sklearn——python机器学习の库
sklearn——python机器学习の库
参考链接
- 【【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习】 https://www.bilibili.com/video/BV1xW411Y7Qd/?p=4&share_source=copy_web&vd_source=163dfdf24f62c25720512aaedbfbd696
- 官方文档地址:https://scikit-learn.org/stable/
1、安装
- sklearn安装前:环境中需要
Python(≥3.3)、NumPy(≥1.6.1)、SciPy(≥0.9) - sklearn安装时:
pip install -U scikit-learn
或
conda install scikit-learn
2、选择机器学习方法
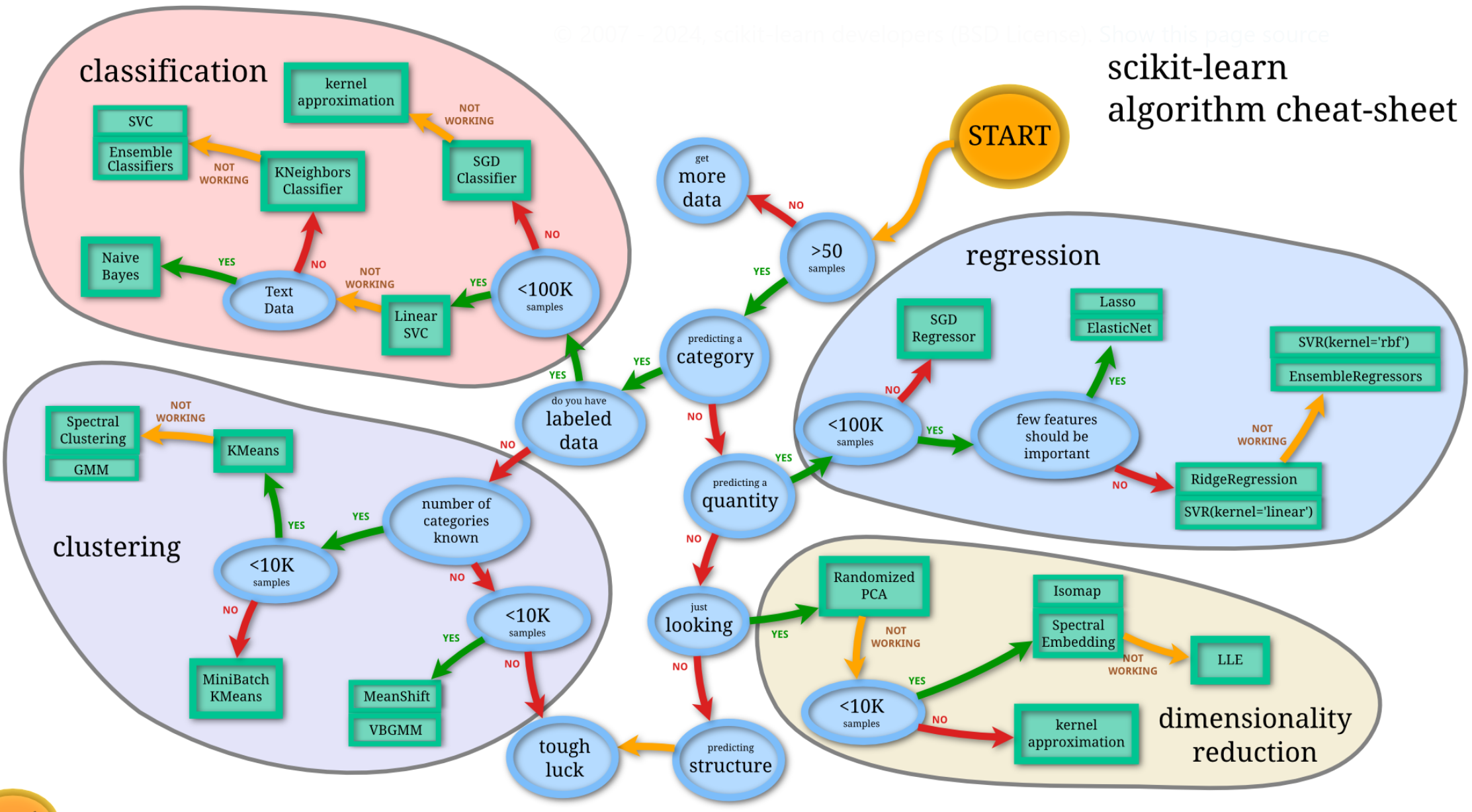
- classification:分类(监督)——线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- regression:回归(监督)——线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
- clustering:聚类(非监督)——k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
- dimensionality reduction:降维(多属性压缩)——LinearDiscriminantAnalysis、PCA
3、通用学习模式
获取数据——》数据预处理——》训练模型——》模型评估——》预测,分类
4、数据集datasets
SKLearn作为通用机器学习建模的工具包,包含六个任务模块和一个数据导入模块:
4.1 sklearn默认数据格式
- Numpy二维数组(ndarray)的稠密数据(dense data),通常都是这种格式。
- SciPy矩阵(scipy.sparse.matrix)的稀疏数据(sparse data),比如文本分析每个单词(字典有100000个词)做独热编码得到矩阵有很多0,这时用ndarray就不合适了,太耗内存。
4.2 自带数据集
- 下面以鸢尾花数据集为例,包含4个特征和3个类别。
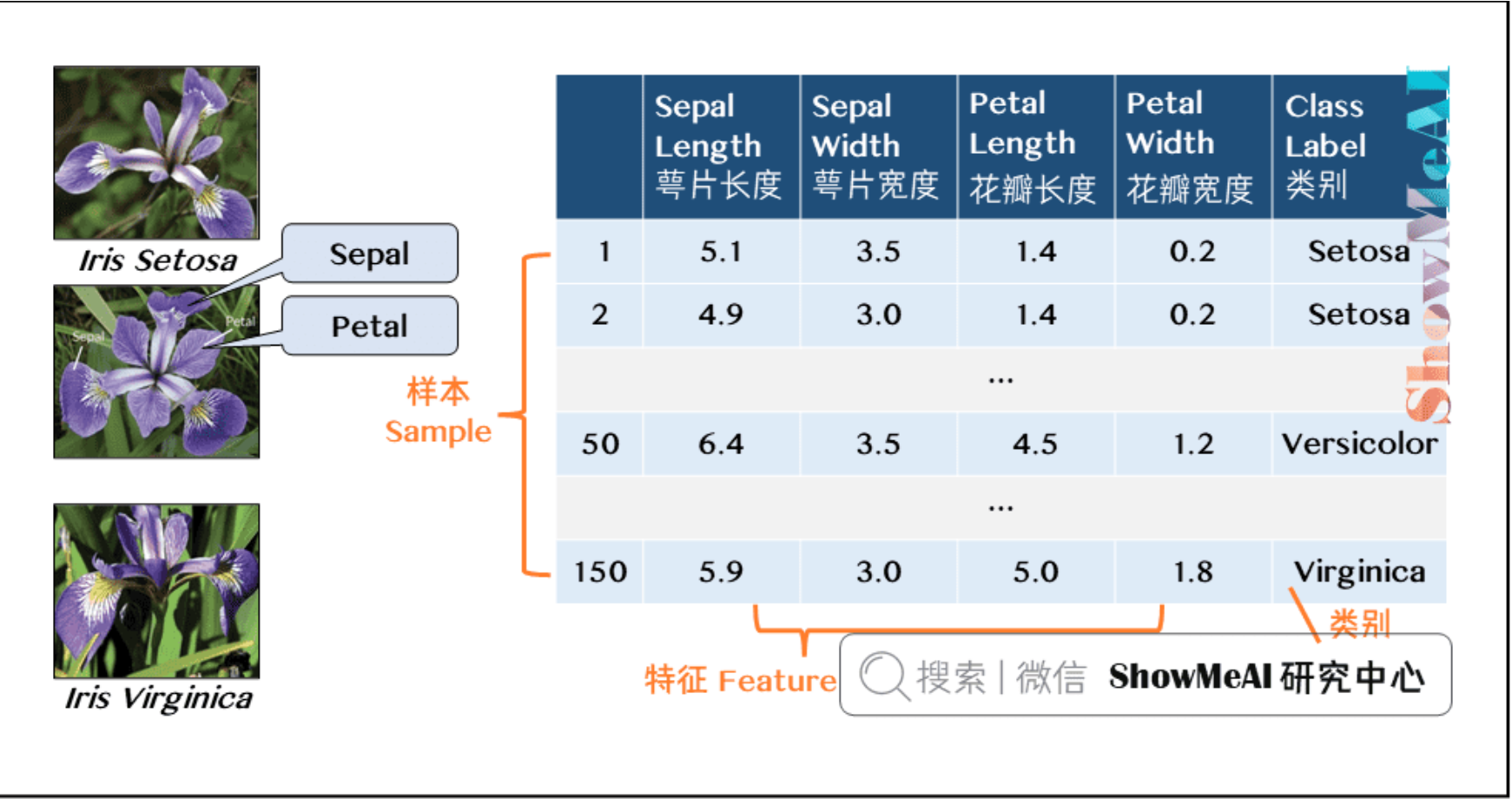
- 数据是以「字典」格式存储的
看看 iris 的键有哪些
代码:
# 导入工具库
from sklearn.datasets import load_iris
iris = load_iris()
iris.keys()
输出:
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
查看iris 数据中特征的大小、名称等信息和前五个样本
代码:
# 导入工具库
n_samples, n_features = iris.data.shape
print((n_samples, n_features))
print(iris.feature_names)
print(iris.target.shape)
print(iris.target_names)
iris.data[0:5]
输出:
(150, 4)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
(150,)
['setosa' 'versicolor' 'virginica']
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])
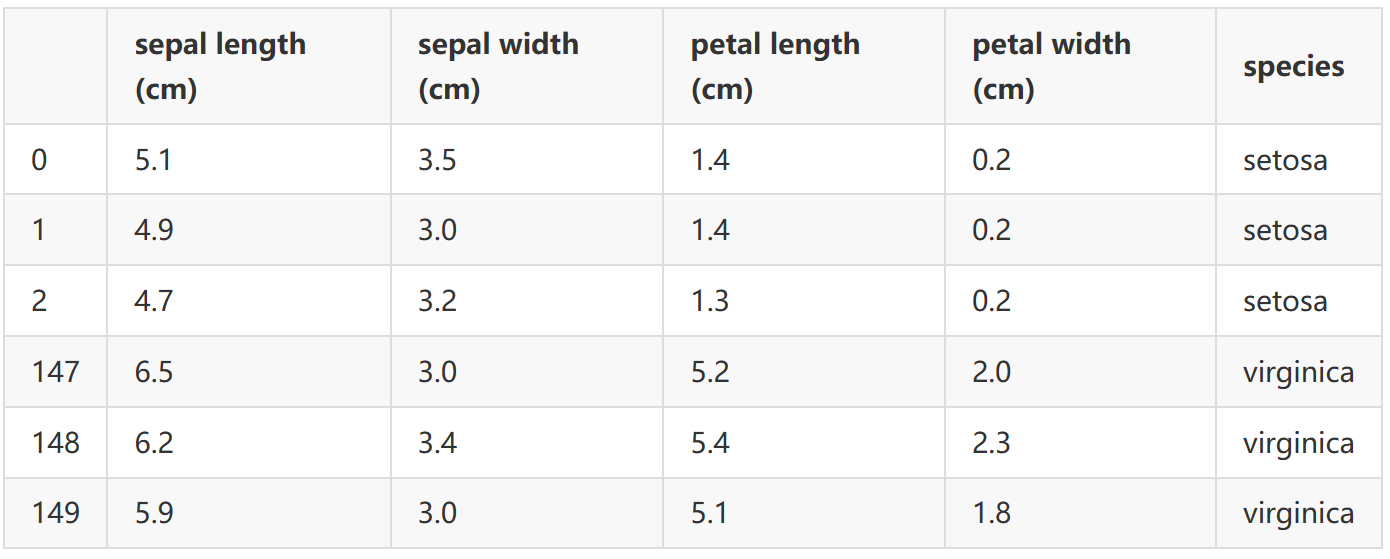
构建Dataframe格式的数据集
代码:
# 将X和y合并为Dataframe格式数据
import pandas as pd
import seaborn as sns
iris_data = pd.DataFrame( iris.data,
columns=iris.feature_names )
iris_data['species'] = iris.target_names[iris.target]
iris_data.head(3).append(iris_data.tail(3))
输出:
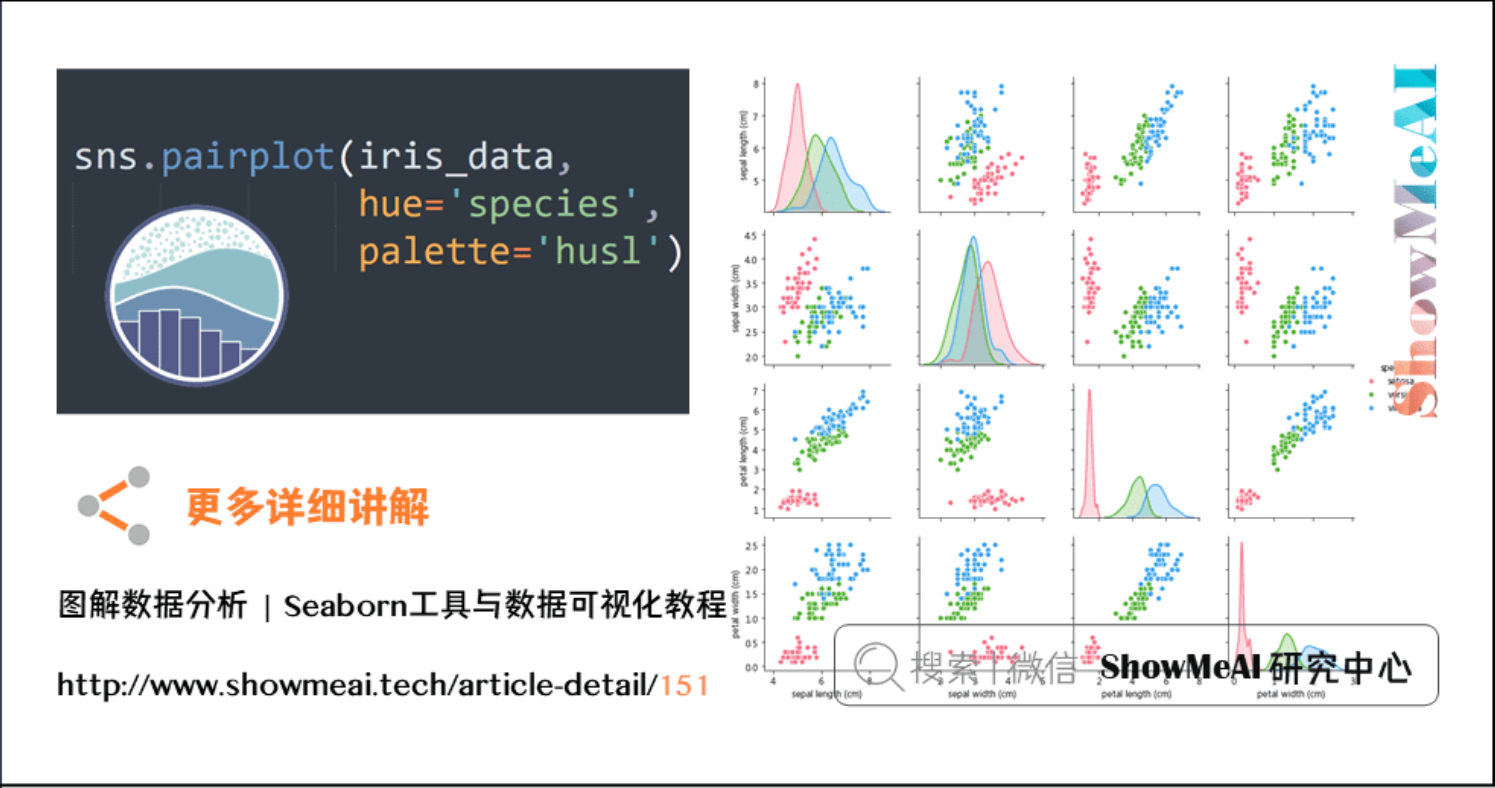
使用seaborn库来做一些数据分析
代码:
# 使用Seaborn的pairplot查看两两特征之间的关系
sns.pairplot( iris_data, hue='species', palette='husl' )
输出:
4.3 数据集引入方式
SKLearn有三种引入数据形式:
- 打包好的数据:对于小数据集,用
sklearn.datasets.load_* - 分流下载数据:对于大数据集,用
sklearn.datasets.fetch_* - 随机创建数据:为了快速展示,用
sklearn.datasets.make_*
上面这个星号*指代具体文件名。
load小数据集
代码:
#手写数字图像数据集
digits = datasets.load_digits()
digits.keys()
输出:
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
fetch大数据集
代码:
#加州房屋数据集
california_housing = datasets.fetch_california_housing()
california_housing.keys()
输出:
dict_keys(['data', 'target', 'feature_names', 'DESCR'])
5、sklearn核心API
SKLearn里万物皆估计器。估计器是个不严谨的叫法,可以视其为一个模型(用来回归、分类、聚类、降维),或一套流程(预处理、网格搜索交叉验证)。
估计器(estimator)通常是用于拟合功能的估计器。预测器(predictor)是具有预测功能的估计器。转换器(transformer)是具有转换功能的估计器。
5.1 估计器
任何可以基于数据集对一些参数进行估计的对象都被称为估计器,它有两个核心点:
- ① 需要输入数据。
- ② 可以估计参数。
估计器使用流程:
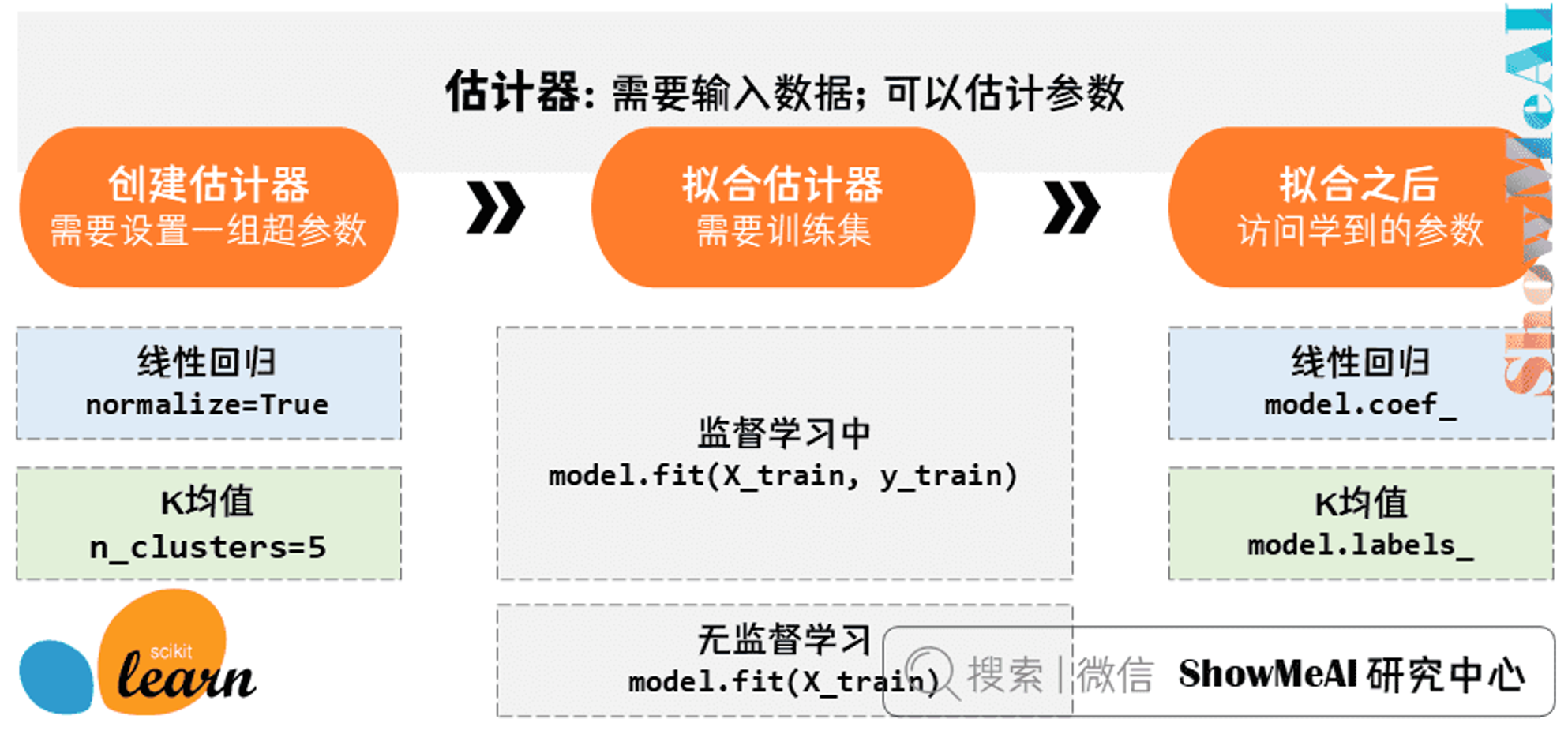
(注:拟合之后可以访问model里学到的参数,比如线性回归里的特征系数coef,或K均值里聚类标签labels。(具体的可以在SKLearn文档的每个模型页查到))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号