
GCC编译环境中文乱码解决方案
https://blog.csdn.net/mylibs/article/details/27913281
展开
在编译参数中增加以下两条指令:
-fexec-charset=gbk
-finput-charset=gbk
原因简单分析:Windows(中文)默认的字符集是Windows-936(GBK),而GCC编译器默认编译的时候是按照UTF-8解析的,当未指定字符集时一律当作UTF-8进行处理,于是造成乱码
https://www.cnblogs.com/dan-jacky/p/6565986.html
g++编译后中文显示乱码解决方案
环境:Windows 10 专业版
GCC版本:5.3.0
测试代码:

1 #include <iostream>
2 using namespace std;
3
4 int main(int argc, char const *argv[])
5 {
6 cout << "你好。" << endl;
7 return 0;
8 }
编译执行后发现,中文不能正确显示出来。

用记事本打开文件,然后【另存为】
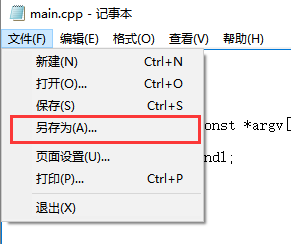
发现文件编码方式是UTF-8,修改成ANSI。继续编译执行,发现中文可以准确显示了。

我们把文件修改为UTF-8的编码方式,用一下命令编译执行,发现中文也可以准确显示了。
g++ -fexec-charset=GBK main.cpp -o main.exe && main.exe

-fexec-charset=charset,此选项指定窄字符或窄字符串的字面值常量的内部编码方式,默认为UTF-8。例如指定此选项为GBK,则窄字符或窄字符串常量将会以GBK编码方式存储而不是默认的UTF-8编码方式。
实际测试utf-8 可行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号