数据采集与融合技术作业2
| 学号姓名 | 102202111 刘哲睿 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13285 |
| 这个作业的目标 | 爬取天气网、股票相关信息、中国大学2021主榜所有院校信息,并存储在数据库中 |
| 实验二仓库地址 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验2 |
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
1)实验过程:
-
1.1核心代码:
get_weather 函数:提取天气信息:找到包含天气信息的元素,遍历每个元素以获取日期、天气情况、温度信息。
import requests
from bs4 import BeautifulSoup
import csv
def get_weather(city_name, city_code):
weather_url = f'https://www.weather.com.cn/weather/{city_code}.shtml'
try:
# 请求天气页面
weather_response = requests.get(weather_url)
weather_response.encoding = 'utf-8'
weather_soup = BeautifulSoup(weather_response.text, 'html.parser')
# 找到天气数据的父元素并提取每一天的天气信息
weather_elements = weather_soup.find('ul', class_='t clearfix').find_all('li')
weather_data = [] # 保存天气数据
for element in weather_elements:
date_str = element.find('h1').text.strip() if element.find('h1') else None
weather = element.find('p', class_='wea').text.strip() if element.find('p', class_='wea') else None
# 获取温度信息
temperature_info = element.find('p', class_='tem').text.strip() if element.find('p', class_='tem') else None
if temperature_info:
if '/' in temperature_info and '℃' in temperature_info:
temperature_high, temperature_low = temperature_info.split('/')
temperature_high = temperature_high.replace('℃', '').strip()
temperature_low = temperature_low.replace('℃', '').strip()
else:
temperature_high = temperature_low = temperature_info.replace('℃', '').strip()
else:
temperature_high = temperature_low = None
if date_str:
if '(' in date_str:
date_str = date_str.split('(')[0]
weather_data.append([city_name, date_str, weather, temperature_high, temperature_low])
-
1.2输出结果:
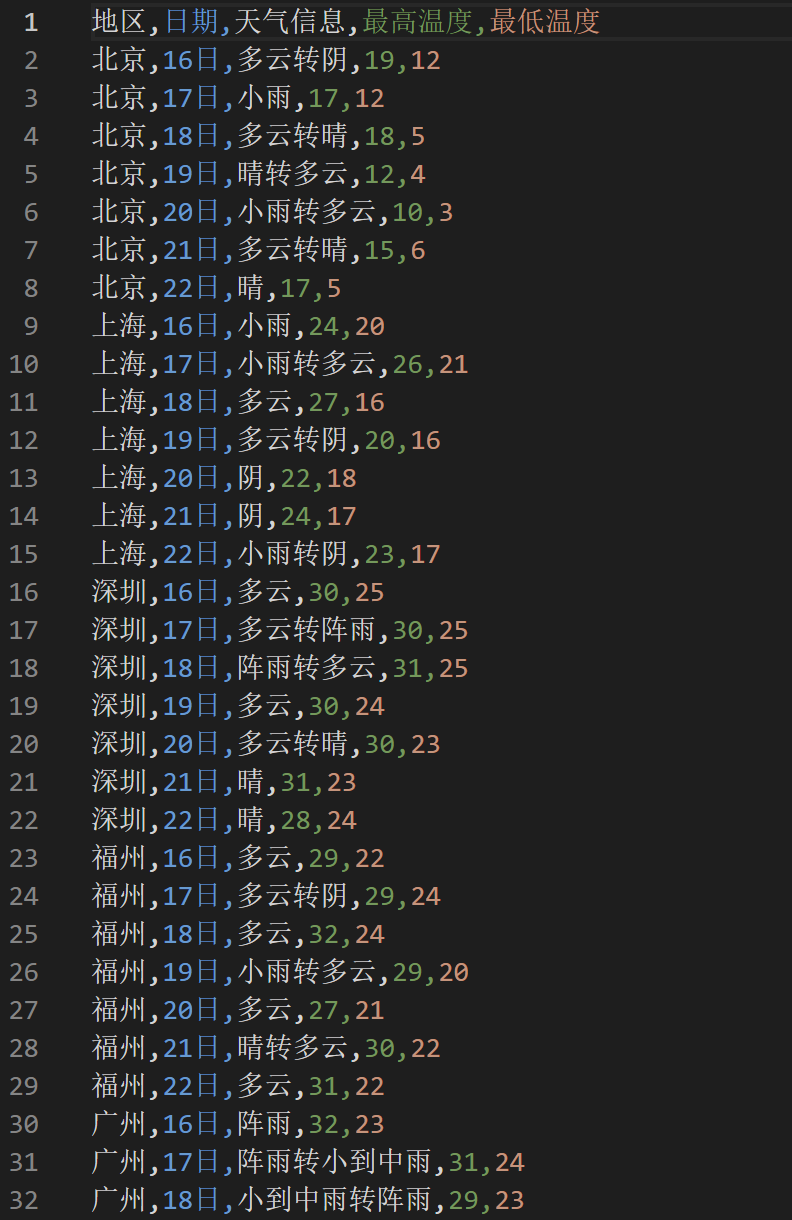
2)心得体会:
在实验中,通过运用 BeautifulSoup 库对 HTML 文档进行解析,我能够高效地提取所需的气象数据。这一过程强调了如何定位特定标签和类名,从而实现数据提取的精确性。在数据抓取过程中,数据的解析至关重要。在处理温度信息时,需考虑不同格式的可能性(如高低温用斜杠分隔),并进行相应的处理。这一过程凸显了数据科学中数据预处理的重要性。
作业②
用 requests 和 BeautifulSoup 库方法定向爬取东方财富网(http://quote.eastmoney.com/center/gridlist.html#hk_sh_stocks) 的股票相关信息,并存储在数据库中。
– 技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数
1)实验过程:
-
1.1抓包界面:
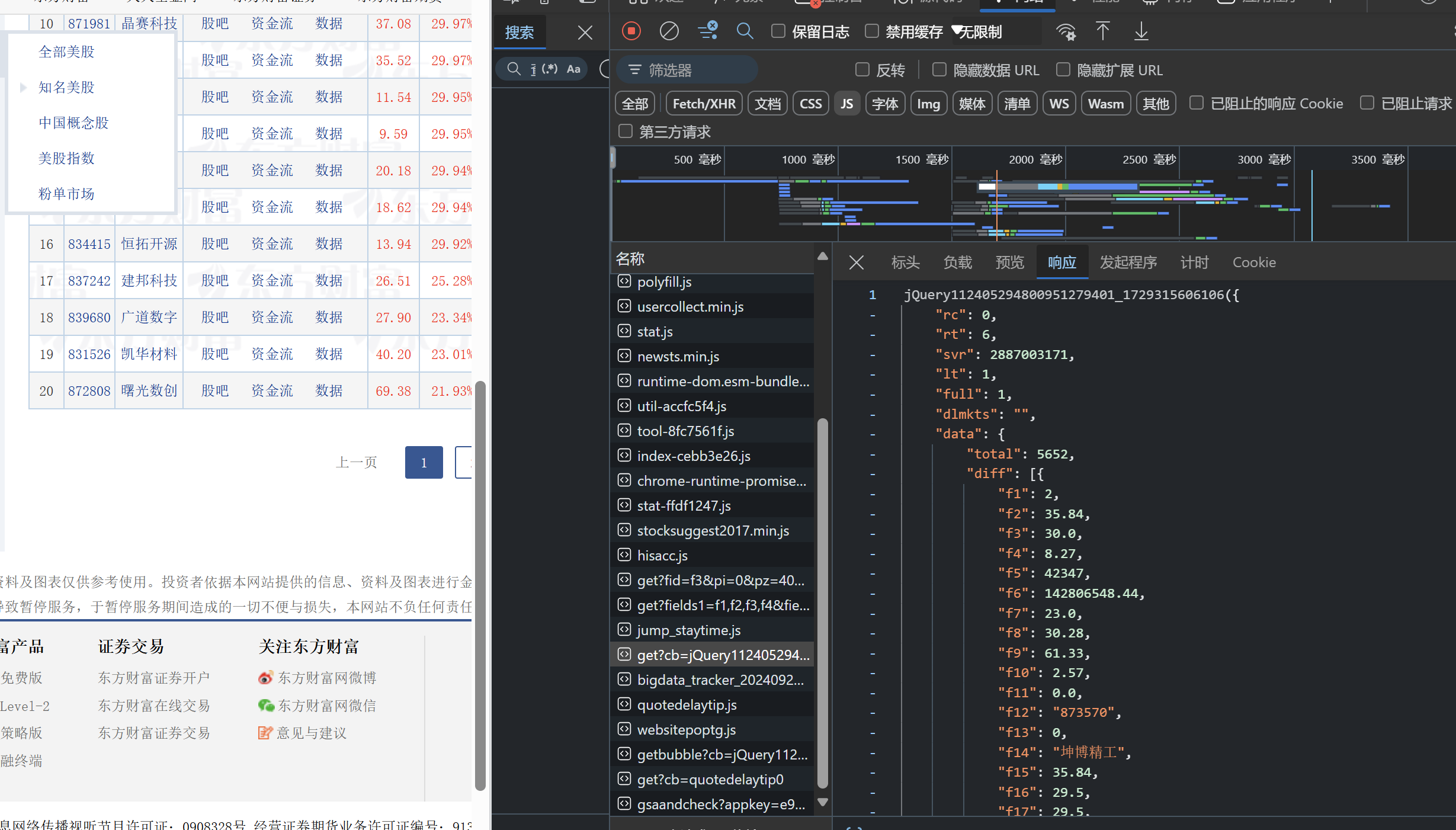
-
1.2 核心代码:
writer.writerow(['序号', '代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量', '成交额', '涨幅'])
# 移除回调函数包裹的部分,解析为 JSON
data_str = response.text.split("(", 1)[1].split(")", 1)[0]
data = json.loads(data_str)
# 获取当前页的股票信息列表
stocks = data['data']['diff']
for i, stock in enumerate(stocks):
code = stock['f12'] # 代码
name = stock['f14'] # 名称
price = stock['f2'] # 最新价
change_percent = stock['f3'] # 涨跌幅
change_amount = stock['f4'] # 涨跌额
volume = stock['f5'] # 成交量
turnover = stock['f6'] # 成交额
amplitude = stock['f7'] # 涨幅
-
1.3 输出结果:
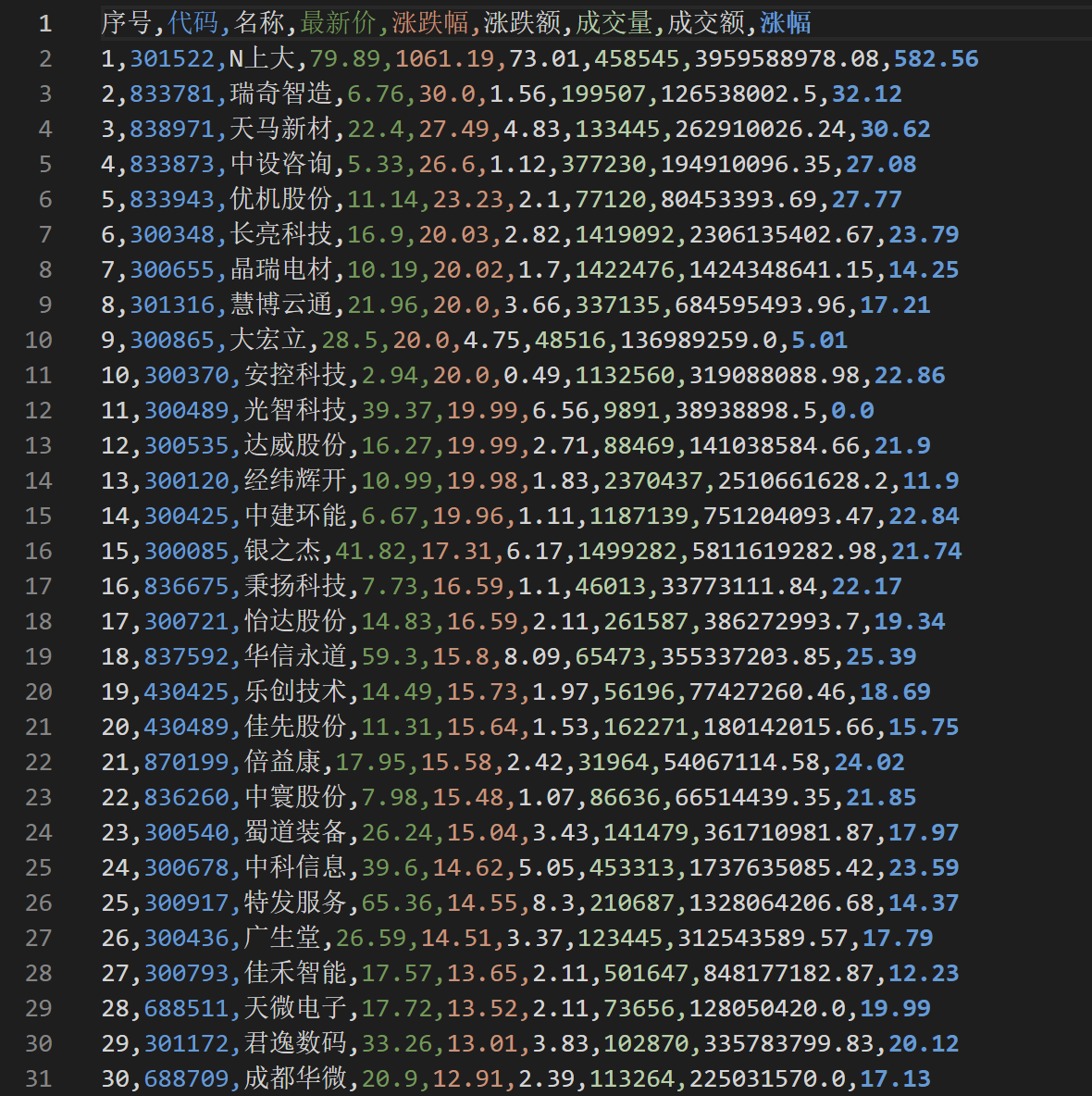
2)心得体会:
- API抓包的必要性
在当今数据驱动的时代,通过对API进行抓包,可以高效、系统地获取所需数据,而无需通过传统的网页解析方式。抓取东财网的股票信息时,API提供了标准化的数据格式,使得后续的数据处理和分析变得更加简便和高效。 - 数据采集的复杂性
在本实验中,东财网的数据返回形式并非直接的 JSON 格式,而是通过 JavaScript 回调函数进行封装。这要求我必须通过字符串处理的方式提取出有效的数据部分,才能进行后续的分析。
作业③:
要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
– 技巧:分析该网站的发包情况,分析获取数据的 api
– 输出信息:
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
1)实验过程:
-
1.1 F12调试分析:
payload.js的头尾字母对应关系:


-
1.2 核心代码:
获取payload数据
第一步:获取 payload.js 文件内容
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
response = requests.get(url)
payload_js = response.text
解析字母映射:
json_data_match = re.search(r'__NUXT_JSONP__\("/rankings/bcur/2021",(.+?)\);', payload_js)
if json_data_match:
json_data_str = json_data_match.group(1)
data = json.loads(json_data_str) # 解析 JSON 数据
else:
raise Exception("未找到有效的 JSON 数据")
# 第三步:解析字母对应关系(假设映射关系)
letter_mapping = {
'a': "",
'b': False,
'c': None,
'd': 0,
'e': "理工",
'f': "综合",
'g': True,
'h': "师范",
'i': "双一流",
'j': "211",
'k': "江苏",
'l': "985",
'm': "农业",
'n': "山东",
# ... 其他映射
}
-
输出结果:
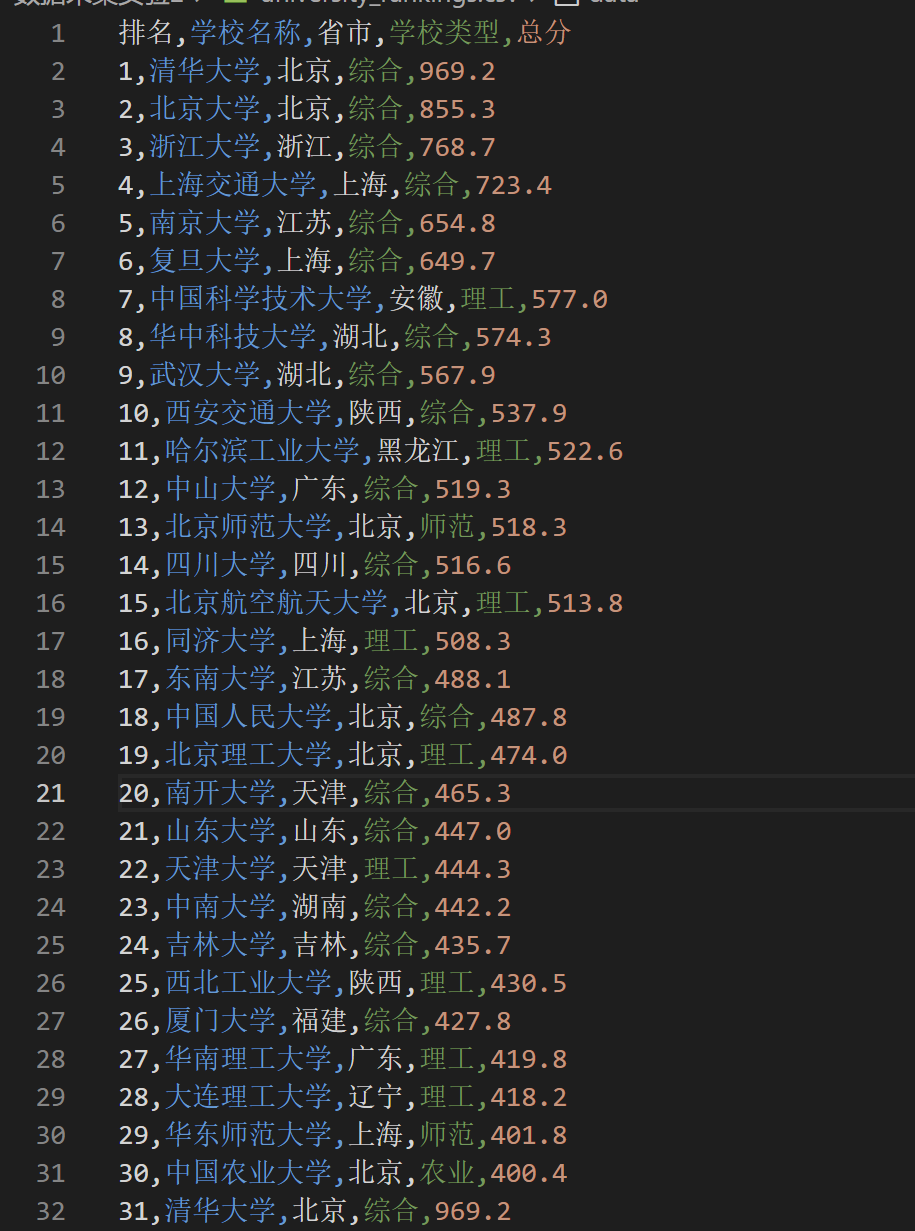
2)心得体会:
在这次实验中,我抓取了2021年大学排名数据这不仅让我提升了技术能力,还让我对数据处理和分析有了更深的理解。通过使用 Python 的 requests 和 BeautifulSoup 库,我体验到了数据爬虫的强大与灵活。爬取数据的过程让我认识到,现代数据科学的核心在于能够快速获取并处理海量信息。
该api返回的数据以 JavaScript 对象的形式呈现,而非传统的 JSON 格式。数据是一次性加载且 URL 是固定的,这为大规模的数据爬取提供了便利。主要字段包括大学名称、省市、大学类型、总分等。为了有效提取这些字段,我们需要使用正则表达式,并在解析时对字段映射和数值异常进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号