Pytorch训练时GPU占用率低0%
问题描述
最近在做毕业设计的论文,训练CNN的时候用nvidia-smi命令查看显卡占用率的时候发现一个事:
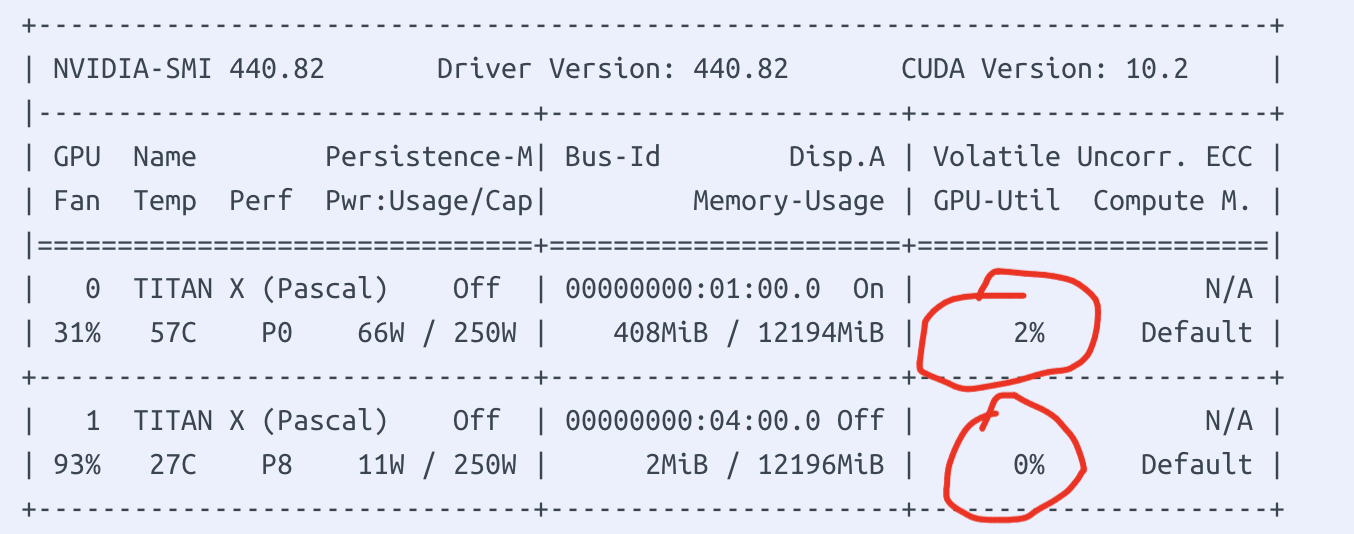
显存占用上去了,但是GPU利用率一直为0%或者频繁跳动(图来自网络)
数据集用的1万张图,7000左右拿来训练,用resnet-18网络,图resize成112*112的灰度图,GPU-A4000。训练一个epoch大概30S......
dataloader部分的解决方法
- 增加dataloader的num_num_workers数量(这个函数应放在main函数里执行,不然会报错)。一般设置为与CPU核心数相同的(这条建议我是从租GPU的网站看到的),不过设置过高并没有用反而性能降低。可以从2,4,6....这样的逐步增加,看看多少合适
train_loader = data.DataLoader(dataset=train_dataset,
batch_size=512,
shuffle=False, num_workers=6)
2.修改dataloader的prefetch_factor(pytorch版本1.7以上的新特性,我用的Pytorch-1.8.1可以使用),default=2,表示有2 * num_workers样本会被提前取出
train_loader = data.DataLoader(dataset=train_dataset,batch_size=512,
num_workers=6,prefetch_factor=4)
3.设置dataloader的persistent_workers。如果为True表示dataset被使用后进程不会被关闭,会一直保持
train_loader = data.DataLoader(dataset=train_dataset,batch_size=512,
num_workers=6,prefetch_factor=4,
persistent_workers=True
)
上述部分的解释可能与pytorch官方文档有一些出入,详细可以见:https://pytorch.org/docs/stable/data.html
从数据集本身
一般的数据读取方法
- 从csv等等文件读取注释信息。以分类任务为例:有图片的路径,和要分类的结果。(img:/root/path/苹果.jpg label:'apple'这样的格式)
- 根据注释的path用cv2,PIL等库对图片读取。以PIL读取为例
from PIL import Image
Image.open(img_path).convert("L")
3.在dataset里使用的时候,读取注释path,转换label为数字
def __getitem__(self, index):
'Generates one sample of data'
img_path = 根据index从csv文件获取路径
label = 根据index从csv文件获取标签
X = Image.open(img_path).convert("L")
y = torch.tensor(label)
return X, y
==========》这样写是很普遍的用法,如果用SSD读取还好,SSD的速度很快。但是!!我租GPU的网站硬盘是机械的,这就导致我大量的时间都耗费在IO上了
但是租GPU的网站有个好处-------->大内存,那么就可以考虑先把所有图片加载到内存中,然后直接映射读取,这样就解决了IO问题
解决方法
1.根据csv读取img_path,label信息
2.把图片和标签存入一个文件,这里我存入npy文件
3.在dataset初始化时直接读取npy文件,就加载到内存中------>后续从npy文件获取数据即可
4.npy文件的shape为[1000, 2] 1000行2列的矩阵
对于每一行元素 npy[i, 0]第一列表示img(注意是img,而不是img_path),npy[i, 1]第二列表示label
部分代码如下
ls = []
for line_index, line in df.iterrows():
img_path = line.path
val = line.cell_type_idx
img_path = line.path
# 读图片 灰度处理 方法缩小
temp_img = Image.open(img_path).convert("L")
temp_img = temp_img.resize([conf.IMAGE_WIDTH, conf.IMAGE_HEIGHT])
temp_img = np.array(temp_img)
# 存入npy
ls.append([temp_img, val])
npy_file = np.array(ls)
np.save("/root/test.npy" (这个参数是你要存npy文件的地方), arr=npy_file (这个参数是需要保存的npy是什么))
在dataset中,初始化时就读取这个npy文件
class MyDataset(data.Dataset):
'Characterizes a dataset for PyTorch'
def __init__(self, train_type):
'Initialization'
train_npy ="/root/test.npy"
train_npy = np.load(train_npy,allow_pickle=True)
self.df = train_npy
def __len__(self):
'Denotes the total number of samples'
return self.df.shape[0]
def __getitem__(self, index):
'Generates one sample of data'
X = self.df[index, 0]
X = np.array(X)
y = torch.tensor(int(self.df[index, 1]))
return X, y
最终效果
最初一个epoch:30s 现在一个epoch5s (进步巨大)
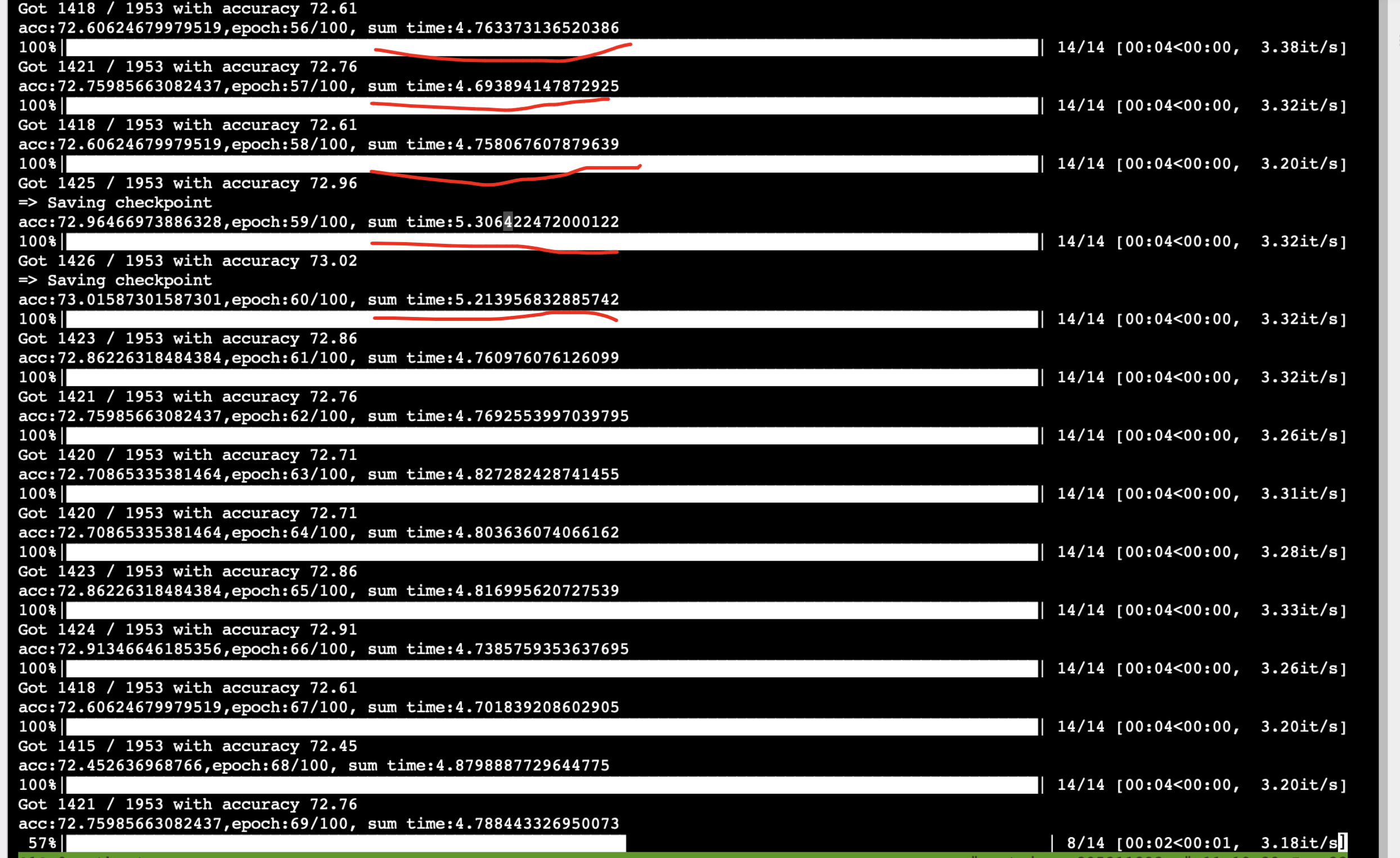
同时GPU占用也上去了
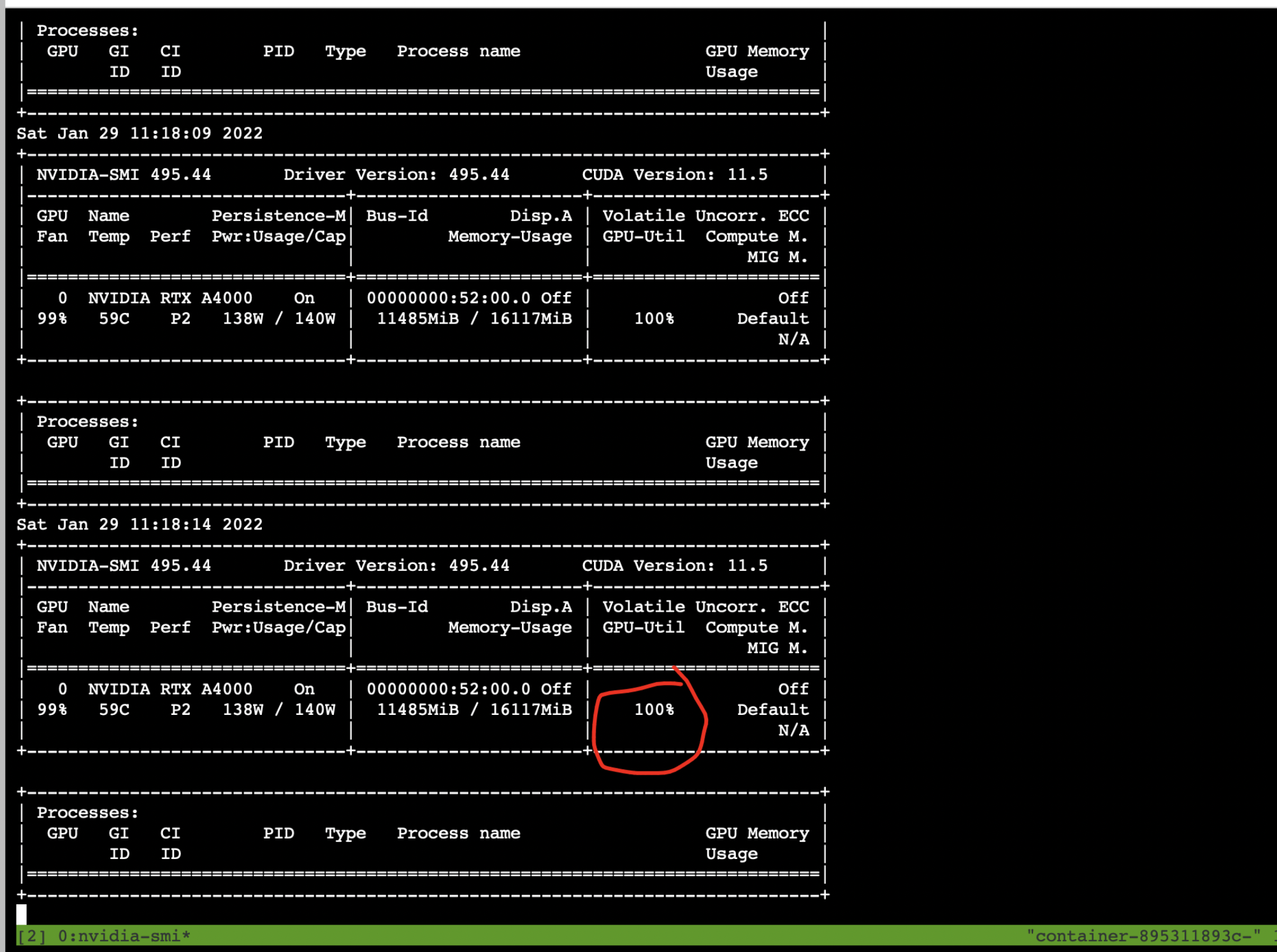
最后再加一个小技巧
让远程服务器的Nvidia-smi命令自动刷新结果 就不用每次都输入命令手动查看了
进入tmux等
nvidia-smi -l

 浙公网安备 33010602011771号
浙公网安备 33010602011771号