Zookeeper梳理
问题引入
有这样一个场景:系统中有大约100w的用户,每个用户平 均有3个邮箱账号,每隔5分钟,每个邮箱账需要收取100封邮件,最多3亿份邮件需要下载到服务器中(不含附件和正文)。用20台机器划分计算的压力,从 多个不同的网路出口进行访问外网,计算的压力得到缓解,那么每台机器的计算压力也不会很大了。
通过我们的讨论和以往的经验判断在这场景中可以实现并行计算,但我们还期望能对并行计算的节点进行动态的添加/删除,做到在线更新并行计算的数目并且不会影响计算单元中的其他计算节点,但是有4个问题需要解决,否则会出现一些严重的问题:
1.20台机器同时工作时,有一台机器down掉了,其他机器怎么进行接管计算任务,否则有些用户的业务不会被处理,造成用户服务终断。
2.随着用户数量增加,添加机器是可以解决计算的瓶颈,但需要重启所有计算节点,如果需要,那么将会造成整个系统的不可用。
3.用户数量增加或者减少,计算节点中的机器会出现有的机器资源使用率繁忙,有的却空闲,因为计算节点不知道彼此的运行负载状态。
4.怎么去通知每个节点彼此的负载状态,怎么保证通知每个计算节点方式的可靠性和实时性。
先不说那么多专业名词,白话来说我们需要的是:1记录状态,2事件通知 ,3可靠稳定的中央调度器,4易上手、管理简单。
采用Zookeeper完全可以解决我们的问题,分布式计算中的协调员,观察者,分布式锁 都可以作为zookeeper的关键词,在系统中利用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁等功能,利用这些特色在分布式计算中发挥重要的作用。
概念
从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理大家都关心的数据,然后接收观察者的注册,一旦这些数据的状态发生变化,Zookeeper将负责通知在ZOOkeeper上注册的那些观察者做出相应的反应。
架构(文件系统+通知机制)
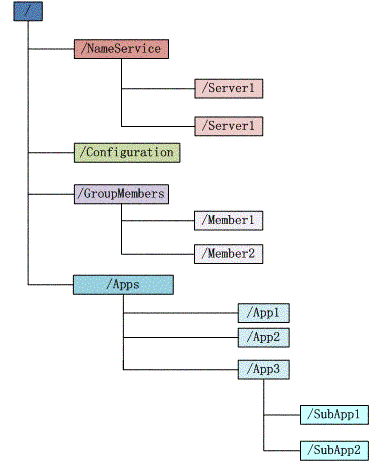
文件系统
通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
角色
-
leader:在ZooKeeper集群中只有一个节点作为集群的领导者,由各Follower通过ZooKeeper Atomic Broadcast(ZAB)协议选举产生,主要负责接收和协调所有写请求,并把写入的信息同步到Follower和Observer。
-
follower:每个Follower都作为Leader的储备,当Leader故障时重新选举Leader,避免单点故障。处理读请求,并配合Leader一起进行写请求处理。
-
observer:Observer不参与选举和写请求的投票,只负责处理读请求、并向Leader转发写请求,避免系统处理能力浪费。
基于角色对于写请求的处理
-
写请求给了observer 和 follower ,转发给leader
-
Leader会向所有的Follower发送提议请求,不对Observer发送。Follower收到来自Leader的提议后,会返回ack响应。
-
Leader收到ack请求后,会采用过半机制,即发送出去的提议有一半以上的ack响应,则就会发送commit提交数据,同时也会向Observer提交commit。
选主流程 fast paxos
Paxos:https://my.oschina.net/u/150175/blog/2992187 https://www.douban.com/note/208430424/
数据模型
投票信息中包含两个最基本的信息。
sid:即server id,用来标识该机器在集群中的机器序号。
zxid:即zookeeper事务id号。ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生. 创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致Zookeeper状态发生改变, 从而导致zxid的值增加.
以(sid,zxid)的形式来标识一次投票信息。例如,如果当前服务器要推举sid为1,zxid为8的服务器成为leader,那么投票信息可以表示为(1,8)
规则
集群中的每台机器发出自己的投票后,也会接受来自集群中其他机器的投票。每台机器都会根据一定的规则,来处理收到的其他机器的投票,以此来决定是否需要变更自己的投票。
规则如下:
(1)初始阶段,都会给自己投票。
(2)当接收到来自其他服务器的投票时,都需要将别人的投票和自己的投票进行pk,规则如下:
优先检查zxid。zxid比较大的服务器优先作为leader。
如果zxid相同的话,就比较sid,sid比较大的服务器作为leader。
举例
假设当前集群中有5台机器组成。sid分别为1,2,3,4,5。zxid分别为9,9,9,8,8,并且此时sid为2的机器是leader。某一时刻,1和2的服务器挂掉了,集群开始进行选主。
在第一次投票中,由于无法检测到集群中其他机器的状态信息,因此每台机器都将自己作为被推举的对象来进行投票。于是sid为3,4,5的机器,投票情况分别为(3,9),(4,8),(5,8)
每台机器把投票发出后,同时也会接收到来自另外两台机器的投票。
对于server3来说,接收到(4,8),(5,8)的投票,对比后由于自己的zxid要大于收到的另外两个投票,因此不需要做任何变更。
对于server4来说,接收到(3,9),(5,8)的投票,对比后由于(3,9)这个投票的zxid大于自己,因此需要变更投票为(3,9),然后继续将这个投票发送给另外两台机器。
对于server5来说,接收到(3,9),(4,8)的投票,对比后由于(3,9)这个投票的zxid大于自己,因此需要变更投票为(3,9),然后继续将这个投票发送给另外两台机器。
经过第二轮投票后,集群中的每台机器都会再次受到其他机器的投票,然后开始统计投票。判断是否有过半的机器收到相同的投票信息,如果有,那么该投票的sid会成为新的leader。
机器总数为5台,server3,4,5都收到投票(3,9)。因此server3成为leader。
无主模型
- 多个从并行,级别相同,但在数据同步的时候交流困难
主从模型
-
客户端可以向任何一个节点发请求
-
对于写操作,从节点请示主节点
-
主节点征求从意见做决定,过半从同意则继续
-
主写完通过各个从的消息队列通知从(消息队列,不会因为节点宕机 消息消失)
监听器原理


 浙公网安备 33010602011771号
浙公网安备 33010602011771号