Spark初始
回顾MR
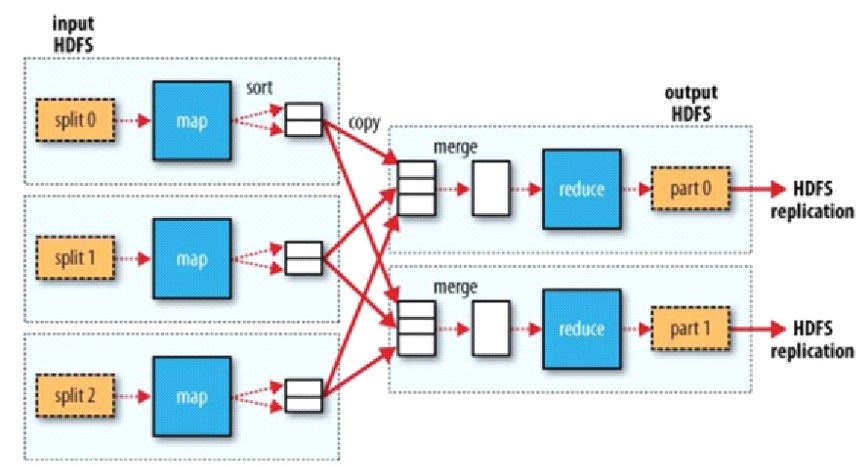
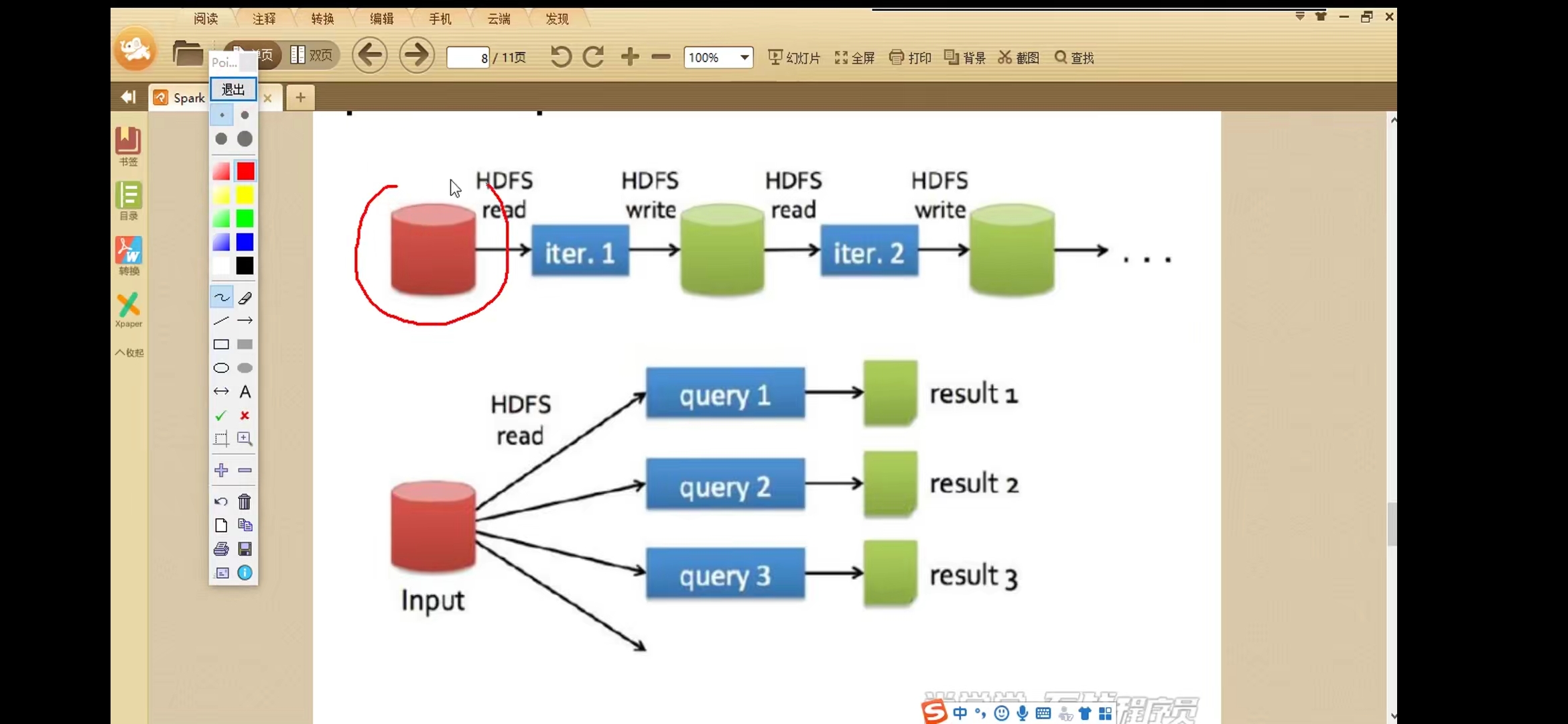
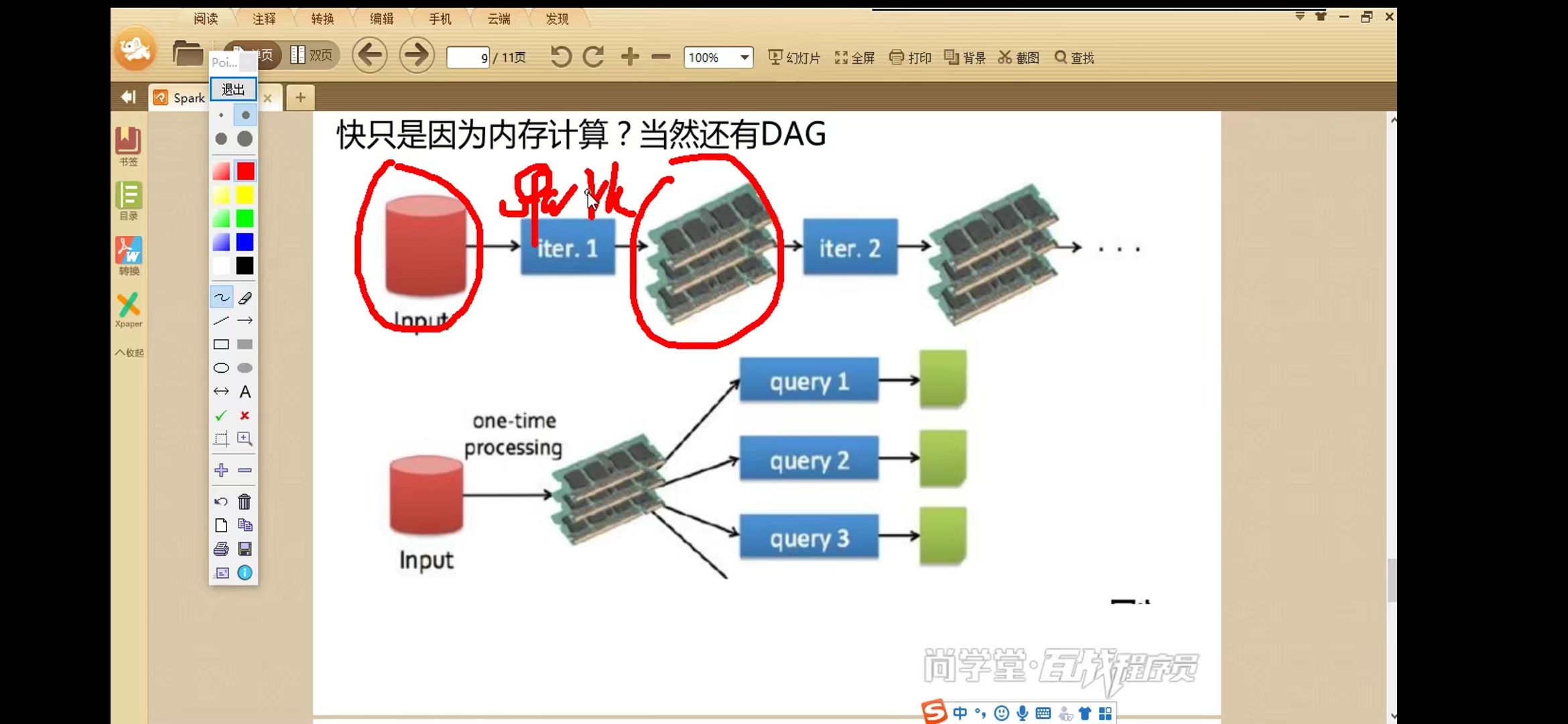
对比Spark
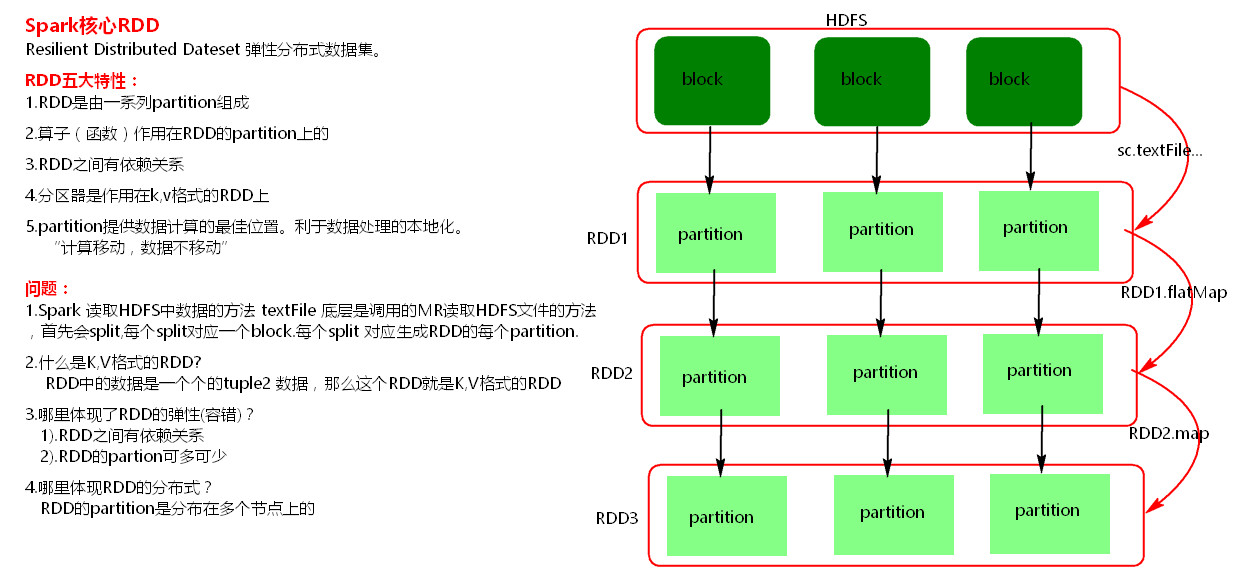
核心RDD
-
理解RDD
一个 RDD 可以简单的理解为一个分布式的元素集合.
RDD 表示只读的分区的数据集,对 RDD 进行改动,只能通过 RDD 的转换操作, 然后得到新的 RDD, 并不会对原 RDD 有任何的影响.
在 Spark 中, 所有的工作要么是创建 RDD, 要么是转换已经存在 RDD 成为新的 RDD, 要么在 RDD 上去执行一些操作来得到一些计算结果.
每个 RDD 被切分成多个分区(partition), 每个分区可能会在集群中不同的节点上进行计算.
-
通过wordCount理解RDD
算子
Transformations转换算子:Transformations算子是延迟执行,也叫懒加载执行。
Action行动算子:一个application应用程序中有几个Action类算子执行,就有几个job运行。
控制算子:控制算子有三种cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
-
控制算子
cache算子:默认将RDD的数据持久化到内存中。cache是懒执行。
persist算子:可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2”表示有副本数。
【注意】
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache和persist算子后不能立即紧跟action算子。
- cache和persist算子持久化的数据当applilcation执行完成之后会被清除。
checkpoint算子:checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。checkpoint目录数据当application执行完之后不会被清除。
【原理】
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号