数据采集与融合技术作业4
| 学号姓名 | 102202111 刘哲睿 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13285 |
| 这个作业的目标 | 用scrapy,Xpath和MySQL方法爬取各网站的数据信息 |
| 实验三仓库地址 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验3 |
• 作业①:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
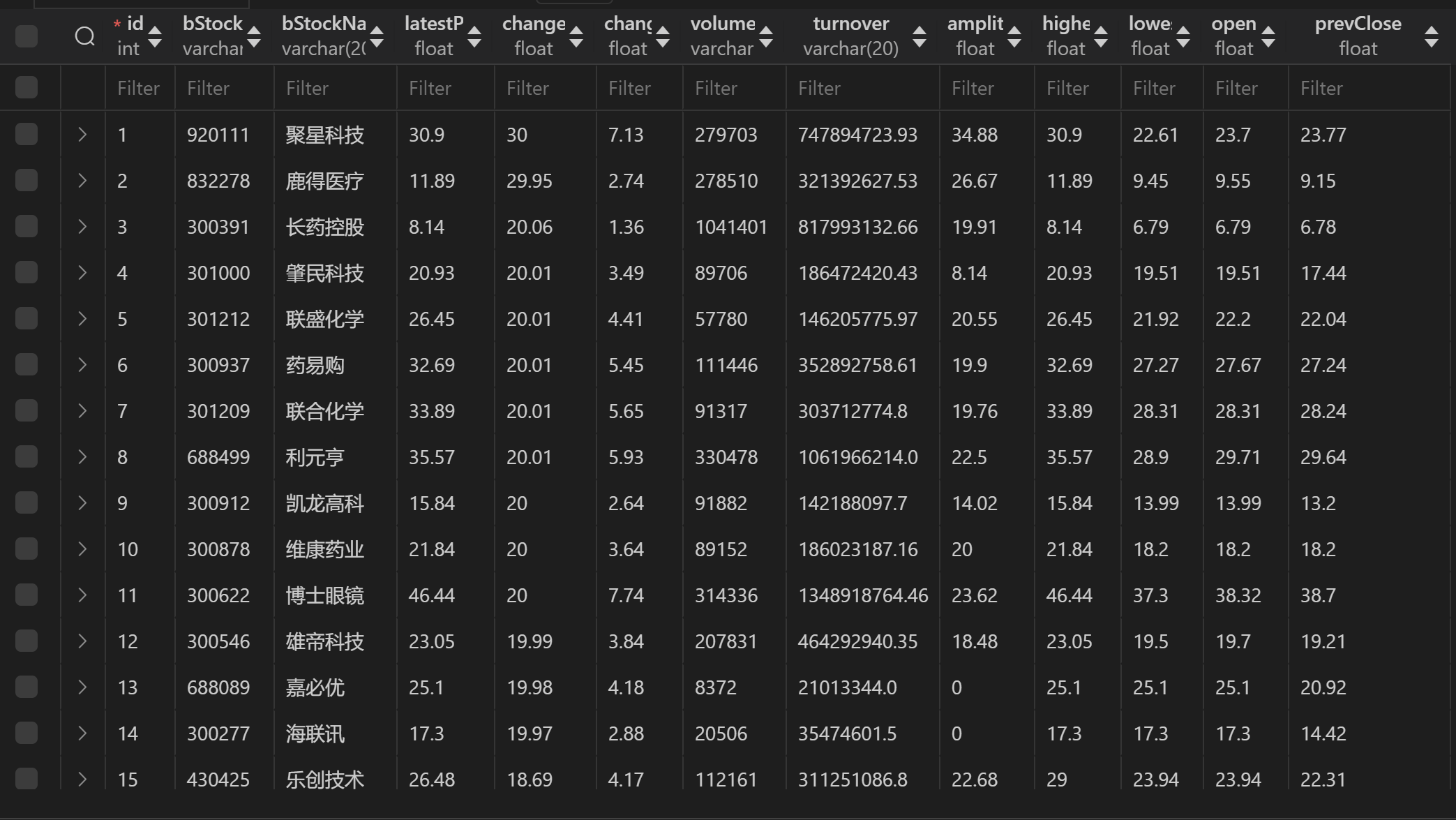
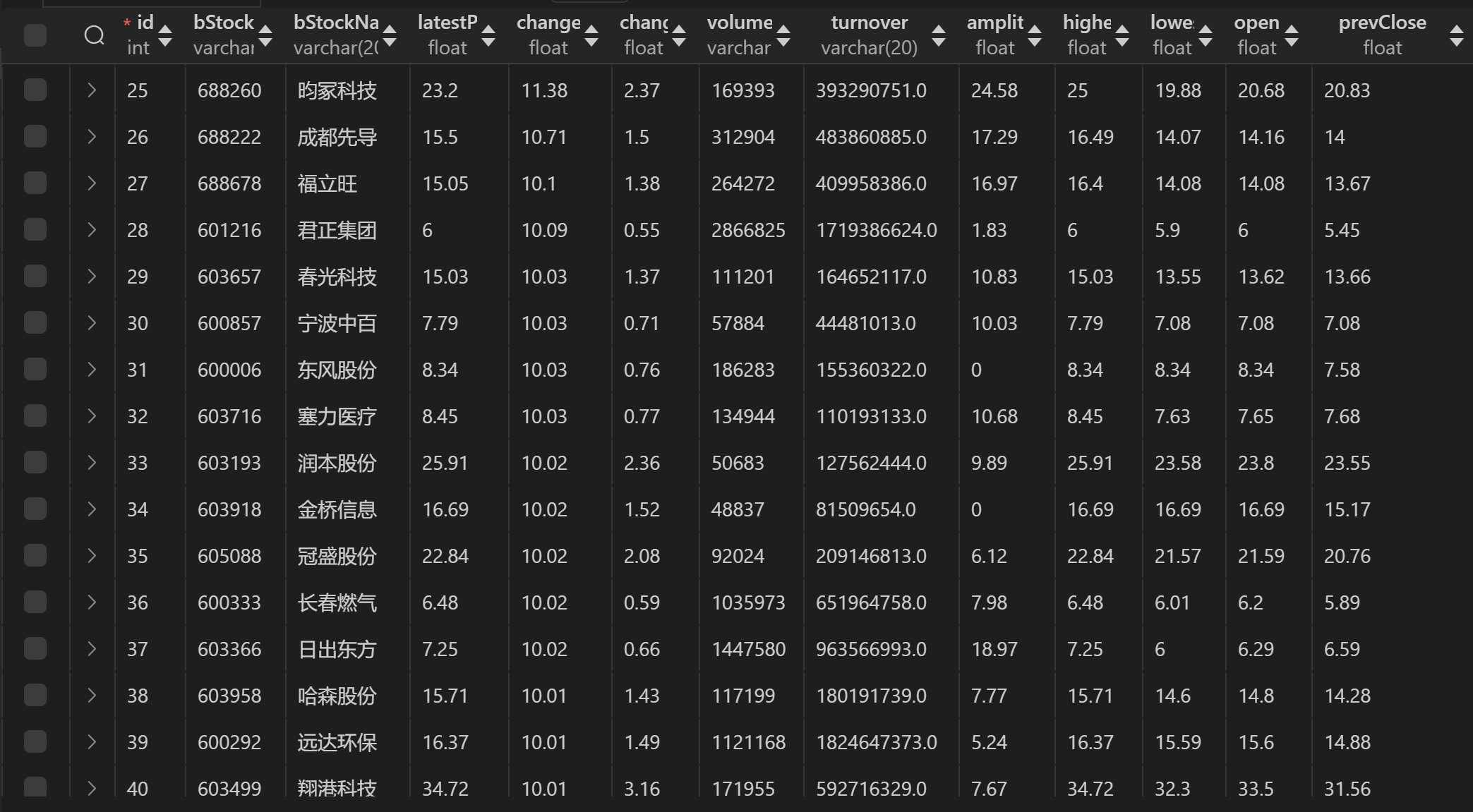
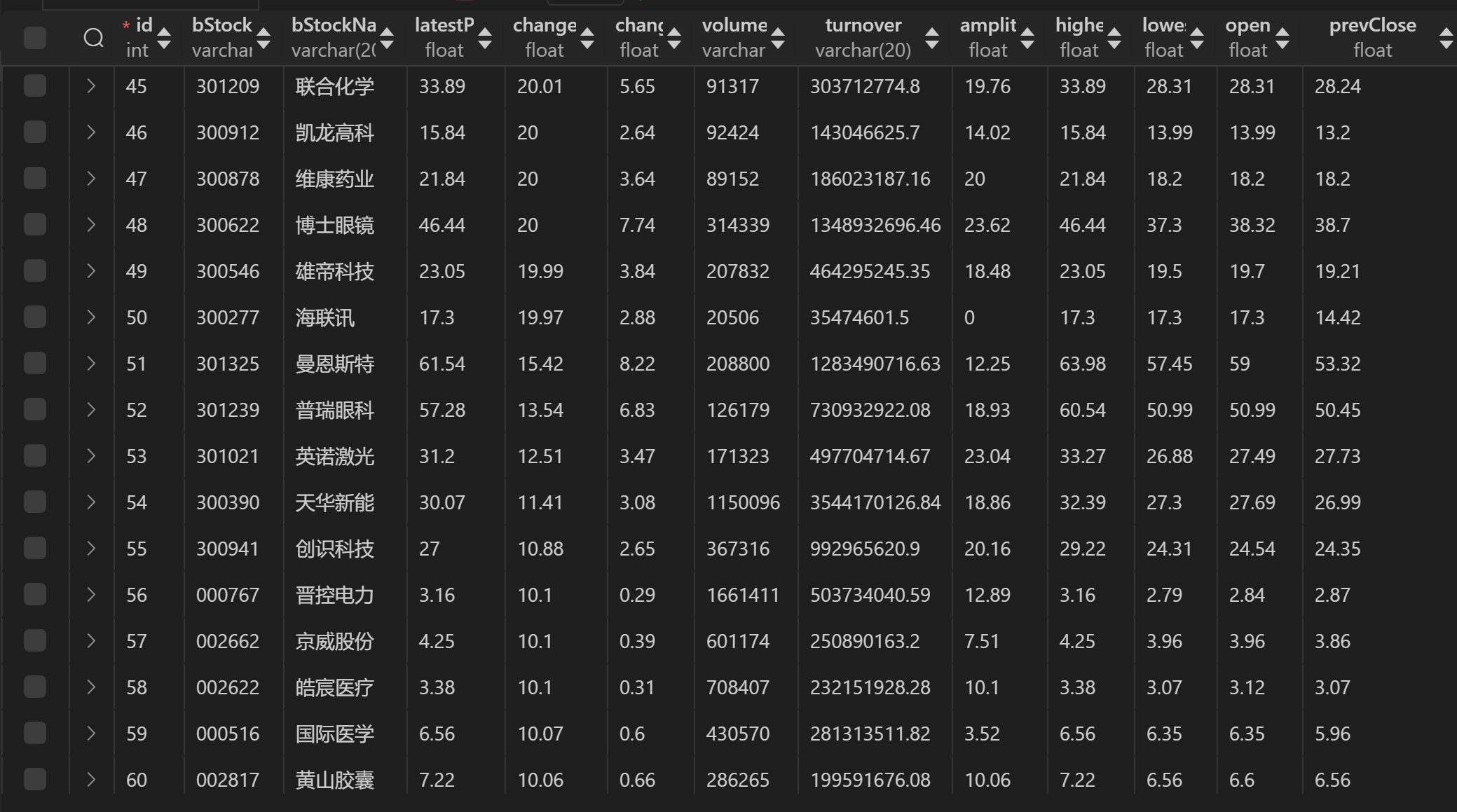
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
• Gitee 文件夹链接:
| Gitee文件夹链接 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验4/1 |
|---|
大致过程
- 配置数据库连接:使用 pymysql 库连接到本地 MySQL 数据库,并创建游标以便执行 SQL 查询。
- 配置 Selenium:设置 Selenium 配置,初始化 Chrome WebDriver 以便抓取网页内容。可以选择启用无头模式来避免打开浏览器界面。
- 定义 API URL:为沪深A股、上证A股、深证A股提供相应的 API URL,以便抓取相关股市数据。
- 获取数据:使用 Selenium 启动浏览器并访问各个 API URL,获取响应的 JSON 数据。
- 数据处理:提取 JSON 数据中的关键信息,并将其转换为结构化数据(如字典形式),对数据进行清洗和格式化。
- 存储数据:使用 pymysql 将清洗后的数据批量插入到 MySQL 数据库中的 stock_data 表。
核心代码
- 获取数据 (fetch_data)
def fetch_data(url):
driver.get(url)
page_source = driver.page_source
json_str = page_source.split("(", 1)[1].rsplit(")", 1)[0]
data = json.loads(json_str)
return data["data"]["diff"]
说明:fetch_data 函数访问提供的 URL,获取网页源代码。
页面源代码是 JSONP 格式的,因此需要提取其中的 JSON 数据部分。
使用 json.loads 将 JSON 字符串解析成字典格式,返回所需的股票数据部分。
2. 数据处理与清洗 (process_data)
def process_data(raw_data):
stock_data = []
for item in raw_data:
stock_info = {
"bStockNo": item["f12"],
"bStockName": item["f14"],
"latestPrice": float(item["f2"]),
"changeRate": float(item["f3"]),
"changeAmount": float(item["f4"]),
"volume": str(item["f5"]),
"turnover": str(item["f6"]),
"amplitude": float(item["f7"]),
"highest": float(item["f15"]),
"lowest": float(item["f16"]),
"open": float(item["f17"]),
"prevClose": float(item["f18"]),
}
stock_data.append(stock_info)
return stock_data
说明:process_data 函数遍历原始数据中的每个项目,提取股票的相关信息(如股票编号、名称、最新价格、涨跌幅等)。
对于数值数据,进行适当的类型转换(如 float),以确保数据格式的一致性。
将处理后的股票信息组成一个字典,存入一个列表中,作为返回值。
3. 数据存储到数据库 (save_to_database)
def save_to_database(data):
sql = """
INSERT INTO stock_data (bStockNo, bStockName, latestPrice, changeRate, changeAmount,
volume, turnover, amplitude, highest, lowest, open, prevClose)
VALUES (%(bStockNo)s, %(bStockName)s, %(latestPrice)s, %(changeRate)s, %(changeAmount)s,
%(volume)s, %(turnover)s, %(amplitude)s, %(highest)s, %(lowest)s, %(open)s, %(prevClose)s)
"""
cursor.executemany(sql, data)
db.commit()
说明:save_to_database 函数使用 pymysql 提供的 executemany 方法将处理后的数据批量插入到 stock_data 表中。
SQL 插入语句使用了参数化查询,确保数据的安全性和防止 SQL 注入。
输出结果
- 三个板块的数据都放在一起
心得体会
通过此次项目,我系统掌握了动态数据抓取、清洗和存储的完整流程。使用 Selenium 实现动态网页数据的抓取,灵活解析 JSONP 数据,避免了复杂网页结构的直接解析。数据清洗过程中,通过类型转换和字符串处理提升了数据的规范性,同时强化了对清洗环节重要性的理解。在数据库操作中,学习了表设计、参数化插入以及批量操作,大幅提高了存储效率并增强了安全性。面对 JSONP 数据解析、字段缺失以及存储效率等难题,通过优化逻辑和异常处理顺利解决。项目中采用模块化设计,不仅提升了代码的可读性和复用性,也为后续扩展提供了便利。这次实践让我深刻体会到细节调试和健壮性设计对项目成功的重要性,为日后从事数据抓取和处理工作打下了坚实基础。
• 作业②:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
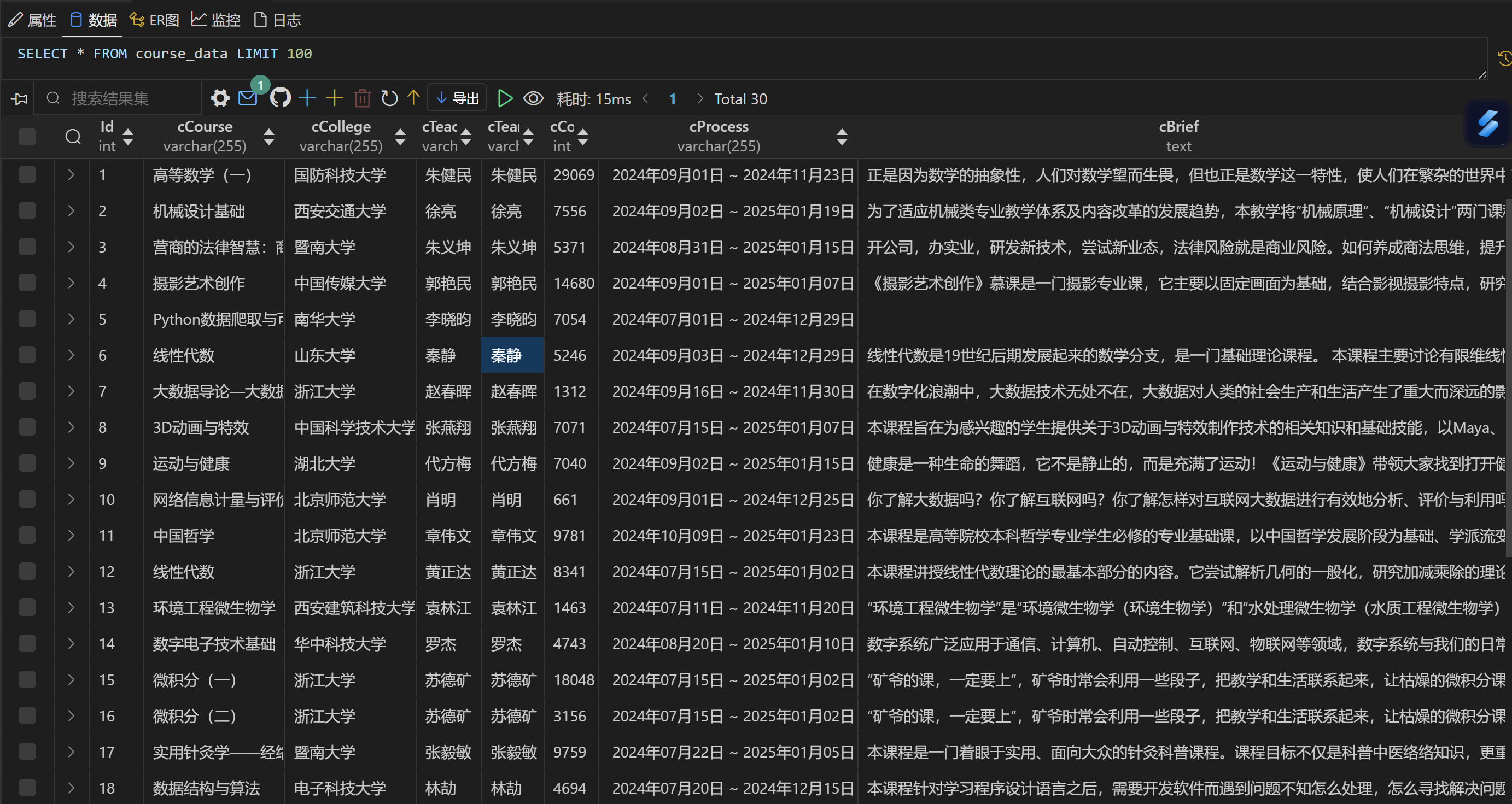
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国 mooc 网:https://www.icourse163.org
o 输出信息:MYSQL 数据库存储和输出格式
• Gitee 文件夹链接:
| Gitee文件夹链接 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验4/2 |
|---|
大致过程:
- 登录功能:使用 Selenium 自动化登录 MOOC 网站。此步骤包括输入手机号和密码,点击登录按钮。
- 选择并进入课程列表页面:通过 Selenium 查找并点击课程页面链接,进入课程列表页。
- 获取课程列表:获取课程页面中每一项课程的元素,遍历每个课程,点击进入详细信息页面。
- 抓取课程详情:在课程详情页面中,提取课程的各个信息
- 清洗数据:对获取的数据进行清洗,如清理数字字符串中的非数字字符和提取课程开课时间
- 分页处理:确保抓取到的课程数达到指定的数量(按每页课程数量循环翻页,直到达到目标)。
- 存储到数据库:将抓取到的课程数据插入 MySQL 数据库中
核心代码
- 登录功能 (login 函数)
def login(driver, username, password):
try:
driver.get("https://www.icourse163.org")
time.sleep(2)
# 点击登录按钮
login_register_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "div._3uWA6[role='button']"))
)
login_register_button.click()
# 切换到登录 iframe
iframe = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "iframe[src*='index_dl2_new.html']"))
)
driver.switch_to.frame(iframe)
# 输入账号和密码
phone_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "phoneipt"))
)
phone_input.send_keys(username)
password_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "j-inputtext"))
)
password_input.send_keys(password)
# 点击登录按钮
login_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "submitBtn"))
)
login_button.click()
driver.switch_to.default_content()
time.sleep(3)
except Exception as e:
print(f"Login failed: {e}")
driver.quit()
raise
功能:自动化登录流程,包括打开登录页面、输入用户名和密码、点击登录。
- 爬取课程数据
while total_scraped < course_limit:
course_items = driver.find_elements(By.XPATH, '//div[contains(@class, "_2mbYw") and contains(@class, "commonCourseCardItem")]')
for course_item in course_items:
if total_scraped >= course_limit:
break
try:
# 滚动页面确保课程可见
driver.execute_script("arguments[0].scrollIntoView();", course_item)
time.sleep(1)
course_item.click()
time.sleep(2)
driver.switch_to.window(driver.window_handles[-1])
# 获取课程详情
cCourse = driver.find_element(By.XPATH, '//span[@class="course-title f-ib f-vam"]').text
cCollege = driver.find_element(By.XPATH, "//img[@class='u-img']").get_attribute("alt")
cTeacher = driver.find_element(By.XPATH, '//div[@class="cnt f-fl"]//h3[@class="f-fc3"]').text
cTeam = cTeacher
cCount = driver.find_element(By.XPATH, '//span[@class="count"]').text
cProcess = driver.find_element(By.XPATH, "//div[@class='course-enroll-info_course-info_term-info_term-time']").text
cBrief = driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']").text
功能:从目标课程列表页面爬取指定数量的课程详情并保存到数据库。
3. 翻页处理
# 翻页处理
if total_scraped < course_limit:
try:
next_page_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@class="_3YiUU " and text()="下一页"]'))
)
next_page_button.click()
time.sleep(3)
except Exception as e:
print("No more pages to scrape.")
break
功能:在抓取课程时自动翻页,确保抓取到足够数量的课程。找到并点击“下一页”按钮,如果没有下一页则停止抓取。
4. 数据清洗
# 数据清洗
participants = int(re.sub(r'\D', '', cCount)) # 提取数字参与人数
course_time = re.sub(r'开课时间:', '', cProcess) # 清理课程时间的无关文字
功能:清理抓取的数据中的不必要字符,cCount:从字符串中提取参与人数的数字部分。cProcess:去掉“开课时间:”前缀,只保留时间。
5. 存储到数据库
# 插入数据库
if insert_values:
insert_query = """
INSERT INTO course_data (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
cursor.executemany(insert_query, insert_values)
db_connection.commit()
功能:将抓取到的课程数据批量插入到 MySQL 数据库中。
输出结果
心得体会
在进行爬取 MOOC 课程数据的项目过程中,我遇到了一些挑战,并且在解决这些问题的过程中学到了很多技术和实践方面的经验。
遇到的困难与解决方法
- 课程列表页面的动态加载与分页问题
在开始爬取课程数据时,我发现课程列表页面是动态加载的,需要点击“下一页”按钮才能加载更多课程。然而,在爬取多个页面时,Selenium 的点击操作有时会出现失误,导致无法正确翻页。
解决方法:我在代码中加入了翻页逻辑,每次抓取完当前页面的课程后,自动点击“下一页”按钮,确保翻页操作的顺利进行。另外,我添加了异常处理机制,在没有“下一页”按钮时,能够安全退出,避免程序崩溃。 - 课程详情页面信息提取的准确性
在提取课程信息时,发现有时页面的元素定位不准确,导致获取的信息为空或不完整,特别是在处理课程详情这类内容时。
解决方法:我利用 Selenium 的 WebDriverWait 和 EC.element_to_be_clickable 等方法来确保元素加载完成并且可以进行点击或获取数据,同时增加了异常捕获机制,避免在某些课程的元素缺失时导致程序中断。 - Selenium 页面切换与 iframe 问题
登录过程中,我需要在多个窗口和 iframe 之间切换。切换不当会导致操作失误,特别是在数据爬取的界面特别容易出现错误。
解决方法:我在登录时使用了 driver.switch_to.frame() 来切换到正确的 iframe,并使用 driver.switch_to.default_content() 来返回主页面,确保操作的顺利进行。
收获与体会
通过这次爬虫项目,我提升了对 Selenium 库的使用能力,深入理解了网页元素定位、动态加载内容、分页和页面切换等核心技能。此外,我学会了如何处理不规则字符串并进行数据清洗,提升了数据准确性。通过使用 MySQL 数据库存储爬取的数据,我也增强了数据库操作能力,能够高效地管理数据。项目中,我深入理解了异常处理和代码优化的重要性,确保程序能够在长时间运行中稳定执行。同时,实际操作让我对 Web 自动化有了更具体的认识。尽管遇到了一些困难,通过不断调试和学习,我克服了这些挑战,对数据抓取和 Web 自动化有了更深入的了解,为未来类似项目打下了坚实的基础。
• 作业③:
o 要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx中的任务,即为下面5个任务,具体操作见文档。
• 环境搭建:
·任务一:开通 MapReduce 服务

• 实时分析开发实战:
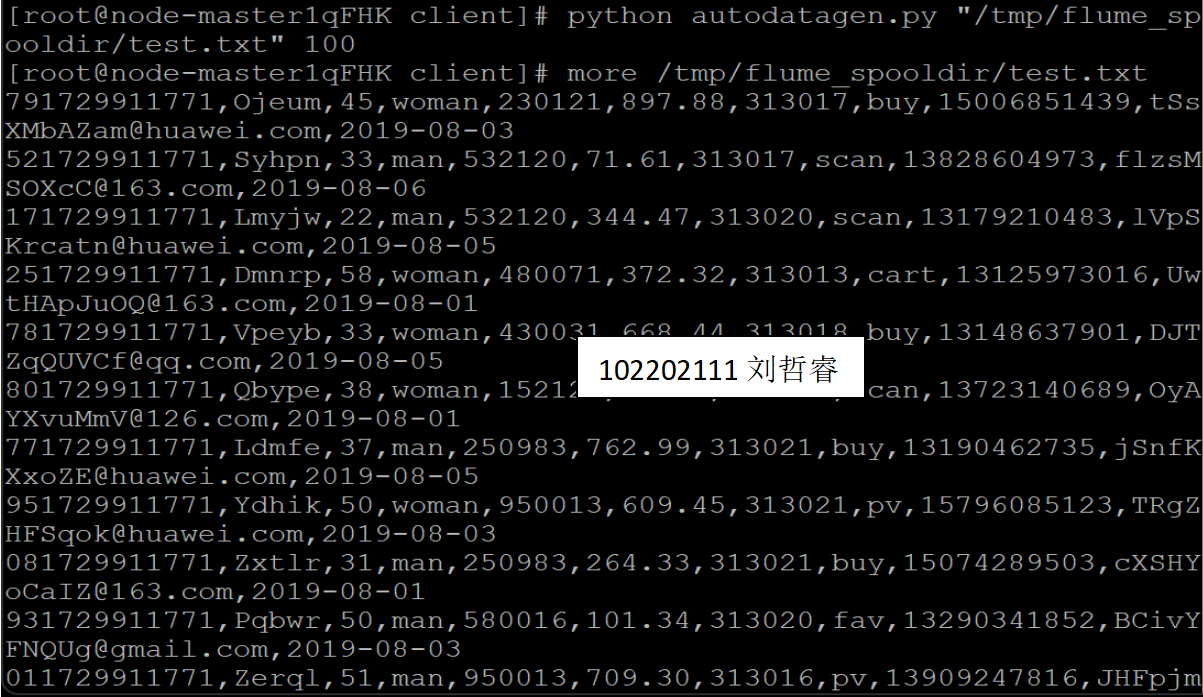
·任务一:Python 脚本生成测试数据
·任务二:配置 Kafka
·任务三: 安装 Flume 客户端
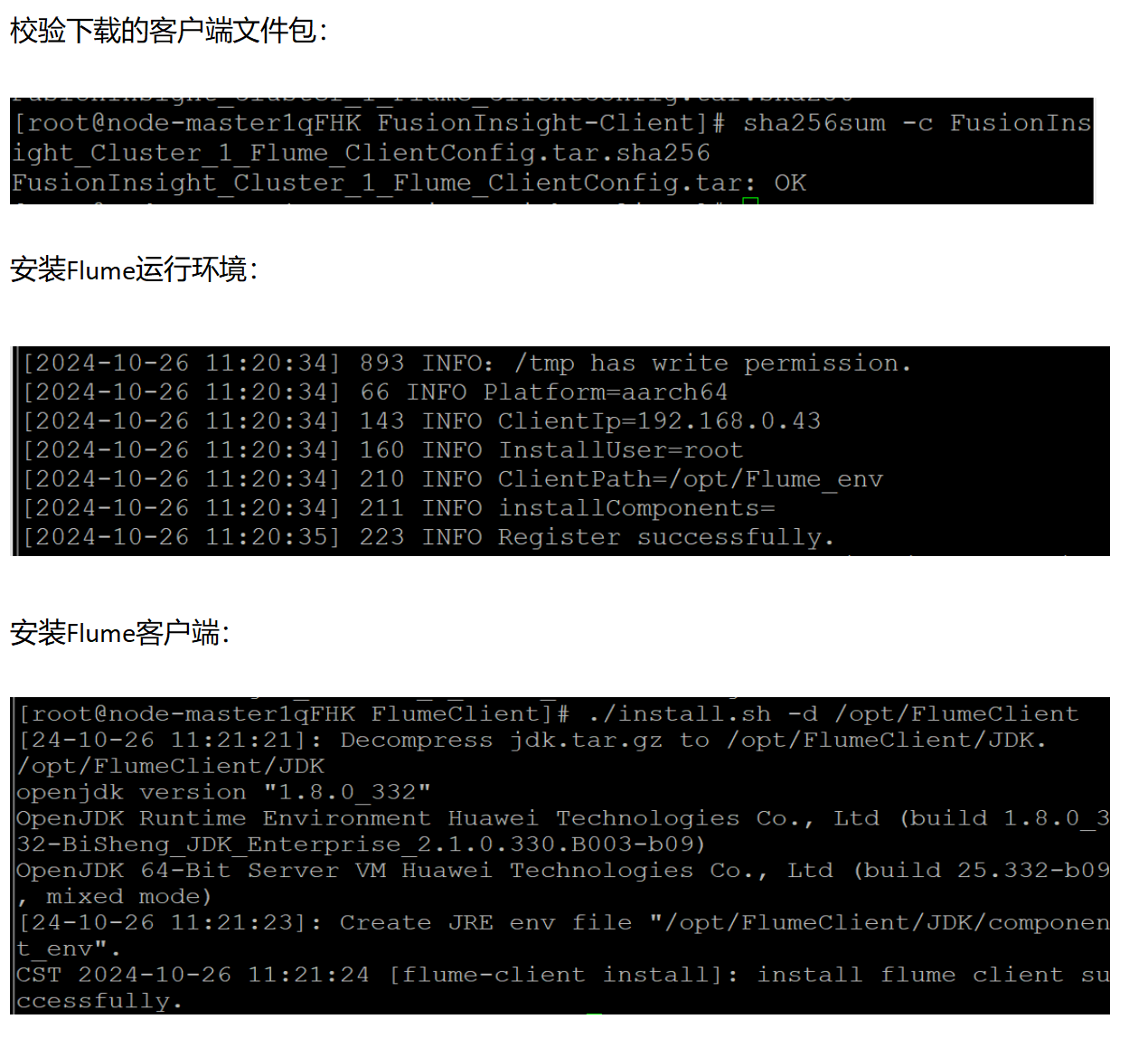
·任务四:配置 Flume 采集数据
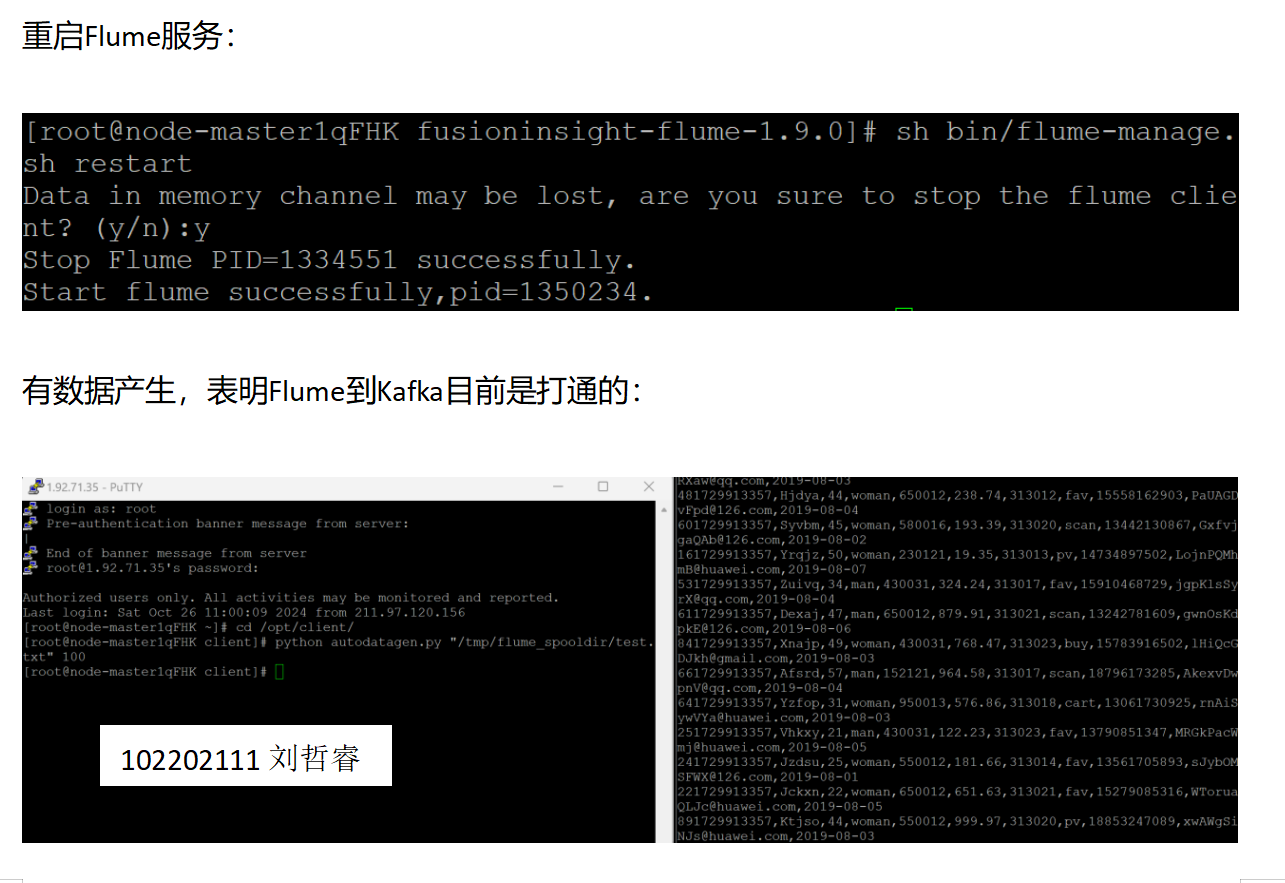
心得体会
通过学习 Flume 日志采集实验手册,我深入了解了 Flume 的核心概念和日志采集服务的使用方法,包括数据流配置与传输优化。借助 华为云实验,我进一步掌握了大数据相关服务和实时数据处理的实际操作,熟悉了 Xshell 工具的使用和远程环境管理。
实践中,我逐一完成文档任务,从环境配置到数据采集和实时处理,全面掌握了大数据服务与工具的操作流程,提升了技术技能和操作能力。同时,对大数据生态系统及其从数据采集到实时处理的完整流程有了更清晰的理解。
本次学习让我强化了 Flume 使用、实时数据处理和工具应用能力,拓宽了大数据相关技术的视野,为后续实践打下了坚实基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号