Hive基础
引入
- 非Java程序员利用SQL进行MR任务处理
简介
-
数据仓库:普通数据库做交互式查询;数据仓库离线数据分析、不支持实时性;数据仓库用ETL把不同数据源数据进行统一存储;时间拉链:仓库里数据不允许删除、修改;
-
解释器、编译器、优化器
-
元数据存储在关系型数据库中(不能存储在HDFS中,因为HDFS皆文件,不会区分你是一个表或者字段关联关系等)
架构
-
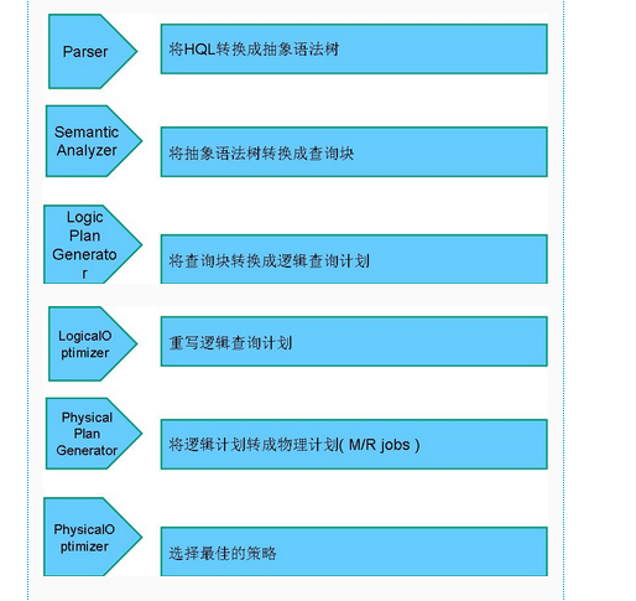
编译器将一个Hive SQL转换操作符,操作符是Hive的最小的处理单元,每个操作符代表HDFS的一个操作或者一道MapReduce作业.
-
Operator都是hive定义的一个处理过程:Select Operator、TableScan Operator、Limit、File Output Operator
安装
-
Local metastore Database(Derby)
-
Remote metastore Database(一台mysql 一台hive)
-
Remote metastore server(一台mysql 一台server 一台hive)可以无感知更换mysql
-
node0001安装mysql node0002安装Hive
操作-DDL(创建表 插入数据)
-
数据类型:primitive:INT、STRING、TIMESTAMP data_type:array_type、map_type
-
[ROW FORMAT row_format] hdfs纯文本文件,需要指定分隔符
-
举例-创建表
create table psn ( id int, name string, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; -
举例-数据
1,小明1,lol-book-movie,beijing:shangxuetang-shanghai-pudong 2,小明2,lol-book-movie,beijing:shangxeutang-shanghai-pudong -
举例-插入数据:insert into条插入数据太费时,因为底层执行的是mr任务。所以用load
load data local inpath '/root/data/data' into table psn; -
插入知识复习:移动计算就是把计算任务下发到数据所在的节点进行处理。移动数据就是将数据移动到计算任务的节点,这样将损耗大量网络开销,导致流量激增,处理效率慢。
-
举例-创建表(hdfs默认分隔符)
create table psn2 ( id int, name string, likes array<string>, address map<string,string> ) -
举例-数据源
1^A小明1^Alol^Bbook^Bmovie^Abeijing^Cshangxuetang^Bshanghai^Bpudong
操作-DDL(table type)
-
举例-建表命令
create external table psn4 ( id int, name string, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/usr/'; -
内部表和外部表的区别:
1、创建表的时候,内部表直接存储再默认的hdfs路径,外部表需要自己指定路径 2、删除表的时候,内部表会将数据和元数据全部删除,外部表只删除元数据,数据不删除 3、每天收集到的网站数据,需要做大量的统计数据分析,所以在数据源上可以使用外部表进行存储,方便数据的共享,在做统计分析时候用到的中间表,结果表可以使用内部表,因为这些数据不需要共享,使用内部表更为合适。 -
Hive和关系型数据库
hive:读时检查(实现解耦,提高数据记载的效率) 关系型数据库:写时检查
操作-分区
- 区别:
1.静态分区是需要指定分区的(源数据中没有)
2.动态分区是利用数据中的字段坐分区的,(源数据中有的),🈲 主分区动态分区,次分区静态分区,使得每个主分区下面都要创建静态分区
-
引入:数据倾斜;
-
MR里的分区:随机分配到不同的计算节点
-
没有建立分区,所有年份数据放在一起,检索年月数据比较拉闸。建立分区,按年月分
-
举例-单分区
create table psn5 ( id int, name string, likes array<string>, address map<string,string> ) partitioned by(age int) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; -
举例-数据加载1
load data local inpath '/root/data/data' into table psn5 partition(age=10); -
举例-查询结果展示1
1 小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 10 -
举例-数据加载2
load data local inpath '/root/data/data' into table psn5 partition(age=20); -
举例-查询结果展示2
1 小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 10 1 小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 20 -
举例-HDFS
/root/age=10/data /root/age=20/data -
举例-双分区
create table psn6 ( id int, name string, likes array<string>, address map<string,string> ) partitioned by(age int,sex string) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; -
举例-数据加载
load data local inpath '/root/data/data' into table psn5 partition(age=20,sex='man'); -
举例-HDFS
/root/age=10/sex=man/data
操作-DML
-
插入知识复习:drop delete truncate
delete是DML,执行delete操作时,每次从表中删除一行,并且同时将该行的的删除操作记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,但要注意表空间要足够大,需要手动提交(commit)操作才能生效,可以通过rollback撤消操作。 truncate是DDL,会隐式提交,所以,不能回滚,不会触发触发器。 drop是DDL,会隐式提交,所以,不能回滚,不会触发触发器。 -
数据加载1:overwrite会覆盖现有的数据,而into是直接将数据写入库。
一次读取 多次插入 FROM psn INSERT OVERWRITE TABLE psn10 SELECT id,name insert into psn11 select id,likes -
数据加载2:
insert overwrite local directory '/root/result' select * from psn; -
插入知识复习:HDFS上的文件不支持修改
操作-Serde
- 类似row format delimited,一种数据组织加载方式。用正则表达式匹配
客户端- BeeLine
-
Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具,Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLine CLI的JDBC客户端。
-
Beeline支持嵌入模式(embedded mode)和远程模式(remote mode)。在嵌入式模式下,运行嵌入式的Hive(类似Hive CLI),而远程模式可以通过Thrift连接到独立的HiveServer2进程上。从Hive 0.14版本开始,Beeline使用HiveServer2工作时,它也会从HiveServer2输出日志信息到STDERR。
-
hive Cli 程序员用 Beeline 客户端用
函数
-
内置函数
-
举例-条件函数(实现行转列)
-
举例-数据
name subject score zhangsan yuwen 89 zhangsan shuxue 90 lisi yuwen 83 lisi shuxue 89 wangwu yuwen 82 wangwu shuxue 88 name yuwen shuxue zhangsan 89 90 lisi 83 89 wangwu 82 88 -
举例-实现(Join)
select name,score from t where t.subject='yuwen'; t1 select name,score from t where t.subject='shuxue'; t2 select t1.name,t1.score,t2.score from t1 join t2 on t1.name=t2.name -
举例-实现(case)
select UserName 姓名, sum(case Subject when '语文' then Source else 0 end) 语文,sum(case Subject when '数学' then Source else 0 end) 数学, sum(case Subject when '英语' then Source else 0 end) 英语 from TestTable group by UserName -
自定义函数
-
a) UDF:一进一出
-
b) UDAF:多进一出
-
c) UDTF:一进多出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号