
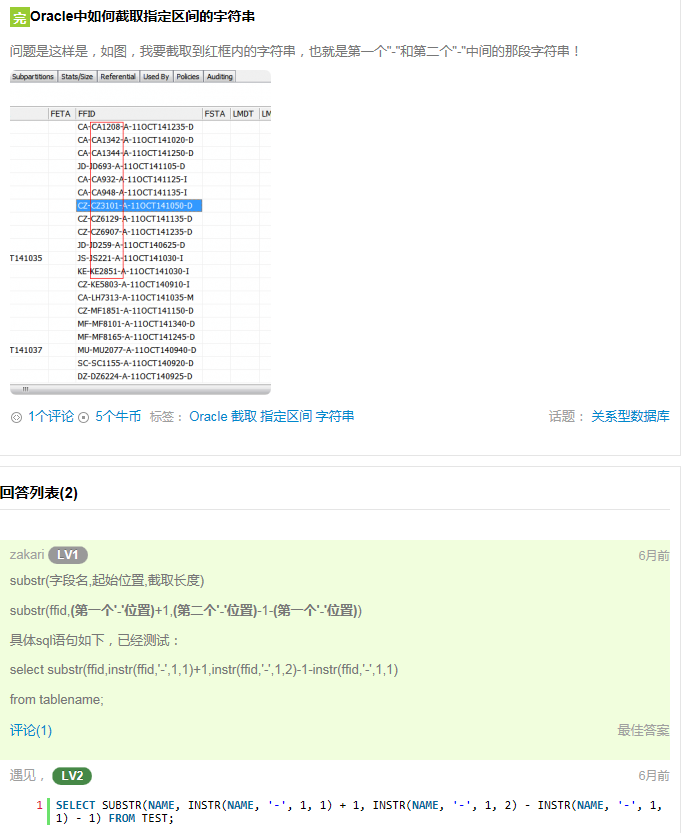
oracle截取字符串,定索引
转载:https://www.cnblogs.com/qmfsun/p/4493918.html
使用Oracle中Instr()和substr()函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
在Oracle中可以使用instr函数对某个字符串进行判断,判断其是否含有指定的字符。其语法为:instr(sourceString,destString,start,appearPosition). instr('源字符串' , '目标字符串' ,'开始位置','第几次出现')其中sourceString代表源字符串;destString代表想聪源字符串中查找的子串;start代表查找的开始位置,该参数可选的,默认为1;appearPosition代表想从源字符中查找出第几次出现的destString,该参数也是可选的,默认为1;如果start的值为负数,那么代表从右往左进行查找,但是位置数据仍然从左向右计算。返回值为:查找到的字符串的位置。对于instr函数,我们经常这样使用:从一个字符串中查找指定子串的位置。例如:SQL> select instr('yuechaotianyuechao','ao') position from dual; POSITION ---------- 6从第7个字符开始搜索<br>SQL> select instr('yuechaotianyuechao','ao', 7) position from dual; POSITION ---------- 17从第1个字符开始,搜索第2次出现子串的位置<br>SQL> select instr('yuechaotianyuechao','ao', 1, 2) position from dual; POSITION ---------- 17<br><br>------------------------------------------------------------- <br><br>对于instr函数,我们经常这样使用:从一个字符串中查找指定子串的位置。例如: <br><br>SQL> select instr('abcdefgh','de') position from dual; <br><br><br>POSITION <br>---------- <br>4 <br>从1开始算 d排第四所以返回4 <br><br>SQL>select instr('abcdefghbc','bc',3) position from dual; <br><br>POSITION <br>---------- <br>9 <br>从第3个字符开始算起 第3个字符是c,所以从3开始以后的字符串找查找bc,返回9 <br><br>--------------------------- <br>从第1个字符开始,查找第2次出现子串的位置 <br>SQL> select instr('qinyinglianqin','qin', 1, 2) position from dual; <br>POSITION <br>---------- <br>12 <br><br>---------------------------------------------------------------------- 注意:1。若‘起始位置’=0 时返回结果为0, 2。这里只有三个参数,意思是查找第一个要查找字符的位置(因为 ‘第几次出现’默认为1), 当‘起始位置’不大于要查找的第一个字符的位置时,返回的值都将是第一个字符的位置,如果‘起始位置’大于要查找的第一个字符的位置时,返回的值都将是第2个字符的位置,依此类推……(但是也是以第一个字符开始计数)<br><br><br>substr函数的用法,取得字符串中指定起始位置和长度的字符串 ,默认是从起始位置到结束的子串。 substr( string, start_position, [ length ] ) substr('目标字符串',开始位置,长度)如: substr('This is a test', 6, 2) would return 'is' substr('This is a test', 6) would return 'is a test' substr('TechOnTheNet', -3, 3) would return 'Net' substr('TechOnTheNet', -6, 3) would return 'The'select substr('Thisisatest', -4, 2) value from dual<br><br><br>SUBSTR()函数 <br>1.用处:是从给定的字符表达式或备注字段中返回一个子字符串。 <br><br>2.语法格式:SUBSTR(cExpression,nStartPosition [,nCharactersReturned]) <br><br>其中,cExpression指定要从其中返回字符串的字符表达式或备注字段; <br><br>nStartPosition用于指定返回的字符串在字符表达式或备注字段中的位置, <br><br>nCharactersReturned用于指定返回的字符数目,缺省时返回字符表达式的值结束前的全部字符。 <br><br>3.举例:STORE'abcdefghijlkm' To mystring <br><br>SUBSTR(mystring ,1,5) 显示 "abcde" 1 从第一个字符开始 截取的字符中,包括第一个字符 <br><br>SUBSTR(mystring ,6) 显示 "fghijklm" <br><br>SUBSTR(mystring,-2)显示“km” 最右边一个字符是-1,最右边左边的字符是-2,然后默认是从左向有取剩下的全部的字符 <br><br>SUBSTR(mystrng,-4)显示“jlkm” |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
oracle截取字符串将 C3411.907w15 截取点号之前的字符串 C3411 SUBSTR ('C3411.907w15', 0, INSTR ('C3411.907w15, '.', 1, 1) - 1) SELECT SUBSTR ('C3411.907w15', 0, INSTR ('C3411.907w15, '.', 1, 1) - 1) www.2cto.com FROM DUAL将 C3411.907w15 截取点号之后 的字符串 907w15 SUBSTR ('C3411.907w15', INSTR ('C3411.907w15', '.', 1, 1)+1)SELECT SUBSTR ('C3411.907w15', INSTR ('C3411.907w15', '.', 1, 1)+1) FROM DUAL |
项目应用实例:
原始字符串:

原始字段中存在7个“_”,我现在只想取出最后一个“_”后面的字符串,该怎么解决呢?
分两步:
第一步,通过Instr()函数,找到第7个“_”字符:
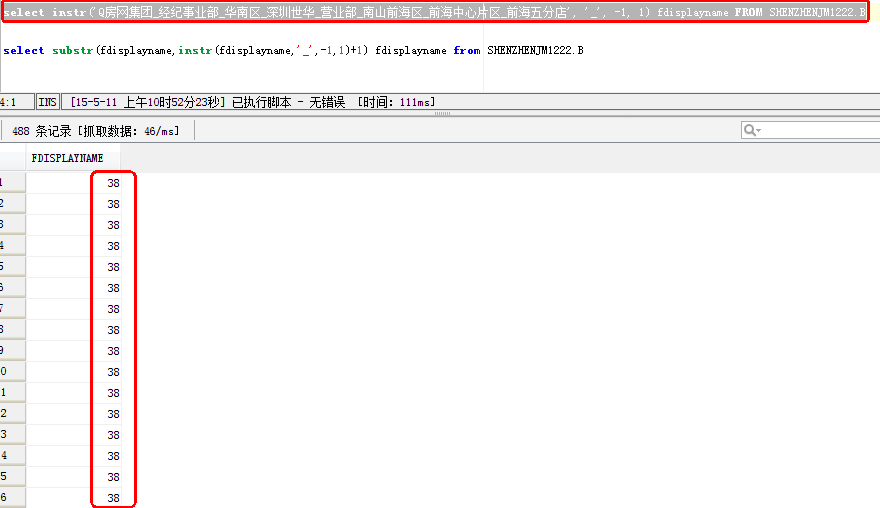
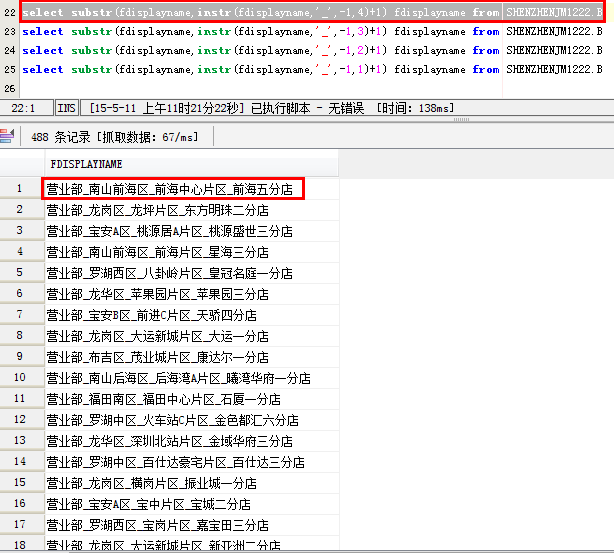
select instr('Q房网集团_经纪事业部_华南区_深圳世华_营业部_南山前海区_前海中心片区_前海五分店','_', 1, 7) fdisplayname from SHENZHENJM1222.B
或者:
select instr('Q房网集团_经纪事业部_华南区_深圳世华_营业部_南山前海区_前海中心片区_前海五分店', '_', -1, 1) fdisplayname FROM SHENZHENJM1222.B
两者效果一样,下面的-1,表示从右边开始算起始字符,1表示获取第一个“_”
获取到的结果如图:
第2步,通过substr()函数,取出所需要的字段:
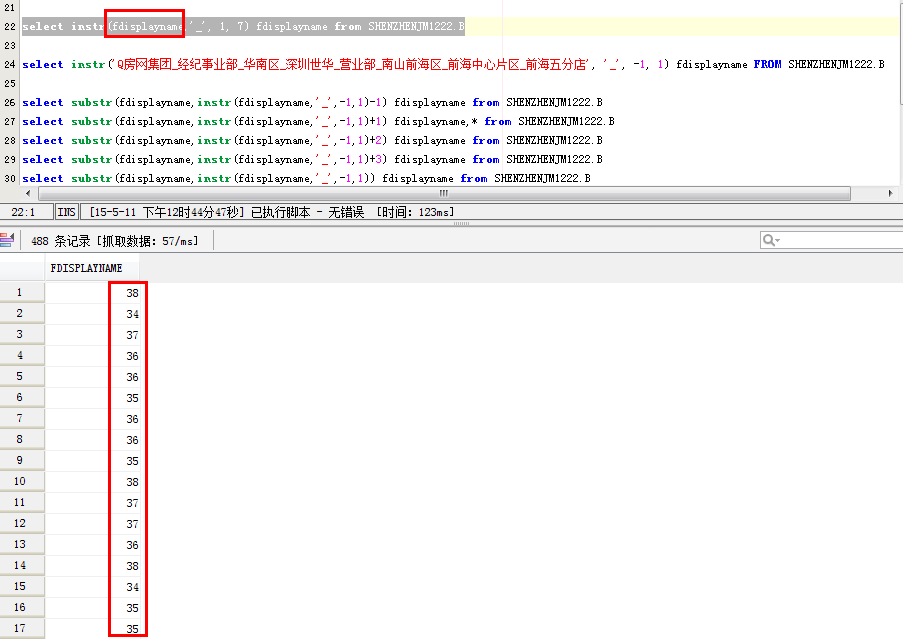
select substr(fdisplayname,instr(fdisplayname,'_',-1,1)+1) fdisplayname from SHENZHENJM1222.B
fdisplayname:代表字段名,相当于元字符串
重点介绍一下+1
+1表示在目标字符串“_”后的第一个字符串开始截取
下面看一下不同的数字的情况:

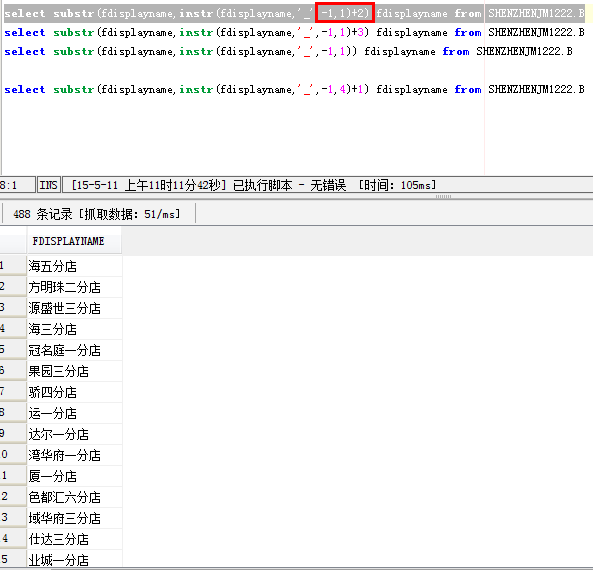
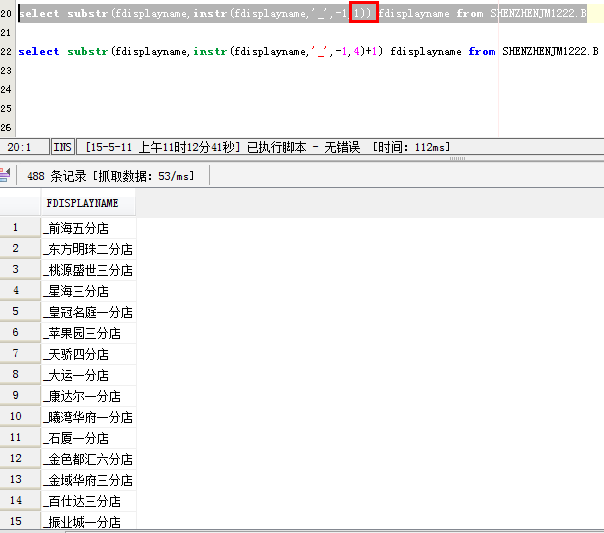
select substr(fdisplayname,instr(fdisplayname,'_',-1,1)+1) fdisplayname from SHENZHENJM1222.B
在来看一下instr(fdisplayname,'_',-1,1)中的1是啥意思:


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
Oracle中INSTR和SUBSTR的用法Oracle中INSTR的用法:INSTR方法的格式为INSTR(源字符串, 要查找的字符串, 从第几个字符开始, 要找到第几个匹配的序号)返回找到的位置,如果找不到则返回0.例如:INSTR('CORPORATE FLOOR','OR', 3, 2)中,源字符串为'CORPORATE FLOOR', 在字符串中查找'OR',从第三个字符位置开始查找"OR",取第三个字后第2个匹配项的位置。默认查找顺序为从左到右。当起始位置为负数的时候,从右边开始查找。所以SELECT INSTR('CORPORATE FLOOR', 'OR', -1, 1) "aaa" FROM DUAL的显示结果是Instring——————14oracle的substr函数的用法: 取得字符串中指定起始位置和长度的字符串 substr( string, start_position, [ length ] ) 如: substr('This is a test', 6, 2) would return 'is' substr('This is a test', 6) would return 'is a test' substr('TechOnTheNet', -3, 3) would return 'Net' substr('TechOnTheNet', -6, 3) would return 'The' select substr('Thisisatest', -4, 2) value from dual综合应用:SELECT INSTR('CORPORATE FLOOR', 'OR', -1, 1) "Instring" FROM DUAL--INSTR(源字符串, 目标字符串, 起始位置, 匹配序号)SELECT INSTR('CORPORATE FLOOR','OR', 3, 2) "Instring" FROM DUALSELECT INSTR('32.8,63.5',',', 1, 1) "Instring" FROM DUALSELECT SUBSTR('32.8,63.5',INSTR('32.8,63.5',',', 1, 1)+1) "INSTRING" FROM DUALSELECT SUBSTR('32.8,63.5',1,INSTR('32.8,63.5',',', 1, 1)-1) "INSTRING" FROM DUAL-- CREATED ON 2008-9-26 BY ADMINISTRATORDECLARE -- LOCAL VARIABLES HERE T VARCHAR2(2000); S VARCHAR2(2000); NUM INTEGER; I INTEGER; POS INTEGER;BEGIN -- TEST STATEMENTS HERE T := '12.3,23.0;45.6,54.2;32.8,63.5;'; SELECT LENGTH(T) - LENGTH(REPLACE(T, ';', '')) INTO NUM FROM DUAL; DBMS_OUTPUT.PUT_LINE('NUM:' || NUM); POS := 0; FOR I IN 1 .. NUM LOOP DBMS_OUTPUT.PUT_LINE('I:' || I); DBMS_OUTPUT.PUT_LINE('POS:' || POS); DBMS_OUTPUT.PUT_LINE('==:' || INSTR(T, ';', 1, I)); DBMS_OUTPUT.PUT_LINE('INSTR:' || SUBSTR(T, POS + 1, INSTR(T, ';', 1, I) - 1)); POS := INSTR(T, ';', 1, I); END LOOP;END;-- Created on 2008-9-26 by ADMINISTRATORdeclare -- Local variables here i integer; T VARCHAR2(2000); S VARCHAR2(2000);begin -- Test statements here --历史状态 T := '12.3,23.0;45.6,54.2;32.8,63.5;'; IF (T IS NOT NULL) AND (LENGTH(T) > 0) THEN --T := T || ','; WHILE LENGTH(T) > 0 LOOP --ISTATUSID := 0; S := TRIM(SUBSTR(T, 1, INSTR(T, ';') - 1)); IF LENGTH(S) > 0 THEN DBMS_OUTPUT.PUT_LINE('LAT:'||SUBSTR('32.8,63.5',1,INSTR('32.8,63.5',',', 1, 1)-1)); DBMS_OUTPUT.PUT_LINE('LON:'||SUBSTR('32.8,63.5',INSTR('32.8,63.5',',', 1, 1)+1)); -- COMMIT; END IF; T := SUBSTR(T, INSTR(T, ';') + 1); END LOOP; END IF;end; |
|
1
2
3
4
5
6
7
8
|
就是在表中有一个字段,最开始的是[XXXX]字样,我要如何操作,才能获得[]中字符?select substr('[xxxx]', instr('[xxxx]','[') + 1, instr('[xxxx]',']') - instr('[xxxx]','[') -1 ) from dual您的需要就是去掉[]而获得[]之间的字符对吧其实很简单,有一个截取字符的函数substr('string',n,m) 其中'string'是目标字符串,n为截取的起始位置,m为结束的位置。例如:select substr('[xxxx]' , 2, 4) from 表名;意思就是对[xxxx]从第二个位置开始截取4个字符。结果就是 xxxx <br><br>比如数据库有个字段为 tellsid,存储值的格式为 <br>"湖北_5874" 我想单独读取这个字段里下横线后面的部分并转换为数字 要怎么实现啊?<br>后面数字部分是序列产生的, 前面部分是地区名,都没有固定的长度<br><br>首先用instr检查'_'的位置,再substr就ok了。<br><br>SELECT to_number(substr(tellsid,<br> instr(tellsid, '_', 1) + 1))<br> FROM your_tablename;<br><br>如果版本是10g以上,试试这个:<br>SELECT to_number(regexp_substr(tellsid, '[0-9]{1,}', 1))<br> FROM your_tablename;<br><br>regexp_substr('fdaf_4556','[[:digit:]]+'),还是感觉这个好点。 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
INSTR (源字符串, 目标字符串, 起始位置, 匹配序号) 在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。只检索一次,就是说从字符的开始 到字符的结尾就结束。 语法如下: instr( string1, string2 [, start_position [, nth_appearance ] ] ) 参数分析: string1 源字符串,要在此字符串中查找。 string2 要在string1中查找的字符串. start_position 代表string1 的哪个位置开始查找。此参数可选,如果省略默认为1. 字符串索引从1开始。如果此参数为正,从左到右开始检索,如果此参数为负,从右到左检索,返回要查找的字符串在源字符串中的开始索引。 nth_appearance 代表要查找第几次出现的string2. 此参数可选,如果省略,默认为 1.如果为负数系统会报错。 注意: 如果String2在String1中没有找到,instr函数返回0. 示例: SELECT instr('syranmo','s') FROM dual; -- 返回 1 SELECT instr('syranmo','ra') FROM dual; -- 返回 3 1 SELECT instr('syran mo','a',1,2) FROM dual; -- 返回 0 (根据条件,由于a只出现一次,第四个参数2,就是说第2次出现a的位置,显然第2次是没有再出现了,所以结果返回0。注意空格也算一个字符!) SELECT instr('syranmo','an',-1,1) FROM dual; -- 返回 4 (就算是由右到左数,索引的位置还是要看‘an’的左边第一个字母的位置,所以这里返回4) SELECT instr('abc','d') FROM dual; -- 返回 0 注:也可利用此函数来检查String1中是否包含String2,如果返回0表示不包含,否则表示包含。 对于上面说到的,我们可以这样运用instr函数。请看下面示例: 如果我有一份资料,上面都是一些员工的工号(字段:CODE),可是我现在要查询出他们的所有员工情况,例如名字,部门,职业等等,这里举例是两个员工,工号分别是’A10001′,’A10002′,其中假设staff是员工表,那正常的做法就如下: 1 2 SELECT code , name , dept, occupation FROM staff WHERE code IN ('A10001','A10002'); 或者: SELECT code , name , dept, occupation FROM staff WHERE code = 'A10001' OR code = 'A10002'; 有时候员工比较多,我们对于那个’觉得比较麻烦,于是就想,可以一次性导出来么?这时候你就可以用instr函数,如下: SELECT code , name , dept, occupation FROM staff WHERE instr('A10001,A10002',code)>0; 查询出来结果一样,这样前后只用到两次单引号,相对方便点。 还有一个用法,如下: SELECT code, name, dept, occupation FROM staff WHERE instr(code, '001') > 0; 等同于 SELECT code, name, dept, occupation FROM staff WHERE code LIKE '%001%' ;<br><br><br><br> |
instr(string1,string2[,start_position[,nth_appearence]])
string1:要在此字符串中查找。
string2:要在string1中查找的字符串。
start_position:从string1开始查找的位置。可选,默认为1,正数时,从左到右检索,负数时,从右到左检索。
nth_appearence:查找第几次出现string2。可选,默认为1,不能为负。
注:如果没有查找到,返回0。
例如:
select instr('abcd','a') from dual; --返回1 select instr('abcd','c') from dual; --返回3 select instr('abcd','e') from dual; --返回0
该函数可以用于模糊查询以及判断包含关系:
例如:
① select code, name, dept, occupation from staff where instr(code, '001') > 0;
等同于
select code, name, dept, occupation from staff where code like '%001%' ;
② select ccn,mas_loc from mas_loc where instr('FH,FHH,FHM',ccn)>0;
等同于
select ccn,mas_loc from mas_loc where ccn in ('FH','FHH','FHM');
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
INSTR(源字符串, 目标字符串, 起始位置, 匹配序号) :在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。只检索一次,就是说从字符的开始到字符的结尾就结束。一、语法如下:instr( string1, string2 [, start_position [, nth_appearance ] ] )1>参数分析: ①string1:源字符串,要在此字符串中查找。 ②string2:要在string1中查找的字符串. ③start_position:代表string1 的哪个位置开始查找。 注:此参数可选,如果省略默认为1. 字符串索引从1开始。 如果此参数为正,从左到右开始检索。 如果此参数为负,从右到左检索,返回要查找的字符串在源字符串中的开始索引。 ④nth_appearance:代表要查找第几次出现的string2. 注:此参数可选,如果省略,默认为 1.如果为负数系统会报错。注意:如果String2在String1中没有找到,instr函数返回0.2>示例: SELECT instr('syranmo','s') FROM dual; -- 返回 1 SELECT instr('syranmo','ra') FROM dual; -- 返回 3 SELECT instr('syran mo','a',1,2) FROM dual; -- 返回 0 SELECT instr('syranmo','an',-1,1) FROM dual; -- 返回 4 SELECT instr('abc','d') FROM dual; -- 返回 0二、其他应用实例:1>从staff表查询工号code分别是’A10001′,’A10002′的员工: ①SELECT code , name , dept, occupation FROM staff WHERE code IN ('A10001','A10002'); ②SELECT code , name , dept, occupation FROM staff WHERE code = 'A10001' OR code = 'A10002'; ③SELECT code , name , dept, occupation FROM staff WHERE instr('A10001,A10002',code)>0; 这种用法时常被用于存储过程,将范围字符串作为参数传入。如果使用①的SQL写法,将拼好的字符串传入直接使用,则存储过程会报错。此时会用这种方法查找,传入的拼好字符串便可直接使用。2>模糊查询: ①SELECT code, name, dept, occupation FROM staff WHERE code LIKE '%001%' ; ②SELECT code, name, dept, occupation FROM staff WHERE instr(code, '001') > 0; |
简述
今天在写 sql时遇到一个情况,表 A中的 ID 是按照 TREE结构存储的。现在需要和表 B中的 NODE_ID连接,取出 B中 NODE_ID可以和 A中任意一个 level的 NODE_ID连接的信息。但是表 B中的 NODE_ID 具体对应到表 A中哪个 level是未知的。对此,最先想到使用的是 OR运算,但是由于效率太低,速度很慢,后来使用 INSTR代替,查询速度得到明显提高。
表结构
表 A - A_SEQ_ID, LVL1_NODE_ID, LVL2_NODE_ID, LVL3_NODE_ID, LVL4_NODE_ID, LVL5_NODE_ID, LVL6_NODE_ID, LVL7_NODE_ID, LVL8_NODE_ID, LVL9_NODE_ID, LVL10_NODE_ID
表 B - B_SEQ_ID, NODE_ID, INFO
开始时的 sql
01.SELECT *02. FROM A, B03.WHERE A.LVL1_NODE_ID = B.NODE_ID OR04. A.LVL2_NODE_ID = B.NODE_ID OR05. A.LVL3_NODE_ID = B.NODE_ID OR 06. A.LVL4_NODE_ID = B.NODE_ID OR 07. A.LVL5_NODE_ID = B.NODE_ID OR 08. A.LVL6_NODE_ID = B.NODE_ID OR 09. A.LVL7_NODE_ID = B.NODE_ID OR10. A.LVL8_NODE_ID = B.NODE_ID OR 11. A.LVL9_NODE_ID = B.NODE_ID OR12. A.LVL10_NODE_ID = B.NODE_ID;这条 sql虽然可以达到最终的目的,但是由于表 A和表 B的数据量比较大,所以执行起来相当慢。
使用 Instr函数
1.SELECT *2. FROM A, B3.WHERE instr(4. (','||A.LVL1_NODE_ID||','||A.LVL2_NODE_ID||','||A.LVL3_NODE_ID||5. ','||A.LVL4_NODE_ID||','||A.LVL5_NODE_ID||','||A.LVL6_NODE_ID||6. ','||A.LVL7_NODE_ID||','||A.LVL8_NODE_ID||','||A.LVL9_NODE_ID||7. ','||A.LVL10_NODE_ID), 8. ','||B.NODE_ID||',') > 0;比起 OR语句一个字段一个字段的比较,instr函数更加高效。当 instr函数匹配到子串的时候就会返回子串在源字符串中的位置,所以这里用 大于0 即表示在表 A的源字符串中可以找到表 B的 NODE_ID (子串或源字符串为 NULL时返回 NULL)。
注:给每个字段加上逗号(',')的原因是匹配的一种方法,例如源数据是 1,2,3,13. 子串是 23.如果直接拼接的话,源字符串就变成 '12313',用instr('12313', '23') 明显可以匹配成功,但事实并非如此。所以换成给每个字符两边都加上逗号,不仅匹配字符也匹配其两边的逗号 - instr(',1,2,3,13,', '23')。
Oracle Instr 函数

其中: INSTR 接受 characters格式的输入字符集,返回 characters格式的子串位置,位置索引从 1开始; INSTRB 使用 bytes 而非 characters; INSTRC 使用 Unicode complete characters; INSTR2 使用UCS2 code points; INSTR4 使用UCS4 code points。
对于源字符串,除了INSTRC, INSTR2, 和 INSTR4 不允许CLOB 和 NCLOB 类型外,其他两个函数的源字符串接受CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB 或 NCLOB等任意数据类型。
instr 语法如下: instr( string1, string2, start_position,nth_appearance )
| string1 | 源字符串,要在此字符串中查找。 |
| string2 | 要在string1中查找的字符串 。 |
| start_position | 代表string1 的哪个位置开始查找。此参数可选,如果省略默认为1. 字符串索引从1开始。如果此参数为正,从左到右开始检索,如果此参数为负,从右到左检索,返回要查找的字符串在源字符串中的开始索引。 |
| nth_appearance | 代表要查找第几次出现的string2. 此参数可选,如果省略,默认为 1.如果为负数系统会报错。 |
注意: 如果String2在String1中没有找到,instr函数返回0。 示例: SELECT instr('syranmo','s') FROM dual; -- 返回 1 SELECT instr('syranmo','ra') FROM dual; -- 返回 3 SELECT instr('syran mo','a',1,2) FROM dual; -- 返回 0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
oracle 截取字符(substr),检索字符位置(instr) case when then else end语句使用 收藏常用函数:substr和instr1.SUBSTR(string,start_position,[length]) 求子字符串,返回字符串解释:string 元字符串 start_position 开始位置(从0开始) length 可选项,子字符串的个数For example:substr("ABCDEFG", 0); //返回:ABCDEFG,截取所有字符substr("ABCDEFG", 2); //返回:CDEFG,截取从C开始之后所有字符substr("ABCDEFG", 0, 3); //返回:ABC,截取从A开始3个字符substr("ABCDEFG", 0, 100); //返回:ABCDEFG,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。substr("ABCDEFG", -3); //返回:EFG,注意参数-3,为负值时表示从尾部开始算起,字符串排列位置不变。2.INSTR(string,subString,position,ocurrence)查找字符串位置解释:string:源字符串 subString:要查找的子字符串 position:查找的开始位置 ocurrence:源字符串中第几次出现的子字符串For example:INSTR('CORPORATE FLOOR','OR', 3, 2)中,源字符串为'CORPORATE FLOOR', 目标字符串为'OR',起始位置为3,取第2个匹配项的位置;返回结果为 14 ' |
|
1
2
3
|
oralce查询字符串截取<br>select substr('XIHE@GXCOURT.GX',instr('XIHE@GXCOURT.GX','@')+1) from dual<br>字段loginname='XIHE@GXCOURT.GX'截取@后面的内容不包括@<br><br><br>sql :charindex('字符串',字段)>0 charindex('administrator',MUserID)>0 <br><br><br>oracle:instr(字段,'字符串',1,1) >0 instr(MUserID,'administrator',1,1)>0 <br><br><br>在项目中用到了Oracle中 Instr 这个函数,顺便仔细的再次学习了一下这个知识。 <br><br>Oracle中,可以使用 Instr <br>函数对某个字符串进行判断,判断其是否含有指定的字符。 <br><br>其语法为: <br>Instr(string, substring, position, <br>occurrence) <br>其中 <br><br>string:代表源字符串; <br><br>substring:代表想聪源字符串中查找的子串; <br><br><br>position:代表查找的开始位置,该参数可选的,默认为 1; <br><br><br>occurrence:代表想从源字符中查找出第几次出现的substring,该参数也是可选的,默认为1; <br>如果 position <br>的值为负数,那么代表从右往左进行查找。 <br>返回值为:查找到的字符串的位置。 <br><br>对于 Instr <br>函数,我们经常这样使用:从一个字符串中查找指定子串的位置。 <br><br>例如: <br><br>SELECT Instr('Hello Word', <br>'o', -1, 1) "String" FROM Dual 的显示结果是 <br><br>Instring <br>———— <br>8 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号