keil mdk+stm32的ac5和 ac6两个编译器下的字节对齐操作方法
最近在使用ac6.9的编译器,编译速度是真的很快,使用stm32的hal库编译速度也比ac5的编译器快很多。
本文试验stm32中字节对齐的代码测试,主要是结构体,因为结构体中实际项目中用到最多,同时在仿真环境中打印出来。
ac5的测试结果:
#ifdef CC_ARM_AC5
//该方式只是使用ac5编译器,结构体不对齐的方式1,结构体的长度,就是各个变量长度的和
__packed typedef struct _li_st
{
uint8_t a; //1个
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}li_st;
//ac5编译器的结构体不对齐的方式2,结构体的长度,就是各个变量长度的和
typedef struct _li_st_2
{
uint8_t a; //1个
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}__attribute__((__packed__)) li_st_2;
//)到4字节,同样可指定对齐到8字节。
typedef struct student_4B
{
char name[7]; //7+1=8
uint32_t id; //4
char subject[5]; //5+3=8
} __attribute__((aligned(4))) li_st_4B;
#pragma pack (1) /*指定按1字节对齐方式3*/
typedef struct _li_st_1B
{
uint8_t a; //1个
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}li_st_1B;
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (2) /*指定按2字节对齐*/
typedef struct _li_st_2B
{
char b;
int a;
short c;
}li_st_2B;
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
测试结果如下:
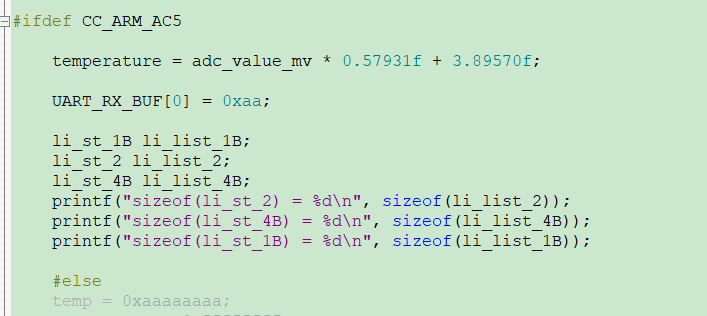
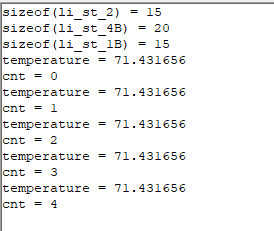
ac6的测试结果:
#elif (CC_ARM_AC6)
//ac6 ac5通用,的结构体不对齐方式,结构体的长度,就是各个变量长度的和
typedef struct _li_st_ac6
{
uint8_t a; //1个
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}__attribute__((packed)) li_st_ac6 ;
//ac6 ac5通用,的结构体不对齐方式2,结构体的长度,就是各个变量长度的和
#pragma pack (1) /*指定按1字节对齐*/
typedef struct _li_st_ac6_1B
{
uint8_t a; //1个
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}li_st_ac6_1B;
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
//ac6 ac5通用,下面的定义和8字节一样的大小,主要看内存分布
#pragma pack (4) /*指定按4字节对齐*/
typedef struct _li_st_ac6_4B
{
uint8_t a; //1个 + 1
uint16_t b; //2个
uint32_t c; //4个
uint64_t d; //8个
}li_st_ac6_4B;
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
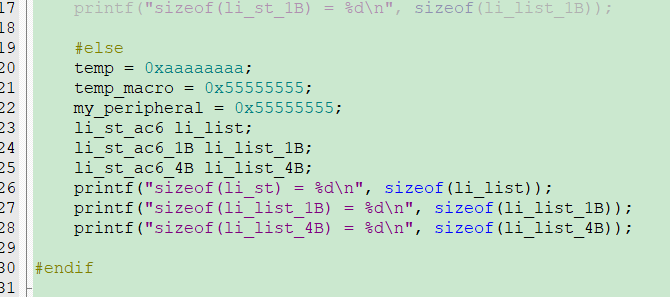
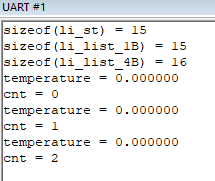

 浙公网安备 33010602011771号
浙公网安备 33010602011771号