webmagic
webmagic框架是一个java实现的爬虫框架,底层依然是Httpclient和jsoup
四大组件了解
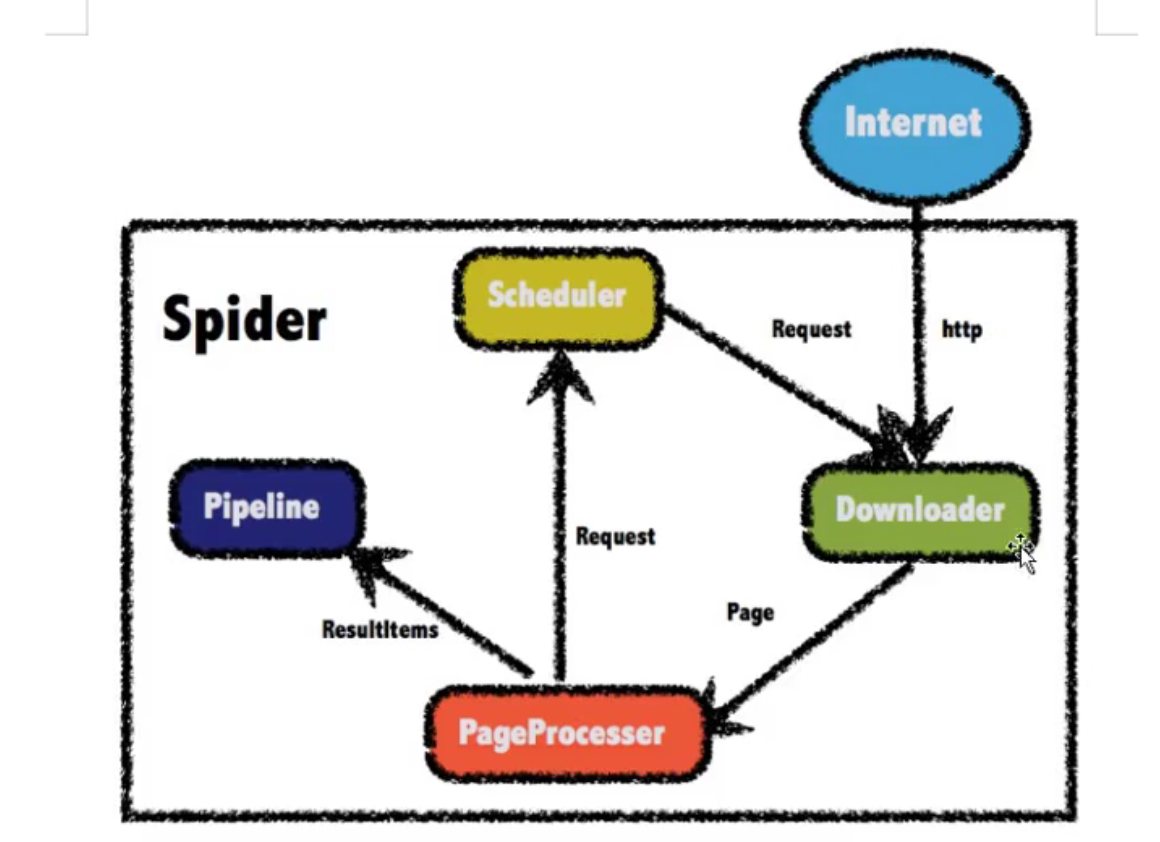
- downloader:下载器组件
- PageProcessor:页面解析组件(必须自定义)
- scheduler:访问队列组件
- pipeline:数据持久化组件(默认输出到控制台)
入门程序
流程:
导入依赖
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
主程序:除了必须自定义的webmagic外,其他均默认
/*
* pageprocessor这个组件必须要自定义
* 实现页面的业务逻辑
* */
public class MyPageProcessor implements PageProcessor {
public void process(Page page) {
//部分一:解析page
String html = page.getHtml().toString();
//部分二:把需要的东西放到ResultItems中
ResultItems resultItems = page.getResultItems();
resultItems.put("html",html);
page.putField("html2",html); //上下方法是一致的的
}
public Site getSite() {
//site:站点的意思,在site中配置抓取网站的相关配置,包括编码、抓取间隔、重试次数等
return Site.me().setRetryTimes(3).setSleepTime(1000);
}
/*
* 初始化爬虫
* */
public static void main(String[] args) {
Spider.create(new MyPageProcessor())
//设置起使url
.addUrl("http://www.itcast.cn/")
//run是同步线程,start是异步线程
.run();
}
}
一、downloader组件
下载器组件,使用HttpClient实现
如果没有特殊需求一般不需要自定义,默认的组件就可以满足全部需求
自定义需要实现DownLoader接口
向pageProcessor传递数据时,把结果封装成page对象(在PageProcess中的process方法中拿到)
二、PageProcessor组件
页面分析的业务组件,页面分析的逻辑在其中实现
需要实现PageProcessor接口
有两个方法需要实现
- public void process(Page page) {}
- public Site getSite() {}
1、site配置
对站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置。
| 方法 | 说明 | 示例 |
|---|---|---|
| setCharset(String) | 设置编码 | site.setCharset("utf-8") |
| setUserAgent(String) | 设置UserAgent | site.setUserAgent("Spider") |
| setTimeOut(int) | 设置超时时间,单位是毫秒 | site.setTimeOut(3000) |
| setRetryTimes(int) | 设置重试次数 | site.setRetryTimes(3) |
| setCycleRetryTimes(int) | 设置循环重试次数 | site.setCycleRetryTimes(3) |
| addCookie(String,String) | 添加一条cookie | site.addCookie("dotcomt_user","code4craft") |
| setDomain(String) | 设置域名,需设置域名后,addCookie才可生效 | site.setDomain("github.com") |
| addHeader(String,String) | 添加一条addHeader | site.addHeader("Referer","https://github.com") |
| setHttpProxy(HttpHost) | 设置Http代理 | site.setHttpProxy(new HttpHost("127.0.0.1",8080)) |
其中循环重试cycleRetry是0.3.0版本加入的机制。
该机制会将下载失败的url重新放入队列尾部重试,直到达到重试次数,以保证不因为某些网络原因漏抓页面。
2、page解析页面
几个重要方法
- getHtml():返回抓取的结果(得到的Html对象在后面的解析中学到)
- getResultItems():返回ResultItem对象,向pipeline中传递数据时使用
- addTargetRequest(),addTargetRequests():向scheduler对象中添加url
3、ResultItems传递结果
作用:把获取到的结果传递给pipeline对象
通过page.getResultItems()获取到ResultItems对象
本身其实就是一个map
源码
public class ResultItems {
private Map<String, Object> fields = new LinkedHashMap<String, Object>();
...
}
4、Request传递url
并不是Http请求的Resuest,而是把url封装好的Request对象
可以添加一个也可以添加多个
三、pipeline组件
数据持久化组件
框架提供三个实现
- ConsolePipeline:向控制台输出,默认使用
- FilePipeline:向磁盘文件输出
- JsonFilePipeline:保存json格式的文件
磁盘文件pipeline
要求:获取到网站的全部页面
public class MyPageProcessor implements PageProcessor {
public void process(Page page) {
//获取html对象
Html html = page.getHtml();
List<String> all_links = html.css("a", "href").all();
page.addTargetRequests(all_links);
page.putField("html",html.get());
}
public Site getSite() {
return Site.me();
}
public static void main(String[] args) {
//创建一个磁盘保存的pipeline
FilePipeline filePipeline = new FilePipeline();
filePipeline.setPath("C:\\Users\\86186\\Desktop\\webmagic\\html");
//初始化爬虫
Spider.create(new MyPageProcessor())
.addUrl("http://www.itcast.cn")
.addPipeline(filePipeline)
.run();
}
}
自定义pipeline
官网教学:
http://webmagic.io/docs/zh/posts/ch6-custom-componenet/pipeline.html
需要实现pipeline接口
在自定义pipeline中一般要做的就是数据库持久化
四、Scheduler组件
http://webmagic.io/docs/zh/posts/ch6-custom-componenet/scheduler.html
访问url队列
默认使用内存队列
但如果需要使用其他储存的方式来储存url队列,参考:
| 类 | 说明 | 备注 |
|---|---|---|
| DuplicateRemovedScheduler | 抽象基类,提供一些模板方法 | 继承它可以实现自己的功能 |
| QueueScheduler | 使用内存队列保存待抓取URL | |
| PriorityScheduler | 使用带有优先级的内存队列保存待抓取URL | 耗费内存较QueueScheduler更大,但是当设置了request.priority之后,只能使用PriorityScheduler才可使优先级生效 |
| FileCacheQueueScheduler | 使用文件保存抓取URL,可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取 | 需指定路径,会建立.urls.txt和.cursor.txt两个文件 |
| RedisScheduler | 使用Redis保存抓取队列,可进行多台机器同时合作抓取 | 需要安装并启动redis |
去重方案
- hashset进行去重
- 在内存中去重处理,需要占用大量的内存
- 规模大时应该使用redis去重
- 使用redis成本高
- 使用布隆过滤器进行去重
- 优点:占内存小,速度快,成本低
- 缺点:有可能误判
(使用布隆过滤器)流程:
导入依赖:
<!--布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
初始化spider时创建页面
public static void main(String[] args) {
//创建一个磁盘保存的pipeline
FilePipeline filePipeline = new FilePipeline();
filePipeline.setPath("C:\\Users\\86186\\Desktop\\webmagic\\html");
//创建基于内存的scheduler
QueueScheduler scheduler = new QueueScheduler();
//给scheduler添加布隆过滤器,设置大概应该有的数据有10000000
scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(10000000));
//初始化爬虫
Spider.create(new MyPageProcessor())
.addUrl("http://www.itcast.cn")
.setScheduler(scheduler)
.addPipeline(filePipeline)
.run();
}
解析页面(Html对象)
html页面也是一个Selectable节点
一个Selectable节点又相当于一个dom节点
三种解析方式
- 原生jsoup
- css选择器解析
- Xpath解析
1、jsoup解析
public void process(Page page) {
//获取jsoup独特的document对象
Document document = page.getHtml().getDocument();
//使用jsoup的api解析
String title = document.getElementsByTag("title").text();
page.putField("title",title);
}
2、css选择器解析
两个方法
- html.css("选择器",[属性])
- html.$("选择器",[属性])
public void process(Page page) {
//获取html页面对象
Html html = page.getHtml();
//使用css解析页面得到dom节点
// Selectable innr = html.css("div.innr p");
Selectable innr = html.css("div.innr p","text");
//获取文本信息
String innr_text = innr.toString();//用get()也可
page.putField("innr",innr_text);
}
Selectable对象使用get方法或者toString方法获取文本信息,但不做处理只能得到第一个dom对象
使用all()方法就可以获取到全部的dom对象
public void process(Page page) {
//获取html页面对象
Html html = page.getHtml();
//使用css解析页面得到dom节点
List<String> all_p = html.css("p", "text").all();
//获取文本信息
page.putField("innr",all_p);
}
3、Xpath解析
语法:
public void process(Page page) {
//获取html对象
Html html = page.getHtml();
//表示获取innr标签div下的p标签的text文本,前面的//表示不一定从根结点开始
Selectable innr = html.xpath("//div[@class=innr]/p/text()");
page.putField("innr",innr.get());
}
spider工具类
Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。
| 方法 | 说明 | 示例 |
|---|---|---|
| create(PageProcessor) | 创建Spider | Spider.create(new GithubRepoProcessor()) |
| addUrl(String…) | 添加初始的URL | spider .addUrl("http://webmagic.io/docs/") |
| addRequest(Request...) | 添加初始的Request | spider .addRequest("http://webmagic.io/docs/") |
| thread(n) | 开启n个线程 | spider.thread(5) |
| run() | 启动,会阻塞当前线程执行 | spider.run() |
| start()/runAsync() | 异步启动,当前线程继续执行 | spider.start() |
| stop() | 停止爬虫 | spider.stop() |
| test(String) | 抓取一个页面进行测试 | spider .test("http://webmagic.io/docs/") |
| addPipeline(Pipeline) | 添加一个Pipeline,一个Spider可以有多个Pipeline | spider .addPipeline(new ConsolePipeline()) |
| setScheduler(Scheduler) | 设置Scheduler,一个Spider只能有个一个Scheduler | spider.setScheduler(new RedisScheduler()) |
| setDownloader(Downloader) | 设置Downloader,一个Spider只能有个一个Downloader | spider .setDownloader(new SeleniumDownloader()) |
| get(String) | 同步调用,并直接取得结果 | ResultItems result = spider .get("http://webmagic.io/docs/") |
| getAll(String…) | 同步调用,并直接取得一堆结果 | List |
实战测试
爬取一个单词站点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号