数据采集与融合技术作业3
| 学号姓名 | 102202111 刘哲睿 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13285 |
| 这个作业的目标 | 用scrapy,Xpath和MySQL方法爬取各网站的数据信息 |
| 实验三仓库地址 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验3 |
作业①:
| Gitee文件夹链接 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验3/图片/dangdang_scraper |
|---|
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
-
实验过程:
1.使用 Scrapy 的命令行创建一个新的项目:
2.爬虫程序dangdang_images.py代码(总页数11页)、总下载的图片数量111张):scrapy startproject dangdang_scraper cd dangdang_scraper
3.items.py代码:class DangdangImagesSpider(scrapy.Spider): name = "dangdang_images" allowed_domains = ["search.dangdang.com", "img3m5.ddimg.cn", "img3m6.ddimg.cn", "img3m7.ddimg.cn", "img3m8.ddimg.cn"] start_urls = ["https://search.dangdang.com/?key=%CA%E9&act=input"] max_pages = 11 max_images = 111 image_count = 0 def parse(self, response): # 修改选择器以获取正确的图片 URL images = response.xpath('//ul[@class="bigimg"]//img/@data-original').getall() # 控制图片数量 for img_url in images: if self.image_count >= self.max_images: return self.image_count += 1 # 检查 URL 是否以 // 开头,添加协议 if img_url.startswith('//'): img_url = 'http:' + img_url # 或 'https:',根据需要选择 print(f"Scraping image URL: {img_url}") # Debug print item = DangdangScraperItem() item['image_urls'] = [img_url] yield item
4.settings.py代码:import scrapy class DangdangScraperItem(scrapy.Item): # 定义你想要抓取的字段 image_urls = scrapy.Field() # 存储图片的 URL images = scrapy.Field() # 存储下载后的图片信息
若是要多线程爬取,则将线程数量改为16:# 下载延迟(根据网站设置) DOWNLOAD_DELAY = 1.5 # 图片存储路径 IMAGES_STORE = r'C:\Users\刘哲睿\Desktop\Typora\数据采集实验3\图片\dangdang_scraper\images' # 启用 ImagesPipeline ITEM_PIPELINES = { 'scrapy.pipelines.images.ImagesPipeline': 1, } FEED_EXPORT_ENCODING = "utf-8" SPIDER_MIDDLEWARES = { 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None, } DOWNLOADER_MIDDLEWARES = { 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, } ITEM_PIPELINES = { 'dangdang_scraper.pipelines.DangdangImagesPipeline': 1, } OFFSITE_ENABLED = False # 单线程 CONCURRENT_REQUESTS = 1 RETRY_ENABLED = True RETRY_TIMES = 3 # 重试次数
5.配置图片管道pipelines.py代码:CONCURRENT_REQUESTS = 16
6.在终端输入运行命令:from scrapy.pipelines.images import ImagesPipeline from scrapy.http import Request class DangdangImagesPipeline(ImagesPipeline): def get_media_requests(self, item, info): for image_url in item.get('image_urls', []): yield Request(image_url) def item_completed(self, results, item, info): item['images'] = [x['path'] for ok, x in results if ok] return itemscrapy crawl dangdang_scraper
输出图片(111张):
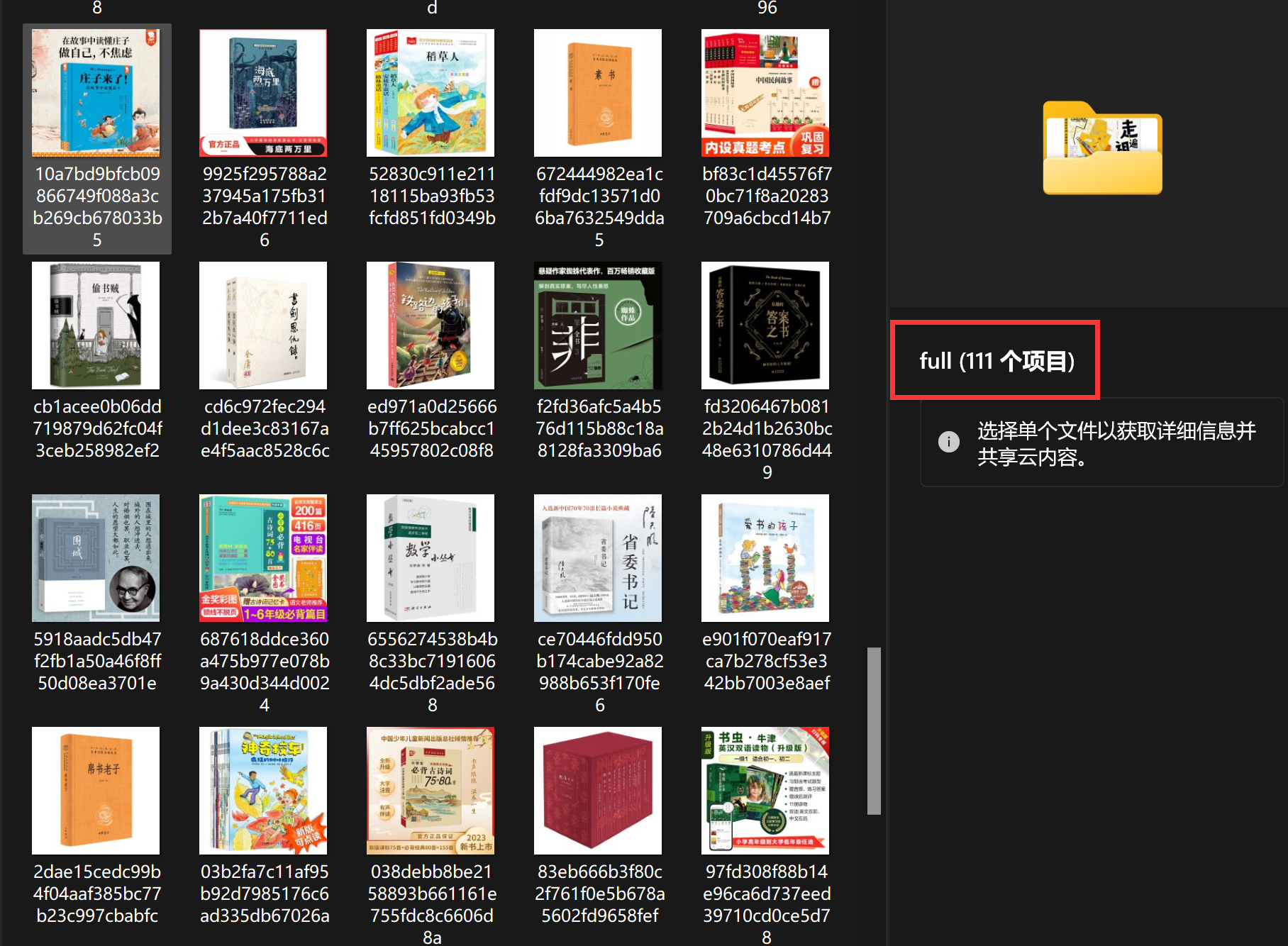
-
心得体会:
通过本次针对当当网图片爬取的实验,我对Scrapy框架有了更深刻的认识,尤其是其在定向图片爬取方面的应用。Scrapy的ImagesPipeline极大地简化了图片下载和存储的工作,使爬虫编写变得轻松。以往处理图片相关任务时,需操心诸多细节,如今借助它,我们只需专注于提取图片链接这一核心逻辑,无需过多关注底层操作,提高了开发效率,降低了出错概率,让开发过程更顺畅。
在实现单线程和多线程爬取过程中,我体会到多线程对提升爬取效率的重要性。调整CONCURRENT_REQUESTS等配置,可显著提升爬虫并发性能,加快图片下载速度。但同时要注意对目标网站的影响,避免因过度请求导致服务器压力过大。我们需在高效与友好之间找到平衡。
总体而言,本次实验让我更熟悉Scrapy框架的使用,以及如何高效、规范地实现网页信息爬取,对我今后学习和实践帮助很大。
作业②
| Gitee文件夹链接 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验3/股票/stock_scraper |
|---|
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
-
实验过程:
1.使用 Scrapy 的命令行创建一个新的项目:
2.爬虫程序stock_spider.py代码:scrapy startproject stock_scraper cd stock_scraper
3.items.py代码:class StockSpider(scrapy.Spider): name = 'stock' start_urls = ['https://21.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112401677766641902747_1730445460944&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=b:DLMK0144&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1730445460948'] def start_requests(self): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', } for url in self.start_urls: yield scrapy.Request(url, headers=headers, callback=self.parse) def parse(self, response): text = response.text json_text = text[text.find('(') + 1:text.rfind(')')] json_data = json.loads(json_text) stocks = json_data.get('data', {}).get('diff', []) for stock in stocks: item = StockItem() item['bStockNo'] = stock.get('f12') # 股票代码 item['stockName'] = stock.get('f14') # 股票名称 item['latestPrice'] = stock.get('f2') # 最新报价 item['changeRate'] = stock.get('f3') # 涨跌幅 item['changeAmount'] = stock.get('f4') # 涨跌额 item['volume'] = stock.get('f5') # 成交量 item['amplitude'] = stock.get('f7') # 振幅 item['high'] = stock.get('f15') # 最高 item['low'] = stock.get('f16') # 最低 item['openPrice'] = stock.get('f17') # 今开 item['closePrice'] = stock.get('f18') # 昨收 yield item
4.settings.py代码:import scrapy class StockItem(scrapy.Item): id = scrapy.Field() # 序号 bStockNo = scrapy.Field() # 股票代码 stockName = scrapy.Field() # 股票名称 latestPrice = scrapy.Field() # 最新报价 changeRate = scrapy.Field() # 涨跌幅 changeAmount = scrapy.Field() # 涨跌额 volume = scrapy.Field() # 成交量 amplitude = scrapy.Field() # 振幅 high = scrapy.Field() # 最高 low = scrapy.Field() # 最低 openPrice = scrapy.Field() # 今开 closePrice = scrapy.Field() # 昨收
5.配置图片管道pipelines.py代码:BOT_NAME = "stock_scraper" SPIDER_MODULES = ["stock_scraper.spiders"] NEWSPIDER_MODULE = "stock_scraper.spiders" ROBOTSTXT_OBEY = False ITEM_PIPELINES = { "stock_scraper.pipelines.StockScraperPipeline": 300, } REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7" TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor" FEED_EXPORT_ENCODING = "utf-8" ITEM_PIPELINES = { 'stock_scraper.pipelines.StockScraperPipeline': 300, } USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0'
6.在终端输入运行命令:class StockScraperPipeline: def open_spider(self, spider): self.connection = mysql.connector.connect( host='localhost', user='root', password='123456', database='hh' ) self.cursor = self.connection.cursor() def close_spider(self, spider): self.connection.commit() self.cursor.close() self.connection.close() def process_item(self, item, spider): sql = """INSERT INTO stocks (bStockNo, stockName, latestPrice, changeRate, changeAmount, volume, amplitude, high, low, openPrice, closePrice) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""" self.cursor.execute(sql, ( item['bStockNo'], item['stockName'], item['latestPrice'], item['changeRate'], item['changeAmount'], item['volume'], item['amplitude'], item['high'], item['low'], item['openPrice'], item['closePrice'] )) return itemscrapy crawl stock
输出结果(sql库表格):
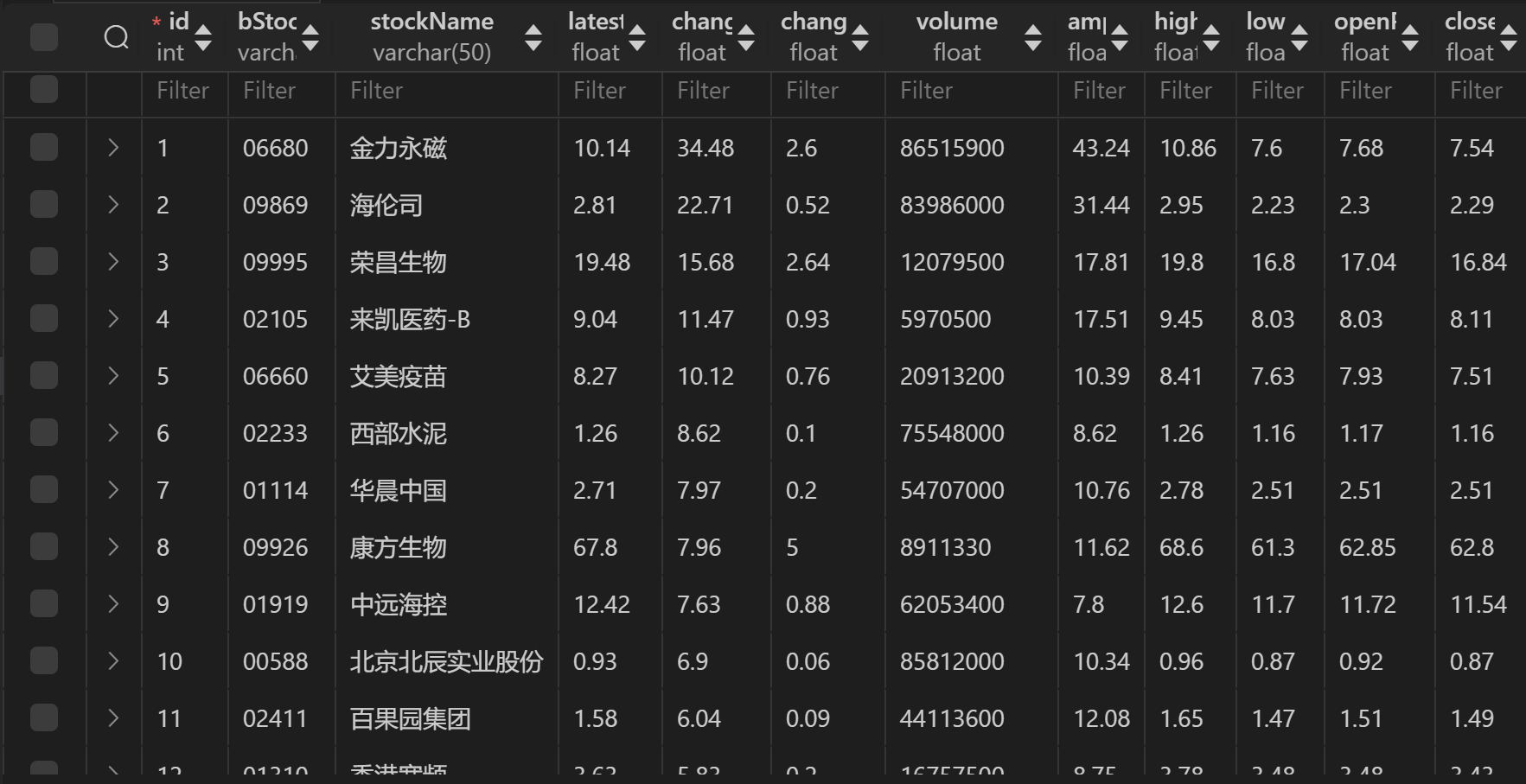
-
心得体会:
通过此次股票信息爬取及存储作业,我对 Scrapy 框架数据流处理机制,尤其是 Item 和 Pipeline 的协同工作有了深入认识。Item 定义数据结构,Pipeline 负责数据清洗、处理与存储,提升了程序模块化程度,便于维护和扩展。将股票信息存至 MySQL 数据库让我在数据库操作上进步显著,包括创建库表、规划字段等,确保了数据完整性和一致性,还熟练掌握了 Python 与 MySQL 交互技巧。
作业中遇到网站反爬虫机制和数据格式不一致等问题,我通过调整爬取策略、增加数据验证与清洗步骤成功解决,加深了对爬虫实际应用技巧的理解,提升了解决问题能力,在技术层面和问题处理能力上都有收获,为后续探索积累了经验
作业③:
| Gitee文件夹链接 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验3/外汇/forex_scraper |
|---|
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:(MySQL数据库存储和数据格式)
-
实验过程:
1.使用 Scrapy 的命令行创建一个新的项目:
2.爬虫程序boc.py代码:scrapy startproject forex_scraper cd forex_scraper
3.items.py代码:class BOCSpider(scrapy.Spider): name = 'boc' allowed_domains = ['boc.cn'] start_urls = ['https://www.boc.cn/sourcedb/whpj/'] def parse(self, response): rows = response.xpath('//tr[td]') for row in rows: item = ForexItem() item['currency'] = row.xpath('td[1]/text()').get() item['tbp'] = row.xpath('td[2]/text()').get() item['cbp'] = row.xpath('td[3]/text()').get() item['tsp'] = row.xpath('td[4]/text()').get() item['csp'] = row.xpath('td[5]/text()').get() item['time'] = row.xpath('td[7]/text()').get() yield item
4.settings.py代码:import scrapy class ForexItem(scrapy.Item): currency = scrapy.Field() tbp = scrapy.Field() # 现汇买入价 cbp = scrapy.Field() # 现钞买入价 tsp = scrapy.Field() # 现汇卖出价 csp = scrapy.Field() # 现钞卖出价 time = scrapy.Field() # 发布时间ITEM_PIPELINES = { "forex_scraper.pipelines.ForexPipeline": 300,
}
5.配置图片管道pipelines.py代码:
```python
import mysql.connector
class ForexPipeline:
def open_spider(self, spider):
self.connection = mysql.connector.connect(
host='localhost',
user='root', # 替换为你的数据库用户名
password='123456', # 替换为你的数据库密码
database='hh' # 替换为你的数据库名
)
self.cursor = self.connection.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS forex (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(255),
tbp DECIMAL(10, 2),
cbp DECIMAL(10, 2),
tsp DECIMAL(10, 2),
csp DECIMAL(10, 2),
time VARCHAR(255)
)''')
def close_spider(self, spider):
self.connection.commit()
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
self.cursor.execute('''
INSERT INTO forex (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
''', (item['currency'], item['tbp'], item['cbp'], item['tsp'], item['csp'], item['time']))
return item
6.在终端输入运行命令:
scrapy crawl boc
输出结果(sql库表格):
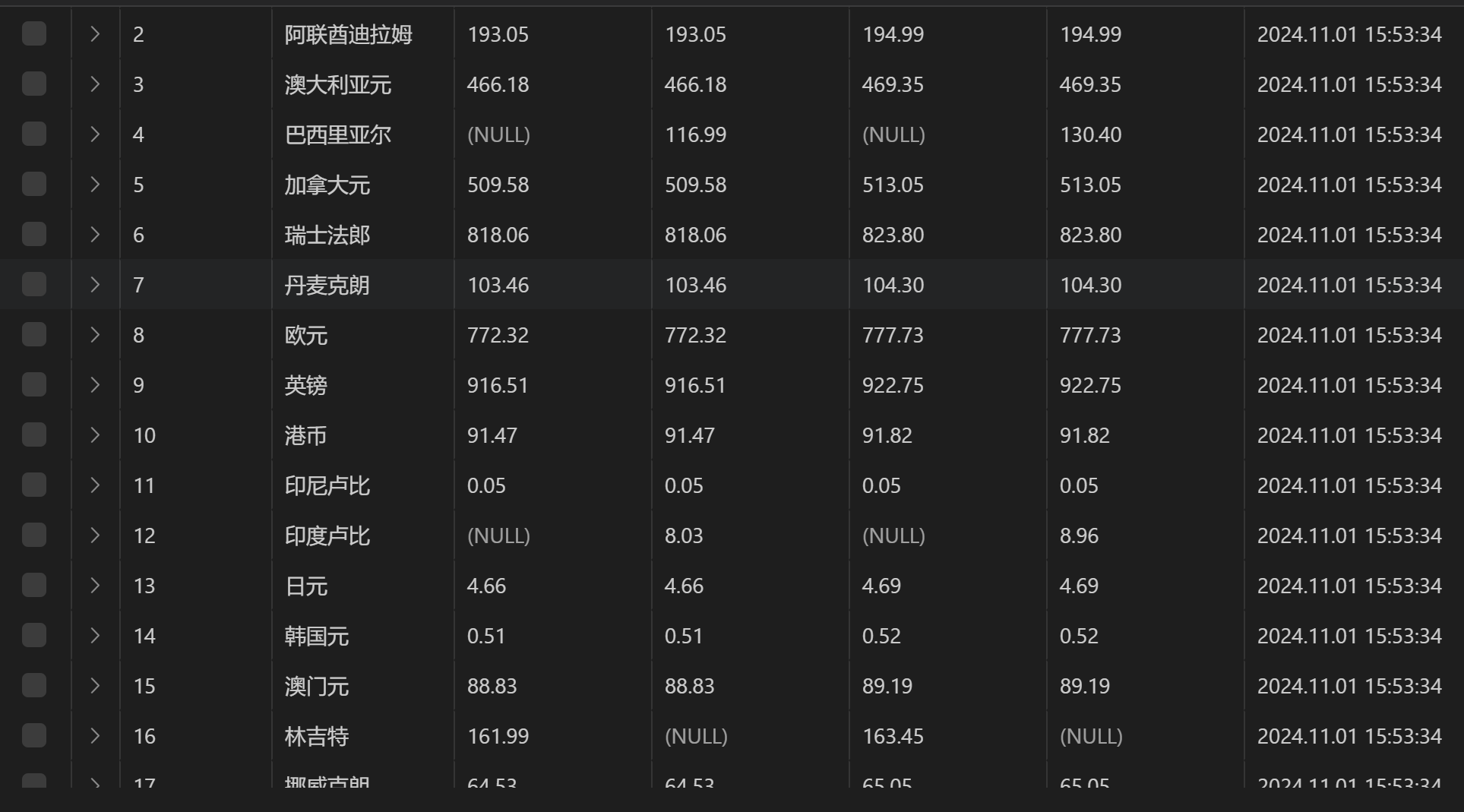
-
心得体会:
通过本次作业,我深入理解了 Scrapy 框架中 Item 和 Pipeline 的作用与实现。Item 定义数据结构,Pipeline 处理并存储数据(如存到 MySQL 数据库)。结合 XPath 提取数据,经 Pipeline 处理后存储。
项目中综合运用 Scrapy、XPath 和 MySQL,包括用 Scrapy 爬虫和 XPath 从中国银行网外汇汇率页面抓数据,在 Pipeline 中处理,再用 PyMySQL 存到数据库。但在设计数据库表结构时,需要考虑到数据之间的关系和查询效率
该作业巩固了我的相关技术知识,提升了我的技术能力和问题解决能力,积累了项目经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号