大模型如何提升训练效率
一、问题背景
随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。
1.1 直接目标
最直接地目标就是提升GPU使用率,充分发挥GPU的计算潜力,以加快模型训练。包括调整 Batch 大小以提供更多并行任务给GPU,优化DataLoader以减少GPU的等待时间,以及选择或设计与GPU并行处理能力相匹配的模型架构。
1.2 额外收益
从正向思维来看,通过合理分配CPU、GPU、内存和存储资源,可以提高资源利用率,加速训练过程,以提高整体的成本效益;同时可减少因资源限制导致训练中断或者失败,保证训练流程的顺利进行,提高模型训练有效率;
从反向思维来看,通过高效的硬件利用,降低能源消耗(如电力),降低长期的训练费用,实现经济高效的模型训练,并减少训练成本。
二、衡量指标
2.1 GPU利用率(GPU-Util)
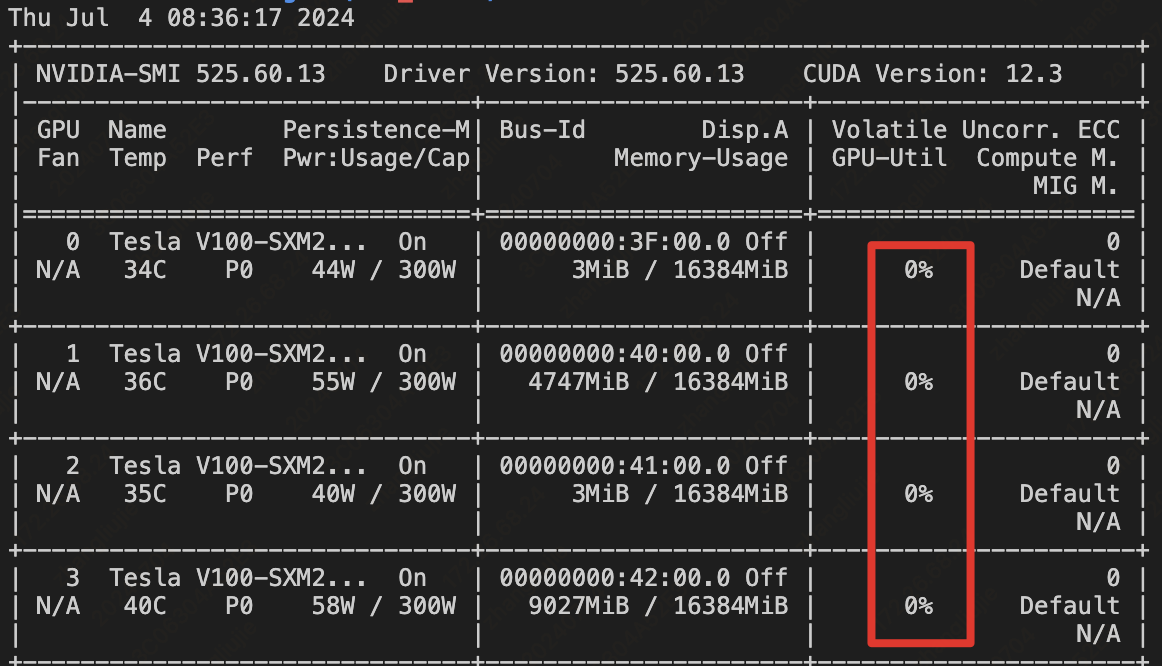
- 定义:GPU利用率是指GPU在训练过程中的繁忙程度,通常以百分比表示。这个指标直接反映了GPU资源的使用情况。
- 重要性:高利用率表示GPU在大部分时间都在进行计算操作,资源被充分利用;而低利用率则表示GPU有空闲时间未被充分利用,可能存在性能瓶颈或资源分配不均的问题。
2.2 显存使用(Memory-Usage)
- 定义 :显存使用是指GPU显存的占用情况,也是衡量GPU资源利用的重要指标之一。
- 重要性 :显存的充分利用对于高效训练至关重要。如果显存使用率很高,接近GPU显存的上限,可能会导致显存溢出错误,影响训练过程的稳定性。相反,如果显存使用率很低,则可能意味着模型没有充分利用GPU资源。
2.3 MFU(Model FLOPs Utilization)
- 定义:即模型算力利用率,是指模型一次前反向计算消耗的矩阵算力与机器(如GPU)算力的比值。
- 重要性 :它直接反映了模型在训练过程中对计算资源的有效利用程度。在大模型训练中,提高MFU是优化训练效率的关键手段之一。
MFU的值受到多种因素的影响,包括但不限于:
- 模型架构 :不同架构的模型在分布式训练中的算力利用率可能存在显著差异。例如,Transformer架构的模型由于其并行性和矩阵运算密集的特点,通常能够在分布式训练中实现较高的MFU。
- 分布式训练策略 :包括数据并行、模型并行、流水线并行等不同的并行策略,以及这些策略的具体实现方式(如梯度累积、张量并行等),都会对MFU产生重要影响。
- 硬件环境 :GPU型号、数量、网络连接速度、显存大小等硬件因素都会限制分布式训练的性能和算力利用率。
- 软件优化 :包括编译器优化、库函数优化、自动混合精度训练等软件层面的优化措施,也能在一定程度上提升MFU。
- 数据集和批次大小 :数据集的大小和复杂性,以及训练时使用的批次大小,都会影响每次迭代中的计算量和算力利用率。
由于上述因素的多样性和复杂性,各大开源模型在分布式训练上的MFU指标很难一概而论。不过,一般来说,经过良好优化和适配的开源模型,在高端GPU集群上进行分布式训练时,MFU值通常能够达到较高的水平(例如,接近或超过50%)。但请注意,这只是一个大致的估计,具体数值可能因模型、硬件和训练策略的不同而有所差异。
字节跳动的MegaScale通过算法-系统协同设计,优化了训练效率。在12288个GPU上训练一个175B LLM模型时,实现了55.2%的MFU,比Megatron-LM提高了1.34倍。
2.4 TensorCore利用率
- 定义 :TensorCore利用率是指Tensor Core在处理深度学习任务时,其计算资源的实际使用效率。
- 重要性 :Tensor Core是NVIDIA GPU上用于加速矩阵乘法和卷积运算的特殊处理单元,对于提升深度学习模型的训练和推理速度至关重要。

使用如torch profiler等工具记录训练过程中各个函数的时间消耗,并在tensorboard等可视化工具上展示,从而可以直接查看到Tensor Core的利用率。
- 优点:这种方法能够提供更详细和准确的信息,包括Tensor Core的具体使用情况和潜在的性能瓶颈。
三、问题分析
3.1 GPU利用率低
通过 nvidia-smi 查看GPU利用率低,则可能意味着GPU等待CPU处理数据,或者IO速度成为瓶颈。这种情况下,可能需要优化数据加载过程,使用更快的数据预处理方法,或者提高数据批量大小。
3.1.1 单卡GPU利用率低
- CPU瓶颈 :CPU处理数据速度跟不上GPU,导致GPU等待。
- IO限制 :数据从硬盘或网络到GPU的传输速度慢。
- 小批量大小 :批量大小设置过小,GPU未充分利用。
- 模型复杂度 :简单模型可能无法充分利用GPU能力。
- 内存带宽限制 :数据从内存到GPU的传输速度成为限制因素。
3.1.2 多卡GPU利用率都低
- 全局数据处理瓶颈 :所有GPU都在等待数据处理或加载。
- 网络通信瓶颈 :分布式训练中的网络带宽不足。
- 不适当的并行策略 :数据并行或模型并行策略设置不当。
- 软件框架和驱动问题 :深度学习框架或GPU驱动配置不佳。
3.1.2 多卡GPU利用率间歇性低
- 异步数据处理问题 :数据加载和预处理的不连续性。
- 模型同步问题 :模型并行中的GPU等待其他GPU同步。
- 负载不均衡 :工作分配给各GPU不均匀。
3.2 CPU负载过高
可以使用 htop 工具观察CPU核心的使用率。如果大部分或所有核心的使用率接近100%,表明CPU正在高强度工作,很可能成了来训练的瓶颈。这可能意味着模型训练正处于密集的计算阶段,
优化思路:
- 优化模型代码:优化数据预处理和模型代码,提高计算效率。
- 多线程或多进程 :在数据加载和预处理阶段使用多线程或多进程,以更好地利用多核CPU。
- 减轻CPU负担 :如果可能,将一些计算任务转移到GPU上,特别是对于可以并行化的任务。
另外还需要注意CPU内存的使用情况。如果内存使用率很高,接近或达到系统的最大容量,可能导致交换使用(swap usage),这会显著减慢训练速度。
3.3 高 I/O 等待
如果通过分析确认CPU和内存并不是训练瓶颈,那么IO(输入/输出)瓶颈可能是导致模型训练效率低下的原因之一。IO瓶颈通常发生在数据从存储设备加载到CPU或GPU的过程中。

我们可以使用iotop工具查看总的IO读写性能现状数据,如上图,从分析角度而言:
- 理解模型需求 :分析模型训练过程中对数据的需求。某些类型的训练,如大规模图像或视频处理,自然需要更高的I/O吞吐量。
- 考虑数据预处理 :评估数据预处理步骤是否在I/O阶段造成瓶颈,如复杂的数据增强或转换操作。
优化思路:
1. 使用更快的存储介质 :如使用SSD代替传统HDD。
2. 预加载数据 :在训练开始前预加载数据到内存中,或者实现数据缓存机制,以减少对磁盘的依赖。
3. 改进数据格式 :使用如HDF5或TFRecord这类支持高效读写的文件格式,这些格式优化了大规模数据集的存储和访问
4. 合并小文件 :将多个小数据文件合并成较大的单个文件,以减少磁盘寻道时间和提高读取效率。
5. 并行读取 :使用多线程或异步I/O来并行读取数据,特别是从大文件中读取时,这可以显著提高I/O效率。
四、分层优化总结
4.1 模型层面
4.1.1 避免D2H的同步拷贝
当频繁地使用 tensor.cpu() 将张量从 GPU 转到 CPU(或使用 tensor.cuda() 将张量从 CPU 转到 GPU)时,代价是非常昂贵的。item() 和 .numpy() 也是一样可以使用. detach() 代替。如果你需要传输数据,可以使用 . to(non_blocking=True) ,只要在传输之后没有同步点。
4.1.2 开启算子融合策略
算子融合是将原本需要多次内存访问和计算的操作合并为一个操作,减少中间结果的存储和传输开销。例如,在深度学习模型中,常见的算子融合包括将多个连续的线性变换(如卷积、全连接层等)合并为一个大的线性变换,或者将矩阵乘法与偏置相加等操作融合。
1. 高频算子优化 :针对大模型中频繁出现的算子进行优化。例如,矩阵乘法(MatMul)是Transformer等大模型中的高频算子,通过算子tiling优化合理切分数据,通过算子流水优化使得数据搬运与计算流水并行,可以显著提升计算效率。
2. 大颗粒算子融合 :将多个计算步骤融合为一个大的计算步骤。例如,CANN(昇腾计算架构)通过Flash/Sparse Attention大颗粒算子融合,减少显存耗用,提升计算性能。这种融合方式支持多种数据类型和长序列模型,具有广泛的应用前景。
3. Transformer加速库 :针对Transformer等大模型结构,构筑专门的加速库来优化核心Kernel性能。这些加速库包含了一系列针对Transformer优化的算子,如FlashAttention、MOE FFN等,能够显著提升模型的训练速度。
4.1.3 使用AMP加速训练
PyTorch 1.6 版本包括对 PyTorch 的自动混合精度训练的本地实现。这里想说的是,与单精度 (FP32) 相比,某些运算在半精度 (FP16) 下运行更快,而不会损失准确率。AMP 会自动决定应该以哪种精度执行哪种运算。这样既可以加快训练速度,又可以减少内存占用。
4.1.4 其他API层面技巧
torch.tensor() 总是会复制数据。如果你要转换一个 numpy 数组,使用 torch.as_tensor() 或 torch.from_numpy() 来避免复制数据。
在开始 BatchNormalization 层之前关闭 bias 层。对于一个 2-D 卷积层,可以将 bias 关键字设置为 False:torch.nn.Conv2d(..., bias=False, ...)。
4.2 数据处理
4.2.1 合理设置num_worker
当使用 torch.utils.data.DataLoader 时,设置 num_workers > 0,而不是默认值 0,同时设置 pin_memory=True ,而不是默认值 False。
选择 worker 数量的经验法则是将其设置为可用 GPU 数量的四倍,大于或小于这个数都会降低训练速度。请注意,增加 num_workers 将增加 CPU 内存消耗。
4.2.2 指定 pinn_memory=True
在使用 PyTorch 的 DataLoader 时,设置pin_memory=True主要是为了加速数据的加载过程。这个选项的作用是将加载的数据张量(Tensor)预先存储在锁页内存(pinned memory)中,而不是常规的内存。锁页内存的一个重要特性是,它可以被GPU直接访问,而不需要通过CPU进行中转。这样做的好处是可以减少数据在CPU和GPU之间的传输次数,从而降低数据传输的开销,加快训练过程。
什么是锁页内存?
锁页内存(Pinned Memory或Page Locked Memory)是一种特殊的内存分配方式,在CUDA编程和深度学习中尤为重要。以下是关于锁页内存的详细解释:
锁页内存是指分配在主机(CPU)内存中的一块区域,该区域被操作系统锁定,以防止其在物理内存中移动或换页到虚拟内存(即硬盘空间)中。这样做的主要目的是为了提高数据在主机与设备(如GPU)之间的传输效率,主要特性如下:
- 固定位置 :锁页内存被固定在物理内存中的特定位置,不会因内存压力而被操作系统移动到虚拟内存中。这保证了内存地址的稳定性,对于需要直接内存访问(DMA)的硬件外设(如GPU)来说至关重要。
- 提高传输效率 :由于锁页内存不会移动,GPU上的DMA控制器可以直接访问这些内存区域,而无需CPU的介入。这减少了CPU的负担,并提高了数据传输的速度和效率。
- 分配与释放:在CUDA中,锁页内存可以通过CUDA驱动API(如cuMemAllocHost())或运行时API(如cudaMallocHost())来分配。释放时,应使用相应的函数(如cudaFreeHost())。此外,还可以使用主机上的Malloc()函数分配内存,然后通过cudaHostRegister()函数将其注册为锁页内存。
4.2.3 使用DALI库
DALI库的核心优势在于其GPU加速能力。传统的数据预处理过程大多在CPU上执行,包括数据的加载、解码、裁剪、调整大小等操作,这些操作往往是计算密集型的,且受限于CPU的计算能力。而DALI库通过将部分或全部数据预处理任务卸载到GPU上执行,充分利用了GPU强大的并行计算能力,从而显著提升了数据预处理的速度。这种GPU加速能力使得DALI在处理大规模数据集时能够保持高效,减少了数据预处理对整体训练过程的瓶颈效应。
DALI允许开发人员创建自定义的数据处理pipeline,通过灵活的计算图来表示不同的数据处理流程。开发人员可以根据需要选择适当的操作符,并指定它们在CPU或GPU上执行,从而构建出最适合自己应用场景的数据预处理方案。此外,DALI还支持通过自定义操作符来扩展其功能,以满足特定的数据处理需求。DALI的异步执行和预取机制有助于隐藏预处理延迟,使得整体训练流程更加流畅。
4.2.4 借助数据预取
在模型训练过程中,数据预取技术主要应用于以下几个方面:
- 大规模数据集处理 :对于包含数百万甚至数十亿样本的大规模数据集,数据预取技术可以显著减少数据处理的时间,提高训练效率。
- 深度学习模型训练 :在训练深度学习模型时,数据预取可以帮助模型在GPU或TPU等加速器上持续获得训练数据,减少因数据加载不足而导致的计算资源闲置。
- 分布式训练 :在分布式训练环境中,数据预取技术可以确保各个计算节点能够及时获得所需的数据,保持训练过程的同步性和高效性。
4.3 框架层面
如果是自研的框架,可以考虑结合前沿深度学习框架发展趋势,研发更高效的功能,开发给用户训推加速。比如开启编译器,或者针对模型特点,自定义实现更大的融合算子;
如果是成熟的开源框架,可以参考官网的最佳实践,或者探索、组合、定制化各种加速策略,包括分布式混合并行的编排方式等,实现训练加速;
4.4 硬件层面
- 内存带宽限制:数据从内存到GPU的传输速度成为限制因素。
- 软件框架和驱动问题:深度学习框架或GPU驱动配置不佳。
五、业务导向
如果所在的部门是负责管理公司的GPU资源的,GPU利用率的治理和提升是部门重要的OKR,从这个角度来来阐述下如何达成OKR?
5.1 指标监控体系(What)
5.1.1 GPU 利用率
可以通过 nvidia-smi 工具和自动化脚本,监控模型训练期间的GPU 利用率、显存占用、功率、显卡温度、风扇转速等信息
5.1.2 CPU 负载
通过 htop 等系统或三方工具,监控模型训练进程的CPU负载、判断是否为CPU瓶颈;监控内存使用情况,是否处于接近打满内存的状态,此时可能会出现频繁的内存交换;如果关心磁盘IO的状态,可以使用iotop等工具来监控模型训练期间磁盘读写的情况,用于判断是否为IO瓶颈;
5.1.3 TensorCore利用率
TensorCore的统计有多种,对于给定的模型,其一个前反向计算所需要的FLOPS是固定的,只需要在模型训练日志里记录其每个迭代的训练时间即可,通过公式即可得到TensorCore的利用率。
5.1.4 通信延迟和带宽占用
5.2 瓶颈分析工具(Why)
5.2.1 Nsight system 工具
NVIDIA Nsight Systems是一个用于监测代码执行效率及分析性能的工具,它是NVIDIA Nsight系列的一部分。Nsight Systems可以收集和分析应用程序在CPU和GPU上的执行数据,帮助开发者识别性能瓶颈,优化程序性能。
1. 安装Nsight Systems:
- 访问NVIDIA官方网站下载Nsight Systems的安装包。
- 按照安装向导完成安装过程。
2. 配置环境:
- 确保CUDA环境变量已正确配置,以便Nsight Systems能够识别CUDA应用程序。
3. 生成Profile文件:
- 使用Nsight Systems提供的命令行工具(如nsys)来生成Profile文件。例如,可以使用nsys profile -o profile_name.qdrep python test.py命令来生成Python脚本的Profile文件。
4. 分析Profile文件:
- 打开Nsight Systems GUI,加载生成的Profile文件(.qdrep格式)。
- 使用Nsight Systems的图形界面来查看和分析应用程序的执行数据,包括CPU和GPU的使用情况、函数调用时间、内存访问等。
5.2.2 torch profile 工具
如果你是使用的Pytorch框架,可以使用其profile工具和tensorboard可视化界面来分析模型的性能瓶颈点,具体可以参考:PyTorch Profiler With TensorBoard。
1. 计算图概况 :torch profile可以生成模型的计算图,并突出显示每个操作的时间消耗,这有助于识别潜在的瓶颈。
2. 内存使用统计 :实时监控模型训练过程中的GPU内存占用情况,便于调整参数以优化资源利用。
3. 快速定位性能问题 :通过可视化每个操作的执行时间,可以迅速找到导致模型训练速度慢的原因。
4. 优化硬件资源利用 :查看内存使用情况,以便确定合适的批量大小和其他内存管理策略。
5. 详细的层析剖析 :不仅仅提供总体性能分析,还可以对模型中的每一个单独层进行分析,展示每个层在CPU和CUDA上的执行时间。
6. 事件列表 :提供原始的PyTorch事件列表,以便开发者能够深入了解底层操作(如卷积、激活函数等)的执行时间。
7. 选择性剖析 :用户可以指定要分析的具体层,其余层将被忽略,这样可以更加聚焦于关键部分。
8. 硬件资源管理 :分析模型在不同硬件环境下的性能,比如CPU与GPU之间的切换。
5.3 系统的优化方法论(How)
5.3.1 明确GPU 空闲产生的原因
借助可视化工具分析profile文件中,GPU 空闲产生的原因,判断属于是哪几类问题?
- 数据读取瓶颈 :一般在timeline里每个Step的开始前面都会有固定的GPU空闲,数据读取无法与计算实现Overlap;
- 模型写法问题 :比如模型计算中间有Sync操作,可能是存在D2H的同步拷贝,比如存在Tensor.numpy()等类似操作;
- 通信存在瓶颈 :在分布式训练中,不同的并行策略可能会影响通信成本;一般张量并行放在同一个机器不同卡上,数据并行是不同机器之间;
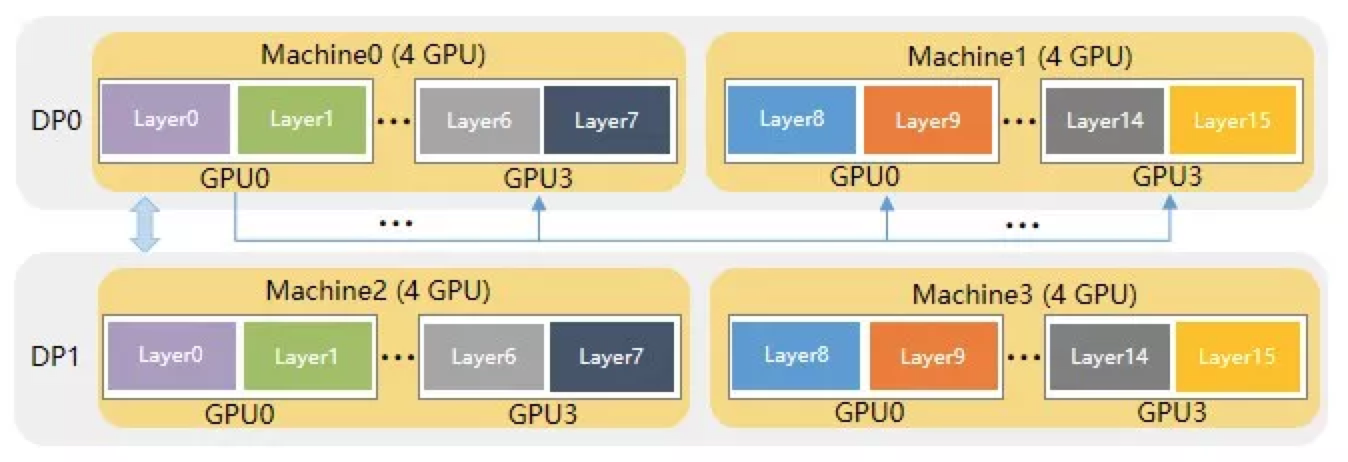
5.3.2 对症下药
最终目的是最大化GPU利用率,前面章节已经根据各种场景针对性地阐述了对应的解决方案;
5.3.3 指导性建议
类似torch.profile在基于TensorBorad可视化后,会针对性提供一些优化的思路,本质是一个对各种监控指标和原生profile数据的建模问题。可以根据沉淀的经验,结合不同的指标特征给业务同学更多的优化经验准则。
从GPU资源管理平台而言,前期应该是尽可能是给出可置信的核心指标数据,以及辅助的层次化指标(如CPU负载、IO等)。大模型训练优化实施方仍然需要模型负责人接入,由于大模型一般变动的频率比较低,因为联动框架同学一同定制化优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号