为企业定制的数据提取解决方案——百万份 PDF,90%的正确率
自 ChatGPT 问世以来,开发人员利用 RAG 技术连接相关知识库来增强大型语言模型 (LLM),无需为每个特定任务重新训练模型。这种结合LLM推理能力和外部知识的方法显著提升了生成结果的准确性。因此,为了训练高质量的AI模型,相关知识库不仅需要大量数据,还必须确保数据质量。在这背景下,数据资源提供商的角色至关重要。
然而,由于PDF格式的非结构化特性,其数据不能直接用于AI训练。因此,数据资源商需要耗费大量人力资源来手动提取和处理这些非结构化数据,这不仅耗时长,而且错误率高。
为了解决这一问题,一家数据资源商向ComPDFKit寻求高效且可靠的解决方案,希望利用其数据提取功能将PDF文档结构化。我们根据他们的需求和检测标准,利用AI和各种算法为他们定制了模型,在5天内处理了超过300万份PDF文档,为他们提供了高质量的结构化数据。这不仅减轻了他们的人工处理负担,还显著提高了其客户AI模型训练的效率和效果,同时帮助他们及其客户扩大了业务范围。
客户需求
这家数据资源商在中国的数据市场上拥有最多的正版高质量数据。随着AI的飞速发展,越来越多的客户向他们购买数据进行AI训练。然而,他们的客户反馈,处理后的PDF数据质量不高,导致训练出的AI模型效果欠佳。他们了解到ComPDFKit提供快速、准确、高质量的PDF数据提取服务,希望我们能帮助他们从超过300万份PDF文档中提取数据。
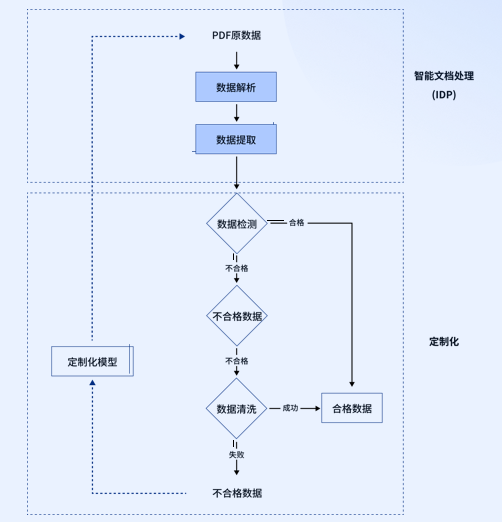
根据行业标准,ComPDFKit的数据提取功能可以保证每份文档80%的准确率,能够准确识别文本、表格、图片、页眉页脚等,基本满足大部分企业的数据检测标准。然而,由于AI模型训练的特殊性,一份文档中20%的脏数据可能会影响AI模型的准确性。因此,这家数据资源商提出了特定需求,例如:对PDF中有分栏或不规则布局的部分需要分块识别并有序记录;对每页都存在的内容,如页眉页脚、页码、页面边缘标题等需要删除。
ComPDFKit的研发团队根据他们的数据检测标准定制了数据提取参数,确保300万份文档中80%的数据100%符合标准。
技术挑战
基础的OCR功能能够准确提取PDF文档中的纯文本。然而,不同格式、排版、字体的文本,以及图片、图表、表格等内容的识别,是提高数据提取准确率的关键和难点。因此,面对该数据资源商提供的多类型、多行业的海量复杂PDF文档,ComPDFKit面临着技术上的重大挑战。
表格的挑战
在PDF文档中,表格的识别和数据提取同样是一个巨大的挑战。许多行业的报告和文献中包含复杂的表格,这些表格可能具有多层嵌套、合并单元格、不同的字体和边框样式等特征。这些复杂的表格结构使得满足准确提取表格中的数据并以合理的格式记录的需求变得尤为困难。
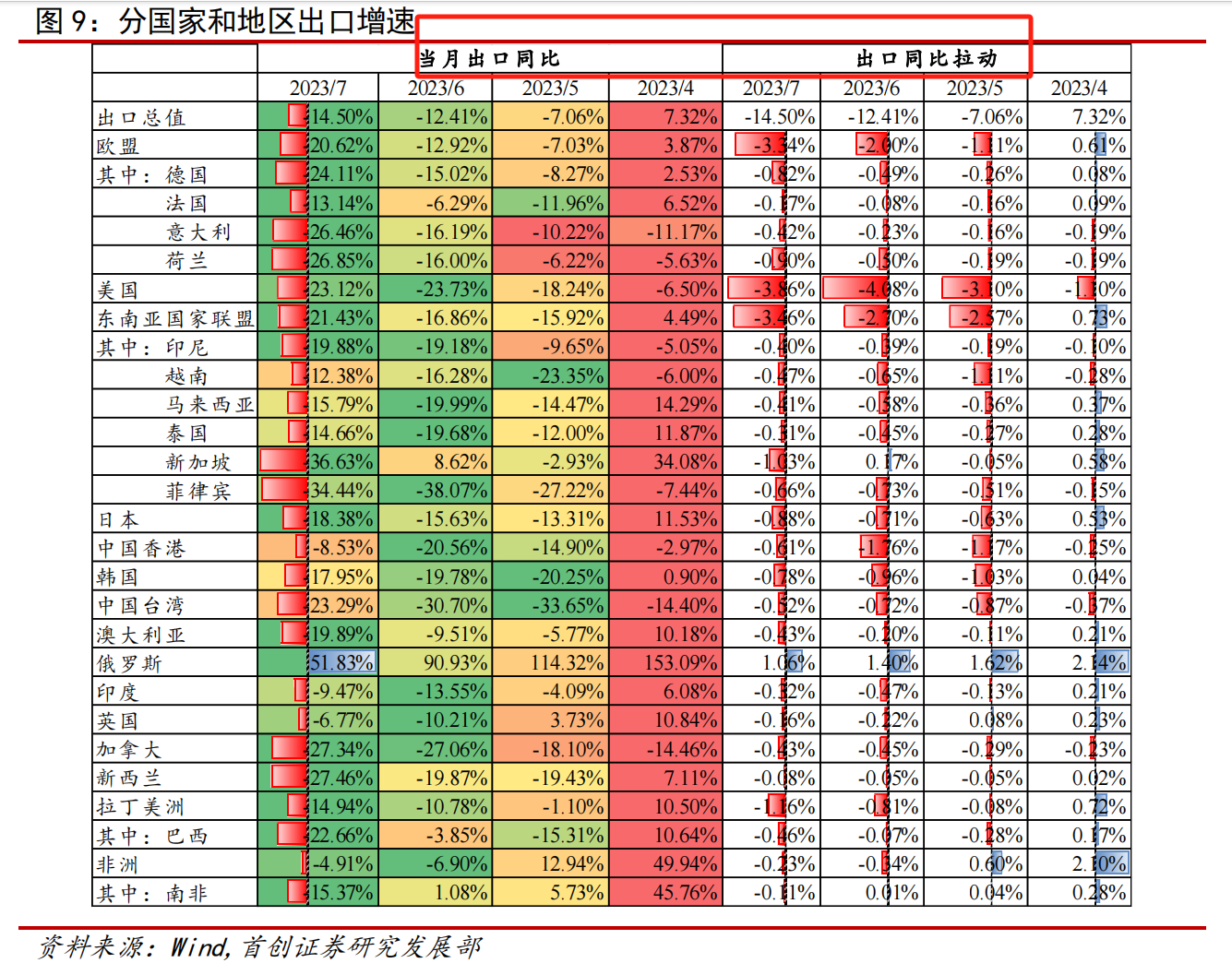
针对这样一个图表,一般的表格识别效果如下图所示,提取的数据不够精准且打乱了逻辑关系。如果使用这些数据让AI进行分析,可能导致结果不准确。
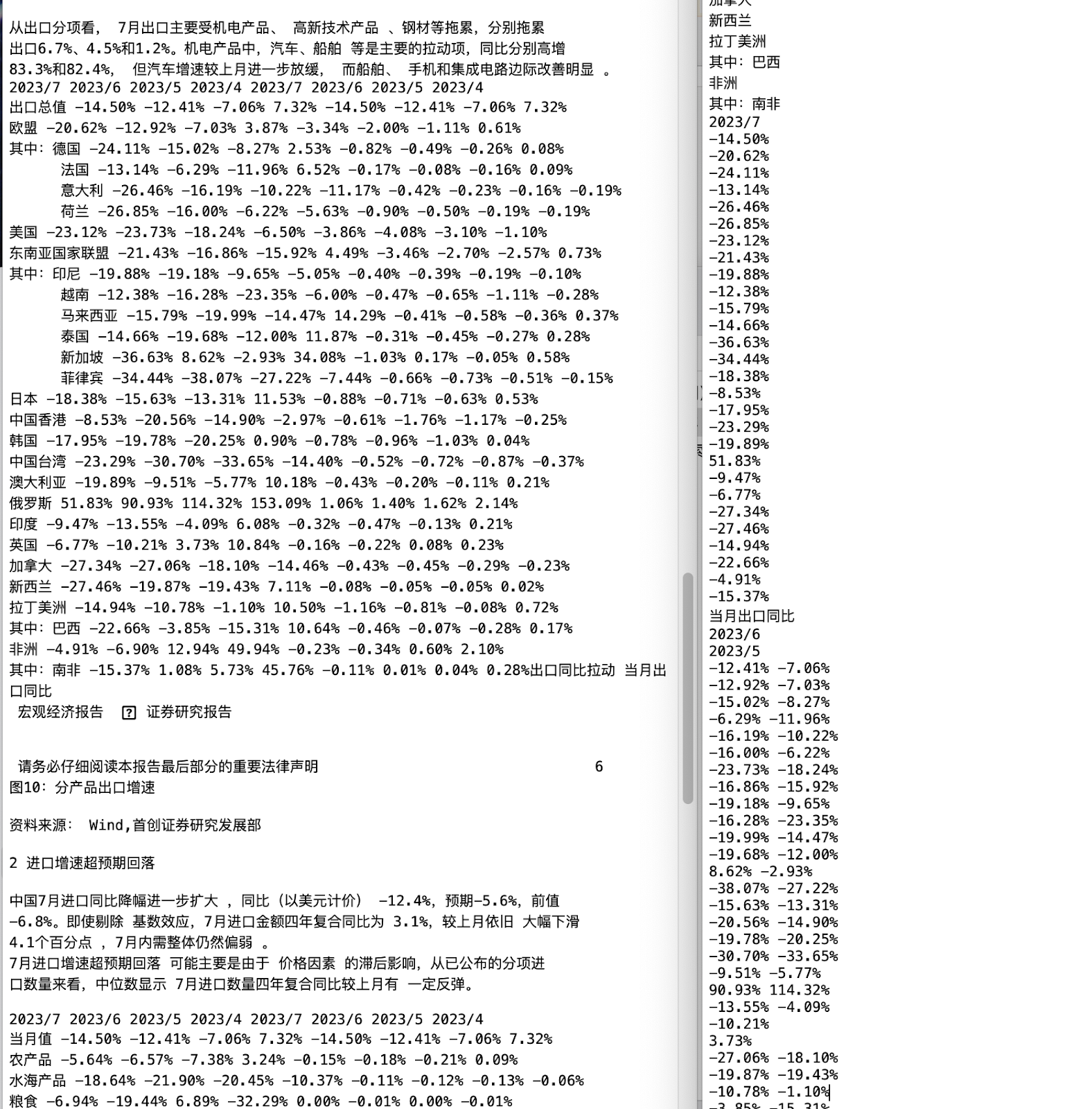
图表和图片的挑战
大部分行业的研究报告、项目报告、商业计划书、论文等文档中都包含各种图片和图表,例如折线图、柱状图、饼状图等。这些图表的图例、标签、横纵坐标数值标注、标题和底注等“脏数据”往往会影响AI模型的训练效果。
模块区分的挑战
PDF文档通常包含文本、图表和图片等多种内容,这种多样性导致了文档布局的不规则性。例如,文本可能与图表紧密相连,或者图片和表格交叉排列,这些情况使得准确地分块处理成为一个重大挑战。传统的算法往往无法有效应对这种复杂的布局结构,导致版面内容错乱。
如下图所示,传统的算法识别的第一行文本一般是 “核心观点 经济研究·宏观周报”。这是由于传统OCR算法仅按行从左至右识别内容,未通过版面分析对数据进行模块区分,提取的数据缺乏连贯性和逻辑性,这可能导致AI进行进一步分析时得出不准确的结果。
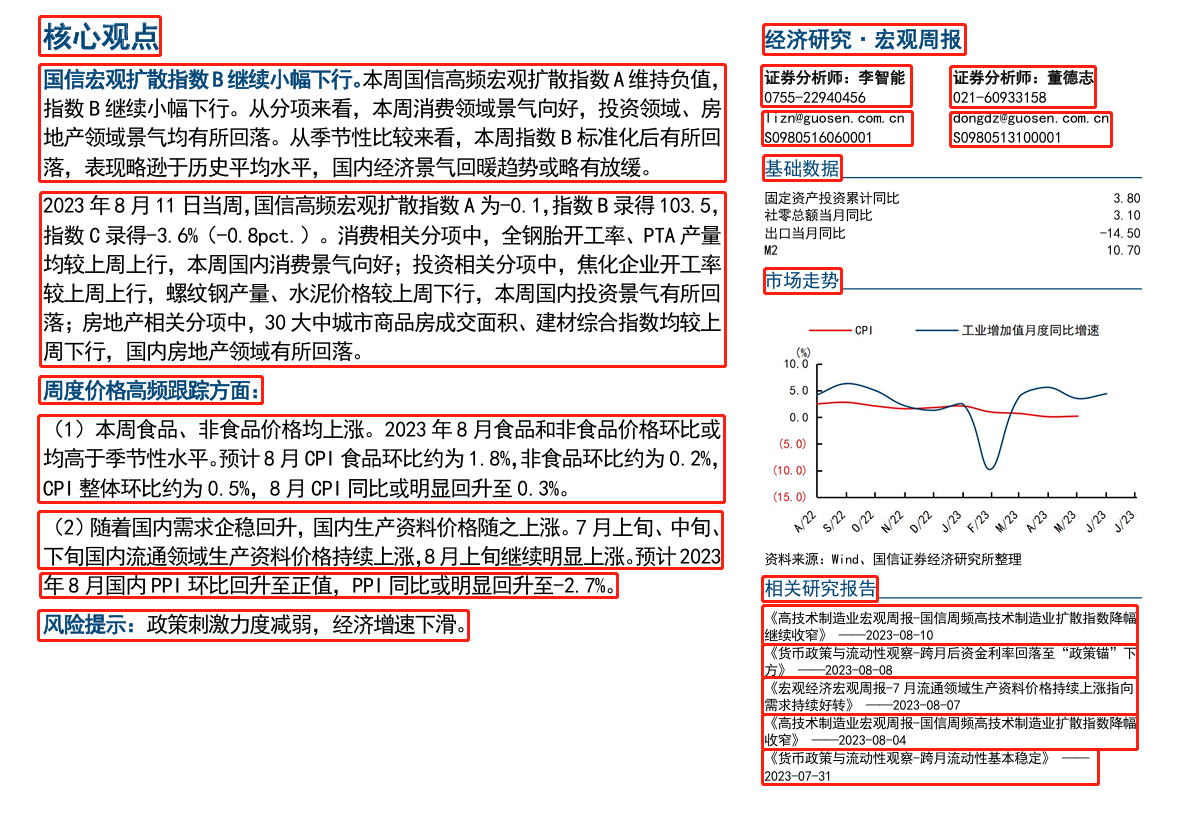
段落处理的挑战
段落处理与模块区分紧密相关。准确分析识别PDF文档的版面后,尽管文档结构可以与原文档保持一致,但每个模块的文本仍然按行提取,每行被视为一个独立的段落。这种提取方式限制了AI理解内容的能力,因为它无法直接捕捉到段落之间的逻辑关系和语义连贯性。因此,有效的段落处理需要超越简单的文本提取,应包括段落边界的准确识别和段落级别的语义分析,以便更准确地理解和利用文档中的信息。


注:左图为传统算法识别,每一行都有换行符;右图为ComPDFKit研发的模型,按段落提取,每段仅有一个换行符
解决方案
为解决PDF文档数据提取中的复杂性和准确性挑战,ComPDFKit专门优化了对图片、图表、表格、版面和段落的处理。我们的研发团队按照该数据资源商的需求为其定制了 AI 模型,用于高效解析和提取PDF文档数据。在此基础上,我们根据客户反馈的具体需求定制数据检测的参数,清洗不符合标准的数据,确保数据质量达到高标准。经过持续优化,我们成功在5天内处理了超过300万份PDF文档,数据合格率高达88%,完全符合客户标准,并帮助客户训练了更加精准的AI模型。
未来合作展望
ComPDFKit处理了高质量数据,提供了专业及时的技术支持,吸引该数据资源商与我们开展进一步合作。他们计划采购ComPDFKit PDF SDK,自主提取PDF文档的数据。未来,他们希望整合ComIDP智能文档处理解决方案,处理不仅限于PDF文档的其他非结构化数据,拓展业务范围,为客户提供更多且更高质量的数据。
如果您也面临海量数据处理的挑战,如果您希望节省人力成本、提高数据质量并增强工作效率,请访问我们的智能文档解决方案页面,了解ComIDP在AI训练和企业系统集成方面的应用。我们将竭诚为您提供解决方案,助您充分利用数据资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号