
Python解析博客园备份的XML文件
准备搭建自己的博客网站,想把在博客园写的内容都保存下来。
-
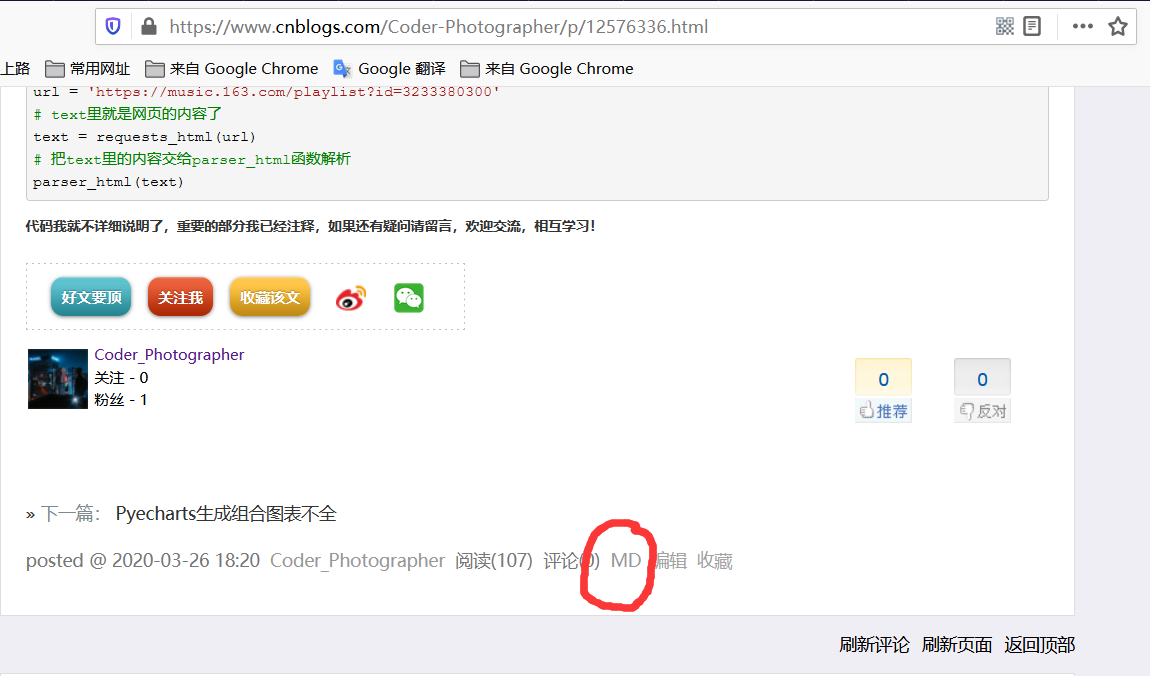
方法1:爬虫,模拟请求自己的每个文章,在页面最下面有
MD按钮,点击会下载markdown的源文件。但是这个不包含日期等信息,只有源文件
![]()
-
方法2:通过解析博客园提供的备份文件,获取内容,时间等信息。这个页面在每个人的文章管理页面
![]()

下载XML文件观察其数据内容
- 下载获取到的文件
![]()
- 通过软件
xmlmarker对文件结构进行可视化
![]()
- 画线的地方就是包含的每篇博客的信息,而对于每个item。其数据结构如下:
![]()
- 所以我们需要做的:利用Python读XML文件,遍历item:在item中获取
title,date,description等信息



代码部分
- 使用Python读文件
from xml.dom.minidom import parse
# xml的文件名
domTree = parse("./CNBlogs_BlogBackup_131_202003_202101.xml")
# 获取root节点
rootNode = domTree.documentElement
- 获取items的集合
items = rootNode.getElementsByTagName("item")
- 遍历item,获取date,description等信息
auther = item.getElementsByTagName("author")[0].childNodes[0].data
title = item.getElementsByTagName("title")[0].childNodes[0].data
# 注意这里的date获取的是GMT格式的时间,例如:Thu, 26 Mar 2020 10:31:00 GMT
date = item.getElementsByTagName("pubDate")[0].childNodes[0].data
content = item.getElementsByTagName("description")[0].childNodes[0].data
- 对时间数据进行修改:GMT格式转标准格式
# original 就是GMT格式的时间
# gmtFormat 用来匹配GMT时间的格式,%a这些字符怎么来可以看注释1
def convertTime(original):
gmtFormat = "%a, %d %b %Y %H:%M:%S GMT"
# 格式化后 强制转为字符串,把':'替换为'-' 因为直接创建带字符':'的文件会报错
return str(datetime.strptime(original, gmtFormat)).replace(':', '~')
- 保存内容
# 这里可以按自己的需要修改部分代码,我只需要作者,时间,标题,内容的字段
# 用文件名保存作者,时间,标题的内容。`作者_标题_时间.md`例如:`Coder_Photographer_Django后端实现基于ajax的pyecharts动态加载_2020-06-06 14~03~00.md`
# 文件的内容就是写的博客
mdFileName = r"{}{}_{}_{}.md".format(baseFolderPath, auther, title, date)
# 如果该文件已存在,覆盖写该文件
if os.path.exists(mdFileName):
f = open(mdFileName, 'w+', encoding='utf-8')
# 如果该文件不存在,追加写该文件
else:
f = open(mdFileName, 'a+', encoding='utf-8')
f.write(content)
- 注释1
解析模板= "%a, %d %b %Y %H:%M:%S GMT"
待解析的数据="Thu, 26 Mar 2020 10:31:00 GMT"
其实就是把数据字段匹配,可以参考下面的对应起来
'''
%a 本地的星期缩写
%A 本地的星期全称
%b 本地的月份缩写
%B 本地的月份全称
%c 本地的合适的日期和时间表示形式
%d 月份中的第几天,类型为decimal number(10进制数字),范围[01,31]
%f 微秒,类型为decimal number,范围[0,999999],Python 2.6新增
%H 小时(24进制),类型为decimal number,范围[00,23]
%I 小时(12进制),类型为decimal number,范围[01,12]
%j 一年中的第几天,类型为decimal number,范围[001,366]
%m 月份,类型为decimal number,范围[01,12]
%M 分钟,类型为decimal number,范围[00,59]
%p 本地的上午或下午的表示(AM或PM),只当设置为%I(12进制)时才有效
%S 秒钟,类型为decimal number,范围[00,61](60和61是为了处理闰秒)
%U 一年中的第几周(以星期日为一周的开始),类型为decimal number,范围[00,53]。在度过新年时,直到一周的全部7天都在该年中时,才计算为第0周。只当指定了年份才有效。
%w 星期,类型为decimal number,范围[0,6],0为星期日
%W 一年中的第几周(以星期一为一周的开始),类型为decimal number,范围[00,53]。在度过新年时,直到一周的全部7天都在该年中时,才计算为第0周。只当指定了年份才有效。
%x 本地的合适的日期表示形式
%X 本地的合适的时间表示形式
%y 去掉世纪的年份数,类型为decimal number,范围[00,99]
%Y 带有世纪的年份数,类型为decimal number
%Z 时区名字(不存在时区时为空)
%% 代表转义的"%"字符
'''
完整代码
from datetime import datetime
import sys
from xml.dom.minidom import parse
import os
def createFolder():
if os.path.isdir(baseFolderPath):
print("路径:{},已有文件夹。程序将MD文件写入该文件夹".format(baseFolderPath))
return True
try:
os.mkdir(baseFolderPath)
print("已新建名为:" + baseFolderPath + "的文件夹")
return True
except Exception as e:
print("请检查文件:", baseFolderPath)
return False
# GMT时间转datetime
# original 就是GMT格式的时间
# gmtFormat 用来匹配GMT时间的格式,%a这些字符怎么来可以看注释1
def convertTime(original):
gmtFormat = "%a, %d %b %Y %H:%M:%S GMT"
# 格式化后 强制转为字符串,把':'替换为'-' 因为直接创建带':'的文件会报错
return str(datetime.strptime(original, gmtFormat)).replace(':', '~')
def parserXML():
# xml的文件名
domTree = parse(xmlPath)
# 文档根元素
rootNode = domTree.documentElement
# 所有文章
items = rootNode.getElementsByTagName("item")
for item in items:
auther = item.getElementsByTagName("author")[0].childNodes[0].data
title = item.getElementsByTagName("title")[0].childNodes[0].data
date = item.getElementsByTagName("pubDate")[0].childNodes[0].data
date = convertTime(date)
# date = date[3] + '~' + date[2] + '~' + date[1]
html = item.getElementsByTagName("guid")[0].childNodes[0].data
content = item.getElementsByTagName("description")[0].childNodes[0].data
mdFileName = r"{}{}_{}_{}.md".format(baseFolderPath, auther, title, date)
# 如果该文件已存在,覆盖写该文件
if os.path.exists(mdFileName):
f = open(mdFileName, 'w+', encoding='utf-8')
else:
f = open(mdFileName, 'a+', encoding='utf-8')
f.write(content)
print(mdFileName + "文件已生成")
# 保存md文件的文件夹路径
baseFolderPath = "./parserResult/"
# 需要解析的xml路径
xmlPath = "./CNBlogs_BlogBackup_131_202003_202101.xml"
if __name__ == '__main__':
if not createFolder():
print("创建文件夹程序出错")
sys.exit(-1)
else:
parserXML()
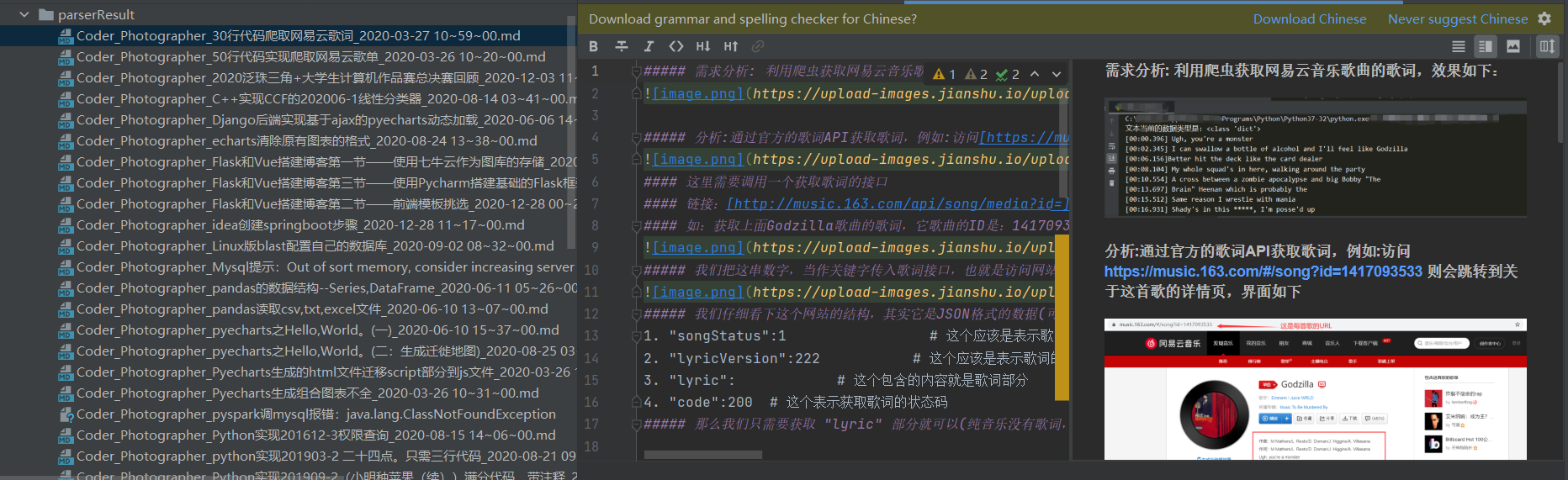
执行结果
- 在当前文件的
parserResult文件夹下保存对应的md文件
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号