
SqueezeNet
虽然网络性能得到了提高,但随之而来的就是效率问题(AlexNet VGG GoogLeNet Resnet DenseNet)
效率问题主要是模型的存储问题和模型进行预测的速度问题.
Model Compression:
- 从模型权重数值角度压缩
- 从网络架构角度压缩
对于效率问题,通常的方法即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时解决速度问题。
相比于在已经训练好的模型上进行处理,轻量化模型模型设计则是另辟蹊径。轻量化模型设计主要思想在于设计更高效的「网络计算方式」(主要针对卷积方式),从而使网络参数减少的同时,不损失网络性能。
- 已训练好的模型上做裁剪 (剪枝、权值共享、量化、神经网络二值化)
- 新的卷积计算方法(SqueezeNet MobileNet ShuffleNet Xception)
一、SqueezeNet (AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size)
该网络能在保证不损失精度的同时,将原始AlexNet压缩至原来的510倍左右(< 0.5MB)。
1.1 设计思想
1.将3x3卷积核替换为1x1卷积核 (1个1x1卷积核的参数是3x3卷积核参数的1/9,这一改动理论上可以将模型尺寸压缩9倍。)
2.减小输入到3x3卷积核的输入通道数
3.尽可能将下采样放在网络后面的层中 (分辨率越大的特征图(延迟降采样)可以带来更高的分类精度,而这一观点从直觉上也可以很好理解,因为分辨率越大的输入能够提供的信息就越多.)
以上,前两个策略都是针对如何降低参数数量而设计的,最后一个旨在最大化网络精度。
1.2 网络架构
基于以上三个策略,提出了一个类似inception的网络单元结构,取名为fire module。一个fire module 包含一个squeeze 卷积层(只包含1x1卷积核)和一个expand卷积层(包含1x1和3x3卷积核)。其中,squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数。
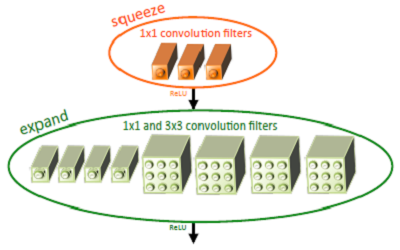
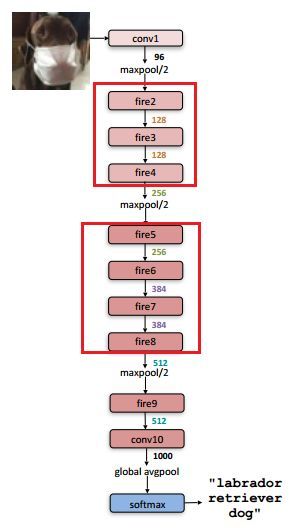
其中,定义squeeze层中1x1卷积核的数量是s1x1,类似的,expand层中1x1卷积核的数量是e1x1, 3x3卷积核的数量是e3x3。令s1x1 < e1x1+ e3x3从而保证输入到3x3的输入通道数减小。SqueezeNet的网络结构由若干个 fire module 组成,另外文章还给出了一些架构设计上的细节:
- 为了保证1x1卷积核和3x3卷积核具有相同大小的输出,3x3卷积核采用1像素的zero-padding和步长
- squeeze层和expand层均采用RELU作为激活函数
- 在fire9后采用50%的dropout
- 由于全连接层的参数数量巨大,因此借鉴NIN的思想,去除了全连接层而改用GAP
1.3 实验结果
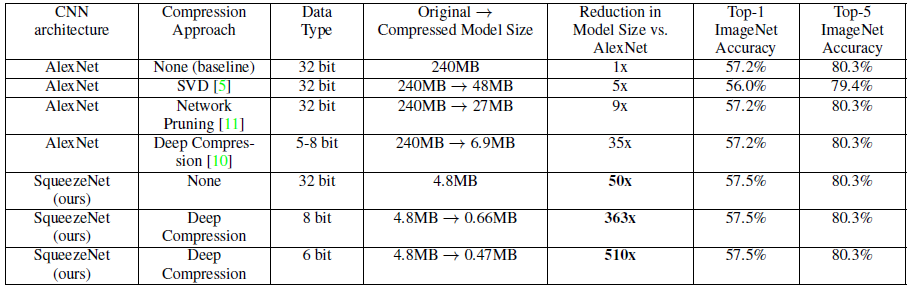
上表显示,相比传统的压缩方法,SqueezeNet能在保证精度不损(甚至略有提升)的情况下,达到最大的压缩率,将原始AlexNet从240MB压缩至4.8MB,而结合Deep Compression后更能达到0.47MB,完全满足了移动端的部署和低带宽网络的传输。
此外,作者还借鉴ResNet思想,对原始网络结构做了修改,增加了旁路分支,将分类精度提升了约3%。
1.4 速度考量
尽管文章主要以压缩模型尺寸为目标,但毋庸置疑的一点是,SqueezeNet在网络结构中大量采用1x1和3x3卷积核是有利于速度的提升的,对于类似caffe这样的深度学习框架,在卷积层的前向计算中,采用1x1卷积核可避免额外的im2col操作,而直接利用gemm进行矩阵加速运算,因此对速度的优化是有一定的作用的。然而,这种提速的作用仍然是有限的,另外,SqueezeNet采用了9个fire module和两个卷积层,因此仍需要进行大量常规卷积操作,这也是影响速度进一步提升的瓶颈。
二、Deep Compression(Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding)
改文章获得了ICLR 2016的最佳论文奖,引领了CNN模型小型化与加速研究方向的新狂潮
2.1 算法流程
"权值压缩派"
Deep Compression的算法流程包含三步:
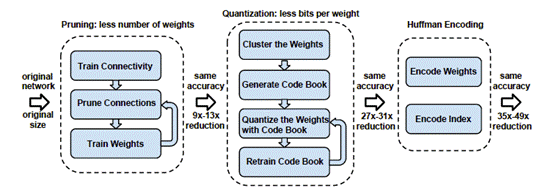
1. Pruning(权值剪枝)
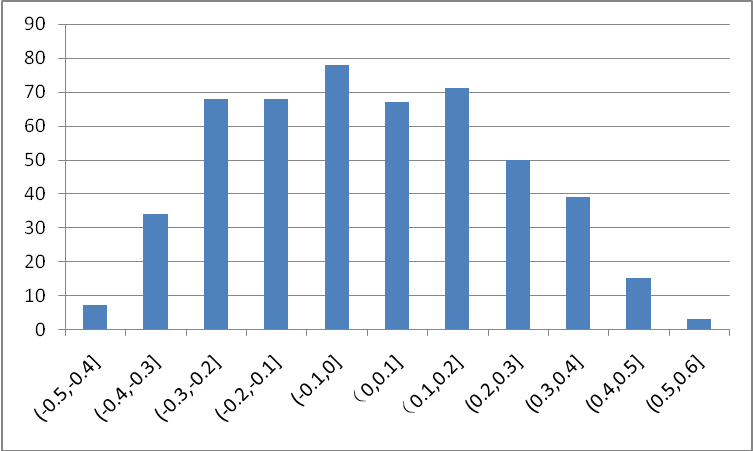
图3是MNIST上训练得到的LeNet conv1卷积层中的参数分布,可以看出,大部分权值集中在0处附近,对网络的贡献较小,在剪值中,将0值附近的较小的权值置0,使这些权值不被激活,从而着重训练剩下的非零权值,最终在保证网络精度不变的情况下达到压缩尺寸的目的。
实验发现模型对剪枝更敏感,因此在剪值时建议逐层迭代修剪,另外每层的剪枝比例如何自动选取仍然是一个值得深入研究的课题。
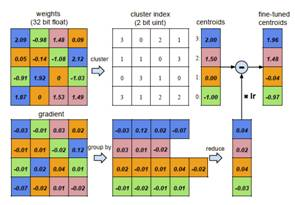
2. Quantization(权值量化)
此处的权值量化基于权值聚类,将连续分布的权值离散化,从而减小需要存储的权值数量。
初始化聚类中心,实验证明线性初始化效果最好;
利用k-means算法进行聚类,将权值划分到不同的cluster中;
在前向计算时,每个权值由其聚类中心表示;
在后向计算时,统计每个cluster中的梯度和将其反传。
3. Huffman encoding(霍夫曼编码)
霍夫曼编码采用变长编码将平均编码长度减小,进一步压缩模型尺寸。
2.2 模型存储
前述的剪枝和量化都是为了实现模型的更紧致的压缩,以实现减小模型尺寸的目的。
对于剪枝后的模型,由于每层大量参数为0,后续只需将非零值及其下标进行存储,文章中采用CSR(Compressed Sparse Row)来进行存储,这一步可以实现9x~13x的压缩率。
对于量化后的模型,每个权值都由其聚类中心表示(对于卷积层,聚类中心设为256个,对于全连接层,聚类中心设为32个),因此可以构造对应的码书和下标,大大减少了需要存储的数据量,此步能实现约3x的压缩率。
最后对上述压缩后的模型进一步采用变长霍夫曼编码,实现约1x的压缩率。
2.3 实验结果
通过SqueezeNet+Deep Compression,可以将原始240M的AlexNet压缩至0.47M,实现约510x的压缩率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号