Spark任务调度和资源调度图解
1、Spark中application、job、stage、task、driver/executor之间的关系
-
一个application就是一个应用程序,包含了客户端所有的代码和计算资源
-
一个action操作对应一个DAG有向无环图,即一个action操作就是一个job
-
一个job中包含了大量的宽依赖,按照宽依赖进行stage划分,一个job产生了很多个stage
-
一个stage中有很多分区,一个分区就是一个task,即一个stage中有很多个task
-
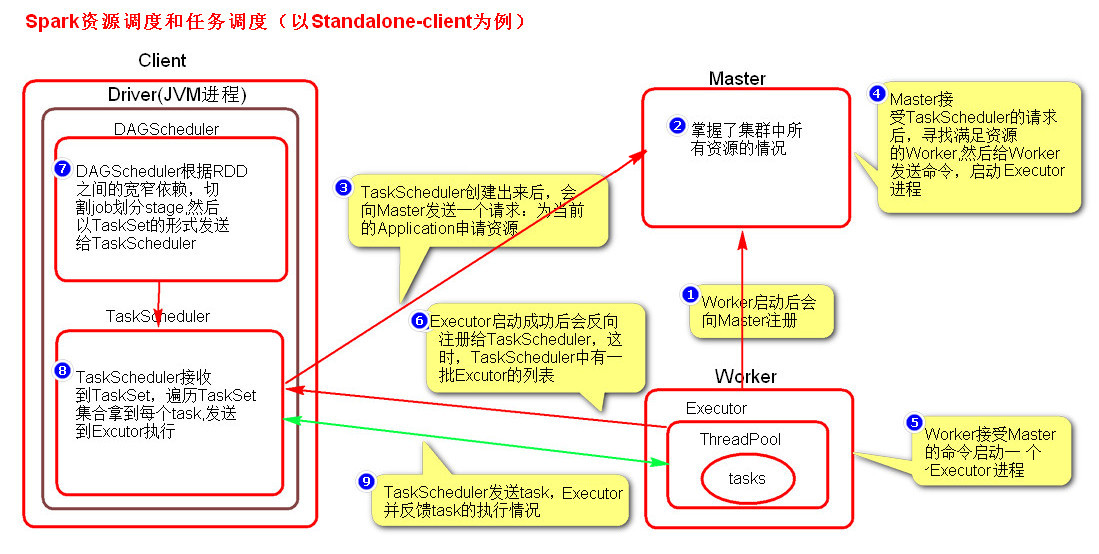
driver进程就是应用的main()函数并且构建sparkContext对象,当我们提交了应用之后,便会启动一个对应的driver进程,driver本身会根据我们设置的参数占有一定的资源(主要指cpu core和memory)。下面说一说driver和executor会做哪些事。driver可以运行在master上,也可以运行worker上(根据部署模式的不同)。driver首先会向集群管理者(standalone、yarn,mesos)申请spark应用所需的资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory。在申请到应用所需的资源以后,driver就开始调度和执行我们编写的应用代码了。driver进程会将我们编写的spark应用代码拆分成多个stage,每个stage执行一部分代码片段,并为每个stage创建一批tasks,然后将这些tasks分配到各个executor中执行。executor进程宿主在worker节点上,一个worker可以有多个executor。每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver,每个executor执行的task都属于同一个应用。此外executor还有一个功能就是为应用程序中要求缓存的 RDD 提供内存式存储,RDD 是直接缓存在executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
2、任务调度
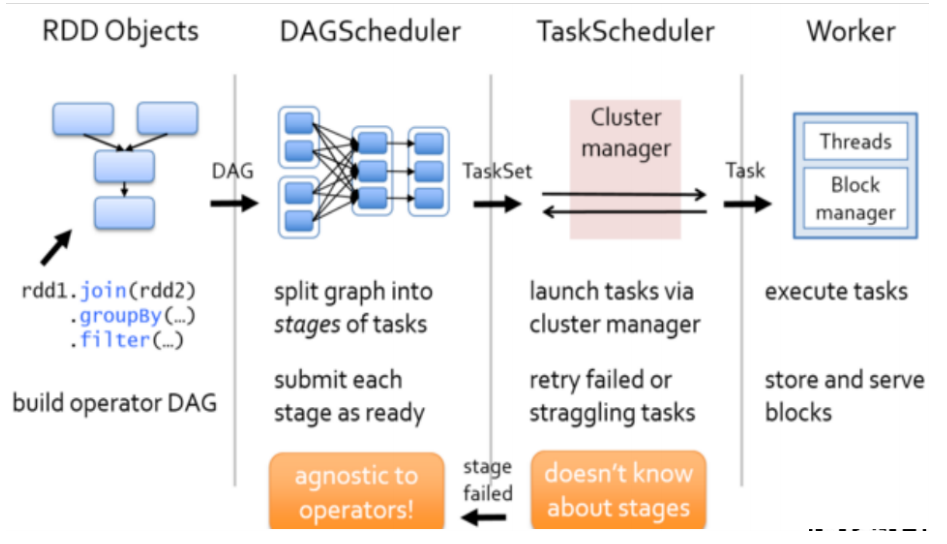
3、资源调度和任务调度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号