摘要: 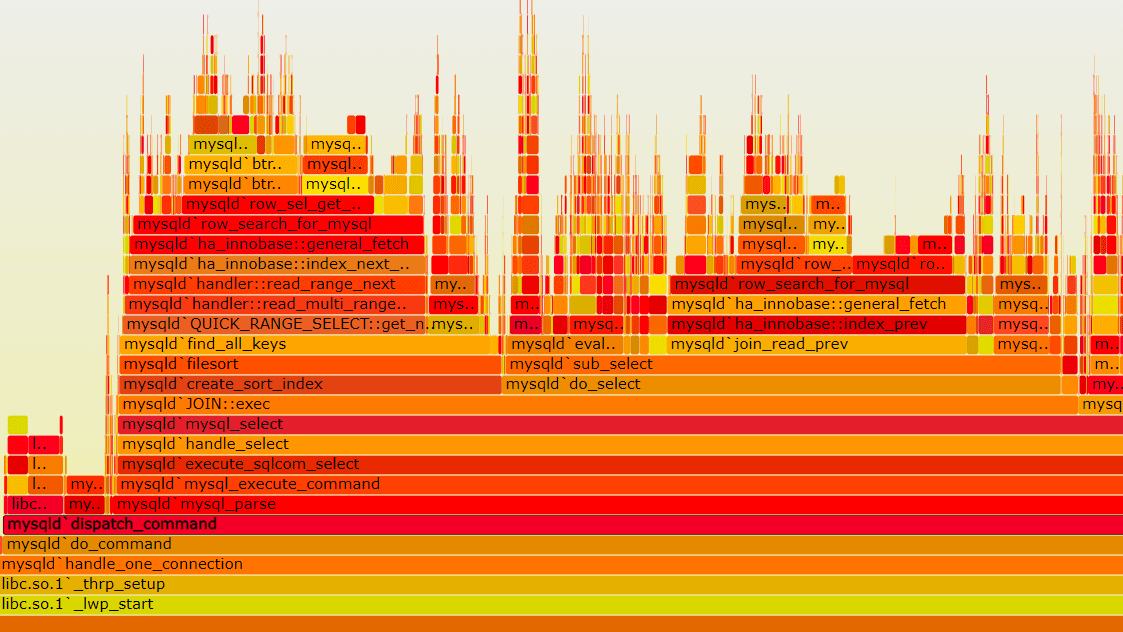 一、基本用法 首先看 Profiler 的用法: with ms.Profiler() as profiler: # .... 用户代码 print("Tuning Time:") print(profiler.table()) 二、前端接口设计 其中 Profiler 类的设计是绑定和映射到了 C 阅读全文
一、基本用法 首先看 Profiler 的用法: with ms.Profiler() as profiler: # .... 用户代码 print("Tuning Time:") print(profiler.table()) 二、前端接口设计 其中 Profiler 类的设计是绑定和映射到了 C 阅读全文
一、基本用法 首先看 Profiler 的用法: with ms.Profiler() as profiler: # .... 用户代码 print("Tuning Time:") print(profiler.table()) 二、前端接口设计 其中 Profiler 类的设计是绑定和映射到了 C 阅读全文
posted @ 2023-05-06 09:50
Aurelius84
阅读(308)
评论(0)
推荐(0)
摘要:  采用 「问-答」形式记录研读 CINN 开源框架的笔记 Q:CINN中子图编译的入口是在哪里? for (const auto& node_vec : clusters) { // < 逐个遍历每个子图 // Classify var node to inputs, outputs, and int 阅读全文
采用 「问-答」形式记录研读 CINN 开源框架的笔记 Q:CINN中子图编译的入口是在哪里? for (const auto& node_vec : clusters) { // < 逐个遍历每个子图 // Classify var node to inputs, outputs, and int 阅读全文
采用 「问-答」形式记录研读 CINN 开源框架的笔记 Q:CINN中子图编译的入口是在哪里? for (const auto& node_vec : clusters) { // < 逐个遍历每个子图 // Classify var node to inputs, outputs, and int 阅读全文
posted @ 2023-05-06 09:45
Aurelius84
阅读(151)
评论(0)
推荐(0)
摘要:  参考自 Nvidia cuRand 官方 API 文档 一、具体使用场景 如下是是在 dropout 优化中手写的 uniform_random 的 Kernel: #include <cuda_runtime.h> #include <curand_kernel.h> __device__ inl 阅读全文
参考自 Nvidia cuRand 官方 API 文档 一、具体使用场景 如下是是在 dropout 优化中手写的 uniform_random 的 Kernel: #include <cuda_runtime.h> #include <curand_kernel.h> __device__ inl 阅读全文
参考自 Nvidia cuRand 官方 API 文档 一、具体使用场景 如下是是在 dropout 优化中手写的 uniform_random 的 Kernel: #include <cuda_runtime.h> #include <curand_kernel.h> __device__ inl 阅读全文
posted @ 2023-05-06 09:35
Aurelius84
阅读(1529)
评论(0)
推荐(0)
 一、概览 注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性 |框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle | |: :|: :|: :|: :| | cond/while| √ | √ | √ |
一、概览 注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性 |框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle | |: :|: :|: :|: :| | cond/while| √ | √ | √ | 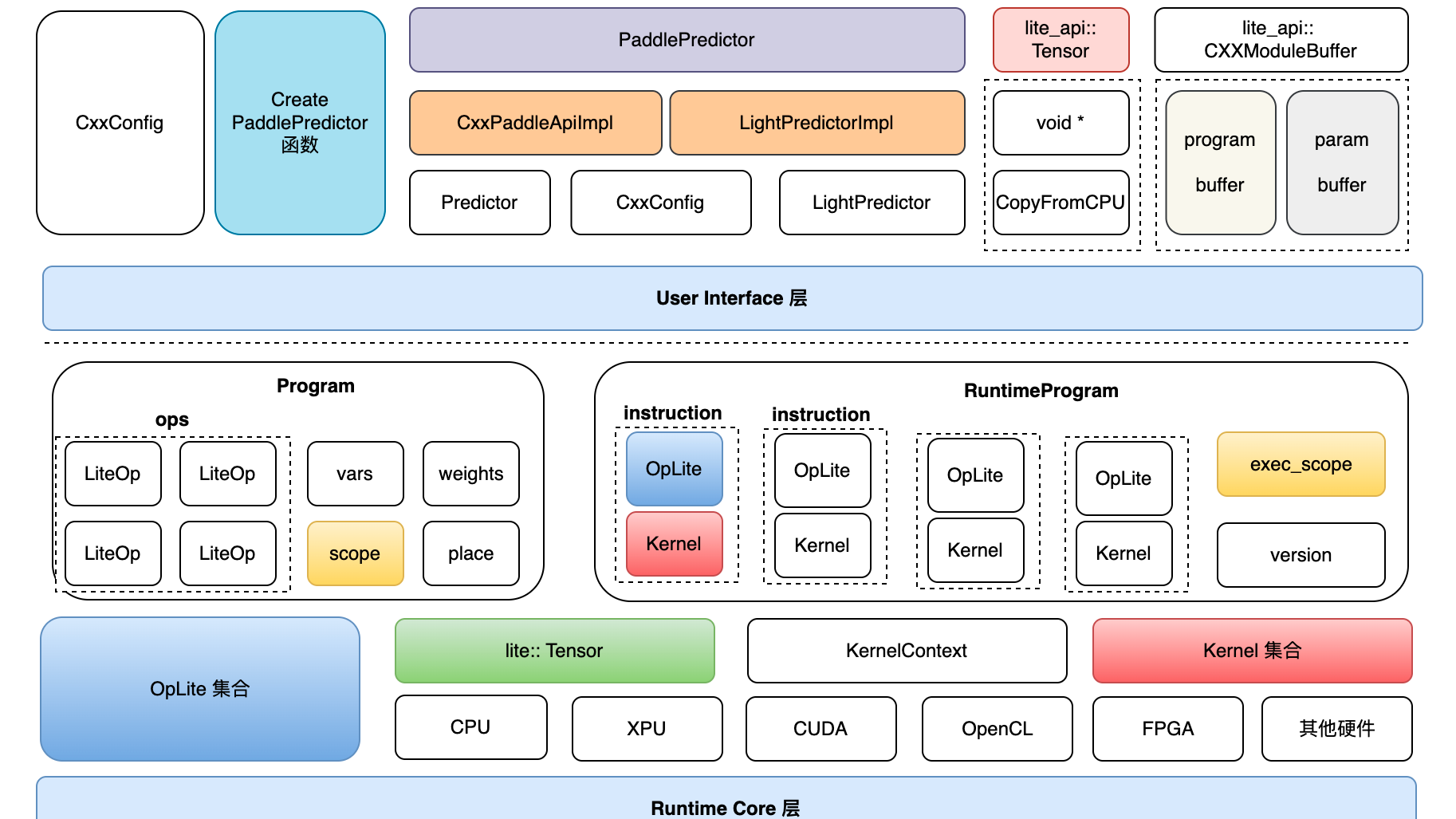 一、架构全景图 二、源码详细解读 1. Lite体系下似乎有多种 op_desc/program_desc 的定义,之间的关系是什么?这样设计的背景和好处是什么? model_parser目录下,包含 flatbuffers——结构描述定义在 framework.fbs 文件中,命名空间为paddl
一、架构全景图 二、源码详细解读 1. Lite体系下似乎有多种 op_desc/program_desc 的定义,之间的关系是什么?这样设计的背景和好处是什么? model_parser目录下,包含 flatbuffers——结构描述定义在 framework.fbs 文件中,命名空间为paddl 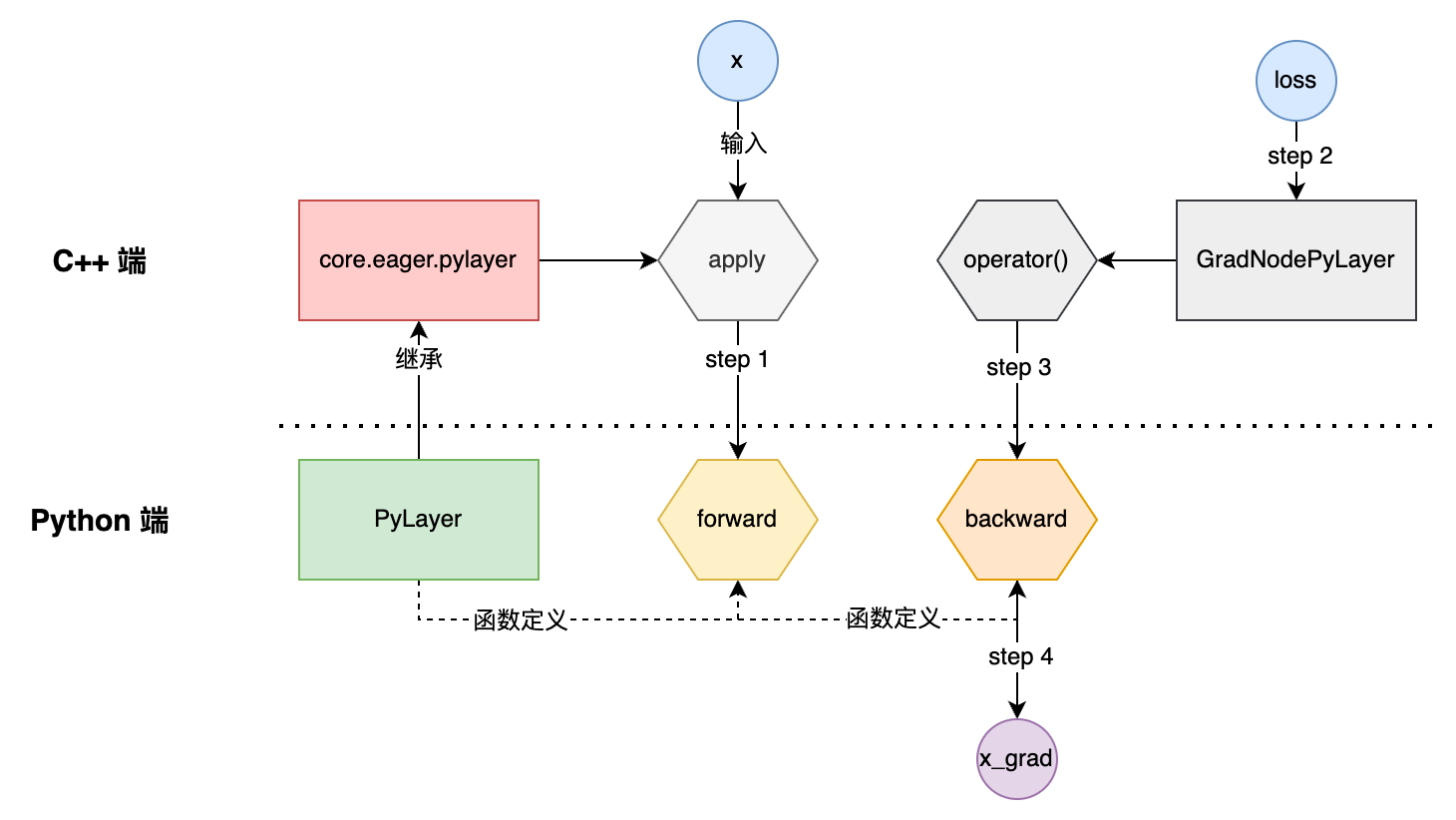 一、主要用法 如下是官方文档上的使用样例: import paddle from paddle.autograd import PyLayer # Inherit from PyLayer class cus_tanh(PyLayer): @staticmethod def forward(ctx,
一、主要用法 如下是官方文档上的使用样例: import paddle from paddle.autograd import PyLayer # Inherit from PyLayer class cus_tanh(PyLayer): @staticmethod def forward(ctx,  一、类型推导 PROs: 源码某处的类型修改,可以自动传播其他地方 Cons: 会让代码更复杂(How?) 在模板类型推导时,有引用的实参会被视为无引用,他们的引用会被忽略 template<typename T> void f(T & param); // param 是一个引用 int x =
一、类型推导 PROs: 源码某处的类型修改,可以自动传播其他地方 Cons: 会让代码更复杂(How?) 在模板类型推导时,有引用的实参会被视为无引用,他们的引用会被忽略 template<typename T> void f(T & param); // param 是一个引用 int x =  1. 命名空间 KeyNotes: 鼓励在.cc文件里使用匿名命名空间或者sttic声明 禁止使用内联命令空间,X::Y::foo 等价与X::foo。其主要用于跨版本的ABI兼容问题 namespace X{ inline namespace Y{ void foo(); } // namespa
1. 命名空间 KeyNotes: 鼓励在.cc文件里使用匿名命名空间或者sttic声明 禁止使用内联命令空间,X::Y::foo 等价与X::foo。其主要用于跨版本的ABI兼容问题 namespace X{ inline namespace Y{ void foo(); } // namespa  第一部分:基础知识 一、const 1. 作用 修饰变量,表示不可能更改 修饰指针 const int *ptr——pointer to const int const *ptr—— const pointer 原则:被const修饰的后面的值是不可改变的 修饰引用 常用于形参。即避免了copy,又
第一部分:基础知识 一、const 1. 作用 修饰变量,表示不可能更改 修饰指针 const int *ptr——pointer to const int const *ptr—— const pointer 原则:被const修饰的后面的值是不可改变的 修饰引用 常用于形参。即避免了copy,又  NVCC编译 nvcc 是cuda程序的编译器。 1. 编译阶段 用于指定编译阶段最基本的编译参数。 -c: 同gcc,只预处理、编译和汇编为.o文件,不link -lib:生成一个库文件,windows上为a.lib,其他为a.a后缀 -cuda:编译所有的.cu文件为.cu.cpp.ii -cu
NVCC编译 nvcc 是cuda程序的编译器。 1. 编译阶段 用于指定编译阶段最基本的编译参数。 -c: 同gcc,只预处理、编译和汇编为.o文件,不link -lib:生成一个库文件,windows上为a.lib,其他为a.a后缀 -cuda:编译所有的.cu文件为.cu.cpp.ii -cu  浙公网安备 33010602011771号
浙公网安备 33010602011771号