

Spring循环依赖注入源码解析
1.循环依赖
所谓循环依赖,就是A对象里包含属性b(B b),B对象里包含属性a(A a),在xml里就是这样配置的:

Spring容器注入的时候,先是会去实例化Bean,然后再进行属性填充完成初始化,这样才是一个完整可用的Bean;
首先A实例化之后进行属性填充,给b赋值的时候,会去容器里找有没有这个Bean,如果没有则会对b进行初始化;
然后B初始化的时候又会遇到需要给a赋值的情况,而又会去初始化a,如此反复下去不就死循环了吗?
不过Spring对循环依赖已经有了解决方案,就是用到了三级缓存,把实例化和初始化分开了,也就是在B赋值的时候,把半成品A赋值进去了。
这样获取到B对象后,A对象也可以完成赋值了。
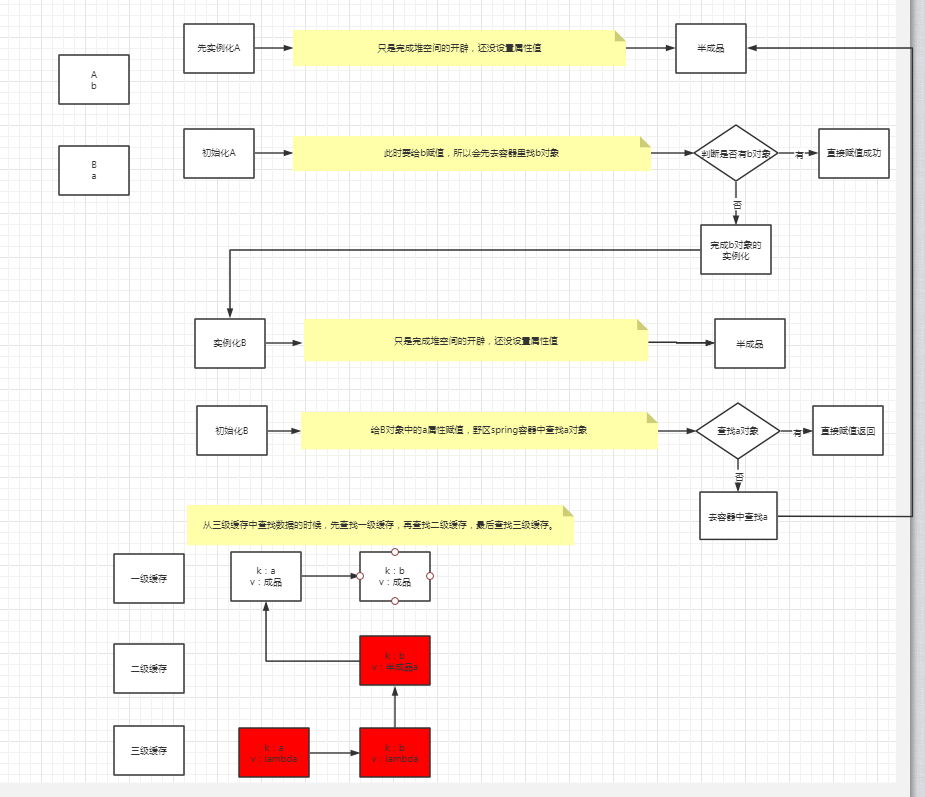
那么所谓的三级缓存是什么呢?他们都分别用来存什么?
2.三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
这个是三级缓存,Key存放的是beanName,Value存的是ObjectFactory,对象工厂存放的是即将要被实例化的对象;它这里放的是一个lambda表达式,可以通过它来获取对象。
private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);
这个是二级缓存,Key存放的是beanName,Value存的是半成品对象,就是还没初始化完的。
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);
最后是一级缓存,Key存放的是beanName,Value存的是成品对象,也就是属性填充完了的对象。
3.源码解析
容器实例化Bean的过程是getBean()->doGetBean()->createBean()->doCreateBean();
首先是实例化A,我们直接看这个方法:
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean
Object sharedInstance = this.getSingleton(beanName);
Object bean;
先看getSingleton这个方法,我们点进去看看:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); // 一级缓存中获取
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) { // bean是否正在创建,这个决定了是否能从二级缓存中拿数据
singletonObject = this.earlySingletonObjects.get(beanName); // 二级缓存中获取
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName); // 一级缓存中获取
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName); // 二级缓存中获取
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName); // 三级缓存中获取
if (singletonFactory != null) { // 如果三级缓存中找到bean
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject); //添加到二级缓存中
this.singletonFactories.remove(beanName); // 删除三级缓存的bean
}
}
}
}
}
}
return singletonObject;
}
这里是从三级缓存中拿数据,第一次实例化A的时候,缓存里肯定是没有的,而且bean也才开始实例化,直接跳过,所以我们回去,再继续往下找,找到这个方法:getSingleton
sharedInstance = this.getSingleton(beanName, () -> {
try {
return this.createBean(beanName, mbd, args);
} catch (BeansException var5) {
this.destroySingleton(beanName);
throw var5;
}
});
bean = this.getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
这个方法传了一个lambda表达式,这个主要是用来创建Bean的,我们先点进getSingleton()里去看看。
Object singletonObject = this.singletonObjects.get(beanName);
一进来就是要去一级缓存里拿数据,当然这里肯定是空的。
继续往下看,看到这个方法: this.beforeSingletonCreation(beanName);
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
这里面是往singletonsCurrentlyInCreation这个里面添加当前的beanName,表示这个bean为创建中。
然后继续下去就是 singletonObject = singletonFactory.getObject(); 这个方法是进行bean的创建,也就是回到上面lambda表达式的createBean()方法。
进到这个方法里,我们直接找 beanInstance = this.doCreateBean(beanName, mbdToUse, args);
这里面的 instanceWrapper = this.createBeanInstance(beanName, mbd, args); 是用反射来创建对象。
往下看找到这里:
boolean earlySingletonExposure = mbd.isSingleton() && this.allowCircularReferences && this.isSingletonCurrentlyInCreation(beanName); //isSingletonCurrentlyInCreation 是前面提到的,已经把beanName放进去了
if (earlySingletonExposure) {
if (this.logger.isTraceEnabled()) {
this.logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references");
}
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});
}
所以这里的判断是可以进去的,我们就可以走到addSingletonFactory()这个方法,提供的ObjectFactory是通过"getEarlyBeanReference"这个方法获取的。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized(this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory); //存三级缓存
this.earlySingletonObjects.remove(beanName); //清楚二级缓存
this.registeredSingletons.add(beanName); // 表示这个单例已经注册过了
}
}
}
这里往三级缓存里存了数据,之后就是填充A的属性了,填充的时候发现B还没有实例化,就继续调“GetBean”重复上面的逻辑;此时一级缓存里有A和B,到了填充B的时候,发现需要A,调用了“GetBean()”,然后关键的地方来了,我们回到一开始的
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); // 一级缓存中获取
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) { // bean是否正在创建,这个决定了是否能从二级缓存中拿数据
singletonObject = this.earlySingletonObjects.get(beanName); // 二级缓存中获取
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName); // 一级缓存中获取
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName); // 二级缓存中获取
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName); // 三级缓存中获取
if (singletonFactory != null) { // 如果三级缓存中找到bean
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject); //添加到二级缓存中
this.singletonFactories.remove(beanName); // 删除三级缓存的bean
}
}
}
}
}
}
return singletonObject;
}
这里“isSingletonCurrentlyInCreation”因为A已经在这里面了,所以可以继续往下走,我们从三级缓存里找到了A,就把它放到了二级缓存中,虽然这个A还只是个半成品。
所以这里B就完成了填充,我们就可以把它放到一级缓存“singletonObjects”中同时会删除二级和三级缓存的数据,这样A也就也可以从一级缓存中拿到完成填充的B了。
最后总结一下三级缓存的作用:
1.Spring解决循环依赖的本质是将实例化和初始化操作分开,在中间过程给其他对象赋值的时候,并不是一个完整的对象,而是把半成品对象赋值给了其他对象。
2.第三级缓存的本质是在于解决AOP代理问题,当一个对象需要被代理的时候,就会创建两个对象,一个是代理对象,一个是普通对象;然后因为Spring默认是单例,一个beanName只能对应一个对象。所以三级缓存的lambda表达式里处理的就是判断需不需要开启代理,需要的话我们“getObject”返回的是代理对象,用lambda表达式可以在需要用这个对象的时候去执行相应的逻辑,这样我们就可以保证只有一个bean了。
3.二级缓存的作用是把bean的实例化和初始化分开操作了,在中间过程中给其他对象赋值的时候,并不是一个完整的对象,而是把半成品对象赋值给了其他对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号