安装
全分布式安装
-
node0001-node0004安装JDK
-
node0001-node0004ssh免密登录
-
修改node0001 全分布式配置文件 [node0001 namenode] [node0002 secondarynode][node0002 node0003 node0004 datanode]
-
拷贝node0001配置到node0002-node0004
-
配置node0002-node0004
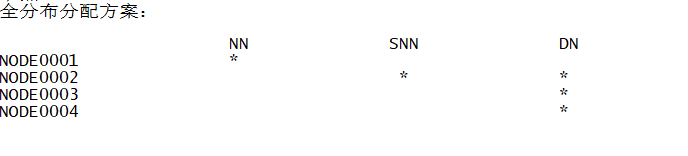
-
在node0001上启动集群:start-dfs.sh stop-dfs.sh
hadoop1.X问题
- NameNode单点故障,难以应用于在线场景=>HA
- NameNode压力过大,且内存受限,影响扩展=>Federation
Hadoop 2.X介绍
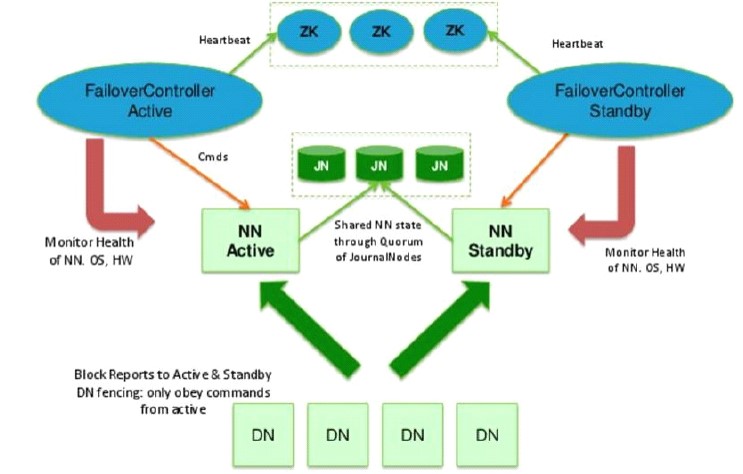
主备NameNode
1.解决单点故障(属性,位置)
主NameNode对外提供服务,备NameNode同步主NameNode元数据(静态信息交换),以待切换(这里根secondaryNode不一样)
所有DataNode同时向两个NameNode汇报数据块信息(动态信息交换)
主备元数据交换:
socket不可取,因为备得发ack确认。所以对于主来说就会有单点阻塞问题
hadoop,二者中间加个外部同步服务器,但还是有单点问题
JournalNode:三台服务器(HA)接收NameNode日志文件,备从里面取
standby:备,完成了edits.log文件的合并产生新的image,推送回ANN(这里体现了secondaryNode的作用)
两种切换选择
手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
自动切换:基于Zookeeper实现
基于Zookeeper自动切换方案
ZooKeeper Failover Controller:监控NameNode健康状态,
并向Zookeeper注册NameNode
NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
zookeeper https://www.cnblogs.com/Coeus-P/p/13234266.html
zookeeper Hadoop
ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。
Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
Federation
2.解决NameNode压力过大
通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。
Hadoop 2.X 搭建
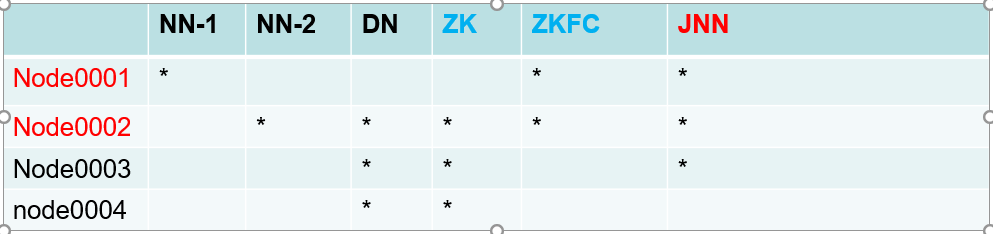
1. NN-2 代替 SNN 不仅完成fsimg edits的合并 而且 充当备
2. zk Zookeeper集群
3. ZkFC zk客户端 监控namenode在zk集群上的znode(参见zookeeper梳理)
4. JNN,NN-1和NN-2交换日志信息=外部共享服务器
5. zk JNN启动要先于 hdfs启动
-
NN-1 和 NN-2要实现自动切换 所以免密登陆
-
node0001进行相关配置文件修改 并且分发到不同的节点
-
node0002 zookeeper安装
-
zookeeper配置
-
node0002 node0003 node0004 zkServer.sh start zkServer.sh stop => jps QuorumPeerMain
-
node0001--0003 hadoop-daemon.sh start journalnode => jps JournalNode
-
node0001 start-dfs.sh => jps namenode datanode DFSZKFailoverController
当前配置的启动和关闭
node0001 stop-dfs.sh => jps namenode datanode journalnode zkfc + zkServer.sh stop
全部:zkServer.sh start node0001 start-dfs.sh
===================================================================================
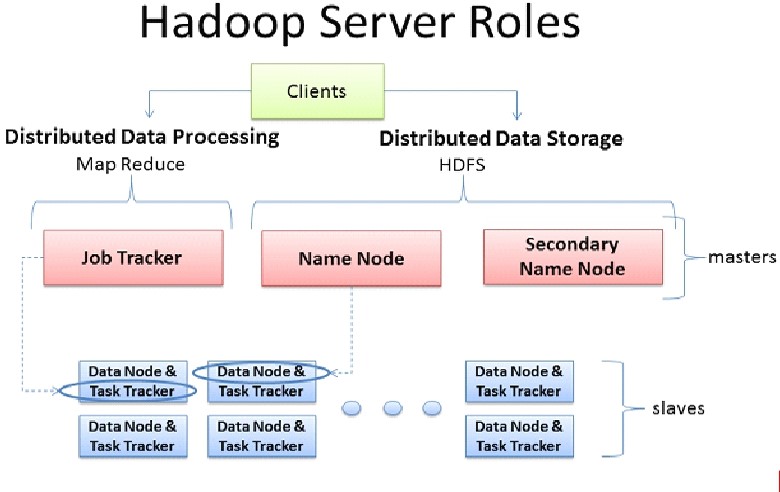
MR 1.X
-
clients:规划任务 map个数 reduce个数
-
Job Tracker :任务调度;在节点上开辟maptask reducetask;task tracker管理map/reduce task,与job tracker保持心跳,汇报资源,获得task。
-
Job Tracker:资源管理,一个集群可能有多个架构,可能别人也在同一节点开辟了reduce task,此时开辟就会失败。所以自己要掌握整个集群的资源利用情况
-
Job Tracker:打包Client的任务配置,提交给HDFS
-
弊端
1. 负载过重,单点故障 2. 资源管理与计算调度强耦合,其他计算框架需要重复实现资源管理 3. 不同框架对资源不能全局管理
MR 2.X
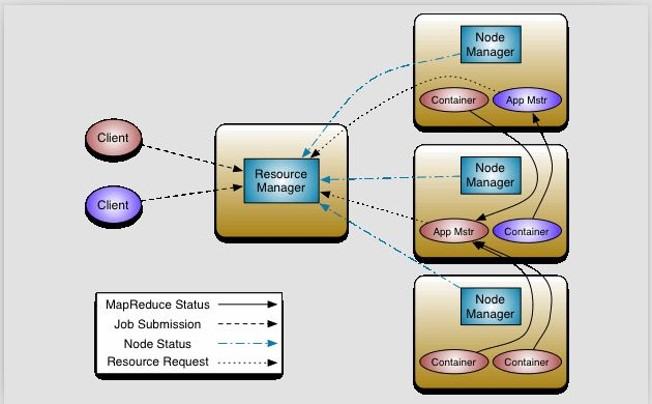
-
resource Manager:总的资源管理
-
nodeManager:本节点资源管理
-
App Mastr: task tracker的作用 与作业一一对应
-
container:map/reduce task容器
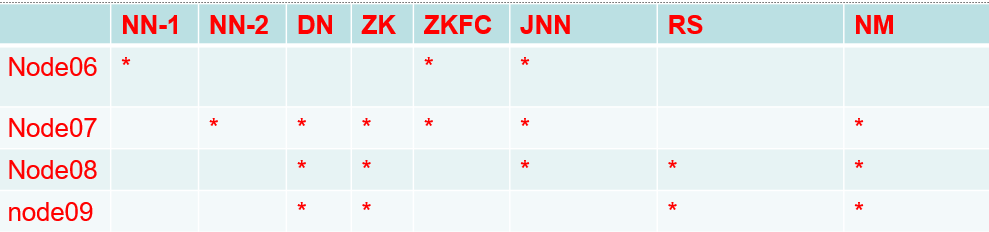
-
Zookeeper和mr计算框架游离于hdfs之外,之间的搭建并不影响
-
全部:zkServer.sh start node0001:start-dfs.sh node0001:start-yarn.sh node0003 node0004: yarn-daemon.sh start resourcemanager
-
node0003 node0004: yarn-daemon.sh stop resourcemanager node0001:stop-all.sh 全部::zkServer.sh stop

