

Redis知识问题汇总
问题1:Redis如何做持久化?它们的优缺点是什么?
1.RDB持久化
RDB持久化是把当前进程数据生成快照保存到硬盘当中,触发条件可分为手动触发和自动触发。
a)手动触发
手动触发命令是"save"和"bgsave",它们的区别是save会阻塞当前redis服务器,直到RDB写入结束。而bgsave则是执行fork创建子进程来完成RDB写入,一般线上环境推荐使用bgsave来写入RDB文件。
b)自动触发
自动触发则是配置“save m n”,意思是当在m秒内执行n次修改时执行bgsave命令;在默认情况下,如果没有开启AOF持久化策略,也会触发bgsave。
RDB的优缺点
优点:RDB文件是某个时间节点的快照,是压缩的二进制文件,非常适用于备份、全量复制等场景;而且,RDB恢复数据的时候速度远远快于AOF。
缺点:RDB没办法做到实时性持久化,因为bgsave每次运行都要执行fork命令创建子进程,属于重量级操作,频繁执行成本太高;再者就是因为是二进制文件,所以可读性差,还有RDB文件版本兼容问题等。
2.AOF持久化
AOF持久化就是用日志的形式把每次写的命令都记录下来,在恢复数据的时候重新执行文件中的命令。
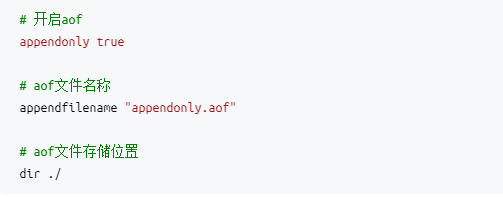
a)开启AOF
开启AOF的方法则是在redis.conf里配置"appendonly true"还有持久化文件的名称如"appendfilename "appendonly.aof",以及文件存储路径。
AOF所有写入的命令都会追加到“aof_buf”缓冲区中,因为如果直接写入硬盘的话性能就完全取决于硬盘的读写能力了,而且使用缓冲区也便于使用不同的同步策略。
b)触发机制
手动执行“bgrewriteaof”命令即可触发aof重写,自动触发则是配置"auto-aof-rewrite-min-size"和"auto-aof-rewrite-percentage"
auto-aof-rewrite-min-size: 表示触发aof重写时aof文件的最小体积,默认64m
auto-aof-rewrite-percentage: 表示当前aof文件空间和上一次重写后aof文件空间的比值,默认是aof文件体积翻倍时触发重写
c)重写机制
当AOF文件过大时,我们需要定期对AOF文件进行重写来达到压缩的目的,重写就是将多条相同的命令合并到一起,比如lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。重写之后加载AOF文件的速度也会提高。重写可以通过直接调用"bgrewriteaof"命令手动触发,也可以配置auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。
auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认 为64MB。
auto-aof-rewrite-percentage:代表当前AOF文件空间 (aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
AOF优缺点
优点:AOF实时性和安全性较高,每隔1秒同步一次数据到AOF文件,最多丢失1秒的数据;AOF文件是以命令的形式存储的,可读性更高,便于灾难恢复。
缺点:虽然AOF有重写机制来压缩文件,但是它的体积仍比RDB文件大很多,不便于数据传输而且数据恢复也比较慢。
问题2:Redis的数据已经设置了TTL,不是过期就已经删除了吗?为什么还存在所谓的淘汰策略呢?
Redis的过期策略
a)定期删除:Redis定时进行一次过期扫描,随机抽取一些设置过期了的Key,检查是否过期,过期了则删除。
b)惰性删除:当客户端访问某个key的时候,Redis会检查这个key是否已经过期,过期了则删除。
总结
定期删除是几种处理,惰性删除是零散处理,不管是哪种处理方案,都会存在有些过期的key无法被处理,所以需要内存淘汰策略进行补充。
问题3:Redis的内存淘汰策略都有哪几种?
Redis内存淘汰策略
noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
allkeys-random:加入键的时候如果过限,从所有key随机删除
volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
allkeys-lfu:从所有键中驱逐使用频率最少的键
问题4:LRU、LFU算法原理是什么?
1.LRU算法
LRU(Least Recently Used)表示最近最少使用,淘汰策略是把访问时间最早的Key删除,核心思想是“最近被使用过的数据将来再次被访问的几率会更高”。最常见的方式是用链表来实现的,新增加的数据放在链表头部,如果数据被再次访问则移动到头部,数据满了的时候就从链表尾部移除数据。
而在Redis中采用的是近似LRU算法,为什么是近似呢?因为Redis是随机抽取5个Key,从中挑选访问时间最早的Key进行淘汰。但是这有个缺陷是,如果热点数据最近未被访问,而非热点数据近期被访问了,就会误把热点数据删除了,所以Redis后面就推出了LFU算法。
2.LFU算法
LFU(Least Frequently Used)表示最不经常使用,淘汰策略是把访问频率最低的Key删除,核心思想是“访问次数最多的数据将来再次被访问的几率会更高”。LFU也是用链表来实现的,新数据放在链表尾部,根据访问次数进行降序排序,如果访问次数相同则按最近访问时间降序排序,数据满了就从链表尾部移除数据。
问题5:存储数据用 string 类型 和 hash 类型,在实际场景怎么选择?
如果我们只对业务类型中的某个字段进行更新或读取这种需求比较频繁的话,用hash比较合适,因为string类型会增加序列化的开销,而且还会出现并发的问题;但是如果需要更新或读取这个业务类型的大量字段,我们只需要反序列化json,更新完后再序列化存入即可。
问题6:zset的底层实现原理是什么?
跳表
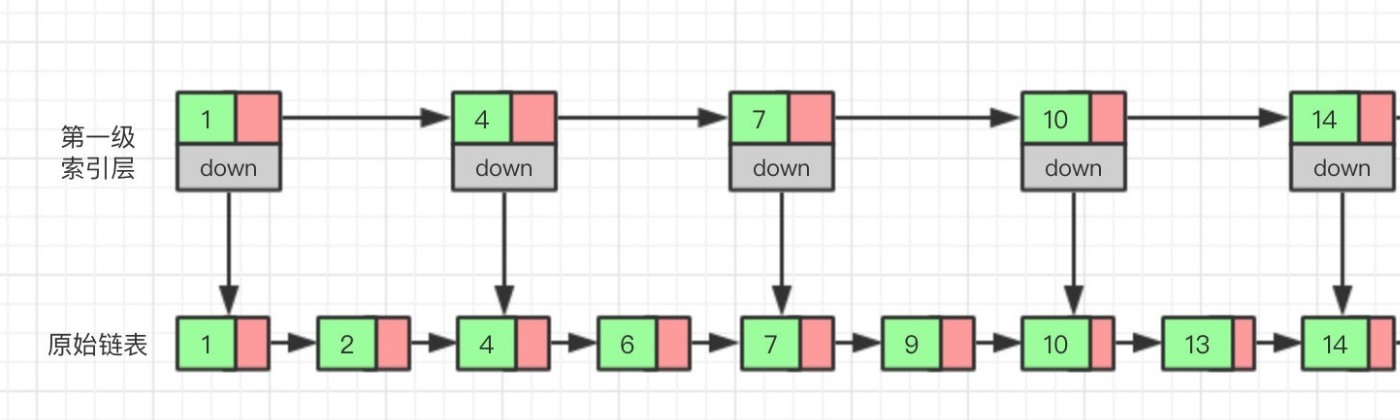
Redis的zset底层是用跳表来实现的,插入、删除、查找的时间复杂度均为O(logN)。跳表就是基于并联的链表,正常链表我们要查找一个数据的时候,需要从链表头部开始进行遍历,最差的情况是遍历到尾部,时间复杂度是O(n)。
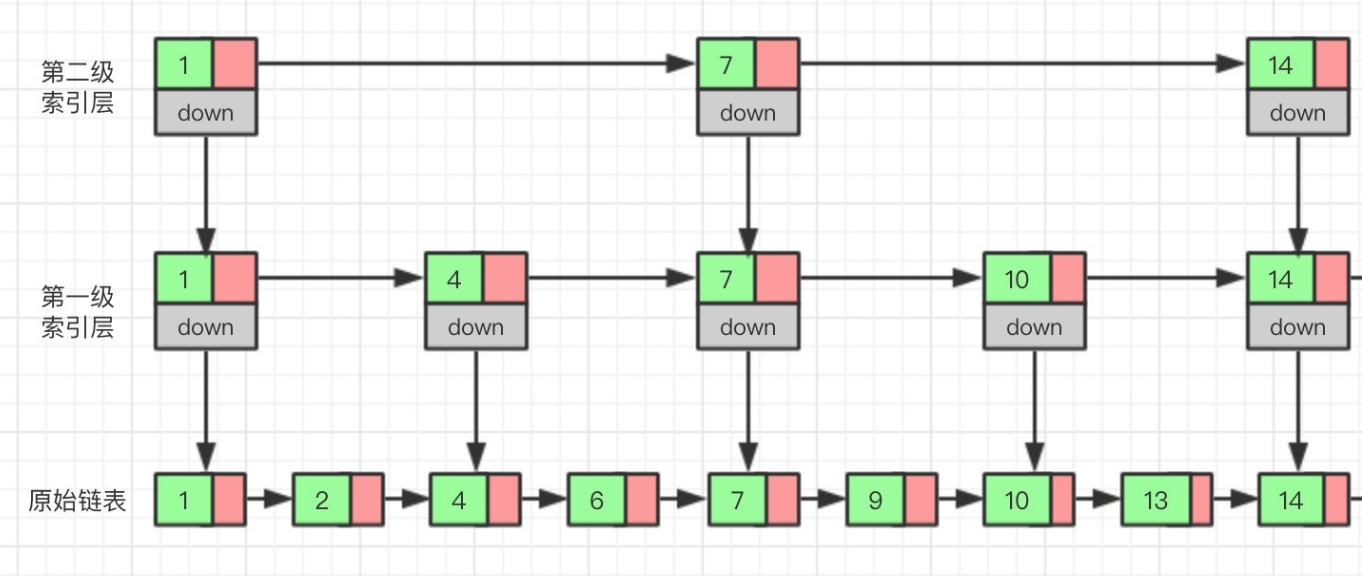
而跳表则是在原来的链表加入了类似“索引”的东西,如下图所示,在原来链表的基础上,每两个节点提取一个节点建立索引,我们将抽取出来的节点叫做"索引层",down表示指向原始链表节点的指针。
相应的如果我们再往索引层上建立索引层,效率就会变得更高了,特别是数据越多效率越明显,这就是利用了二分查找的原理来实现的跳表。
问题7:缓存穿透、缓存击穿、缓存雪崩是什么?如何解决?
1.缓存穿透
缓存穿透是用户频繁访问缓存和数据库中都不存在的数据,导致数据库压力过大崩溃。
解决方案:可以将数据库不存在的数据以key-null存到缓存中,设置30秒过期时间,防止用户在短时间内疯狂攻击同一个key。还有就是用布隆过滤器。
2.缓存击穿
缓存击穿就是大量用户同时访问一个缓冲中不存在但是数据库存在的数据,可以理解是缓存过期,所有的请求都到数据库去了,导致数据库崩溃。
解决方案:可以将热点数据不设置过期时间、接口限流、加互斥锁以及使用布隆过滤器。
3.缓存雪崩
缓存雪崩就是大量的缓存过期,导致缓存没有拿到数据都去请求数据库,数据库压力过大导致崩溃。
解决方案:设置缓冲存期时间用随机值,防止大量缓存同一时间过期。
4.布隆过滤器基本原理
布隆过滤器底层是一个bit数组,将数据存到bit数组中,需要先经过hash函数得到对应的hash值,然后用hash值在bit数组中找到对应的下标,设置值为1(布隆过滤器初始化bit数组时值都为0)。
当需要判断一个元素是否存在时,同样对这个元素进行hash函数运算得到下标,然后检查对应的所有下标值是否为1,如果有一个是0则说明该元素不存在。
优点:占用空间少,查询效率高。
缺点:只能插入和查询,无法删除,而且有一定的误算率,就是得到的结果不一定百分百准确,特别是数据量越大的时候误算率越高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号