

数据采集与融合技术作业1
| 学号姓名 | 102202111 刘哲睿 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13286 |
| 这个作业的目标 | 用requests和BeautifulSoup库方法定向爬取各网页内容 |
| 实验一仓库地址 | https://gitee.com/qweasdzxc123-456/crawl_project/tree/master/数据采集实验1 |
作业1
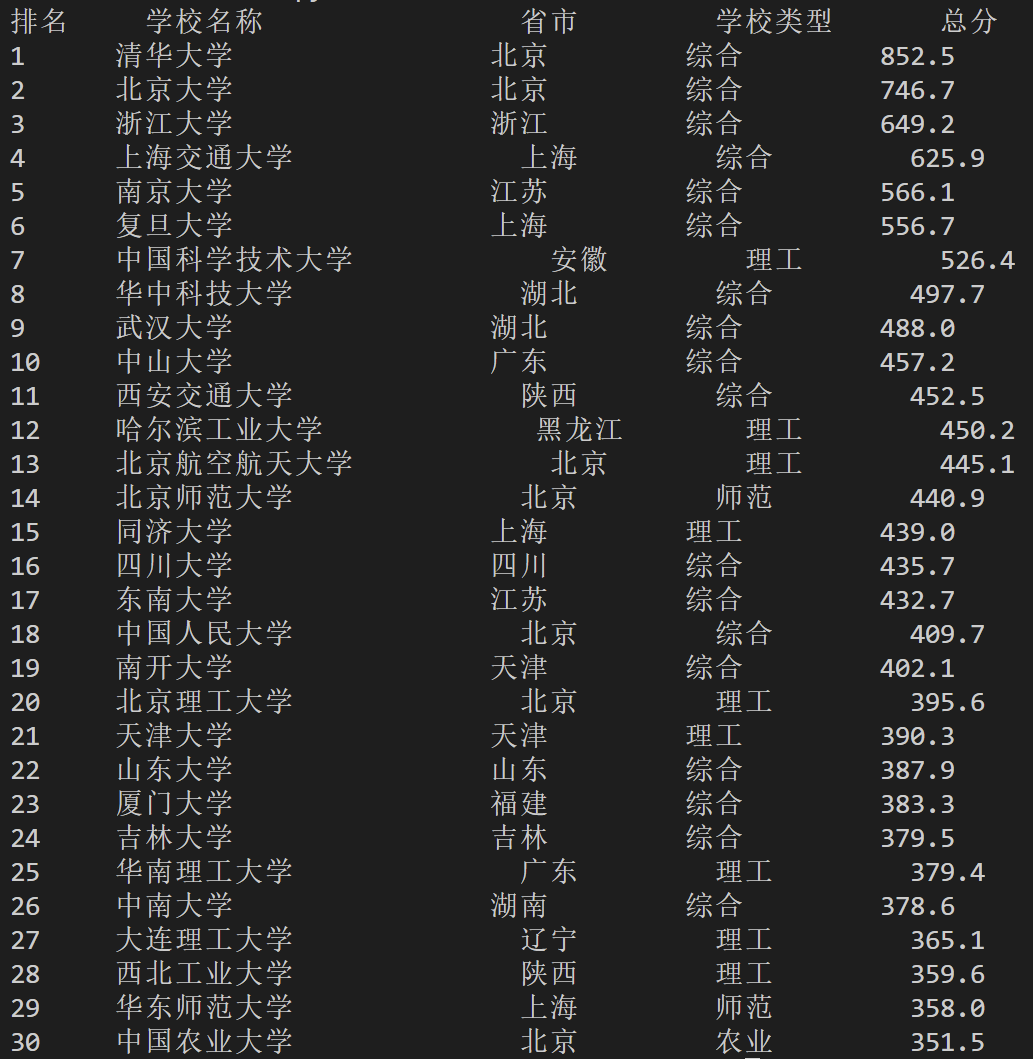
1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
代码:
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 查找包含排名信息的表格
ranking_table = soup.find('table', {'class': 'rk-table'})
# 定义一个正则表达式来匹配中文字符(去掉英文名)
chinese_pattern = re.compile(r"[\u4e00-\u9fff]+")
# 遍历表格行,提取排名信息
if ranking_table:
rows = ranking_table.find_all('tr')
# 输出表头
print(f"{'排名':<6} {'学校名称':<20} {'省市':<10} {'学校类型':<10} {'总分':<6}")
# 遍历每一行,提取信息
for row in rows[1:]: # 跳过表头
cols = row.find_all('td')
if len(cols) >= 5: # 确保有足够的列数据
rank = cols[0].text.strip()
# 只提取中文学校名称,使用正则表达式去除英文部分
raw_name = cols[1].text.strip()
name = ''.join(chinese_pattern.findall(raw_name)) # 只保留中文部分
name = name.replace('双一流', '') # 去除"双一流"信息
# 去除双一流/985/211信息
raw_location = cols[2].text.strip()
location = raw_location.split('/')[0].strip() # 提取省市,去掉后面的内容
school_type = cols[3].text.strip()
score = cols[4].text.strip()
输出结果:
2)心得体会
这个任务之前在老师布置的作业里已经完成过了
作业2
1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码:
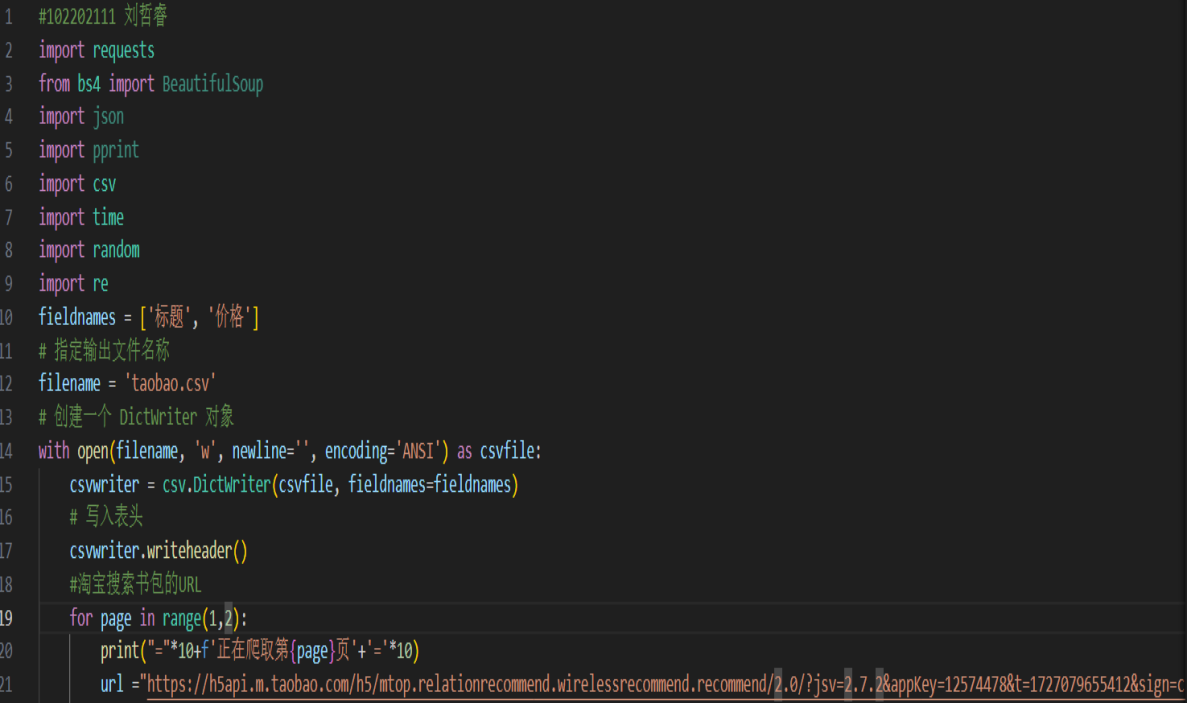
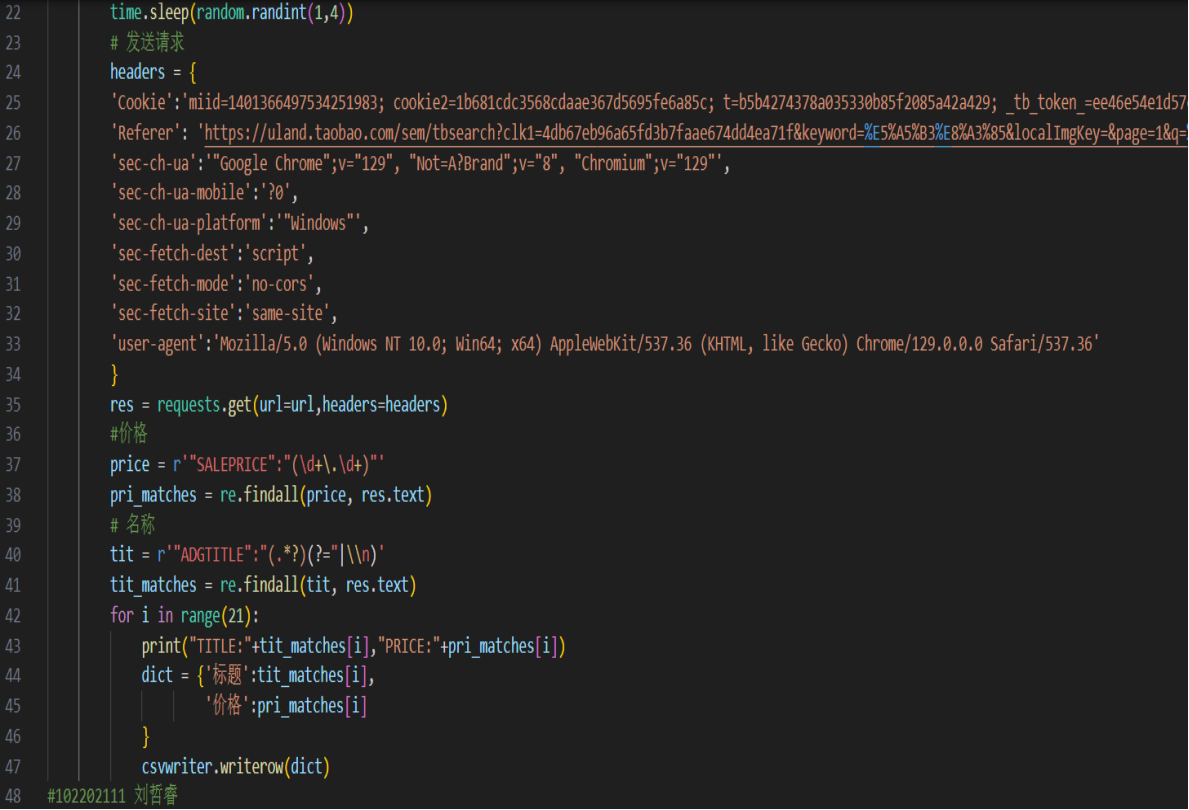
输出结果:

2)心得体会
这个任务之前在老师布置的作业里也已经完成过了
作业3
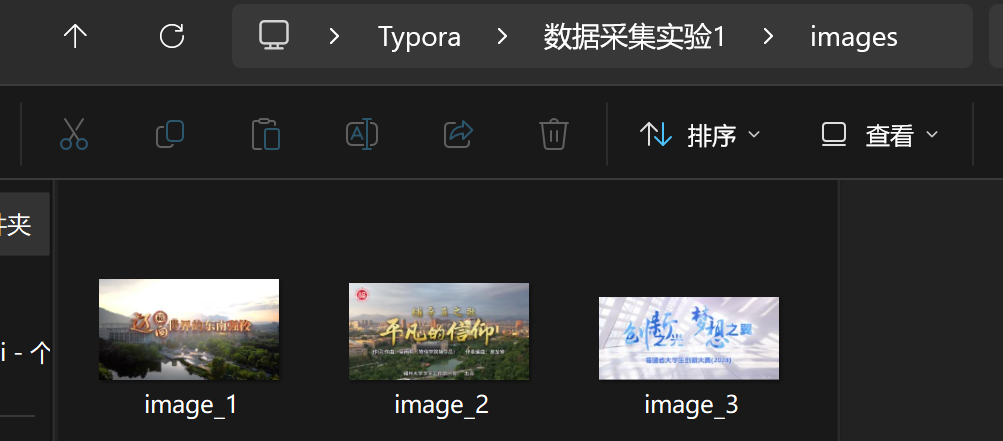
1)爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm) 的所有JPEG和JPG格式文件
代码:
# 禁用不安全请求警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 目标网页 URL
url = "http://news.fzu.edu.cn/yxfd.htm" # 尝试使用 http
# 保存图片的文件夹路径
save_folder = r'C:\Users\刘哲睿\Desktop\Typora\数据采集实验1\images'
# 如果文件夹不存在则创建
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 自定义请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
# 创建一个会话对象
session = requests.Session()
# 发送请求获取网页内容,禁用 SSL 证书验证
try:
response = session.get(url, headers=headers, verify=False)
response.encoding = 'utf-8' # 设置编码
html_content = response.text
except requests.exceptions.ConnectionError as e:
print(f"连接失败: {e}")
exit()
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 定义图片格式的正则表达式,匹配 .jpg 和 .jpeg 文件
img_pattern = re.compile(r'.*\.(jpg|jpeg)$', re.IGNORECASE)
# 查找所有图片链接
img_links = []
# 查找所有 <img> 标签
for img in soup.find_all('img'):
img_url = img.get('src') or img.get('data-src') # 获取图片链接
if img_url and img_pattern.search(img_url):
# 如果图片链接是相对路径,转换为绝对路径
if img_url.startswith('/'):
img_url = "http://news.fzu.edu.cn" + img_url # 修改为 http
img_links.append(img_url)<details>
输出结果:

2)心得体会
我们需要查看网页的HTML源码,定位图片的位置。通过分析标签属性,如 class 和 id,可以较为准确地编写正则表达式进行匹配。使用BeautifulSoup的img_pattern = re.compile(r'.*.(jpg|jpeg)$', re.IGNORECASE)可高效筛选出以.jpg和jpeg结尾的图片链接,基于标签属性和条件筛选能准确定位目标图片元素,提高爬取准确性和效率。

