
基于图像处理和tensorflow实现GTA5的车辆自动驾驶——第十节平衡数据
在上节我们实现了生成一个训练集,数据的预处理十分重要,我们使用Python库看看这个数据集的结构
shape
import pandas as pd
train_data = np.load('test.npy', allow_pickle=True)
df = pd.DataFrame(train_data)
print(df.shape)
# 如果没修改前一节的代码,这里的结果应该是 (2000,2)
查看按键列数据是否平衡,即左转次数右转次数直线次数
print(df[1].value_counts())
结果: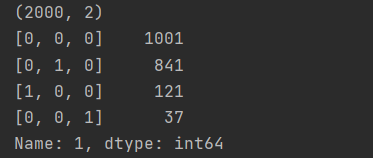
注:数据偏移量好大,如果出现这么大偏移可以多跑一次,找转弯比较多的地方跑。也可以修改main.py的源代码if len(training_data) % 2000 == 0: 修改这一行的2000为5000,这样会记录5000帧的数据集。
结果: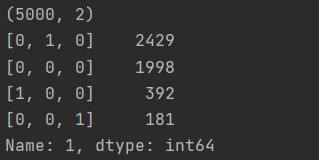
对不同的按键列数据进行分类
# 数据集
lefts = []
rights = []
forwards = []
# 遍历5000帧的数据
for data in train_data:
img = data[0]
choice = data[1]
if choice == [1, 0, 0]:
lefts.append(data)
if choice == [0, 1, 0]:
forwards.append(data)
if choice == [0, 0, 1]:
rights.append(data)
选择最小的数据集的len作为整个数据的大小
# 切分数据集
forwards = forwards[:len(lefts)][:len(rights)]
lefts = lefts[:len(forwards)]
rights = rights[:len(forwards)]
整合数据,打乱数据并保存
# add 数据集
final_data = forwards + lefts + rights
# 打乱数据
shuffle(final_data)
print(final_data)
# save data
np.save("test_train_data.npy", final_data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号