大小端的另一种测试方法
为何会出现大小端之分:
这是因为在计算机系统中,我们是以字节为单位的,
每个地址单元都对应着一个字节,一个字节为8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),
另外,对于位数大于8位的处理器,例如16位或者32位的处理器,
由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。
因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,
那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,
0x22放在高地址中,即0x0011中。小端模式,刚好相反。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式。
很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
存储模式:
小端:较高的有效字节存储在较高的存储器地址,较低的有效字节存储在较低的存储器地址。
大端:较高的有效字节存储在较低的存储器地址,较低的有效字节存储在较高的存储器地址。
STM32 属于小端模式,简单地说:比如:temp=0X12345678;假设temp的地址为:0X4000 0000
那么,在内存里面,其存储就变成了:
| 地址 | HEX |
|0X4000 0000 |78 56 43 12|
更为简单一点:
低地址---------->高地址【大端模式】:
0X12|0X34|0X56|0X78|
低地址---------->高地址【小端模式】:
0X78|0X56|0X34|0X12|
大端与小端的优势
二者无所谓优势,无所谓劣势,各自优势便是对方劣势
大端模式:符号位的判定固定为第一个字节,容易判断正负。
小端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样
数组在大端小端情况下的存储:
以unsigned int value = 0x12345678为例,
分别看看在两种字节序下其存储情况,
我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下:
高地址
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
低地址
Little-Endian: 低地址存放低位,如下:
高地址
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
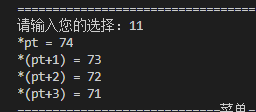
/* x86大小端测试 */
void test11(void)
{
unsigned int ui_val = 0x71727374;
unsigned char *pt=&ui_val;
printf("*pt = %x\n",*pt);
printf("*(pt+1) = %x\n",*(pt+1));
printf("*(pt+2) = %x\n",*(pt+2));
printf("*(pt+3) = %x\n",*(pt+3));
}
实际测试如下:
字节序:【一般操作系统都是小端,而通讯协议是大端的】
常见CPU字节序:
Big Endian : PowerPC、IBM、Sun
Little Endian : x86、DEC
ARM既可以工作在大端模式,也可以工作在小端模式
常见文件的字节序
Adobe PS – Big Endian
BMP – Little Endian
DXF(AutoCAD) – Variable
GIF – Little Endian
JPEG – Big Endian
MacPaint – Big Endian
RTF – Little Endian
另外,Java和所有的网络通讯协议都是使用Big-Endian的编码
对于CPU是大端还是小段,可使用代码来进行测试:
//CPU大小端
//0,小端模式;1,大端模式.
static u8 cpu_endian;
//获取CPU大小端模式,结果保存在cpu_endian里面
void find_cpu_endian(void)
{
int x=1;
if(*(char*)&x==1)cpu_endian=0; //小端模式
elsecpu_endian=1; //大端模式
}
以上测试,在STM32上,你会得到cpu_endian=0,也就是小端模式.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号