 API 对某个类进行反射调用时,初始化这个类;
-
当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
public class Singleton {
private Singleton() {}
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
这段代码是在著名的单例延迟初始化例子中2,只有当调用 Singleton.getInstance 时,程序才会访问 LazyHolder.INSTANCE,才会触发对 LazyHolder 的初始化(对应第 4 种情况),继而新建一个 Singleton 的实例。
由于类初始化是线程安全的,并且仅被执行一次,因此程序可以确保多线程环境下有且仅有一个 Singleton 实例。
总结
加载是指查找字节流,并且据此创建类的过程。加载需要借助类加载器,在 Java 虚拟机中,类加载器使用了双亲委派模型,即接收到加载请求时,会先将请求转发给父类加载器。
链接,是指将创建成的类合并至 Java 虚拟机中,使之能够执行的过程。链接还分验证、准备和解析三个阶段。其中,解析阶段为非必须的。
初始化,则是为标记为常量值的字段赋值,以及执行 < clinit > 方法的过程。类的初始化仅会被执行一次,这个特性被用来实现单例的延迟初始化。
4.JVM执行方法调用
重载与重写
在 Java 程序里,如果同一个类中出现多个名字相同,并且参数类型相同的方法,那么它无法通过编译。也就是说,在正常情况下,如果我们想要在同一个类中定义名字相同的方法,那么它们的参数类型必须不同。这些方法之间的关系,我们称之为重载。
重载的方法在编译过程中即可完成识别。具体到每一个方法调用,Java 编译器会根据所传入参数的声明类型(注意与实际类型区分)来选取重载方法。选取的过程共分为三个阶段:
- 在不考虑对基本类型自动装拆箱(auto-boxing,auto-unboxing),以及可变长参数的情况下选取重载方法;
- 如果在第 1 个阶段中没有找到适配的方法,那么在允许自动装拆箱,但不允许可变长参数的情况下选取重载方法;
- 如果在第 2 个阶段中没有找到适配的方法,那么在允许自动装拆箱以及可变长参数的情况下选取重载方法。
如果 Java 编译器在同一个阶段中找到了多个适配的方法,那么它会在其中选择一个最为贴切的,而决定贴切程度的一个关键就是形式参数类型的继承关系。
如果子类定义了与父类中非私有方法同名的方法,而且这两个方法的参数类型不同则是属于重载。
参数相同的情况,如果这两个方法都是静态的,那么子类中的方法隐藏了父类中的方法。如果这两个方法都不是静态的,且都不是私有的,那么子类的方法重写了父类中的方法。
JVM 的静态绑定和动态绑定
Java 虚拟机中关于方法重写的判定同样基于方法描述符。也就是说,如果子类定义了与父类中非私有、非静态方法同名的方法,那么只有当这两个方法的参数类型以及返回类型一致,Java 虚拟机才会判定为重写。
对于 Java 语言中重写而 Java 虚拟机中非重写的情况,编译器会通过生成桥接方法 [2] 来实现 Java 中的重写语义。
由于对重载方法的区分在编译阶段已经完成,我们可以认为 Java 虚拟机不存在重载这一概念。因此,在某些文章中,重载也被称为静态绑定(static binding),或者编译时多态(compile-time polymorphism);而重写则被称为动态绑定(dynamic binding)。
这个说法在 Java 虚拟机语境下并非完全正确。这是因为某个类中的重载方法可能被它的子类所重写,因此 Java 编译器会将所有对非私有实例方法的调用编译为需要动态绑定的类型。
确切地说,Java 虚拟机中的静态绑定指的是在解析时便能够直接识别目标方法的情况,而动态绑定则指的是需要在运行过程中根据调用者的动态类型来识别目标方法的情况。
具体来说,Java 字节码中与调用相关的指令共有五种。
- invokestatic:用于调用静态方法。
- invokespecial:用于调用私有实例方法、构造器,以及使用 super 关键字调用父类的实例方法或构造器,和所实现接口的默认方法。
- invokevirtual:用于调用非私有实例方法。
- invokeinterface:用于调用接口方法。
- invokedynamic:用于调用动态方法。
调用指令的符号引用
在编译过程中,我们并不知道目标方法的具体内存地址。因此,Java 编译器会暂时用符号引用来表示该目标方法。这一符号引用包括目标方法所在的类或接口的名字,以及目标方法的方法名和方法描述符。
符号引用存储在 class 文件的常量池之中。根据目标方法是否为接口方法,这些引用可分为接口符号引用和非接口符号引用。
在执行使用了符号引用的字节码前,Java 虚拟机需要解析这些符号引用,并替换为实际引用。
对于非接口符号引用,假定该符号引用所指向的类为 C,则 Java 虚拟机会按照如下步骤进行查找。
- 在 C 中查找符合名字及描述符的方法。
- 如果没有找到,在 C 的父类中继续搜索,直至 Object 类。
- 如果没有找到,在 C 所直接实现或间接实现的接口中搜索,这一步搜索得到的目标方法必须是非私有、非静态的。并且,如果目标方法在间接实现的接口中,则需满足 C 与该接口之间没有其他符合条件的目标方法。如果有多个符合条件的目标方法,则任意返回其中一个。
对于接口符号引用,假定该符号引用所指向的接口为 I,则 Java 虚拟机会按照如下步骤进行查找。
- 在 I 中查找符合名字及描述符的方法。
- 如果没有找到,在 Object 类中的公有实例方法中搜索。
- 如果没有找到,则在 I 的超接口中搜索。这一步的搜索结果的要求与非接口符号引用步骤 3 的要求一致。
经过上述的解析步骤之后,符号引用会被解析成实际引用。对于可以静态绑定的方法调用而言,实际引用是一个指向方法的指针。对于需要动态绑定的方法调用而言,实际引用则是一个方法表的索引。
虚方法调用
Java 里所有非私有实例方法调用都会被编译成 invokevirtual 指令,而接口方法调用都会被编译成 invokeinterface 指令。这两种指令,均属于 Java 虚拟机中的虚方法调用。
在 Java 虚拟机中,静态绑定包括用于调用静态方法的 invokestatic 指令,和用于调用构造器、私有实例方法以及超类非私有实例方法的 invokespecial 指令。如果虚方法调用指向一个标记为 final 的方法,那么 Java 虚拟机也可以静态绑定该虚方法调用的目标方法。
否则,Java 虚拟机将采用动态绑定,在运行过程中根据调用者的动态类型,来决定具体的目标方法。
方法表
Java 虚拟机中采取了一种用空间换取时间的策略来实现动态绑定。它为每个类生成一张方法表,用以快速定位目标方法。
方法表本质上是一个数组,每个数组元素指向一个当前类及其祖先类中非私有的实例方法。
在执行过程中,Java 虚拟机将获取调用者的实际类型,并在该实际类型的虚方法表中,根据索引值获得目标方法。这个过程便是动态绑定。
内联缓存
内联缓存是一种加快动态绑定的优化技术。它能够缓存虚方法调用中调用者的动态类型,以及该类型所对应的目标方法。在之后的执行过程中,如果碰到已缓存的类型,内联缓存便会直接调用该类型所对应的目标方法。如果没有碰到已缓存的类型,内联缓存则会退化至使用基于方法表的动态绑定。
一般来说,我们会将更加热门的动态类型放在前面。在实践中,大部分的虚方法调用均是单态的,也就是只有一种动态类型。为了节省内存空间,Java 虚拟机只采用单态内联缓存。
Java 虚拟机中的即时编译器会使用内联缓存来加速动态绑定。Java 虚拟机所采用的单态内联缓存将纪录调用者的动态类型,以及它所对应的目标方法。
当碰到新的调用者时,如果其动态类型与缓存中的类型匹配,则直接调用缓存的目标方法。
否则,Java 虚拟机将该内联缓存劣化为超多态内联缓存,在今后的执行过程中直接使用方法表进行动态绑定。
5.JVM处理异常
ava 的异常分为 Exception 和 Error 两种,而 Exception 又分为 RuntimeException 和其他类型。RuntimeException 和 Error 属于非检查异常。其他的 Exception 皆属于检查异常,在触发时需要显式捕获,或者在方法头用 throws 关键字声明。
Java 字节码中,每个方法对应一个异常表。当程序触发异常时,Java 虚拟机将查找异常表,并依此决定需要将控制流转移至哪个异常处理器之中。Java 代码中的 catch 代码块和 finally 代码块都会生成异常表条目。
Java 7 引入了 Supressed 异常、try-with-resources,以及多异常捕获。后两者属于语法糖,能够极大地精简我们的代码。
6.JVM实现反射
如果你查阅 Method.invoke 的源代码,那么你会发现,它实际上委派给 MethodAccessor 来处理。MethodAccessor 是一个接口,它有两个已有的具体实现:一个通过本地方法来实现反射调用,另一个则使用了委派模式。为了方便记忆,我便用“本地实现”和“委派实现”来指代这两者。
每个 Method 实例的第一次反射调用都会生成一个委派实现,它所委派的具体实现便是一个本地实现。本地实现非常容易理解。当进入了 Java 虚拟机内部之后,我们便拥有了 Method 实例所指向方法的具体地址。这时候,反射调用无非就是将传入的参数准备好,然后调用进入目标方法。
反射调用先是调用了 Method.invoke,然后进入委派实现(DelegatingMethodAccessorImpl),再然后进入本地实现(NativeMethodAccessorImpl),最后到达目标方法。
Java 的反射调用机制还设立了另一种动态生成字节码的实现(下称动态实现),直接使用 invoke 指令来调用目标方法。之所以采用委派实现,便是为了能够在本地实现以及动态实现中切换。
考虑到许多反射调用仅会执行一次,Java 虚拟机设置了一个阈值 15(可以通过 -Dsun.reflect.inflationThreshold= 来调整),当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
反射调用的 Inflation 机制是可以通过参数(-Dsun.reflect.noInflation=true)来关闭的。这样一来,在反射调用一开始便会直接生成动态实现,而不会使用委派实现或者本地实现。
反射的开销
方法的反射调用会带来不少性能开销,原因主要有三个:变长参数方法导致的 Object 数组,基本类型的自动装箱、拆箱,还有最重要的方法内联。
方法内联指的是编译器在编译一个方法时,将某个方法调用的目标方法也纳入编译范围内,并用其返回值替代原方法调用这么个过程。
由于 Java 虚拟机的关于调用点的类型 profile(注:对于 invokevirtual 或者 invokeinterface,Java 虚拟机会记录下调用者的具体类型,我们称之为类型 profile)无法同时记录这么多个类,因此可能造成反射调用没有被内联的情况。
7.JVM实现invokedynamic:方法句柄
方法句柄的概念
方法句柄是一个强类型的,能够被直接执行的引用 。该引用可以指向常规的静态方法或者实例方法,也可以指向构造器或者字段。当指向字段时,方法句柄实则指向包含字段访问字节码的虚构方法,语义上等价于目标字段的 getter 或者 setter 方法。
这里需要注意的是,它并不会直接指向目标字段所在类中的 getter/setter,毕竟你无法保证已有的 getter/setter 方法就是在访问目标字段。
方法句柄的类型(MethodType)是由所指向方法的参数类型以及返回类型组成的。它是用来确认方法句柄是否适配的唯一关键。当使用方法句柄时,我们其实并不关心方法句柄所指向方法的类名或者方法名。
方法句柄的创建是通过MethodHandles.Lookup 类来完成的。它提供了多个 API,既可以使用反射 API 中的 Method 来查找,也可以根据类、方法名以及方法句柄类型来查找。
class Foo {
private static void bar(Object o) {
..
}
public static Lookup lookup() {
return MethodHandles.lookup();
}
}
// 获取方法句柄的不同方式
MethodHandles.Lookup l = Foo.lookup(); // 具备 Foo 类的访问权限
Method m = Foo.class.getDeclaredMethod("bar", Object.class);
MethodHandle mh0 = l.unreflect(m);
MethodType t = MethodType.methodType(void.class, Object.class);
MethodHandle mh1 = l.findStatic(Foo.class, "bar", t);
方法句柄可以通过 invokeExact 以及 invoke 来调用。其中,invokeExact 要求传入的参数和所指向方法的描述符严格匹配。方法句柄还支持增删改参数的操作,这些操作是通过生成另一个充当适配器的方法句柄来实现的。
方法句柄的实现
import java.lang.invoke.*;
public class Foo {
public static void bar(Object o) {
new Exception().printStackTrace();
}
public static void main(String[] args) throws Throwable {
MethodHandles.Lookup l = MethodHandles.lookup();
MethodType t = MethodType.methodType(void.class, Object.class);
MethodHandle mh = l.findStatic(Foo.class, "bar", t);
mh.invokeExact(new Object());
}
}
方法句柄的调用和反射调用一样,都是间接调用。因此,它也会面临无法内联的问题。不过,与反射调用不同的是,方法句柄的内联瓶颈在于即时编译器能否将该方法句柄识别为常量。
invokedynamic指令
invokedynamic 是 Java 7 引入的一条新指令,用以支持动态语言的方法调用。具体来说,它将调用点(CallSite)抽象成一个 Java 类,并且将原本由 Java 虚拟机控制的方法调用以及方法链接暴露给了应用程序。在运行过程中,每一条 invokedynamic 指令将捆绑一个调用点,并且会调用该调用点所链接的方法句柄。
在字节码中,启动方法是用方法句柄来指定的。这个方法句柄指向一个返回类型为调用点的静态方法。该方法必须接收三个固定的参数,分别为一个 Lookup 类实例,一个用来指代目标方法名字的字符串,以及该调用点能够链接的方法句柄的类型。
除了这三个必需参数之外,启动方法还可以接收若干个其他的参数,用来辅助生成调用点,或者定位所要链接的目标方法。
import java.lang.invoke.*;
class Horse {
public void race() {
System.out.println("Horse.race()");
}
}
class Deer {
public void race() {
System.out.println("Deer.race()");
}
}
// javac Circuit.java
// java Circuit
public class Circuit {
public static void startRace(Object obj) {
// aload obj
// invokedynamic race()
}
public static void main(String[] args) {
startRace(new Horse());
// startRace(new Deer());
}
public static CallSite bootstrap(MethodHandles.Lookup l, String name, MethodType callSiteType) throws Throwable {
MethodHandle mh = l.findVirtual(Horse.class, name, MethodType.methodType(void.class));
return new ConstantCallSite(mh.asType(callSiteType));
}
}
为了支持调用任意类的 race 方法,我实现了一个简单的单态内联缓存。如果调用者的类型命中缓存中的类型,便直接调用缓存中的方法句柄,否则便更新缓存。
// 需要更改 ASMHelper.MyMethodVisitor 中的 BOOTSTRAP_CLASS_NAME
import java.lang.invoke.*;
public class MonomorphicInlineCache {
private final MethodHandles.Lookup lookup;
private final String name;
public MonomorphicInlineCache(MethodHandles.Lookup lookup, String name) {
this.lookup = lookup;
this.name = name;
}
private Class<?> cachedClass = null;
private MethodHandle mh = null;
public void invoke(Object receiver) throws Throwable {
if (cachedClass != receiver.getClass()) {
cachedClass = receiver.getClass();
mh = lookup.findVirtual(cachedClass, name, MethodType.methodType(void.class));
}
mh.invoke(receiver);
}
public static CallSite bootstrap(MethodHandles.Lookup l, String name, MethodType callSiteType) throws Throwable {
MonomorphicInlineCache ic = new MonomorphicInlineCache(l, name);
MethodHandle mh = l.findVirtual(MonomorphicInlineCache.class, "invoke", MethodType.methodType(void.class, Object.class));
return new ConstantCallSite(mh.bindTo(ic));
}
}
可以看到,尽管 invokedynamic 指令调用的是所谓的 race 方法,但是实际上我返回了一个链接至名为“invoke”的方法的调用点。由于调用点仅要求方法句柄的类型能够匹配,因此这个链接是合法的。
Java 8 的 Lambda 表达式
Java 编译器利用 invokedynamic 指令来生成实现了函数式接口的适配器。这里的函数式接口指的是仅包括一个非 default 接口方法的接口,一般通过 @FunctionalInterface 注解。不过就算是没有使用该注解,Java 编译器也会将符合条件的接口辨认为函数式接口。
在编译过程中,Java 编译器会对 Lambda 表达式进行解语法糖(desugar),生成一个方法来保存 Lambda 表达式的内容。该方法的参数列表不仅包含原本 Lambda 表达式的参数,还包含它所捕获的变量。
如果该 Lambda 表达式没有捕获其他变量,那么可以认为它是上下文无关的。因此,启动方法将新建一个适配器类的实例,并且生成一个特殊的方法句柄,始终返回该实例。
如果该 Lambda 表达式捕获了其他变量,那么每次执行该 invokedynamic 指令,我们都要更新这些捕获了的变量,以防止它们发生了变化。
不管是捕获型的还是未捕获型的 Lambda 表达式,它们的性能上限皆可以达到直接调用的性能。其中,捕获型 Lambda 表达式借助了即时编译器中的逃逸分析,来避免实际的新建适配器类实例的操作。
8.Java对象的内存布局
当我们调用一个构造器时,它将优先调用父类的构造器,直至 Object 类。这些构造器的调用者皆为同一对象,也就是通过 new 指令新建而来的对象。
通过 new 指令新建出来的对象,它的内存其实涵盖了所有父类中的实例字段。也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
压缩指针
在 Java 虚拟机中,每个 Java 对象都有一个对象头(object header),这个由标记字段和类型指针所构成。其中,标记字段用以存储 Java 虚拟机有关该对象的运行数据,如哈希码、GC 信息以及锁信息,而类型指针则指向该对象的类。
为了尽量较少对象的内存使用量,64 位 Java 虚拟机引入了压缩指针 [1] 的概念(对应虚拟机选项 -XX:+UseCompressedOops,默认开启),将堆中原本 64 位的 Java 对象指针压缩成 32 位的。
默认情况下,Java 虚拟机堆中对象的起始地址需要对齐至 8 的倍数。如果一个对象用不到 8N 个字节,那么空白的那部分空间就浪费掉了。这些浪费掉的空间我们称之为对象间的填充(padding)。
在默认情况下,Java 虚拟机中的 32 位压缩指针可以寻址到 2 的 35 次方个字节,也就是 32GB 的地址空间(超过 32GB 则会关闭压缩指针)。
在对压缩指针解引用时,我们需要将其左移 3 位,再加上一个固定偏移量,便可以得到能够寻址 32GB 地址空间的伪 64 位指针了。
字段重排列
字段重排列,顾名思义,就是 Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的。Java 虚拟机中有三种排列方法(对应 Java 虚拟机选项 -XX:FieldsAllocationStyle,默认值为 1),但都会遵循如下两个规则。
其一,如果一个字段占据 C 个字节,那么该字段的偏移量需要对齐至 NC。这里偏移量指的是字段地址与对象的起始地址差值。
其二,子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
8.JVM垃圾回收
引用计数法与可达性分析
引用计数法(reference counting)。它的做法是为每个对象添加一个引用计数器,用来统计指向该对象的引用个数。一旦某个对象的引用计数器为 0,则说明该对象已经死亡,便可以被回收了。
存在的问题:除了需要额外的空间来存储计数器,以及繁琐的更新操作,引用计数法还有一个重大的漏洞,那便是无法处理循环引用对象。
目前 Java 虚拟机的主流垃圾回收器采取的是可达性分析算法。这个算法的实质在于将一系列 GC Roots 作为初始的存活对象合集(live set),然后从该合集出发,探索所有能够被该集合引用到的对象,并将其加入到该集合中,这个过程我们也称之为标记(mark)。最终,未被探索到的对象便是死亡的,是可以回收的。
那么什么是 GC Roots 呢?我们可以暂时理解为由堆外指向堆内的引用,一般而言,GC Roots 包括(但不限于)如下几种:
- Java 方法栈桢中的局部变量;
- 已加载类的静态变量;
- JNI handles;
- 已启动且未停止的 Java 线程。
可达性分析可以解决引用计数法所不能解决的循环引用问题。举例来说,即便对象 a 和 b 相互引用,只要从 GC Roots 出发无法到达 a 或者 b,那么可达性分析便不会将它们加入存活对象合集之中。
存在的问题:在多线程环境下,其他线程可能会更新已经访问过的对象中的引用,从而造成误报(将引用设置为 null)或者漏报(将引用设置为未被访问过的对象)。
误报并没有什么伤害,Java 虚拟机至多损失了部分垃圾回收的机会。漏报则比较麻烦,因为垃圾回收器可能回收事实上仍被引用的对象内存。一旦从原引用访问已经被回收了的对象,则很有可能会直接导致 Java 虚拟机崩溃。
Stop-the-world 以及安全点
在 Java 虚拟机里,传统的垃圾回收算法采用的是一种简单粗暴的方式,那便是 Stop-the-world,停止其他非垃圾回收线程的工作,直到完成垃圾回收。这也就造成了垃圾回收所谓的暂停时间(GC pause)。
Java 虚拟机中的 Stop-the-world 是通过安全点(safepoint)机制来实现的。当 Java 虚拟机收到 Stop-the-world 请求,它便会等待所有的线程都到达安全点,才允许请求 Stop-the-world 的线程进行独占的工作。
当然,安全点的初始目的并不是让其他线程停下,而是找到一个稳定的执行状态。在这个执行状态下,Java 虚拟机的堆栈不会发生变化。这么一来,垃圾回收器便能够“安全”地执行可达性分析。
垃圾回收的三种方式
第一种是清除(sweep),即把死亡对象所占据的内存标记为空闲内存,并记录在一个空闲列表(free list)之中。当需要新建对象时,内存管理模块便会从该空闲列表中寻找空闲内存,并划分给新建的对象。
缺点:一是会造成内存碎片,另一个则是分配效率较低。
第二种是压缩(compact),即把存活的对象聚集到内存区域的起始位置,从而留下一段连续的内存空间。这种做法能够解决内存碎片化的问题,但代价是压缩算法的性能开销。
第三种则是复制(copy),即把内存区域分为两等分,分别用两个指针 from 和 to 来维护,并且只是用 from 指针指向的内存区域来分配内存。当发生垃圾回收时,便把存活的对象复制到 to 指针指向的内存区域中,并且交换 from 指针和 to 指针的内容。复制这种回收方式同样能够解决内存碎片化的问题,但是它的缺点也极其明显,即堆空间的使用效率极其低下。
Java 虚拟机的堆划分
Java 虚拟机将堆划分为新生代和老年代。其中,新生代又被划分为 Eden 区,以及两个大小相同的 Survivor 区。
默认情况下,Java 虚拟机采取的是一种动态分配的策略(对应 Java 虚拟机参数 -XX:+UsePSAdaptiveSurvivorSizePolicy),根据生成对象的速率,以及 Survivor 区的使用情况动态调整 Eden 区和 Survivor 区的比例。
当然,你也可以通过参数 -XX:SurvivorRatio 来固定这个比例。但是需要注意的是,其中一个 Survivor 区会一直为空,因此比例越低浪费的堆空间将越高。
当 Eden 区的空间耗尽了怎么办?这个时候 Java 虚拟机便会触发一次 Minor GC,来收集新生代的垃圾。存活下来的对象,则会被送到 Survivor 区。
前面提到,新生代共有两个 Survivor 区,我们分别用 from 和 to 来指代。其中 to 指向的 Survivior 区是空的。
当发生 Minor GC 时,Eden 区和 from 指向的 Survivor 区中的存活对象会被复制到 to 指向的 Survivor 区中,然后交换 from 和 to 指针,以保证下一次 Minor GC 时,to 指向的 Survivor 区还是空的。
Java 虚拟机会记录 Survivor 区中的对象一共被来回复制了几次。如果一个对象被复制的次数为 15(对应虚拟机参数 -XX:+MaxTenuringThreshold),那么该对象将被晋升(promote)至老年代。另外,如果单个 Survivor 区已经被占用了 50%(对应虚拟机参数 -XX:TargetSurvivorRatio),那么较高复制次数的对象也会被晋升至老年代。
卡表
Minor GC 的另外一个好处是不用对整个堆进行垃圾回收。但是,它却有一个问题,那就是老年代的对象可能引用新生代的对象。也就是说,在标记存活对象的时候,我们需要扫描老年代中的对象。如果该对象拥有对新生代对象的引用,那么这个引用也会被作为 GC Roots。
为了避免扫描整个老年代,Java 虚拟机引入了名为卡表的技术,大致地标出可能存在老年代到新生代引用的内存区域。
该技术将整个堆划分为一个个大小为 512 字节的卡,并且维护一个卡表,用来存储每张卡的一个标识位。这个标识位代表对应的卡是否可能存有指向新生代对象的引用。如果可能存在,那么我们就认为这张卡是脏的。
在进行 Minor GC 的时候,我们便可以不用扫描整个老年代,而是在卡表中寻找脏卡,并将脏卡中的对象加入到 Minor GC 的 GC Roots 里。当完成所有脏卡的扫描之后,Java 虚拟机便会将所有脏卡的标识位清零。
Java虚拟机中的垃圾回收器
针对新生代的垃圾回收器共有三个:Serial,Parallel Scavenge 和 Parallel New。这三个采用的都是标记 - 复制算法。其中,Serial 是一个单线程的,Parallel New 可以看成 Serial 的多线程版本。Parallel Scavenge 和 Parallel New 类似,但更加注重吞吐率。此外,Parallel Scavenge 不能与 CMS 一起使用。
针对老年代的垃圾回收器也有三个:刚刚提到的 Serial Old 和 Parallel Old,以及 CMS。Serial Old 和 Parallel Old 都是标记 - 压缩算法。同样,前者是单线程的,而后者可以看成前者的多线程版本。
G1(Garbage First)是一个横跨新生代和老年代的垃圾回收器。实际上,它已经打乱了前面所说的堆结构,直接将堆分成极其多个区域。每个区域都可以充当 Eden 区、Survivor 区或者老年代中的一个。它采用的是标记 - 压缩算法,而且和 CMS 一样都能够在应用程序运行过程中并发地进行垃圾回收。
G1 能够针对每个细分的区域来进行垃圾回收。在选择进行垃圾回收的区域时,它会优先回收死亡对象较多的区域。这也是 G1 名字的由来。
9.Java内存模型
为了让应用程序能够免于数据竞争的干扰,Java 5 引入了明确定义的 Java 内存模型。其中最为重要的一个概念便是 happens-before 关系。happens-before 关系是用来描述两个操作的内存可见性的。如果操作 X happens-before 操作 Y,那么 X 的结果对于 Y 可见。
在同一个线程中,字节码的先后顺序(program order)也暗含了 happens-before 关系:在程序控制流路径中靠前的字节码 happens-before 靠后的字节码。然而,这并不意味着前者一定在后者之前执行。实际上,如果后者没有观测前者的运行结果,即后者没有数据依赖于前者,那么它们可能会被重排序。
除了线程内的 happens-before 关系之外,Java 内存模型还定义了下述线程间的 happens-before 关系。
- 解锁操作 happens-before 之后(这里指时钟顺序先后)对同一把锁的加锁操作。
- volatile 字段的写操作 happens-before 之后(这里指时钟顺序先后)对同一字段的读操作。
- 线程的启动操作(即 Thread.starts()) happens-before 该线程的第一个操作。
- 线程的最后一个操作 happens-before 它的终止事件(即其他线程通过 Thread.isAlive() 或 Thread.join() 判断该线程是否中止)。
- 线程对其他线程的中断操作 happens-before 被中断线程所收到的中断事件(即被中断线程的 InterruptedException 异常,或者第三个线程针对被中断线程的 Thread.interrupted 或者 Thread.isInterrupted 调用)。
- 构造器中的最后一个操作 happens-before 析构器的第一个操作。
happens-before 关系还具备传递性。如果操作 X happens-before 操作 Y,而操作 Y happens-before 操作 Z,那么操作 X happens-before 操作 Z。
拥有 happens-before 关系的两对赋值操作之间没有数据依赖,因此即时编译器、处理器都可能对其进行重排序。解决这种数据竞争问题的关键在于构造一个跨线程的 happens-before 关系。
Java 内存模型的底层实现
Java 内存模型是通过内存屏障(memory barrier)来禁止重排序的。
对于即时编译器来说,它会针对前面提到的每一个 happens-before 关系,向正在编译的目标方法中插入相应的读读、读写、写读以及写写内存屏障。
这些内存屏障会限制即时编译器的重排序操作。以 volatile 字段访问为例,所插入的内存屏障将不允许 volatile 字段写操作之前的内存访问被重排序至其之后;也将不允许 volatile 字段读操作之后的内存访问被重排序至其之前。
然后,即时编译器将根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令。以我们日常接触的 X86_64 架构来说,读读、读写以及写写内存屏障是空操作(no-op),只有写读内存屏障会被替换成具体指令 [2]。
然而,在 X86_64 架构上,只有 volatile 字段写操作之后的写读内存屏障需要用具体指令来替代。
该具体指令的效果,可以简单理解为强制刷新处理器的写缓存。写缓存是处理器用来加速内存存储效率的一项技术。
在碰到内存写操作时,处理器并不会等待该指令结束,而是直接开始下一指令,并且依赖于写缓存将更改的数据同步至主内存(main memory)之中。
强制刷新写缓存,将使得当前线程写入 volatile 字段的值(以及写缓存中已有的其他内存修改),同步至主内存之中。
由于内存写操作同时会无效化其他处理器所持有的、指向同一内存地址的缓存行,因此可以认为其他处理器能够立即见到该 volatile 字段的最新值。
锁,volatile 字段,final 字段与安全发布
即时编译后的 synchronized (new Object()) {},可能等同于空操作,而不会强制刷新缓存。
volatile 字段可以看成一种轻量级的、不保证原子性的同步,其性能往往优于(至少不亚于)锁操作。然而,频繁地访问 volatile 字段也会因为不断地强制刷新缓存而严重影响程序的性能。
即时编译器会在 final 字段的写操作后插入一个写写屏障,以防某些优化将新建对象的发布(即将实例对象写入一个共享引用中)重排序至 final 字段的写操作之前。在 X86_64 平台上,写写屏障是空操作。
Java 内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。
10.Java虚拟机实现synchronized
当声明 synchronized 代码块时,编译而成的字节码将包含 monitorenter 和 monitorexit 指令。这两种指令均会消耗操作数栈上的一个引用类型的元素(也就是 synchronized 关键字括号里的引用),作为所要加锁解锁的锁对象。
关于 monitorenter 和 monitorexit 的作用,我们可以抽象地理解为每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
当执行 monitorenter 时,如果目标锁对象的计数器为 0,那么说明它没有被其他线程所持有。在这个情况下,Java 虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加 1。
在目标锁对象的计数器不为 0 的情况下,如果锁对象的持有线程是当前线程,那么 Java 虚拟机可以将其计数器加 1,否则需要等待,直至持有线程释放该锁。
当执行 monitorexit 时,Java 虚拟机则需将锁对象的计数器减 1。当计数器减为 0 时,那便代表该锁已经被释放掉了。
重量级锁
重量级锁是 Java 虚拟机中最为基础的锁实现。在这种状态下,Java 虚拟机会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程。
为了尽量避免昂贵的线程阻塞、唤醒操作,Java 虚拟机会在线程进入阻塞状态之前,以及被唤醒后竞争不到锁的情况下,进入自旋状态,在处理器上空跑并且轮询锁是否被释放。如果此时锁恰好被释放了,那么当前线程便无须进入阻塞状态,而是直接获得这把锁。
自旋状态还带来另外一个副作用,那便是不公平的锁机制。处于阻塞状态的线程,并没有办法立刻竞争被释放的锁。然而,处于自旋状态的线程,则很有可能优先获得这把锁。
轻量级锁
多个线程在不同的时间段请求同一把锁,也就是说没有锁竞争。针对这种情形,Java 虚拟机采用了轻量级锁,来避免重量级锁的阻塞以及唤醒。
对象头中的标记字段(mark word)。它的最后两位便被用来表示该对象的锁状态。其中,00 代表轻量级锁,01 代表无锁(或偏向锁),10 代表重量级锁,11 则跟垃圾回收算法的标记有关。
当进行加锁操作时,Java 虚拟机会判断是否已经是重量级锁。如果不是,它会在当前线程的当前栈桢中划出一块空间,作为该锁的锁记录,并且将锁对象的标记字段复制到该锁记录中。
然后,Java 虚拟机会尝试用 CAS(compare-and-swap)操作替换锁对象的标记字段。这里解释一下,CAS 是一个原子操作,它会比较目标地址的值是否和期望值相等,如果相等,则替换为一个新的值。
当进行解锁操作时,如果当前锁记录(你可以将一个线程的所有锁记录想象成一个栈结构,每次加锁压入一条锁记录,解锁弹出一条锁记录,当前锁记录指的便是栈顶的锁记录)的值为 0,则代表重复进入同一把锁,直接返回即可。
否则,Java 虚拟机会尝试用 CAS 操作,比较锁对象的标记字段的值是否为当前锁记录的地址。如果是,则替换为锁记录中的值,也就是锁对象原本的标记字段。此时,该线程已经成功释放这把锁。
如果不是,则意味着这把锁已经被膨胀为重量级锁。此时,Java 虚拟机会进入重量级锁的释放过程,唤醒因竞争该锁而被阻塞了的线程。
偏向锁
如果说轻量级锁针对的情况很乐观,那么接下来的偏向锁针对的情况则更加乐观:从始至终只有一个线程请求某一把锁。
具体来说,在线程进行加锁时,如果该锁对象支持偏向锁,那么 Java 虚拟机会通过 CAS 操作,将当前线程的地址记录在锁对象的标记字段之中,并且将标记字段的最后三位设置为 101。
在接下来的运行过程中,每当有线程请求这把锁,Java 虚拟机只需判断锁对象标记字段中:最后三位是否为 101,是否包含当前线程的地址,以及 epoch 值是否和锁对象的类的 epoch 值相同。如果都满足,那么当前线程持有该偏向锁,可以直接返回。
当请求加锁的线程和锁对象标记字段保持的线程地址不匹配时(而且 epoch 值相等,如若不等,那么当前线程可以将该锁重偏向至自己),Java 虚拟机需要撤销该偏向锁。这个撤销过程非常麻烦,它要求持有偏向锁的线程到达安全点,再将偏向锁替换成轻量级锁。
如果某一类锁对象的总撤销数超过了一个阈值(对应 Java 虚拟机参数 -XX:BiasedLockingBulkRebiasThreshold,默认为 20),那么 Java 虚拟机会宣布这个类的偏向锁失效。
如果总撤销数超过另一个阈值(对应 Java 虚拟机参数 -XX:BiasedLockingBulkRevokeThreshold,默认值为 40),那么 Java 虚拟机会认为这个类已经不再适合偏向锁。此时,Java 虚拟机会撤销该类实例的偏向锁,并且在之后的加锁过程中直接为该类实例设置轻量级锁。
总结:
重量级锁会阻塞、唤醒请求加锁的线程。它针对的是多个线程同时竞争同一把锁的情况。Java 虚拟机采取了自适应自旋,来避免线程在面对非常小的 synchronized 代码块时,仍会被阻塞、唤醒的情况。
轻量级锁采用 CAS 操作,将锁对象的标记字段替换为一个指针,指向当前线程栈上的一块空间,存储着锁对象原本的标记字段。它针对的是多个线程在不同时间段申请同一把锁的情况。
偏向锁只会在第一次请求时采用 CAS 操作,在锁对象的标记字段中记录下当前线程的地址。在之后的运行过程中,持有该偏向锁的线程的加锁操作将直接返回。它针对的是锁仅会被同一线程持有的情况。
11.Java语法糖与Java编译器
泛型与类型擦除
往 ArrayList 中添加元素的 add 方法,所接受的参数类型是 Object;而从 ArrayList 中获取元素的 get 方法,其返回类型同样也是 Object。
前者还好,但是对于后者,在字节码中我们需要进行向下转换,将所返回的 Object 强制转换为 Integer,方能进行接下来的自动拆箱。
之所以会出现这种情况,是因为 Java 泛型的类型擦除。这是个什么概念呢?简单地说,那便是 Java 程序里的泛型信息,在 Java 虚拟机里全部都丢失了。这么做主要是为了兼容引入泛型之前的代码。
当然,并不是每一个泛型参数被擦除类型后都会变成 Object 类。对于限定了继承类的泛型参数,经过类型擦除后,所有的泛型参数都将变成所限定的继承类。也就是说,Java 编译器将选取该泛型所能指代的所有类中层次最高的那个,作为替换泛型的类。
Java 编译器可以根据泛型参数判断程序中的语法是否正确。举例来说,尽管经过类型擦除后,ArrayList.add 方法所接收的参数是 Object 类型,但是往泛型参数为 Integer 类型的 ArrayList 中添加字符串对象,Java 编译器是会报错的。
桥接方法
class Merchant<T extends Customer> {
public double actionPrice(T customer) {
return 0.0d;
}
}
class VIPOnlyMerchant extends Merchant<VIP> {
@Override
public double actionPrice(VIP customer) {
return 0.0d;
}
}
VIPOnlyMerchant 中的 actionPrice 方法是符合 Java 语言的方法重写的,毕竟都使用 @Override 来注解了。然而,经过类型擦除后,父类的方法描述符为 (LCustomer;)D,而子类的方法描述符为 (LVIP;)D。这显然不符合 Java 虚拟机关于方法重写的定义。
为了保证编译而成的 Java 字节码能够保留重写的语义,Java 编译器额外添加了一个桥接方法。该桥接方法在字节码层面重写了父类的方法,并将调用子类的方法。
除了泛型重写会生成桥接方法之外,如果子类定义了一个与父类参数类型相同的方法,其返回类型为父类方法返回类型的子类,那么 Java 编译器也会为其生成桥接方法。
jvm即时编译
通常而言,代码会先被 Java 虚拟机解释执行,之后反复执行的热点代码则会被即时编译成为机器码,直接运行在底层硬件之上。
分层编译模式
HotSpot 虚拟机包含多个即时编译器 C1、C2 和 Graal。
其中,Graal 是一个实验性质的即时编译器,可以通过参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 启用,并且替换 C2。
在 Java 7 以前,我们需要根据程序的特性选择对应的即时编译器。对于执行时间较短的,或者对启动性能有要求的程序,我们采用编译效率较快的 C1,对应参数 -client。
对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的 C2,对应参数 -server。
Java 7 引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。
分层编译将 Java 虚拟机的执行状态分为了五个层次。为了方便阐述,我用“C1 代码”来指代由 C1 生成的机器码,“C2 代码”来指代由 C2 生成的机器码。五个层级分别是:
- 解释执行;
- 执行不带 profiling 的 C1 代码;
- 执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
- 执行带所有 profiling 的 C1 代码;
- 执行 C2 代码。
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。然而,对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层。
profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的 profile。
在 5 个层次的执行状态中,1 层和 4 层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么 Java 虚拟机是不会再次发出该方法的编译请求的。
通常情况下,热点方法会被 3 层的 C1 编译,然后再被 4 层的 C2 编译。
如果方法的字节码数目比较少(如 getter/setter),而且 3 层的 profiling 没有可收集的数据。
那么,Java 虚拟机断定该方法对于 C1 代码和 C2 代码的执行效率相同。在这种情况下,Java 虚拟机会在 3 层编译之后,直接选择用 1 层的 C1 编译。由于这是一个终止状态,因此 Java 虚拟机不会继续用 4 层的 C2 编译。
在 C1 忙碌的情况下,Java 虚拟机在解释执行过程中对程序进行 profiling,而后直接由 4 层的 C2 编译。在 C2 忙碌的情况下,方法会被 2 层的 C1 编译,然后再被 3 层的 C1 编译,以减少方法在 3 层的执行时间。
即时编译的触发
Java 虚拟机是根据方法的调用次数以及循环回边的执行次数来触发即时编译的。前面提到,Java 虚拟机在 0 层、2 层和 3 层执行状态时进行 profiling,其中就包含方法的调用次数和循环回边的执行次数。
总结:
从 Java 8 开始,Java 虚拟机默认采用分层编译的方式。它将执行分为五个层次,分为为 0 层解释执行,1 层执行没有 profiling 的 C1 代码,2 层执行部分 profiling 的 C1 代码,3 层执行全部 profiling 的 C1 代码,和 4 层执行 C2 代码。
通常情况下,方法会首先被解释执行,然后被 3 层的 C1 编译,最后被 4 层的 C2 编译。
即时编译是由方法调用计数器和循环回边计数器触发的。在使用分层编译的情况下,触发编译的阈值是根据当前待编译的方法数目动态调整的。
OSR 是一种能够在非方法入口处进行解释执行和编译后代码之间切换的技术。OSR 编译可以用来解决单次调用方法包含热循环的性能优化问题。
12.Profiling
分层编译中的 0 层、2 层和 3 层都会进行 profiling,收集能够反映程序执行状态的数据。其中,最为基础的便是方法的调用次数以及循环回边的执行次数。它们被用于触发即时编译。
此外,0 层和 3 层还会收集用于 4 层 C2 编译的数据,比如说分支跳转字节码的分支 profile(branch profile),包括跳转次数和不跳转次数,以及非私有实例方法调用指令、强制类型转换 checkcast 指令、类型测试 instanceof 指令,和引用类型的数组存储 aastore 指令的类型 profile(receiver type profile)。
分支 profile 和类型 profile 的收集将给应用程序带来不少的性能开销。据统计,正是因为这部分额外的 profiling,使得 3 层 C1 代码的性能比 2 层 C1 代码的低 30%。
在通常情况下,我们不会在解释执行过程中收集分支 profile 以及类型 profile。只有在方法触发 C1 编译后,Java 虚拟机认为该方法有可能被 C2 编译,方才在该方法的 C1 代码中收集这些 profile。
只要在比较极端的情况下,例如等待 C1 编译的方法数目太多时,Java 虚拟机才会开始在解释执行过程中收集这些 profile。
C2 可以根据收集得到的数据进行猜测,假设接下来的执行同样会按照所收集的 profile 进行,从而作出比较激进的优化。
基于分支 profile 的优化
根据条件跳转指令的分支 profile,即时编译器可以将从未执行过的分支剪掉,以避免编译这些很有可能不会用到的代码,从而节省编译时间以及部署代码所要消耗的内存空间。此外,“剪枝”将精简程序的数据流,从而触发更多的优化。
在现实中,分支 profile 出现仅跳转或者仅不跳转的情况并不多见。当然,即时编译器对分支 profile 的利用也不仅限于“剪枝”。它还会根据分支 profile,计算每一条程序执行路径的概率,以便某些编译器优化优先处理概率较高的路径。
基于类型 profile 的优化
和基于分支 profile 的优化一样,基于类型 profile 的优化同样也是作出假设,从而精简控制流以及数据流。这两者的核心都是假设。
对于分支 profile,即时编译器假设的是仅执行某一分支;对于类型 profile,即时编译器假设的是对象的动态类型仅为类型 profile 中的那几个。
去优化
当假设失败的情况下,Java 虚拟机给出的解决方案便是去优化,即从执行即时编译生成的机器码切换回解释执行。
在生成的机器码中,即时编译器将在假设失败的位置上插入一个陷阱(trap)。该陷阱实际上是一条 call 指令,调用至 Java 虚拟机里专门负责去优化的方法。与普通的 call 指令不一样的是,去优化方法将更改栈上的返回地址,并不再返回即时编译器生成的机器码中。
在去优化的过程中,需要将当前机器码的执行状态转换至某一字节码之前的执行状态,并从该字节码开始执行。这便要求即时编译器在编译过程中记录好这两种执行状态的映射。
当根据映射关系创建好对应的解释执行栈桢后,Java 虚拟机便会采用 OSR 技术,动态替换栈上的内容,并在目标字节码处开始解释执行。
如果去优化的原因与基于 profile 的激进优化有关,那么生成的机器码需要在调用去优化方法时传入 Action_Reinterpret,表示不保留这一份机器码,而且需要重新收集程序的 profile。
这是因为基于 profile 的优化失败的时候,往往代表这程序的执行状态发生改变,因此需要更正已收集的 profile,以更好地反映新的程序执行状态。
13.即时编译器的中间表达形式
1. 中间表达形式(IR)
在编译原理课程中,我们通常将编译器分为前端和后端。其中,前端会对所输入的程序进行词法分析、语法分析、语义分析,然后生成中间表达形式,也就是 IR(Intermediate Representation )。后端会对 IR 进行优化,然后生成目标代码。
Java 字节码本身并不适合直接作为可供优化的 IR。这是因为现代编译器一般采用静态单赋值(Static Single Assignment,SSA)IR。这种 IR 的特点是每个变量只能被赋值一次,而且只有当变量被赋值之后才能使用。
即时编译器会将 Java 字节码转换成 SSA IR。更确切的说,是一张包含控制流和数据流的 IR 图,每个字节码对应其中的若干个节点(注意,有些字节码并没有对应的 IR 节点)。然后,即时编译器在 IR 图上面进行优化。
我们可以将每一种优化看成一个独立的图算法,它接收一个 IR 图,并输出经过转换后的 IR 图。整个编译器优化过程便是一个个优化串联起来的。
2. Sea-of-nodes
HotSpot 里的 C2 采用的是一种名为 Sea-of-Nodes 的 SSA IR。它的最大特点,便是去除了变量的概念,直接采用变量所指向的值,来进行运算。
3. Gloval Value Numbering
因 Sea-of-Nodes 而变得非常容易的优化技术 —— Gloval Value Numbering(GVN)。
GVN 是一种发现并消除等价计算的优化技术。举例来说,如果一段程序中出现了多次操作数相同的乘法,那么即时编译器可以将这些乘法并为一个,从而降低输出机器码的大小。如果这些乘法出现在同一执行路径上,那么 GVN 还将省下冗余的乘法操作。
总结:
即时编译器将所输入的 Java 字节码转换成 SSA IR,以便更好地进行优化。
具体来说,C2 和 Graal 采用的是一种名为 Sea-of-Nodes 的 IR,其特点用 IR 节点来代表程序中的值,并且将源程序中基于变量的计算转换为基于值的计算。
14.Java字节码
操作数栈
Java 字节码是 Java 虚拟机所使用的指令集。因此,它与 Java 虚拟机基于栈的计算模型是密不可分的。
在解释执行过程中,每当为 Java 方法分配栈桢时,Java 虚拟机往往需要开辟一块额外的空间作为操作数栈,来存放计算的操作数以及返回结果。
具体来说便是:执行每一条指令之前,Java 虚拟机要求该指令的操作数已被压入操作数栈中。在执行指令时,Java 虚拟机会将该指令所需的操作数弹出,并且将指令的结果重新压入栈中。
Java 字节码中有好几条指令是直接作用在操作数栈上的。最为常见的便是 dup: 复制栈顶元素,以及 pop:舍弃栈顶元素。
dup 指令常用于复制 new 指令所生成的未经初始化的引用。例如在下面这段代码的 foo 方法中,当执行 new 指令时,Java 虚拟机将指向一块已分配的、未初始化的内存的引用压入操作数栈中。
public void foo() {
Object o = new Object();
}
// 对应的字节码如下:
public void foo();
0 new java.lang.Object [3]
3 dup
4 invokespecial java.lang.Object() [8]
7 astore_1 [o]
8 return
long 类型或者 double 类型的值,需要占据两个栈单元。当遇到这些值时,我们需要同时复制栈顶两个单元的 dup2 指令,以及弹出栈顶两个单元的 pop2 指令。
在 Java 字节码中,有一部分指令可以直接将常量加载到操作数栈上。以 int 类型为例,Java 虚拟机既可以通过 iconst 指令加载 -1 至 5 之间的 int 值,也可以通过 bipush、sipush 加载一个字节、两个字节所能代表的 int 值。
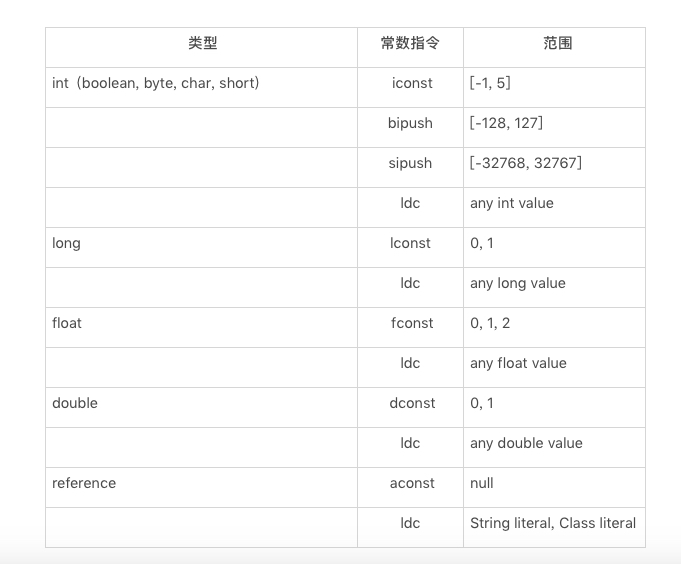
正常情况下,操作数栈的压入弹出都是一条条指令完成的。唯一的例外情况是在抛异常时,Java 虚拟机会清除操作数栈上的所有内容,而后将异常实例压入操作数栈上。
局部变量区
Java 方法栈桢的另外一个重要组成部分则是局部变量区,字节码程序可以将计算的结果缓存在局部变量区之中。
实际上,Java 虚拟机将局部变量区当成一个数组,依次存放 this 指针(仅非静态方法),所传入的参数,以及字节码中的局部变量。
和操作数栈一样,long 类型以及 double 类型的值将占据两个单元,其余类型仅占据一个单元。
存储在局部变量区的值,通常需要加载至操作数栈中,方能进行计算,得到计算结果后再存储至局部变量数组中。这些加载、存储指令是区分类型的。例如,int 类型的加载指令为 iload,存储指令为 istore。
局部变量区访问指令表
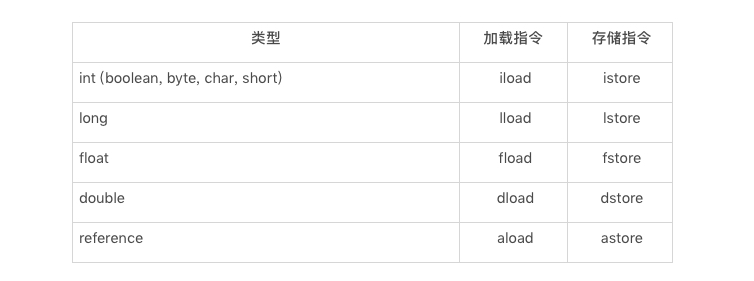
局部变量数组的加载、存储指令都需要指明所加载单元的下标。举例来说,aload 0 指的是加载第 0 个单元所存储的引用.
Java 字节码中唯一能够直接作用于局部变量区的指令是 iinc M N(M 为非负整数,N 为整数)。该指令指的是将局部变量数组的第 M 个单元中的 int 值增加 N,常用于 for 循环中自增量的更新。
public void foo() {
for (int i = 100; i>=0; i--) {}
}
// 对应的字节码如下:
public void foo();
0 bipush 100
2 istore_1 [i]
3 goto 9
6 iinc 1 -1 [i] // i--
9 iload_1 [i]
10 ifge 6
13 return
综合示例
这里我定义了一个 bar 方法。它将接收一个 int 类型的参数,进行一系列计算之后再返回。
public static int bar(int i) {
return ((i + 1) - 2) * 3 / 4;
}
// 对应的字节码如下:
Code:
stack=2, locals=1, args_size=1
0: iload_0
1: iconst_1
2: iadd
3: iconst_2
4: isub
5: iconst_3
6: imul
7: iconst_4
8: idiv
9: ireturn
对应的字节码中的 stack=2, locals=1 代表该方法需要的操作数栈空间为 2,局部变量数组空间为 1。
Java 字节码简介
Java 相关指令,包括各类具备高层语义的字节码,即 new(后跟目标类,生成该类的未初始化的对象),instanceof(后跟目标类,判断栈顶元素是否为目标类 / 接口的实例。是则压入 1,否则压入 0),checkcast(后跟目标类,判断栈顶元素是否为目标类 / 接口的实例。如果不是便抛出异常),athrow(将栈顶异常抛出),以及 monitorenter(为栈顶对象加锁)和 monitorexit(为栈顶对象解锁)。
此外,该类型的指令还包括字段访问指令,即静态字段访问指令 getstatic、putstatic,和实例字段访问指令 getfield、putfield。这四条指令均附带用以定位目标字段的信息,但所消耗的操作数栈元素皆不同。
方法调用指令,包括 invokestatic,invokespecial,invokevirtual,invokeinterface 以及 invokedynamic。
除 invokedynamic 外,其他的方法调用指令所消耗的操作数栈元素是根据调用类型以及目标方法描述符来确定的。在进行方法调用之前,程序需要依次压入调用者(invokestatic 不需要),以及各个参数。
public int neg(int i) {
return -i;
}
public int foo(int i) {
return neg(neg(i));
}
// foo 方法对应的字节码如下:foo 方法对应的字节码如下:
public int foo(int i);
0 aload_0 [this]
1 aload_0 [this]
2 iload_1 [i]
3 invokevirtual FooTest.neg(int) : int [25]
6 invokevirtual FooTest.neg(int) : int [25]
9 ireturn
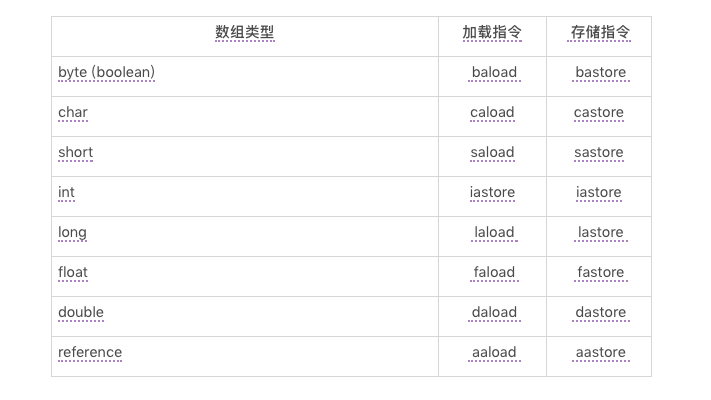
数组相关指令,包括新建基本类型数组的 newarray,新建引用类型数组的 anewarray,生成多维数组的 multianewarray,以及求数组长度的 arraylength。另外,它还包括数组的加载指令以及存储指令。这些指令是区分类型的。例如,int 数组的加载指令为 iaload,存储指令为 iastore。
数组访问指令表
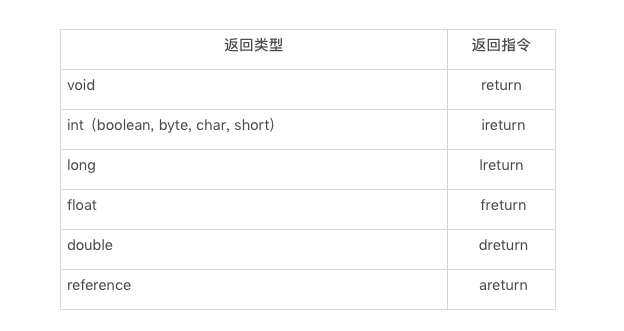
控制流指令,包括无条件跳转 goto,条件跳转指令,tableswitch 和 lookupswtich(前者针对密集的 cases,后者针对稀疏的 cases),返回指令,以及被废弃的 jsr,ret 指令。其中返回指令是区分类型的。例如,返回 int 值的指令为 ireturn。
返回指令表
除返回指令外,其他的控制流指令均附带一个或者多个字节码偏移量,代表需要跳转到的位置。例如下面的 abs 方法中偏移量为 1 的条件跳转指令,当栈顶元素小于 0 时,跳转至偏移量为 6 的字节码。
public int abs(int i) {
if (i >= 0) {
return i;
}
return -i;
}
// 对应的字节码如下所示:
public int abs(int i);
0 iload_1 [i]
1 iflt 6
4 iload_1 [i]
5 ireturn
6 iload_1 [i]
7 ineg
8 ireturn
15.方法内联
方法内联:在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
方法内联不仅可以消除调用本身带来的性能开销,还可以进一步触发更多的优化。因此,它可以算是编译优化里最为重要的一环。
以 getter/setter 为例,如果没有方法内联,在调用 getter/setter 时,程序需要保存当前方法的执行位置,创建并压入用于 getter/setter 的栈帧、访问字段、弹出栈帧,最后再恢复当前方法的执行。而当内联了对 getter/setter 的方法调用后,上述操作仅剩字段访问。
在 C2 中,方法内联是在解析字节码的过程中完成的。每当碰到方法调用字节码时,C2 将决定是否需要内联该方法调用。如果需要内联,则开始解析目标方法的字节码。
同 C2 一样,Graal 也会在解析字节码的过程中进行方法调用的内联。此外,Graal 还拥有一个独立的优化阶段,来寻找指代方法调用的 IR 节点,并将之替换为目标方法的 IR 图。
方法内联的条件
方法内联能够触发更多的优化。通常而言,内联越多,生成代码的执行效率越高。然而,对于即时编译器来说,内联越多,编译时间也就越长,而程序达到峰值性能的时刻也将被推迟。
即时编译器不会无限制地进行方法内联。下面我便列举即时编译器的部分内联规则。(其他的特殊规则,如自动拆箱总会被内联、Throwable 类的方法不能被其他类中的方法所内联,你可以直接参考JDK 的源代码。)
- 由 -XX:CompileCommand 中的 inline 指令指定的方法,以及由 @ForceInline 注解的方法(仅限于 JDK 内部方法),会被强制内联。 而由 -XX:CompileCommand 中的 dontinline 指令或 exclude 指令(表示不编译)指定的方法,以及由 @DontInline 注解的方法(仅限于 JDK 内部方法),则始终不会被内联。
- 如果调用字节码对应的符号引用未被解析、目标方法所在的类未被初始化,或者目标方法是 native 方法,都将导致方法调用无法内联。
- C2 不支持内联超过 9 层的调用(可以通过虚拟机参数 -XX:MaxInlineLevel 调整),以及 1 层的直接递归调用(可以通过虚拟机参数 -XX:MaxRecursiveInlineLevel 调整)。
- 即时编译器将根据方法调用指令所在的程序路径的热度,目标方法的调用次数及大小,以及当前 IR 图的大小来决定方法调用能否被内联。
去虚化
对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化(devirtualize),即转换为一个或多个直接调用,然后才能进行方法内联。
即时编译器的去虚化方式可分为完全去虚化以及条件去虚化(guarded devirtualization)。
完全去虚化是通过类型推导或者类层次分析(class hierarchy analysis),识别虚方法调用的唯一目标方法,从而将其转换为直接调用的一种优化手段。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化则是将虚方法调用转换为若干个类型测试以及直接调用的一种优化手段。它的关键在于找出需要进行比较的类型。
基于类型推导的完全去虚化将通过数据流分析推导出调用者的动态类型,从而确定具体的目标方法。
基于类层次分析的完全去虚化通过分析 Java 虚拟机中所有已被加载的类,判断某个抽象方法或者接口方法是否仅有一个实现。如果是,那么对这些方法的调用将只能调用至该具体实现中。
条件去虚化
将调用者的动态类型,依次与 Java 虚拟机所收集的类型 Profile 中记录的类型相比较。如果匹配,则直接调用该记录类型所对应的目标方法。
第一,如果类型 Profile 是完整的,也就是说,所有出现过的动态类型都被记录至类型 Profile 之中,那么即时编译器可以让程序进行去优化,重新收集类型 Profile。
第二,如果类型 Profile 是不完整的,也就是说,某些出现过的动态类型并没有记录至类型 Profile 之中,那么重新收集并没有多大作用。此时,即时编译器可以让程序进行原本的虚调用,通过内联缓存进行调用,或者通过方法表进行动态绑定。
在 C2 中,如果类型 Profile 是不完整的,即时编译器压根不会进行条件去虚化,而是直接使用内联缓存或者方法表。
16.HotSpot虚拟机的intrinsic
HotSpot 虚拟机将为标注了@HotSpotIntrinsicCandidate注解的方法额外维护一套高效实现。对这些方法的调用,会被 HotSpot 虚拟机替换成高效的指令序列。而原本的方法实现则会被忽略掉。如果 Java 核心类库的开发者更改了原本的实现,那么虚拟机中的高效实现也需要进行相应的修改,以保证程序语义一致。
之所以这么实现是因为高效实现通常依赖于具体的 CPU 指令,而这些 CPU 指令不好在 Java 源程序中表达。再者,换了一个体系架构,说不定就没有对应的 CPU 指令,也就无法进行 intrinsic 优化了。
intrinsic 与 CPU 指令
一般我们在做整数加法时,需要考虑结果是否会溢出,并且在溢出的情况下作出相应的处理,以保证程序的正确性。
Java 核心类库提供了一个Math.addExact方法。它将接收两个 int 值(或 long 值)作为参数,并返回这两个 int 值的和。当这两个 int 值之和溢出时,该方法将抛出ArithmeticException异常。
@HotSpotIntrinsicCandidate
public static int addExact(int x, int y) {
int r = x + y;
// HD 2-12 Overflow iff both arguments have the opposite sign of the result
if (((x ^ r) & (y ^ r)) < 0) {
throw new ArithmeticException("integer overflow");
}
return r;
}
在 Java 层面判断 int 值之和是否溢出比较费事。我们需要分别比较两个 int 值与它们的和的符号是否不同。如果都不同,那么我们便认为这两个 int 值之和溢出。对应的实现便是两个异或操作,一个与操作,以及一个比较操作。
在 X86_64 体系架构中,大部分计算指令都会更新状态寄存器(FLAGS register),其中就有表示指令结果是否溢出的溢出标识位(overflow flag)。因此,我们只需在加法指令之后比较溢出标志位,便可以知道 int 值之和是否溢出了。
intrinsic 与方法内联
HotSpot 虚拟机中,intrinsic 的实现方式分为两种。
一种是独立的桩程序。它既可以被解释执行器利用,直接替换对原方法的调用;也可以被即时编译器所利用,它把代表对原方法的调用的 IR 节点,替换为对这些桩程序的调用的 IR 节点。以这种形式实现的 intrinsic 比较少,主要包括Math类中的一些方法。
另一种则是特殊的编译器 IR 节点。显然,这种实现方式仅能够被即时编译器所利用。
在编译过程中,即时编译器会将对原方法的调用的 IR 节点,替换成特殊的 IR 节点,并参与接下来的优化过程。最终,即时编译器的后端将根据这些特殊的 IR 节点,生成指定的 CPU 指令。大部分的 intrinsic 都是通过这种方式实现的。
事实上,不少被标记为 intrinsic 的方法都是 native 方法。原本对这些 native 方法的调用需要经过 JNI(Java Native Interface),其性能开销十分巨大。但是,经过即时编译器的 intrinsic 优化之后,这部分 JNI 开销便直接消失不见,并且最终的结果也十分高效。
HotSpot 虚拟机定义了三百多个 intrinsic。其中比较特殊的有Unsafe类的方法,基本上使用 java.util.concurrent 包便会间接使用到Unsafe类的 intrinsic。除此之外,String类和Arrays类中的 intrinsic 也比较特殊。即时编译器将为之生成非常高效的 SIMD 指令。
17.逃逸分析
ArrayList.iterator方法将创建一个ArrayList$Itr实例。因此,有同学认为我们应当避免在热点代码中使用 foreach 循环,并且直接使用基于ArrayList.size以及ArrayList.get的循环方式(如下所示),以减少对 Java 堆的压力。
public class ArrayList ... {
public Iterator<E> iterator() {
return new Itr();
}
实际上,Java 虚拟机中的即时编译器可以将ArrayList.iterator方法中的实例创建操作给优化掉。不过,这需要方法内联以及逃逸分析的协作。
逃逸分析是“一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针”。
在 Java 虚拟机的即时编译语境下,逃逸分析将判断新建的对象是否逃逸。即时编译器判断对象是否逃逸的依据,一是对象是否被存入堆中(静态字段或者堆中对象的实例字段),二是对象是否被传入未知代码中。
前者很好理解:一旦对象被存入堆中,其他线程便能获得该对象的引用。即时编译器也因此无法追踪所有使用该对象的代码位置。
关于后者,由于 Java 虚拟机的即时编译器是以方法为单位的,对于方法中未被内联的方法调用,即时编译器会将其当成未知代码,毕竟它无法确认该方法调用会不会将调用者或所传入的参数存储至堆中。因此,我们可以认为方法调用的调用者以及参数是逃逸的。
通常来说,即时编译器里的逃逸分析是放在方法内联之后的,以便消除这些“未知代码”入口。
基于逃逸分析的优化
即时编译器可以根据逃逸分析的结果进行诸如锁消除、栈上分配以及标量替换的优化。
锁消除:如果即时编译器能够证明锁对象不逃逸,那么对该锁对象的加锁、解锁操作没有意义。这是因为其他线程并不能获得该锁对象,因此也不可能对其进行加锁。在这种情况下,即时编译器可以消除对该不逃逸锁对象的加锁、解锁操作。
我们知道,Java 虚拟机中对象都是在堆上分配的,而堆上的内容对任何线程都是可见的。与此同时,Java 虚拟机需要对所分配的堆内存进行管理,并且在对象不再被引用时回收其所占据的内存。
如果逃逸分析能够证明某些新建的对象不逃逸,那么 Java 虚拟机完全可以将其分配至栈上,并且在 new 语句所在的方法退出时,通过弹出当前方法的栈桢来自动回收所分配的内存空间。这样一来,我们便无须借助垃圾回收器来处理不再被引用的对象。
不过,由于实现起来需要更改大量假设了“对象只能堆分配”的代码,因此 HotSpot 虚拟机并没有采用栈上分配,而是使用了标量替换这么一项技术。
所谓的标量,就是仅能存储一个值的变量,比如 Java 代码中的局部变量。与之相反,聚合量则可能同时存储多个值,其中一个典型的例子便是 Java 对象。
标量替换这项优化技术,可以看成将原本对对象的字段的访问,替换为一个个局部变量的访问。举例来说,前面经过内联之后的 forEach 代码可以被转换为如下代码:
public void forEach(ArrayList<Object> list, Consumer<Object> f) {
// Itr iter = new Itr; // 经过标量替换后该分配无意义,可以被优化掉
int cursor = 0; // 标量替换 原来是:iter.cursor = 0
int lastRet = -1; // 标量替换 原来是:iter.lastRet = -1
int expectedModCount = list.modCount; // 标量替换 原来是:iter.expectedModCount = list.modCount
while (cursor < list.size) {
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor;
if (i >= list.size)
throw new NoSuchElementException();
Object[] elementData = list.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
lastRet = i;
Object obj = elementData[i];
f.accept(obj);
}
}
可以看到,原本需要在内存中连续分布的对象,现已被拆散为一个个单独的字段cursor,lastRet,以及expectedModCount。这些字段既可以存储在栈上,也可以直接存储在寄存器中。而该对象的对象头信息则直接消失了,不再被保存至内存之中。
由于该对象没有被实际分配,因此和栈上分配一样,它同样可以减轻垃圾回收的压力。与栈上分配相比,它对字段的内存连续性不做要求,而且,这些字段甚至可以直接在寄存器中维护,无须浪费任何内存空间。
部分逃逸分析
C2 的逃逸分析与控制流无关,相对来说比较简单。Graal 则引入了一个与控制流有关的逃逸分析,名为部分逃逸分析(partial escape analysis)[2]。它解决了所新建的实例仅在部分程序路径中逃逸的情况。
public static void bar(boolean cond) {
Object foo = new Object();
if (cond) {
foo.hashCode();
}
}
// 可以手工优化为:
public static void bar(boolean cond) {
if (cond) {
Object foo = new Object();
foo.hashCode();
}
}
部分逃逸分析将根据控制流信息,判断出新建对象仅在部分分支中逃逸,并且将对象的新建操作推延至对象逃逸的分支中。这将使得原本因对象逃逸而无法避免的新建对象操作,不再出现在只执行 if-else 分支的程序路径之中。
综上,与 C2 所使用的逃逸分析相比,Graal 所使用的部分逃逸分析能够优化更多的情况,不过它编译时间也更长一些。
18.字段访问相关优化
字段读取优化:当即时编译器遇到对同一字段的读取节点时,如果缓存值还没有失效,那么它会将读取节点替换为该缓存值。
即时编译器将在 volatile 字段访问前后插入内存屏障节点。这些内存屏障节点会阻止即时编译器将屏障之前所缓存的值用于屏障之后的读取节点之上。
同理,加锁、解锁操作也同样会阻止即时编译器的字段读取优化。
字段存储优化:如果一个字段先后被存储了两次,而且这两次存储之间没有对第一次存储内容的读取,那么即时编译器可以将第一个字段存储给消除掉。
如果所存储的字段被标记为 volatile,那么即时编译器也不能将冗余的存储操作消除掉。
死代码消除:局部变量的死存储(dead store)同样也涉及了冗余存储。这是死代码消除(dead code eliminiation)的一种。不过,由于 Sea-of-Nodes IR 的特性,死存储的优化无须额外代价。
另一种死代码消除则是不可达分支消除。不可达分支就是任何程序路径都不可到达的分支,我们之前已经多次接触过了。
在即时编译过程中,我们经常因为方法内联、常量传播以及基于 profile 的优化等,生成许多不可达分支。通过消除不可达分支,即时编译器可以精简数据流,并且减少编译时间以及最终生成机器码的大小。
总结:
即时编译器将沿着控制流缓存字段存储、读取的值,并在接下来的字段读取操作时直接使用该缓存值。
这要求生成缓存值的访问以及使用缓存值的读取之间没有方法调用、内存屏障,或者其他可能存储该字段的节点。
即时编译器还会优化冗余的字段存储操作。如果一个字段的两次存储之间没有对该字段的读取操作、方法调用以及内存屏障,那么即时编译器可以将第一个冗余的存储操作给消除掉。
此外,我还介绍了死代码消除的两种形式。第一种是局部变量的死存储消除以及部分死存储消除。它们可以通过转换为 Sea-of-Nodes IR 来完成。第二种则是不可达分支。通过消除不可达分支,即时编译器可以精简数据流,并且减少编译时间以及最终生成机器码的大小。
19.循环优化
循环无关代码外提
循环无关代码外提将循环中值不变的表达式,或者循环无关检测外提至循环之前,以避免在循环中重复进行冗余计算。前者是通过 Sea-of-Nodes IR 以及节点调度来共同完成的,而后者则是通过一个独立优化 —— 循环预测来完成的。循环预测还可以外提循环有关的数组下标范围检测。
int foo(int x, int y, int[] a) {
int sum = 0;
for (int i = 0; i < a.length; i++) {
sum += x * y + a[i];
}
return sum;
}
理想情况下,上面这段代码经过循环无关代码外提之后,等同于下面这一手工优化版本。
int fooManualOpt(int x, int y, int[] a) {
int sum = 0;
int t0 = x * y;
int t1 = a.length;
for (int i = 0; i < t1; i++) {
sum += t0 + a[i];
}
return sum;
}
循环展开
它指的是在循环体中重复多次循环迭代,并减少循环次数的编译优化。
for (int i = START; i < LIMIT; i += STRIDE) { .. }
// 等价于
int i = START;
while (i < LIMIT) {
..
i += STRIDE;
}
循环展开的缺点显而易见:它可能会增加代码的冗余度,导致所生成机器码的长度大幅上涨。
在 C2 中,只有计数循环(Counted Loop)才能被展开。所谓的计数循环需要满足如下四个条件。
- 维护一个循环计数器,并且基于计数器的循环出口只有一个(但可以有基于其他判断条件的出口)。
- 循环计数器的类型为 int、short 或者 char(即不能是 byte、long,更不能是 float 或者 double)。
- 每个迭代循环计数器的增量为常数。
- 循环计数器的上限(增量为正数)或下限(增量为负数)是循环无关的数值。
循环展开有一种特殊情况,那便是完全展开(Full Unroll)。当循环的数目是固定值而且非常小时,即时编译器会将循环全部展开。此时,原本循环中的循环判断语句将不复存在,取而代之的是若干个顺序执行的循环体。
int foo(int[] a) {
int sum = 0;
for (int i = 0; i < 4; i++) {
sum += a[i];
}
return sum;
}
上述代码将被完全展开为下述代码:
int foo(int[] a) {
int sum = 0;
sum += a[0];
sum += a[1];
sum += a[2];
sum += a[3];
return sum;
}
循环判断外提:指的是将循环中的 if 语句外提至循环之前,并且在该 if 语句的两个分支中分别放置一份循环代码。
int foo(int[] a) {
int sum = 0;
for (int i = 0; i < a.length; i++) {
if (a.length > 4) {
sum += a[i];
}
}
return sum;
}
上面这段代码经过循环判断外提之后,将变成下面这段代码:
int foo(int[] a) {
int sum = 0;
if (a.length > 4) {
for (int i = 0; i < a.length; i++) {
sum += a[i];
}
}
return sum;
}
循环剥离:指的是将循环的前几个迭代或者后几个迭代剥离出循环的优化方式。
int foo(int[] a) {
int j = 0;
int sum = 0;
for (int i = 0; i < a.length; i++) {
sum += a[j];
j = i;
}
return sum;
}
上面这段代码剥离了第一个迭代后,将变成下面这段代码:
int foo(int[] a) {
int sum = 0;
if (0 < a.length) {
sum += a[0];
for (int i = 1; i < a.length; i++) {
sum += a[i - 1];
}
}
return sum;
}
20.向量化
void foo(byte[] dst, byte[] src) {
for (int i = 0; i < dst.length - 4; i += 4) {
dst[i] = src[i];
dst[i+1] = src[i+1];
dst[i+2] = src[i+2];
dst[i+3] = src[i+3];
}
... // post-loop
}
由于数组元素在内存中是连续的,当从src[i]的内存地址处读取 32 位的内容时,我们将一并读取src[i]至src[i+3]的值。同样,当向dst[i]的内存地址处写入 32 位的内容时,我们将一并写入dst[i]至dst[i+3]的值。
通过综合这两个批量操作,我们可以使用一条内存读取指令以及一条内存写入指令,完成上面代码中循环体内的全部工作。如果我们用x[i:i+3]来指代x[i]至x[i+3]合并后的值,那么上述优化可以被表述成如下所示的代码:
void foo(byte[] dst, byte[] src) {
for (int i = 0; i < dst.length - 4; i += 4) {
dst[i:i+3] = src[i:i+3];
}
... // post-loop
}
SIMD 指令
我们知道,X86_64 体系架构上通用寄存器的大小为 64 位(即 8 个字节),无法暂存int 数组,或者 long 数组这些超长的数据。因此,即时编译器将借助长度足够的 XMM 寄存器,来完成 int 数组与 long 数组的向量化读取和写入操作。(为了实现方便,byte 数组的向量化读取、写入操作同样使用了 XMM 寄存器。)
128 位 XMM 寄存器里的值可以看成 16 个 byte 值组成的向量,或者 8 个 short 值组成的向量,4 个 int 值组成的向量,两个 long 值组成的向量;而 SIMD 指令PADDB、PADDW、PADDD以及PADDQ,将分别实现 byte 值、short 值、int 值或者 long 值的向量加法。
void foo(int[] a, int[] b, int[] c) {
for (int i = 0; i < c.length; i++) {
c[i] = a[i] + b[i];
}
}
上面这段代码经过向量化优化之后,将使用PADDD指令来实现c[i:i+3] = a[i:i+3] + b[i:i+3]。
也就是说,原本需要c.length次加法操作的代码,现在最少只需要c.length/4次向量加法即可完成。因此,SIMD 指令也被看成 CPU 指令级别的并行。
使用 SIMD 指令的 HotSpot Intrinsic
SIMD 指令虽然非常高效,但是使用起来却很麻烦。这主要是因为不同的 CPU 所支持的 SIMD 指令可能不同。一般来说,越新的 SIMD 指令,它所支持的寄存器长度越大,功能也越强。
Java 虚拟机所执行的 Java 字节码是平台无关的。它首先会被解释执行,而后反复执行的部分才会被 Java 虚拟机即时编译为机器码。换句话说,在进行即时编译的时候,Java 虚拟机已经运行在目标 CPU 之上,可以轻易地得知其所支持的指令集。
然而,Java 字节码的平台无关性却引发了另一个问题,那便是 Java 程序无法像 C++ 程序那样,直接使用由 Intel 提供的,将被替换为具体 SIMD 指令的 intrinsic 方法 [2]。
HotSpot 虚拟机提供的替代方案是 Java 层面的 intrinsic 方法,这些 intrinsic 方法的语义要比单个 SIMD 指令复杂得多。在运行过程中,HotSpot 虚拟机将根据当前体系架构来决定是否将对该 intrinsic 方法的调用替换为另一高效的实现。如果不,则使用原本的 Java 实现。
这种类型的 intrinsic 屈指可数,如用于复制数组的System.arraycopy和Arrays.copyOf,用于比较数组的Arrays.equals,以及 Java 9 新加入的Arrays.compare和Arrays.mismatch,以及字符串相关的一些方法String.indexOf、StringLatin1.inflate。
自动向量化
即时编译器的自动向量化将针对能够展开的计数循环,进行向量化优化。
自动向量化的条件:
- 循环变量的增量应为 1,即能够遍历整个数组。
- 循环变量不能为 long 类型,否则 C2 无法将循环识别为计数循环。
- 循环迭代之间最好不要有数据依赖,例如出现类似于a[i] = a[i-1]的语句。当循环展开之后,循环体内存在数据依赖,那么 C2 无法进行自动向量化。
- 循环体内不要有分支跳转。
- 不要手工进行循环展开。如果 C2 无法自动展开,那么它也将无法进行自动向量化。
总结:
向量化优化借助的是 CPU 的 SIMD 指令,即通过单条指令控制多组数据的运算。它被称为 CPU 指令级别的并行。
HotSpot 虚拟机运用向量化优化的方式有两种。第一种是使用 HotSpot intrinsic,在调用特定方法的时候替换为使用了 SIMD 指令的高效实现。Intrinsic 属于点覆盖,只有当应用程序明确需要这些 intrinsic 的语义,才能够获得由它带来的性能提升。
第二种是依赖即时编译器进行自动向量化,在循环展开优化之后将不同迭代的运算合并为向量运算。自动向量化的触发条件较为苛刻,因此也无法覆盖大多数用例。
21.注解处理器
注解(annotation)是 Java 5 引入的,用来为类、方法、字段、参数等 Java 结构提供额外信息的机制。
package java.lang;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
@Override注解本身被另外两个元注解(即作用在注解上的注解)所标注。其中,@Target用来限定目标注解所能标注的 Java 结构,这里@Override便只能被用来标注方法。
@Retention则用来限定当前注解生命周期。注解共有三种不同的生命周期:SOURCE,CLASS或RUNTIME,分别表示注解只出现在源代码中,只出现在源代码和字节码中,以及出现在源代码、字节码和运行过程中。
这里@Override便只能出现在源代码中。一旦标注了@Override的方法所在的源代码被编译为字节码,该注解便会被擦除。
Java 的注解机制允许开发人员自定义注解。这些自定义注解同样可以为 Java 编译器添加编译规则。不过,这种功能需要由开发人员提供,并且以插件的形式接入 Java 编译器中,这些插件我们称之为注解处理器(annotation processor)。
除了引入新的编译规则之外,注解处理器还可以用于修改已有的 Java 源文件(不推荐),或者生成新的 Java 源文件。
注解处理器的原理
Java 源代码的编译过程可分为三个步骤:
- 将源文件解析为抽象语法树;
- 调用已注册的注解处理器;
- 生成字节码。
如果在第 2 步调用注解处理器过程中生成了新的源文件,那么编译器将重复第 1、2 步,解析并且处理新生成的源文件。每次重复我们称之为一轮(Round)。
也就是说,第一轮解析、处理的是输入至编译器中的已有源文件。如果注解处理器生成了新的源文件,则开始第二轮、第三轮,解析并且处理这些新生成的源文件。当注解处理器不再生成新的源文件,编译进入最后一轮,并最终进入生成字节码的第 3 步。
public interface Processor {
void init(ProcessingEnvironment processingEnv);
Set<String> getSupportedAnnotationTypes();
SourceVersion getSupportedSourceVersion();
boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv);
...
}
所有的注解处理器类都需要实现接口Processor。该接口主要有四个重要方法。其中,init方法用来存放注解处理器的初始化代码。之所以不用构造器,是因为在 Java 编译器中,注解处理器的实例是通过反射 API 生成的。也正是因为使用反射 API,每个注解处理器类都需要定义一个无参数构造器。
通常来说,当编写注解处理器时,我们不声明任何构造器,并依赖于 Java 编译器,为之插入一个无参数构造器。而具体的初始化代码,则放入init方法之中。
在剩下的三个方法中,getSupportedAnnotationTypes方法将返回注解处理器所支持的注解类型,这些注解类型只需用字符串形式表示即可。
getSupportedSourceVersion方法将返回该处理器所支持的 Java 版本,通常,这个版本需要与你的 Java 编译器版本保持一致;而process方法则是最为关键的注解处理方法。
JDK 提供了一个实现Processor接口的抽象类AbstractProcessor。该抽象类实现了init、getSupportedAnnotationTypes和getSupportedSourceVersion方法。
它的子类可以通过@SupportedAnnotationTypes和@SupportedSourceVersion注解来声明所支持的注解类型以及 Java 版本。
process方法涉及各种不同类型的Element,分别指代 Java 程序中的各个结构。如TypeElement指代类或者接口,VariableElement指代字段、局部变量、enum 常量等,ExecutableElement指代方法或者构造器。
package foo; // PackageElement
class Foo { // TypeElement
int a; // VariableElement
static int b; // VariableElement
Foo () {} // ExecutableElement
void setA ( // ExecutableElement
int newA // VariableElement
) {}
}
我们可以通过TypeElement.getEnclosedElements方法,获得上面这段代码中Foo类的字段、构造器以及方法。
我们也可以通过ExecutableElement.getParameters方法,获得setA方法的参数。
在将该注解处理器编译成 class 文件后,我们便可以将其注册为 Java 编译器的插件,并用来处理其他源代码。注册的方法主要有两种。
第一种是直接使用 javac 命令的-processor参数:
$ javac -cp /CLASSPATH/TO/CheckGetterProcessor -processor bar.CheckGetterProcessor Foo.java
error: Class 'Foo' is annotated as @CheckGetter, but field 'a' is without getter
1 error
第二种则是将注解处理器编译生成的 class 文件压缩入 jar 包中,并在 jar 包的配置文件中记录该注解处理器的包名及类名,即bar.CheckGetterProcessor。
当启动 Java 编译器时,它会寻找 classpath 路径上的 jar 包是否包含上述配置文件,并自动注册其中记录的注解处理器。
$ javac -cp /PATH/TO/CheckGetterProcessor.jar Foo.java
error: Class 'Foo' is annotated as @CheckGetter, but field 'a' is without getter
1 error
利用注解处理器生成源代码
注解处理器并不能真正地修改已有源代码。这里指的是修改由 Java 源代码生成的抽象语法树,在其中修改已有树节点或者插入新的树节点,从而使生成的字节码发生变化。
lombok并根据注解的内容来修改已有的源代码。例如它提供了@Getter和@Setter注解,能够为程序自动添加getter以及setter方法。
21.基准测试框架JMH
Java 虚拟机、操作系统,乃至硬件系统给性能测试所带来的影响
Java 虚拟机:堆空间的自适配,即时编译等。
操作系统和硬件系统:电源管理策略。在许多机器,特别是笔记本上,操作系统会动态配置 CPU 的频率。而 CPU 的频率又直接影响到性能测试的数据,因此短时间的性能测试得出的数据未必可靠。CPU 缓存、分支预测器,以及超线程技术,都会对测试结果造成影响。
JMH
由于许多即时编译器的开发人员参与了该项目,因此 JMH 内置了许多功能来控制即时编译器的优化。对于其他影响性能评测的因素,JMH 也提供了不少策略来降低影响,甚至是彻底解决。
因此,使用这个性能基准测试框架的开发人员,可以将精力完全集中在所要测试的业务逻辑,并以最小的代价控制除了业务逻辑之外的可能影响性能的因素。
不过,JMH 也不能完美解决性能测试数据的偏差问题。它甚至会在每次运行的输出结果中打印上述语句,所以,JMH 的开发人员也给出了一个小忠告:我们开发人员不要轻信 JMH 的性能测试数据,不要基于这些数据乱下结论。
通常来说,性能基准测试的结果反映的是所测试的业务逻辑在所运行的 Java 虚拟机,操作系统,硬件系统这一组合上的性能指标,而根据这些性能指标得出的通用结论则需要经过严格论证。
开发人员仅需将所要测试的业务逻辑通过@Benchmark注解,便可以让 JMH 的注解处理器自动生成真正的性能测试代码,以及相应的性能测试配置文件。
JMH 的进阶功能
@Fork允许开发人员指定所要 Fork 出的 Java 虚拟机的数目。
@BenchmarkMode允许指定性能数据的格式。
@Warmup和@Measurement允许配置预热迭代或者测试迭代的数目,每个迭代的时间以及每个操作包含多少次对测试方法的调用。
@State允许配置测试程序的状态。测试前对程序状态的初始化以及测试后对程序状态的恢复或者校验可分别通过@Setup和@TearDown来实现。
22.JDK 中用于监控及诊断的命令行工具
1.jps将打印所有正在运行的 Java 进程。
$ jps -mlv
18331 org.example.Foo Hello World
18332 jdk.jcmd/sun.tools.jps.Jps -mlv -Dapplication.home=/Library/Java/JavaVirtualMachines/jdk-11.jdk/Contents/Home -Xms8m -Djdk.module.main=jdk.jcmd
2.jstat允许用户查看目标 Java 进程的类加载、即时编译以及垃圾回收相关的信息。它常用于检测垃圾回收问题以及内存泄漏问题。
$ jstat -gc 22126 1s 4
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT CGC CGCT GCT
17472,0 17472,0 0,0 0,0 139904,0 47146,4 349568,0 21321,0 30020,0 28001,8 4864,0 4673,4 22 0,080 3 0,270 0 0,000 0,350
17472,0 17472,0 420,6 0,0 139904,0 11178,4 349568,0 21321,0 30020,0 28090,1 4864,0 4674,2 28 0,084 3 0,270 0 0,000 0,354
17472,0 17472,0 0,0 403,9 139904,0 139538,4 349568,0 21323,4 30020,0 28137,2 4864,0 4674,2 34 0,088 4 0,359 0 0,000 0,446
17472,0 17472,0 0,0 0,0 139904,0 0,0 349568,0 21326,1 30020,0 28093,6 4864,0 4673,4 38 0,091 5 0,445 0 0,000 0,536
3.jmap允许用户统计目标 Java 进程的堆中存放的 Java 对象,并将它们导出成二进制文件。
$ jmap -histo 22574
num #instances #bytes class name (module)
-------------------------------------------------------
1: 500004 20000160 org.python.core.PyComplex
2: 570866 18267712 org.python.core.PyFloat
3: 360295 18027024 [B (java.base@11)
4: 339394 11429680 [Lorg.python.core.PyObject;
5: 308637 11194264 [Ljava.lang.Object; (java.base@11)
6: 301378 9291664 [I (java.base@11)
7: 225103 9004120 java.math.BigInteger (java.base@11)
8: 507362 8117792 org.python.core.PySequence$1
9: 285009 6840216 org.python.core.PyLong
10: 282908 6789792 java.lang.String (java.base@11)
...
2281: 1 16 traceback$py
2282: 1 16 unicodedata$py
Total 5151277 167944400
由于jmap将访问堆中的所有对象,为了保证在此过程中不被应用线程干扰,jmap需要借助安全点机制,让所有线程停留在不改变堆中数据的状态。
4.jinfo将打印目标 Java 进程的配置参数,并能够改动其中 manageabe 的参数。
$ jinfo 31185
Java System Properties:
gopherProxySet=false
awt.toolkit=sun.lwawt.macosx.LWCToolkit
java.specification.version=11
sun.cpu.isalist=
sun.jnu.encoding=UTF-8
...
VM Flags:
-XX:CICompilerCount=4 -XX:ConcGCThreads=3 -XX:G1ConcRefinementThreads=10 -XX:G1HeapRegionSize=2097152 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=536870912 -XX:MarkStackSize=4194304 -XX:MaxHeapSize=8589934592 -XX:MaxNewSize=5152702464 -XX:MinHeapDeltaBytes=2097152 -XX:NonNMethodCodeHeapSize=5835340 -XX:NonProfiledCodeHeapSize=122911450 -XX:ProfiledCodeHeapSize=122911450 -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC
VM Arguments:
jvm_args: -Xlog:gc -Xmx1024m
java_command: org.example.Foo
java_class_path (initial): .
Launcher Type: SUN_STANDARD
5.jstack将打印目标 Java 进程中各个线程的栈轨迹、线程状态、锁状况等信息。它还将自动检测死锁。
$ jstack 31634
...
"Thread-0" #12 prio=5 os_prio=31 cpu=1.32ms elapsed=34.24s tid=0x00007fb08601c800 nid=0x5d03 waiting for monitor entry [0x000070000bc7e000]
java.lang.Thread.State: BLOCKED (on object monitor)
at DeadLock.foo(DeadLock.java:18)
- waiting to lock <0x000000061ff904c0> (a java.lang.Object)
- locked <0x000000061ff904b0> (a java.lang.Object)
at DeadLock$$Lambda$1/0x0000000800060840.run(Unknown Source)
at java.lang.Thread.run(java.base@11/Thread.java:834)
"Thread-1" #13 prio=5 os_prio=31 cpu=1.43ms elapsed=34.24s tid=0x00007fb08601f800 nid=0x5f03 waiting for monitor entry [0x000070000bd81000]
java.lang.Thread.State: BLOCKED (on object monitor)
at DeadLock.bar(DeadLock.java:33)
- waiting to lock <0x000000061ff904b0> (a java.lang.Object)
- locked <0x000000061ff904c0> (a java.lang.Object)
at DeadLock$$Lambda$2/0x0000000800063040.run(Unknown Source)
at java.lang.Thread.run(java.base@11/Thread.java:834)
...
JNI global refs: 6, weak refs: 0
Found one Java-level deadlock:
=============================
"Thread-0":
waiting to lock monitor 0x00007fb083015900 (object 0x000000061ff904c0, a java.lang.Object),
which is held by "Thread-1"
"Thread-1":
waiting to lock monitor 0x00007fb083015800 (object 0x000000061ff904b0, a java.lang.Object),
which is held by "Thread-0"
Java stack information for the threads listed above:
===================================================
"Thread-0":
at DeadLock.foo(DeadLock.java:18)
- waiting to lock <0x000000061ff904c0> (a java.lang.Object)
- locked <0x000000061ff904b0> (a java.lang.Object)
at DeadLock$$Lambda$1/0x0000000800060840.run(Unknown Source)
at java.lang.Thread.run(java.base@11/Thread.java:834)
"Thread-1":
at DeadLock.bar(DeadLock.java:33)
- waiting to lock <0x000000061ff904b0> (a java.lang.Object)
- locked <0x000000061ff904c0> (a java.lang.Object)
at DeadLock$$Lambda$2/0x0000000800063040.run(Unknown Source)
at java.lang.Thread.run(java.base@11/Thread.java:834)
Found 1 deadlock.
6.jcmd则是一把瑞士军刀,可以用来实现前面除了jstat之外所有命令的功能。
23.Java Mission Control
Java Mission Control(JMC)是 Java 虚拟机平台上的性能监控工具。它包含一个 GUI 客户端,以及众多用来收集 Java 虚拟机性能数据的插件,如 JMX Console(能够访问用来存放虚拟机各个子系统运行数据的MXBeans),以及虚拟机内置的高效 profiling 工具 Java Flight Recorder(JFR)。
JFR 的性能开销很小,在默认配置下平均低于 1%。与其他工具相比,JFR 能够直接访问虚拟机内的数据,并且不会影响虚拟机的优化。因此,它非常适用于生产环境下满负荷运行的 Java 程序。
当启用时,JFR 将记录运行过程中发生的一系列事件。其中包括 Java 层面的事件,如线程事件、锁事件,以及 Java 虚拟机内部的事件,如新建对象、垃圾回收和即时编译事件。
按照发生时机以及持续时间来划分,JFR 的事件共有四种类型,它们分别为以下四种。
- 瞬时事件(Instant Event),用户关心的是它们发生与否,例如异常、线程启动事件。
- 持续事件(Duration Event),用户关心的是它们的持续时间,例如垃圾回收事件。
- 计时事件(Timed Event),是时长超出指定阈值的持续事件。
- 取样事件(Sample Event),是周期性取样的事件。
取样事件的其中一个常见例子便是方法抽样(Method Sampling),即每隔一段时间统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法。
JFR 的启用方式主要有三种。
第一种是在运行目标 Java 程序时添加-XX:StartFlightRecording=参数。
在下面这条命令中,JFR 将会在 Java 虚拟机启动 5s 后(对应delay=5s)收集数据,持续 20s(对应duration=20s)。当收集完毕后,JFR 会将收集得到的数据保存至指定的文件中(对应filename=myrecording.jfr)。
$ java -XX:StartFlightRecording=delay=5s,duration=20s,filename=myrecording.jfr,settings=profile MyApp
settings=profile指定了 JFR 所收集的事件类型。默认情况下,JFR 将加载配置文件$JDK/lib/jfr/default.jfc,并识别其中所包含的事件类型。当使用了settings=profile配置时,JFR 将加载配置文件$JDK/lib/jfr/profile.jfc。该配置文件所包含的事件类型要多于默认的default.jfc,因此性能开销也要大一些(约为 2%)。default.jfc以及profile.jfc均为 XML 文件。
在下面这条命令中,JFR 将在 Java 虚拟机启动之后持续收集数据,直至进程退出。在进程退出时(对应dumponexit=true),JFR 会将收集得到的数据保存至指定的文件中。
$ java -XX:StartFlightRecording=dumponexit=true,filename=myrecording.jfr MyApp
在下面这条命令中,JFR 将在 Java 虚拟机启动之后持续收集数据,直至进程退出。该命令不会主动保存 JFR 收集得到的数据。
$ java -XX:StartFlightRecording=maxage=10m,maxsize=100m,name=SomeLabel MyApp
由于 JFR 将持续收集数据,如果不加以限制,那么 JFR 可能会填满硬盘的所有空间。因此,我们有必要对这种模式下所收集的数据进行限制。
在这条命令中,maxage=10m指的是仅保留 10 分钟以内的事件,maxsize=100m指的是仅保留 100MB 以内的事件。一旦所收集的事件达到其中任意一个限制,JFR 便会开始清除不合规格的事件。
该命令不会主动保存 JFR 收集得到的数据。用户需要运行jcmd
这便是 JFR 的第二种启用方式,即通过jcmd来让 JFR 开始收集数据、停止收集数据,或者保存所收集的数据,对应的子命令分别为JFR.start,JFR.stop,以及JFR.dump。
$ jcmd <PID> JFR.start settings=profile maxage=10m maxsize=150m name=SomeLabel
上述命令运行过后,目标进程中的 JFR 已经开始收集数据。此时,我们可以通过下述命令来导出已经收集到的数据:
$ jcmd <PID> JFR.dump name=SomeLabel filename=myrecording.jfr
最后,我们可以通过下述命令关闭目标进程中的 JFR:
$ jcmd <PID> JFR.stop name=SomeLabel
第三种启用 JFR 的方式则是 JMC 中的 JFR 插件。
24.JNI的运行机制
在调用 native 方法前,Java 虚拟机需要将该 native 方法链接至对应的 C 函数上。
链接方式主要有两种。第一种是让 Java 虚拟机自动查找符合默认命名规范的 C 函数,并且链接起来。
采用javac -h命令,便可以根据 Java 程序中的 native 方法声明,自动生成包含符合命名规范的 C 函数的头文件。
在下面这段代码中,Foo类有三个 native 方法,分别为静态方法foo以及两个重载的实例方法bar。
package org.example;
public class Foo {
public static native void foo();
public native void bar(int i, long j);
public native void bar(String s, Object o);
}
通过执行javac -h . org/example/Foo.java命令,我们将在当前文件夹(对应-h后面跟着的.)生成名为org_example_Foo.h的头文件。其内容如下所示:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class org_example_Foo */
#ifndef _Included_org_example_Foo
#define _Included_org_example_Foo
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: org_example_Foo
* Method: foo
* Signature: ()V
*/
JNIEXPORT void JNICALL Java_org_example_Foo_foo
(JNIEnv *, jclass);
/*
* Class: org_example_Foo
* Method: bar
* Signature: (IJ)V
*/
JNIEXPORT void JNICALL Java_org_example_Foo_bar__IJ
(JNIEnv *, jobject, jint, jlong);
/*
* Class: org_example_Foo
* Method: bar
* Signature: (Ljava/lang/String;Ljava/lang/Object;)V
*/
JNIEXPORT void JNICALL Java_org_example_Foo_bar__Ljava_lang_String_2Ljava_lang_Object_2
(JNIEnv *, jobject, jstring, jobject);
#ifdef __cplusplus
}
#endif
#endif
下面我们采用第一种链接方式,并且实现其中的bar(String, Object)方法。
// foo.c
#include <stdio.h>
#include "org_example_Foo.h"
JNIEXPORT void JNICALL Java_org_example_Foo_bar__Ljava_lang_String_2Ljava_lang_Object_2
(JNIEnv *env, jobject thisObject, jstring str, jobject obj) {
printf("Hello, World\n");
return;
}
然后,我们可以通过 gcc 命令将其编译成为动态链接库:
这里需要注意的是,动态链接库的名字须以lib为前缀,以.dylib(或 Linux 上的.so)为扩展名。在 Java 程序中,我们可以通过System.loadLibrary("foo")方法来加载libfoo.dylib。
如果libfoo.dylib不在当前路径下,我们可以在启动 Java 虚拟机时配置java.library.path参数,使其指向包含libfoo.dylib的文件夹。
第二种链接方式则是在 C 代码中主动链接。
这种链接方式对 C 函数名没有要求。通常我们会使用一个名为registerNatives的 native 方法,并按照第一种链接方式定义所能自动链接的 C 函数。在该 C 函数中,我们将手动链接该类的其他 native 方法。
举个例子,Object类便拥有一个registerNatives方法,所对应的 C 代码如下所示:
// 注:Object 类的 registerNatives 方法的实现位于 java.base 模块里的 C 代码中
static JNINativeMethod methods[] = {
{"hashCode", "()I", (void *)&JVM_IHashCode},
{"wait", "(J)V", (void *)&JVM_MonitorWait},
{"notify", "()V", (void *)&JVM_MonitorNotify},
{"notifyAll", "()V", (void *)&JVM_MonitorNotifyAll},
{"clone", "()Ljava/lang/Object;", (void *)&JVM_Clone},
};
JNIEXPORT void JNICALL
Java_java_lang_Object_registerNatives(JNIEnv *env, jclass cls)
{
(*env)->RegisterNatives(env, cls,
methods, sizeof(methods)/sizeof(methods[0]));
}
当使用第二种方式进行链接时,我们需要在其他 native 方法被调用之前完成链接工作。因此,我们往往会在类的初始化方法里调用该registerNatives方法。具体示例如下所示:
public class Object {
private static native void registerNatives();
static {
registerNatives();
}
}
局部引用与全局引用
JNI 中的引用可分为局部引用和全局引用。这两者都可以阻止垃圾回收器回收被引用的 Java 对象。不同的是,局部引用在 native 方法调用返回之后便会失效。传入参数以及大部分 JNI API 函数的返回值都属于局部引用。
实际上,无论是局部引用还是全局引用,都是句柄。其中,局部引用所对应的句柄有两种存储方式,一是在本地方法栈帧中,主要用于存放 C 函数所接收的来自 Java 层面的引用类型参数;另一种则是线程私有的句柄块,主要用于存放 C 函数运行过程中创建的局部引用。
当从 C 函数返回至 Java 方法时,本地方法栈帧中的句柄将会被自动清除。而线程私有句柄块则需要由 Java 虚拟机显式清理。
25.Java Agent与字节码注入
我们可以通过 Java agent 的类加载拦截功能,修改某个类所对应的 byte 数组,并利用这个修改过后的 byte 数组完成接下来的类加载。
package org.example;
public class MyAgent {
public static void premain(String args) {
System.out.println("premain");
}
}
为了能够以 Java agent 的方式运行该premain方法,我们需要将其打包成 jar 包,并在其中的 MANIFEST.MF 配置文件中,指定所谓的Premain-class。
除了在命令行中指定 Java agent 之外,我们还可以通过 Attach API 远程加载。
使用 Attach API 远程加载的 Java agent 不会再先于main方法执行,这取决于另一虚拟机调用 Attach API 的时机。并且,它运行的也不再是premain方法,而是名为agentmain的方法。
在premain方法或者agentmain方法中打印一些字符串并不出奇,我们完全可以将其中的逻辑并入main方法,或者其他监听端口的线程中。除此之外,Java agent 还提供了一套 instrumentation 机制,允许应用程序拦截类加载事件,并且更改该类的字节码。
字节码注入
package org.example;
import java.lang.instrument.*;
import java.security.ProtectionDomain;
public class MyAgent {
public static void premain(String args, Instrumentation instrumentation) {
instrumentation.addTransformer(new MyTransformer());
}
static class MyTransformer implements ClassFileTransformer {
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined,
ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
System.out.printf("Loaded %s: 0x%X%X%X%X\n", className, classfileBuffer[0], classfileBuffer[1],
classfileBuffer[2], classfileBuffer[3]);
return null;
}
}
}
基于这一类加载事件的拦截功能,我们可以实现字节码注入(bytecode instrumentation),往正在被加载的类中插入额外的字节码。
基于字节码注入的 profiler
通常,我们会定义一个运行时类,并在某一程序行为的周围,注入对该运行时类中方法的调用,以表示该程序行为正要发生或者已经发生。
package org.example;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
public class MyProfiler {
public static ConcurrentHashMap<Class<?>, AtomicInteger> data = new ConcurrentHashMap<>();
public static void fireAllocationEvent(Class<?> klass) {
data.computeIfAbsent(klass, kls -> new AtomicInteger())
.incrementAndGet();
}
public static void dump() {
data.forEach((kls, counter) -> {
System.err.printf("%s: %d\n", kls.getName(), counter.get());
});
}
static {
Runtime.getRuntime().addShutdownHook(new Thread(MyProfiler::dump));
}
}
上面这段代码便是一个运行时类。该类维护了一个HashMap,用来统计每个类所新建实例的数目。当程序退出时,我们将逐个打印出每个类的名字,以及其新建实例的数目。
基于字节码注入的 profiler,可以统计程序运行过程中某些行为的出现次数。如果需要收集 Java 核心类库的数据,那么我们需要小心避免无限递归调用。另外,我们还需通过自定义类加载器来解决命名空间的问题。
由于字节码注入会产生观察者效应,因此基于该技术的 profiler 所收集到的数据并不能反映程序的真实运行状态。它所反映的是程序在被注入的情况下的执行状态。
面向方面编程
面向方面编程的核心理念是定义切入点(pointcut)以及通知(advice)。程序控制流中所有匹配该切入点的连接点(joinpoint)都将执行这段通知代码。
面向方面编程的其中一种实现方式便是字节码注入,比如AspectJ。
26.Graal:用Java编译Java
Graal是一个用 Java 写就的即时编译器,它从 Java 9u 开始便被集成自 JDK 中,作为实验性质的即时编译器。
Graal 编译器可以通过 Java 虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用。当启用时,它将替换掉 HotSpot 中的 C2 编译器,并响应原本由 C2 负责的编译请求。
Graal 和 Java 虚拟机的交互
即时编译器是 Java 虚拟机中相对独立的模块,它主要负责接收 Java 字节码,并生成可以直接运行的二进制码。
即时编译器与 Java 虚拟机的交互可以分为如下三个方面。
- 响应编译请求;
- 获取编译所需的元数据(如类、方法、字段)和反映程序执行状态的 profile;
- 将生成的二进制码部署至代码缓存(code cache)里。
即时编译器通过这三个功能组成了一个响应编译请求、获取编译所需的数据,完成编译并部署的完整编译周期。
为了让 Java 虚拟机与 Graal 解耦合,我们引入了Java 虚拟机编译器接口(JVM Compiler Interface,JVMCI),将上述三个功能抽象成一个 Java 层面的接口。这样一来,在 Graal 所依赖的 JVMCI 版本不变的情况下,我们仅需要替换 Graal 编译器相关的 jar 包(Java 9 以后的 jmod 文件),便可完成对 Graal 的升级。
Graal 和 C2 的区别
Graal 和 C2 最为明显的一个区别是:Graal 是用 Java 写的,而 C2 是用 C++ 写的。相对来说,Graal 更加模块化,也更容易开发与维护。
对 Java 程序而言,Graal 编译结果的性能略优于 OpenJDK 中的 C2;对 Scala 程序而言,它的性能优势可达到 10%(企业版甚至可以达到 20%!)。这背后离不开 Graal 所采用的激进优化方式。
Graal 的实现
Graal 编译器将编译过程分为前端和后端两大部分。前端用于实现平台无关的优化(如方法内联),以及小部分平台相关的优化;而后端则负责大部分的平台相关优化(如寄存器分配),以及机器码的生成。
Graal 与 C2 相比会更加激进。它从设计上便十分青睐这种基于假设的优化手段。在编译过程中,Graal 支持自定义假设,并且直接与去优化节点相关联。
Java 虚拟机的另一个能够大幅度提升性能的特性是 intrinsic 方法。在 Graal 中,实现高性能的 intrinsic 方法也相对比较简单。Graal 提供了一种替换方法调用的机制,在解析 Java 字节码时会将匹配到的方法调用,替换成对另一个内部方法的调用,或者直接替换为特殊节点。
27.GraalVM 中的 Truffle
在理想情况下,我们希望在不同的语言实现中复用这些组件。也就是说,每当开发一门新语言时,我们只需要实现它的解释执行器,便能够直接复用即时编译、垃圾回收等组件,从而达到高性能的效果。这也是 Truffle 项目的目标。
Truffle 是一个用 Java 写就的语言实现框架。基于 Truffle 的语言实现仅需用 Java 实现词法分析、语法分析以及针对语法分析所生成的抽象语法树(Abstract Syntax Tree,AST)的解释执行器,便可以享用由 Truffle 提供的各项运行时优化。
Truffle 是一个语言实现框架,允许语言开发者在仅实现词法解析、语法解析以及 AST 解释器的情况下,达到极佳的性能。目前 Oracle Labs 已经实现并维护了 JavaScript、Ruby、R、Python 以及可用于解析 LLVM bitcode 的 Sulong。后者将支持在 GraalVM 上运行 C/C++ 代码。
Truffle 背后所依赖的技术是 Partial Evaluation 以及节点重写。Partial Evaluation 指的是将所要编译的目标程序解析生成的抽象语法树当做编译时常量,特化该 Truffle 语言的解释器,从而得到指代这段程序解释执行过程的 Java 代码。然后,我们可以借助 Graal 编译器将这段 Java 代码即时编译为机器码。
节点重写则是收集 AST 节点的类型,根据所收集的类型 profile 进行的特化,并在节点类型不匹配时进行去优化并重新收集、编译的一项技术。
Truffle 的 Polyglot 特性支持在一段代码中混用多种不同的语言。与其他 Polyglot 框架相比,它支持在不同的 Truffle 语言中复用内存中存储的同一个对象。
28.GraalVM 中的 AOT 编译框架 SubstrateVM
所谓 AOT 编译,是与即时编译相对立的一个概念。我们知道,即时编译指的是在程序的运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。
而 AOT 编译指的则是,在程序运行之前,便将字节码转换为机器码的过程。它的成果可以是需要链接至托管环境中的动态共享库,也可以是独立运行的可执行文件。
AOT 编译的优点显而易见:我们无须在运行过程中耗费 CPU 资源来进行即时编译,而程序也能够在启动伊始就达到理想的性能。
然而,与即时编译相比,AOT 编译无法得知程序运行时的信息,因此也无法进行基于类层次分析的完全虚方法内联,或者基于程序 profile 的投机性优化(并非硬性限制,我们可以通过限制运行范围,或者利用上一次运行的程序 profile 来绕开这两个限制)。这两者都会影响程序的峰值性能。
SubstrateVM 的设计初衷是提供一个高启动性能、低内存开销,和能够无缝衔接 C 代码的 Java 运行时。它是一个独立的运行时,拥有自己的内存管理等组件。
SubstrateVM 要求所要 AOT 编译的目标程序是封闭的,即不能动态加载其他类库等。在进行 AOT 编译时,它会探索所有可能运行到的方法,并全部纳入编译范围之内。
SubstrateVM 的启动时间和内存开销都非常少,这主要得益于在 AOT 编译时便已保存了已初始化好的堆快照,并支持从程序入口直接开始运行。作为对比,HotSpot 虚拟机在执行 main 方法前需要执行一系列的初始化操作,因此启动时间和内存开销都要远大于运行在 SubstrateVM 上的程序。
Metropolis 项目将运用 SubstrateVM 项目,逐步地将 HotSpot 虚拟机中的 C++ 代码替换成 Java 代码,从而提升 HotSpot 虚拟机的可维护性,也加快新 Java 功能的开发效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号