
Data Mining notes
1.1 整装待发
data mining前提:00~07年数据存储能力大幅提升。
data无处不在
data rich,information poor。
1.2 学而不思则惘
learning resources
data mining书籍推荐。
国际会议:
看国际会议以了解行业最新动态。
一些顶级期刊:
行业大牛:
搜索工具:
- google(scholar)
- weka
- UCI:machine learning repository
- matlab
- KDnuggets
data mining是一个多学科综合起来的领域,data mining是一个很宽泛的概念,big data和data analytics等归根结底都是data mining。
如何学好:
- 思考讨论
- 阅读材料
- 练习应用
学会思考。
1.3 知行合一
什么是data,data is not information
data types:
- binary
- symbolic
storage:
- physical
- logical
major issues:
- transformation
- errors and corruption
什么是big data,3个v:high-volume、high-velocity、high-variety。
说明了目前进行 data mining 的难点和要点在哪里。
big data 的现实应用:
- 降低犯罪率
- 药量的定制化(画饼,: P)
- urban planning
- location data(记录顾客在商场中的游览顺序,在货架的停留事件等)
- retail data(进行精准广告投送)
- sentiment analysis
- social network
- sports:利用数据分析,分析球员潜力,以最少资金获取最具潜力的球员。(真实案例)
- attractiveness mining(哈哈,以非诚勿扰作为案例分析哪些女人好看)
小结:简单介绍 data 的概念种类以及应用。
1.4 从数据到知识
open data
where ot find data?
画质太低了:各种领域的data
open government data
data mining
- definition:data mining 是一个从繁杂海量且不完整的数据中提取出有趣且有用的隐式模式(patterns)。
- synonym:knowledge discovery
business intelligence
data mining 在 business intelligence的各种应用,类似球员潜力分析。
from data to intelligence
ETL:一种数据分析软件。
介绍了一些商业 data mining 软件。
1.5 分类问题(Classification)
准备讲一些算法。
cross validation
注意 Training set与Test set不能使用同一个set。
介绍了训练模型的基本流程。
Confusion Matrix
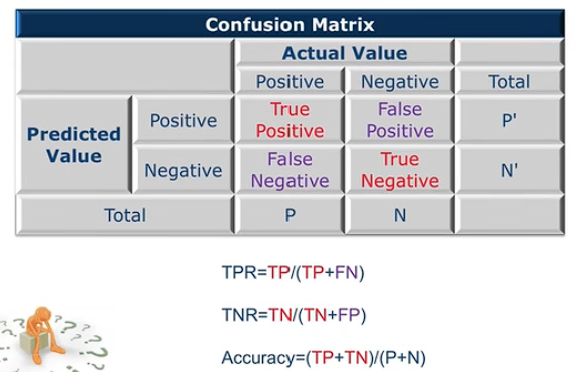
Receiver Opetating Characteristic
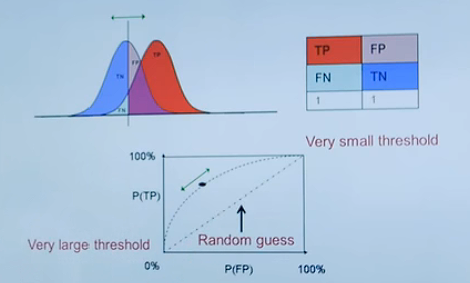
ROC 曲线
Receiver operating characteristic (ROC) analysis is a graphical approach for analyzing the performance of a classifier.
AUC stands for "Area under the ROC Curve."
cost sensitive learning
提及Confusion Matrix在现实生活中 TP,RF等的权重问题。
lift analysis
经过分析使得成本降低。
1.6 聚类问题及其他数据挖掘问题(Clustering)
Hierarchical Cluster
分层聚类
Association Rule
关联规则
买了a,b就很容易去买c
Regression
回归
Performance Dashboard
一些有趣的可视化软件,善于利用可视化软件。
Data Preprocessing
data preprocessing是data mining中最有挑战性的部分。
1.7 隐私保护与并行计算
Privacy Portection
举了一个例子,在不获取用户隐私的情况下获取到我想要得到的数据。
人群中吸大麻比例调查问题。
Cloud Computing
pay as you go:现付现用
definition:cloud computing is the on-demand delivery of IT resources over the Internet with pay-as-you-go pricing。
Parallel Computing
Mobile Supercomputing
The Big Picture
data + model + computer --> data mining (for golden)
No Free Luch
各种算法和模型各有优势和短板,学习多种算法和模型按照实际问题的具体情况选择最佳的算法。
1.8 迷雾重重
股票走向
彩票预测
Grouping
处理数据的时候需要注意数据的内在分组。
Violent Crime vs. Vedio Games
注意数据的相关性,x影响y,是否有直接的影响。
Tricky?
Survivorship Bias
幸存者偏差:)
小结: 从各种角度和层次来看问题。
2.1 数据清洗
Data Preprocessing:数据预处理
真实的 data mining 绝大部分时间花费在 data preprocessing。
Missing Data
Data are not always available
Possible Reasons
- Equipment malfunction
- Data not provied
- Not Applicable(N/A)(不适用)
Different Types
- Completely random
- Conditionally random
- Not missing
how to handle missing data?
- 忽视
- 人工填写
- 自动填写
Outliers
离群点
Anomaly vs. Outliers
异常 vs. 离群
小结:列举数据缺失的各种可能性,缺失的原因以及若干种如何因对确实的方法;介绍了利群点的概念并说明了离群点与异常点本质是不同的。
2.2 异常值与重复数据监测
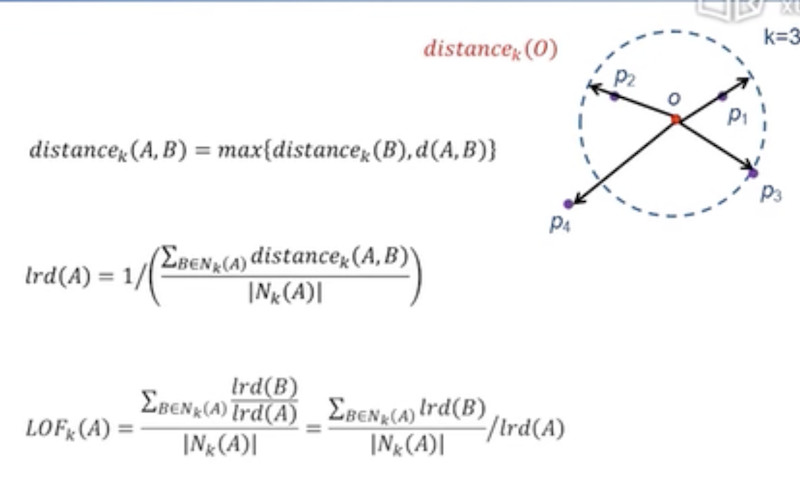
Local Outlier Factor
计算距离公式:
Duplicata Data
slide window,前提:可能重复的数据在数据库中是靠近的。
步骤:
编写规则合并两个相似的项时需要注意其属性对应的文化背景。比如中国人同姓的人多,欧美人同名的人多。
小结:介绍了异常值如何得出的基本思想以及一个计算公式;合并重复数据的基本思想。
2.3 类型转换与采样
Data Transportation:类型转换。
说明:经过上一节的步骤,now we have an error free dataset.
Attribute Types:
- Continuous(连续的)
- Discrete(离散的)
- Ordinal(序数的): Rankings:
- Nominal(名义上的): {Red, Green, Blue},
- String
Type Conversion(类型转变)
以Nominal类型的颜色编码问题为引子,简单介绍了编码背后隐藏的问题:不同的编码表示在空间上的距离是不同的。
解决办法:假设有三种颜色,使用的编码为:001,010,100。此时三种编码在空间距离上是一致的。
Sampling(采样)
为什么采取采样?
-
CPU运算很快,但是IO相比于CPU运算太慢。
-
统计学采用采样是因为,采样成本过于昂贵。而在Data Mining中是因为,数据量过大,无法全部处理所以采用采样。
Aggregation(聚集)
适当的放大范围
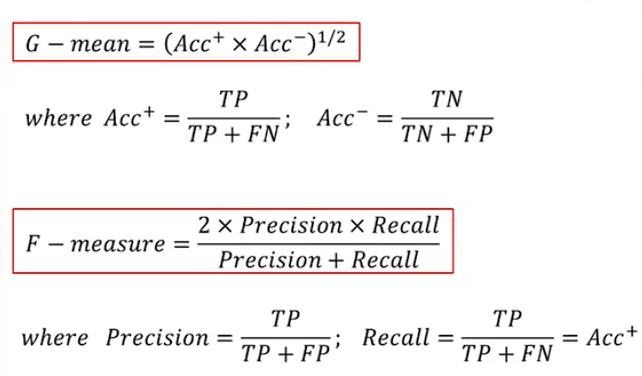
Imbalanced Datasets
数据集很多情况下数据种类数量是极度不平衡的。使用 G-mean 该衡量指标可以剔除“来了都说好”这类的模型算法。
Over-Sampling(向上采样)
在 Imbalance Datasets 中通过一些算法将较少数量的元素进行“复制”增多,以达到更好的模型训练效果。
Boundary Sampling(边界采样)
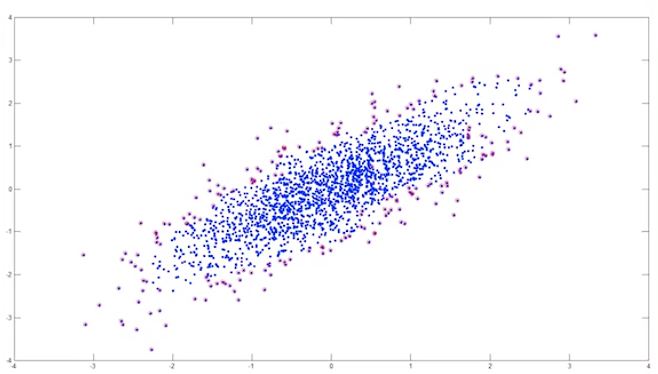
当数据量十分庞大时,采取Boundary Sampling 便可使用少量的点来描述整个数据集。节省资源。
2.4 数据描述与可视化
Normalization
-
Min-max normalization:将有明确区间的数据使用公式1映射到(0.0, 1.0) 区间
\[公式1:v'=\frac{v-min}{max-min}(new\_max-new\_min)+new\_min \] -
Z-score normalization (\(\mu\): mean, \(\sigma\), : standard deviation),偏离均值多少个标准差。
\[公式2:v'=\frac{v-\mu}{\sigma} \]
Data Description
- Mean
- Median
- Mode(The most frequently occuring value in a list for non-numerical data)
- Variance(方差):Degree of diversity,有两个公式。
如何计算两组数据的相关性,有两个公式...
数据可视化
- 1D,饼状图,柱状图之类的。
- 2D,使用matlab。
- 3D,在matlab里使用Surf函数来可视化。
Box Plots(High Dimensional)
matlab中的一个函数。缺点:丢失了维度与维度之间的关系。
Parallel Coordinates:平行坐标(High Dimensional)
每条线代表一个点在多维的属性。
两个可视化软件:
- CiteSpace:文字可视化的软件。
- Gephi:
2.5 特征选择
两个核心算法:
Feature Selection(该小结讲述)
Feature Extraction(2.6小节讲述)
Class Distributions:
举了两个例子:
- 属性分类的好坏。
- 区别明显属性可以提高判断的成功率。
Entropy(熵)
Information Gain(信息增效,在学习决策树时会使用到)当你获得一个属性时,不确定性下降的幅度即information gain。
Feature Subset Search
要从海量的 Features 中选择出最能使某元素确定的少量 Features,遍历所有组合一般不太现实。此时我们使用到 Branch and Bound(分支定界)
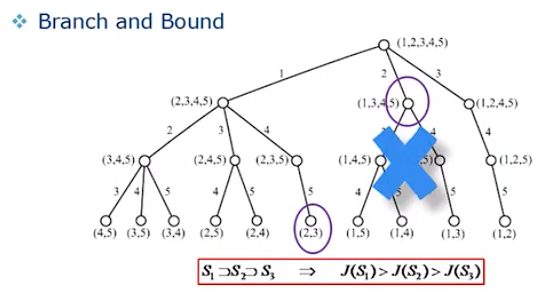
红字说明:使用BAD的前提,当属性单调减少时,其 J(暂定为能效) 也单调减少。
其他一些方法?:
- Top K Individual Features:找最好的 K 个属性组合在一起。
- Sequential Forward Selection:先找一个最好的属性F1,在F1的基础上加一个属性,遍历二属性组,找到最好的二属性组。以此递增。
- Sequential Backward Selection:同上,反之。
小结:这些方法难以找到最优解。
Optimization Algorithms:
- Simulated Annealing(模拟退火)
- Tabu Search(禁忌搜索)
- Genetic Algorithms(遗传算法)
2.6主成分分析(数学元素较多,较难)
FS和FE的不同点
多维数据压缩到低维会损失很多的信息,如何在压缩维度的同时尽可能的减少信息的损失。
2D Example
Variance:information。差异越大则该属性越重要。(因为该属性能更好的使元素区分开来。)
另一个例子:Remove correlation
Some Math
一些数学方法:
- 将二维数据进行变换的矩阵公式推导。
- 进行变换的过程中,新点与原点的距离最小则其信息损失最小。接下来便是距离最小公式的推导。最后通过 Lagrange Multipliers 解决(带约束条件的求最大值)
More Math

PCA:将原点数据投影到具有最大特征值的 S 的特征向量上。
PCA Examples
在matlab中实现PCA较为简单,给予了一个简单的例子,可以试着在matlab中实现。
Fish
2.7 线性判别分析
The Issue of PCA:
PCA is Unsupervisor,它不考虑class information。
Linear Discriminant Analysis(LDA)
The objective of LDA is to perform dimension reduction while preserving as much of the class discriminatory(类的区别) information as possible。
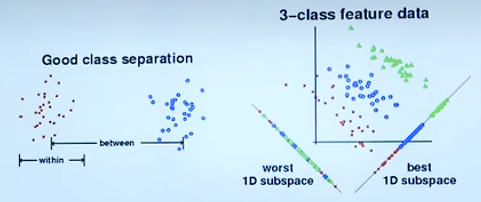
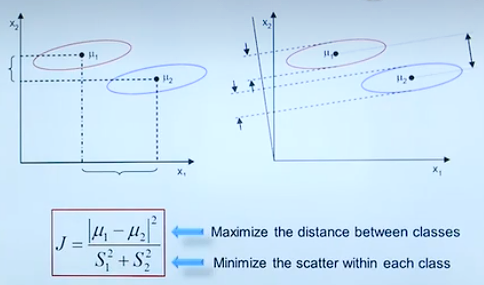
Measure of Separability
组内属性尽可能靠近,组外属性尽可能远离。
Fisher Criterion
Some Math...
两分类问题投影方向的公式推导。[b站视频](https://www.bilibili.com/video/BV154411Q7mG?p=17&spm_id_from=pageDriver&vd_source=2456bd97f87d1daadd52439e6aaac59a 7:06)
LDA Example
对同样的数据分别使用PCA和LDA算法给出详细计算过程得出投影方向。从数学角度阐述了 PCA 与 LDA 本质上的区别。(区别,是否保留不同 class 间的 variance)下为 PCA 与 LAD 投影方向图。
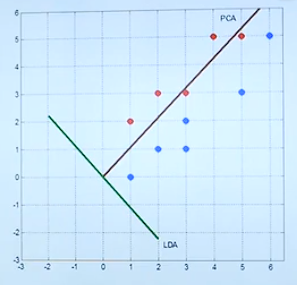
C-Class LDA
介绍了 C-Class 投影的计算公式...
给出了一段可以在matlab上执行的代码。[b站](https://www.bilibili.com/video/BV154411Q7mG?p=18&spm_id_from=pageDriver&vd_source=2456bd97f87d1daadd52439e6aaac59a 8:38)
Limitation of LDA
阅读推荐:

3.1 贝叶斯奇幻之旅
Classification
classification is a kind of supervisor learning.
there is <input, output> in classification.
what is supervisor means:
Classifiers
training a classifiers.
举了几个例子:教开车...
Bayes Theorem
公式: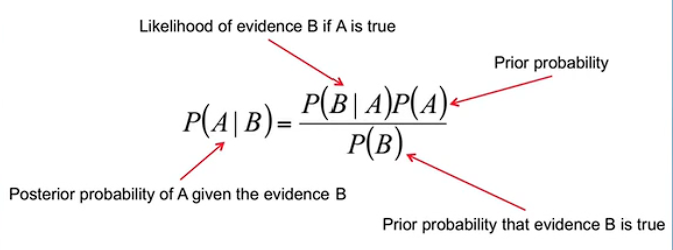
可视化 Bayes 公式:这里。让 Bayes 公式更新你的观点,而不是改变你的观点。
fish example
猜鱼...
Shooting Example
Cancel Example
Headache & Flu Example
有点意思:
3.2 朴素是一种美德
Naive Bayes
两个公式...
Independence
独立概率
Conditional Independence
条件概率
吸烟例子
格子例子
抛硬币例子...
Independent \(\ne\) Uncorrelation
Estimating \(P(a_j|\omega_i)\)
Laplace Smoothing...有个公式
Tennis Example
Text Classification Example
Text Representation
计算感兴趣单词的频率...
Case Study: Newsgroups
3.3 数据、规则与树
Decision Making
简单介绍...
A Survey Dataset
市场调研进行用户画像。
A Tree Model
使用决策树细化庞大的数据,最好是让叶子结点为“纯的”。(即x:0或0:y)
Some Notes...
强调了一下,性能相同选结构简单的树。
3.4 植树造林学问大
ID3
如何选择属性,即树的节点。
ID3,迭代?
Entropy
用数学方法来衡量这些属性。
使用 Entropy来衡量节点的重要性。
有个公式...
Attribute Selection
information gain 越高越好
ID3 Framework
基本思想在3.3节 a tree model已陈述过。
举个例子:
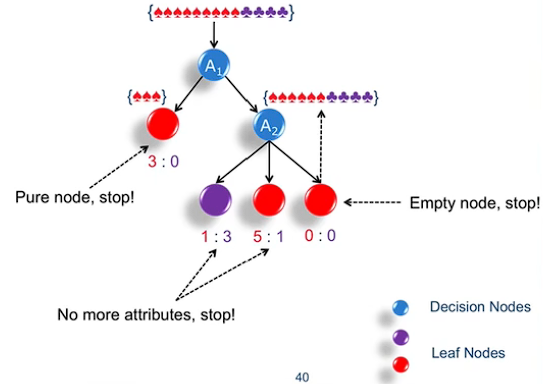
Overfitting
overfitting:A训练集性能比B的好,测试集相反。
如何解决overfitting:
- 限制决策树的长度。
- 剪枝
Pruning
剪枝是改善模型在ValidationSet的性能。通过Pruning不断的减少节点时,在模型 ValidationSet 误差曲线的拐点处停止Pruning。
Entropy Bias
有个公式...
Continuous Attributes
连续的属性例如温度,如何进行 threshold 的选定,通过计算 Gain,gain越大越适合当作 threshold。
Reading Materials
c4.5决策树?

4.1 智慧之源神经元
Overview
Biological Motivation
生物上的神经元...
大脑的力量来自于并行。(parallelism)
Case Study
神经网络如何学习?
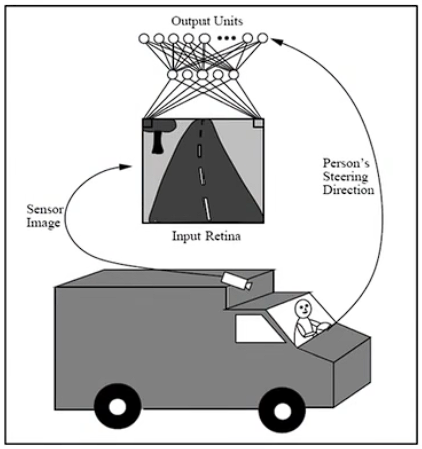
Perceptrons
Perceptrons:感知器,就是一个神经元。
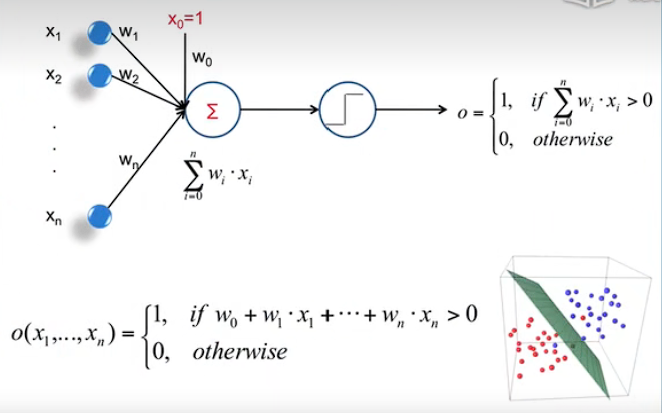
x:属性
w:权重
w_0:偏置?当
超平面这里不是很理解。
Power of Perceptrons
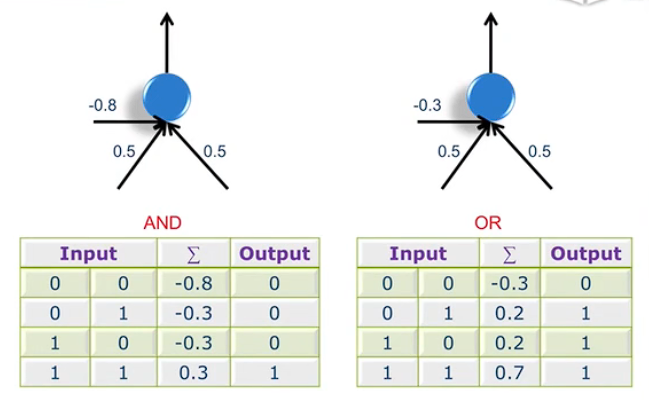
通过控制\(w_0\) 的数值来模拟与门和或门。上图中 \(w_0\) 为 -0.8 和 -0.3.
4.2 会学习的神经元
Error Surface
如何得到 \(w_0\) 权重?
如何修正权重?
Gradient Descent
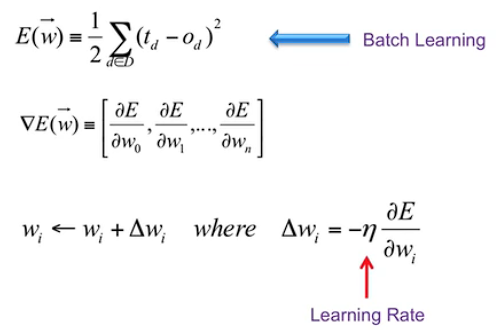
D:训练集
t:target,期望或者目标输出
o:实际的输出
E:误差
\(\eta\) 为学习率。
\(\Delta w_i = -\eta\frac {\partial E} {\partial w_i}\) 公式内误差对权重求偏导,为什么要加负号:
偏导为正时,权重增加,误差也增加,即此时偏导大于零,而我们希望的是误差越来越小。故\(\eta\) 前加个负号。
偏导为负时,权重增加,误差反而减小,即此时偏导小于零,而我们希望的是误差越来越小。故\(\eta\) 前加个负号。
Delta Rule
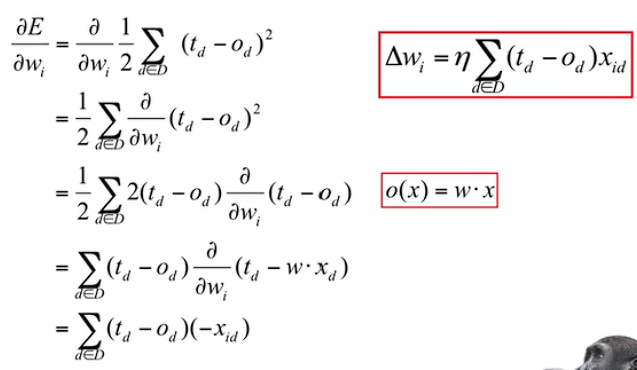
当\(t_d - o_d > 0\) ,即期望输出大于实际输出。此时需要实际输出更加靠近期望输出:
当 \(x_{id}>0,t_d>0,o_d>0\) 时,\(\Delta w_i\) 为正,故\(w\) 增大,此时\(o(x)=w·x\) 增大。
当 \(x_{id}<0,t_d>0,o_d>0\) 时,\(\Delta w_i\) 为负,故\(w\) 减小,此时\(o(x)=w·x\) 增大。(该条推断是矛盾的)
Batch Learning

小结:计算出一个属性的\(\eta (t-o)x_i\) , \(w_i\) 就更新一下。直到所有属性计算完后再更新\(w_i\).(这应该是单个神经元权重的计算)
Stochastic Learning
...
4.3 从一个到一群
Multilayer Perceptron
因为单个感知机无法完成线性不可分的分类问题,故使用多层感知机。
多层感知机结构: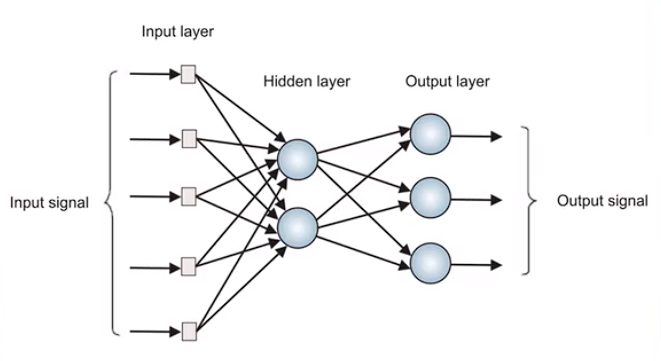
注意:Hidden layer 可以由多层组成,上结构图将其省略为一层。
XOR
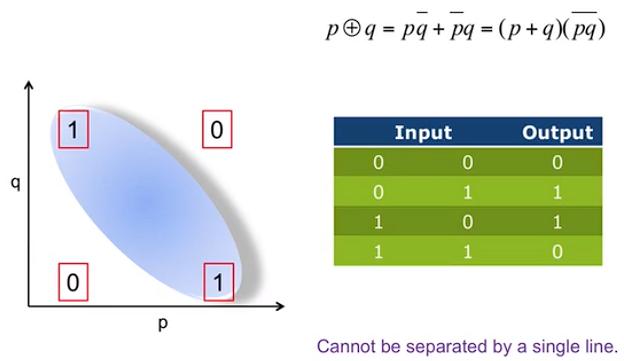
解决办法: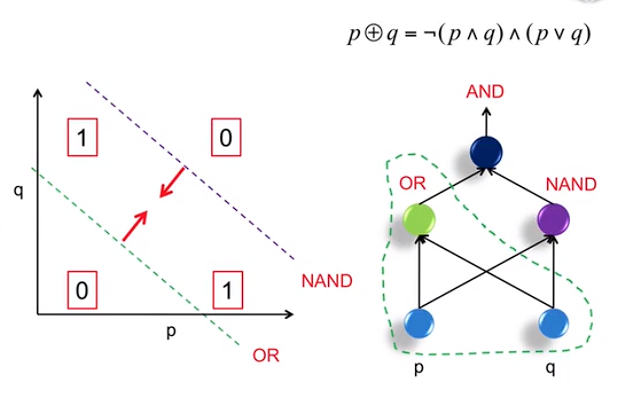
这不就是电路嘛...
Hidden Layer Representation
representation:表示
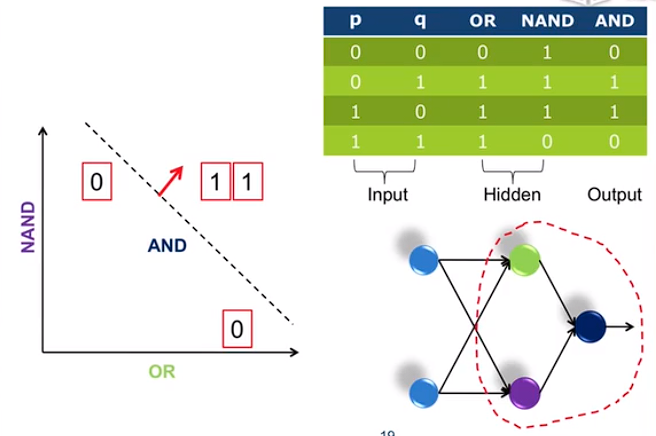
将图中红色圈抽象成一个“感知机”。
将原始复杂问题简化。
The Sigmoid Threshold Unit
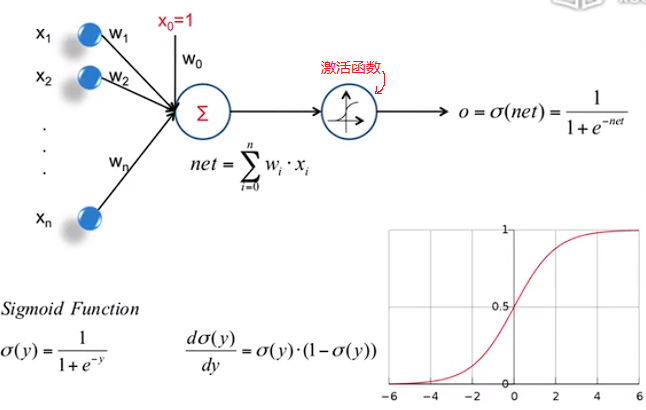
优点:
- 将输入输出漂亮的映射。
- 导数可以直接计算出来。
注意:导数可以直接计算出来,由此得出当输入为0时导数最大,故一般将权重设置的比较小。
4.4 层次分明,责任到人
Backpropagation Rule
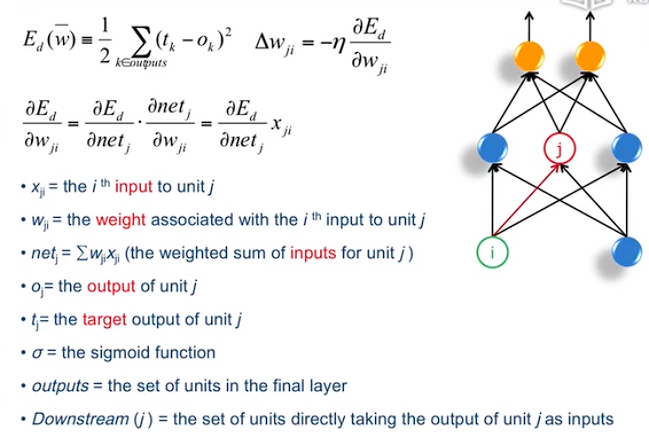
Traning Rule for Output units
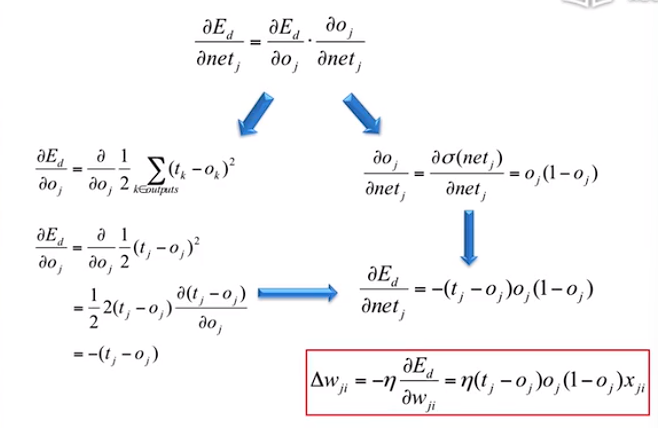
误差逆传播算法推导: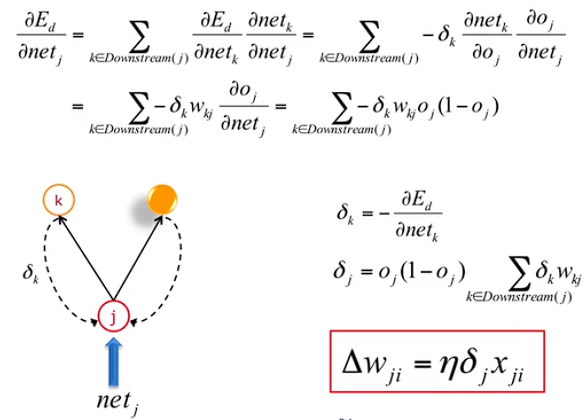
小结:算法其核心是通过输出k的误差,来反映隐藏层 j 的误差,以此来修正 j 的权重。
BP Framework

More about BP Networks...
Local Minima:局部最小值。
如何处理 Local Minima 问题。
...
Overfitting
Practical Considerations:实际考虑。
- Monmentum(冲量)
- Adaptive learning rate
4.5 管中窥豹,抛砖引玉
Beyond BP Networks
介绍了两个其他的神经网络
Elman Network
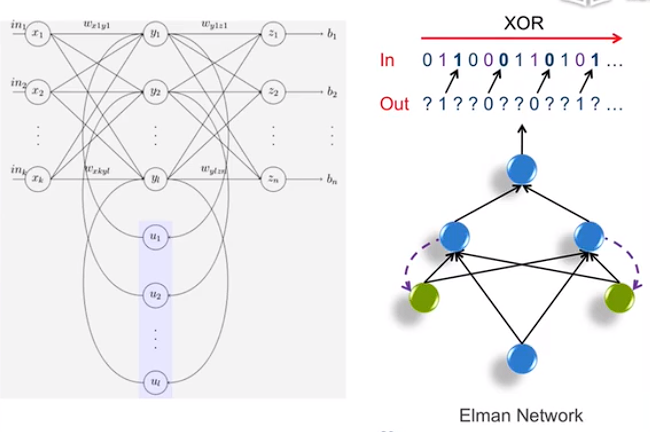
小结:具有一定的上下文记忆功能。上图的绿色结点实现类似记忆功能。
Hopefield Network
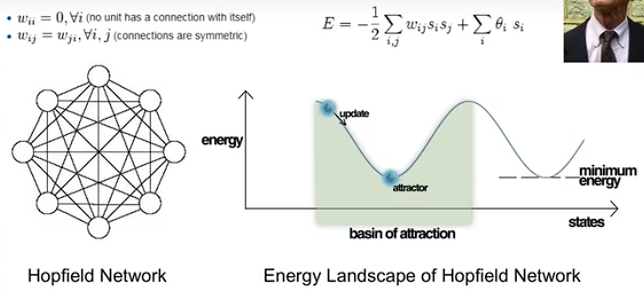
给予若干pattern,通过该网络记住某个pattern。
When does ANN work?
训练时间长,但好用。
不具有可解释性。
Reading Materials

5.1 最大间隔
低纬到高纬。
Distance to Hyperplane:
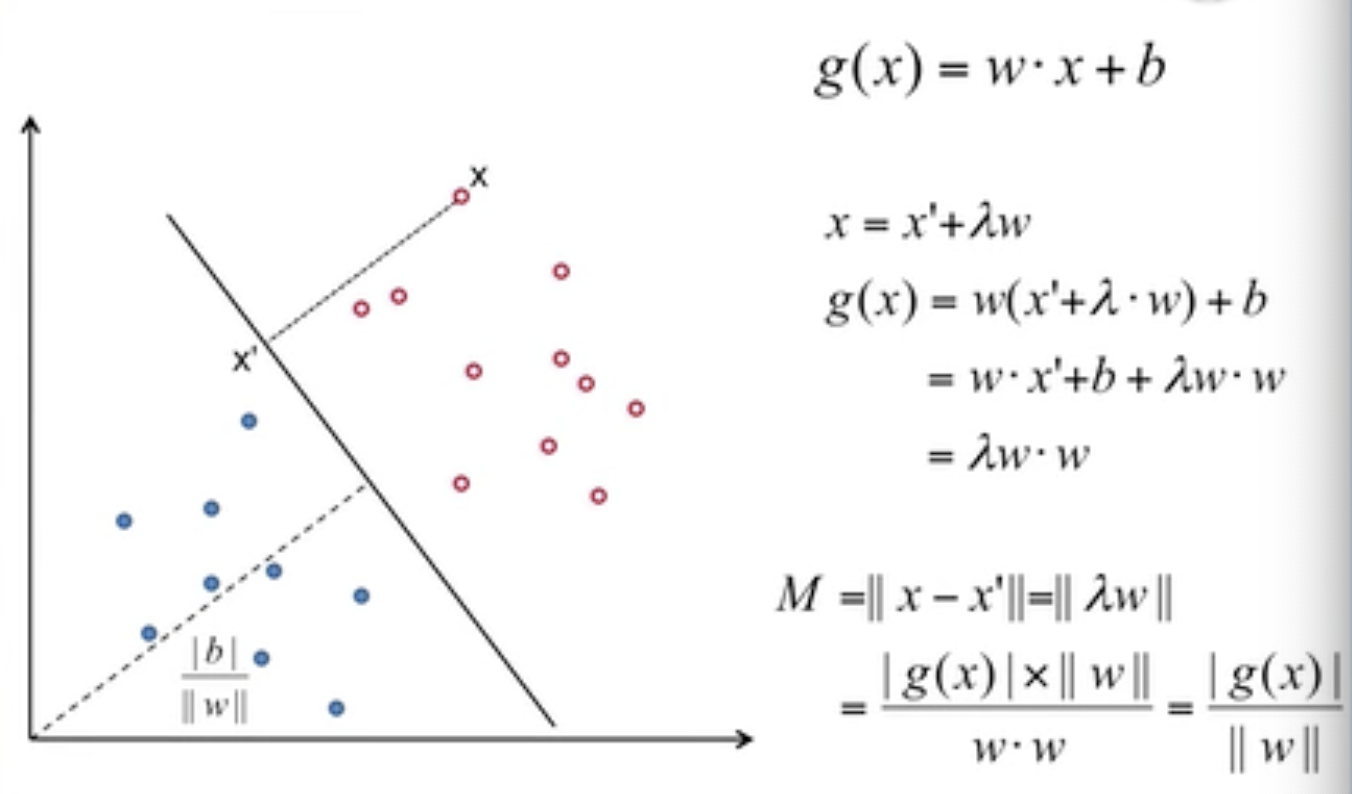
Selection of classifier
多个感知机生成的多个分类器,尽量选择将空白部分平分的分类器。
Margins
Margin 中文翻译为 间隔。
选择不同的分类器,其margin 和 support vectors会不同。
margin,support vectors示意图:
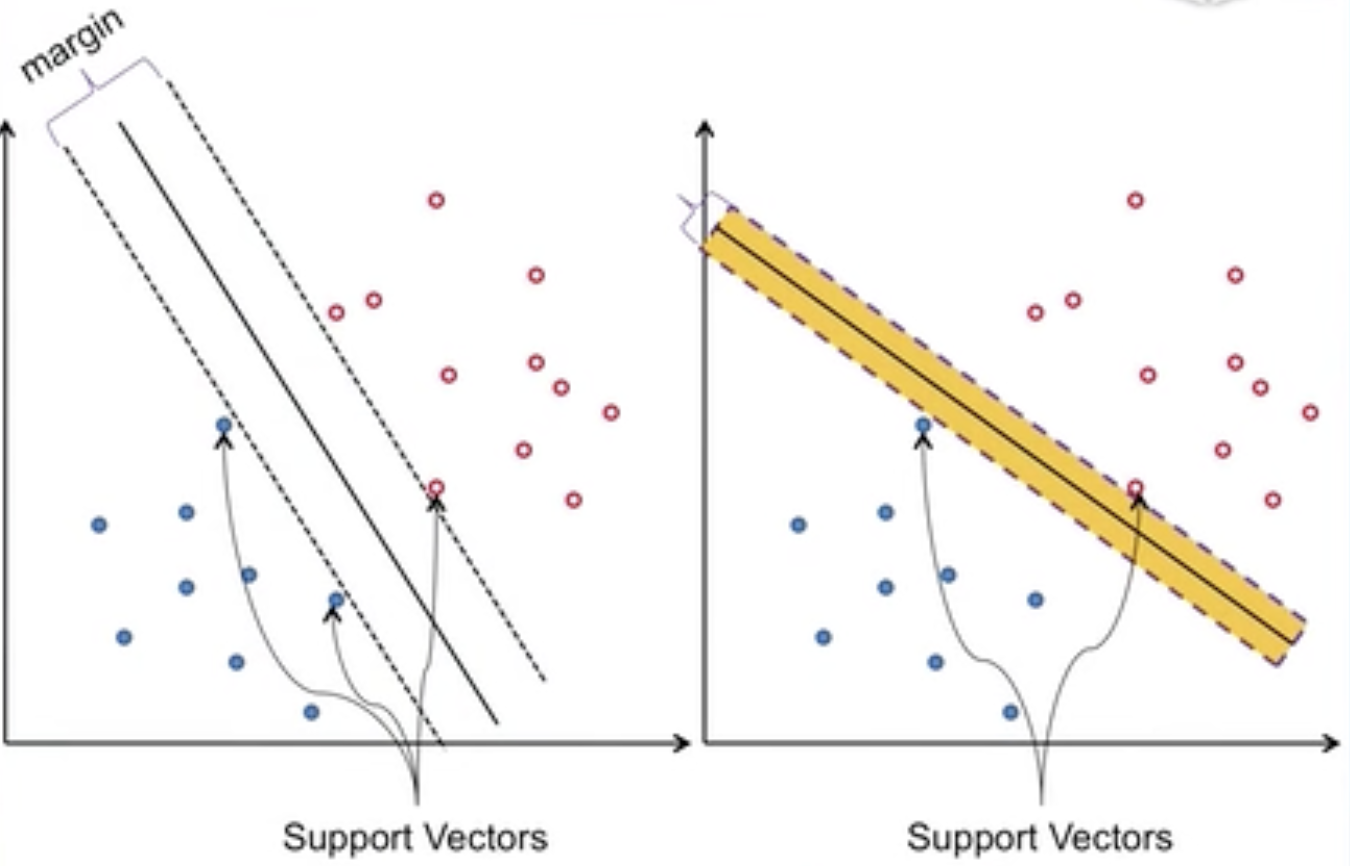
小结:
Liner Support Vector Machine(LSVM)线性支持向量机:仍然是一个线性分类器,与其他线性分类器相比它的margin是最大的。
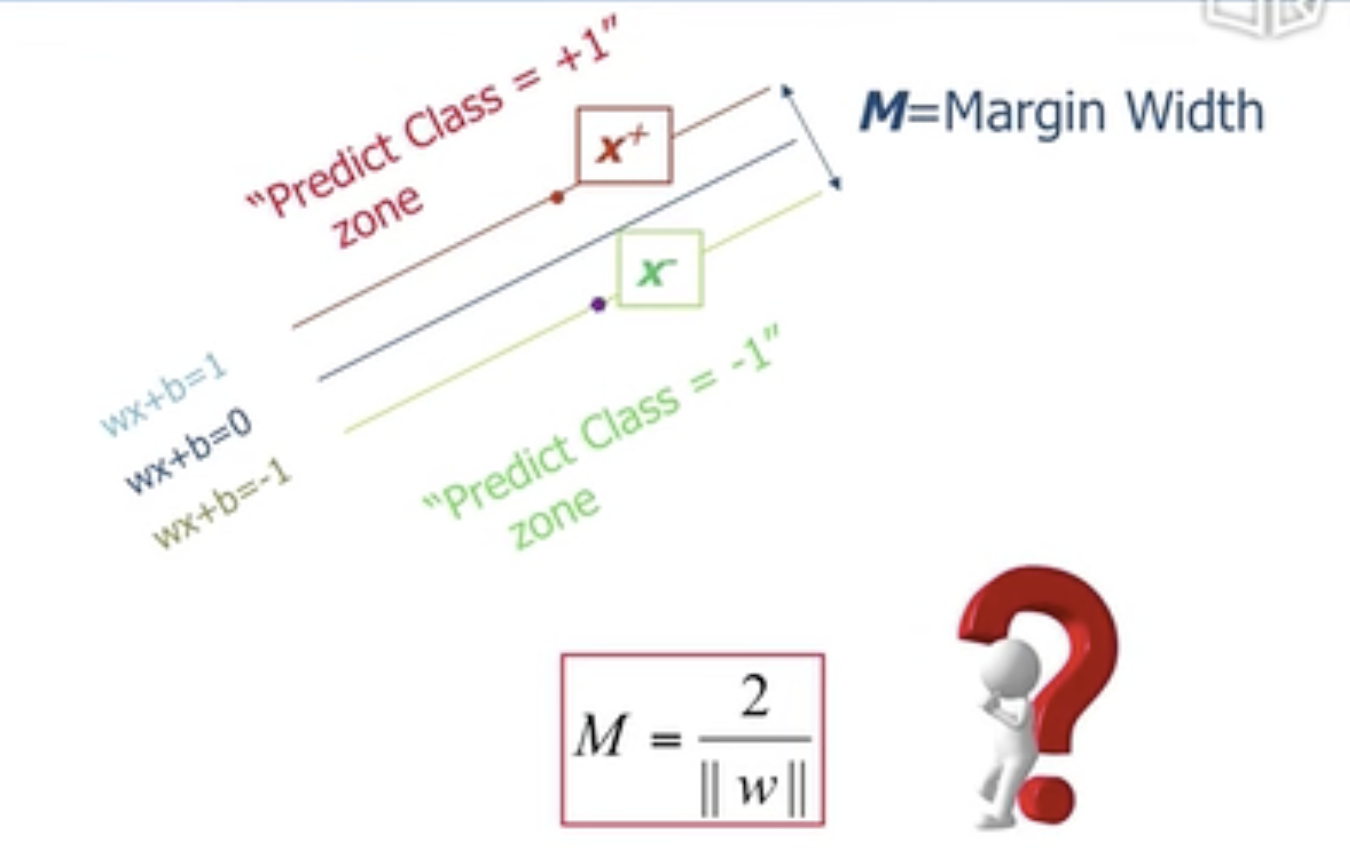
最大化公式Margin:\(M=\frac2{||w||}\)
5.2 线性SVM
Objective Function
Objective Function,目标函数
两个目标:
- 分对
- margin最大化
Lagrange Multipliers
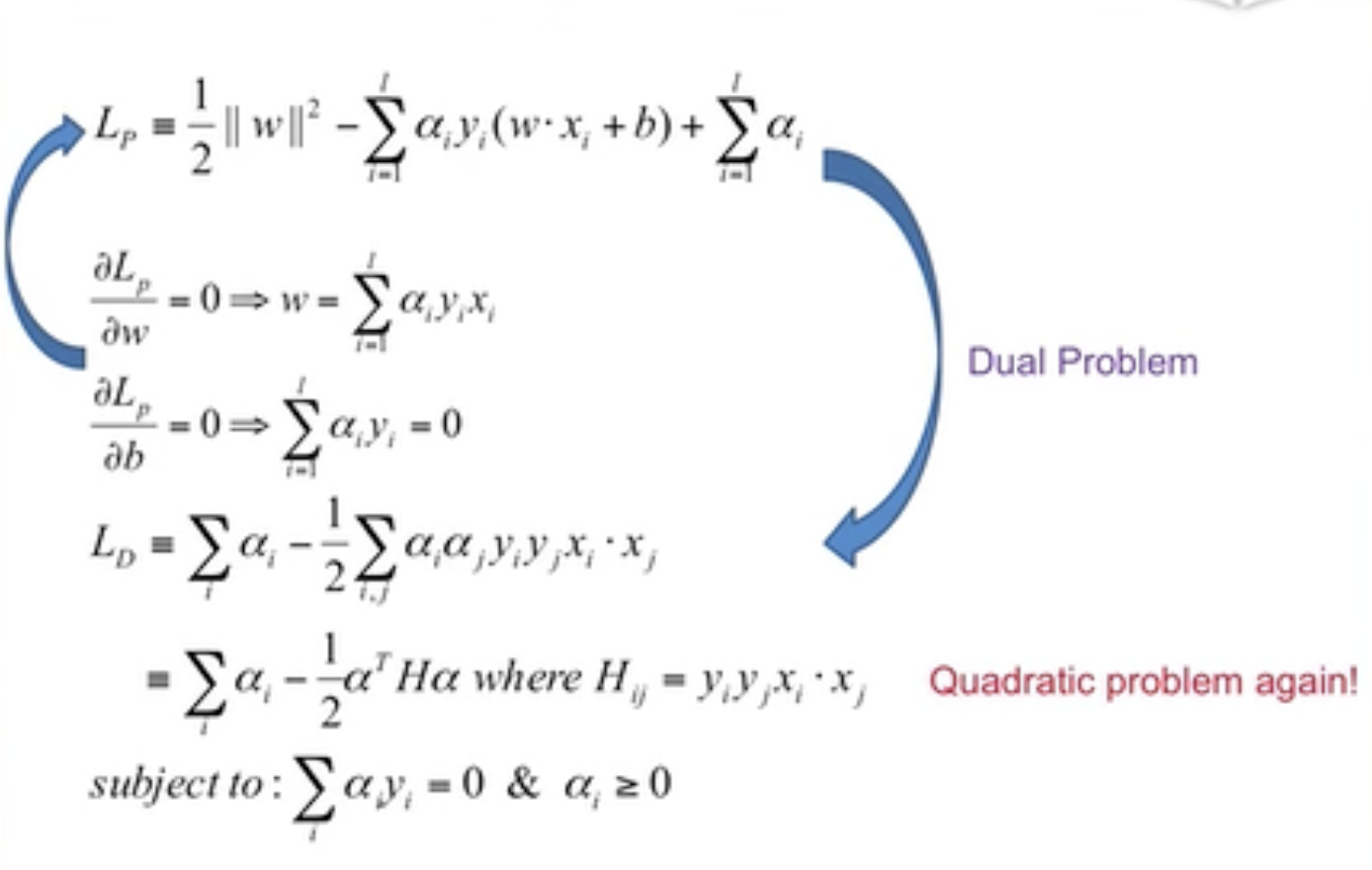
Solutions of w&b

Soft Margin
某些情况下分类器并不能完全的将所有的点分对。
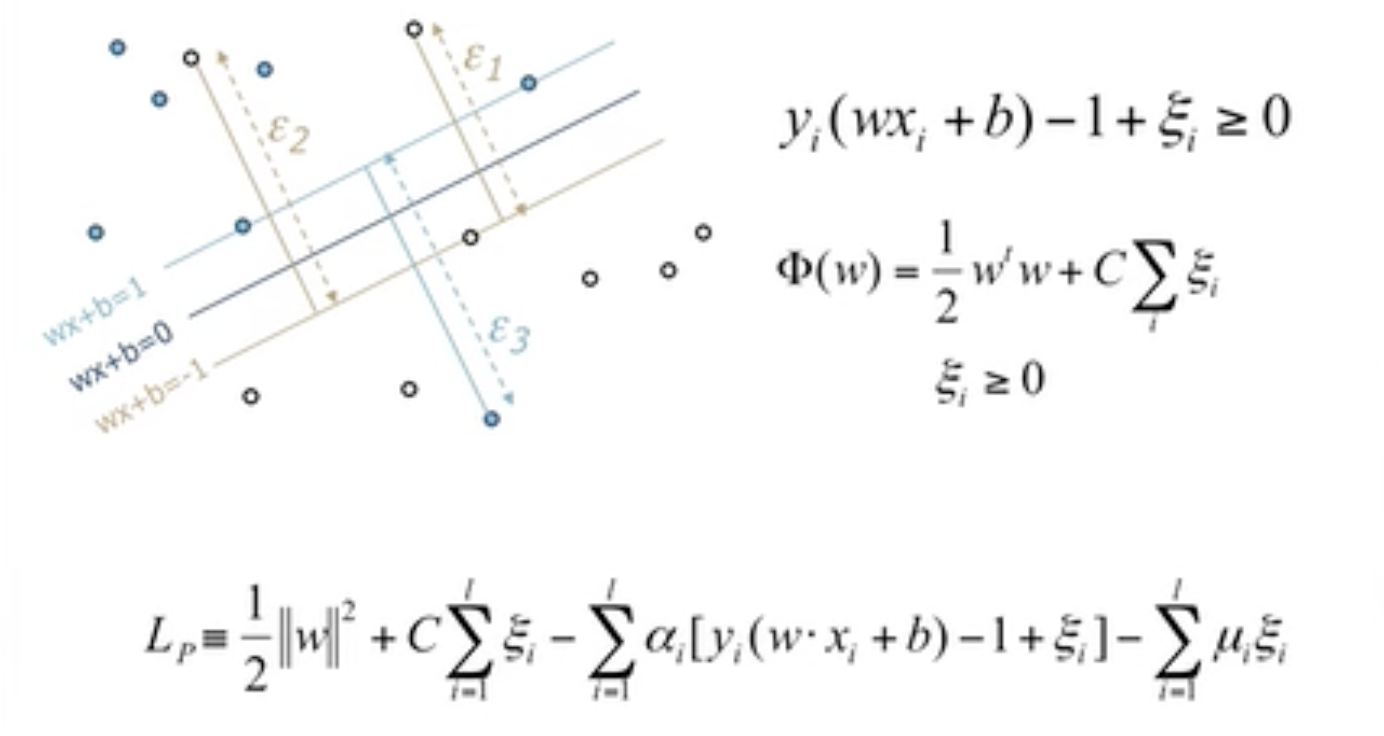
5.3 数学家的把戏
Non-liner SVMs
针对某些线性不可分的数据,将其映射到另一个维度使其线性可分,该另一个维度叫Feature Space(特征空间)。
注意:针对同一问题其映射的方法并不唯一。
Quadratic Basis Function
Quadratic Basis Function:二次基函数
映射方法一般使用几种常用的方法。

Kernel Trick

Kernels
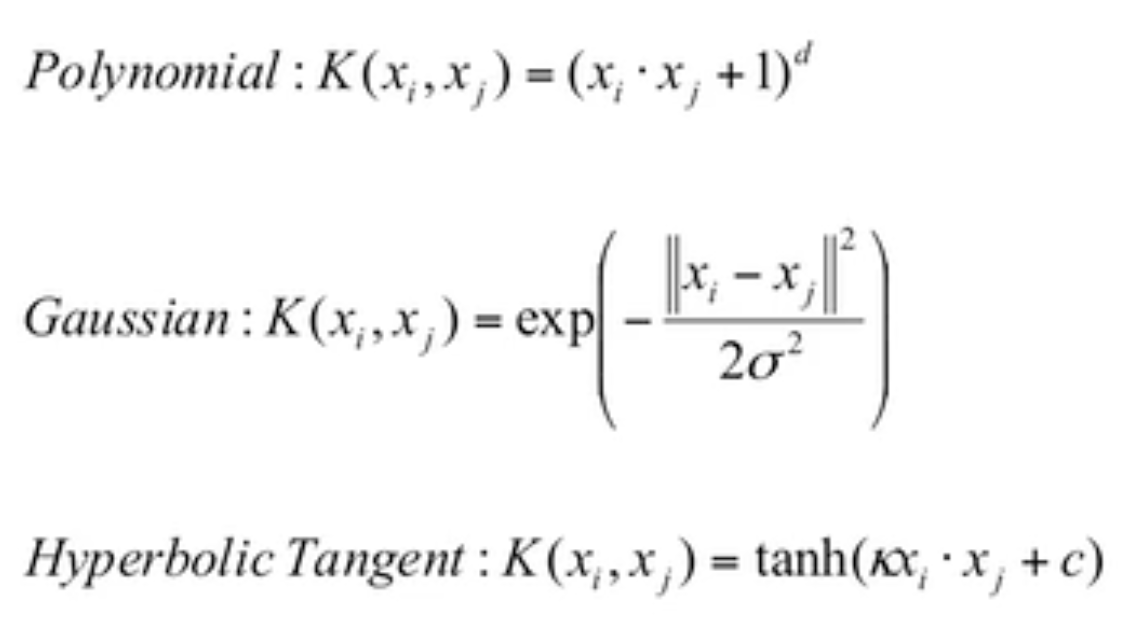
Solutions of w & b

5.4 致敬真神
SVM Roadmap
Liner Classifer(Maximum Margin)
=>
Linear SVM(Noise)
=>
Soft Margin(Nonliner Promblem)
=>
\(a·b->\Phi(a)·\Phi(b)\)(High Computational Cost)
=>
Kernel Trick(\(K(a,b)=\Phi(a)·\Phi(b)\))
经过多年的发展才形成现代的SVM模型。
Model Capacity
Capacity是一个非正式的术语。 它与模型复杂性非常接近(如果不是同义词的话)。 这是一种谈论模型可以表达多么复杂的模式或关系的方式。 可以期望容量较高的模型能够比容量较低的模型建模更多变量之间的关系。
VC Dimension
从数学的角度给出解释,当训练误差相同时选择复杂度较低的模型。
6.1 无监督学习(聚类)
聚类的分类
Partitioning Methods
Hierarchical Methods
聚类分析的定义...
Applications of Cluster
举了一些例子...
- 地震...
- Image Segmentation
聚类流程![image-20231106094749381]()
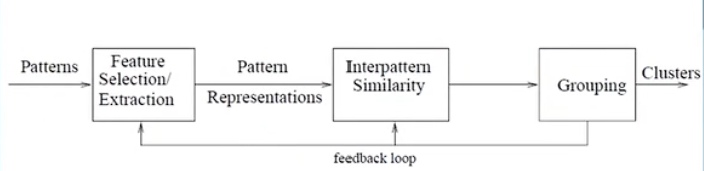
interpattern similarity:模式间相似度
pattern representations:模式表示
使用聚类的要求
- Ability to discover clusters with arbitrary shape
- Ability to deal with noise and outliers
Practical Considerations
Practical: 实际的
数据预处理的坐标变换会影响聚类的结果。
Normalization or Not:归一化后也会影响聚类的结果。
6.2 K-Means
Evaluation
距离公式: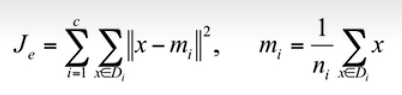
存在的问题:假定聚类是呈球状的。
举例说明: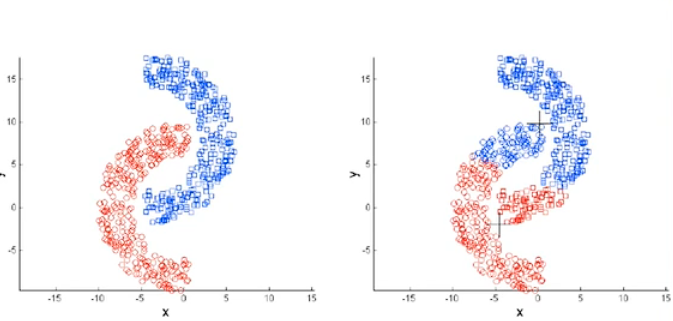
Silhouette
解释和验证数据聚类的方法:有个公式...
举例:...
K-Means
时间复杂度O(r·k·n):
t:iterationK:number of centroids(质心)(聚类的个数)n:number of data points
缺点:
...
Sequential Leader Clustering
优缺点...
需要设置threshold.
算法基本思想:顺序扫描一边所有元素,算出与所有与已知簇的中心点的距离,距离小于Threshold的为同一簇,大于的自立门户。
6.3 期望最大法
Gaussian Mixture(model)
使用多个高斯函数来逼近已知数据,通过添加权重使所有高斯函数的面积仍为1.(多个高斯函数叠加有点想傅里叶级数)
K-Means Revisited
Expectation Maximization
EM算法
具体过程...
EM:Gaussian Mixture
公式...
6.4 密度与层次
Density Based Methonds
DBSCAN:
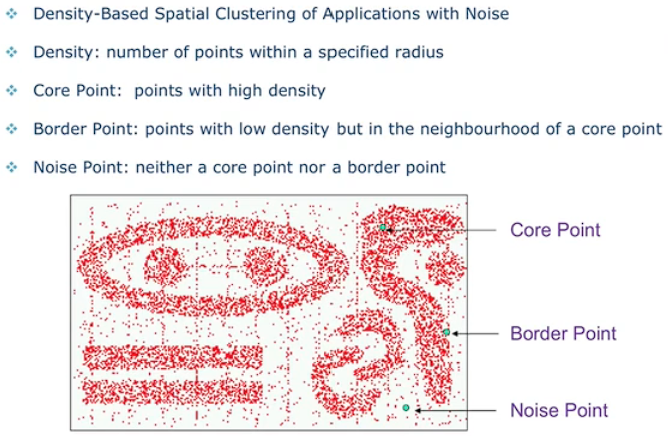
三个概念:
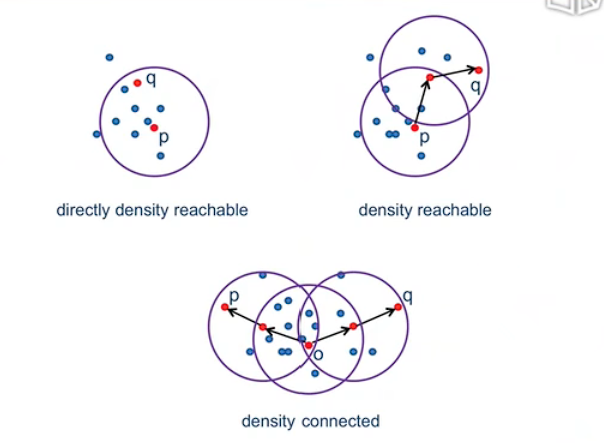
Hierarchical Clustering
agglomerative Method
Example
Min vs. Max
Reading Materials

7.1 项集与规则
associate rule 定义:前项(Antecedent)和后项(Consequent)。前项是规则的先决条件,后项是规则的结果。这两部分之间用箭头连接。一个简单的关联规则的例子如下:如果{商品A}出现,那么{商品B}也很可能出现。关联规则的度量通常包括支持度(Support)和置信度(Confidence)。支持度表示规则中前项和后项同时出现的频率,而置信度表示在前项出现的条件下,后项也同时出现的概率。
7.2 支持度与置信度
\(Support(X)=\frac {\#X}n\), 即n个items中 X出现的频率.
The Support of an Association rule: \(Supoort(X\to Y)=\frac{\#(X\cup Y)}n\), 即同时购买了X和Y的频率
The Confidence of an Association rule: \(Confidence(X\to Y)=\frac{\#(X\cup Y)}{\#(X)}\), 即购买了X的人数当中同时购买了X 和 Y 的比例。即条件概率...
7.3 误区
- 算出
support和confidence需要再去看商品本身先验概率。 - 要注意
support差距非常大的商品。 - \(Association\ne Causality\)(有关系不等于有因果关系)
7.4 Apriori算法
Apriori算法,数据挖掘十大算法
Key ideas:
- A subset of a frequent itemset must be frequent.(频繁
itemset的子集一定频繁) - The supersets of any infrequent itemset cannot be frequent.(不频繁的
itemset的超集一定不频繁)
算法思想:
- 选出1个频繁的item
- 从频繁的item中选出2个频繁的
- 以2类推...
如图:
7.5 实例分析
...
具体讲了如何计算出\(C_3\),简单来说就是必须有\(C_2=\{\{1,2\},\{1,5\},\{2,5\}\}\),才能推出\(C_3=\{1,2,3\}\).
7.6 序列模式
Sequential Pattern
什么是sequence?
答:具有先后顺序的 集合list。集合是itemset.
序列t是否是序列s的子序列, 看是否能在s内按顺序的找到t中集合的超集。
数学定义: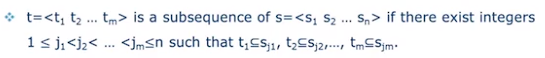
Support of Sequence: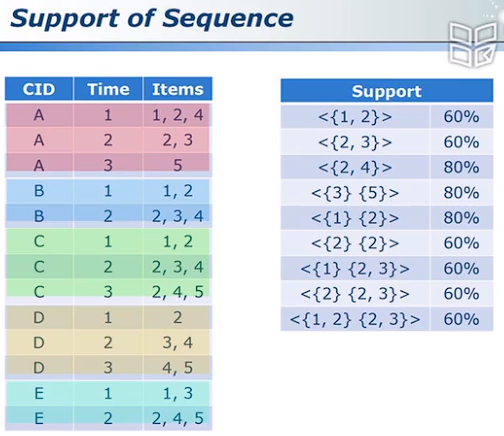
8.1 无处不在的推荐
Recommendation Systems
- Content-Based Filtering
- Collaborative Filtering
Targeted Advertisement
Ads Engine
各种例子。
8.2 隐含语义分析
TF-IDF
三个公式...
Term Frequency:词频
Inverse Document Frequency:逆文档频率
TF-IDF,越高越好。
Term-Document Matrix...
Vector Space Model
将整篇文档转化为向量:\(p=(w_{1,p},w{2,p},...,{w_{t,p}})\)。(w stands for word,单词)
通过cos公式计算两篇文档的相似度,值越大越相似。
该模型存在的问题:
- Synonymy(同义词),导致 poor recall。
- Polysemy(一词多义),导致 poor precision。
Latent Semantic Analysis
Latent Semantic Analysis,隐含语义分析
举了个例子...
8.3 PageRank传奇
google的衡量方法
取决于两个指标:
- PageRank(指向与自己网站的网页数量?)
- number of outbound links(指向自己网站的网页的出站连接总数)
8.4 协同过滤
Collaborative Filtering,协同过滤
核心想法...
存在的问题...
User-Based CF
在讲公式...
Item-Based CF
举了一个例子。
Model-Based CF
8.5 告诉你一个真实的推荐
Netflex案例。
KDD,数据挖掘顶会
淘宝推荐案例
Reality Mining
9.1 Ensemble
图示: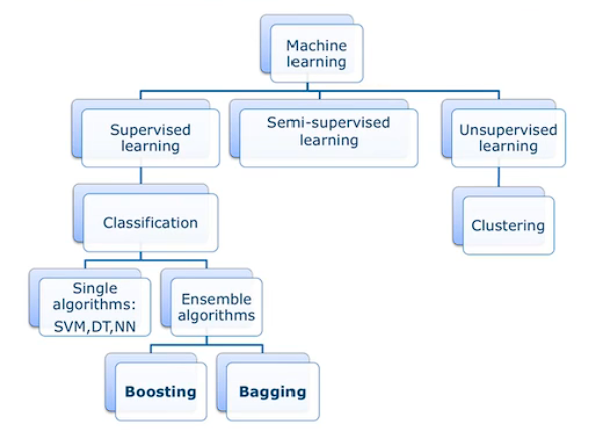
Model Selection
多个模型取平均,即集成学习(Ensemble learning)
Divide and Conquer
大问题化为小问题。微分思想。
9.2 Bagging
Diversity
Bootstrap Sample
使用有放回的抽样形成的数据集训练出的分类器可以视作不同的分类器。
bagging 流程
图示: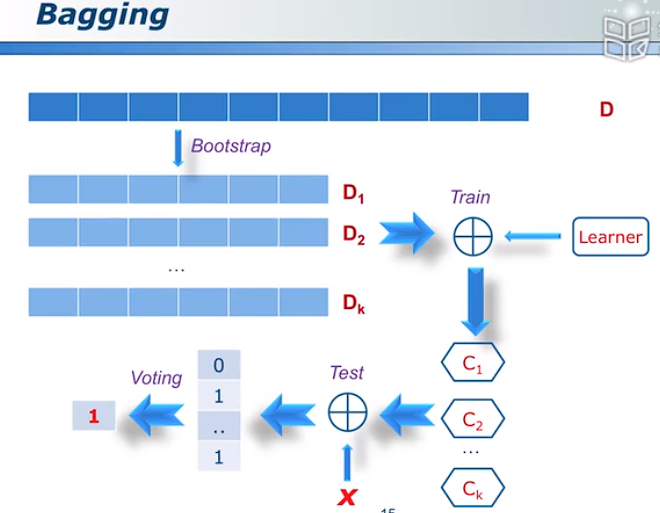
图中Learner为模型
Random Forest
Bagging的算法之一,随机森林
RF Main Features
RF Advantages
9.3 Boosting
Stacking:加权重的Bagging
Stacking图示: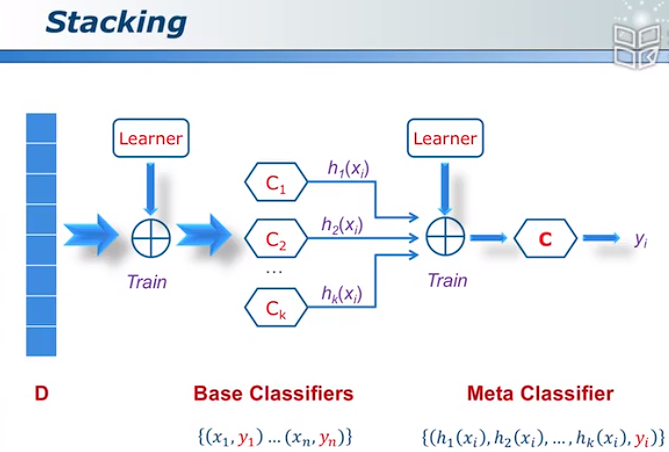
Bosting图示:
下图中\(C_2\)分类器着重训练\(D_2\)中判断错误的样本以实现分类器的互补。
注意:着重训练的方法是通过增加判断错误样本的权重实现的。
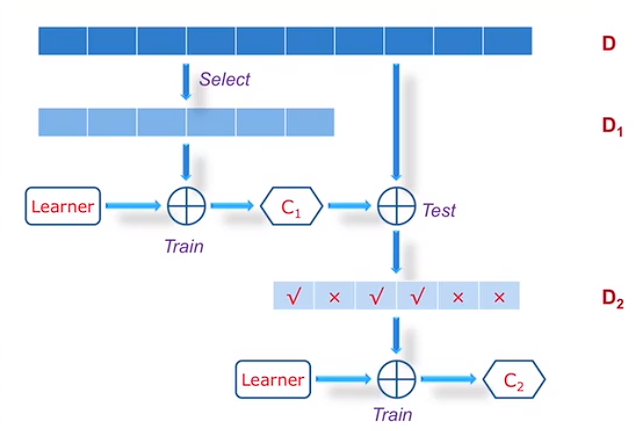
下图中\(C_3\)分类器负责解决\(C_1,C_2\)分类器同时分类时出现的判断不一致的问题。
9.4 AdaBoost
数据挖掘十大算法之一
AdaBoost的优缺点:...
9.5 RegionBoost
Dynamic Weight Scheme
不同的输入在不同的分类器中的权重是不一样的
10.1 人与自然
该文章对进化计算有一个全面概要的介绍:进化计算_百度百科 (baidu.com)。
Overview:
- Global Optimization
- Genetic Algorithms
- Genetic Programming
- Evolvable Things
Motivation of EAs: Optimization for our subject
Key Concepts:
- Population-Based Stochastic Optimization Mehtod(基于数量的随机优化方法。)
- Inherently Parallel(本质上并行的)
- A Good Example of Bionics in Engineering(生物工程)
- Survival of the Fittest(适者生存)
- Chromosome, Crossover, Mutation(染色体,杂交,变异)
- Metaheuristics(元启发算法)
- Bio-/Nature Inspired Computing
The big picture
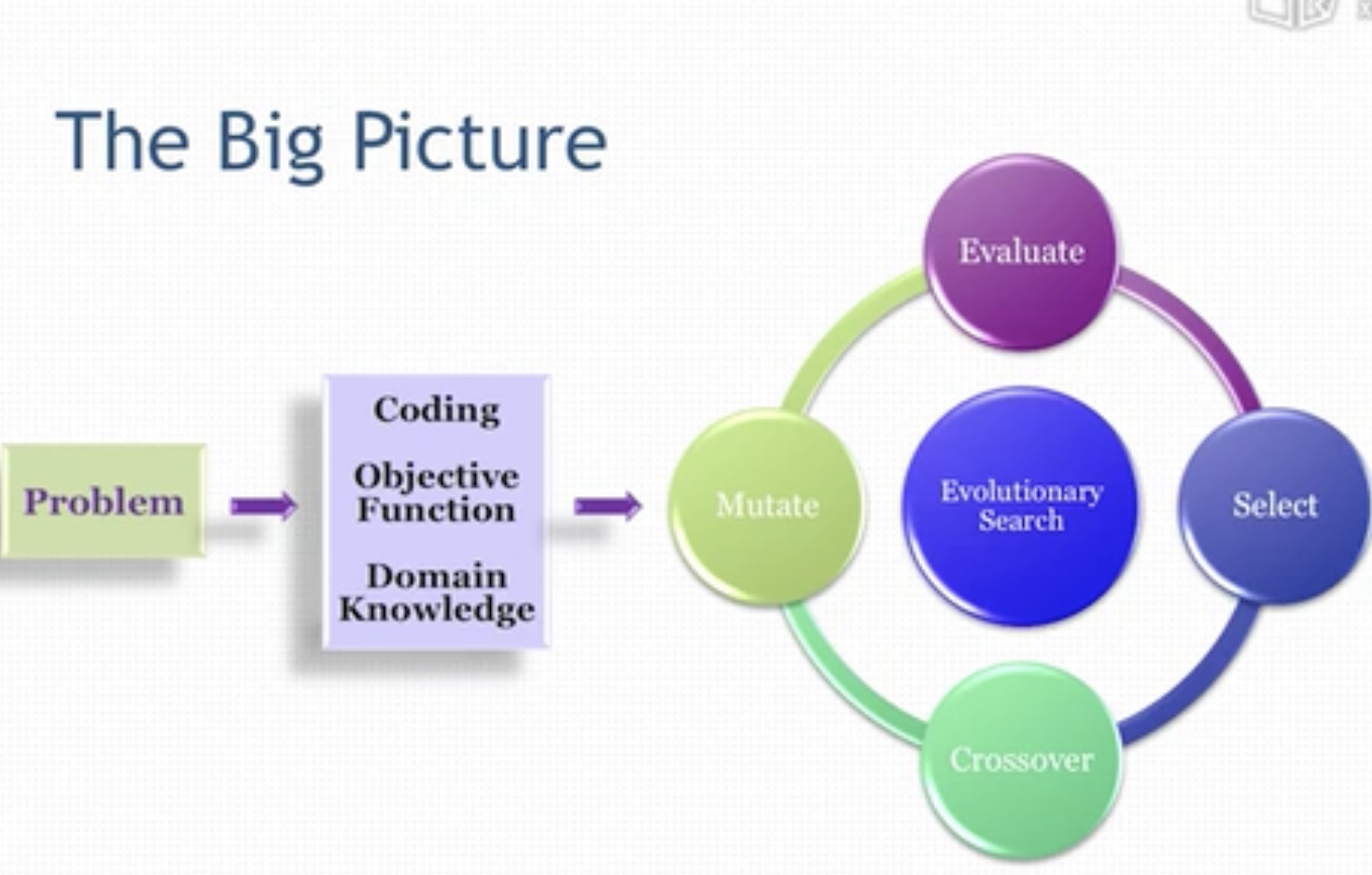
EA Family
它有一系列的算法。
10.2 尽善尽美
Bin Packing 优化算法:
- First fit algorithms
- First Fit decreasing algorithms(先排序再放)
用几个例子说明优化问题无法用暴力算法解出。
10.3 走向进化
防止陷入局部最优化的方法:Parellel search
介绍了领域内的人与相关书籍。
Blondie24,自监督学习的跳棋软件。
10.4 遗传算法初探
生物学背景:

Genetic Algorithms:

Basic Components
组成:
- Representation:如何编码的问题。
- Individual(Chromosome),A vector that represent a specific solution to the promblem.
- Population, A set of individuals.
- Offspring(后代), New individuals generated via genetic operators.
- Encoding, Binary vs. Gray
- Genetic Operator:杂交和变异。
- Selection Strategy:选择
Gray 码,任意两个相邻的编码之间只有一位的不同。
Selection
种类:
- Roulette Wheel Selection(某个体分数占所有个体分数和的百分比来排名)
- Rank Selection(按分数排名,解决了有负数的问题)
- Tournament Selection
- Elitism(精英选择)
10.5 遗传算法进阶
Crossover
种类:
- One point crossover:选一个点,该点后面的所有点进行交换。
- Two point crossover:选两个点,两点之间的元素进行交换。
- Uniform Crossover:对所有的点,若两元素不相同则随机选择其中一个元素继承。
Mutation

Selection vs. Crossover vs. Mutation:

GA Frameworks的完整流程:
Parameters:
- Population Size
- Too big:Slow convergence rate(减慢收敛速度)
- Too small:Premature convergence(不成熟的收敛,即收敛的局部最优点)
- Crossover Rate
- Recommended value:0.8
- Mutation Rate
- Recommend value:1/L
- Selecton Strateg,使用上面提到的算法。
Feature Selection

GAs & Clustering

Pareto Front
给出所有“好”的解,让用户来选择最适合他自己目标任务的解。
10.6 遗传程序设计
GA: Genetic algorithms,遗传算法。
GP: Genetic Programming,遗传编程。
GA vs. GP
Function & Terminals

Crossover
树也可以进行杂交。
Mutation
对树的某个节点进行变异。
10.7 万物皆进化
Evolvable Circuits,可进化电路。
通过控制不同电路不同部分的断开和连接来实现不同的功能,以达到可编程的功能。
Antenna for NASA
Car Design, 使用机器设计汽车。
Artificial Life,通过程序以实现某个目的自主设计结构。
Evolutionary Arts

 浙公网安备 33010602011771号
浙公网安备 33010602011771号